
Intelligent Anti-Jamming Decision Algorithm for Wireless Communication Based on MAPPO


Abstract
1. Introduction
2. System Model and Problem Formulation
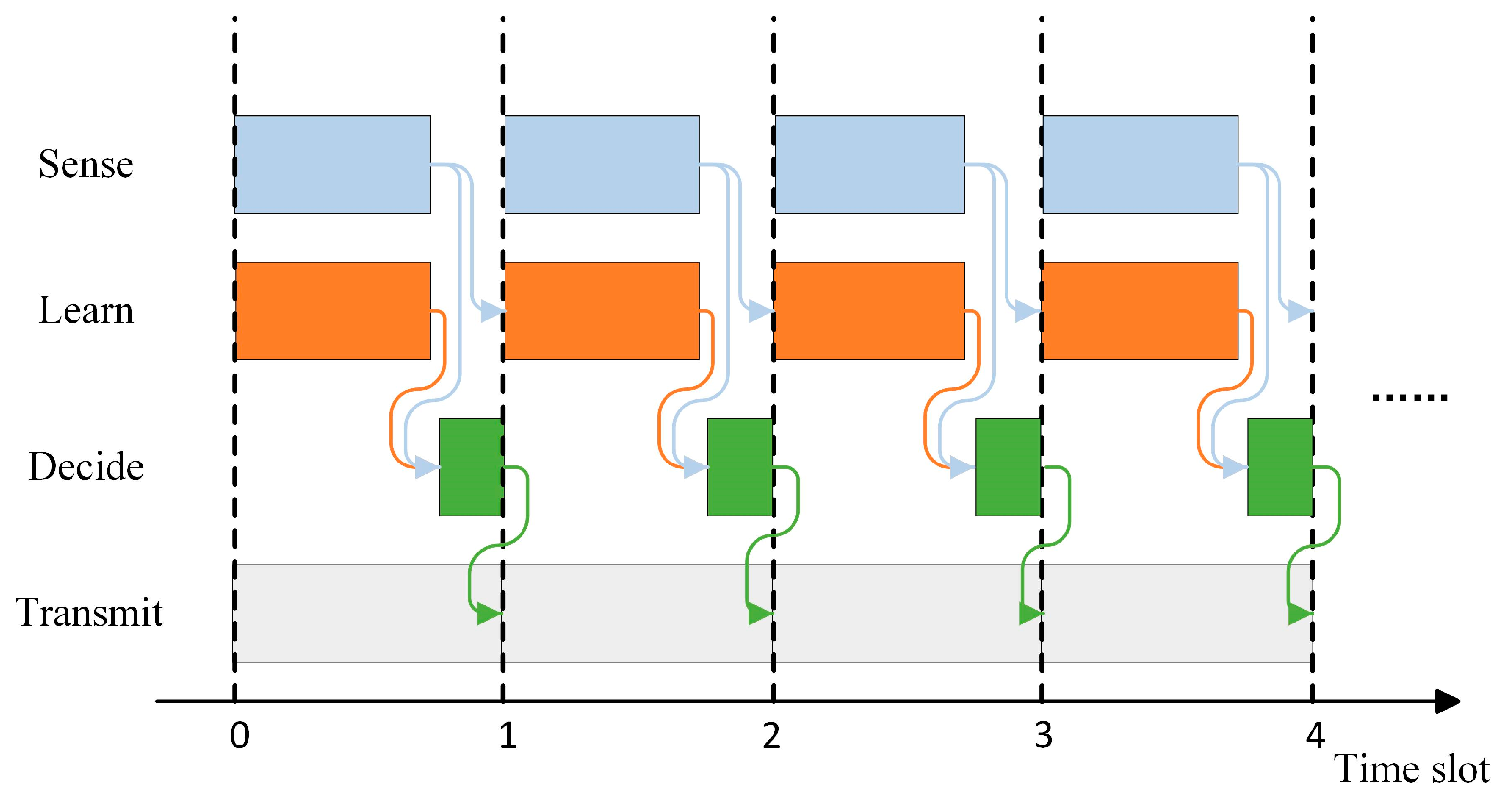
2.1. System Model
2.2. Problem Formulation
3. Intelligent Anti-Jamming Decision Algorithm for Wireless Communication Based on MAPPO
| Algorithm 1: The wireless communication intelligent anti-jamming algorithm based on MAPPO |
|
4. Simulations and Analyses
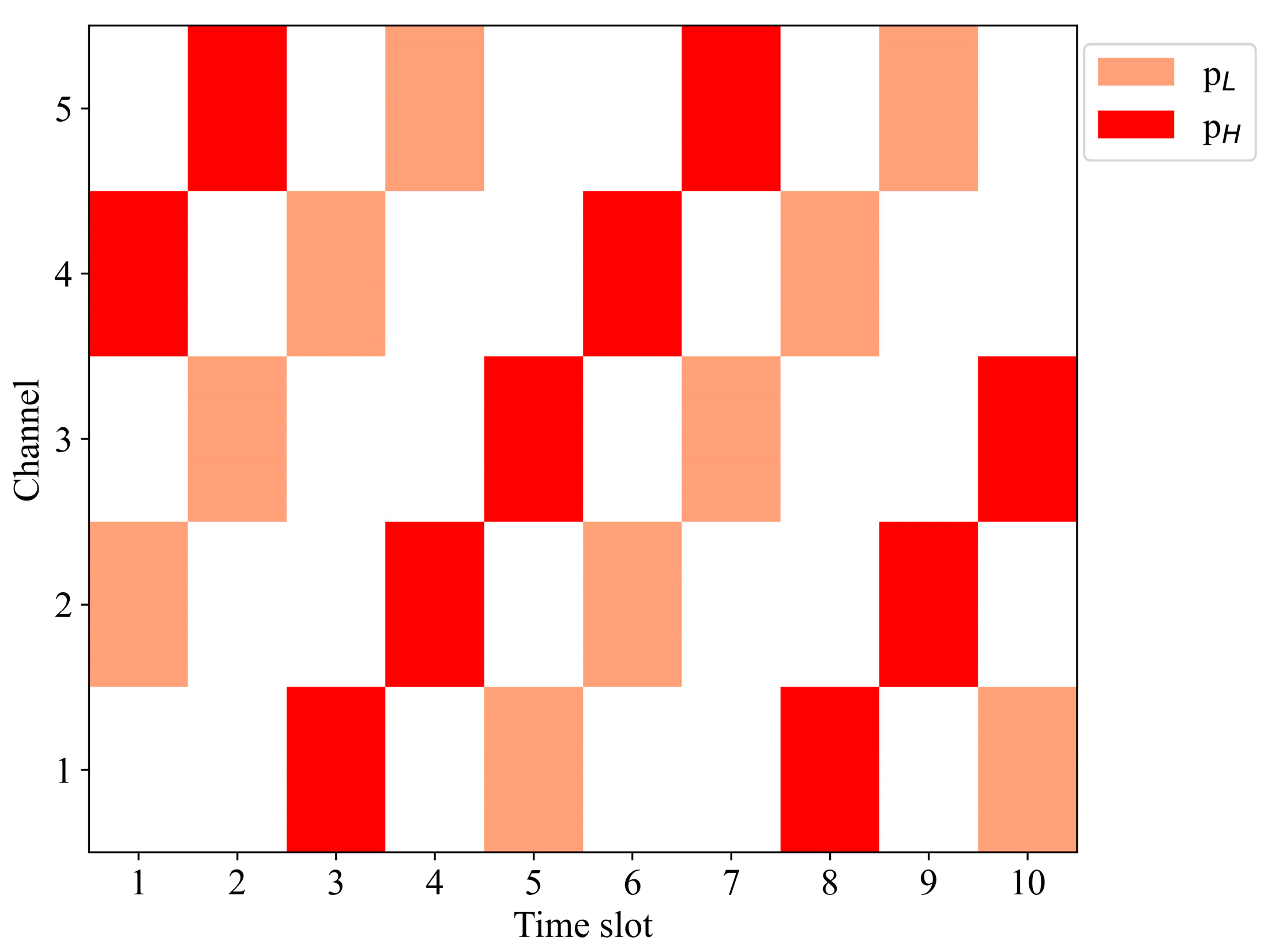
4.1. Parameter Settings
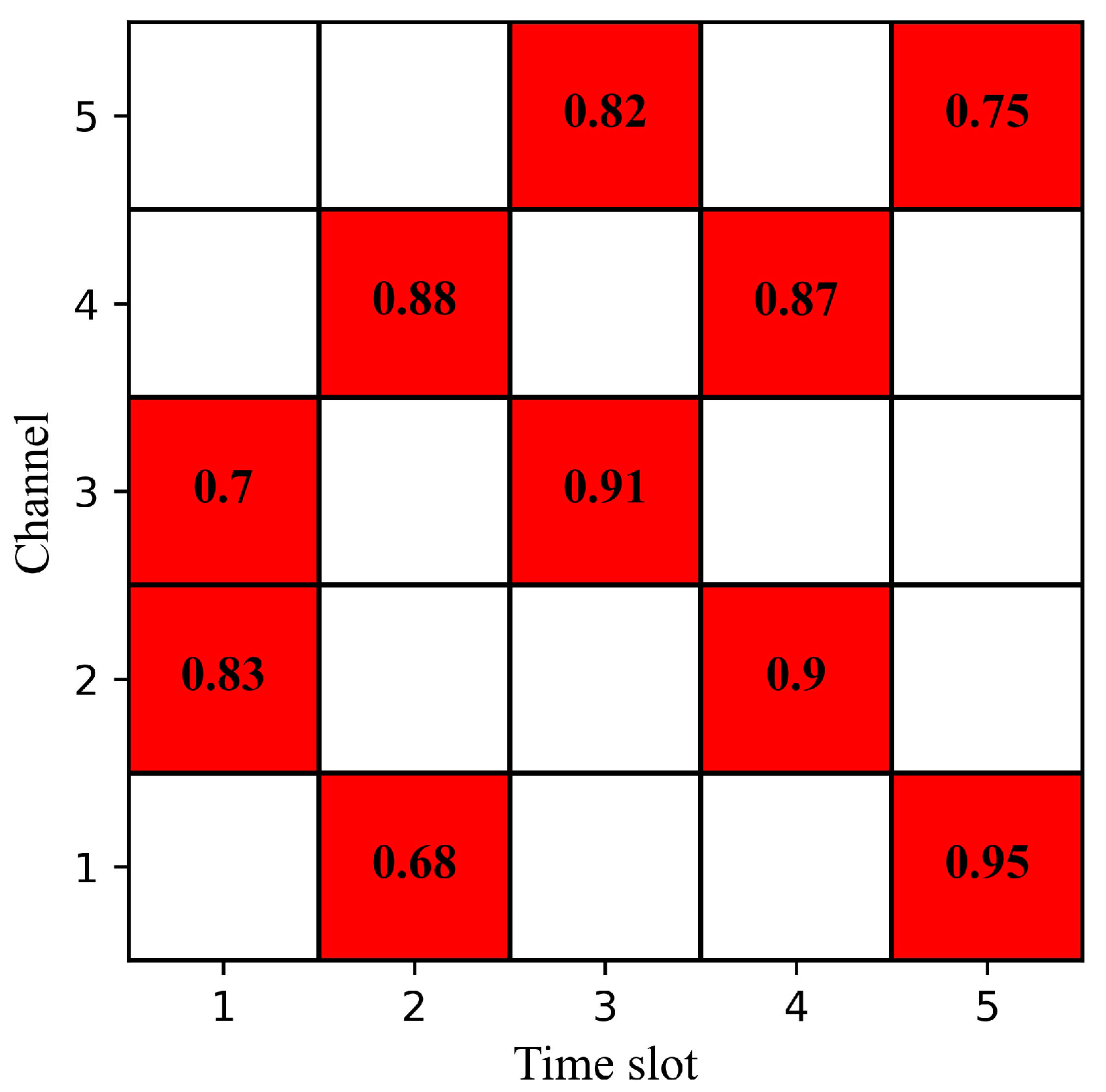
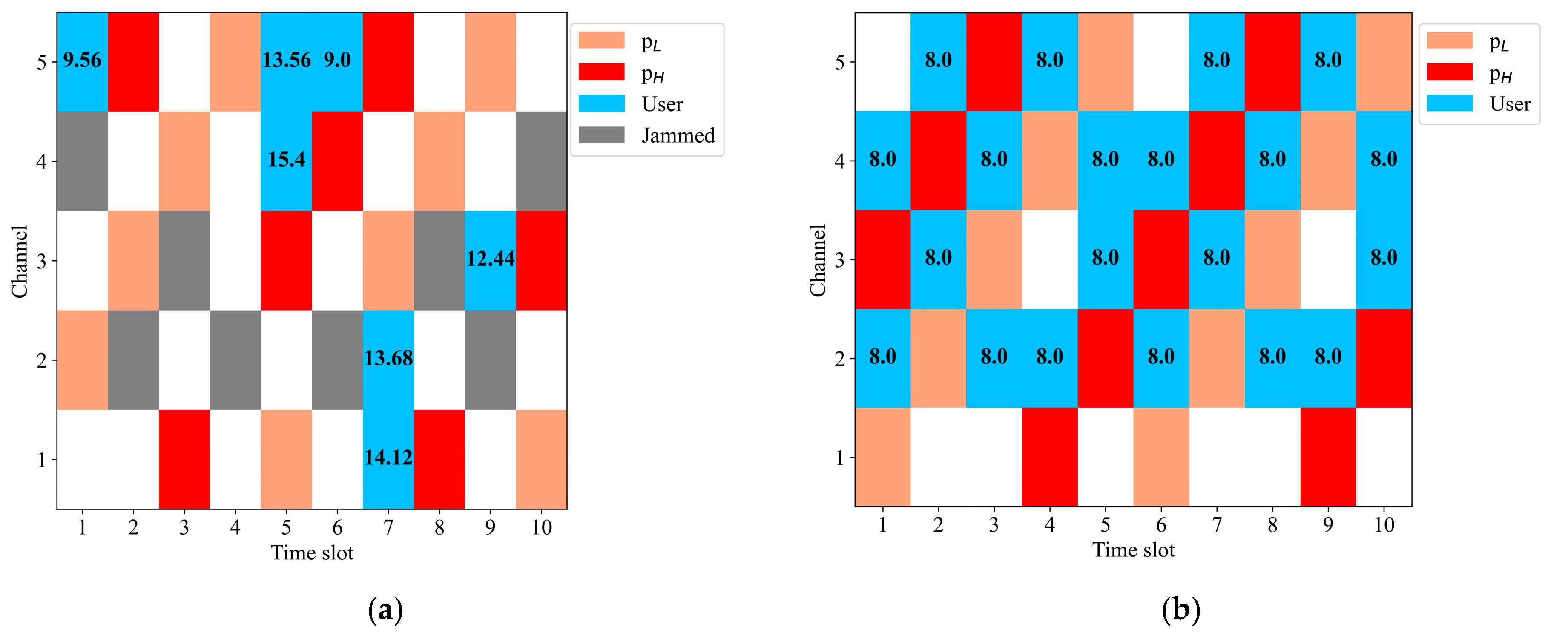
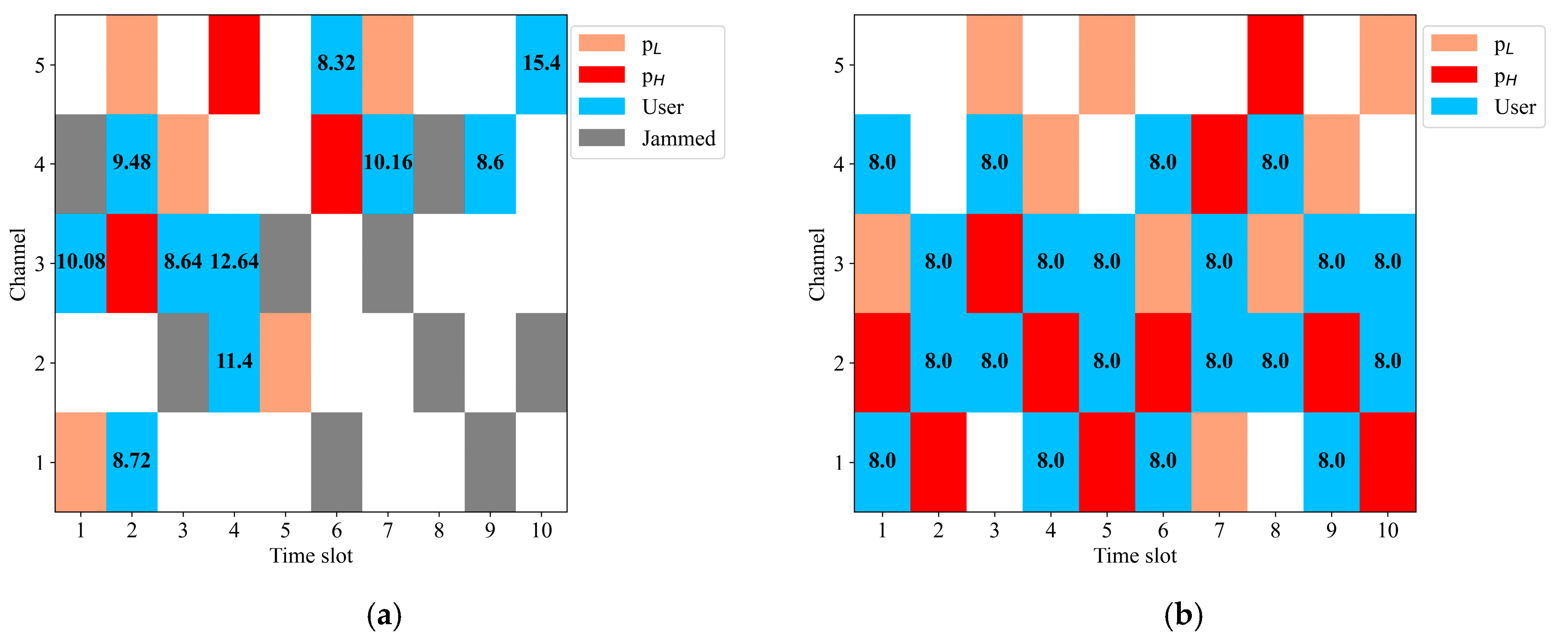
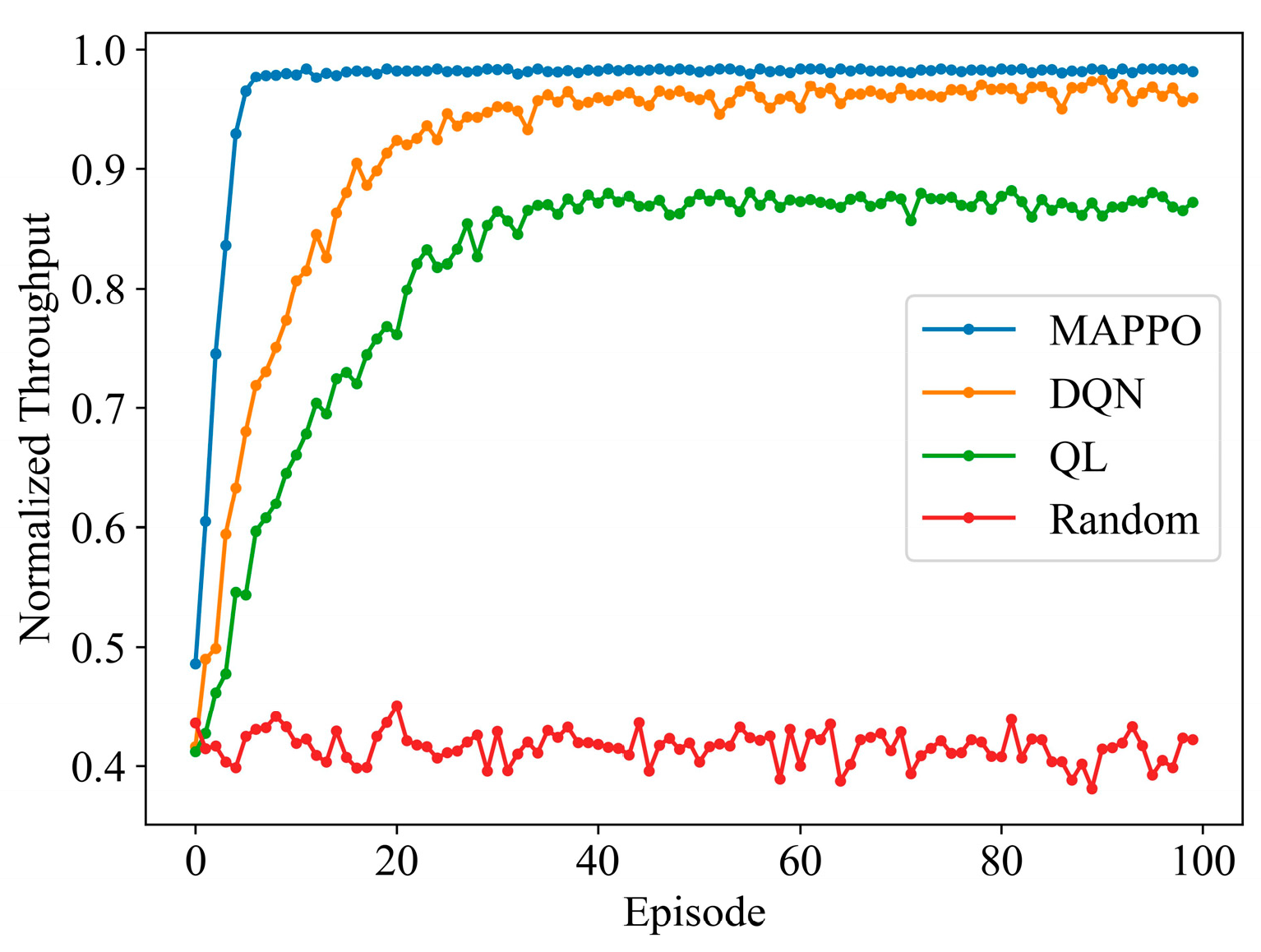
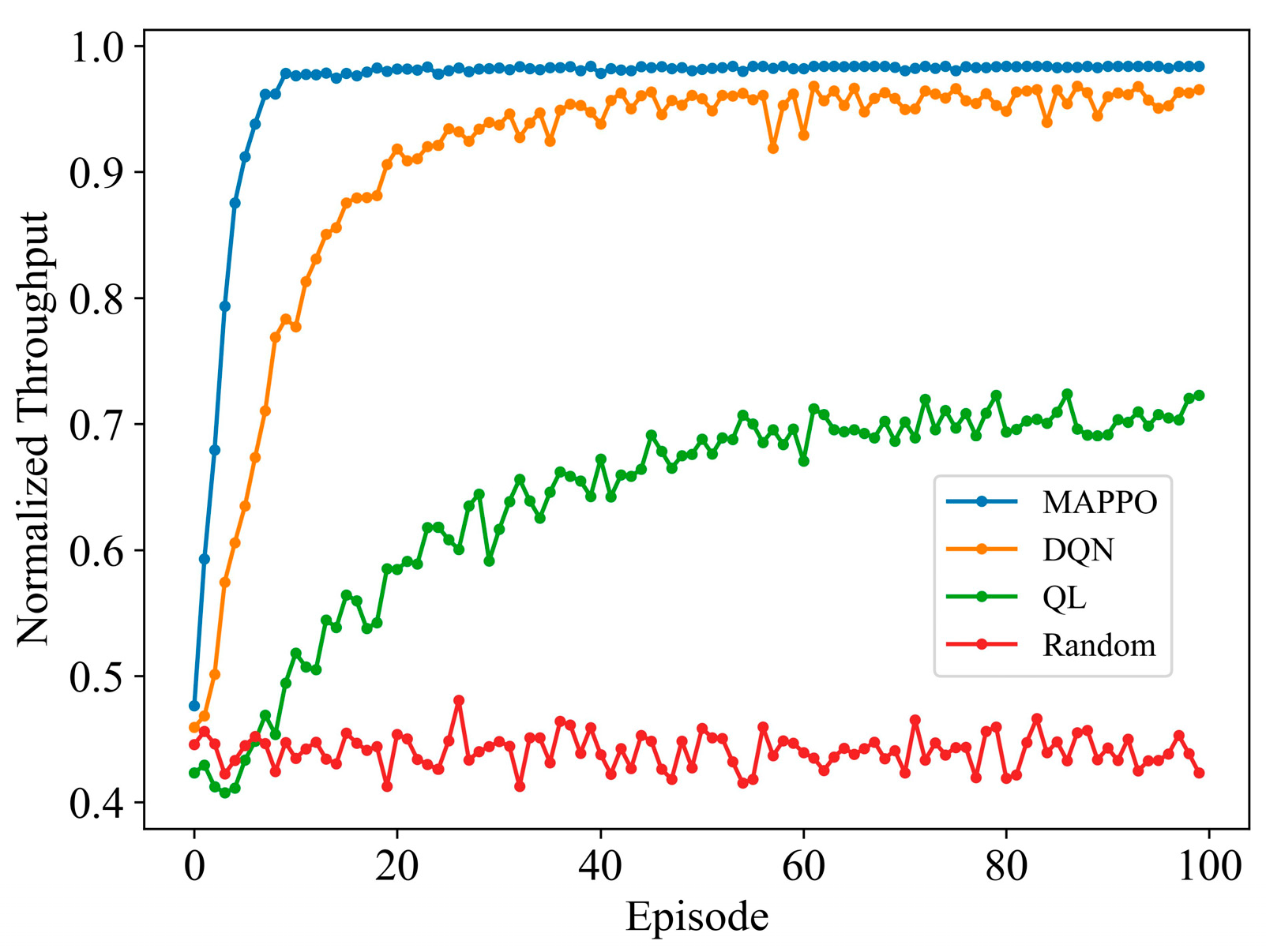
4.2. Simulation Results and Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zuo, Y.; Guo, J.; Gao, N.; Zhu, Y.; Jin, S.; Li, X. A survey of blockchain and artificial intelligence for 6G wireless communications. IEEE Commun. Surv. Tutor. 2023, 25, 2494–2528. [Google Scholar] [CrossRef]
- Pirayesh, H.; Zeng, H. Jamming attacks and anti-jamming strategies in wireless networks: A comprehensive survey. IEEE Commun. Surv. Tutor. 2022, 24, 767–809. [Google Scholar] [CrossRef]
- Torrieri, D. Principles of Spread-Spectrum Communication Systems; Springer Publishing Company: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Yao, F. Communication Anti-Jamming Engineering and Practice; Publishing House of Electronics Industry: Beijing, China, 2012. [Google Scholar]
- Aref, M.A.; Jayaweera, S.K.; Yepez, E. Survey on cognitive anti-jamming communications. IET Commun. 2020, 14, 3110–3127. [Google Scholar] [CrossRef]
- Bell, J. What is machine learning. In Machine Learning and the City: Applications in Architecture and Urban Design; John Wiley & Sons: Hoboken, NJ, USA, 2022; Volume 9, pp. 207–216. [Google Scholar] [CrossRef]
- Zhou, Q.; Niu, Y.; Xiang, P.; Li, Y. Intra-domain knowledge reuse assisted reinforcement learning for fast Anti-Jamming communication. IEEE Trans. Inf. Forensics Secur. 2023, 18, 4707–4720. [Google Scholar] [CrossRef]
- Li, Y.; Xu, Y.; Wang, X.; Li, W.; Bai, W. Power and Frequency Selection optimization in Anti-Jamming Communication: A Deep Reinforcement Learning Approach. In Proceedings of the IEEE 5th International Conference on Computer and Communications, Chengdu, China, 6–9 December 2019; pp. 815–820. [Google Scholar] [CrossRef]
- Yuan, H.; Song, F.; Chu, X.; Li, W.; Wang, X.; Han, H.; Gong, Y. Joint Relay and Channel Selection Against Mobile and Smart Jammer: A Deep Reinforcement Learning Approach. IET Commun. 2021, 15, 2237–2251. [Google Scholar] [CrossRef]
- Foerster, J.N.; Assael, Y.M.; Freitas, N.D.; Whiteson, S. Learning to communicate with Deep multi-agent reinforcement learning. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 2145–2153. [Google Scholar] [CrossRef]
- Gao, A.; Du, C.; Ng, S.X.; Liang, W. A Cooperative Spectrum Sensing With Multi-Agent Reinforcement Learning Approach in Cognitive Radio Networks. IEEE Commun. Lett. 2021, 25, 2604–2608. [Google Scholar] [CrossRef]
- Yu, C.; Velu, A.; Vinitsky, E.; Gao, J.; Wang, Y.; Bayen, A.; Wu, Y. The surprising effectiveness of PPO in cooperative, multi-agent games. arXiv 2022, arXiv:2103.01955. [Google Scholar]
- He, Y.; Gang, X.; Gao, Y. Intelligent Decentralized Multiple Access via Multi- Agent Deep Reinforcement Learning. In Proceedings of the IEEE Wireless Communications and Networking Conference, Dubai, United Arab Emirates, 21–24 April 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Sun, Y.; He, Q. Computational Offloading for MEC Networks with Energy Harvesting: A Hierarchical Multi-Agent Reinforcement Learning Approach. Electronics 2023, 12, 1304. [Google Scholar] [CrossRef]
- Pu, Z.; Niu, Y.; Zhang, G. A Multi-Parameter Intelligent Communication Anti-Jamming Method Based on Three-Dimensional Q-Learning. In Proceedings of the IEEE 2nd International Conference on Computer Communication and Artificial Intelligence, Beijing, China, 6–8 May 2022; pp. 205–210. [Google Scholar] [CrossRef]
- Zhou, Q.; Niu, Y.; Xiang, W.; Zhao, L. A Novel Reinforcement Learning Algorithm Based on Broad Learning System for Fast Communication Anti-jamming. IEEE Trans. Ind. Inform. 2024, 1–10. [Google Scholar] [CrossRef]
- Mughal, M.O.; Nawaz, T.; Marcenaro, L.; Regazzoni, C.S. Cyclostationary-based jammer detection algorithm for wide-band radios using compressed sensing. In Proceedings of the IEEE Global Conference on Signal and Information Processing, Orlando, FL, USA, 14–16 December 2015; pp. 280–284. [Google Scholar] [CrossRef]
- Chang, X.; Li, Y.B.; Zhao, Y.; Du, Y.F.; Liu, D.H. An Improved Anti-Jamming Method Based on Deep Reinforcement Learning and Feature Engineering. IEEE Access 2022, 10, 69992–70000. [Google Scholar] [CrossRef]
- Niu, Y.; Zhou, Z.; Pu, Z.; Wan, B. Anti-Jamming Communication Using Slotted Cross Q Learning. Electronics 2023, 12, 2879. [Google Scholar] [CrossRef]
- Watkins, C.J.C.H. Learning from Delayed Rewards. Ph.D. Thesis, University of Cambridge, Cambridge, UK, 1989. [Google Scholar] [CrossRef]
- Lin, X.; Liu, A.; Han, C.; Liang, X.; Sun, Y.; Ding, G.; Zhou, H. Intelligent Adaptive MIMO Transmission for Nonstationary Communication Environment: A Deep Reinforcement Learning Approach. IEEE Trans. Commun. 2025. [Google Scholar] [CrossRef]
- Zuo, J.; Ai, Q.; Wang, W.; Tao, W. Day-Ahead Economic Dispatch Strategy for Distribution Networks with Multi-Class Distributed Resources Based on Improved MAPPO Algorithm. Mathematics 2024, 12, 3993. [Google Scholar] [CrossRef]
- Ibrahim, K.; Ng, S.X.; Qureshi, I.M.; Malik, A.N.; Muhaidat, S. Anti-Jamming Game to Combat Intelligent Jamming for Cognitive Radio Networks. IEEE Access 2021, 9, 137941–137956. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari with Deep Reinforcement Learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Wang, Y.; Niu, Y.; Chen, J.; Fang, F.; Han, C. Q-Learning Based Adaptive Frequency Hopping Strategy Under Probabilistic Jamming. In Proceedings of the 2019 11th International Conference on Wireless Communications and Signal Processing, Xi’an, China, 23–25 October 2019; pp. 1–7. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Numerical Values | Parameters | Numerical Values |
|---|---|---|---|
| 2 | 5 | ||
| 2 MHz | 20 ms | ||
| 8~16 dBm | 12 dBm, 20 dBm | ||
| 4 dB | 0.02 | ||
| 0.025 | Experience pool size | 10,000 | |
| 0.3 | 0.2 | ||
| 0.0005 | Optimizer | RMSprop |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, F.; Niu, Y.; Zhou, W. Intelligent Anti-Jamming Decision Algorithm for Wireless Communication Based on MAPPO. Electronics 2025, 14, 462. https://doi.org/10.3390/electronics14030462
Zhang F, Niu Y, Zhou W. Intelligent Anti-Jamming Decision Algorithm for Wireless Communication Based on MAPPO. Electronics. 2025; 14(3):462. https://doi.org/10.3390/electronics14030462
Chicago/Turabian StyleZhang, Feng, Yingtao Niu, and Wenhao Zhou. 2025. "Intelligent Anti-Jamming Decision Algorithm for Wireless Communication Based on MAPPO" Electronics 14, no. 3: 462. https://doi.org/10.3390/electronics14030462
APA StyleZhang, F., Niu, Y., & Zhou, W. (2025). Intelligent Anti-Jamming Decision Algorithm for Wireless Communication Based on MAPPO. Electronics, 14(3), 462. https://doi.org/10.3390/electronics14030462