1. Introduction
With the rapid development of the internet and the popularization of web applications, web security problems have become increasingly serious. A Webshell [
1,
2,
3] is a kind of malicious script that realizes remote control through the script interface provided by a web page, and it is often used by attackers to invade and control web servers, which results in serious consequences, such as data leakage and server crashes. Therefore, effective Webshell detection methods have become a key means of securing web applications. However, as a Webshell is usually used by attackers to bypass antivirus detection through obfuscation, nesting, and other antivirus-free methods, this brings many challenges to network defense.
As shown in
Figure 1a, for Webshell code, traditional rule-based detection methods first match the “<?php” tag to identify the content as PHP code. Then, they match the “eval” function name to detect the presence of a code execution function. Finally, by matching “
$_REQUEST”, the code is determined to be a Webshell.
Although this matching method can detect conventional Webshell content, for the obfuscated Webshell shown in
Figure 1b, the aforementioned rules can only identify the PHP tag, recognizing it as a PHP code snippet. However, the “eval” function is obfuscated using comment symbols that disrupt the structure, causing matching rules to fail. Therefore, traditional rule-based matching cannot effectively address such cases.
In recent years, the rapid development of deep learning technology has provided new opportunities for Webshell detection. The emergence of large language models has achieved remarkable success in the field of natural language processing (NLP), with Google’s BERT model reaching the forefront of NLP research. Similarly, code can also be viewed as a language fragment with specific relationships. For the code shown in
Figure 1b, the CodeBERT [
4,
5,
6] model can understand that the portion “/*xxxxxxxxxxxx*/” represents comment symbols, and it still retains the “eval” function name, thereby extracting this critical feature. However, for the code in
Figure 1c, which constructs a Webshell using the PHP’s self-increment properties and XOR principles, this type of code lacks standard syntactic features. As a result, text-based detection methods alone cannot effectively handle such Webshell samples. Nevertheless, these samples exhibit distinct structural features. For instance, in
Figure 1c, there are fixed patterns, such as the “.” symbol following the variable declaration symbol “
$__” and the XOR calculation involving two characters after the “=” symbol. Leveraging convolutional neural networks (CNNs) [
7,
8,
9], which excel in image processing, can achieve better feature extraction for such structural characteristics.
To address the limitations of existing research in effectively detecting Webshell samples processed using evasion techniques, this study comprehensively extracted features from both the semantic and visual modalities of Webshell samples. It proposes a multimodal feature fusion-based Webshell detection method (MMF-Detect, Method of Multimodal Fusion) that extracts features from both the semantic and visual modalities of code. This approach effectively mitigates the interference caused by encoding, encryption, and obfuscation techniques in static sample file detection, significantly improving the detection accuracy of evasion samples.The main contributions of this paper include the following three points:
(1) Innovation in Visual Modality Feature Extraction: A DropCNN model was designed for RGB images of code. By optimizing the model architecture, two sets of convolutional layers, pooling layers, and drop layers with varying dimensions were connected. This design enhances the extraction of subtle patterns in code images, facilitating the classification of Webshell samples through a visual modality.
(2) Efficient Semantic Modality Classification Model: A CodeBERT-based code language model (CodeBERT-CL) was constructed, specifically developed to achieve a semantic understanding of Webshell samples. By innovatively applying masked language modeling techniques, the model’s efficiency in processing long code sequences was significantly enhanced. This approach enables the model to focus on learning the semantic information within the code sequences while ignoring irrelevant noise.
(3) Multimodal Feature Fusion and Decision Algorithm: To fully leverage the features of both semantic and visual modalities, we have designed an adaptive multimodal feature fusion algorithm (DQS). This algorithm dynamically calculates the fusion coefficient Q based on the length and complexity of the sample file, maximizing the effective features from different modalities while minimizing the impact of sample disparities on the fusion decision. Ultimately, this approach achieves a higher classification accuracy for evasion Webshell samples.
The structure of this paper is organized as follows: In
Section 2, we review relevant work in the field of Webshell detection, demonstrating that the MMF-Detect method can overcome the limitations of existing research.
Section 3 explores the design of the MMF-Detect method, providing a detailed introduction to the construction of the text classifier based on CodeBERT-CL, the image classifier based on DropCNN, and the adaptive fusion mechanism utilizing the DQS algorithm. This section explains how the method integrates semantic and visual features to identify Webshell code.
Section 4 presents the experimental evaluation of the MMF-Detect method, detailing the datasets used, evaluation metrics, and comparisons with other existing methods through a series of experiments. This section offers empirical evidence of the method’s superiority.
Section 5 discusses the limitations, practical applications, and future research directions for the MMF-Detect method. Finally,
Section 6 concludes the paper by summarizing the achievements of the MMF-Detect method and emphasizing its effectiveness in detecting evasive Webshells.
2. Related Work
The detection of Webshells has always been a critical research topic in the field of cybersecurity. Traditional signature-based and rule-based detection methods have gradually become ineffective in countering complex and covert attack techniques. In recent years, researchers have begun exploring machine learning and deep learning-based methods for Webshell detection. Guo et al. [
10] proposed a Webshell detection model based on the Naive Bayes classifier, which analyzes features such as the length of the longest word in the file and overlap factors, effectively detecting obfuscated Webshell files. Lv et al. [
11] presented a detection method based on a convolutional neural network (CNN). This method first segments characters, then vectorizes word encoding using the Word2Vec algorithm and finally applies a CNN network for binary classification. Although this method eliminates the need for manual feature extraction, the model heavily relies on the quantity and quality of the training samples.
To further explore sample features and mitigate the influence of the sample quantity on the model, Zhu et al. [
12] proposed a Webshell detection method based on support vector machines (SVMs). This method extracts lexical features, syntactic features, and abstract syntax tree (AST) features, using the SVM algorithm for classification based on the importance of each feature. Although this method reduces the dependency on training data, obfuscated samples can blur features such as the code line count and comments. To address this issue, Pan et al. [
13] proposed training the SVM model using PHP code Opcode instruction [
14] sequences combined with the features from Zhu et al. [
12]. This method captures the execution process of PHP code through Opcode sequences, effectively overcoming the impact of obfuscation on static detection.
Although the above methods have achieved good detection results, an increasing number of Webshell samples use extensive function calls and junk code injection to interfere with model detection. With the emergence of BERT [
15,
16] models, their variants, and new neural network algorithms, related research has gradually progressed to a theoretical level concerning modeling methods. Deng et al. [
17] proposed a Webshell file detection method based on a BERT-LSTM model, leveraging the text comprehension capabilities of the BERT model to extract Opcode sequence features from PHP code and using LSTM for classification, ultimately achieving an accuracy of 98%. However, since the BERT model is pre-trained on natural language data, it is not sufficiently accurate in understanding code. To address this limitation, Cheng et al. [
18] proposed using the CodeBERT model to directly classify code text, thereby eliminating the need to extract PHP code Opcode sequences.
Xie et al. [
19] used the Vulcan Logic Disassembler (VLD) PHP extension to obtain the Opcode sequence of PHP files and converted the Opcodes into fixed 100-dimensional vectors using Word2Vec. They then employed an EDRN neural network for feature extraction and obtained the final classification results through a Sigmoid function. However, this method cannot fully address the limitations associated with feature engineering. Liu et al. [
20] proposed a multilingual Webshell detection method based on bidirectional GRU and attention mechanisms, which is capable of directly extracting the abstract features of Webshells without relying on feature engineering. Gogoi et al. [
21] used an LSTM neural network to analyze common function calls and superglobal variable calls in a PHP Webshell. Jiang et al. [
22] explored a multimodal Webshell detection scheme, analyzing Webshells from multiple dimensions (such as the traffic, logs, page associations, etc.) and generating feature vectors using TinyBERT. However, the preprocessing phase of this method involves overly strict rules, resulting in the loss of key information and adversely affecting feature correlation analysis. Due to the presence of Webshell samples with varying sizes, such as “one-liner backdoors”, “short backdoors”, and “large backdoors” significant differences in code length, feature extraction from text content is influenced. Therefore, transforming the code into images of a specific size and utilizing image features can reduce this issue. Long et al. [
23] proposed a code visualization-based industrial internet malicious code detection method, converting malicious code files into color images and using an improved GoogLeNet model for detection, achieving higher accuracy compared to text-based feature detection.
Although the methods mentioned above have made significant progress in single-feature classification tasks and have contributed to the development of the field, single-modal features cannot handle the diverse nature of Webshell files. Therefore, this paper proposes a detection method based on two modalities: semantic and visual. The semantic modality leverages the advantages of large language models to comprehend the syntactical meaning at the code text level and to extract logical features from the code. This approach is particularly beneficial for identifying malicious samples that have undergone nested calls and obfuscation. The visual modality uses RGB images to extract features, which can capture subtle differences in the code structure and reduce the interference of encryption and obfuscation techniques in file detection. Finally, based on the characteristics of the samples, weight coefficients are used to achieve the optimal fusion of the two modalities, thereby enhancing the overall detection performance.
3. Design of MMF-Detect Method
Existing Webshell evasion techniques can generally be categorized into three types: encoding bypass, function call bypass, and alphanumeric-free bypass. To more effectively counter these evasion-processed Webshells, this paper proposes a Webshell detection method based on multimodal feature fusion (MMF-Detect). The goal of MMF-Detect is to classify samples by combining text features and image features, thereby enabling the timely detection of maliciously injected Webshell files.
Figure 2 illustrates the architecture of this method, which consists of two feature extraction modules and an adaptive fusion mechanism for combining features. For a given sample file, the model first extracts both the text features of the code and the RGB image features of the code. Then, two independent classifiers process the two modalities of data derived from the same sample file. Finally, the adaptive coefficient
Q is calculated based on the number of RGB pigments present in the code, and the decision-level fusion of the multimodal features is executed using the DQS algorithm.
Section 3.1,
Section 3.2 and
Section 3.3 provide detailed descriptions of the text classifier based on the CodeBERT-CL model, the image classifier based on the DropCNN model, and the adaptive fusion mechanism based on the DQS algorithm, respectively.
3.1. Text Classifier Based on CodeBERT-CL Models
In recent years, large models have made significant advancements in natural language processing. CodeBERT, a pre-trained model based on the Transformer architecture, is specifically designed for dual-modal tasks that involve both source code and natural language. Trained on extensive datasets of code and documentation, it supports various tasks, including code searching, code completion, and natural language-to-code generation. Code snippets can be considered specialized text segments with unique characteristics. Therefore, this study developed a text classifier based on CodeBERT to capture the features of Webshell code text. The CodeBERT model was originally designed to perform bidirectional understanding tasks between code and natural language, demonstrating excellent performance in generating code from natural language and describing code in natural language. However, for code classification tasks, it necessitates the integration of additional models to achieve high-performance classification. This dependency significantly increases the complexity of the model structure and the number of parameters. To improve the model’s performance and robustness, we adapted CodeBERT’s masked language modeling task for PHP code, resulting in the CodeBERT-CL model. By employing the masking mechanism, the model effectively classified PHP code and was fine-tuned and tested with PHP–language Webshell data.
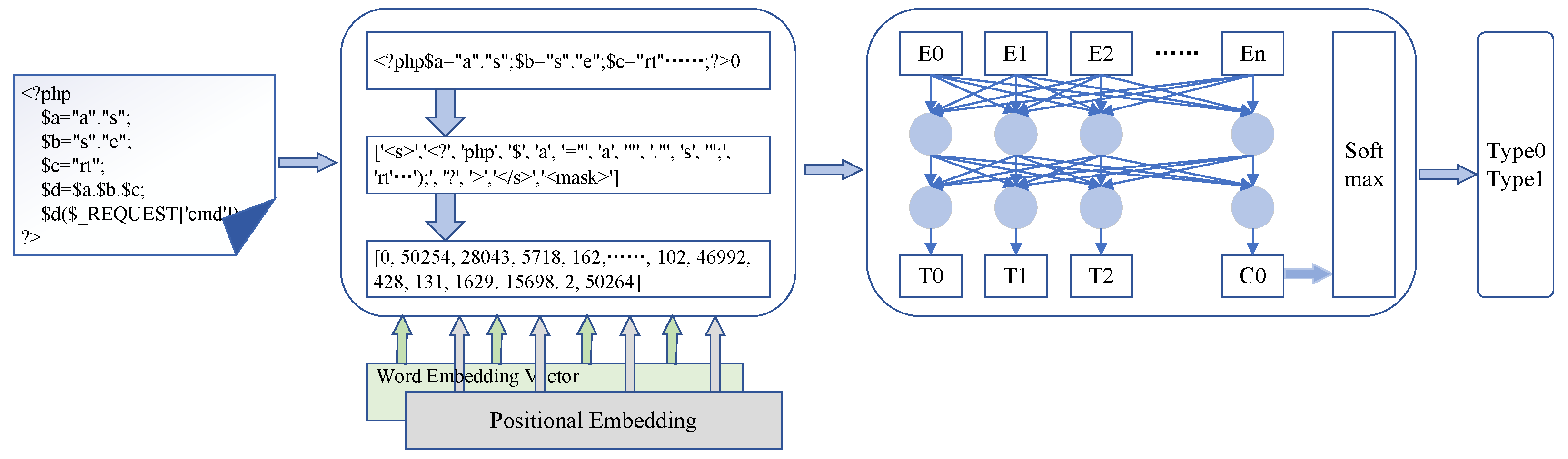
The CodeBERT-CL model consists of three parts, as illustrated in
Figure 3. The first part aims to eliminate line breaks, extraneous symbols, and unnecessary spaces from the code. For example, in this paper, the code depicted on the left side of
Figure 3 is tokenized after removing spaces and line breaks. The code’s symbols, variable names, and values are split. Unlike the traditional BERT tokenization method, this study removed the “[CLS]” tag at the beginning of the original character sequence and appended a mask character sequence, “m1”, following the “</s>” tag at the end. This formed the character sequence
, where the model was trained to predict “m1” after the “” tag. Consequently, the CodeBERT-CL task was transformed into solving the following probability:
. Subsequently, the sequence
was embedded, incorporating both word embedding and position embedding.
(1)
Word Embedding: In order to uniquely map the character sequence to a fixed-dimensional vector representation, the pre-trained embedding matrix assigns an integer to each word, symbol, and tag in the code. For example, in
Figure 3 above, the “<s>” tag and the word “php” are replaced by the integers 0 and 28,043, respectively. After the word embedding process, each code file is transformed into a fixed-dimensional vector representation, which facilitates improved feature extraction.
(2)
Position Embedding: As illustrated in
Figure 4, in order to capture the positional information of tokens within the sequence, a position embedding vector is added for each position in the sequence. The mathematical principles underlying this process are presented in Equations (1)–(5), and the parameters involved are detailed in the accompanying table,
Table 1.
The word “php” in the figure is represented by a 512-dimensional word vector. The position vector PE [
18] is calculated for each word vector using the position encoding equations, as shown in Equations (1) and (2):
According to the properties of trigonometric functions, as shown in Equations (3):
Equations (4) and (5) can be derived as follows:
Therefore, the positional vector of each word is a linear combination of the positional vectors of other words. Through the positional vectors, the relative positions of words in the text can be identified, facilitating a more profound extraction of textual features.
3.2. Image Classifier Based on DropCNN Models
Due to the existence of three types of Webshell evasion methods—XOR, increment, and obfuscation encryption—relying solely on text-based feature extraction is often inadequate for detecting such Webshells. Therefore, this study explored feature extraction from the perspective of the code structure by visualizing the Webshell code, converting it into RGB images, and utilizing neural networks to classify these images.
Figure 5 illustrates the RGB images of evasion Webshells generated by the image generation algorithm proposed in this paper. From the figure, it can be observed that samples processed using the same evasion method exhibit consistency in the layout and tone of the color blocks, while code images generated using different evasion methods display distinct features and variations. For example, in
Figure 5a, the Webshell image processed with the XOR evasion method displays red color blocks arranged in a skewed distribution. In
Figure 5b, the image processed with the increment evasion method displays red and green color blocks in a vertical distribution. Due to the obfuscation method making the code chaotic, the image in
Figure 5c also displays disorganized colors with no obvious concentration of the same color tone. Leveraging the strong visual characteristics of the samples, this study designed an image classifier based on a CNN model. The classifier internally implements the code-to-RGB image conversion algorithm and subsequently extracts features through the convolutional neural network to achieve classification. The classifier primarily comprises the RGB image generation algorithm and the DropCNN model.
3.2.1. RGB Image Generation
Considering that Webshell samples have a relatively small amount of code, RGB images can extract more features than grayscale images. Therefore, this study designed an RGB image generation algorithm to convert the samples into color images, as illustrated in Algorithm 1. RGB images consist of three color channels, each with values ranging from 0 to 255. Unlike other generation algorithms, in order to control the distribution of colors in the image, in this study, PHP code was first converted into a binary string, transforming high-level symbolic information into a low-level numerical representation. Since each pixel in an RGB image is represented by three 8-bit values, the length of the binary string may not meet the grouping requirements. Therefore, zero-padding is applied to the end of the binary string to ensure its length is divisible by nine. The binary string is then divided into groups of 9 bits, with each group further split into three segments, each containing 3 binary bits that correspond to the intensity values of the red (R), green (G), and blue (B) channels of an image pixel. Specifically, the red channel takes the upper 3 bits (the first 3 bits from left to right) and is left-shifted by 5 bits (adding five zeros at the end); the green channel directly extends the middle 3 bits; and the blue channel takes the lower 3 bits and is right-shifted by 5 bits. This mapping strategy not only preserves the distribution characteristics of the original data but also ensures the visibility of the converted results in the RGB channels.
| Algorithm 1 RGB image generation algorithm. |
- 1:
Read the PHP file content into php_code - 2:
Binary string conversion: - 3:
IF the length of binary_string is not a multiple of 9: - 4:
padding_length binary_string - 5:
binary_string= pad with zeros to make the length a multiple of 9 - 6:
FOR i IN range(0,len(binary_string)): - 7:
binary_values = 9-bit binary numbers - 8:
FOR b IN binary_values: - 9:
int_values = convert 9-bit binary numbers to 3-digit decimal numbers - 10:
Data length processing: - 11:
total_pixels - 12:
IF len(int_values) > len(total_pixels): - 13:
step = len(int_values) total_pixels - 14:
int_values = downsample to total_pixels values via average sampling - 15:
ELSE - 16:
int_values = pad with zeros to reach a length of total_pixels - 17:
Convert integers to RGB values: - 18:
rgb_values = NULL - 19:
FOR value IN int_values: - 20:
the high 3 bits of value left-shifted by 5, extended to 8 bits - 21:
the middle 3 bits of value, extended to 8 bits - 22:
the low 3 bits of value, extended to 8 bits - 23:
add INTO rgb_values - 24:
Calculate image dimensions: - 25:
image_size - 26:
image = create a blank RGB image of size image_size × image_size - 27:
FOR i IN (0, len(rgb_values)): - 28:
image_size - 29:
image_size - 30:
Set the pixel at (x, y) in image to rgb_values[i] - 31:
Output the image: rgb_image
|
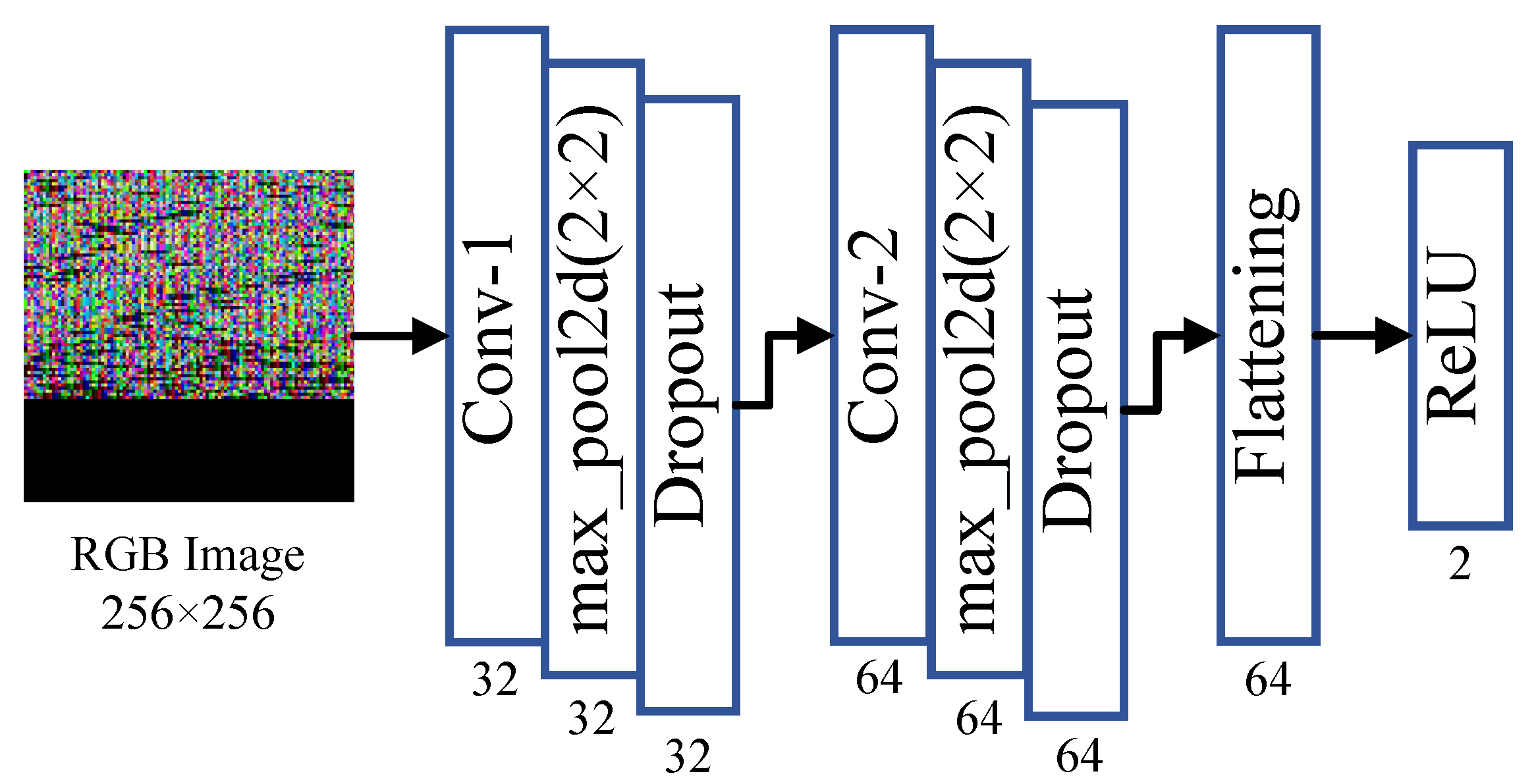
3.2.2. DropCNN Model
The DropCNN model was obtained by optimizing the CNN model specifically for the image features of Webshell code, as illustrated in
Figure 6.
The model consists of two convolutional layers, Conv-1 and Conv-2, two max pooling layers, and one fully connected layer. For the 2D convolutional layers, let
and
denote the height and width of the input feature map,
K be the size of the convolutional kernel,
P be the padding size, and
S be the stride size. The height
and width
of the output feature map can be expressed using Equations (6) and (7).
To maximize the extraction of RGB image features while avoiding overfitting in the neural network, this study added a Dropout layer following each convolutional layer and after the first fully connected layer. During the training phase, this layer randomly selects or drops each neuron based on a preset probability,
p, in each iteration. Let the input vector be
x, the weight matrix be
W, and the bias vector be
b; then, the activation value of the neuron is represented by Equation (
8):
where
r is a vector of the same dimension as the input vector
x, with each element independently set to 1 with a probability of (
). The activation value
h can then be calculated using Equation (
9):
In Equation (
9),
f is the activation function, and ∗ signifies element-wise multiplication. During the testing phase, the weights are scaled, and the output of the neuron is scaled to (
) of its original value, as illustrated in Equation (
10):
The specific operation process of the model is illustrated in
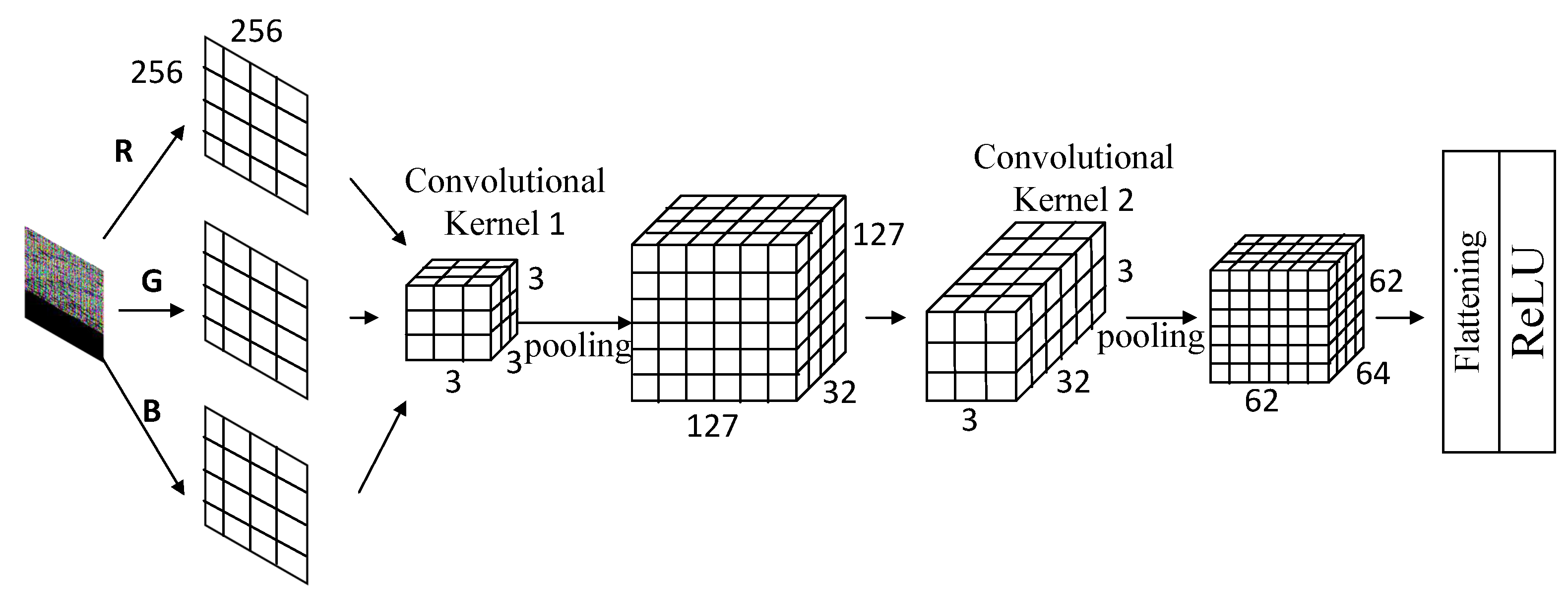
Figure 7. The generated RGB image has dimensions of 256 × 256 pixels. The first convolutional layer uses 32 convolutional kernels, each measuring 3 × 3 × 3, with a stride of 1, outputting a feature map of the dimensions 254 × 254 × 32. The first pooling layer applies 2 × 2 max pooling, which reduces the dimensions to 127 × 127 × 32 before inputting it to the second convolutional layer. The second convolutional layer uses 64 kernels of the dimensions 3 × 3 × 32 to extract high-dimensional features. Following the second 2 × 2 pooling operation, the output feature map measures 62 × 62 × 64. This is followed by a flattening operation before it is input into the fully connected layer, which uses the ReLU activation function to output a probability between 0 and 1, serving as the basis for sample classification.
3.3. Adaptive Fusionizer Based on DQS Algorithm
The feature classification results derived above may face the problem of a poor generalization performance on unknown samples when a single classifier is used for decision-making. This limitation arises because each classifier possesses distinct advantages and constraints when addressing various features. Decision fusion plays an important role in this context. By integrating the representations of different models and combining modal features, more accurate judgments can be made, which can be used to detect unknown Webshell sample files. Research has shown that when Webshell samples undergo encryption and obfuscation techniques, the length of the text correlates with the degree of obfuscation. For long content samples, finer features can often be extracted through images. Therefore, this study constructed an adaptive decision fusion mechanism for the above two modalities. The core DQS algorithm is shown in Algorithm 2. Based on the ratio of the pigment in the RGB image to the total image, the sample data are categorized into short, medium, and long samples with the proportions (0, 1/3], (1/3, 2/3], and (2/3, 1), respectively. An adaptive coefficient,
Q, which is greater than 0 and less than 1, is then defined. When the sample is short,
Q takes the value of 0.15; when the sample is medium,
Q takes the value of 0.65; and when the sample is long,
Q equals 0.90. The decision bias is adjusted using the decision coefficient
Q to maximize the utilization of sample features for decision-making. (The rationale for selecting the adaptive coefficient
Q will be provided in
Section 4).
Using the method proposed in this paper, after inputting a Webshell file, the two modality classifiers will produce two sets of probabilities. For the text modality, the output probability is
, and for the image modality, the output probability is
. The conflict term
K can be calculated from
and
as shown in Equation (
11):
The final sample classification probability, after integrating the decision coefficient
Q into the trust allocation function (BPA) [
24], is calculated as shown in Equations (12) and (13).
The conflict term
K is utilized to measure the degree of inconsistency between the text modality and image modality in classification predictions. It quantifies the level of disagreement between the two modalities. A higher value of
K indicates a more severe conflict and reflects greater inconsistency in the predicted categories. In the subsequent BPA synthesis process, the conflict term
K serves as an adjustment factor for the denominator. When
K is large, the denominator
increases, thereby reducing the weight of unreliable fusion results. This adjustment enhances the robustness of the predictions by minimizing the impact of conflicting or less reliable contributions from the modalities.
| Algorithm 2 DQS algorithm. |
Input: Text classifier output probabilities m1_black, m1_white Image classifier output probabilities m2_black, m2_white Output: Fusion result sample classification probabilities m12_black, m12_white
- 1:
Read the image from image_path and convert it to RGB format - 2:
Calculate total pixels: total_pixels =pixels.shape[0]* pixels.shape[1] - 3:
Get the number of dark pixels (pixels with an RGB channel value of 0): dark_pixels - 4:
Calculate pigment ratio pigment_ratio = dark_pixels/total_pixels - 5:
Determine the adaptive coefficient Q: - 6:
IF pigment_ratio : - 7:
- 8:
ELIF pigment_ratio: - 9:
- 10:
ELSE: - 11:
- 12:
Calculate the conflict term black ∗ Q ∗ m2_white white ∗ Q ∗ m2_black) - 13:
Calculate the fused sample classification probabilities: - 14:
black black black - 15:
white white - 16:
Output the decision probabilities: m12_black, m12_white
|
4. Experiments
4.1. Dataset and Metrics
Dataset: The dataset used in this experiment was based on the Hugging Face open-source dataset c01dsnap/Webshell, with an additional 1400 evasion Webshell sample files added to form the complete dataset. For each Webshell sample, we added the label “black” or “white” after the code. This approach created key–value pairs in a dictionary, and these pairs collectively formed the dataset used for the experiments presented in this paper. The proportion of the data samples is shown in
Table 2.
Metrics: When using deep learning algorithms for binary classification, four outcomes are generated: true positive (TP), false negative (FN), true negative (TN), and false positive (FP). In this study, Webshell files were classified as positive samples, while normal files were categorized as negative samples. The model’s performance was evaluated using four metrics: the accuracy, precision, recall, and F1-score. The accuracy indicates the ratio of correctly predicted samples to all samples, whereas the F1-score is the harmonic mean of the precision and recall. Since the precision and recall cannot be optimized simultaneously, evaluating the model’s performance solely on these two metrics has limitations. Consequently, the accuracy and F1-score are more effective indicators for representing the model’s overall performance. The calculations for these metrics are detailed in Equations (14)–(17).
4.2. Implementation Detail
In the experiment, the following configurations were set for the text classifier using the CodeBERT-CL model: the batch size for both the training and test sets was set to 128, and the learning rate was set to . For the image classifier, an optimized CNN model was used, with adjustments made to the convolution kernel dimensions to extract more features from RGB images. Dropout layers were applied to mitigate overfitting. Furthermore, the multimodal detection model was trained for 26 epochs, with the ratio of the test set to the training set being 1:3. Finally, performance experiments were conducted on the multimodal classification model, comparing it with existing methods on the same dataset to validate the superiority of the MMF-Detect method. Ablation experiments were also performed to validate the effectiveness and rationality of each module within the multimodal classification model. All experiments were conducted on a 64-bit Ubuntu-20.04 system with an Nvidia A100 GPU, CUDA version: 12.0.
4.3. Comparative Experiments and Analysis
In this section, we first evaluate the performance of the proposed model, which is intuitively reflected through the accuracy and the F1-score. Next, we compare the detection of evasive Webshell samples with existing methods. Finally, we conduct comparisons on the conventional Webshell sample dataset against existing methods. All the results demonstrate that the proposed method achieves superior performance.
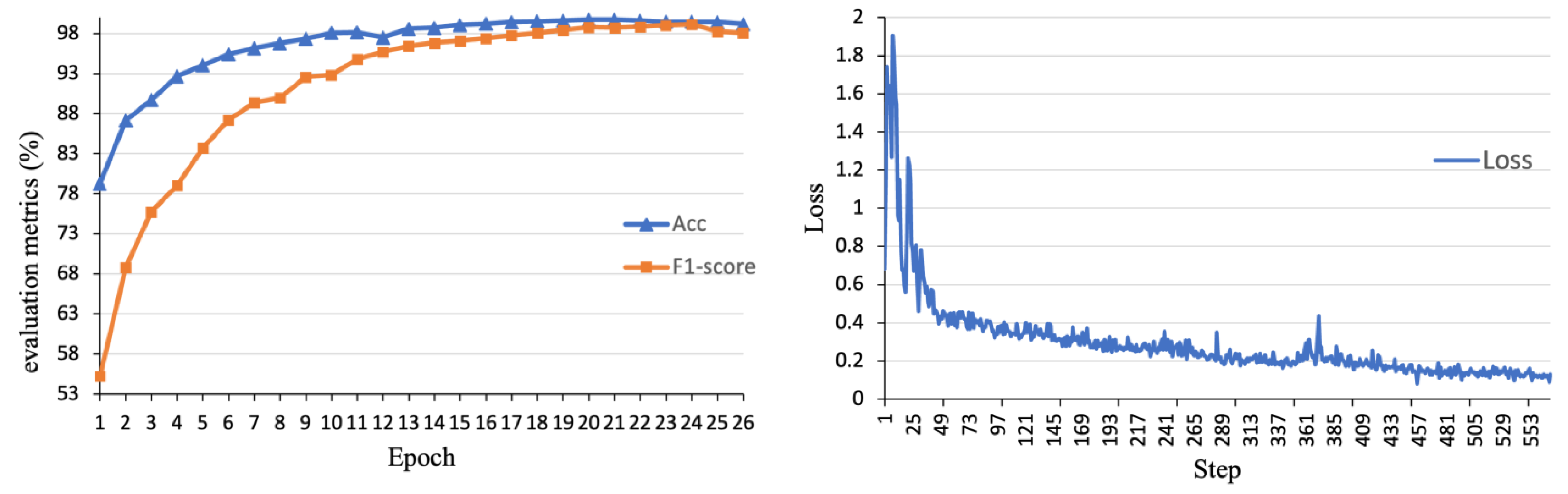
First, the model was trained using the full dataset, with a total of 26 iterations, with the results illustrated in
Figure 8. During the training process, the accuracy gradually improved from an initial value of 78.30% and peaked after the 21st iteration. Following this peak, there was a slight decline; however, considering the variations in other parameters, the training concluded after the 26th iteration, achieving a maximum accuracy of 99.47%. Simultaneously, the loss value steadily decreased and stabilized, confirming that the model’s overall performance was stable while maintaining a high level of accuracy. The F1-score also increased throughout the training process, ultimately reaching 99.13%.
In practical network defense tasks, conventional Webshells are usually detected and blocked by security tools. This paper focuses on the identification and detection of evasion Webshells. The performance of the MMF-Detect model was compared with the models [
13] of Opcode&Static&Exec, Opcode&Static, and Opcode&Exec, Bi-GRU [
14], BERT-LSTM [
17], EDRN [
25], and AST-DF [
26] on the evasion Webshell test set. The experimental results are shown in
Table 1.
By analyzing
Table 3, it can be observed that due to the complex encoding, encryption, and obfuscation techniques employed in the evasion samples, machine learning-based models exhibited inadequate feature extraction capabilities, leading to significantly lower performance compared to deep learning models. In regard to the AST-DF model and deep learning architectures such as Bi-GRU and BERT-LSTM, which either focus on detecting the syntactic structures of code or utilize extensive models for understanding the code syntax, the accuracy in detecting obfuscated and encoded Webshells remained suboptimal due to the absence of standard syntactic features. In contrast, the MMF-Detect model capitalizes on the advantages of large models in comprehending the semantics of evasion sample code while harnessing a deep learning model’s capacity to extract visual features from such samples. Consequently, it achieved improvements of 5.39 percentage points in the accuracy and 4.95 percentage points in the F1-score, thereby demonstrating its superior performance in evasion Webshell detection tasks.
To verify that the model proposed in this paper performs equally well on standard Webshell samples, a comparative experiment was conducted with classic machine learning models and existing models. The experiment used the open-source dataset c01dsnap/Webshell, and the results are shown in
Table 4.
By analyzing
Table 4, it can be observed that deep learning models, due to their superior representation capabilities and complex model fitting abilities. The BERT-LSTM model, based on large language models, showed further enhancements in the detection performance due to its advanced language comprehension. In this study, we improved the accuracy by taking into account the unique characteristics of programming languages and using a code-pre-trained large model.
From the comprehensive analysis of the experimental results presented in
Table 3 and
Table 4, it is evident that the MMF-Detect model demonstrates a significant advantage in detecting obfuscated Webshell samples. Furthermore, it surpasses other models in detecting regular Webshell samples. This superiority can be attributed to the MMF-Detect model’s ability to extract rich features from both the visual and syntactic modalities of the samples, while also adjusting the fusion decision based on the inherent characteristics of the samples themselves. Consequently, this approach effectively reduces the impact of differences in the sample size and variations in obfuscation methods on the model’s performance.
4.4. Ablation Experiment and Analysis
To thoroughly analyze the effectiveness of each module in the proposed multimodal detection method, ablation experiments were conducted on the full dataset, with all parameters controlled and kept consistent across the experiments. The specific experiments were as follows:
(1) CodeBERT-CL: The text classifier was used independently, and the fusion module was removed. The purpose of this experiment was to evaluate the effectiveness of classification based on the text classifier’s comprehension of the code.
(2) DropCNN: The image classifier was used independently to confirm that the optimized CNN model can extract richer features from RGB images.
(3) Based on experiments (1) and (2), the adaptive coefficient was removed, and decision fusion was performed by fixing the classifier weights. The purpose of this experiment was to verify the effectiveness and necessity of adjusting the fusion coefficient based on the characteristics of the samples when using the text method.
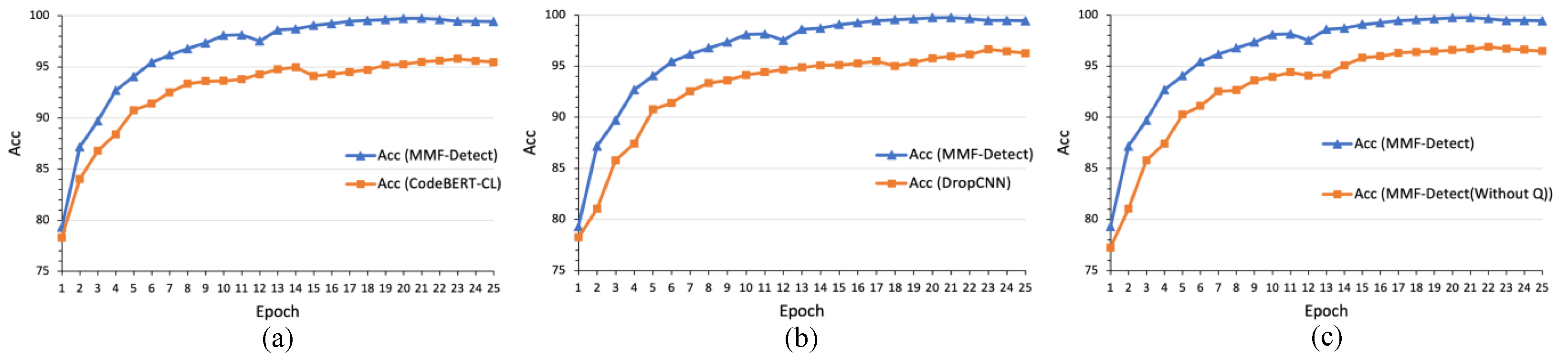
According to
Table 5 and
Figure 9a, when the text classifier CodeBERT-CL was used alone for sample classification, the model’s convergence speed was relatively slow. The model achieved its best performance of 96.13 at the 23rd epoch but experienced a slight decline in accuracy afterward. This peak performance is 3.34 percentage points lower than that of the MMF-Detect multimodal model. This indicates that although CodeBERT-CL achieves good results in a single modality, its accuracy does not reach the upper limit. From
Figure 9b, when using the single image classifier DropCNN for the classification task, the model showed significant convergence fluctuations before the 10th epoch due to sample size differences. The model achieved its best accuracy at the 23rd epoch.
Figure 9c shows that when the adaptive coefficient was removed, the model’s peak accuracy was higher than that of
Figure 9a,b but still lower than that of the full model. This demonstrates that while the fusion of the two modalities effectively improves the model’s accuracy, the absence of an adaptive coefficient prevents the model from achieving its maximum detection accuracy.
To further validate the superior performance of the core models in the text classifier and image classifier, the original models were replaced with the Code Llama [
27] pre-trained code model and a basic convolutional neural network (CNN) model. The experimental results are shown in
Table 6, and the specific experimental setups were as follows:
(1) Code Llama and DropCNN: Replace the CodeBERT-CL model with the Code Llama model and pair it with the DropCNN model. This experiment aimed to demonstrate that the CodeBERT-CL model utilized in this study possesses superior code comprehension capabilities compared to existing pre-trained code models and shows greater applicability to the research presented in this paper.
(2) CodeBERT-CL and CNN: Replace the DropCNN model with a standard CNN model while integrating it with the CodeBERT-CL model. This experiment aimed to demonstrate that the DropCNN model utilized in this study outperforms conventional CNN models in terms of image processing capabilities and aligns more effectively with the research objectives of this paper.
(3) Code Llama and CNN: Combine the Code Llama model with a basic CNN model. This experiment aimed to evaluate the enhanced performance achieved by the integration of these two modalities utilized in this study.
Based on the experimental results shown in
Table 6, it can be concluded that the combination of the Code Llama model and the DropCNN model demonstrated satisfactory performance; however, its accuracy was still lower than that of the combination of the CodeBERT-CL model and the DropCNN model. This discrepancy arose because the Code Llama model was derived from pre-training Llama2 on code data. Upon analysis, it is evident that Llama2 is an autoregressive generative model based on the Transformer decoder, excelling in open-domain dialogue, long-text generation, and multi-turn interaction tasks. In contrast, the base model of CodeBERT-CL, BERT, is a bidirectional encoder model. Its bidirectional attention mechanism facilitates a comprehensive understanding of contextual information within sentences, making it particularly well suited for tasks such as text classification, sentiment analysis, question answering, and named entity recognition. Consequently, the CodeBERT-CL model achieved optimal results in detecting Webshells. Furthermore, the basic convolutional neural network (CNN) model emphasizes local texture patterns in images rather than global structures or logical relationships. This limitation increases the likelihood of false positives and false negatives in the detection of Webshell RGB images. By incorporating pooling layers into the CNN model to extract global features and integrating them with local features, this study significantly improved the classification performance for Webshell images.
In summary, the proposed comprehensive model outperformed its submodules in terms of the convergence speed, learning capacity, and performance ceiling, as demonstrated in
Table 5. The integration of each module significantly enhanced the test accuracy, while the inclusion of the adaptive coefficient further improved the overall model accuracy. This fully validates the effectiveness of each module in the MMF-Detect method. Furthermore, the results presented in
Table 6 confirm that the two-modal models proposed in this study exceed the performance of other models.
4.5. Adaptive Coefficient Experiments and Analysis
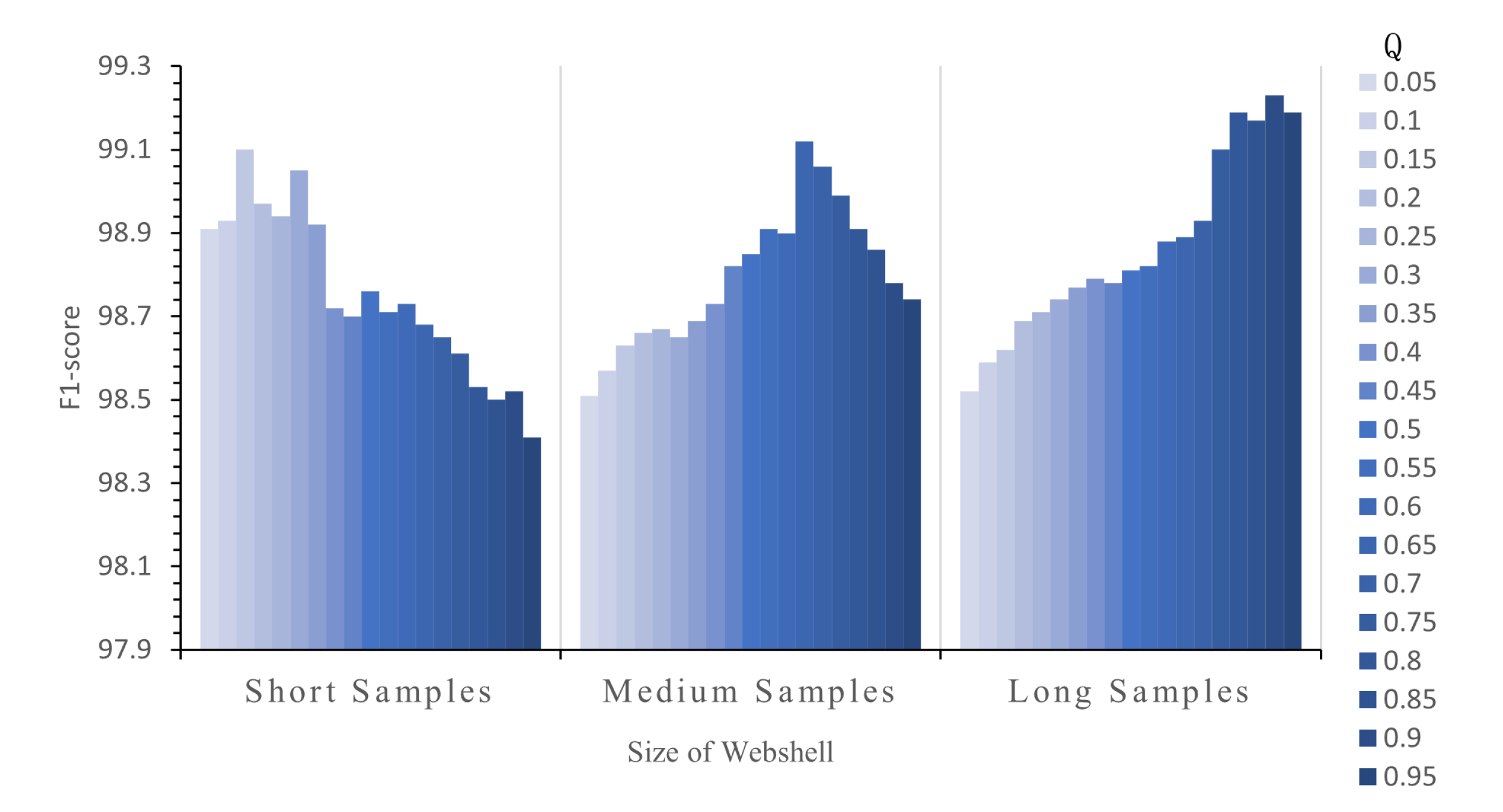
To determine the appropriate value of
Q for adjusting the modal weights of samples of different lengths, we conducted an adaptive coefficient selection experiment. The experimental subjects included three categories of samples: short, medium, and long. The initial value of
Q was set to 0.05 and incremented in steps of 0.05. The results were evaluated using the F1-score metric, as illustrated in
Figure 10.
From
Figure 10, it is evident that the value of the adaptive coefficient
Q significantly influences the model’s performance when analyzing samples of different lengths. For short samples, when
Q ranged from 0.05 to 0.5, the evaluation metric was consistently at least 0.2 points higher than in other ranges, with the highest value of 99.10 achieved at
Q = 0.15. For medium-length samples, the highest evaluation metric of 99.12 was attained at
Q = 0.65. In the case of long samples, an optimal performance of 99.23 was achieved when
Q equaled 0.90. These results illustrate that the sample size significantly affects the detection performance and further confirm that the MMF-Detect method, with the use of the adaptive coefficient
Q, effectively mitigates the influence of the sample size on the detection results.
5. Discussion
5.1. Language Adaptability and Extensibility
The experiments in this study primarily focused on PHP code. Both the construction of the dataset and the design and training of the model were based on PHP Webshell samples. This indicates that the MMF-Detect method was highly tailored to the PHP language from its inception. Different programming languages have unique syntactic structures, semantic rules, and coding conventions. For example, Python relies on indentation to define code blocks, while PHP uses curly braces to delimit them. Consequently, if directly applying the MMF-Detect method to other languages, it may encounter challenges in accurately understanding and processing their specific syntactic structures. However, whether in PHP, Python, or Java, all programming languages possess syntax structures, and their transformation into RGB images reveals distinct features. Thus, the approach proposed in this study is adaptable to other programming languages.
To enhance the applicability of the MMF-Detect method across a wider array of languages, it is essential to construct a large-scale dataset comprising code samples from various programming languages and to perform comprehensive training. Additionally, the Webshell samples in different languages vary in size, which necessitates modifications to the RGB image dimensions based on the specific characteristics of each language to ensure all pixel blocks are accommodated. Consequently, assessing the suitability of the MMF-Detect method for detecting Webshells in other languages requires us to fine-tune the model with samples from the relevant languages, along with making the necessary adjustments and conducting thorough investigations.
5.2. Practical Application
In practical applications, the MMF-Detect model can be integrated into firewalls or intrusion detection software to enhance the detection of Webshells.
A typical use case for the MMF-Detect method involves two scenarios: File Uploading and Local File Editing, where the method conducts security checks on the file content. For the file uploading functionality, when a user uploads a file, the system first extracts the file content and preprocesses both textual and image features. The preprocessed data are then input into the text classifier and image classifier, respectively. Following decision fusion, a binary classification probability is generated, indicating whether the file has been identified as a Webshell, and the detection result is returned accordingly. In the case of editing local files, the content intended for saving can be directly preprocessed and analyzed by the classifiers to determine whether it contains Webshell code. By incorporating the MMF-Detect method into security inspection workflows, a system’s overall security and defense capabilities can be significantly enhanced.
5.3. Further Research
Although the MMF-Detect method has achieved significant success in detecting Webshells, it still has limitations. For instance, the model was fine-tuned exclusively on PHP Webshell samples, which restricts its direct applicability to Webshell detection tasks involving other programming languages. Additionally, this method primarily focuses on identifying the content of Webshell files. Some Webshells may utilize specific network protocols and request methods for covert transmission, making it difficult to detect Webshells embedded in request headers during transmission.
To address the limitations of MMF-Detect regarding detection pathways and the multilingual adaptability, several enhancements can be implemented. First, incorporating training data that encompass various programming languages, along with the integration of adaptive modules, can facilitate the conversion of Webshell content in different languages into appropriately sized RGB images, thereby improving the model’s multilingual applicability. Second, integrating network traffic analysis techniques to extract the transmission-related features of Webshells, such as the traffic size, request frequency, and protocol type, and combining these with file-level features can create a more comprehensive detection framework, ultimately enhancing the detection accuracy. Additionally, examining collaborative attack patterns that merge Webshells with other attack methods and developing corresponding detection models could aid us in identifying complex attack scenarios.
6. Conclusions
To address the challenges posed by existing Webshell anti-detection techniques for traditional static file analysis methods, this paper proposes a multimodal feature fusion-based evasion Webshell detection method (MMF-Detect). This method takes advantage of image recognition in extracting the structural features of evasion samples and a pre-trained model’s ability to comprehend the hidden semantics of these samples. MMF-Detect consists of an image classifier, a text classifier, and an adaptive decision fusion mechanism. The image classifier uses an optimized CNN model to extract multi-dimensional features from the generated RGB images, retaining as much feature information as possible. The text classifier modifies the pre-trained model’s masked language modeling task to obtain the CodeBERT-CL model, using a masking mechanism to classify code. Finally, an adaptive decision fusion algorithm (DQS) was designed, mapping the file size to an adaptive coefficient and fully leveraging the strengths of different modalities for classification decisions.
The experimental results show that the MMF-Detect method achieves high accuracy across samples of different sizes and effectively detects evasion Webshell files, proving the method’s effectiveness. Furthermore, when compared to various existing algorithms, this method significantly enhances the recognition accuracy on anti-detection datasets.
Future work is expected to integrate more programming languages for pre-trained models and combined features to tackle the multi-language code classification challenge.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}