
Ultra-Short-Term Photovoltaic Power Prediction Based on BiLSTM with Wavelet Decomposition and Dual Attention Mechanism


Abstract
1. Introduction
- By using the quartile range method for outlier detection and the multiple interpolation method for missing value completion, data preprocessing is achieved to solve the problem of outliers and missing values in actual on-site data collection.
- We propose for the first time a bidirectional long short-term memory network (W-DA-BiLSTM) enhanced by wavelet decomposition and a dual attention mechanism for photovoltaic power prediction, which can effectively handle nonlinear data and automatically extract relevant features.
- Through testing with actual data, it has been verified that compared with other SOTA methods, it has higher prediction accuracy, confirming its practicality and efficiency in the field of photovoltaic power generation prediction.
2. Data Preprocessing
2.1. Outlier Detection
- Find the middle value of the dataset, which is the second quartile Q2.
- Calculate the median of the upper and lower parts of the dataset separately to obtain the first quartile Q1 and the third quartile Q3.
2.2. Missing Data Completion
3. W-DA-BiLSTM Principle
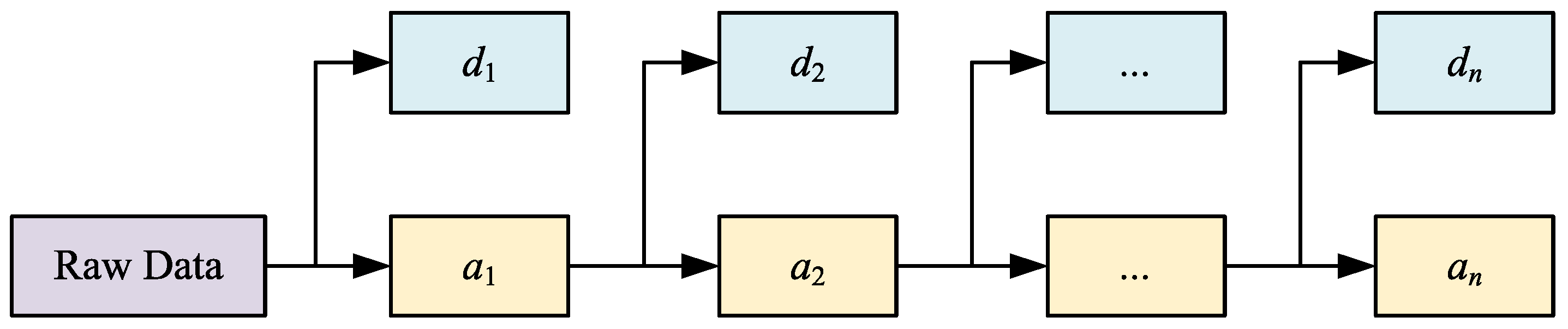
3.1. Wavelet Decomposition
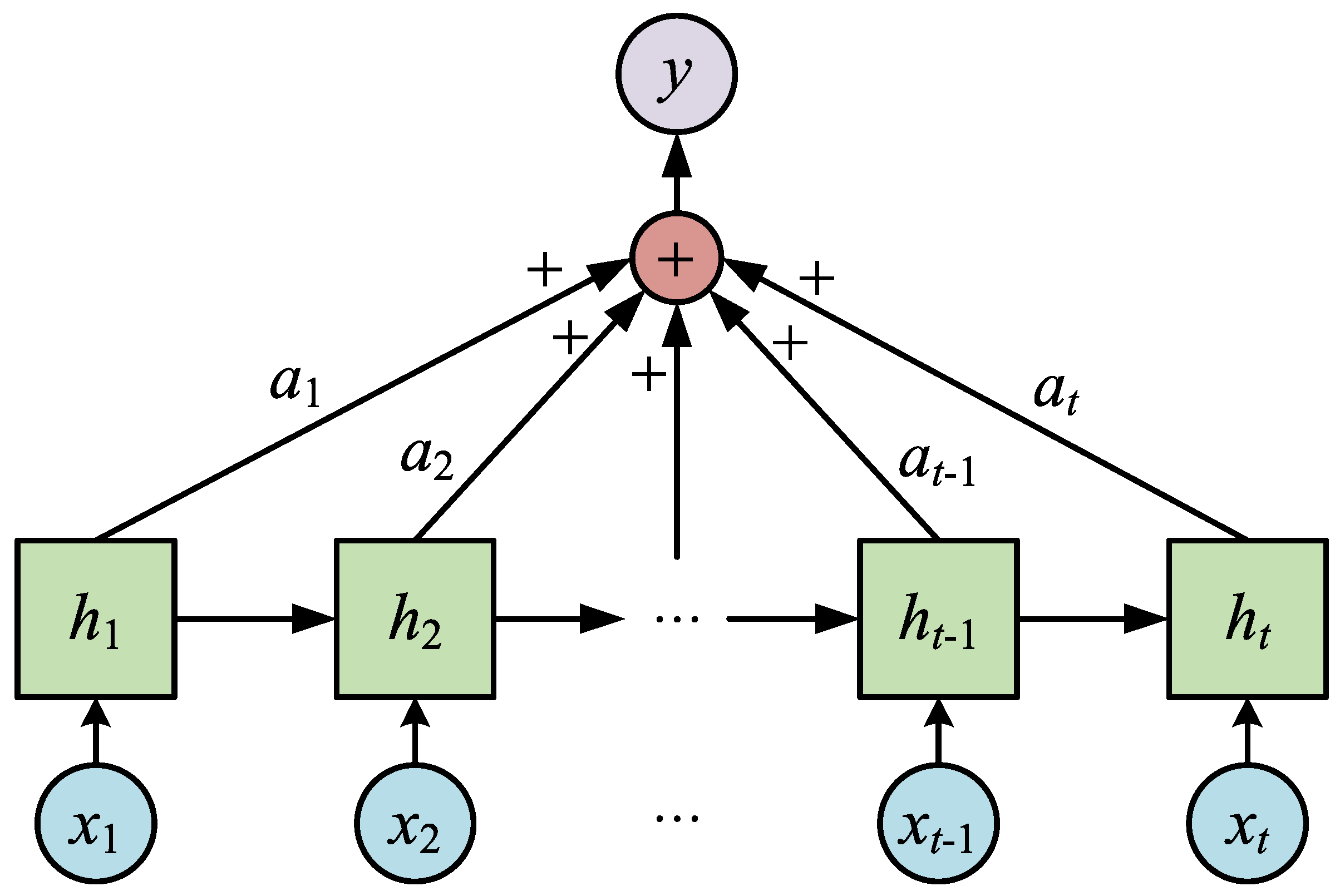
3.2. Dual Attention Mechanism
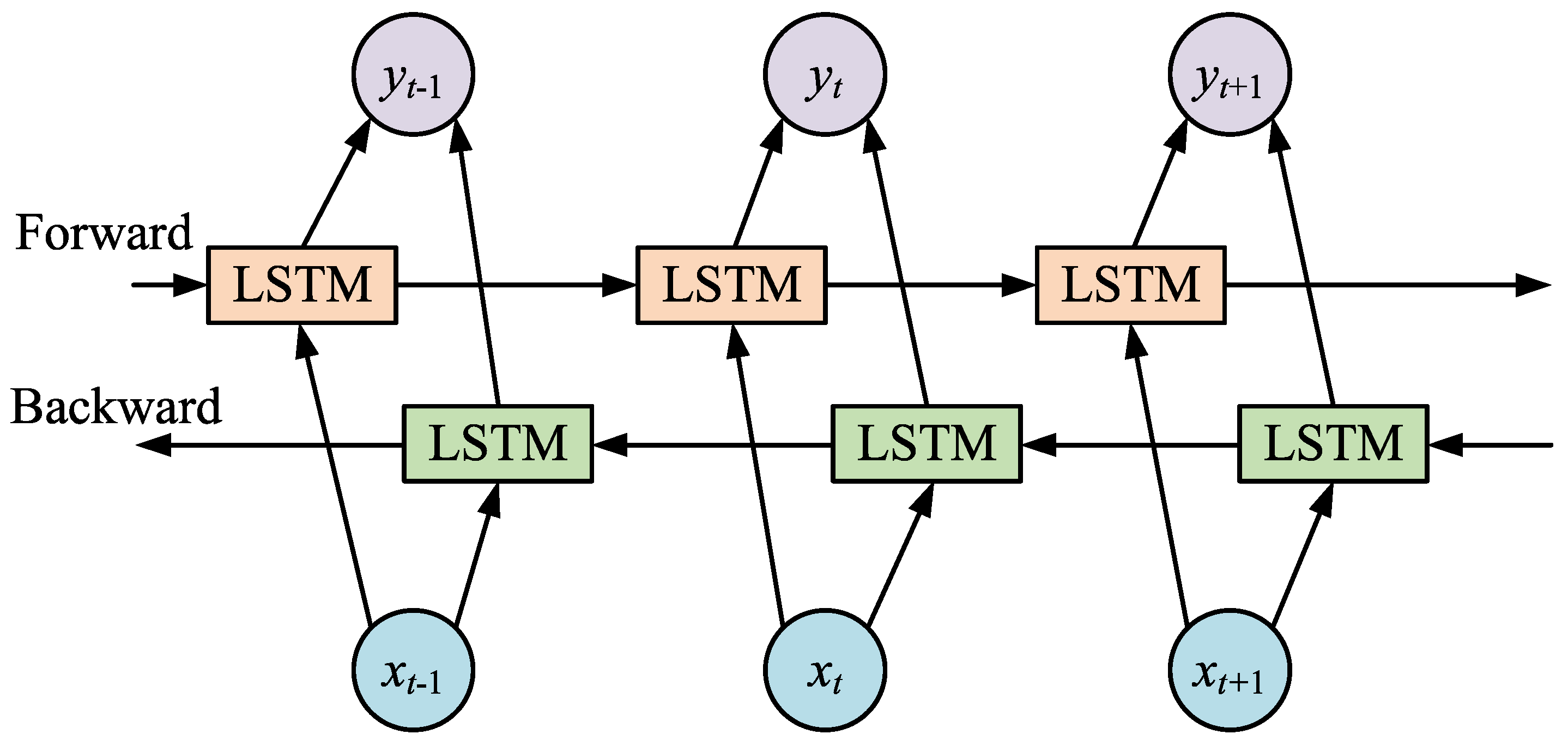
3.3. BiLSTM
4. Model Architecture
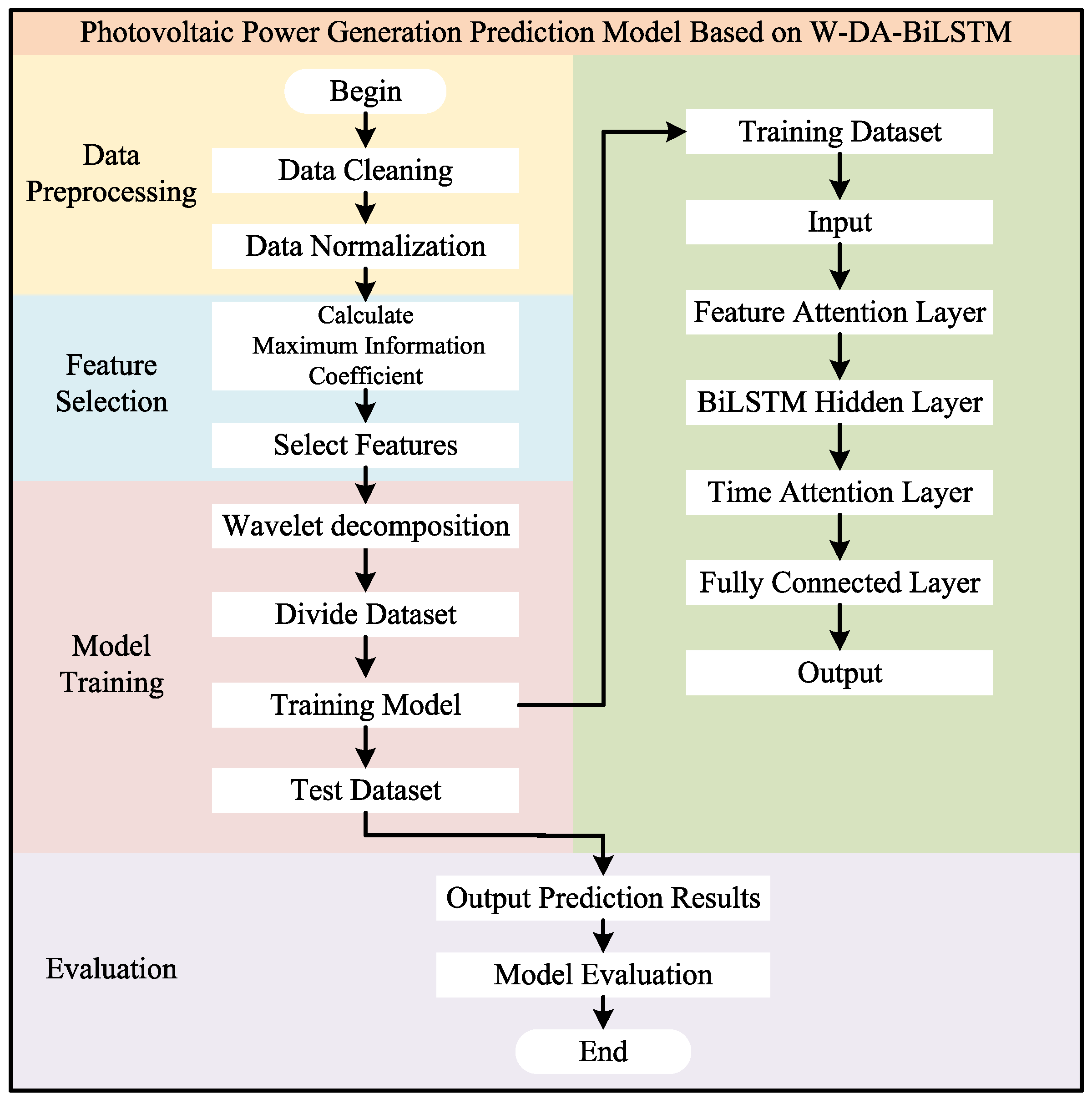
4.1. Algorithm Flow
- Data preprocessing: clean the raw data, including outlier detection and removal and missing value completion, and then normalize the data to eliminate the influence of dimensionality.
- Feature selection: calculate the maximum information coefficient between each input, analyze the correlation between various factors, and then extract factors with a strong correlation with photovoltaic power generation.The definition of the maximum information coefficient is as follows [38]:where X and Y are two input variables; I and p are the mutual information coefficient and joint probability between two variables, respectively; a and b are the number of grids divided in the X and Y directions; and is the data range, usually set to the power of 0.6 of the total dataset.The maximum information coefficient value range is [0, 1]. When its value is 0, it indicates no correlation, and when it is 1, it indicates complete correlation. The stronger the correlation, the closer its value is to 1.
- Model training: perform wavelet decomposition and single-branch reconstruction on the filtered data, filter out noise, and then extract trend information.
- Model evaluation: use the trained prediction model to predict the test set, output the prediction results, and then evaluate the model using evaluation metrics.
4.2. Network Structure
- Input layer: uses the partitioned training set data as input for the model.
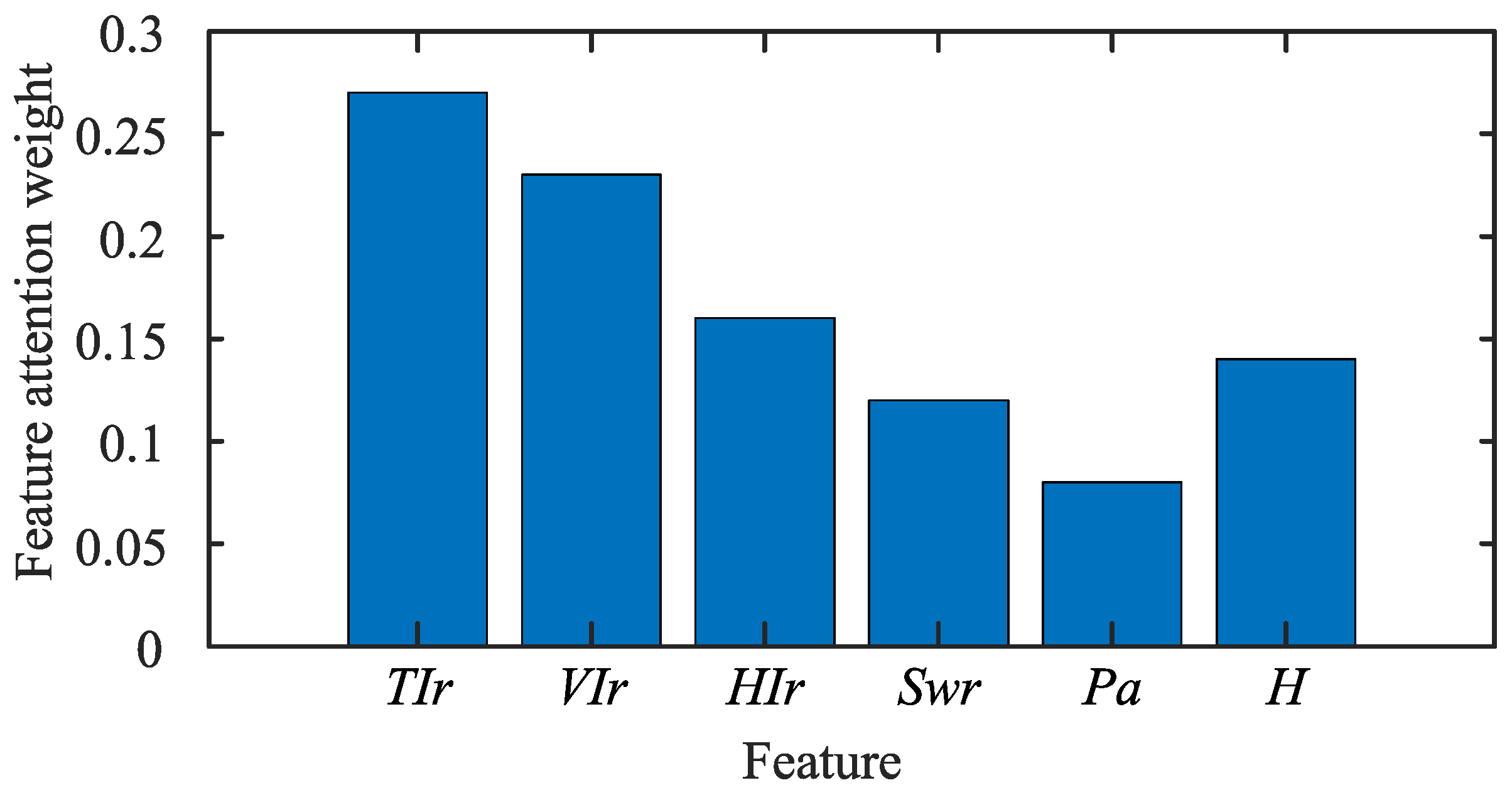
- Feature attention layer: learning the weight distribution of input data, the model can automatically identify the impact relationship between environmental features and photovoltaic power generation and enhance the influence of important features on prediction.
- BiLSTM hidden layer: processes forward and backward sequences to obtain the dependency relationship between them in the time series and combines the corresponding cell states in the forward and backward directions to obtain the output value at each time step.
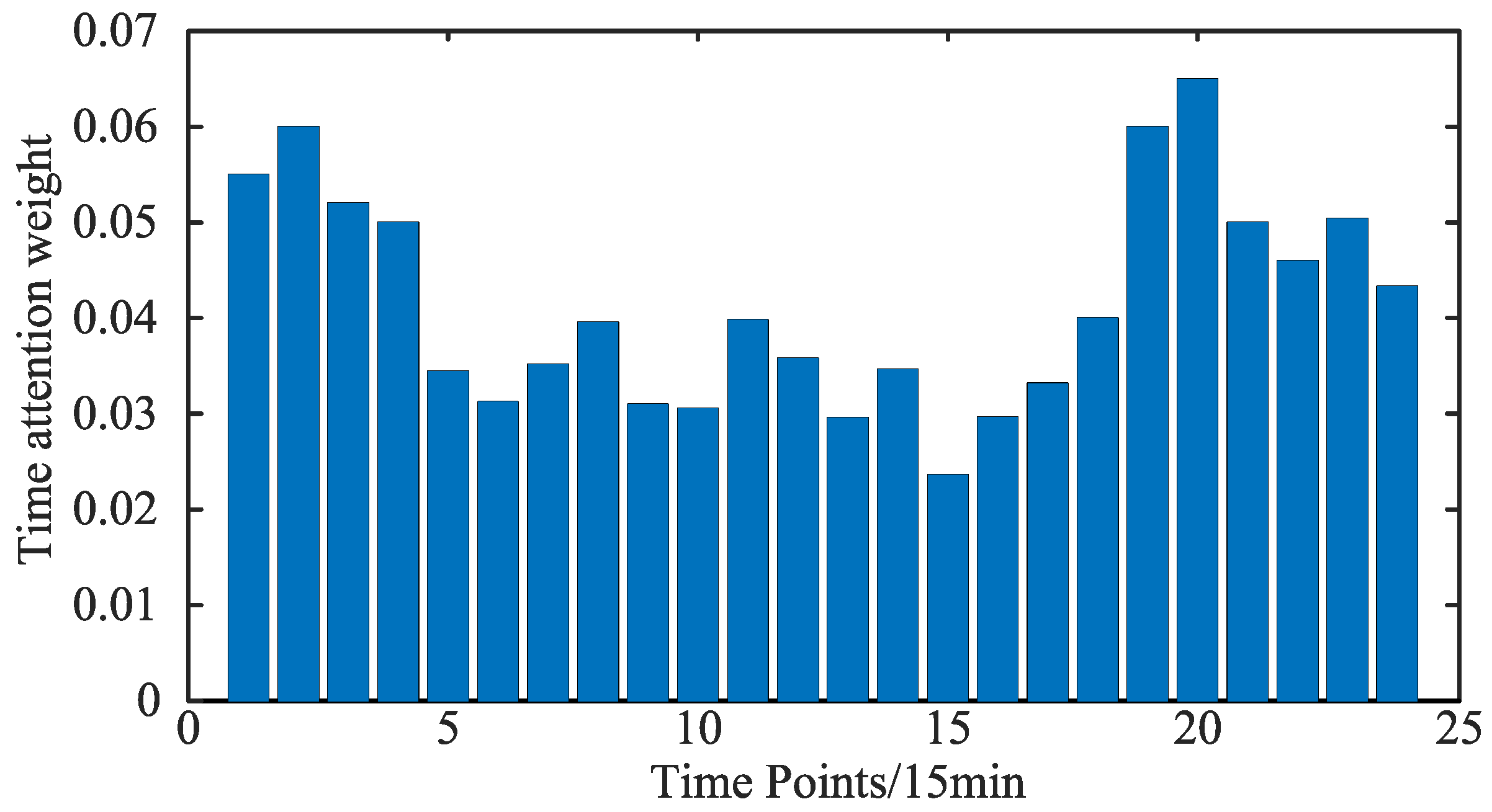
- Time attention layer: weights the sequence output of the model, highlighting the time points that have the most impact on the prediction results, and improves prediction accuracy through the temporal correlation between data.
- Fully connected layer and output layer: by reducing the dimensionality of the results through the fully connected layer and using the ReLU activation function to perform nonlinear mapping on the output data, the training speed can be improved and the final prediction results can be output.
5. Experiment
5.1. Experimental Data
5.2. Parameter Settings
5.3. Evaluation Index
5.4. Result
6. Analysis
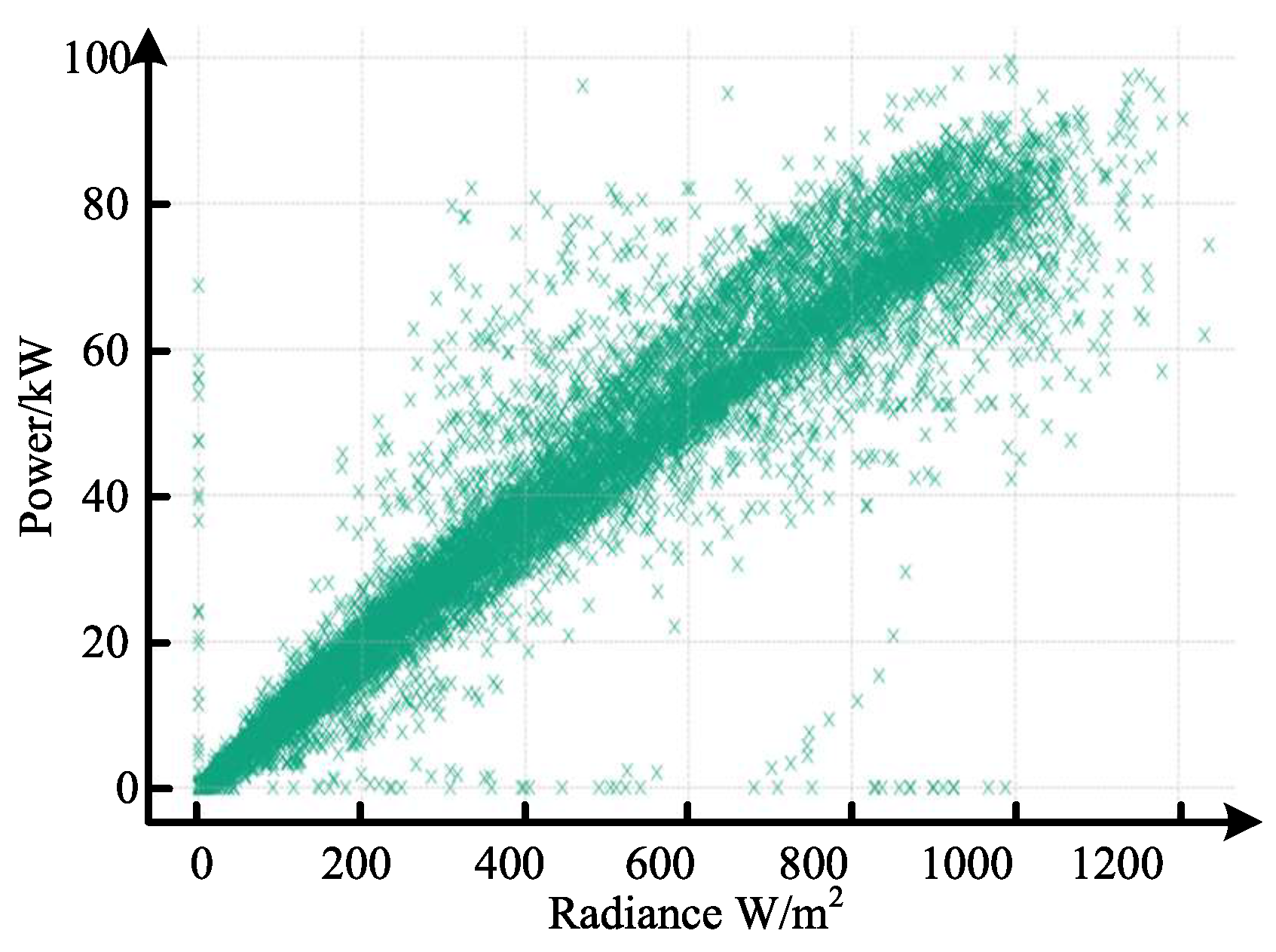
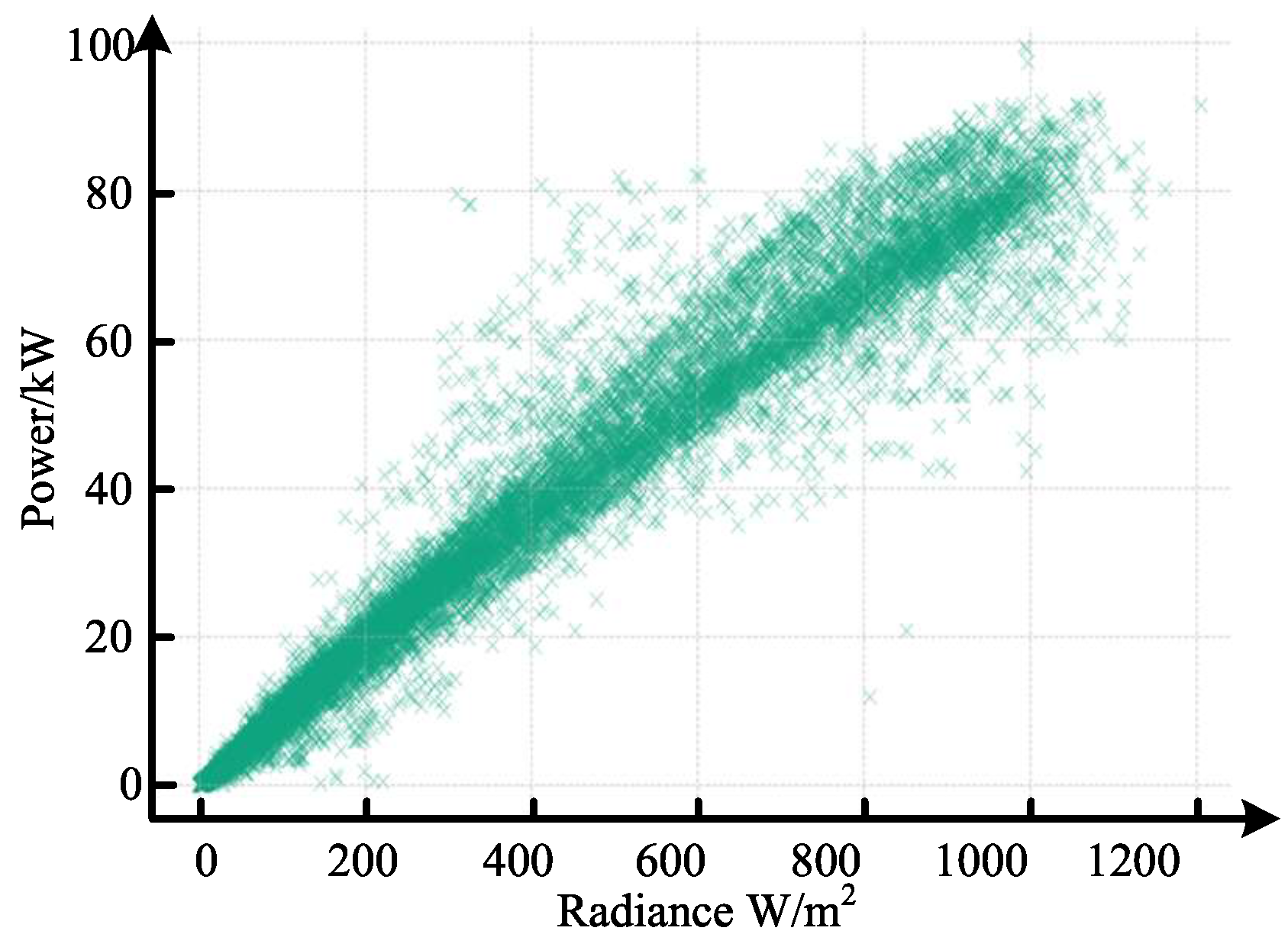
6.1. Analysis of Processing Results for Outliers and Missing Values
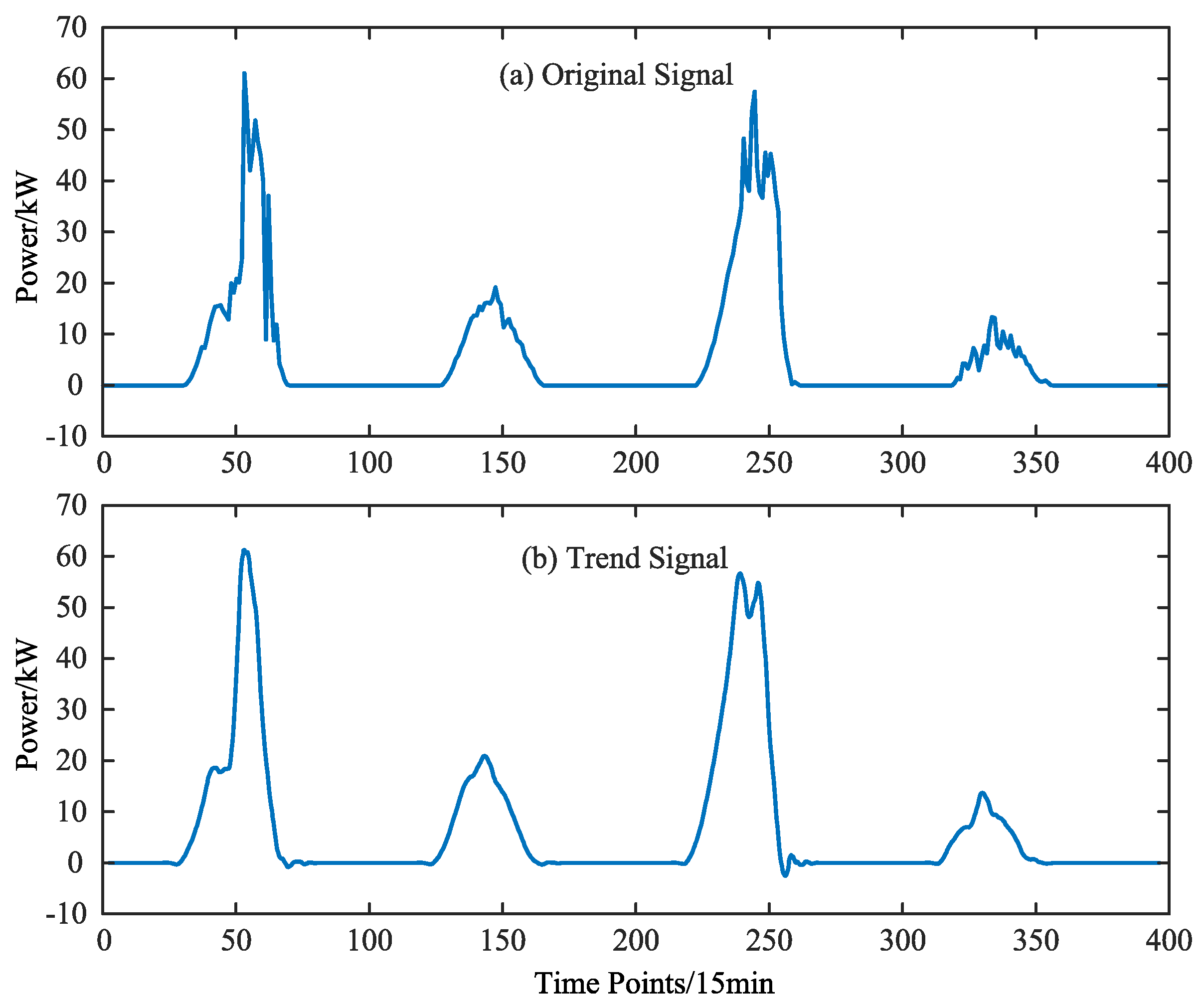
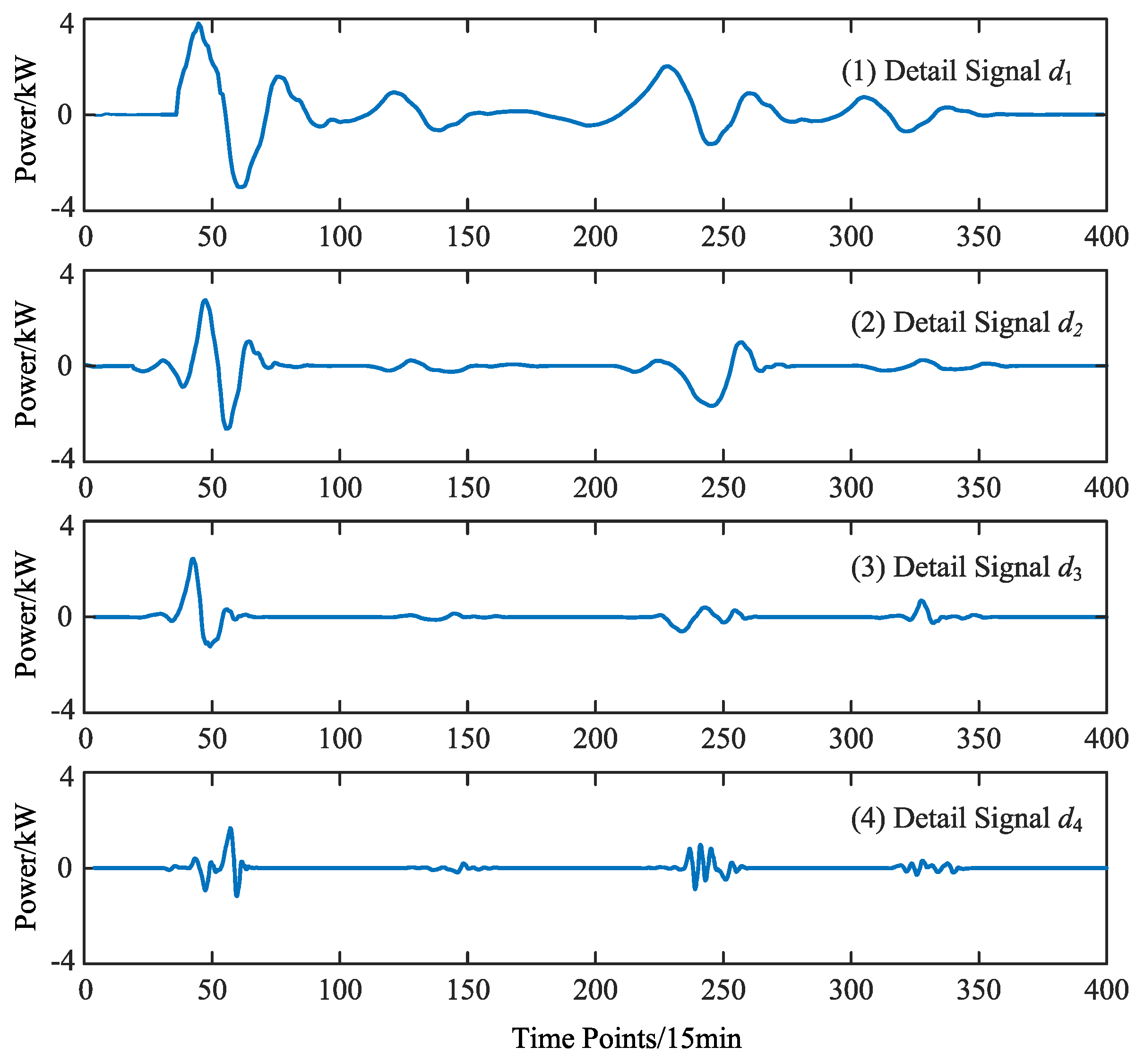
6.2. Analysis of Wavelet Decomposition Results
6.3. Analysis of the Results of Dual Attention Mechanism
7. Conclusions
- To improve the accuracy of photovoltaic power generation forecasting, this paper proposes a combined prediction model based on wavelet decomposition, dual attention mechanisms, and bidirectional long short-term memory networks (W-DA-BiLSTM). Simulation results using real-world data validate the model’s accuracy and effectiveness. The use of the quartile range method for outlier detection and the multiple interpolation method for missing value completion in data preprocessing improved the integrity and reliability of the dataset.
- Accurate ultra-short-term photovoltaic power forecasting is crucial for optimizing the scheduling strategies of photovoltaic-storage micro-grid systems. It ensures adequate power supply during peak demand periods while enabling low-cost energy storage during off-peak periods. This not only ensures the stable operation of the micro-grid but also maximizes economic benefits.
- The proposed prediction model achieves favorable forecasting results under various weather conditions. However, its accuracy under complex and extreme weather scenarios still has room for improvement. Further exploration of the factors affecting prediction accuracy under volatile weather conditions and potential enhancement strategies would be beneficial.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, Y.; Chen, L.; Han, X. The key problem analysis on the alternative new energy under the energy transition. In Proceedings of the CSEE, Sanya, China, 25–27 February 2022; Volume 42, pp. 515–524. [Google Scholar]
- Saeed, S.; Siraj, T. Global Renewable Energy Infrastructure: Pathways to Carbon Neutrality and Sustainability. Sol. Energy Sustain. Dev. J. 2024, 13, 183–203. [Google Scholar] [CrossRef]
- Jaxa-Rozen, M.; Trutnevyte, E. Sources of uncertainty in long-term global scenarios of solar photovoltaic technology. Nat. Clim. Chang. 2021, 11, 266–273. [Google Scholar] [CrossRef]
- Zhang, B.; Gao, Y. Data-driven voltage/var optimization control for active distribution network considering PV inverter reliability. Electr. Power Syst. Res. 2023, 224, 109800. [Google Scholar] [CrossRef]
- Ibrahim, I.A.; Hossain, M.; Duck, B.C. An optimized offline random forests-based model for ultra-short-term prediction of PV characteristics. IEEE Trans. Ind. Inform. 2019, 16, 202–214. [Google Scholar] [CrossRef]
- Wang, J.; Zhou, Y.; Li, Z. Hour-ahead photovoltaic generation forecasting method based on machine learning and multi objective optimization algorithm. Appl. Energy 2022, 312, 118725. [Google Scholar] [CrossRef]
- Markovics, D.; Mayer, M.J. Comparison of machine learning methods for photovoltaic power forecasting based on numerical weather prediction. Renew. Sustain. Energy Rev. 2022, 161, 112364. [Google Scholar] [CrossRef]
- Mayer, M.J.; Gróf, G. Extensive comparison of physical models for photovoltaic power forecasting. Appl. Energy 2021, 283, 116239. [Google Scholar] [CrossRef]
- Lorenz, E.; Scheidsteger, T.; Hurka, J.; Heinemann, D.; Kurz, C. Regional PV power prediction for improved grid integration. Prog. Photovolt. Res. Appl. 2011, 19, 757–771. [Google Scholar] [CrossRef]
- Perez, R.; Kivalov, S.; Schlemmer, J.; Hemker, K., Jr.; Renné, D.; Hoff, T.E. Validation of short and medium term operational solar radiation forecasts in the US. Sol. Energy 2010, 84, 2161–2172. [Google Scholar] [CrossRef]
- Sheng, H.; Xiao, J.; Cheng, Y.; Ni, Q.; Wang, S. Short-term solar power forecasting based on weighted Gaussian process regression. IEEE Trans. Ind. Electron. 2017, 65, 300–308. [Google Scholar] [CrossRef]
- Lamsal, D.; Sreeram, V.; Mishra, Y.; Kumar, D. Kalman filter approach for dispatching and attenuating the power fluctuation of wind and photovoltaic power generating systems. IET Gener. Transm. Distrib. 2018, 12, 1501–1508. [Google Scholar] [CrossRef]
- Miao, S.; Ning, G.; Gu, Y.; Yan, J.; Ma, B. Markov Chain model for solar farm generation and its application to generation performance evaluation. J. Clean. Prod. 2018, 186, 905–917. [Google Scholar] [CrossRef]
- Dong, J.; Olama, M.M.; Kuruganti, T.; Melin, A.M.; Djouadi, S.M.; Zhang, Y.; Xue, Y. Novel stochastic methods to predict short-term solar radiation and photovoltaic power. Renew. Energy 2020, 145, 333–346. [Google Scholar] [CrossRef]
- Hocaoglu, F.O.; Serttas, F. A novel hybrid (Mycielski-Markov) model for hourly solar radiation forecasting. Renew. Energy 2017, 108, 635–643. [Google Scholar] [CrossRef]
- Sun, X.; Qiu, J.; Tao, Y.; Ma, Y.; Zhao, J. A multi-mode data-driven volt/var control strategy with conservation voltage reduction in active distribution networks. IEEE Trans. Sustain. Energy 2022, 13, 1073–1085. [Google Scholar] [CrossRef]
- Ahmed, A.; Khalid, M. A review on the selected applications of forecasting models in renewable power systems. Renew. Sustain. Energy Rev. 2019, 100, 9–21. [Google Scholar] [CrossRef]
- Ghimire, S.; Deo, R.C.; Downs, N.J.; Raj, N. Global solar radiation prediction by ANN integrated with European Centre for medium range weather forecast fields in solar rich cities of Queensland Australia. J. Clean. Prod. 2019, 216, 288–310. [Google Scholar] [CrossRef]
- VanDeventer, W.; Jamei, E.; Thirunavukkarasu, G.S.; Seyedmahmoudian, M.; Soon, T.K.; Horan, B.; Mekhilef, S.; Stojcevski, A. Short-term PV power forecasting using hybrid GASVM technique. Renew. Energy 2019, 140, 367–379. [Google Scholar] [CrossRef]
- Behera, M.K.; Majumder, I.; Nayak, N. Solar photovoltaic power forecasting using optimized modified extreme learning machine technique. Eng. Sci. Technol. Int. J. 2018, 21, 428–438. [Google Scholar] [CrossRef]
- Pan, C.; Tan, J. Day-ahead hourly forecasting of solar generation based on cluster analysis and ensemble model. IEEE Access 2019, 7, 112921–112930. [Google Scholar] [CrossRef]
- Wang, K.; Qi, X.; Liu, H. Photovoltaic power forecasting based LSTM-Convolutional Network. Energy 2019, 189, 116225. [Google Scholar] [CrossRef]
- Zhen, H.; Niu, D.; Wang, K.; Shi, Y.; Ji, Z.; Xu, X. Photovoltaic power forecasting based on GA improved Bi-LSTM in microgrid without meteorological information. Energy 2021, 231, 120908. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; Hawash, H.; Chakrabortty, R.K.; Ryan, M. PV-Net: An innovative deep learning approach for efficient forecasting of short-term photovoltaic energy production. J. Clean. Prod. 2021, 303, 127037. [Google Scholar] [CrossRef]
- Shi, P.M.; Guo, X.Y.; Du, Q.C.; Xu, X.F.; He, C.B.; Li, R.X. Photovoltaic Power Prediction Based on TCN-BiLSTM-Attention-ESN. Acta Energiae Solaris Sin. 2024, 45, 304–316. [Google Scholar]
- Huang, L.; Gan, H.Y.; Liu, X.J.; Kou, Z.; Li, J.; Wang, Y.H.; Gu, B. Ultra-short-term Photovoltaic Power Generation Prediction Based on Transformer Encoder. Smart Power 2024, 52, 16–23. [Google Scholar]
- Huang, Z.; Bi, G.-H.; Xie, X.; Zhao, X.; Chen, C.P.; Zhang, Z.R.; Luo, Z. Ultra-short-term PV power prediction based on MBI-PBI-Res Net. Power Syst. Prot. Control 2024, 52, 165–176. [Google Scholar]
- Swami, R.; Dave, M.; Ranga, V. IQR-based approach for DDoS detection and mitigation in SDN. Def. Technol. 2023, 25, 76–87. [Google Scholar] [CrossRef]
- Frery, A.C. Interquartile Range. In Encyclopedia of Mathematical Geosciences; Springer: Berlin/Heidelberg, Germany, 2023; pp. 664–666. [Google Scholar]
- Singh, K.; Upadhyaya, S. Outlier detection: Applications and techniques. Int. J. Comput. Sci. Issues (IJCSI) 2012, 9, 307. [Google Scholar]
- Royston, P. Multiple imputation of missing values. Stata J. 2004, 4, 227–241. [Google Scholar] [CrossRef]
- Zhao, P.; Tan, W.; Cao, S.; Liu, Y. Short term PV power generation prediction based on wavelet transform and LSTM. In Proceedings of the Eighth International Conference on Energy System, Electricity, and Power (ESEP 2023), Wuhan, China, 24–26 November 2023; SPIE: Bellingham, WA, USA, 2024; Volume 13159, pp. 191–197. [Google Scholar]
- Pathak, R.S. The Wavelet Transform; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2009; Volume 4. [Google Scholar]
- Zhang, D. Wavelet transform. In Fundamentals of Image Data Mining: Analysis, Features, Classification and Retrieval; Springer: Cham, Switzerland, 2019; pp. 35–44. [Google Scholar] [CrossRef]
- Nason, G.P.; Silverman, B.W. The discrete wavelet transform in S. J. Comput. Graph. Stat. 1994, 3, 163–191. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Siami-Namini, S.; Tavakoli, N.; Namin, A.S. The performance of LSTM and BiLSTM in forecasting time series. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; IEEE: Washington, DC, USA, 2019; pp. 3285–3292. [Google Scholar]
- Kinney, J.B.; Atwal, G.S. Equitability, mutual information, and the maximal information coefficient. Proc. Natl. Acad. Sci. USA 2014, 111, 3354–3359. [Google Scholar] [CrossRef] [PubMed]
- Gao, Z. Stock Price Prediction Based on Joint LSTM and Fully Connected Layer. In Proceedings of the Recent Advancements in Computational Finance and Business Analytics: Proceedings of the 2nd International Conference on Computational Finance and Business Analytics-ICCFBA-2024, Bhubaneswar, India, 5–6 April 2024; Springer Nature: Berlin/Heidelberg, Germany, 2024; Volume 42, p. 109. [Google Scholar]
- Chai, T.; Draxler, R.R. Root mean square error (RMSE) or mean absolute error (MAE). Geosci. Model Dev. Discuss. 2014, 7, 1525–1534. [Google Scholar]
- Nespoli, A.; Ogliari, E.; Leva, S.; Massi Pavan, A.; Mellit, A.; Lughi, V.; Dolara, A. Day-ahead photovoltaic forecasting: A comparison of the most effective techniques. Energies 2019, 12, 1621. [Google Scholar] [CrossRef]
- Ağbulut, Ü.; Gürel, A.E.; Biçen, Y. Prediction of daily global solar radiation using different machine learning algorithms: Evaluation and comparison. Renew. Sustain. Energy Rev. 2021, 135, 110114. [Google Scholar] [CrossRef]
- Chicco, D.; Warrens, M.J.; Jurman, G. The coefficient of determination R-squared is more informative than SMAPE, MAE, MAPE, MSE and RMSE in regression analysis evaluation. Peerj Comput. Sci. 2021, 7, e623. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attribute | Value |
|---|---|
| Sampling interval | 15 min |
| Time | From 0:00 on 1 January 2020 to 23:45 on 31 December 2020 |
| Input factors | , , , , T, , H, |
| Dataset | Training Dataset | Test Dataset | Time |
|---|---|---|---|
| A | 3532 | 884 | 1 January to 15 February |
| B | 3532 | 884 | 1 April to 15 May |
| C | 3532 | 884 | 1 July to 15 August |
| D | 3532 | 884 | 1 Octobert to 15 November |
| Parameters | Name | Value |
|---|---|---|
| Wavelet decomposition parameters | db | 4 |
| level | 4 | |
| Network parameters | Time step | 24 |
| Hidden layer | 32 | |
| Number of iterations | 100 | |
| Learning rate | 0.01 | |
| Optimizer | Adam |
| Method | Evaluation | A | B | C | D |
|---|---|---|---|---|---|
| W-DA-Bi-LSTM | NMAE | 0.0078 | 0.0065 | 0.0215 | 0.0119 |
| NRMSE | 0.0199 | 0.0189 | 0.0387 | 0.0263 | |
| N | 0.9910 | 0.9932 | 0.9783 | 0.9889 | |
| LSTM-Attention | NMAE | 0.0203 | 0.0158 | 0.0359 | 0.0246 |
| NRMSE | 0.0369 | 0.0288 | 0.0583 | 0.0410 | |
| N | 0.9802 | 0.9842 | 0.9549 | 0.9754 | |
| LSTM | NMAE | 0.0404 | 0.0363 | 0.0467 | 0.0437 |
| NRMSE | 0.0723 | 0.0589 | 0.0895 | 0.0819 | |
| N | 0.9510 | 0.9547 | 0.9379 | 0.9470 | |
| GRU | NMAE | 0.0393 | 0.0371 | 0.0532 | 0.0451 |
| NRMSE | 0.0692 | 0.0635 | 0.1021 | 0.0872 | |
| N | 0.9515 | 0.9530 | 0.9289 | 0.9411 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, M.; Wang, X.; Zhong, Z. Ultra-Short-Term Photovoltaic Power Prediction Based on BiLSTM with Wavelet Decomposition and Dual Attention Mechanism. Electronics 2025, 14, 306. https://doi.org/10.3390/electronics14020306
Liu M, Wang X, Zhong Z. Ultra-Short-Term Photovoltaic Power Prediction Based on BiLSTM with Wavelet Decomposition and Dual Attention Mechanism. Electronics. 2025; 14(2):306. https://doi.org/10.3390/electronics14020306
Chicago/Turabian StyleLiu, Mingyang, Xiaohuan Wang, and Zhiwen Zhong. 2025. "Ultra-Short-Term Photovoltaic Power Prediction Based on BiLSTM with Wavelet Decomposition and Dual Attention Mechanism" Electronics 14, no. 2: 306. https://doi.org/10.3390/electronics14020306
APA StyleLiu, M., Wang, X., & Zhong, Z. (2025). Ultra-Short-Term Photovoltaic Power Prediction Based on BiLSTM with Wavelet Decomposition and Dual Attention Mechanism. Electronics, 14(2), 306. https://doi.org/10.3390/electronics14020306