
Detection of Sealing Surface of Electric Vehicle Electronic Water Pump Housings Based on Lightweight YOLOv8n


Abstract
1. Introduction
2. Comparison and Application of Deep Learning Algorithms
2.1. Comparison of Deep Learning Algorithms
2.2. The Application of Deep Learning
3. Research on Defect Detection Methods
3.1. Dataset Construction and Analysis
3.2. Design of Defect Detection Model Based on YOLOv8n
3.2.1. Design of the Backbone Network
3.2.2. Design of CMPDual Module
3.2.3. Loss Function
4. Experimental Results and Analysis
4.1. Experimental Environment and Configuration
4.2. Evaluation Metrics
4.3. Ablation Study
4.4. Comparison Experiment of Different Loss Functions
4.5. Comparison Experiment of Different Models
4.6. Analysis of Defect Detection Results
5. Conclusions
- To address the shortcomings of deep learning models, such as large size and low detection accuracy, this study introduces the lightweight MobileNetV3 module and redesigns the backbone network structure, effectively reducing the model’s parameters and computational cost. In feature fusion, the inverted residual structure is used to better retain low-level feature information, enhancing the model’s feature extraction capability. Additionally, the network model adopts convolution kernels of different sizes, using 3 × 3 kernels to effectively extract detailed features and 5 × 5 kernels to capture broader contextual information. This allows the network to extract multi-level information at multiple scales, enabling improved defect category recognition accuracy and detection precision even with a lightweight design.
- To reduce redundant parameters and further optimize the model, this study introduces the DualConv convolution and redesigns the lightweight CMPDual module to replace the C2f module in the neck network. By using this module, the model’s parameter size and computational cost are reduced by 0.2 MB and 0.2 GB, respectively, effectively eliminating redundant parameters and achieving a lightweight model design.
- To address the challenges of large size variations and shape irregularities in defects on the sealing surfaces of electronic pump housings, this study adopts the Inner-WIoU loss function to replace the traditional CIoU loss function. Compared to CIoU, the WIoU loss function places greater emphasis on the relative position and size matching between the predicted and ground truth boxes. Additionally, a scale factor is introduced in the WIoU loss function to adjust loss calculations based on the size of different targets, enabling faster network convergence and improving the localization accuracy of the predicted boxes.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, Y.H.; He, L.J. Analysis on thermal management technology of new energy Vehicle power battery. Auto Time 2023, 19, 76–78. [Google Scholar] [CrossRef]
- Yang, X.G.; Lou, H.Y.; Zhang, M. Design of cooling water channels for electric vehicle motors. Agric. Equip. Veh. Eng. 2024, 62, 132–137. [Google Scholar] [CrossRef]
- Zhu, B.; Zhou, Y.F.; Yao, M.Y. Research on pump control strategy of battery thermal management system for electric Vehicle. Automot. Appl. Technol. 2023, 48, 1–8. [Google Scholar] [CrossRef]
- Elizar, E.; Zulkifley, M.A.; Muharar, R.; Zaman, M.H.M.; Mustaza, S.M. A review on multiscale-deep-learning application. Sensors 2022, 22, 7384. [Google Scholar] [CrossRef]
- Jiao, L.C.; Zhao, J. A survey on the new generation of deep learning in image processing. IEEE Access 2019, 7, 172231–172263. [Google Scholar] [CrossRef]
- Gu, P.; Lan, X.S.; Li, S.X. Object detection combining CNN and adaptive coloe prior features. Sensors 2021, 21, 2796. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Y.; Xia, Q.Y.; Jin, W. SRDD: A lightweight end-to-end object detection with transformer. Connect. Sci. 2022, 34, 2448–2465. [Google Scholar] [CrossRef]
- Joseph, R.; Santosh, D.; Ross, G. You Only Look Once: Unified real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recongnition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef]
- Wang, Y.C.; Feng, X.H.; Shi, P.F. Research on defect detection system for injection parts based on Machine vision. Control. Instrum. Chem. Ind. 2024, 51, 113–119. [Google Scholar] [CrossRef]
- Xie, D.; He, F.Q.; He, H. Surface defects detection of wiper based on machine vision. Comput. Digit. Eng. 2024, 52, 1221–1227. [Google Scholar] [CrossRef]
- Li, Q.; Shi, Y.; Fan, T. Research on O-ring surface defect detection algorithm based on improved YOLOv8n. Comput. Eng. Appl. 2024, 60, 126–135. [Google Scholar] [CrossRef]
- Shan, M.T.; Gao, W.W. Improved YOLOv4’s algorithm for detecting defects on the sealing surface of inner wire joints. J. Electron. Meas. Instrum. 2022, 36, 120–127. [Google Scholar] [CrossRef]
- Wang, C.J.; Sun, Q.B.; Dong, X.G. Automotive adhesive defect detection based on improved YOLOv8. Signal Image Video Process. 2024, 18, 2583–2595. [Google Scholar] [CrossRef]
- Liu, F.C.; Zhang, J.; Xue, T. YOLO-VDCW: A new surface defect detection algorithm for lightweight strip steel. China Metall. 2024, 34, 125–135. [Google Scholar] [CrossRef]
- Tan, X.; Zhao, J. Enhancing YOLOv8 for improved instance segmentation of automotive surface damage. Comput. Eng. Appl. 2024, 60, 197–208. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.T.; Wang, F. YOLOX: Exceeding YOLO series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar] [CrossRef]
- Howard, A.; Sandler, M.; Chu, G. Searching for MoblieNetV3. In Proceedings of the IEEE/CVF Internation Conference on Computer Vision, Seoul, Republic of Korea, 27 October–20 November 2019; pp. 1314–1324. [Google Scholar] [CrossRef]
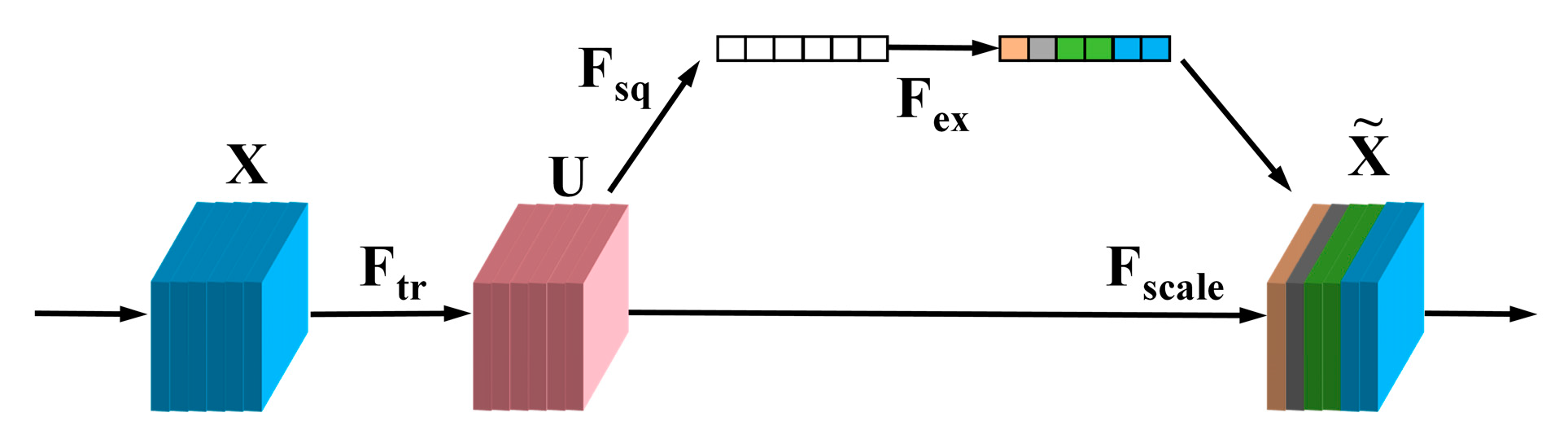
- Hu, J.; Shen, L.; Albanie, S. Squeeze-and-Excitation networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed]
- Liu, A.L.; Chen, Z.X. Construction and approximation of ReLU activation function deep network. J. Shaoxing Univ. 2024, 44, 58–68. [Google Scholar] [CrossRef]
- Liu, X.; Wang, D. Universal consistency of deep ReLU neural networks (in China). Sci. Sin. Inform. 2024, 54, 638–652. [Google Scholar] [CrossRef]
- Zhong, J.C.; Chen, J.Y.; Mian, A. DualConv: Dual convolutional kernels for Lightweight deep neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 9528–9535. [Google Scholar] [CrossRef] [PubMed]
- Gibson, P.; Cano, J.E.; Turner, J. Optimizing grouped convolutions on edge devices. In Proceedings of the IEEE International Conference on Application-Specific Systems, Manchester, UK, 6–8 July 2020; pp. 189–196. [Google Scholar] [CrossRef]
- Zheng, Z.H.; Wang, P.; Ren, D.W. Enhancing geometric factors in model learning and inference for object detection and instance segmentation. IEEE Trans. Cybern. 2022, 52, 8574–8586. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.T.; Dai, G.J.; Zhou, W.H. Multi-scale feature fusion with attention mechanism for crowded road object detection. J. Real Time Image Process. 2024, 21, 29. [Google Scholar] [CrossRef]
- Zhang, T.; Pan, P.F.; Zhang, J. Steel surface defect detection algorithm based on improved YOLOv8n. Appl. Sci. 2024, 14, 5325. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F. Pytorch: An imperative style, high-performance deep learning Library. In Proceedings of the Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 70–78. [Google Scholar] [CrossRef]
- Du, S.J.; Zhang, B.F.; Zhang, P. Scale-Sensitive IoU loss: An improved regression loss function in remote sensing object detection. IEEE Access 2021, 9, 141258–141272. [Google Scholar] [CrossRef]
- Zhang, Y.F.; Ren, W.Q.; Zhang, Z. Focal and efficient IOU loss for accurate bounding box regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| YOLOv8n | Lightweight Backbone Network | CMPDual | Inner-WIou | Weight /MB | FLOPs /G | Accuracy Rate/% | mAP@0.5/% |
|---|---|---|---|---|---|---|---|
| √ | \ | \ | \ | 6.3 | 8.1 | 81.1 | 76.6 |
| √ | √ | \ | \ | 2.6 | 3.6 | 85.7 | 79.7 |
| √ | √ | √ | \ | 2.4 | 3.4 | 85.7 | 79.2 |
| √ | √ | √ | √ | 2.4 | 3.4 | 90.5 | 83.5 |
| IoU Loss Function | Weight/MB | FLOPs/G | Accuracy Rate/% | mAP@0.5/% |
|---|---|---|---|---|
| CIoU | 2.4 | 3.4 | 85.7 | 79.2 |
| SIoU | 2.4 | 3.4 | 83.4 | 79.3 |
| EIoU | 2.4 | 3.4 | 87.5 | 83.1 |
| WIoU | 2.4 | 3.4 | 88.8 | 82.1 |
| Inner-SIoU | 2.4 | 3.4 | 88.8 | 83.4 |
| Inner-EIoU | 2.4 | 3.4 | 84.7 | 82.3 |
| Inner-WIoU | 2.4 | 3.4 | 90.5 | 83.5 |
| IoU Loss Function | Weight/MB | FLOPs/G | Accuracy Rate/% | mAP@0.5/% |
|---|---|---|---|---|
| SSD | 102 | 30.4 | 80.6 | 66.1 |
| YOLOv5s | 3.68 | 4.1 | 85.8 | 79.0 |
| YOLOv7-tiny | 12.3 | 13.2 | 86.9 | 77.8 |
| YOLOv8n | 6.3 | 8.1 | 81.1 | 76.6 |
| Proposed Model | 2.4 | 3.4 | 88.8 | 83.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, L.; Shen, Y.; Li, J.; Jiang, W.; Bian, X.; Yuan, M. Detection of Sealing Surface of Electric Vehicle Electronic Water Pump Housings Based on Lightweight YOLOv8n. Electronics 2025, 14, 258. https://doi.org/10.3390/electronics14020258
Sun L, Shen Y, Li J, Jiang W, Bian X, Yuan M. Detection of Sealing Surface of Electric Vehicle Electronic Water Pump Housings Based on Lightweight YOLOv8n. Electronics. 2025; 14(2):258. https://doi.org/10.3390/electronics14020258
Chicago/Turabian StyleSun, Li, Yi Shen, Jie Li, Weiyu Jiang, Xiang Bian, and Mingxin Yuan. 2025. "Detection of Sealing Surface of Electric Vehicle Electronic Water Pump Housings Based on Lightweight YOLOv8n" Electronics 14, no. 2: 258. https://doi.org/10.3390/electronics14020258
APA StyleSun, L., Shen, Y., Li, J., Jiang, W., Bian, X., & Yuan, M. (2025). Detection of Sealing Surface of Electric Vehicle Electronic Water Pump Housings Based on Lightweight YOLOv8n. Electronics, 14(2), 258. https://doi.org/10.3390/electronics14020258