Abstract
Three-dimensional object detection based on deep neural networks (DNNs) is widely used in safety-related applications, such as autonomous driving. However, existing research has shown that 3D object detection models are vulnerable to adversarial attacks. Hence, the improvement on the robustness of deep 3D detection models under adversarial attacks is investigated in this work. A deep autoencoder-based anomaly detection method is proposed, which has a strong ability to detect elaborate adversarial samples in an unsupervised way. The proposed anomaly detection method operates on a given Light Detection and Ranging (LiDAR) scene in its Bird’s Eye View (BEV) image and reconstructs the scene through an autoencoder. To improve the performance of the autoencoder, an augmented memory module with typical normal patterns recorded is introduced. It is designed to help the model to amplify the reconstruction errors of malicious samples with normal samples negligibly affected. Experiments on several public datasets show that the proposed anomaly detection method achieves an AUC of 0.8 under adversarial attacks and improves the robustness of 3D object detection.
1. Introduction
The task of 3D object detection benefits from the recent development of deep neural networks and has successfully been applied in various fields, including autonomous driving [1] and robotics [2]. Nonetheless, deep neural networks have been shown to be vulnerable [3], i.e., carefully crafted adversarial samples can easily lead to unpredictable results from deep models [4]. In recent years, several studies [5,6,7,8] have investigated adversarial attacks against 3D point cloud recognition and 3D object detection models, achieving successful attack performance. Although there have been many studies [9,10,11] on adversarial defense strategies for 3D point cloud recognition tasks, the improvement of adversarial robustness in the field of 3D object detection is still limited due to the large-scale of the scene and more sparse points [12].
In adversarial attacks, anomaly detection is often used to reveal anomalies or malicious samples, which ensures the security of data and further promotes the robustness of deep models. Traditional anomaly detection methods are developed from rules, state estimation and statistical models [13], which have successfully been applied to industrial control systems and cyber-physical systems [14]. However, faced with the popularity of DNN-based applications, these typical methods suffer from their limitations on modeling data with a high dimension and large complexity. The technique of deep learning has been introduced to anomaly detection to take full advantage of its superior capabilities in learning latent distributions of complex data [13]. Subsequently, deep learning-based anomaly detection (DLAD) has successfully been applied to detect anomalous events in a video sequence [15,16,17]. The advantages of DLAD include its high accuracy in detecting anomalies by learning complex data features and its strong adaptability to different types of data and tasks. However, DLAD is sensitive to noise in data, and its model updating may require longer time when the input space changes [18]. Moreover, the autoencoder (AE) was introduced to anomaly detection because it has strong capabilities to reconstruct samples in an unsupervised manner [19,20,21]. The goal of AE training is to make the reconstruction error between the reconstructed samples and the input samples as small as possible. The abnormal samples reconstructed by a well-trained AE tend to have a larger reconstruction error. However, these techniques focus primarily on 2D images and videos. The existing anomaly detection methods for 3D point cloud data, such as M3DM [22] and the complementary pseudo multimodal feature (CPMF) [23], mainly target small-scale individual point cloud object and 3D recognition. It cannot guarantee the same effectiveness for large-scale LiDAR scenes in autonomous driving because they are sparser compared to single object point clouds. The existing anomaly detection method for LiDAR scenes is only CARLO [7], but it is a rule-based anomaly detection method that finds it difficult to cope with adversarial attack methods based on point perturbations. There is still little research on LiDAR-based 3D object detection from the perceptive of anomaly detection. Considering the severe challenges posed by adversarial attacks, the task of anomaly detection in the field of 3D object detection should further be investigated.
In this paper, we propose a new unsupervised anomaly detection method for 3D object detection models. This method can be independently equipped on any 3D detector and disclose adversarial samples from input LiDAR scenes, leading to an improvement on its robustness. The autoencoder structure was utilized in the anomaly detection process to reveal malicious samples, which calculates the reconstruction loss of any LiDAR scene with its BEV image. Additionally, an augmented memory module was introduced into the autoencoder, which enhanced its capacity to accommodate normal sample patterns and simultaneously increased the reconstruction loss of abnormal samples.
The contributions of this paper are summarized as follows:
- In order to improve the adversarial robustness of LiDAR-based 3D object detection, a deep learning-based anomaly detection method for LiDAR scenes is proposed for the first time to facilitate 3D object detection tasks.
- Due to the lack of abnormal annotated samples, the anomaly detection method leverages the autoencoder structure to disclose a malicious sample in an unsupervised learning manner.
- To improve its ability of discrimination, a memory enhancement module and feature similarity metric are introduced, which facilitate the reconstruction capability of the autoencoder.
- Experiments show that the proposed LiDAR anomaly detection method outperforms the current state-of-the-art methods by a large margin under a popular adversarial attack on three large-scale LiDAR datasets.
2. Related Work
2.1. Three-Dimensional Object Detection
LiDAR-based 3D object detection is widely applied to perception tasks [1,2]. Existing 3D object detection models process LiDAR scene data with different point cloud representations, such as voxel, BEV image and raw point cloud. The voxel-based approaches divide a 3D space with multiple voxel units so that the point cloud data in a scene can be collected by the corresponding voxels and thus solve the challenge of point cloud disorder. VoxelNet [24] and SECOND [25] stand out as an end-to-end learning framework for point cloud-based 3D object detection, eliminating the need for manual feature engineering by converting point clouds into descriptive volumetric representations and interfacing with a Region Proposal Network (RPN) for detection results. PointPillars [26] further refines this approach by transforming sparse point clouds into regular pillar structures, enabling 2D Convolutional Neural Networks (CNNs) to process the data efficiently. However, voxel-based approaches are computationally complex. PIXOR [27] offers a real-time 3D object detection solution by projecting point clouds into BEV form and outputting pixel-wise neural network predictions. The BEV-image-based methods reduce computational consumption by compressing the 3D point cloud into a 2D image and borrow advanced methods from 2D object detection. Following the success of PointNet [28] and PointNet++ [29], the raw point cloud data have been used in PointRCNN [30] and its subsequent work [31,32] and achieved the superior performance compared to other data representations. PointRCNN [30] proposes a two-stage framework for detecting 3D objects from raw point clouds, generating high-quality 3D proposals in a bottom-up manner and refining them with local spatial features. PV-RCNN [32] integrates 3D voxel CNNs with PointNet-based set abstraction methods, leveraging the efficiency of voxel-based learning and the flexible receptive fields of point-based networks to achieve precise 3D object detection. In addition, prediction methods based on center points have also made significant progress in performance. CenterPoint [33] focuses on detecting the center point of each object for localization and employs techniques like Non-Maximum Suppression (NMS) for post-processing. Moreover, CenterFormer [34] introduces transformer-based architectures to capture long-range dependencies in point cloud data, enhancing the detection accuracy and robustness.
2.2. Attacks on 3D Object Detection
Since Szegedy [3] succeeded in adversarial sample generation to attack deep models, the vulnerability of deep neural networks has been actively explored. Shin et al. [35] first investigated the interference of light on LiDAR, which affected the detection of 3D objects. Cao et al. [36] added a small amount of points into the scene to deceive a 3D detector, proving that 3D object detectors can be easily disrupted by malicious point injection attacks. Sun et al. [7] injected extra points into occluded regions of the LiDAR scene, which violated the physical laws of light occlusion and achieved a high success rate in this attack. Tu et al. [37] added a point cloud of objects to the roof of a car to simulate the cargo on top of a vehicle, and successfully spoofed the detector. Wang et al. [8] and Cai et al. [38,39] added carefully optimized perturbation points to the target object while maintaining visual imperceptibility iteratively. Hahner et al. [40,41] investigated the effect of snow fall and fog on LiDAR data generation and improved the robustness of 3D object detection models by adversarial training. LISA [42] considered the impact of various extreme weathers, such as fog and rain, on 3D object detection models and generated adverse weather-augmented datasets. Dong et al. [43] divided the corruptions of LiDAR data into 27 categories and investigated their effect on 3D object detectors. The 3D-Vfield [44] added damaged vehicles’ points to the scene and explored the robustness of the 3D object detector to unknown objects. The aforementioned methods can successfully attack 3D object detection models in most cases and demonstrate the vulnerability of these models.
2.3. Anomaly Detection
Typically, anomaly detection methods are developed from rules, statistical learning and machine learning, such as the one-class classification models [45]. However, these methods are difficult to adapt to the distribution of high-dimensional data. Recently, anomaly detection methods benefiting from the advances in the technique of unsupervised deep learning have been proposed. The methods of [22,23,46,47] performed anomaly detection on point clouds using deep neural networks and achieved excellent results, demonstrating that DLAD can effectively detect anomalies in point cloud data. The methods of [16,19] generated an image from the passing frames and compared it with the real captured frame to reveal potential malicious samples. Although its process was complicated, it created a new idea for later anomaly detection methods. In addition, studies [15,48] introduced autoencoders for reconstruction in the anomaly detection process, demonstrating that the autoencoder developed on the basis of the reconstruction strategy can improve the anomaly detection performance significantly. Slavic et al. [49] applied anomaly detection of video frames to autonomous driving scenarios using autoencoders and dynamic Bayesian network frameworks. However, the performance of the AE was limited for reconstruction of complex data. Therefore, memory mechanisms were introduced to the autoencoder to improve the reconstruction performance. The memory mechanism has been applied to various applications and achieved success in neural networks [50,51]. MemAE [52] first applied the memory mechanism to anomaly detection and recorded the prototypical elements of the encoded normal data in memory. Park et al. [53] used a small number of memory items to record diverse and discriminative patterns of normal data, demonstrating the effectiveness of memory items in anomaly detection. Additionally, Wu et al. [54] and Guo et al. [55] also utilized memory modules as guidance to improve video anomaly detection and achieve leading performance. However, in the field of 3D object detection, the only existing anomaly detection method is CARLO [7], which is a rule-based anomaly detection method. Thus, introducing anomaly detection methods based on autoencoders and memory mechanisms into 3D object detection and LiDAR scene data has great potential and is worth exploring.
3. Methods
In this section, the autoencoder facilitated with a memory augmentation module and reconstruction loss are explained. An overview of the framework is illustrated in Section 3.1. In Section 3.2, the problem of anomaly detection for 3D object detection models is formulated. In Section 3.3 and Section 3.4, the method to generate the memory module augmented autoencoder is detailed. In Section 3.5, the loss function and optimization strategy of the anomaly detection is described.
3.1. Method Overview
The purpose of anomaly detection is to distinguish whether an input to a deep 3D model is a benign or adversarial sample. It operates independently of the detector and can be equipped before any detection pipeline. As illustrated in Figure 1, all LiDAR scenes are first converted into BEV images to handle the challenge of disorder and sparsity, as well as the large computation complexity. It should be noted that the conversion of the BEV image only exists in anomaly detection methods and is independent of the point cloud data representation of subsequent detectors. In the unsupervised training phase, the memory augmented autoencoder takes normal samples as input. Meanwhile, the memory module stores and updates features of the normal samples. In the detection phase, an image is input into the autoencoder and the reconstruction loss is computed after reconstruction, according to which the anomaly samples can be detected indicated by large reconstruction loss.
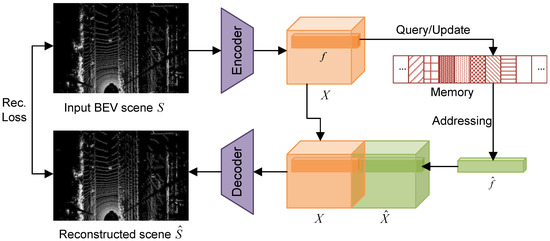
Figure 1.
Illustration of the proposed unsupervised anomaly detection on BEV LiDAR scenes. The encoder extracts a feature map X from an input BEV LiDAR scene. In the training phase, features from normal BEV scenes are used to update features of the same length stored in the memory module. In the prediction phase, each feature f in X queries the memory module to address the normal feature that is most similar to it. All addressed features form the feature map , which concatenates to X and is used as the input to the decoder. The output BEV scene decoded from the concatenated feature can be used to calculate the reconstruction loss for anomaly detection.
3.2. Formulation of Anomaly Detection
Let P represent a benign LiDAR scene and represent an adversarial sample generated from P. and are the reconstructed outputs of P and , respectively, produced with the autoencoder . The main goal of the anomaly detection task is to distinguish the normal LiDAR scene P and the adversarial scene maliciously modified by adversarial attack methods. The target of the anomaly detection is defined as follows [23]:
where is a metric used to measure the distance between the original scene and the scene reconstructed by the autoencoder.
3.3. Encoder and Decoder
To detect the crafted adversarial samples, the reconstruction method of the memory-augmented autoencoder is utilized in anomaly detection. The memory-augmented autoencoder is composed of an encoder, a memory module and a decoder. Inspired by methods such as MNAD [53] and Gong et al. [52], anomaly detection transforms the LiDAR point cloud scene into a BEV image and calculates the difference between that input and its reconstructed image. The purpose of the anomaly detection process is to screen out anomalous samples before the 3D object detection. It is independent of the 3D object detector, and only samples that are considered to have no anomalies will be sent to the 3D object detector.
As shown in Figure 1, the encoder maps the input image to the latent space, where it is represented with the feature map X. Each feature f in the latent space will be a query for the memory module to retrieve the most relevant feature stored in memory. In addition, it updates the normal image features to items of the memory module during training. As a reconstructed feature of f, is composed of all feature items in the memory module. The features map X retrieves its similar map through the address process from f to . The decoder reconstructs the input image from X concatenated with the retrieved feature map. Compared to the reconstruction loss of the normal samples, the reconstruction loss of adversarial samples is much larger. The autoencoder reconstructs the samples on the basis of the typical normal features recorded in the augmented memory modules. The output reconstructed samples are more similar to the normal samples and diverse from the abnormal inputs. The augmented memory module is described in Section 3.4.
3.4. Augmented Memory Module
The memory module is designed to encode the latent distribution of normal samples in the feature space, which is derived from the benign dataset with the help of the encoder and decoder structure. The memory module is exploited to measure the deviation of the input sample from the distribution of normal samples.
Specifically, during the training process of the autoencoder, all normal samples will be extracted as features in turn by the encoder. When the memory module has free space, the features extracted from the sample will be directly stored. After the memory module is filled, the similarity is calculated between the features in the memory. If the similarity loss of the next normal sample is less than the maximum similarity loss in the existing memory module, the feature with a smaller will replace the existing feature and be stored in the memory module.
Considering the strong ability of the autoencoder to reconstruct inputs even with abnormal samples, a memory augmentation module is introduced. Typical normal features are recorded in the proposed memory module, which can be represented as , where the memory size N represents the number of memory items used to store typical features and C represents the channels of each memory feature. Note that the performance of the memory module is influenced by the number of recorded typical features, where a memory module with a larger size generally describes the latent data distribution more precisely at the cost of a higher memory and computation requirement. In the case of a bigger training dataset, the size of the memory module can be increased to achieve a desired performance.
It should be noted that C should have the same dimension as the query f output of the encoder. The memory module retrieves the features vector according to the probability vector generated by the similarity between and each memory item, which can be expressed as follows [52]:
where the weight is obtained from the query f and memory item . Besides the cosine similarity, we chose the Hausdorff distance to better compute the similarity between f and . The Hausdorff distance can directly represent the largest gap between the two sets. In anomaly detection, cosine similarity and the Hausdorff distance are used at the same time. Cosine similarity is used to measure the overall difference between two features, and the Hausdorff distance is used to measure the maximum difference between two features. The softmin function is used to convert the result of the distance to the corresponding probability weight. Meanwhile, the softmax function is used for the cosine similarity:
where the represents the Hausdorff distance that we used,
Thus, the normal features that closest to the query feature f can be found. All memory items will be included in the output vector according to the weight . The detailed process of the proposed memory module-based anomaly detection method is described in Algorithm 1.
| Algorithm 1: The proposed anomaly detection method for the LiDAR scene |
 |
3.5. Loss Function
Let S and denote the input BEV scene and output scene from the proposed unsupervised anomaly detection, respectively. The loss function is designed to minimize the reconstruction loss between S and . The L2 norm is used to define the loss:
In the unsupervised training phase, all samples update the memory-augmented autoencoder. Meanwhile, the memory module also records the typical non-perturbed pattern. In the testing phase, the normal samples can find similar features from the memory module for the concatenation of these two features. However, the abnormal samples produce a larger reconstruction loss because they cannot retrieve similar normal patterns. In the process of anomaly detection, when the reconstruction loss between the input sample and its reconstructed sample is greater than the reconstruction threshold T, it is determined that there is an anomaly.
In order for the memory modules to better learn the distribution of normal sample features, items in memory should be distinctly separated from each other. Therefore, we propose a feature similarity loss to promote the difference of memory module items [53]:
where the Hausdorff distance is not used to allow for greater variability between items in memory. The feature similarity loss needs to measure the difference in all dimensions of the features, while Hausdorff distance can only measure the maximum value of the difference.
Let denote the probability weights of in features map X. The sparsity of needs to be guaranteed to ensure that more memory items are utilized. Here, we chose to minimize the entropy as the sparsity loss, which is defined as follows:
where M represents the number of queries f in the features map X. Therefore, the loss function of the anomaly detection process can be described as follows:
The construction loss, similarity loss and sparsity loss are balanced by the parameters and . The loss encourages items in the memory module to be separated and utilized. During the training, the memory module will update synchronously with the autoencoder through backpropagation.
4. Experiments
In this section, the experimental results of proposed anomaly detection method are analyzed. The dataset and target adversarial attack methods are described in Section 4.1. In Section 4.2, the implementation of the anomaly detection is described in detail. We present the quantitative results in Section 4.3 and qualitative results in Section 4.4. Additionally, the ablation studies are conducted in Section 4.5.
4.1. Dataset and Target Methods
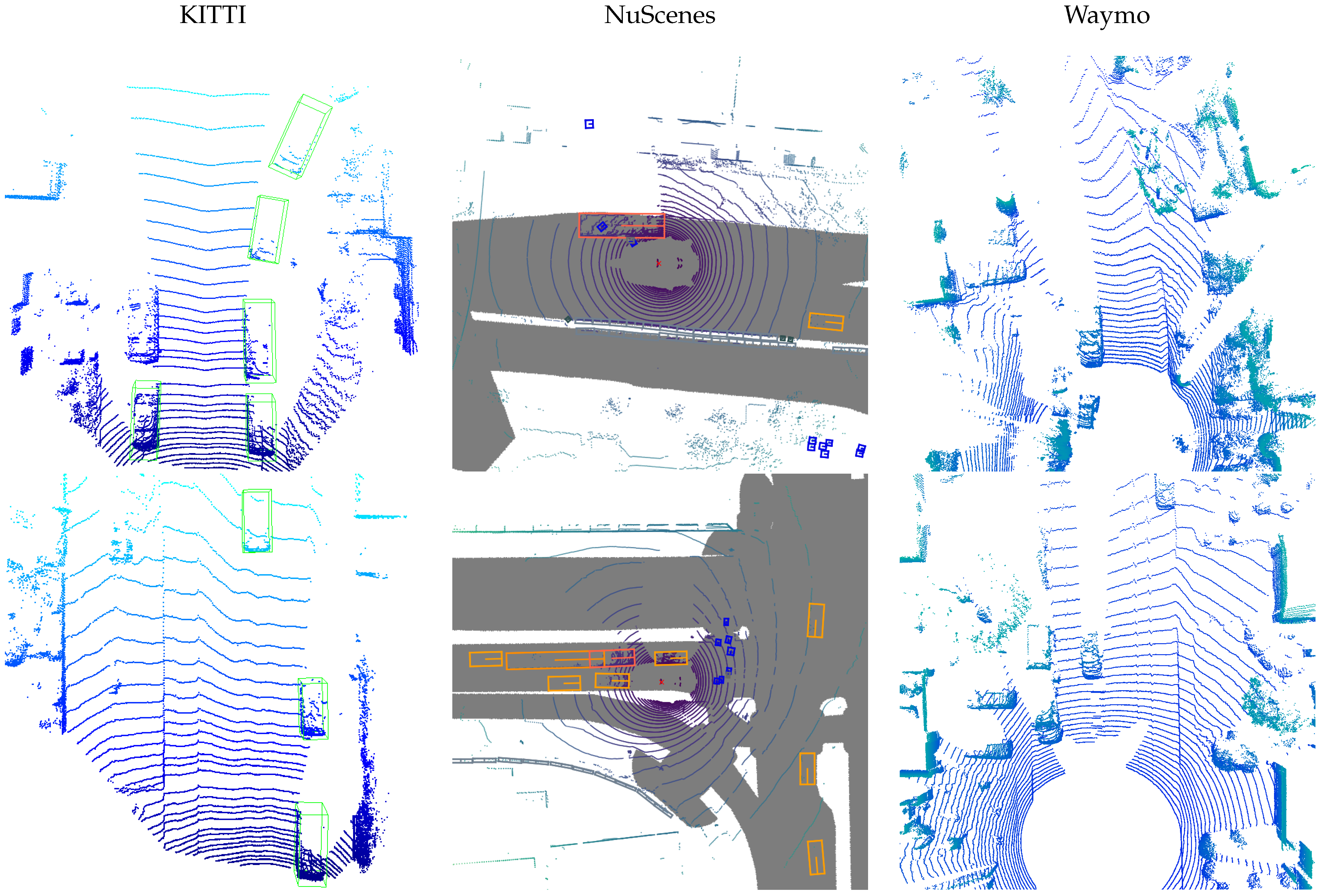
The KITTI [56] dataset contains 3712 training samples and 3769 validation samples. In addition, the large-scale autonomous scenes datasets NuScenes [57] and Waymo [58] are used to verify the proposed anomaly detection method. An illustration of typical scene samples from the three datasets are shown in Figure 2. They contain 700 and 798 sequences for training. Furthermore, 150 and 202 sequences were prepared for validation experiments, respectively. We used the validation set samples to generate adversarial samples. In the process of generating adversarial samples and anomaly detection, due to the differences between the detector and the dataset, we only considered vehicles and did not include other object categories. The proposed anomaly detection algorithm was applied on the advanced adversarial attack method [8]. The adversarial attack method generates different adversarial samples against each of the five different victim detectors, which are PIXOR [27], PointPillars [26], PointRCNN [30], PV-RCNN [32] and CenterPoint [33]. The code implementation about the detector utilizes the MMDetection3d platform [59], which integrates advanced 3D object detection models.
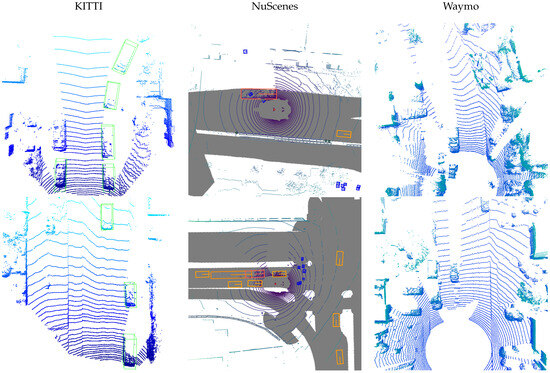
Figure 2.
Visualization of sample scenes from the datasets used in the work.
4.2. Implementation Details
To better optimize the memory module, the training set of the LiDAR dataset was used to train as the unattacked samples. Half of the samples of the validation set were used to generated adversarial samples and the labeled anomaly. Unattacked samples are defined as normal samples, while adversarial samples are abnormal samples.
When converting the scenes to BEV images, the area we selected was meters for KITTI and meters for NuScenes and Waymo. We set the number of epochs and initial learning rate as 80 and empirically, which achieved the best performance in our experiment. The values of the hyperparameters and chosen by grid search were set to 0.1 during the training phase.
4.3. Quantitative Evaluation
Following [22,23], the adversarial samples were considered as an anomaly and the performance was evaluated in terms of Area Under Curve (AUC). AUC represents the area enclosed by the coordinate axis under the Receiver Operating Characteristic Curve (ROC). The ROC represents the False Positive Rate (FPR) and the True Positive Rate (TPR) with various thresholds, while a higher AUC indicates better anomaly detection performance. We report the AUC performance of the proposed anomaly detection method on the elaborate test set with adversarial samples. It should be noted that the samples generated by the attacks on PIXOR, PointPillars, PointRCNN, PV-RCNN and CenterPoint are from the KITTI dataset, while the attacks from other two datasets are launched on PointPillars, PV-RCNN and CenterPoint detectors. The state-of-the-art LiDAR data anomaly detection methods CARLO [7], M3DM [22] and CPMF [23] are utilized to detect the adversarial samples. The quantitative results are shown in Table 1.

Table 1.
The AUC results and comparison of the anomaly detection method on the KITTI dataset. The victim detectors represent the target detectors used to generate the adversarial samples by method [8].
It can be seen from Table 1 that the proposed anomaly detection method outperforms existing point cloud-based anomaly detection methods M3DM and CPMF, as well as the LiDAR-data-based anomaly detection method, CARLO. Compared to the point cloud-based anomaly detection methods M3DM and CPMF, the proposed anomaly detection method has an AUC improvement of over . Specifically, compared to the previous LiDAR-based anomaly detection method CARLO, AUC has been increased by an additional on PointPillars and PV-RCNN detectors. In addition, an AUC of has been achieved by the proposed method on the CenterPoint detector, in contrast to an AUC of by CARLO. Since CARLO is a rule-based anomaly detection method, it is difficult to detect perturbations in the samples that are generated by the deep model. The results demonstrate that the anomaly detection method based on point cloud data has limited performance in large-scale LiDAR scenes and the proposed BEV-image-based transformation can better handle large-scale scene data. The memory-augmented autoencoder, on the other hand, increases the ability to discriminate subtle perturbations and thus successfully detects adversarial samples.
Moreover, the quantitative results on the NuScenes dataset are shown in Table 2. In terms of AUC performance, the proposed method outperforms the other three anomaly detection methods at least on all victim detectors. This illustrates that the proposed method is also effective for the larger LiDAR dataset.
Table 2.
The AUC results and comparison of the anomaly detection method under adversarial attack [8] on the Nuscenes dataset.
The same evaluation is performed on the Waymo dataset and the results are shown in Table 3. The performance of the proposed anomaly detection method exceeds in AUC on all victim detectors. It can be found that the proposed method performs better on the NuScenes and Waymo datasets, which have more data compared to the KITTI dataset. The performance of M3DM and CPMF in Table 3 is substantially lower than that of the proposed methods, which suggests that they are difficult to handle when there are more points and sparser distributions in large-scale LiDAR scenes. Meanwhile, for the rule-based anomaly detection method CARLO, it proved to be unable to detect the adversarial samples generated by the point perturbation attack.
Table 3.
The AUC results and comparison of the anomaly detection method under adversarial attack [8] on the Waymo dataset.
4.4. Qualitative Evaluation
In this section, we demonstrate the qualitative evaluation of the proposed anomaly detection method. PointRCNN is used as a victim detector on the KITTI dataset to generate adversarial samples. Normal scenes and adversarial samples are converted into BEV images and reconstructed by the proposed anomaly detection method, respectively. The different reconstruction effects of the proposed anomaly detection method for normal and abnormal samples can be demonstrated by comparing the errors between the BEV images before and after the reconstruction process. The visualization of the reconstruction errors of three scenes in the KITTI dataset are shown in Figure 3, where the reconstruction errors are denoted as red areas. The first row of Figure 3 represents a BEV image of the normal sample along with its reconstructed sample and the reconstruction error for the comparison. The last two rows represent the reconstructed samples of the adversarial samples as well as the reconstruction errors. While the first column represents the BEV images of the original input scenes, the second column represents the BEV images of the reconstructed scenes and the third column shows the reconstruction error between them after rendering.

Figure 3.
Visualization of reconstruction error on normal samples and adversarial samples: input scenes (left); reconstruction scenes (middle); construction error (right). The input of the first row is a normal scene, and the input of the second and third rows are adversarial scenes. Best viewed in color.
It can be learned from Figure 3 that the reconstruction error of the first row of normal scenes is small, while the reconstruction error of abnormal samples fills most areas. For the reconstruction scenes of the second column, the main perturbed regions have been reconstructed correctly for adversarial samples, and nd the perturbations of the reconstructed images are significantly reduced. Figure 3 shows that the reconstruction method can retain a large number of features of normal samples. For adversarial anomaly samples, the reconstruction method can smooth its anomalous regions and make it closer to normal samples. These prove the effectiveness of the proposed anomaly detection method and its reconstruction process.
4.5. Ablation Studies
In this section, we investigated the performance impact of each component in the memory module, including cosine similarity, Hausdorff distance, , and memory size N. We conducted the ablation studies on the adversarial samples generated on the KITTI dataset and PointRCNN as a victim detector. The results are shown in Table 4; the other components include the cosine similarity and Hausdorff distance, and .
Table 4.
Performance for different components combinations of anomaly detection models.
It should be noted that these components are based on memory modules. In particular, the anomaly detection model equipped with or without the memory enhancement module results in an asymmetric or symmetric autoencoder and decoder structure, whose performance are listed in the first and respective rows of Table 4. It can be learned from Table 4 that both model structures can achieve comparative results, reaching to larger than 0.7 in terms of AUC. Thus, it can be concluded that the symmetry of the automatic encoder has no effect on the performance of anomaly detection.
Among the components, the augmented memory modules have the greatest impact on performance. The combination of the cosine similarity and the Hausdorff distance is more effective in measuring feature similarity. Meanwhile, and play an important role in the construction and selection of memory modules.
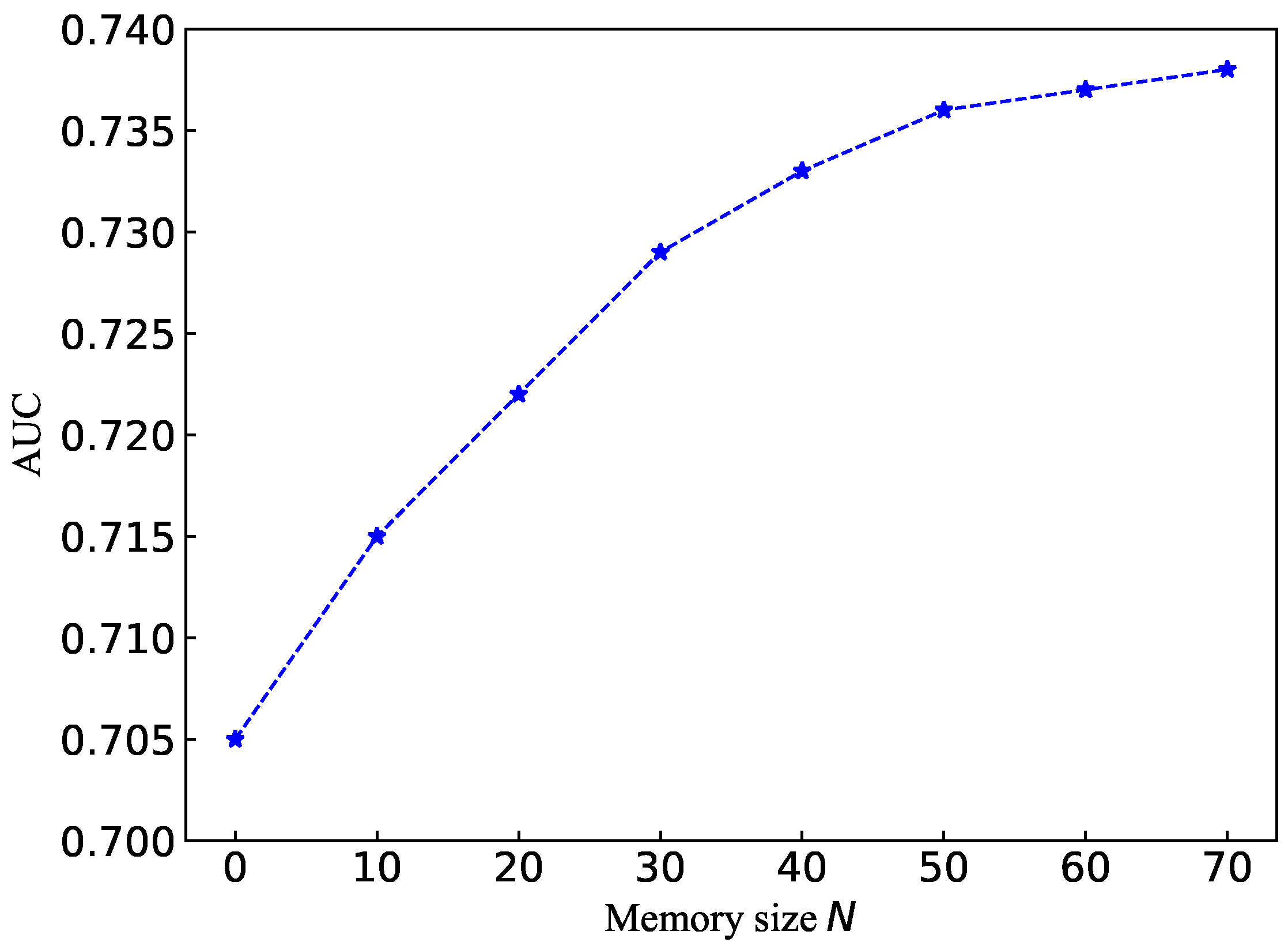
We also investigated the influence on the performance of the memory module size N. We conducted experiments by using different memory size settings on the PointRCNN detector and KITTI dataset. The AUC results are reported in Figure 4.
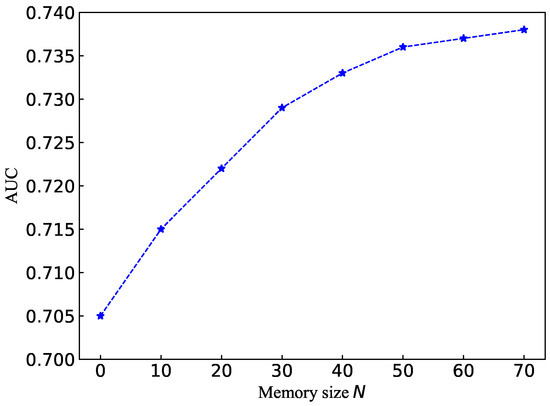
Figure 4.
The effect of memory size N on anomaly detection performance.
It can be seen from Figure 4 that the number of memory items can highly affect the performance of anomaly detection. When the memory is relatively compact, an increase in the memory item size N will effectively improve AUC. The memory module ultimately represents the probability distribution of typical normal samples rather than all cases under the constraints of memory size N. With a large memory size, an increase in the size N will have little impact on performance. At the same time, an expansion of the memory size will also significantly increase the training time.
5. Discussion
The research presented in this paper introduces an unsupervised anomaly detection method aimed at improving the adversarial robustness of 3D object detection models. The proposed method leverages a deep autoencoder equipped with a memory augmentation module to detect anomalies in LiDAR scenes, which can be independently integrated into any 3D detector. This study addresses a critical issue in the field of computer vision, where adversarial attacks pose significant threats to the reliability and safety of 3D object detection systems, particularly in applications such as autonomous driving.
The key innovation of our approach lies in the transformation of LiDAR point cloud scenes into BEV images for anomaly detection. This transformation allows for more effective anomaly detection in large-scale scenes compared to methods that operate directly on point cloud data. By calculating the difference between the input and reconstructed BEV images, our method can accurately identify adversarial samples that introduce perturbations to the scene.
Experimental results demonstrate the superiority of our proposed anomaly detection method over existing point cloud-based and LiDAR-data-based anomaly detection methods. Specifically, our method achieves higher AUC scores on both the KITTI, NuScenes and Waymo datasets, indicating its ability to better detect adversarial samples generated by adversarial attack against different 3D object detection models. The effectiveness of the proposed anomaly detection method is mainly because it converts the LiDAR scene point cloud data into a BEV image to solve the challenges of sparsity and disorder. At the same time, ablation studies have proved that the augmented memory module can greatly improve the reconstruction performance of the automatic encoder.
One of the primary advantages of our method is its unsupervised nature, which eliminates the need for labeled abnormal samples during training. This is particularly beneficial in real-world applications where abnormal samples may be rare or difficult to obtain. Additionally, our method is flexible and can be easily adapted to different 3D detectors, making it a versatile solution for improving adversarial robustness. However, it is worth noting that while our method performs well in detecting perturbation-based adversarial samples, there may still be challenges in detecting other types of attacks. For example, for the well-designed point injection attack and point drop attack, the proposed anomaly detection method can only output a small reconstruction loss; that is, it is difficult to find anomalies. Both of them can disguise the adversarial attack as a normal vehicle or background point cloud, which still poses a great threat to the security of 3D object detector. Furthermore, the performance of our method may be affected by the quality and resolution of the LiDAR data, as well as the complexity of the scene.
In conclusion, our proposed unsupervised anomaly detection method represents a significant step forward in improving the adversarial robustness of 3D object detection models. By leveraging the power of deep learning-based anomaly detection and the augmented memory module, our method achieves high AUC performance. Future research could explore ways to further enhance the robustness of our method against more sophisticated adversarial attacks and to adapt it to other types of sensors and data representations. Additionally, integrating our anomaly detection method with other defensive strategies, such as adversarial training, could provide a more comprehensive solution to the problem of adversarial attacks in 3D object detection.
6. Conclusions
This study proposes an unsupervised anomaly detection method to enhance the adversarial robustness of 3D object detection models. By utilizing a deep autoencoder with a memory augmentation module, the method effectively detects anomalies in LiDAR scenes, demonstrating superior performance compared to existing anomaly detection techniques. Autoencoders are utilized to reconstruct BEV images of LiDAR scenes, while the augmented memory module preserves latent features of normal samples during unsupervised training to assist in the reconstruction process of the autoencoder. The experimental results validate the effectiveness of the proposed approach. It achieved an AUC of over 0.7 for adversarial samples on three large-scale LiDAR datasets and even reached 0.8 on the NuScenes dataset, significantly leading existing point cloud anomaly detection methods. Meanwhile, our study shows that deep learning-based adversarial attack method can be detected through deep learning-based anomaly detection method. It improves the robustness of 3D object detection models against adversarial attacks, which needs to be continuously investigated for applications security.
Author Contributions
Conceptualization, M.C. and X.W.; Data curation, M.C.; Formal analysis, M.C.; Funding acquisition, X.W. and H.L.; Investigation, M.C.; Methodology, M.C.; Project administration, M.C.; Resources, M.C.; Software, M.C.; Supervision, X.W., F.S. and H.L.; Validation, M.C. and X.W.; Visualization, M.C.; Writing—original draft, M.C.; Writing—review and editing, X.W., F.S. and H.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China (No. 62072076), Sichuan Provincial Research Plan Project (No. 2022ZDZX0005, No. 24ZDZX0001, No. 24ZDZX0002).
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Hong, D.S.; Chen, H.H.; Hsiao, P.Y.; Fu, L.C.; Siao, S.M. CrossFusion net: Deep 3D object detection based on RGB images and point clouds in autonomous driving. Image Vis. Comput. 2020, 100, 103955. [Google Scholar] [CrossRef]
- An, P.; Liang, J.; Yu, K.; Fang, B.; Ma, J. Deep structural information fusion for 3D object detection on LiDAR-camera system. Comput. Vis. Image Underst. 2022, 214, 103295. [Google Scholar] [CrossRef]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.J.; Fergus, R. Intriguing properties of neural networks. In Proceedings of the International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2014; Bengio, Y., LeCun, Y., Eds.; DBLP: Trier, Germany, 2013. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Frossard, P. DeepFool: A Simple and Accurate Method to Fool Deep Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE Computer Society: Los Alamitos, CA, USA, 2016; pp. 2574–2582. [Google Scholar] [CrossRef]
- Xiang, C.; Qi, C.R.; Li, B. Generating 3D Adversarial Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; Computer Vision Foundation/IEEE: Piscataway, NJ, USA, 2019; pp. 9136–9144. [Google Scholar] [CrossRef]
- Hamdi, A.; Rojas, S.; Thabet, A.K.; Ghanem, B. AdvPC: Transferable Adversarial Perturbations on 3D Point Clouds. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2020; Volume 12357, pp. 241–257. [Google Scholar] [CrossRef]
- Sun, J.; Cao, Y.; Chen, Q.A.; Mao, Z.M. Towards Robust LiDAR-based Perception in Autonomous Driving: General Black-box Adversarial Sensor Attack and Countermeasures. In Proceedings of the USENIX Security Symposium, Boston, MA, USA, 12–14 August 2020; Capkun, S., Roesner, F., Eds.; USENIX Association: Berkeley, CA, USA, 2020; pp. 877–894. [Google Scholar]
- Wang, X.; Cai, M.; Sohel, F.; Sang, N.; Chang, Z. Adversarial point cloud perturbations against 3D object detection in autonomous driving systems. Neurocomputing 2021, 466, 27–36. [Google Scholar] [CrossRef]
- Wu, Z.; Duan, Y.; Wang, H.; Fan, Q.; Guibas, L.J. IF-Defense: 3D Adversarial Point Cloud Defense via Implicit Function based Restoration. arXiv 2020, arXiv:2010.05272. [Google Scholar]
- Li, G.; Xu, G.; Qiu, H.; He, R.; Li, J.; Zhang, T. Improving Adversarial Robustness of 3D Point Cloud Classification Models. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Avidan, S., Brostow, G.J., Cissé, M., Farinella, G.M., Hassner, T., Eds.; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2022; Volume 13664, pp. 672–689. [Google Scholar] [CrossRef]
- Li, K.; Zhang, Z.; Zhong, C.; Wang, G. Robust Structured Declarative Classifiers for 3D Point Clouds: Defending Adversarial Attacks with Implicit Gradients. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 15273–15283. [Google Scholar] [CrossRef]
- Cai, M.; Wang, X.; Sohel, F.; Lei, H. Diffusion Models-Based Purification for Common Corruptions on Robust 3D Object Detection. Sensors 2024, 24, 5440. [Google Scholar] [CrossRef]
- Pang, G.; Shen, C.; Cao, L.; Hengel, A.v.d. Deep Learning for Anomaly Detection: A Review. ACM Comput. Surv. 2021, 54, 38:1–38:38. [Google Scholar] [CrossRef]
- Giraldo, J.; Urbina, D.I.; Cárdenas, A.A.; Valente, J.; Faisal, M.A.; Ruths, J.; Tippenhauer, N.O.; Sandberg, H.; Candell, R. A Survey of Physics-Based Attack Detection in Cyber-Physical Systems. ACM Comput. Surv. 2018, 51, 76:1–76:36. [Google Scholar] [CrossRef] [PubMed]
- Zong, B.; Song, Q.; Min, M.R.; Cheng, W.; Lumezanu, C.; Cho, D.k.; Chen, H. Deep Autoencoding Gaussian Mixture Model for Unsupervised Anomaly Detection. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Zhao, Y.; Deng, B.; Shen, C.; Liu, Y.; Lu, H.; Hua, X.S. Spatio-Temporal AutoEncoder for Video Anomaly Detection. In Proceedings of the ACM on Multimedia Conference, Mountain View, CA, USA, 23–27 October 2017; Liu, Q., Lienhart, R., Wang, H., Chen, S.W.K.T., Boll, S., Chen, Y.P.P., Friedland, G., Li, J., Yan, S., Eds.; ACM: New York, NY, USA, 2017; pp. 1933–1941. [Google Scholar] [CrossRef]
- Park, C.; Kim, D.; Cho, M.; Kim, M.; Lee, M.; Park, S.; Lee, S. Fast video anomaly detection via context-aware shortcut exploration and abnormal feature distance learning. Pattern Recognit. 2025, 157, 110877. [Google Scholar] [CrossRef]
- Hojjati, H.; Ho, T.K.K.; Armanfard, N. Self-supervised anomaly detection in computer vision and beyond: A survey and outlook. Neural Netw. 2024, 172, 106106. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Luo, W.; Lian, D.; Gao, S. Future Frame Prediction for Anomaly Detection—A New Baseline. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; Computer Vision Foundation/IEEE Computer Society: Los Alamitos, CA, USA, 2018; pp. 6536–6545. [Google Scholar] [CrossRef]
- Su, Y.; Tan, Y.; An, S.; Xing, M.; Feng, Z. Semantic-driven dual consistency learning for weakly supervised video anomaly detection. Pattern Recognit. 2025, 157, 110898. [Google Scholar] [CrossRef]
- Cao, C.; Zhang, H.; Lu, Y.; Wang, P.; Zhang, Y. Scene-Dependent Prediction in Latent Space for Video Anomaly Detection and Anticipation. IEEE Trans. Pattern Anal. Mach. Intell. 2025, 47, 224–239. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Peng, J.; Zhang, J.; Yi, R.; Wang, Y.; Wang, C. Multimodal Industrial Anomaly Detection via Hybrid Fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 8032–8041. [Google Scholar] [CrossRef]
- Cao, Y.; Xu, X.; Shen, W. Complementary pseudo multimodal feature for point cloud anomaly detection. Pattern Recognit. 2024, 156, 110761. [Google Scholar] [CrossRef]
- Zhou, Y.; Tuzel, O. VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; Computer Vision Foundation/IEEE Computer Society: Los Alamitos, CA, USA, 2018; pp. 4490–4499. [Google Scholar] [CrossRef]
- Yan, Y.; Mao, Y.; Li, B. SECOND: Sparsely Embedded Convolutional Detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. PointPillars: Fast Encoders for Object Detection From Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; Computer Vision Foundation/IEEE: Piscataway, NJ, USA, 2019; pp. 12697–12705. [Google Scholar] [CrossRef]
- Yang, B.; Luo, W.; Urtasun, R. PIXOR: Real-Time 3D Object Detection From Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; Computer Vision Foundation/IEEE Computer Society: Los Alamitos, CA, USA, 2018; pp. 7652–7660. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; IEEE Computer Society: Los Alamitos, CA, USA, 2017; pp. 77–85. [Google Scholar] [CrossRef]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. In Proceedings of the Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U.v., Bengio, S., Wallach, H.M., Fergus, R., Vishwanathan, S.V.N., Garnett, R., Eds.; pp. 5099–5108. [Google Scholar]
- Shi, S.; Wang, X.; Li, H. PointRCNN: 3D Object Proposal Generation and Detection From Point Cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; Computer Vision Foundation/IEEE: Piscataway, NJ, USA, 2019; pp. 770–779. [Google Scholar] [CrossRef]
- Shi, S.; Wang, Z.; Shi, J.; Wang, X.; Li, H. From Points to Parts: 3D Object Detection From Point Cloud With Part-Aware and Part-Aggregation Network. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 2647–2664. [Google Scholar] [CrossRef] [PubMed]
- Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; Li, H. PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; Computer Vision Foundation/IEEE: Piscataway, NJ, USA, 2020; pp. 10526–10535. [Google Scholar] [CrossRef]
- Yin, T.; Zhou, X.; Krähenbühl, P. Center-Based 3D Object Detection and Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; Computer Vision Foundation/IEEE: Piscataway, NJ, USA, 2021; pp. 11784–11793. [Google Scholar] [CrossRef]
- Zhou, Z.; Zhao, X.; Wang, Y.; Wang, P.; Foroosh, H. CenterFormer: Center-Based Transformer for 3D Object Detection. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Avidan, S., Brostow, G.J., Cissé, M., Farinella, G.M., Hassner, T., Eds.; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2022; Volume 13698, pp. 496–513. [Google Scholar] [CrossRef]
- Shin, H.; Kim, D.; Kwon, Y.; Kim, Y. Illusion and Dazzle: Adversarial Optical Channel Exploits Against Lidars for Automotive Applications. In Proceedings of the Cryptographic Hardware and Embedded Systems, Taipei, Taiwan, 25–28 September 2017; Fischer, W., Homma, N., Eds.; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2017; Volume 10529, pp. 445–467. [Google Scholar] [CrossRef]
- Cao, Y.; Xiao, C.; Cyr, B.; Zhou, Y.; Park, W.; Rampazzi, S.; Chen, Q.A.; Fu, K.; Mao, Z.M. Adversarial Sensor Attack on LiDAR-based Perception in Autonomous Driving. In Proceedings of the ACM SIGSAC Conference on Computer and Communications Security, London, UK, 11–15 November 2019; Cavallaro, L., Kinder, J., Wang, X., Katz, J., Eds.; ACM: New York, NY, USA, 2019; pp. 2267–2281. [Google Scholar] [CrossRef]
- Tu, J.; Ren, M.; Manivasagam, S.; Liang, M.; Yang, B.; Du, R.; Cheng, F.; Urtasun, R. Physically Realizable Adversarial Examples for LiDAR Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; Computer Vision Foundation/IEEE: Piscataway, NJ, USA, 2020; pp. 13713–13722. [Google Scholar] [CrossRef]
- Cai, M.; Wang, X.; Sohel, F.; Lei, H. Contextual Attribution Maps-Guided Transferable Adversarial Attack for 3D Object Detection. Remote Sens. 2024, 16, 4409. [Google Scholar] [CrossRef]
- Cai, M.; Wang, X.; Sohel, F.; Lei, H. Universal Adversarial Attack for Trustworthy LiDAR based Object Detection in Embedded Applications. In Proceedings of the 4th International Conference on Intelligent Technology and Embedded Systems, Chengdu, China, 20–23 September 2024; pp. 7–14. [Google Scholar] [CrossRef]
- Hahner, M.; Sakaridis, C.; Bijelic, M.; Heide, F.; Yu, F.; Dai, D.; Gool, L.V. LiDAR Snowfall Simulation for Robust 3D Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 16343–16353. [Google Scholar] [CrossRef]
- Hahner, M.; Sakaridis, C.; Dai, D.; Gool, L.V. Fog Simulation on Real LiDAR Point Clouds for 3D Object Detection in Adverse Weather. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 15263–15272. [Google Scholar] [CrossRef]
- Kilic, V.; Hegde, D.; Sindagi, V.; Cooper, A.B.; Foster, M.A.; Patel, V.M. Lidar Light Scattering Augmentation (LISA): Physics-based Simulation of Adverse Weather Conditions for 3D Object Detection. arXiv 2021, arXiv:2107.07004. [Google Scholar]
- Dong, Y.; Kang, C.; Zhang, J.; Zhu, Z.; Wang, Y.; Yang, X.; Su, H.; Wei, X.; Zhu, J. Benchmarking Robustness of 3D Object Detection to Common Corruptions in Autonomous Driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1022–1032. [Google Scholar] [CrossRef]
- Lehner, A.; Gasperini, S.; Marcos-Ramiro, A.; Schmidt, M.; Mahani, M.A.N.; Navab, N.; Busam, B.; Tombari, F. 3D-VField: Adversarial Augmentation of Point Clouds for Domain Generalization in 3D Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 17274–17283. [Google Scholar] [CrossRef]
- Kaltsa, V.; Briassouli, A.; Kompatsiaris, I.; Hadjileontiadis, L.J.; Strintzis, M.G. Swarm Intelligence for Detecting Interesting Events in Crowded Environments. IEEE Trans. Image Process. 2015, 24, 2153–2166. [Google Scholar] [CrossRef]
- Masuda, M.; Hachiuma, R.; Fujii, R.; Saito, H.; Sekikawa, Y. Toward Unsupervised 3d Point Cloud Anomaly Detection Using Variational Autoencoder. In Proceedings of the IEEE International Conference on Image Processing, Anchorage, AK, USA, 19–22 September 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 3118–3122. [Google Scholar] [CrossRef]
- Bergmann, P.; Sattlegger, D. Anomaly Detection in 3D Point Clouds using Deep Geometric Descriptors. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 2612–2622. [Google Scholar] [CrossRef]
- Zhou, C.; Paffenroth, R.C. Anomaly Detection with Robust Deep Autoencoders. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; ACM: New York, NY, USA, 2017; pp. 665–674. [Google Scholar] [CrossRef]
- Slavic, G.; Alemaw, A.S.; Marcenaro, L.; Gómez, D.M.; Regazzoni, C.S. A Kalman Variational Autoencoder Model Assisted by Odometric Clustering for Video Frame Prediction and Anomaly Detection. IEEE Trans. Image Process. 2023, 32, 415–429. [Google Scholar] [CrossRef] [PubMed]
- Weston, J.; Chopra, S.; Bordes, A. Memory Networks. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; Bengio, Y., LeCun, Y., Eds.; ACM Digital Library: New York, NY, USA, 2015. [Google Scholar]
- Miller, A.H.; Fisch, A.; Dodge, J.; Karimi, A.H.; Bordes, A.; Weston, J. Key-Value Memory Networks for Directly Reading Documents. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–4 November 2016; Su, J., Carreras, X., Duh, K., Eds.; The Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 1400–1409. [Google Scholar] [CrossRef]
- Gong, D.; Liu, L.; Le, V.; Saha, B.; Mansour, M.R.; Venkatesh, S.; Hengel, A.v.d. Memorizing Normality to Detect Anomaly: Memory-Augmented Deep Autoencoder for Unsupervised Anomaly Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1705–1714. [Google Scholar] [CrossRef]
- Park, H.; Noh, J.; Ham, B. Learning Memory-Guided Normality for Anomaly Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; Computer Vision Foundation/IEEE: Piscataway, NJ, USA, 2020; pp. 14360–14369. [Google Scholar] [CrossRef]
- Wu, Y.; Zeng, K.; Li, Z.; Peng, Z.; Chen, X.; Hu, R. Learning a multi-cluster memory prototype for unsupervised video anomaly detection. Inf. Sci. 2025, 686, 121385. [Google Scholar] [CrossRef]
- Guo, C.; Wang, H.; Xia, Y.; Feng, G. Learning Appearance-Motion Synergy via Memory-Guided Event Prediction for Video Anomaly Detection. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 1519–1531. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A Multimodal Dataset for Autonomous Driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; Computer Vision Foundation/IEEE: Piscataway, NJ, USA, 2020; pp. 11618–11628. [Google Scholar] [CrossRef]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. Scalability in Perception for Autonomous Driving: Waymo Open Dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; Computer Vision Foundation/IEEE: Piscataway, NJ, USA, 2020; pp. 2443–2451. [Google Scholar] [CrossRef]
- Contributors, M. MMDetection3D: OpenMMLab Next-Generation Platform for General 3D Object Detection. 2020. Available online: https://github.com/open-mmlab/mmdetection3d (accessed on 26 October 2024).

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).