1. Introduction
The rapid advancement of virtual reality (VR) and augmented reality (AR) technologies is accelerating the rise of the metaverse, creating new digital spaces that offer immersive experiences and realistic interactions for users [
1,
2]. These immersive experiences enable personalized services based on user data but also raise significant concerns regarding the security and privacy of the vast amounts of user data being collected [
3]. Therefore, developing reliable authentication mechanisms for immersive platforms such as the metaverse has become an essential task.
Currently, VR and AR platforms primarily rely on traditional authentication methods such as personal identification numbers (PINs) or passwords [
4]. However, these methods are not well suited to immersive environments and may detract from the user experience. Furthermore, in environments that require continuous authentication, existing methods reveal significant security vulnerabilities [
5]. This highlights the urgent need for new authentication technologies that balance immersion with security.
One promising technology to address this challenge is periocular biometric authentication. This technology leverages unique biometric features around the eye, such as the iris, eyelids, and eyelashes, to identify users. It shows significant potential, especially for providing continuous and reliable authentication even while wearing a VR headset [
6,
7]. However, implementing this technology effectively in VR environments requires addressing several noise-related challenges.
One major noise issue in VR environments is flicker noise. This noise arises from brightness fluctuations caused by alternating current (AC)-powered lighting, producing banding artifacts in images captured by rolling-shutter cameras [
8]. Flicker noise hinders the accurate extraction of iris and surrounding biometric features due to continuous brightness variations. Existing synchronization technologies and filtering algorithms aimed at mitigating this problem face challenges related to high technical complexity and cost, making practical application difficult [
9,
10]. Another significant obstacle is infrared (IR) reflection noise. IR reflections generated by VR headsets cause strong light reflections on the iris surface, distorting image details and introducing significant noise during model training. Furthermore, reflection patterns change dynamically with gaze shifts, negatively affecting the generalization performance of the model and the accuracy of authentication.
This study proposes a periocular biometric authentication method optimized for VR environments by utilizing the AffectiVR dataset [
11], which contains images affected by flicker noise and IR reflection noise. Designed to overcome the limitations of existing authentication systems, this study specifically addresses major noise challenges in VR scenarios. The proposed process effectively removes IR reflections from the iris area, providing stable training data. Furthermore, the proposed model accurately captures detailed biometric features of the iris and surrounding tissues, enhancing the reliability of biometric authentication models. Despite realistic constraints such as flicker and reflection noise in immersive VR environments, the proposed process delivers highly reliable biometric authentication. This advancement significantly contributes to improving user experiences and strengthening security levels in next-generation digital platforms such as the metaverse. The key contributions of this study are as follows. First, the model’s performance is enhanced by removing IR illumination reflections. Second, the model’s reliability is ensured by mitigating the impact of flicker noise.
This manuscript is organized as follows:
Section 2 reviews related works, highlighting previous studies on periocular biometrics and their limitations.
Section 3 presents the proposed method, including dataset preprocessing, model architecture, and training procedures.
Section 4 discusses experimental results and comparative analysis with baseline models. Finally,
Section 5 and
Section 6 conclude the study with implications and future directions.
2. Related Works
2.1. Biometric Authentication Using Head-Mounted Display
Sivasamy et al. [
12] proposed a novel system called VRCAuth for continuous user authentication in VR environments. To address the limitations of password or PIN-based initial authentication, which struggles to continuously verify user identity during VR usage, VRCAuth analyzes user head movements using VR headset sensors to provide seamless continuous authentication. The system leverages various machine-learning algorithms to identify users without disrupting their activities. However, since it relies solely on head movements, distinguishing attackers with similar patterns from legitimate user behavior may be challenging. Additionally, while the system achieves high accuracy with multiple classifiers, its training and updating processes may pose inefficiencies when handling real-time scenarios or large-scale datasets.
Bhalla et al. [
13] explored user authentication using IMU (Inertial Measurement Unit) data collected from AR head-mounted displays and proposed a novel authentication system leveraging holographic headset sensor data as an auxiliary continuous behavioral biometric. A user study using Microsoft HoloLens collected unique motion samples, including head movements and hand gestures, from participants within an AR environment. The findings indicate that IMU data from head-mounted displays can effectively profile and authenticate users, demonstrating the potential for continuous authentication based on user interactions in AR environments. However, the study’s sample size was limited to five subjects, posing challenges in generalizing findings to real-world applications.
Lohr et al. [
14] employed the DenseNet architecture for end-to-end Eye Movement Biometrics (EMB) as a novel method for user authentication in VR and AR devices. Their study achieved an EER of 3.66% using 5 s of registration and authentication. However, since the method relies on high-quality eye movement data, the eye-tracking sensors in VR/AR devices may not match the signal quality of the data used in their research.
2.2. Biometric Authentication Using Periocular Images
Kumari et al. [
15] proposed a novel periocular biometrics system for robust authentication in scenarios impacted by the COVID-19 pandemic. Addressing the limitations of contact-based biometrics like fingerprint systems or face biometrics affected by mask-wearing, the proposed method focuses on the periocular region as it remains visible and provides sufficient discriminative information. The system combines handcrafted features (e.g., HOG), non-handcrafted features from pretrained CNN models, and semantic information, such as gender, extracted through a custom CNN model. A feature fusion approach ensures robust performance across varied conditions, including eyeglasses, masked eye regions, and pose variations. Despite achieving high accuracy with feature fusion and multiclass SVM classifiers, the computational complexity of combining multiple feature types may limit real-time applicability or scalability for large datasets.
Zhang et al. [
16] proposed a deep feature fusion approach for iris and periocular biometrics on mobile devices to address challenges like low-resolution images and limited computational resources. Using maxout CNNs for compact feature extraction and adaptive weights for multimodal fusion, the system optimizes joint representation, achieving high accuracy and outperforming traditional methods. They also introduced the CASIA-Iris-Mobile-V1.0 database, the largest NIR mobile iris dataset, to support further research.
Almadan et al. [
17] attempted to solve the problem that, despite the high performance of the convolutional neural network (CNN) model for periocular image-based user authentication on mobile devices, it is difficult to deploy on mobile devices with limited resources because the model requires large space and has high computational complexity due to millions of parameters and calculations. To this end, they evaluated five neural network pruning methods and compared them with the knowledge distillation method to analyze the performance of CNN model inference and user biometric authentication using periocular images on mobile devices. However, this approach was tested on periocular images collected from mobile devices, and it presents the challenge of being difficult to implement in a head-mounted display environment.
Zou et al. [
18] proposed a lightweight CNN that combines the attention mechanism and intermediate features, considering that although deep learning-based periocular biometric algorithms have made great progress, it is necessary to improve network performance with fewer parameters in practical applications. Experimental results using three public datasets and one self-collected periocular dataset demonstrate the effectiveness of the proposed network. However, it shares the disadvantage of being difficult to apply in a head-mounted display-wearing environment, as in the previous study.
Lohith et al. [
19] proposed a multimodal biometric method using multiple biometric information to solve the problem that single-modal biometrics may deteriorate performance due to limitations such as intra-class variation and non-universality because it identifies users using one biometric information. In the paper, multimodality biometric authentication is proposed through feature-level fusion using biometric information from the face, ear, and periocular regions, and CNN is applied for feature representation. However, this approach necessitates additional inputs beyond the periocular region, which may limit its applicability.
3. Proposed Method
Figure 1 illustrates the periocular image-based biometric authentication system proposed in this study. The proposed method can be broadly divided into four processes, with the second process further comprising four subprocesses. Detailed explanations for each step are provided in the following. We used PyTorch and OpenCV libraries in our experiments, versions 2.5.3 and 4.2.0.34 respectively.
3.1. Dataset
In this study, the AffectiVR dataset [
11] was used. This dataset contains data collected from 100 participants, and images around the eyes were recorded in a VR environment using the HTC Vive Pro and the ‘HTC Vive Binocular Add-on’. During the dataset collection process, 360-degree videos were selected based on the study of [
20], and 7 videos were selected considering changes in pupil size and eye movements of the participants. The videos included various lighting conditions, such as natural light, indoor lighting, and dark indoor environments, and reflected both static and dynamic viewpoints.
Each video played for approximately 90 s, and participants were able to freely control their movements and gaze directions. After watching the videos, a 3-min break was provided to relieve fatigue caused by VR exposure. The data were recorded as a monocular video of each eye at 30 frames per second, 1920 × 1080 resolution, providing high-resolution data suitable for analyzing individual features such as skin texture around the eyes, eyelid shape, and eyelashes. This dataset contains a total of 5,199,175 frames of video data.
3.2. Data Preprocessing
Due to individual differences in the shape of the left and right eyes, this study utilized only the right eye’s images. This approach was taken to maintain consistency in analysis and minimize variables that could arise from differences in the shape of both eyes. Additionally, frames unsuitable for biometric authentication, such as those depicting blinking, were excluded from the dataset acquired in this experiment. To remove frames where the eyes were closed, the following method was used: first, the pupil was extracted, and frames where the pupil was not captured, where the pupil’s center suddenly moved significantly, or where the pupil’s radius abruptly changed, were classified as frames with closed eyes. This process filtered out frames where the pupil was not clearly visible or displayed abnormal movement. Furthermore, in cases where the eyes were partially closed, it was likely that the frame was captured either during the act of opening or closing the eyes; thus, an additional eight frames surrounding the closed-eye frame were also removed. Through this method, we ensured that only images of open eyes were obtained. As a result, we secured periocular images exclusively in the open-eye state through a rigorous data filtering process, enhancing the reliability of the study and enabling accurate biometric authentication.
Additionally, reflections in the iris area typically have significantly higher brightness values compared to the surrounding regions, and this can act as noise during model training. To mitigate the impact of reflection noise, this study employed a method to remove reflections present in the iris. While eliminating reflections in the iris region can be problematic in iris authentication systems that directly rely on iris texture, we determined that this would not impact performance in our study, as we utilized periocular features in addition to the iris. The process of reflection removal proceeded as follows: the coordinates of the pupil center detected earlier were used to eliminate reflections. Since the size of the human iris does not exhibit significant variation between individuals, a circular region of interest (ROI) with a radius of 75 pixels was established around the detected pupil center. This ROI encompassed the iris area and served as the region for reflection detection. To detect reflections within this iris ROI, OpenCV was utilized, which identified the location and size of bright spots representing reflections. In this process, OpenCV’s SimpleBlobDetector class was utilized and the minThreshold parameter was set to 190 to detect light reflection pixels. Once reflections were detected, the pixel values of a neighboring 7 × 7 region were analyzed to calculate the median value. The median value was used because it is less affected by outliers, allowing for more accurate interpolation. The calculated median value was then applied to the pixels containing reflections, effectively removing them. Through this interpolation process, a clean iris image with removed reflections was obtained.
Figure 2 presents a comparison of images before and after reflection removal. In the image before reflection removal, noticeable reflections are present in the iris area; however, in the image after reflection removal, the reflections with higher values than the surrounding pixels are eliminated, resulting in a cleaner iris image. This can enhance the model’s performance.
3.3. Model
To train the biometric authentication model, images were extracted from a dataset specifically constructed through experiments. To ensure an equal number of images per subject, 15 images were randomly selected from each subject’s data for training. Ultimately, 105 images were compiled for each subject, resulting in a total of 10,500 training samples for 100 subjects, which were then used to train the model. To account for the variability in device positioning when wearing a VR headset, random horizontal translation and brightness adjustment were applied to the images during model training. Furthermore, recognizing that there are more impostor pairs than genuine pairs in real biometric authentication scenarios, the proportion of impostor pairs increased within the 10,500 training samples to create a robust comparison that closely mirrors actual conditions.
The base model structure utilized was a Siamese network-based deep learning model, as proposed in Hwang et al. [
21]. The Siamese network is a deep learning model structure designed to learn the relationship between feature vectors of two images extracted from a convolutional neural network (CNN) model with shared weights. The goal is to minimize the distance between feature vectors for positive pair images while maximizing the distance for negative pairs. The Siamese network model structure is illustrated in
Figure 3, while the feature extraction model structure is depicted in
Figure 4.
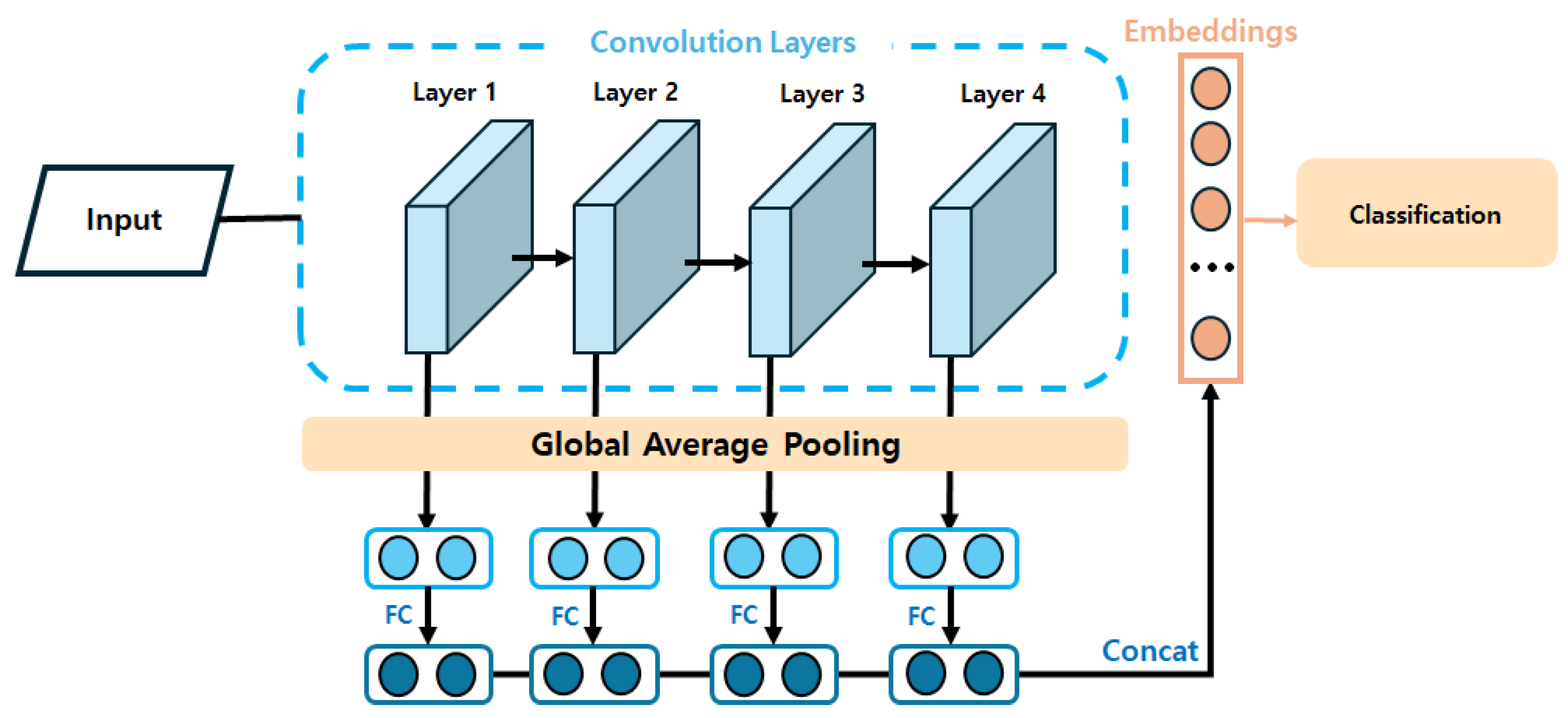
In a CNN used for image feature extraction, shallow layers capture low-level features, while deeper layers extract high-level features. Typically, CNNs have multiple stacked layers, with the final output feature vector being utilized for further processing. However, Hwang et al. [
21] suggested that useful features for biometric authentication based on eye images can also exist in the intermediate layers of CNN-based models. Thus, they designed the model to also utilize features extracted from the intermediate layers of the deep learning model. To achieve this, global average pooling is applied to the feature maps extracted from each layer to convert them into 1-dimensional vectors. These converted vectors are then connected to a fully connected layer to generate a unified 1-dimensional vector. As a result, one feature vector is generated for each convolutional layer, and the final feature vector is produced by merging them. These two feature vectors are then used to compare the two images, therefore performing biometric authentication based on the periocular image.
The model employed in this experiment was based on the Deep-ResNet18 architecture introduced by Hwang et al. [
21]. Additionally, the periocular images used as inputs for the model were downsampled from the original resolution of 1920 × 1080 to a lower resolution of 320 × 240. The detailed structure of the model used in this experiment is summarized in
Table 1.
The dataset used for training the deep learning model contained noise manifested as thick horizontal lines in the images, as shown in
Figure 5. This type of noise can be misinterpreted as a feature during model training. To mitigate this issue, we incorporated a Squeeze-and-Excitation (SE) block after the Residual block in our model. The SE block, commonly used in computer vision research to enhance image authentication performance, models the interdependence between channels to highlight significant features and suppress less relevant ones. It is a simple module that integrates seamlessly into various convolutional neural network (CNN) architectures and adds minimal additional parameters, therefore improving performance without substantially increasing model complexity. The Residual block structure with the SE block is illustrated in
Figure 6.
For comparative performance evaluation, we modified the feature extraction model and conducted training under identical conditions. We selected two comparison models, MobileViT [
22], and ResNet34 [
23], to ensure a fair evaluation, particularly considering the need for continuous biometric authentication in practical environments. Models with excessive parameters were excluded from comparison to avoid undue complexity.
Training was performed using the Adam optimizer, known for its effectiveness, with binary cross-entropy as the loss function. To identify the best-performing model, we saved the model parameters corresponding to the lowest validation loss. The batch size was set to 16, and training was conducted for 10 epochs. To prevent overfitting, we employed early stopping, halting training if validation loss did not improve over 5 consecutive epochs. Performance evaluation involved splitting the dataset into training and testing sets at an 8:2 ratio and performing 5-fold cross-validation. The final performance metrics were calculated as the average across the five folds. The experiments were performed using Python 3.8.17 and CUDA 11.6, with TensorFlow 2.7.0 as the learning framework.
4. Results
4.1. Comparison of Results Before and After Reflective Noise Suppression
First, to compare the performance before and after reflection removal, the model was trained and evaluated with and without removing reflected light.
Table 2 presents the biometric authentication performance based on whether reflection removal was applied. In biometric authentication, it is crucial to maintain a low False Acceptance Rate (FAR), which relates to the risk of incorrectly recognizing an impostor as a legitimate user. Therefore, we compared the False Rejection Rate (FRR) when the FAR was less than 1%. In this study, heatmap analysis was conducted to investigate the prediction results of the biometric authentication model. This technique visualizes the significant regions in the model’s output and has been widely used in recent computer vision-based studies, such as object detection and image classification. Many of these studies have employed the gradient-weighted class activation mapping (Grad-CAM) method [
24]. Grad-CAM evaluates the gradient of each pixel concerning the model’s output, reflecting the degree of influence each pixel has on the final result. Pixels that are more influential are represented in red on the heatmap, indicating their importance.
Figure 7 illustrates the results of a heatmap analysis conducted to assess the impact of reflection removal on model performance. As seen in
Figure 7, the influence of specular light pixels is significant in images that have not undergone reflection removal. This suggests that specular light features are heavily relied upon during the biometric authentication process. However, in the images where reflection removal was applied, it is evident that the model focuses more on features related to the shape of the eyes and the surrounding skin rather than on specular light. Thus, it can be concluded that the model was trained to prioritize specific periocular features over specular light using the images applied to reflection removal.
Figure 8 and
Figure 9 display the Genuine–Impostor distribution and the receiver operating characteristic (ROC) curve, respectively, for the model when evaluated with the AffectiVR dataset used in this study. The x-axis of
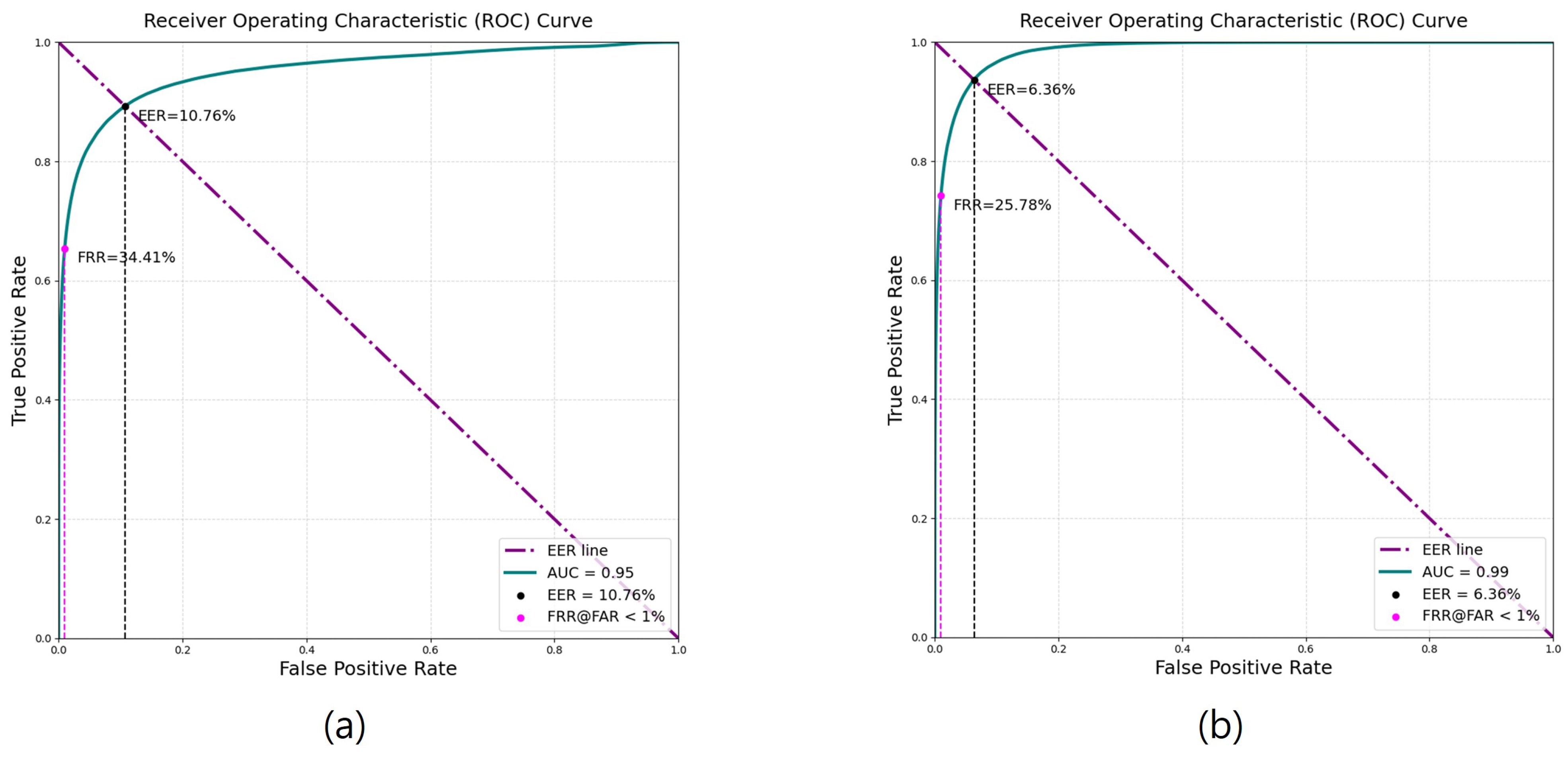
Figure 8 represents the distance between the feature vectors of the two images input into the model. Typically, the Genuine–Impostor distribution forms two Gaussian curves with some separation, and the less overlap there is between these distributions, the better the biometric authentication performance. According to the performance evaluation, training the model with the data after reflection removal led to improvements in both the Equal Error Rate (EER) and the False Rejection Rate (FRR) when the False Acceptance Rate (FAR) was less than 1%.
4.2. Comparison of Results Before and After Using SE Block
In order to compare the performance before and after utilizing the SE block structure, models before and after introducing the SE block structure were trained.
Table 3 shows the biometric authentication performance depending on whether the SENet structure was reflected.
Figure 10 shows the Genuine–Impostor distribution and ROC curve of the model predicted using the AffectiVR dataset in this study as input, and
Figure 11 shows the Genuine—Impostor distribution and ROC curve of the model trained by integrating the SENet structure into the model. The
x-axis in
Figure 10b is the distance between the feature vectors of two images used as inputs of the model. According to the performance measurement results, when the model was trained using the data after introducing the SENet structure, it was confirmed that the performance slightly decreased in both measures of EER and FRR.
Through
Figure 12, we can see that the preprocessed image mainly utilizes the features around the eyes related to the skin around the eyes and the shape of the eyes instead of the power noise. Therefore, we can conclude that by incorporating the SENet structure into the model, the performance decreased, but the model was trained to emphasize the specific features around the eyes rather than the power noise.
4.3. Additional Model Training and Performance Comparison
In this study, to compare models suitable for the dataset environment, two additional models were trained by changing only the feature extraction network while maintaining the same environment. This experiment aimed to compare the performance of a deeper model within the same architecture and the performance of a model incorporating an attention mechanism. To this end, ResNet34 [
23] and MobileViT [
22] were additionally trained.
The choice of MobileViT over vanilla ViT was driven by the requirement for real-time performance in user biometric authentication systems, particularly in head-mounted display (HMD) environments. MobileViT offers a more lightweight structure, which is crucial for maintaining real-time processing capabilities while achieving high accuracy. The performance evaluation of each model is presented in
Table 4.
5. Discussion
In this study, when comparing the performance before and after integrating the SENet structure, the EER of the model slightly decreased from 5.52% to 6.39% and the FRR (FAR < 1%) slightly decreased from 19.28% to 24.52% after introducing the SENet structure. In a performance comparison with the ResNet34 model and the MobileViT model, the ResNet34 model achieved the best performance with an EER of 5.61% and an FRR of 18.44%, while the MobileViT model had the poorest performance with an EER of 9.74% and an FRR of 30.33%. These results show that the performance of the Deep-SE-ResNet model slightly decreased after the introduction of the SE block, but the heatmap analysis results show that the model with the SE block introduced learns only specific and meaningful periocular features better. This indicates that the model has shifted towards more effectively suppressing abnormal features such as power noise and more clearly extracting periocular features, which are crucial for biometric authentication. Power noise was recognized as a major feature in the previous model, but with the introduction of the SE block, these abnormal features were suppressed, and instead, specific features such as the skin around the eyes and the shape of the eyes were highlighted as major features. Our study used periocular images that are not front-facing like those used in prior research, and they contain power noise. Considering that the SE block suppresses noise and emphasizes crucial features, we expect that performance could be further improved if noise-free data were utilized. In particular, the SE block models the interdependence between channels to emphasize important features and suppress less important features, so the model was trained in a direction that enables more reliable biometric authentication. Based on these results, the model that introduced the SE block is significant in that the model was changed to extract only the features of the meaningful part of the data.
Therefore, despite a slight decrease in performance, the introduction of the SE block contributed to extracting more reliable features for biometric authentication by suppressing abnormal features such as power noise and emphasizing periocular-specific features. This suggests an important direction for future research on user biometric authentication in VR environments, and it is expected that the dataset and model of this study will play an important role in increasing the applicability in real-world environments.
These findings underscore the unique advantage of using SE blocks and reflective noise suppression in environments where maintaining specific feature fidelity is critical. By actively down-weighting noise-prone areas and highlighting periocular features, this approach enables the model to be more resilient to variations that can compromise authentication accuracy. Such robustness is crucial for VR environments, where environmental noise and lighting inconsistencies are common. Thus, our method lays the groundwork for creating authentication systems that are both adaptive and precise in real-time applications.
In addition, as a result of experiments using multiple models, the Deep-SE-ResNet18 model showed the most effective performance relative to the number of model parameters. This suggests that the Deep-SE-ResNet18 model can achieve high performance even with relatively few parameters, considering the relationship between the dataset size and the number of model parameters. These results emphasize the necessity and practicality of lightweight models in biometric authentication research in virtual reality environments and show that they can increase the applicability in environments that require real-time performance.
6. Conclusions
In this study, we utilized the AffectiVR dataset for user authentication in a virtual reality head-mounted display environment and presented a biometric authentication model using it. We utilized the AffectiVR dataset, which was acquired from virtual reality devices and is therefore suitable for real environments. This dataset is essential for user authentication research in a virtual reality environment and can also contribute to improving biometric authentication performance with high-resolution images. Additionally, we removed reflected light from the iris, which can act as noise, to enhance the model’s ability to learn features around the eyes. Through this preprocessing, we improved the performance from the existing 6.73% to 5.52% EER.
The dataset used in this study contained noise in the form of horizontal lines. Upon analyzing the heatmap of the existing model, we observed that the heatmap was centered around this noise. To reduce the impact of this noise, we introduced the SE block structure, resulting in a slightly higher EER of 6.39%. However, further heatmap analysis revealed that the model with the SE block focused on biometric features around the eyes rather than the noise. This study also compared various models and presented a benchmark that will be valuable for future research.
Given the limited research on periocular biometrics in virtual reality environments, this study offers several significant advantages. First, it provides an opportunity to develop and verify a more realistic biometric authentication model using data collected in an actual virtual reality device usage environment. Second, this study successfully trained a model that is robust to power noise, which can occur in a VR environment, using the SE block structure. This can serve as an important reference for developing models that consider similar environments in future studies. Finally, by comparing various models and presenting a benchmark, this study makes an academic contribution that researchers can use to develop more effective biometric authentication systems in the future. Finally, by comparing various models and presenting a benchmark, this study makes an academic contribution that researchers can use to develop more effective biometric authentication systems in the future.
In future studies, we will optimize machine-learning algorithms to enable faster and more accurate real-time authentication. Moreover, we anticipate that extracting the iris from the image and combining it with periocular biometrics to perform multi-biometric authentication will yield even better performance. Iris authentication technology, known for its high accuracy and security, combined with existing eye image-based authentication, could establish a dual security system, ensuring high reliability even in a virtual reality environment. We expect that this multi-biometric authentication system will further strengthen security by analyzing various biometric characteristics such as the user’s eye blinking and gaze movements.
In addition, incorporating SE blocks into the model demonstrated robustness to noise in Grad-CAM qualitative evaluations. This indicates the potential to develop models less influenced by noise, addressing one of the major challenges in learning with the AffectiVR dataset. In other words, this suggests that the model could demonstrate strong generalization capabilities when applied to other datasets without the noise present in the AffectiVR dataset. Therefore, future research will focus on improving performance by integrating SE blocks and conducting evaluations on data collected from various head-mounted devices.
Author Contributions
Conceptualization, E.C.L.; Data curation, C.S.; Formal analysis, J.B. and C.S.; Investigation, Y.P., J.B. and C.S.; Methodology, J.B. and Y.P.; Project administration, E.C.L.; Resources, C.S., Y.P. and J.B.; Software, Y.P. and J.B.; Supervision, E.C.L.; Validation, J.B. and Y.P.; Visualization, C.S.; Writing—original draft, J.B. and Y.P.; Writing—review and editing, E.C.L., Y.P. and J.B. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by a 2024 Research Grant from Sangmyung University (2024-A000-0086).
Institutional Review Board Statement
Based on Article 13-1-1 and 13-1-2 of the Enforcement Regulations of the Act on Bioethics and Safety of the Republic of Korea, ethical review and approval were waived (IRB-SMU-C-2023-1-007) for this study by Sangmyung University’s Institutional Review Board because this study uses only simple contact-measuring equipment or observation equipment that does not involve physical changes and does not include invasive procedures such as drug administration or blood sampling.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study. Written informed consent has been obtained from the subjects to publish this paper.
Data Availability Statement
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Wang, Y.; Su, Z.; Zhang, N.; Xing, R.; Liu, D.; Luan, T.H.; Shen, X. A survey on metaverse: Fundamentals, security, and privacy. IEEE Commun. Surv. Tutor. 2022, 25, 319–352. [Google Scholar] [CrossRef]
- Mystakidis, S. Metaverse. Encyclopedia 2022, 2, 486–497. [Google Scholar] [CrossRef]
- Zhao, R.; Zhang, Y.; Zhu, Y.; Lan, R.; Hua, Z. Metaverse: Security and privacy concerns. J. Metaverse 2023, 3, 93–99. [Google Scholar] [CrossRef]
- George, C.; Khamis, M.; von Zezschwitz, E.; Burger, M.; Schmidt, H.; Alt, F.; Hussmann, H. Seamless and Secure vr: Adapting and Evaluating Established Authentication Systems for Virtual Reality; NDSS: San Diego, CA, USA, 2017. [Google Scholar]
- Boutros, F.; Damer, N.; Raja, K.; Ramachandra, R.; Kirchbuchner, F.; Kuijper, A. Fusing iris and periocular region for user verification in head mounted displays. In Proceedings of the 2020 IEEE 23rd International Conference on Information Fusion (FUSION), Rustenburg, South Africa, 6–9 July 2020; pp. 1–8. [Google Scholar]
- Kumari, P.; Seeja, K. Periocular biometrics: A survey. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 1086–1097. [Google Scholar] [CrossRef]
- Alonso-Fernandez, F.; Bigun, J.; Fierrez, J.; Damer, N.; Proença, H.; Ross, A. Periocular biometrics: A modality for unconstrained scenarios. Computer 2024, 57, 40–49. [Google Scholar] [CrossRef]
- Lin, X.; Li, Y.; Zhu, J.; Zeng, H. DeflickerCycleGAN: Learning to detect and remove flickers in a single image. IEEE Trans. Image Process. 2023, 32, 709–720. [Google Scholar] [CrossRef] [PubMed]
- Nadernejad, E.; Mantel, C.; Burini, N.; Forchhammer, S. Flicker reduction in LED-LCDs with local backlight. In Proceedings of the 2013 IEEE 15th International Workshop on Multimedia Signal Processing (MMSP), Pula, Sardinia, Italy, 30 September–2 October 2013; pp. 312–316. [Google Scholar]
- Castro, I.; Vazquez, A.; Arias, M.; Lamar, D.G.; Hernando, M.M.; Sebastian, J. A review on flicker-free AC–DC LED drivers for single-phase and three-phase AC power grids. IEEE Trans. Power Electron. 2019, 34, 10035–10057. [Google Scholar] [CrossRef]
- Seok, C.; Park, Y.; Baek, J.; Lim, H.; Roh, J.h.; Kim, Y.; Kim, S.; Lee, E.C. AffectiVR: A Database for Periocular Identification and Valence and Arousal Evaluation in Virtual Reality. Electronics 2024, 13, 4112. [Google Scholar] [CrossRef]
- Sivasamy, M.; Sastry, V.; Gopalan, N. VRCAuth: Continuous authentication of users in virtual reality environment using head-movement. In Proceedings of the 2020 5th International Conference on Communication and Electronics Systems (icces), Coimbatore, India, 10–12 June 2020; pp. 518–523. [Google Scholar]
- Bhalla, A.; Sluganovic, I.; Krawiecka, K.; Martinovic, I. MoveAR: Continuous biometric authentication for augmented reality headsets. In Proceedings of the 7th acm on Cyber-Physical System Security Workshop, Virtual, 7 June 2021; pp. 41–52. [Google Scholar]
- Lohr, D.; Komogortsev, O.V. Eye know you too: Toward viable end-to-end eye movement biometrics for user authentication. IEEE Trans. Inf. Forensics Secur. 2022, 17, 3151–3164. [Google Scholar] [CrossRef]
- Kumari, P.; Seeja, K.R. A novel periocular biometrics solution for authentication during COVID-19 pandemic situation. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 10321–10337. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Q.; Li, H.; Sun, Z.; Tan, T. Deep feature fusion for iris and periocular biometrics on mobile devices. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2897–2912. [Google Scholar] [CrossRef]
- Almadan, A.; Rattani, A. Compact cnn models for on-device ocular-based user recognition in mobile devices. In Proceedings of the 2021 IEEE Symposium Series on Computational Intelligence (SSCI), Virtual, 5–7 December 2021; pp. 1–7. [Google Scholar]
- Zou, Q.; Wang, C.; Yang, S.; Chen, B. A compact periocular recognition system based on deep learning framework AttenMidNet with the attention mechanism. Multimed. Tools Appl. 2023, 82, 15837–15857. [Google Scholar] [CrossRef]
- Lohith, M.; Manjunath, Y.S.K.; Eshwarappa, M. Multimodal biometric person authentication using face, ear and periocular region based on convolution neural networks. Int. J. Image Graph. 2023, 23, 2350019. [Google Scholar] [CrossRef]
- Li, B.J.; Bailenson, J.N.; Pines, A.; Greenleaf, W.J.; Williams, L.M. A public database of immersive VR videos with corresponding ratings of arousal, valence, and correlations between head movements and self report measures. Front. Psychol. 2017, 8, 2116. [Google Scholar] [CrossRef]
- Hwang, H.; Lee, E.C. Near-infrared image-based periocular biometric method using convolutional neural network. IEEE Access 2020, 8, 158612–158621. [Google Scholar] [CrossRef]
- Mehta, S.; Rastegari, M. Mobilevit: Light-weight, general-purpose, and mobile-friendly vision transformer. arXiv 2021, arXiv:2110.02178. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
Figure 1.
The periocular image-based biometric authentication system proposed in the study.
Figure 1.
The periocular image-based biometric authentication system proposed in the study.
Figure 2.
Example of removing reflective light (a): before removing reflective light, (b) after removing reflective light.
Figure 2.
Example of removing reflective light (a): before removing reflective light, (b) after removing reflective light.
Figure 3.
Siamese network architecture used for training.
Figure 3.
Siamese network architecture used for training.
Figure 4.
Structure of the feature extraction model proposed in the study by Hwang et al. [
21].
Figure 4.
Structure of the feature extraction model proposed in the study by Hwang et al. [
21].
Figure 5.
Noise observed in image data over time.
Figure 5.
Noise observed in image data over time.
Figure 6.
Residual block structure with SE block.
Figure 6.
Residual block structure with SE block.
Figure 7.
Heatmap images according to reflection removal; (a) before reflection removal, (b) after reflection removal. Red on the heatmap indicates a higher value, while blue indicates a lower value.
Figure 7.
Heatmap images according to reflection removal; (a) before reflection removal, (b) after reflection removal. Red on the heatmap indicates a higher value, while blue indicates a lower value.
Figure 8.
Comparison of Genuine—Impostor distribution graphs according to reflection removal; (a) before reflection removal, (b) after reflection removal.
Figure 8.
Comparison of Genuine—Impostor distribution graphs according to reflection removal; (a) before reflection removal, (b) after reflection removal.
Figure 9.
Comparison of ROC curves according to reflection removal; (a) before reflection removal, (b) after reflection removal.
Figure 9.
Comparison of ROC curves according to reflection removal; (a) before reflection removal, (b) after reflection removal.
Figure 10.
Biometric authentication performance results before reflecting SENet structure. (a) ROC curve, (b) Genuine—Impostor distribution.
Figure 10.
Biometric authentication performance results before reflecting SENet structure. (a) ROC curve, (b) Genuine—Impostor distribution.
Figure 11.
Biometric authentication performance results after reflecting SENet structure. (a) ROC curve, (b) Genuine—Impostor distribution.
Figure 11.
Biometric authentication performance results after reflecting SENet structure. (a) ROC curve, (b) Genuine—Impostor distribution.
Figure 12.
Heatmap images according to whether the SENet structure is integrated or not. (a) Image before integration, (b) image after integration. Red on the heatmap indicates a higher value, while blue indicates a lower value.
Figure 12.
Heatmap images according to whether the SENet structure is integrated or not. (a) Image before integration, (b) image after integration. Red on the heatmap indicates a higher value, while blue indicates a lower value.
Table 1.
Structure of the Deep-ResNet18 periocular image-based biometric authentication model proposed in the study by Hwang et al. [
21].
Table 1.
Structure of the Deep-ResNet18 periocular image-based biometric authentication model proposed in the study by Hwang et al. [
21].
| Block | #Layer | Structure | #Channel |
|---|
| Block 1 | 1 | Conv(7 × 7), stride = 2 | 32 |
| 2 | Max Pooling(3 × 3), stride = 2 |
| Block 2 | 3 | Conv(3 × 3) | 32 |
| 4 | Conv(3 × 3) |
| 5 | Shortcut(2, 4) 1 |
| 6 | Conv(3 × 3) |
| 7 | Conv(3 × 3) |
| 8 | Shortcut(5, 7) 1 |
| Block 3 | 9 | Conv(3 × 3), stride = 2 | 64 |
| 10 | Conv(3 × 3) |
| 11 | Shortcut(8, 10) 1 |
| 12 | Conv(3 × 3) |
| 13 | Conv(3 × 3) |
| 14 | Shortcut(11, 13) 1 |
| Block 4 | 15 | Conv(3 × 3), stride = 2 | 128 |
| 16 | Conv(3 × 3) |
| 17 | Shortcut(14, 16) 1 |
| 18 | Conv(3 × 3) |
| 19 | Conv(3 × 3) |
| 20 | Shortcut(17, 19) 1 |
| Block 5 | 21 | Conv(3 × 3), stride = 2 | 256 |
| 22 | Conv(3 × 3) |
| 23 | Shortcut(20, 22) 1 |
| 24 | Conv(3 × 3) |
| 25 | Conv(3 × 3) |
| 26 | Shortcut(24, 25) 1 |
| Pooling | 27 | Vector(8) 2 | 32 |
| 28 | Vector(14) 2 | 64 |
| 29 | Vector(20) 2 | 128 |
| 30 | Vector(26) 2 | 256 |
| Concat | 31 | Concatenate(29, 30, 31, 32) | 480 |
Table 2.
Comparison of Biometric Authentication Performance with and without Reflection Removal.
Table 2.
Comparison of Biometric Authentication Performance with and without Reflection Removal.
| Performance (%) | Before Reflection Removal | After Reflection Removal |
|---|
| EER | 6.73 | 5.52 |
| FRR (FAR < 1%) | 23.70 | 19.28 |
Table 3.
Comparison of performance results depending on whether SENet structure is reflected or not.
Table 3.
Comparison of performance results depending on whether SENet structure is reflected or not.
| Model | EER | FRR (FAR < 1%) |
|---|
| Deep-ResNet [21] | 5.52 | 19.28 |
| Deep-SE-ResNet | 6.39 | 24.52 |
Table 4.
Comparison of biometric authentication performance according to the number of parameters of several backbone models.
Table 4.
Comparison of biometric authentication performance according to the number of parameters of several backbone models.
| Model | Parameters | EER | FRR (FAR < 1%) |
|---|
| ResNet34 [23] | 5.7 M | 5.61 | 18.44 |
| MobileViT [22] | 2.3 M | 6.39 | 30.33 |
| Deep-SE-ResNet | 3.2 M | 6.39 | 24.52 |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}