Abstract
As cybersecurity threats continue to escalate, assessing the security and credibility of critical network nodes, such as web servers, email servers, and URLs, becomes pivotal to ensure network integrity. This entails a comprehensive evaluation of the network nodes’ reputation, employing reputation scores as performance indices to instigate bespoke protective measures, thereby alleviating Internet-associated risks. This paper examines the progress in the realm of IP reputation evaluation, providing an exhaustive analysis of reputation assessment methodologies premised on statistical analysis, similarity detection, and machine learning. Further, it underlines their practical applications and effectiveness in bolstering network security. In a head-to-head comparison of the assorted methods, the paper underscores their merits and demerits relative to implementation specifics and performance. In conclusion, it outlines the evolving trends and challenges in network reputation evaluation, providing a scientific framework and valuable technical references for prompt detection and effective mitigation of latent security threats in the network milieu.
1. Introduction
In the face of escalating network security threats and increasingly sophisticated attack methods, the effective appraisal and evaluation of the security and trustworthiness of pivotal network assets, such as web servers, email servers, and URLs, become imperative. Utilizing reputation scores as evaluative standards and resorting to tailored protective measures can potentially minimize Internet-associated risks. Network reputation symbolizes the degree of trust conferred on resources and services by the stakeholders in information technology and network communication, and is derived from information related to interactions and feedback amongst the entities. It steers users towards informed trust decisions by gauging the reliability of an entity’s behavior and the veracity of associated content, thus mitigating the risks that users may potentially encounter during the utilization of online resources [1,2].
Reputation assessment systems analyze the behavioral patterns of IP addresses or network nodes, accumulating data about their activities. They establish criteria for measuring reputation, continually evaluating entities to support informed decision-making and to improve network service quality [3,4]. The field of security services has seen the emergence of several mature systems for evaluating sender reputation and identifying spam. For instance, SenderBase and Smart Network Data Services (SNDS) focus on discriminating spam based on reputation scores [5,6]. Meanwhile, systems like Talos Intelligence, Sender Score, TrustedSource, and ReputationAuthority quantify credit ratings by continuously monitoring data [7,8,9,10]. Additionally, Tencent’s Threat Intelligence Cloud Service (TICS) aggregates global threat intelligence, categorizing various online activities into a structured, labeled format for security analysis [11].
This paper reviews current mainstream reputation assessment methods, systematically analyzing their respective core advantages, limitations, and applicability in various scenarios. A multi-dimensional comparative framework encompassing core principles, data dependency, computational overhead, robustness, and scalability—is introduced to conduct a side-by-side analysis of representative studies. Finally, in light of recent technological advancements, the paper explores the future prospects and challenges of applying cutting-edge fields such as data fusion, Explainable AI (XAI), federated learning, and adversarial robustness to this domain.
The paper is organized as follows: Section 2 reviews and critiques three primary categories of reputation assessment methods. Section 3 summarizes and compares existing methods using the proposed multi-dimensional framework. Section 4 discusses future trends and challenges in the field. Lastly, Section 5 provides a conclusion to the paper.
2. Methods of Reputation Assessment
The algorithms used to assess reputation are primarily categorized into three groups: reputation evaluations founded on statistics, those built on similarity, and ones constructed on machine learning. The following sections will introduce and critically review representative works from each category.
2.1. Reputation Assessment Based on Statistical Algorithms
Statistics-based methods were among the earliest and most widely studied assessment models. These approaches typically rely on empirical or prior knowledge to quantify reputation by statistically analyzing a node’s historical behavior.
2.1.1. Representative Methods
- Feedback-Based Assessment: This class of methods directly aggregates interaction feedback from users or entities. For instance, the PeerTrust model [12] (Figure 1) calculates the reputation of nodes in a P2P network by integrating multiple weighted factors, including transaction satisfaction, transaction context, and feedback credibility. Similarly, the cloud service evaluation system STRAF [13,14] employs this concept, conducting comprehensive trust assessments by combining service feedback weight, historical feedback weight, users’ prior trust, and similarity preferences.
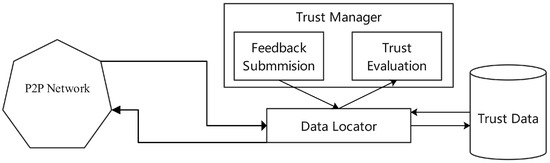 Figure 1. Architecture of PeerTrust system.
Figure 1. Architecture of PeerTrust system. - Statistics-Based Inference Assessment: This class of methods treats a node’s behavioral pattern as a random process and employs statistical inference to identify anomalies. For instance, Yang et al. [15] assess node stability by calculating a confidence interval for its historical behavior; if fluctuations exceed this interval, the node’s reputation is downgraded. Zheng et al. [16] perform an evaluation by determining whether the access volume from an IP address within a specific period surpasses a predefined threshold.
- Collaboration-Based Assessment: This class of methods builds a global reputation by exchanging information across different administrative domains. The CARE system [17] (Figure 2) allows multiple mail domains to share their historical email databases. The system then collaboratively assesses a mail sender’s reputation by assigning different weights to local data versus remote data obtained from other domains.
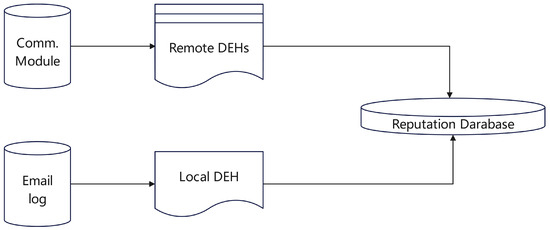 Figure 2. Architecture of CARE system.
Figure 2. Architecture of CARE system. - Assessment Based on Specific Behavior Patterns: Many studies design statistical features for specific malicious behaviors. For example, the IoTrust architecture [18] integrates Software-Defined Networking (SDN) technology, covering the object layer, node layer, SDN control layer, organization layer, and reputation management layer; a cross-layer authorization protocol verifies node behavior and status to comprehensively analyze the node’s reputation level. Tian et al. [19] (Figure 3) decompose user reputation into multiple sub-dimensions, such as security and fulfillment, and aggregate them over time based on the principle of “slow rise, fast fall.” Peng et al. [20] (Figure 4) utilize DNS CNAME records to construct an alias-canonical graph and identify malicious domains by propagating labels through the Belief Propagation algorithm. Sharifnya et al. [21] (Figure 5) screen out DNS query records with similar attributes in each time window and construct a suspicious group activity matrix and a failure matrix using statistical indicators like failure rate and query patterns; combining the data in these two matrices, they calculate a reputation score for each host. Wang et al. [22] use a Bayesian network to fuse multiple dimensions, such as file quality and download speed, for a comprehensive assessment of a file server’s reputation level.The IIM-ARE model features two modules: Behavior Classification and Reputation Consensus. The first module dynamically assesses user behavior in each interaction, while the second integrates short-term and long-term reputation through a consensus mechanism to generate an adaptive final reputation score [23].
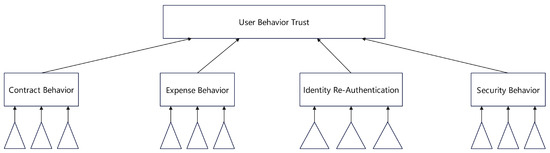 Figure 3. Hierarchical Model for User Behavior Trust Evaluation in Cloud Computing.
Figure 3. Hierarchical Model for User Behavior Trust Evaluation in Cloud Computing.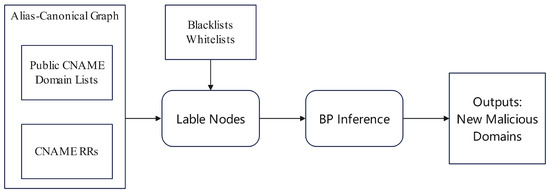 Figure 4. Workflow for the identification process of malicious domains.
Figure 4. Workflow for the identification process of malicious domains.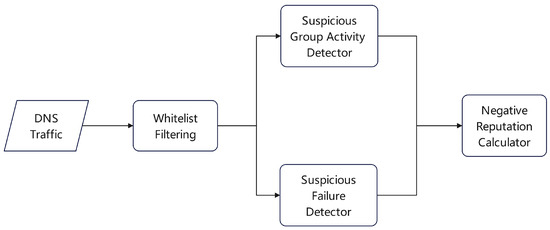 Figure 5. Schematic of the DNS-based reputation estimation system.
Figure 5. Schematic of the DNS-based reputation estimation system.
2.1.2. Discussion
Valued for their simple models and strong interpretability, statistical methods remain an effective first line of defense in many scenarios, particularly for tasks with stable behavioral patterns and well-defined features. However, their inherent limitations are significant:
- 1.
- Strong Dependence on Data Quality and Prior Knowledge: The effectiveness of most statistical models hinges on high-quality feedback or pre-defined thresholds. In practice, data is often noisy and feedback can be manipulated (e.g., through collusion or bad-mouthing). Meanwhile, static thresholds struggle to adapt to dynamic network environments, leading to inaccuracies.
- 2.
- Insufficient Robustness Against Attacks: Statistical methods often assume that most nodes are honest or that malicious behavior shows clear statistical anomalies. This makes them vulnerable to sophisticated collusion or camouflage attacks. For instance, attackers can conspire to provide false positive feedback or mimic normal user behavior to slowly accumulate reputation (a “slow-ingress attack”), thereby evading detection.
- 3.
- Limited Feature Extraction Capabilities: These methods typically rely on manually engineered, low-dimensional features. This makes it difficult to capture the complex, non-linear correlations hidden in high-dimensional data, which are often key to distinguishing advanced threats.
2.2. Reputation Assessment Based on Similarity
Similarity-based methods operate on the core principle that “birds of a feather flock together”, inferring a node’s reputation based on its similarity to known benign or malicious anchors, as measured by a set of standardized parameters.
2.2.1. Representative Methods
- Similarity Based on Infrastructure Information: This approach leverages the tendency of attackers to operate on similar network infrastructures. Fukushima et al. [24] proposed a reputation evaluation method based on domain names and IP registration addresses. The method allocates IP address blocks to each Autonomous System (AS). Each IP address within these blocks is associated with a domain name managed by a registrar. The authors’ approach involves inspecting the reputation of particular IP address ranges and registrars that are frequently used by acknowledged attackers, thus forming a blacklist informed by the reputations of these entities. During the reputation assessment, domain information extracted through the hierarchical structure is compared against the blacklist.
- Similarity Based on Multi-Source Threat Intelligence: Because malicious network activities share inherent patterns, the resulting threat intelligence naturally reflects these commonalities. Gong et al. [25] developed a procedure for evaluating the reputation of network entities by integrating data from Security Information and Event Management (SIEM) systems. As depicted in Figure 6, the method is structured into three consecutive stages: data collection, feature analysis, and the computation of reputation scores. The data collection phase amalgamates inputs from security surveillance systems with data pooled from network threat intelligence sources. It also compiles records from malware attacks, honeypot engagements, and security incident responses. In the feature analysis phase, the data attributes are carefully examined; this is followed by a reputation rating procedure assessing the veracity of each Cyber Threat Intelligence (CTI) input. The Mahalanobis distance metric is employed to evaluate the divergence from expected behavior patterns.
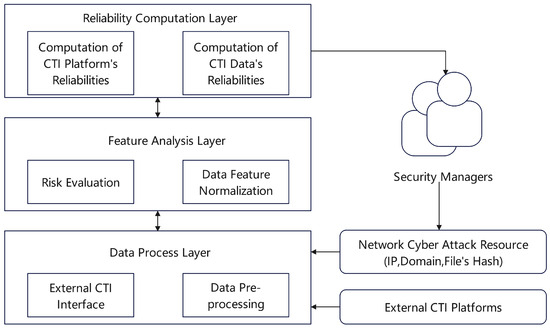 Figure 6. Triple-layered structure of the SIEM-based model for reputation assessment.
Figure 6. Triple-layered structure of the SIEM-based model for reputation assessment. - Similarity based on Data Features: This category of methods assesses network behavior by extracting and comparing intrinsic data features from network traffic. For instance, Esquivel et al. [26] discovered that spam botnets produce unique TCP header fingerprints. Similarity analysis of these fingerprints allows for the effective inference of an IP address’s maliciousness. In another study, Renjan et al. [27] proposed a method for Dynamic Attribute-Based Reputation (DABR). As depicted in Figure 7, the approach first extracts multiple meta-features from known malicious IP addresses to construct a baseline model. Subsequently, for a new IP address under evaluation, DABR calculates the Euclidean distance of its feature vector from this model to quantify its reputation score.
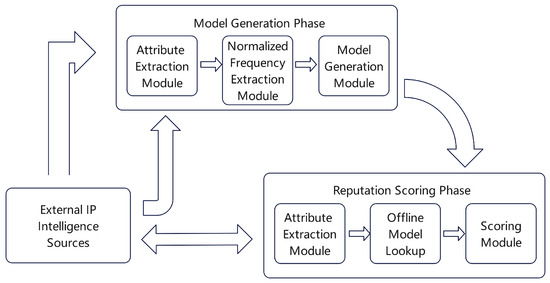 Figure 7. Operational framework of the DABR system.
Figure 7. Operational framework of the DABR system. - Similarity Based on Network and Geographical Features: This method combines traffic statistics with IP geolocation information to measure similarity between entities in encrypted traffic. Sainani et al. [28] devised an approach to evaluate the trustworthiness of IP addresses in scenarios involving encrypted communications. Figure 8 demonstrates the model, which consolidates network metrics sourced from various databases with geographic information to create a Geographically Enhanced Network dataset (GeoNet). The model employs a customized clustering algorithm to establish a reference model; thereafter, it assesses the interconnectedness between individual IP addresses. The trustworthiness of an IP address is ultimately determined by the degree of its alignment with the reference model.
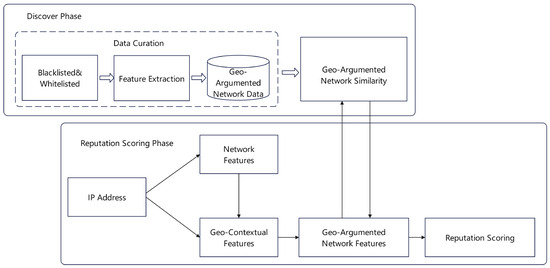 Figure 8. GeoNet model illustrating the integration of GeoNet for IP credibility assessment.
Figure 8. GeoNet model illustrating the integration of GeoNet for IP credibility assessment. - Similarity Based on Rendered Content: This method leverages the tendency of attackers to reuse identical or similar web page templates, using visual content similarity to identify associated malicious servers. Anderson et al. [29] explored the presence of fraudulent activities within spam emails by adopting an “image layering” technique. This method involves analyzing the visual congruities among web page snapshots to group together scam-related servers. The system extracts content from emails, detects URLs embedded within, and dynamically follows these links to identify the associated servers. It subsequently engages in proactive server probing to elucidate key operational characteristics, such as server uptime, activity periods, and geographic distribution, thereby enabling a comprehensive assessment of server reputation.
2.2.2. Discussion
Similarity-based methods are promising for scenarios with limited labeled data. Instead of learning a direct classification boundary, they construct a metric space where similar nodes are grouped together. However, this approach faces three primary challenges:
- 1.
- Anchor Selection and Updating: Performance heavily depends on the quality and representativeness of the anchors (known benign or malicious samples). Selecting and dynamically updating these anchors to keep pace with new attack patterns is a difficult problem.
- 2.
- Definition of Similarity Metrics: The choice of a similarity metric is critical. Metrics like Euclidean distance, cosine similarity, or Mahalanobis distance are suited for different data types and distributions. A key challenge is designing a metric that effectively separates benign from malicious entities while remaining robust to noise.
- 3.
- Computational Cost: Evaluating a new node by calculating its similarity to numerous existing nodes or anchors can be computationally expensive for large-scale networks, impacting real-time performance.
2.3. Reputation Assessment Employing Machine Learning Methods
With the growth in data volume and computational power, the dominant paradigm in reputation assessment has shifted toward machine learning, particularly deep learning. These methods can automatically learn complex, non-linear relationships from high-dimensional, heterogeneous data, enabling more precise classification and prediction than traditional similarity matching.
2.3.1. Representative Methods
- Classification Models Based on Feature Engineering: Early machine learning methods relied on manually crafted features to train classifiers. In the context of malicious URL and domain detection, researchers typically extracted two types of features: static lexical/host information and dynamic network-level relationships. For example, Ma et al. [30] encoded URL length, character counts, IP addresses, and WHOIS data into feature vectors, applying Support Vector Machines (SVM) and Logistic Regression (LR) for classification. In contrast, MalPortrait [31] modeled domains as nodes in a graph, creating edges between domains that resolved to the same IP address. The edge weights quantified the correlation between domains, and graph algorithms were used to generate new structural features for a Random Forest model to perform maliciousness detection.Another class of methods focuses on extracting behavioral patterns from network traffic. The Notos system [32], illustrated in Figure 9, trained its classifier using multi-dimensional features from DNS traffic and Security Information and Event Management (SIEM) logs, such as network behavior and regional history. In email security, researchers identified spam by analyzing sender behavior. Tang et al. [33] extracted vectors representing the breadth of IP activity and spectral patterns of sending behavior for classification. Similarly, SNARE [34] and PreSTA [35] assessed sender reputation by analyzing spatio-temporal features of emails. Furthermore, Chiba et al. [36] combined the temporal stability and spatial concentration of IP addresses, adjusting the output of an SVM with a logistic sigmoid function to compute a final reputation score [37].
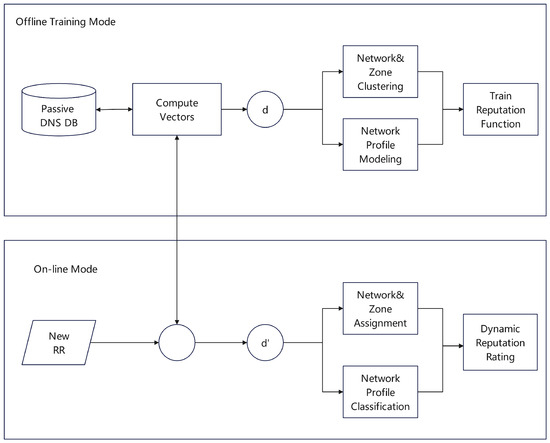 Figure 9. The Notos model system architecture.
Figure 9. The Notos model system architecture. - End-to-End Models Based on Deep Learning: The application of deep learning has reduced the reliance on manual feature engineering, enabling end-to-end learning from raw data to final judgment. In domain and IP address reputation assessment, Graph Neural Networks (GNNs) have become a prominent approach. For instance, Lison et al. [38] constructed a bipartite graph of domains and IP addresses, where a node’s reputation is influenced by its neighbors. As shown in Figure 10, their model inputs a domain’s character sequences and categorical features into a neural network, combining recurrent analysis with feed-forward layers to ultimately generate a probability distribution representing its reputation. Similarly, Huang et al. [39] utilized a Graph Convolutional Network (GCN) to integrate features from various protocols like network traffic, email, and DNS. As depicted in Figure 11, the model first builds an IP-to-IP graph and uses the GCN to automatically learn feature representations of the nodes, followed by a Random Forest classifier to assess their maliciousness probability.
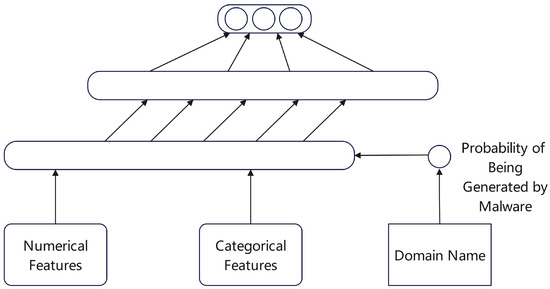 Figure 10. Deep Neural Network architecture for domain reputation prediction.
Figure 10. Deep Neural Network architecture for domain reputation prediction.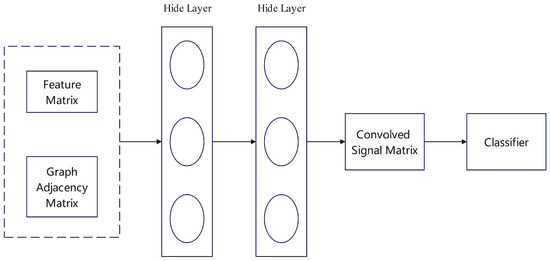 Figure 11. Application of the GCN model to node classification for IP reputation analysis.Another distinct deep learning paradigm is based on similarity metrics. The Siamese Network Classification Framework (SNCF) proposed by Sun et al. [40] is a prime example. As illustrated in Figure 12, the core idea is to learn a function that measures the similarity between pairs of samples (Xi, Xj). By minimizing or maximizing the Euclidean distance between sample pairs during training, the Siamese network learns a representation space that is robust to data noise. In the prediction phase, the model can efficiently assess the risk of new data, requiring minimal feature engineering and offering excellent scalability.
Figure 11. Application of the GCN model to node classification for IP reputation analysis.Another distinct deep learning paradigm is based on similarity metrics. The Siamese Network Classification Framework (SNCF) proposed by Sun et al. [40] is a prime example. As illustrated in Figure 12, the core idea is to learn a function that measures the similarity between pairs of samples (Xi, Xj). By minimizing or maximizing the Euclidean distance between sample pairs during training, the Siamese network learns a representation space that is robust to data noise. In the prediction phase, the model can efficiently assess the risk of new data, requiring minimal feature engineering and offering excellent scalability.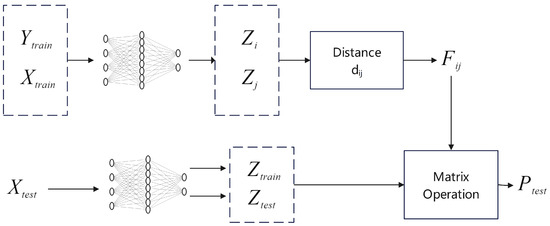 Figure 12. The SNCF for similarity-based risk assessment.Furthermore, deep learning is also applied to analyze encrypted traffic and the dynamic behavior of malware. Anderson et al. [41] discovered that even under TLS encryption, the network behavior of malware (e.g., handshake information, packet length sequences, byte distributions) differs from normal traffic. As shown in Figure 13, a logistic regression classifier analyzing these features can effectively identify malicious traffic and evaluate its reputation. Usman et al. [42] proposed a comprehensive method combining dynamic malware analysis with machine learning. As detailed in Figure 14, this approach executes samples in a sandbox to collect data on network activity, file system, and registry behavior. It then uses algorithms like decision trees to analyze these dynamic behavioral patterns, thereby accurately assessing the reputation of the associated IP addresses.
Figure 12. The SNCF for similarity-based risk assessment.Furthermore, deep learning is also applied to analyze encrypted traffic and the dynamic behavior of malware. Anderson et al. [41] discovered that even under TLS encryption, the network behavior of malware (e.g., handshake information, packet length sequences, byte distributions) differs from normal traffic. As shown in Figure 13, a logistic regression classifier analyzing these features can effectively identify malicious traffic and evaluate its reputation. Usman et al. [42] proposed a comprehensive method combining dynamic malware analysis with machine learning. As detailed in Figure 14, this approach executes samples in a sandbox to collect data on network activity, file system, and registry behavior. It then uses algorithms like decision trees to analyze these dynamic behavioral patterns, thereby accurately assessing the reputation of the associated IP addresses.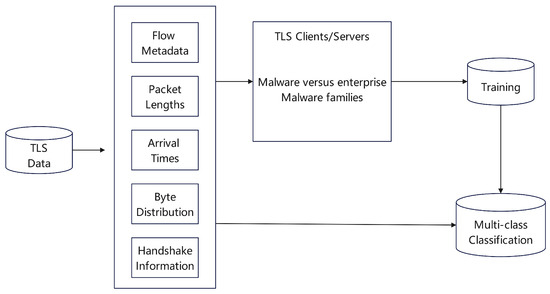 Figure 13. Analyzing malware activity via TLS characteristics.
Figure 13. Analyzing malware activity via TLS characteristics.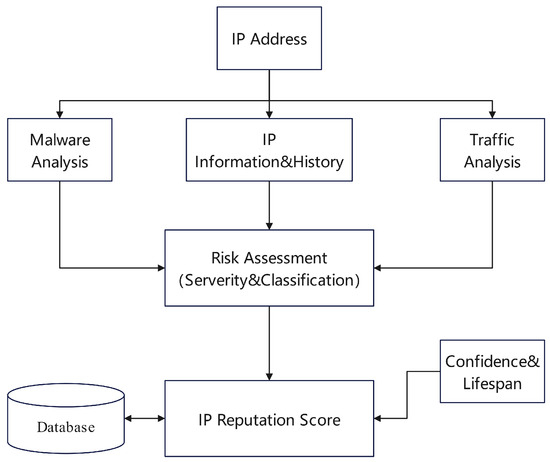 Figure 14. Representation of the dynamic IP reputation system.
Figure 14. Representation of the dynamic IP reputation system. - Hybrid Models: To leverage the advantages of different technologies, many studies have adopted hybrid models. These approaches typically integrate multiple algorithms or data sources to achieve a more comprehensive reputation assessment. One strategy involves combining traditional scoring systems with modern machine learning algorithms. For instance, the PST-SRF model proposed by Zhou et al. [43] is designed to evaluate the public security reputation of cloud users. The model first collects user link-following behavior and content information via web crawlers and log systems, using a Convolutional Neural Network (CNN) to extract key features. Subsequently, a scorecard method is employed to select indicators highly correlated with reputation. Finally, these indicators are fed into a Random Forest algorithm to produce the final reputation score. This approach combines the interpretability of scorecards with the classification power of Random Forests. Another hybrid approach combines unsupervised clustering with known threat data. Morales et al. [44] proposed a scheme to identify malicious DNS queries by using clustering algorithms to find unknown domains similar to known malicious ones. As shown in Figure 15, this method begins by extracting features like domain names and TTLs from passive DNS data, which is preprocessed with ratings from authoritative websites. High-risk domains are then designated as “anchors.” Using a sliding window to process the large dataset, each window of data is analyzed by multiple clustering algorithms, such as k-Means. Unknown domains that cluster together with the “anchors” are identified as potentially malicious targets. This technique cleverly uses unsupervised learning to expand the coverage of known threat intelligence. Within a federated learning framework, Al-Maslamani et al. [45] introduced a reputation-based mechanism to prevent malicious participants from uploading “poisonous” model updates. The system calculates a reputation score for each participant based on their historical interactions. Concurrently, it employs deep reinforcement learning to monitor the global model’s performance and dynamically adjusts the reputation threshold used for participant selection. This adaptive filtering approach enables a more intelligent and secure model aggregation, effectively defending against attacks.
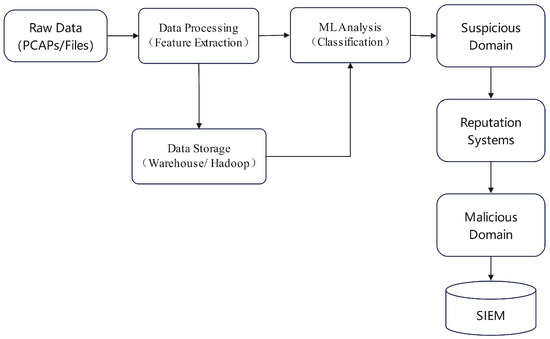 Figure 15. Schematic of big data platform for malicious domain detection.
Figure 15. Schematic of big data platform for malicious domain detection.
2.3.2. Discussion
Machine learning methods, especially those using graph and deep learning, represent the forefront of reputation assessment. They excel at handling complex, high-dimensional data and identifying novel attack patterns. However, their complexity introduces new challenges:
- 1.
- Problem of Interpretability: Deep learning models are often seen as “black boxes” because their decision-making processes lack transparency. This is a major drawback in security applications, where understanding why a decision was made (e.g., blocking a critical IP) is crucial for trust and recourse.
- 2.
- Dependency on Data and The Cost of Labeling: Supervised learning performance is highly dependent on large volumes of high-quality labeled data. In cybersecurity, acquiring accurate labels for diverse and evolving attack types is expensive. Furthermore, datasets often suffer from severe class imbalance, which complicates model training.
- 3.
- Computational Resources and Deployment Complexity: Training large deep learning models, particularly GNNs, requires significant computational resources (e.g., GPUs) and time. Deploying, monitoring, and maintaining these complex models also pose greater challenges than traditional methods, especially in real-time environments.
- 4.
- Vulnerability to Adversarial Attacks: Attackers can craft subtle, often imperceptible, perturbations to input data (like minor changes to a URL or traffic pattern) to deceive a model into making incorrect judgments. This vulnerability means that even highly accurate models can potentially be bypassed in real-world attacks.
3. Comparative Summary of Existing Methods
To provide a more intuitive overview of the characteristics of various methods, Table 1 summarizes and compares the representative methods mentioned above across multiple dimensions, including their core principles, data sources, computational overhead, scalability, robustness, and a summary of their advantages and disadvantages.

Table 1.
Multi-dimensional comparative analysis of reputation assessment methods.
From this analysis and comparison, several insights can be distilled:
- 1.
- Technological Evolution: From Simplicity to Complexity. Reputation assessment technology has evolved from early, simple statistical counting to the sophisticated machine learning models of today. The core driving force behind this progression is the continuous escalation of attack techniques, which compels defenders to seek out traces of malicious activity within higher-dimensional and more complex correlations.
- 2.
- The Trade-off between Performance and Cost: No “Silver Bullet” Exists. Statistics-based methods are characterized by low overhead and high interpretability, making them suitable as a baseline defense or for resource-constrained environments. In contrast, methods based on machine learning (especially Graph Neural Networks) offer powerful performance and are more effective against coordinated attacks. However, their high computational costs, dependency on high-quality data, and inherent model complexity represent critical trade-offs that must be considered in practical deployments.
- 3.
- The Rise of Graph-Based Methods: Connectivity as a Key Indicator. The trend toward coordinated cyberattacks has turned graph-structured data, which captures the relationships between nodes, into a “gold mine” for reputation assessment. Whether through explicitly engineering graph features (as in MalPortrait) or directly applying Graph Neural Networks (GNNs), leveraging the topological relationships between nodes to identify malicious clusters has become one of the most effective research paradigms today.
It is also important to note that the performance metrics presented, such as accuracy, are often derived from specific, non-standardized datasets. Therefore, direct comparison of these figures across studies should be approached with caution, as results are highly contingent on the evaluation environment and data distribution. This highlights a broader challenge in the field: the need for standardized benchmarks to enable more reliable and generalizable comparisons.
4. Development Trends
Despite significant progress in network reputation assessment, the field still faces numerous challenges in the face of an ever-evolving network environment and attack techniques. Future developments are shaping up in the following directions.
4.1. From Single to Multi-Source Heterogeneous Data Fusion
Traditional assessment methods often rely on a single data source, such as DNS queries or IP blacklists. However, sophisticated attack campaigns typically leave traces across multiple network protocols and data layers. Consequently, a clear trend is the fusion of data from diverse channels, formats, and quality levels to construct more comprehensive and robust node profiles. For example, combining NetFlow data, TLS handshake metadata, passive DNS records, and external threat intelligence can create a multi-dimensional feature space. The core challenge here lies in effectively aligning this heterogeneous data and managing potential conflicts and noise among the various sources.
4.2. From “Black-Box” Decisions to Explainable AI (XAI)
As deep learning models become dominant in reputation assessment, their “black-box” nature has emerged as a major obstacle to deployment. When a model makes a critical decision, such as blocking an important IP address, explaining “why” is as crucial as concluding “what.” Consequently, applying Explainable AI (XAI) techniques like SHAP, LIME, and GNNExplainer has become a vital research direction. As demonstrated by GNNGuard [46] in its analysis of adversarial attacks, understanding a model’s decision attribution not only helps diagnose its “failure modes” when under attack but also provides a necessary foundation for building more robust and trustworthy reputation assessment systems.
4.3. From Centralized Processing to Federated Learning for Massive-Scale Nodes
The proliferation of IPv6 and the Internet of Things (IoT) has led to an explosive growth in network nodes, creating significant storage, computational, and privacy challenges for traditional centralized data processing. Federated Learning (FL) addresses these issues by enabling local model training and uploading only encrypted updates for aggregation. Such as the PQBFL protocol combines blockchain for authentication with FL to support data aggregation and model updates in distributed reputation systems [47].
4.4. From Static Defense to a Dynamic Game in an Adversarial Environment
Current reputation systems are mostly static classifiers, overlooking the adaptive nature of attackers. Once a defense mechanism is deployed, adversaries analyze its weaknesses and devise evasion strategies, creating a continuous “cat-and-mouse game.” Future research must therefore incorporate this adversarial dynamic. This implies developing adversarial training techniques to enhance model robustness against subtle malicious perturbations. Further, research can explore adaptive defense strategies based on reinforcement learning, enabling a reputation system to dynamically adjust its models and thresholds in response to observed changes in attack patterns.
4.5. From Isolated Evaluations to Standardized Benchmarks
A challenge in the reputation assessment field is the absence of standardized benchmarks and unified evaluation frameworks. Research is commonly conducted in “isolated evaluations” on private datasets, a practice that not only prevents fair comparisons between methods but also undermines reproducibility, thereby slowing overall technological progress. Therefore, future efforts should focus on the collaborative development of large-scale, public benchmark datasets covering diverse scenarios and attack models, complemented by standardized evaluation metrics. Such a shift will not only foster more objective performance comparisons but also accelerate the maturation of the field’s technologies.
5. Conclusions
Network reputation evaluation, given its considerable potential and practicality, emerges as a critical research direction within the field of network security. This paper has systematically reviewed and commented on the current state of research in network security reputation assessment, focusing on three mainstream approaches: statistics-based, similarity-based, and machine learning-based methods. By constructing a multi-dimensional comparative framework, this work reveals the advantages and limitations of different technical routes, as well as the complex trade-offs between their performance and cost. The analysis indicates that leveraging graph-structured data and advanced machine learning models has become the dominant paradigm for combating coordinated and sophisticated cyberattacks. However, this trend has also introduced new challenges, particularly concerning model interpretability, data dependency, and adversarial robustness.
Looking ahead, the research focus in this field is shifting toward several frontier directions: fusing multi-source heterogeneous data for a more holistic view; enhancing the transparency and interpretability of model decisions; adopting privacy-preserving learning frameworks (such as Federated Learning) to accommodate massive-scale node environments; and strengthening system robustness within a dynamic, adversarial game. Addressing these challenges is key to advancing reputation assessment systems from theoretical research to broader and more reliable practical applications. It is hoped that the critical analysis and forward-looking discussion presented in this paper will provide a valuable reference for future research in the field.
Author Contributions
Conceptualization, J.X. and L.H.; methodology, J.X. and L.H.; validation, F.Z. and K.S.; formal analysis, F.Z.; investigation, J.X., F.Z., Z.N., K.S. and Q.L.; resources, J.X., F.Z., Z.N. and K.S.; data curation, J.X.; writing—original draft preparation, J.X.; writing—review and editing, L.H., F.Z., Z.N. and K.S.; visualization, J.X., F.Z., Z.N., K.S. and Q.L.; supervision, L.H. and Z.N.; project administration, L.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
No new data were created or analyzed in this study.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Resnick, P.; Kuwabara, K.; Zeckhauser, R.; Friedman, E. Reputation systems. Commun. ACM 2000, 43, 45–48. [Google Scholar] [CrossRef]
- De Cristofaro, E.; Gasti, P.; Tsudik, G. Fast and private computation of cardinality of set intersection and union. In Proceedings of the International Conference on Cryptology and Network Security, Darmstadt, Germany, 12–14 December 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 218–231. [Google Scholar]
- Abrams, M.D.; Joyce, M.V. Trusted system concepts. Comput. Secur. 1995, 14, 45–56. [Google Scholar] [CrossRef]
- Jøsang, A.; Ismail, R.; Boyd, C. A survey of trust and reputation systems for online service provision. Decis. Support Syst. 2007, 43, 618–644. [Google Scholar] [CrossRef]
- Cisco Systems, Inc. How does SenderBase Work? 2020. Available online: https://www.cisco.com/c/en/us/support/docs/security/email-security-appliance/118378-technote-esa-00.html?dtid=osscdc000283&linkclickid=srch (accessed on 27 September 2025).
- Microsoft. WhatIsSNDS. 2013. Available online: https://sendersupport.olc.protection.outlook.com/snds/FAQ.aspx#WhatIsSNDS (accessed on 27 September 2025).
- Talos, C. Cisco Talos Intelligence Group-Comprehensive Threat Intelligence. 2023. Available online: https://support.talosintelligence.com/ (accessed on 27 September 2025).
- Validity. Sender Score Email Reputation Management. 2022. Available online: https://senderscore.org/assess/get-your-score (accessed on 27 September 2025).
- Wikipedia. TrustedSource. 2016. Available online: https://en.wikipedia.org/wiki/TrustedSourc (accessed on 27 September 2025).
- Preuveneers, D.; Joosen, W. Managing distributed trust relationships for multi-modal authentication. J. Inf. Secur. Appl. 2018, 40, 258–270. [Google Scholar] [CrossRef]
- Tencent Cloud. Tencent’s Threat Intelligence Cloud Search Service. 2022. Available online: https://cloud.tencent.com/document/product/1013/31158 (accessed on 27 September 2025).
- Xiong, L.; Liu, L. Peertrust: Supporting reputation-based trust for peer-to-peer electronic communities. IEEE Trans. Knowl. Data Eng. 2004, 16, 843–857. [Google Scholar] [CrossRef]
- Li, B.; Wu, L.; Zhou, Z.; Li, H. Design and implementation of trust-based identity management model for cloud computing. Comput. Sci. 2014, 41, 3–21. [Google Scholar]
- Li, X.; Wang, Q.; Lan, X.; Chen, X.; Zhang, N.; Chen, D. Enhancing cloud-based IoT security through trustworthy cloud service: An integration of security and reputation approach. IEEE Access 2019, 7, 9368–9383. [Google Scholar] [CrossRef]
- Yang, S.; Deng, Q. P2P Reputation Estimation Based on Statistical Inference. Microelectron. Comput. 2008, 25, 61–64. [Google Scholar]
- Zheng, Y.; Hu, B.; Zheng, X.; Zhang, Q. A Network Security Protection Method and System and Process BASED on IP Address Security Credibility. CN Patent 201610820694.2, 17 November 2020. [Google Scholar]
- Xie, M.; Wang, H. A collaboration-based autonomous reputation system for email services. In Proceedings of the 2010 IEEE INFOCOM, San Diego, CA, USA, 14–19 March 2010; pp. 1–9. [Google Scholar]
- Chen, J.; Tian, Z.; Cui, X.; Yin, L.; Wang, X. Trust architecture and reputation evaluation for internet of things. J. Ambient. Intell. Humaniz. Comput. 2019, 10, 3099–3107. [Google Scholar] [CrossRef]
- Tian, L.Q.; Lin, C.; Ni, Y. Evaluation of user behavior trust in cloud computing. In Proceedings of the 2010 International Conference on Computer Application and System Modeling (ICCASM 2010), Taiyuan, China, 22–24 October 2010; Volume 7, pp. V7–567. [Google Scholar]
- Peng, C.; Yun, X.; Zhang, Y.; Li, S.; Xiao, J. Discovering malicious domains through alias-canonical graph. In Proceedings of the 2017 IEEE Trustcom/BigDataSE/ICESS, Sydney, NSW, Australia, 1–4 August 2017; pp. 225–232. [Google Scholar]
- Sharifnya, R.; Abadi, M. A novel reputation system to detect DGA-based botnets. In Proceedings of the ICCKE 2013, Mashhad, Iran, 31 October–1 November 2013; pp. 417–423. [Google Scholar]
- Wang, Y.; Vassileva, J. Trust and reputation model in peer-to-peer networks. In Proceedings of the Third International Conference on Peer-to-Peer Computing (P2P2003), Linköping, Sweden, 1–3 September 2003; pp. 150–157. [Google Scholar]
- Tang, X.; Liu, J.; Li, K.; Tu, W.; Xu, X.; Xiong, N.N. IIM-ARE: An Effective Interactive Incentive Mechanism Based on Adaptive Reputation Evaluation for Mobile Crowd Sensing. IEEE Internet Things J. 2025, 12, 16181–16191. [Google Scholar] [CrossRef]
- Fukushima, Y.; Hori, Y.; Sakurai, K. Proactive blacklisting for malicious web sites by reputation evaluation based on domain and IP address registration. In Proceedings of the 2011 IEEE 10th International Conference on Trust, Security and Privacy in Computing and Communications, Changsha, China, 16–18 November 2011; pp. 352–361. [Google Scholar]
- Gong, S.; Cho, J.; Lee, C. A reliability comparison method for OSINT validity analysis. IEEE Trans. Ind. Inform. 2018, 14, 5428–5435. [Google Scholar] [CrossRef]
- Esquivel, H.; Akella, A.; Mori, T. On the effectiveness of IP reputation for spam filtering. In Proceedings of the 2010 Second International Conference on COMmunication Systems and NETworks (COMSNETS 2010), Bangalore, India, 5–9 January 2010; pp. 1–10. [Google Scholar]
- Renjan, A.; Joshi, K.P.; Narayanan, S.N.; Joshi, A. Dabr: Dynamic attribute-based reputation scoring for malicious ip address detection. In Proceedings of the 2018 IEEE International Conference on Intelligence and Security Informatics (ISI), Miami, FL, USA, 9–11 November 2018; pp. 64–69. [Google Scholar]
- Sainani, H.; Namayanja, J.M.; Sharma, G.; Misal, V.; Janeja, V.P. IP reputation scoring with geo-contextual feature augmentation. ACM Trans. Manag. Inf. Syst. TMIS 2020, 11, 1–29. [Google Scholar] [CrossRef]
- Anderson, D.S.; Fleizach, C.; Savage, S.; Voelker, G.M. Spamscatter: Characterizing Internet Scam Hosting Infrastructure. Ph.D. Thesis, University of California, San Diego, CA, USA, 2007. [Google Scholar]
- Ma, J.; Saul, L.K.; Savage, S.; Voelker, G.M. Beyond blacklists: Learning to detect malicious web sites from suspicious URLs. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009; pp. 1245–1254. [Google Scholar]
- Liang, Z.; Zang, T.; Zeng, Y. Malportrait: Sketch malicious domain portraits based on passive DNS data. In Proceedings of the 2020 IEEE Wireless Communications and Networking Conference (WCNC), Seoul, Republic of Korea, 25–28 May 2020; pp. 1–8. [Google Scholar]
- Antonakakis, M.; Perdisci, R.; Dagon, D.; Lee, W.; Feamster, N. Building a dynamic reputation system for {DNS}. In Proceedings of the 19th USENIX Security Symposium (USENIX Security 10), Washington, DC, USA, 11–13 August 2010. [Google Scholar]
- Tang, Y.; Krasser, S.; Judge, P.; Zhang, Y.Q. Fast and effective spam sender detection with granular svm on highly imbalanced mail server behavior data. In Proceedings of the 2006 International Conference on Collaborative Computing: Networking, Applications and Worksharing, Atlanta, GA, USA, 17–20 November 2006; pp. 1–6. [Google Scholar]
- Hao, S.; Syed, N.A.; Feamster, N.; Gray, A.G.; Krasser, S. Detecting Spammers with SNARE: Spatio-temporal Network-level Automatic Reputation Engine. In Proceedings of the USENIX Security Symposium, Berkeley, CA, USA, 10–14 August 2009; Volume 9. [Google Scholar]
- West, A.G.; Aviv, A.J.; Chang, J.; Lee, I. Spam mitigation using spatio-temporal reputations from blacklist history. In Proceedings of the 26th Annual Computer Security Applications Conference, Austin, TX, USA, 6–10 December 2010; pp. 161–170. [Google Scholar]
- Chiba, D.; Tobe, K.; Mori, T.; Goto, S. Detecting malicious websites by learning IP address features. In Proceedings of the 2012 IEEE/IPSJ 12th International Symposium on Applications and the Internet, Izmir, Turkey, 16–20 July 2012; pp. 29–39. [Google Scholar]
- Platt, J. Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods. Adv. Large Margin Classif. 1999, 10, 61–74. [Google Scholar]
- Lison, P.; Mavroeidis, V. Neural reputation models learned from passive DNS data. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; pp. 3662–3671. [Google Scholar]
- Huang, Y.; Negrete, J.; Wagener, J.; Fralick, C.; Rodriguez, A.; Peterson, E.; Wosotowsky, A. Graph neural networks and cross-protocol analysis for detecting malicious IP addresses. Complex Intell. Syst. 2023, 9, 3857–3869. [Google Scholar] [CrossRef] [PubMed]
- Sun, D.; Wu, Z.; Wang, Y.; Lv, Q.; Hu, B. Risk prediction for imbalanced data in cyber security: A Siamese network-based deep learning classification framework. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]
- Anderson, B.; Paul, S.; McGrew, D. Deciphering malware’s use of TLS (without decryption). J. Comput. Virol. Hacking Tech. 2018, 14, 195–211. [Google Scholar] [CrossRef]
- Usman, N.; Usman, S.; Khan, F.; Jan, M.A.; Sajid, A.; Alazab, M.; Watters, P. Intelligent dynamic malware detection using machine learning in IP reputation for forensics data analytics. Future Gener. Comput. Syst. 2021, 118, 124–141. [Google Scholar] [CrossRef]
- ZHOU, S.; JIN, C.; WU, L.; HONG, Z. Research on cloud computing users’ public safety trust model based on scorecard-random forest. J. Commun. 2018, 39, 143–152. [Google Scholar]
- Watkins, L.; Beck, S.; Zook, J.; Buczak, A.; Chavis, J.; Robinson, W.H.; Morales, J.A.; Mishra, S. Using semi-supervised machine learning to address the big data problem in DNS networks. In Proceedings of the 2017 IEEE 7th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 9–11 January 2017; pp. 1–6. [Google Scholar]
- Al-Maslamani, N.M.; Ciftler, B.S.; Abdallah, M.; Mahmoud, M.M.E.A. Toward Secure Federated Learning for IoT Using DRL-enabled Reputation Mechanism. IEEE Internet Things J. 2022, 9, 21971–21983. [Google Scholar] [CrossRef]
- Zhang, X.; Zitnik, M. Gnnguard: Defending graph neural networks against adversarial attacks. Adv. Neural Inf. Process. Syst. 2020, 33, 9263–9275. [Google Scholar]
- Gharavi, H.; Granjal, J.; Monteiro, E. PQBFL: A Post-Quantum Blockchain-based Protocol for Federated Learning. Comput. Netw. 2025, 269, 111472. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).