Abstract
Sign language serves as a vital way to communicate with individuals with hearing loss, deafness, or a speech disorder, yet accessibility remains limited, requiring technological advances to bridge the gap. This study presents the first real-time Greek Sign Language recognition system utilizing deep learning and embedded computers. The recognition system is implemented using You Only Look Once (YOLO11X-seg), an advanced object detection model, which is embedded in a Python-based framework. The model is trained to recognize Greek Sign Language letters and an expandable set of specific words, i.e., the model is capable of distinguishing between static hand shapes (letters) and dynamic gestures (words). The most important advantage of the proposed system is its mobility and scalable processing power. The data are recorded using a mobile IP camera (based on Raspberry Pi 4) via a Motion-Joint Photographic Experts Group (MJPEG) Stream. The image is transmitted over a private ZeroTier network to a remote powerful computer capable of quickly processing large sign language models, employing Moonlight streaming technology. Smaller models can run on an embedded computer. The experimental evaluation shows excellent 99.07% recognition accuracy, while real-time operation is supported, with the image frames processed in 42.7 ms (23.4 frames/s), offering remote accessibility without requiring a direct connection to the processing unit.
1. Introduction
Sign language recognition has evolved significantly over the years, moving from the traditional methods to advanced approaches based on deep learning. The early attempts in this area introduced the concept of breaking signal gestures into subunits to improve recognition accuracy and facilitate signer-independent systems [1]. These initial methods laid the foundation for further developments, structuring the elements into smaller, linguistically significant modules. As research progressed, Electro-Myo-Graphic (EMG) signal processing became an effective approach to recording muscle activity, providing a direct method for recognizing gestures in sign language [2]. This method was further improved through advanced pattern recognition techniques, which significantly enhanced classification accuracy in Polish sign language using different machine learning models, particularly Convolutional Neural Networks (CNNs) [3]. Wearable technology has also played a critical role in sign language recognition, with real-time wearable systems integrating surface Electromyography (sEMG) and Inertial Measurement Unit (IMU) data from both arms, achieving highly accurate recognition results [4]. The introduction of sensors in wearable gloves has further improved sign language processing by recording precise hand movements and using deep learning architectures such as Convolutional Progress Learning Neural Networks (PLD-CNNs) for better recognition efficiency [5].
The integration of deep learning models has significantly improved sign language recognition. A hybrid approach leveraging CNNs and Long Short-Term Memory (LSTM) networks demonstrated high accuracy in real-time signal detection, combining static gesture recognition using YOLOv6 with dynamic signal processing via LSTM [6]. Further developments incorporated ResNet and LSTM models to improve video-based sign language recognition, recording both spatial and temporal characteristics [7]. The development of deep learning models adapted for American Sign Language (ASL) alphabet recognition used 87.000 images of the alphabet and introduced architectures such as AlexNet with a success rate of 99.50%, ConvNeXt with a success rate of 99.51%, EfficientNet with a success rate of 99.95%, ResNet-50 with a success rate of 99.98%, and Vision Transformers (ViT) with a success rate of 88.59%, achieving near-perfect accuracy in the recognition of ASL letters [8]. A comparison between ViT- and CNN-based models for Japanese Sign Language (JSL) revealed that ViT has a 99.7% success rate, while CNN has a 99.3% success rate [9]. Hybrid models incorporating the CNN and LSTM have also been applied to real-time Arabic Sign Language Recognition, demonstrating efficiency in handling both static and dynamic gestures with success rates of 94.40% and 82.70%, respectively [10]. The development of attention-based deep learning models has further promoted video-based sign language recognition. A CNN-LSTM hybrid architecture based on MobileNetV2, has shown 84.65% accuracy in video processing [11]. A hybrid R3(2 + 1) D-SLR model and a Support Vector Machine (SVM) classifier performed recognition independently of the person making the move in [12].
The multimodal approach presented in [13] uses portable glove sensors, two-axis bending sensors, and Red-Green-Blue (RGB) cameras for Japanese sign language recognition based on a CNN-BiLSTM hybrid model. In addition, wearable motion capture systems such as perception neuron have been used to recognize and translate ASL, achieving high accuracy rates of 99.07% at the word level and 97.34% at the sentence level [14]. Self-attention mechanisms have further improved static recognition, emphasizing key gesture characteristics, ensuring higher recognition rates even with non-standard gestures (98.63% and 86.63%) [15]. The introduction of feature-isolated transformer models such as Siformer led to significant improvements in skeleton-based sign language recognition, effectively capturing spatiotemporal features for increased accuracy [16]. A Multi-view Space-Time Network (MSTN) combines RGB video and skeletal motion data for Continuous Sign Language Recognition, and using a transformer with a Connectionist Temporal Classification (CTC) decoder has been quite successful [17]. Real-time sign language translation has also been improved through online Continuous Sign Language Recognition (CSLR) models that use pre-trained networks and sliding window techniques to identify and dynamically translate sign language [18]. The implementation of MediaPipe Holistic in CSLR systems enabled accurate tracking of face, hand, and body parts, leading to the development of powerful datasets that improve model performance in real-time applications, with an 88.23% success rate [19]. A comprehensive review of sign language recognition research highlights the significant progress in deep learning methodologies, data availability, and future directions for real-time applications [20]. Image augmentation techniques have been introduced to improve gesture recognition in various environments using transformations such as background replacement, geometric modifications, and lighting adjustments to improve the generalization of the model used by CNNs [21]. The development of British Sign Language recognition based on deep learning in interactive applications has enabled real-time feedback for sign language learners, leveraging YOLOv5 for instant recognition and educational support [22]. Web-based platforms supported by LSTM have been developed to promote sign language awareness and facilitate user participation in real-time sign language learning using CNNs [23]. In addition, LSTM real-time based recognition systems are designed to improve accessibility for the hearing impaired by integrating MediaPipe for accurate handheld milestone tracking [24]. A ten-year systematic review analyzed the CNN’s Arabic Sign Language Recognition (ArSLR) for static words in CNN-LSTM hybrid models for dynamic gestures [25]. The introduction of recursive neural networks (RNNs) improved Mexican sign language interpretation by incorporating spatial monitoring of facial expressions and hand movements, leading to more accurate and up-to-date translations [26]. An integrated application was proposed, featuring sign language alphabet and word recognition, text-to-action conversion, multilingual translation, and voice output to support communication and learning for sign language users and improve interaction with non-signers, given the current shortage of comprehensive, accessible tools [27]. Finally, a CNN-based framework was developed to recognize both Indian and American Sign Languages, offering multilingual text translation to bridge communication between sign language users and speakers of various Indian regional languages [28].
In the context of this work, YOLO11X-seg is trained with 1669 photographs with letters and words in order to be able to recognize Greek Sign Language (GSL). The trained model is then incorporated in Python code to enable the recognition of Greek letters using OpenCV and a Greek font set. A pair of windows in the user interface display the person who makes the gesture as well as the recognized letter or word. Remote operation is achieved using Raspberry Pi 4 connected to a camera. This is feasible due to a private network that has been created using ZeroTier that assigns a static IP to Raspberry Pi 4, eliminating the problem of network switching. Therefore, Raspberry Pi 4 and its camera are converted into an IP camera with the use of the MJPEG format. It is also feasible to send an image and control the central unit executing the Python program from Raspberry Pi 4 with nearly zero latency using the Moonlight application. Separating the mobile Raspberry Pi 4 and camera module from the main computer allows for the sign language model to be executed using powerful processing units, i.e., desktops, Graphics Processing Units (GPUs), etc., that are not portable.
The contribution of this work can be summarized in the following text: (a) Greek Sign Language is recognized; no other approaches to this language have been reported in the literature. (b) A state-of-the-art advanced YOLO architecture is adopted (version 11X-seg), but the referenced approaches do not take advantage of the YOLO architecture, except from references [6,22] that use the older YOLOv5 and YOLOv6, respectively. (c) An efficient system architecture is developed allowing for remote operation using a mobile camera connected to a Rasberry Pi 4 microcomputer, communicating wirelessly with the main computer. (d) Both remote operation and a scalable amount of computational power to run this large sign language model are achieved.
In Section 2, an overview of the related work in sign language recognition is presented. In Section 3, the system architecture is described, outlining the main components of the Greek Sign Language (GSL) recognition system. More specifically, in Section 3.1, the experimental setup and data collection process are detailed, including the hardware and software configurations used for training the model. Also, in Section 3.2, the detailed workflow for system implementation is described. Furthermore, in Section 3.3, the architecture of the YOLO11X-seg model is briefly presented. In Section 4, the training dataset used is introduced. In Section Labeling Images, the annotation process using the LabelMe application is explained. Section 5 analyzes the experimental results, evaluating the system’s performance in terms of success rates and precision for the various hand gestures. The details of YOLO11X-seg training are examined in Section 5.1. Section 5.2 discusses the impact of lighting and background conditions, while Section 5.3 assesses the performance of the proposed Greek Sign Language recognition system. A comparison with related works is provided in Section 5.4. Finally, the conclusions and future directions are outlined in Section 6.
2. Related Work
Many approaches have been explored for Sign Language Recognition (SLR), leveraging deep learning, wearable sensors, and computer vision. The previous work on sign language recognition has focused mainly on models based on deep learning and wearable sensor technologies. One of the first deep learning approaches was implemented by YOLOv5 [22] for BSL, and then by YOLOv6 for ASL recognition [6], leveraging object detection to classify gestures in real time. While this method showed low inference latency, it did not have remote real-time accessibility and was limited to recognizing only American Sign Language (ASL). Another notable approach integrated ResNet with LSTM for video-based signal recognition [7]. This method effectively captured spatial and temporal dependencies, making it resilient against noise and improving gesture differentiation. However, it required large datasets and had high computational requirements, making real-time deployment difficult. In contrast, sensor-based wearable recognition [10] uses glove sensors and Inertial Units of Measurement (IMUs) to accurately track hand movements. These systems achieve high accuracy in controlled environments, but require expensive hardware. Similarly, models based on a 3D skeleton [16] used motion capture technologies such as the perception neuron to track whole body movements, yielding high accuracy, but requiring specialized equipment. More recent developments in transform-based models [15] have introduced self-attention mechanisms, such as ViT and Siformer, which recorded the spatiotemporal relationships in sign gestures. While these models improved point differentiation, they required large, labeled datasets and struggled with real-time deployment. In addition, the CNN-LSTM hybrid approaches [11] combined convolutional networks for feature extraction with repeating networks for temporal processing, making them effective for both single and continuous points. However, they suffered from slow speeds and required a large number of GPU resources. Another method, MediaPipe Holistic with LSTM [19], used pre-extracted key points from the hands, the face, and the body to perform spot recognition. This lightweight application did not require training in deep learning models, making it computationally efficient. However, it resulted in lower accuracy and limited generalization to different sign languages. Self-supervised learning for SLRs [20] has also emerged as an alternative, reducing the annotation effort, while improving generalization. Nevertheless, this approach shows a poorer performance compared to those of the fully supervised deep learning approaches.
While previous research has significantly advanced sign language recognition, most existing methods have key limitations, such as expensive hardware requirements, lack of real-time processing and mobility, and dataset limitations. Our method aims to address these gaps by introducing Greek Sign Language (GSL) support. To our knowledge, no deep-learning-based models exist for GSL recognition, thus our work is vital to Greek-speaking deaf communities. Unlike the previous studies based on older YOLO versions (e.g., YOLOv5 and YOLOv6) or CNN-based methods, our approach leverages YOLO11X-seg, which offers an improved detection speed and accuracy. The proposed method offers remote accessibility and edge computing since it runs on Raspberry Pi 4 with ZeroTier networking, allowing for real-time remote spot detection, unlike most other approaches that work only locally. Using a separate mobile camera from the main computer allows for the use of a high-computational-power platform to run a large sign language model. This computer can be equipped with a GPU, but lacks portability. At the same time, our approach is also a lower-cost and more scalable solution compared to the sensor-based mobile methods that require custom gloves or tracking devices. Our solution uses a low-cost, standard camera, making it more affordable and cost-effective. It is also optimized for real-time performance since Transformer and LSTM-based approaches require significant computational resources, and our system is also optimized for quick inference and deployment on embedded devices, depending of course on the size of the sign language model and the vocabulary supported. Consequently, our approach presents an effective and scalable solution for Greek Sign Language recognition, incorporating vision models using deep learning, remote accessibility, as well as low-cost equipment. The benefits of the proposed architecture can be exploited of course for the recognition of different sign languages or larger vocabulary.
3. System Architecture
To enable real-time recognition of Greek Sign Language (GSL), the proposed system integrates gesture recognition based on deep learning with embedded computers and networked communication. The system consists of three main components, as shown in Figure 1:

Figure 1.
Block architecture of Greek Sign Language recognition system.
- (a)
- Input module: This is the mobile part of the system. It records video stream using Raspberry Pi 4 connected to an IP camera.
- (b)
- Processing unit: Executes a deep learning model based on YOLO11X-seg to recognize static and dynamic gestures. This unit can be a high-computational-power platform with a GPU capable of executing large, trained sign language models with high speed. Smaller models can be executed on laptops or embedded computers. Thus, the system architecture is scalable and extensible according to the application.
- (c)
- Output module: Displays the detected letter or word on a Graphical User Interface (GUI).
3.1. System Platforms and Components
The software code used for training and the development of the database was executed on using an Intel I7 9700K computer with Nvidia Gtx 1660 super GPU and 16 GB RAM, as shown in Figure 2. Miniconda was used to create a suitable environment so that the necessary programs could be executed. In this way, the training of the YOLO11X-seg model could be carried out with the preprocessed data. The following software packages were exploited:
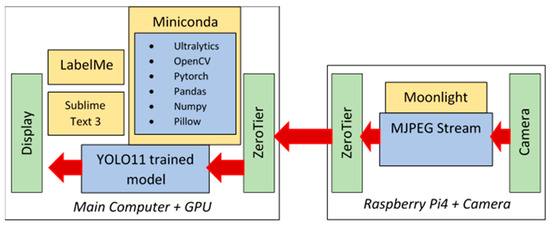
Figure 2.
Software packages used in Greek Sign Language recognition system.
- Ultralytics is used to train the YOLO11X-seg model with our data. It also supports the execution of the model within the Python program.
- Pytorch enables the training of the model and inference execution using the GPU instead of the CPU, which would result in a slower operation.
- OpenCV is required for recording videos, editing images, drawing bounding boxes, and displaying the results.
- Pandas is needed to handle the data in tables; it converts the YOLO11X-seg output into DataFrames for easier processing.
- Numpy handles arithmetic operations, arrays, and mathematical calculations.
- Pillow handles image editing, including converting text into images and using custom fonts as required to display Greek characters using the appropriate Greek fonts.
The USB camera connected to the Raspberry Pi 4 was used to collect the data, capturing 1669 photographs of handforms in Greek Sign Language. These photographs were processed using the LabelMe application in order to create the necessary label for each photo.
By installing the necessary files and applications on Raspberry Pi 4, remote use of the system is supported. These files and applications include Moonlight, which is used to control the main computer unit from Raspberry Pi 4, transmitting images with almost zero delay. This is necessary for the proper functioning of the whole system. ZeroTier is also installed, so that Raspberry Pi 4 is assigned with a specific fake static IP. In this way, it is able to have a permanent connection to the host through a private network. Using this approach, Raspberry Pi 4 is transparent when entering a new network. It can be used anywhere as long as there is access to the Internet. MJPEG Stream is also used on the side of the Raspberry Pi 4 client to convert the USB camera into an IP one. The main Python code is written in Sublime Text 3. Two Windows frames are created, one for displaying the handform and the second to display the letter or word corresponding to the specific handform. For convenience, the last window remains stable for 5 s to avoid continuously recognizing a single handform as multiple copies of the same alphabet character or word.
3.2. System Implementation Workflow
The implementation of the sign language recognition system follows a structured workflow designed for efficiency and portability as shown in Table 1. The process starts with capturing the handforms in photos, which are then annotated using the LabelMe application to label regions of interest. After completing annotation, an appropriate environment is created using Miniconda to manage all the dependencies for model training. The next step is training the YOLO11X-seg model, an advanced object detection framework known for its accuracy and speed. The resulting model is integrated and runs in Python code on the main computer. The application is deployed on Raspberry Pi 4, with all the necessary files installed. Zerotier is used to establish a private network for remote operation and visualization, enabling secure connectivity. The Moonlight app streams the main computer’s display, allowing for control and monitoring from another device like Raspberry Pi 4 in our case.

Table 1.
Workflow diagram of proposed sign language recognition system.
3.3. Brief Description of YOLO11X-seg
YOLO11X-seg represents a significant advancement in the evolution of real-time object detection models, incorporating architectural enhancements that improve both performance and versatility. The model’s architecture is divided into three primary components: the Backbone, the Neck, and the Head. The Backbone utilizes advanced modules, such as the C3k2 block and Spatial Pyramid Pooling Fast (SPPF), to facilitate efficient multi-scale feature extraction. The Neck integrates features using the Cross-Stage Partial with Spatial Attention (C2PSA) mechanism, refining the information before it reaches the Head, which is responsible for final predictions, including bounding boxes, classifications, and masks. The basic blocks of its architecture are shown in Figure 3.
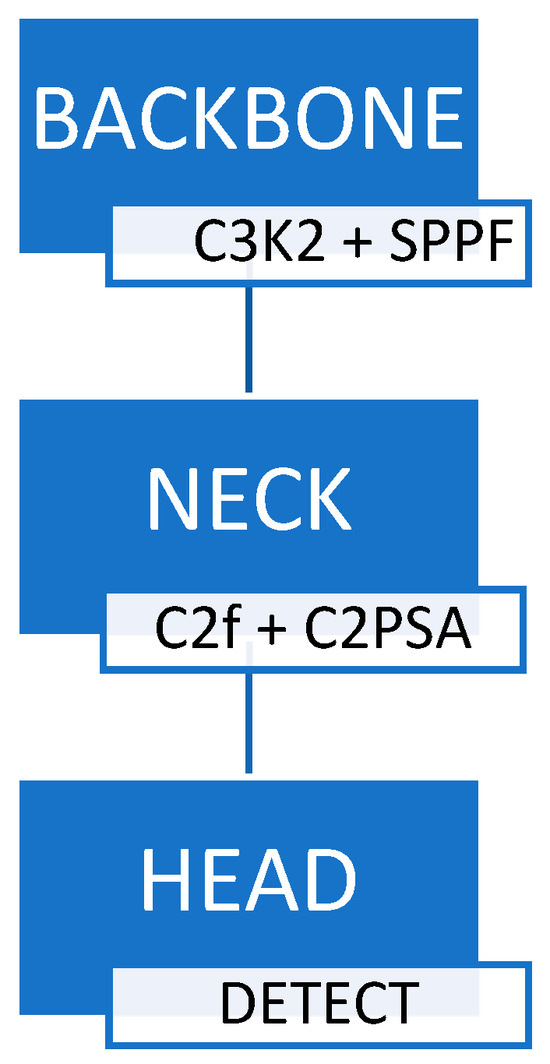
Figure 3.
YOLO11X-seg architecture block diagram.
There has been a notable improvement in YOLO11X-seg’s capability to handle varying image resolutions effectively. The model maintains high accuracy even when processing images at resolutions like 1280 × 1280 (displayed at 1920 × 1080), provided that the training data matches these dimensions, thus avoiding the pitfalls of upscaling and potential loss of detail. This ability ensures that YOLOv11 can be effectively utilized in scenarios requiring high-resolution image analysis, without compromising speed or accuracy.
When compared to its predecessors YOLOv8, YOLOv9, and YOLOv10, YOLO11X-seg demonstrates several improvements. It achieves higher mean Average Precision (mAP) scores, while utilizing approximately 22% fewer parameters, indicating a more efficient architecture. Additionally, YOLO11X-seg extends its applicability beyond traditional object detection, supporting tasks such as instance segmentation, pose estimation, and oriented object detection, thereby providing a comprehensive solution for various computer vision challenges. These enhancements position YOLO11X-seg as a superior choice for applications requiring a combination of speed, accuracy, and versatility in a streamlined model architecture. More information can be found in [29].
4. Dataset Creation
A dataset is created that includes 1669 images categorized into 28 distinct categories, with each class representing a specific word or letter. These images serve as the input data for the identification system. About 30–60 images are used for each class, as listed in Table 2.
Table 2.
Training dataset properties.
Labeling Images
In the training photographs, the gestures or handforms have to be mapped to letters or word. The LabelMe application is used to perform annotation. Tags are created for each photo separately. However, in order to have the best possible accuracy in the image, a polygon must be created around the handform in order to segment the photograph, as shown in Figure 4 (the annotated part of the photograph is displayed).
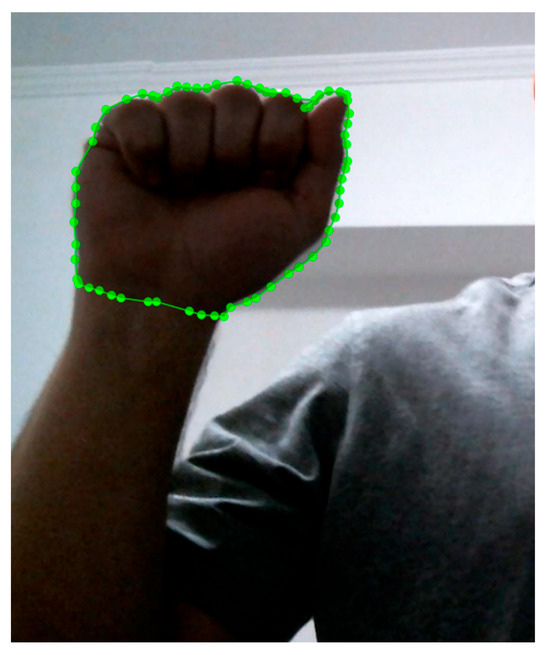
Figure 4.
Annotation of chiral form with LabelMe.
Annotation is performed on images that had different resolutions, different sizes, and different lighting conditions, as in the example in Figure 5.

Figure 5.
Photos from training dataset with different properties.
These 1669 images display a single user (the first author of this paper) and are used to train the sign language model. This does not pose any significant limitation since the system segments the input photograph and focuses on the handform. Thus, the features of the face and the rest of the body are not important in the training and test phase, and therefore the accuracy of the sign recognition is not significantly affected, as will be shown in the Experimental Results, where different users have also participated in the experiments. The background on the other hand does not have to be plain, although complicated backgrounds can make difficult the recognition of the hand contour and lead to false results. Moreover, a very bright light can also lead to failures because the camera cannot detect properly the hand in this case. However, the experimental results show that good recognition results are retrieved even against a complex background, although no particular condition has been developed for this case. Concerning a very bright light, this can be easily handled by preprocessing the image and shifting it to a darker color. Future work will focus on successfully segmenting the hand from complex backgrounds. The training dataset and the test set with the same user are publicly available in [30].
5. Experimental Setup and Results
The present study evaluates the effectiveness of the Greek Sign Language (GSL) recognition system through a number of experiments that test the accuracy of handform recognition under different lighting and background conditions. Initially, we present the details of the training process of YOLO11X-seg and the accuracy results achieved after each epoch.
Evaluation was initially conducted with images of the same person that appears in the training photographs in four different experimental settings: (i) photographs with a white background and bright lighting conditions, (ii) a black background with bright lighting, (iii) a white background with low light, and (iv) a black background with low light. The fact that all the photographs display the same person does not affect the accuracy since the system focuses on his hands. The results showed high success rates, particularly in good lighting conditions, where recognition was extremely accurate. The average success rate of the system was 99.11%, with success rates ranging from 99.88% in ideal lighting conditions to 97.86% in low-light environments with a darker background. In order to determine the accuracy of the model at class level, key performance metrics, such as Average Precision (AP), True Positives (TPs), False Positives (FPs), and False Negatives (FNs), were calculated. Letters and words with high average accuracy (100%) include most letters and all the words, while the letter “Y” showed the lowest accuracy (93.33%), probably due to its similarity to the handform of the word “Airplane”. Overall, the model’s performance was evaluated through mean Average Precision (mAP), which reached 99.07%, showing that the YOLO11X-seg can achieve maximum accuracy in GSL recognition. In addition, the high score of other indicators, like precision (99.48%), recall (99.57%), and F1-score (99.48%), confirm the model’s strong ability to correctly identify and classify the handforms.
5.1. Training YOLO11X-seg Details
The proposed system based on YOLO11X-seg was trained with 1669 labeled images covering 28 different classes. Each one of these classes can either be one of the twenty-four Greek letters or a GSL-specific word. YOLO11X-seg is trained on 640 pixel photographs, and the trained model contains 62.1 M parameters. Processing required 319 billion floating point operations (FLOPs). The advertised speed on a CPU ONNX interface is 664 ms, but this is reduced to 16 ms on a T4 TensorRT10 model. Training was performed using 100 epochs and eight batches on an NVIDIA GeForce GTX 1660 6144MiB. The details of the training configuration are listed in Table 3. Default augmentation settings were applied. The Ultralytics 8.3.170, Python 3.12.3, and Torch 2.6.0 versions were employed.
Table 3.
Details of training configuration.
During the training process, four loss parameters are listed after each epoch: (a) box loss related to the location error of the detected bounding box around the handform; (b) seg loss, which concerns the image segmentation accuracy; (c) cls loss, which concerns the classification correctness; and (d) distributed focal loss (dfl). Moreover, the mAP50, which is the mean Average Precision at 0.5 threshold for Intersection over Union (IoU), and the mAP50-95 at varying IoU thresholds, ranging from 0.50 to 0.95, are displayed both for the bounding box and the mask of the handform contour.
The evolution of box, seg, cls, and dfl loss, as well as of the mask mAP50 and mAP50-95 is shown for each epoch in Figure 6. The model’s box loss fell from over 1.2 to 0.259, cls loss stabilized at 0.1483, and seg loss plateaued near 0.8077. All the 24 letter classes exhibited robust detection and segmentation performances since most classes achieved mAP50 scores of at least 0.995. The worst-performing class maintained an mAP50-95 greater than 0.85. No significant class imbalance or performance degradation was identified. The best result for mAP50 (99.5%) was already achieved at epoch 42, and this precision was also achieved at the end of epoch 100. The best mAP50-95 (87.9%) was achieved at epoch 85 and is very close to the final 87.7% that was achieved at the end of training. These scores indicate a high level of object localization and a strong mask segmentation performance, with the model demonstrating recall and precision values that are close to the maximum, as will be shown in the next paragraphs.
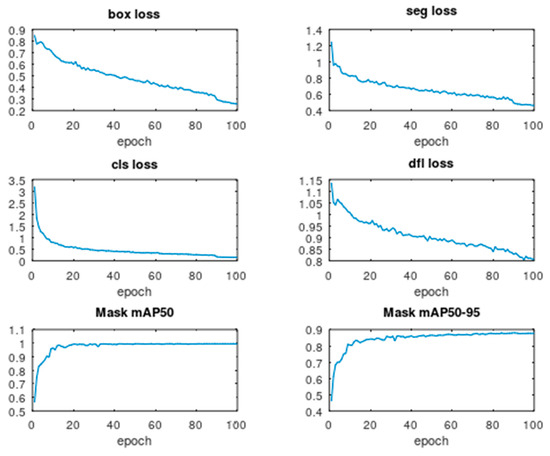
Figure 6.
Evolution of the loss and mAP functions over the 100 epochs.
5.2. Analysis of Handform Success Rates in Different Light and Background Conditions
Table 4 below shows the success rate of each handform, i.e., each letter of the Greek alphabet and the four Greek words examined. The experimental results were obtained against a separate background and lighting, with 30 handforms tested each time. A white background with good lighting (Figure 7a) was used thirty times, a black background with good lighting (Figure 7b) was used thirty times, and a white background with low light (Figure 7c) and a black background with low light (Figure 7d) were also used thirty times. Adding more words would not have affected the recognition accuracy for the existing words and letters. However, the training time would be significantly increased with more words.
Table 4.
The handforms’ success rate for the user that participated in the training dataset.

Figure 7.
Handform against white background with good lighting (a), black background with good lighting (b), white background and low light (c), and black background and low light (d). At the bottom left of each figure the recognized Greek word is displayed.
The overall success rates for the four different conditions are displayed in Table 5.
Table 5.
Overall success rates based on results in Table 4.
Different male and female users have also participated in the experiments in order to study a possible degradation in the accuracy achieved with the earlier single-user experiment. Examples of the female and male users appear in Figure 8 and Figure 9, respectively. Some photographs of the new users were captured in a controllable internal environment (Figure 8a,b and Figure 9a,b), while others were taken against a complex outdoor background (Figure 8c,d and Figure 9c,d). Success rates similar to those in Table 4 for the new users appear in Table 6. Additionally, the overall success rates of these categories are listed in Table 7.

Figure 8.
Greek letter “Δ” handform against white background with bright lighting (a), Greek word “AΕΡOΠΛAΝO” handform against white background with bright lighting (b), Greek letter “Υ” handform against outdoor, complex background with bright lighting (c), and Greek word “AΥΤOΚΙΝHΤO” handform against complex outdoor background with bright lighting (d). The recognized Greek word or letter is displayed at the bottom left of these figures.
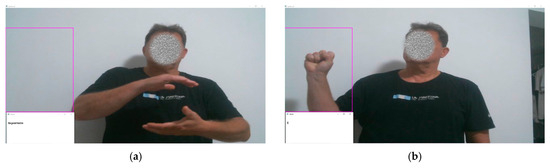

Figure 9.
Greek word “AΕΡOΣΤAΤO” handform against white background with bright lighting (a), Greek letter “Χ” handform against white background with bright lighting (b), Greek word “AΕΡOΠΛAΝO” handform against complex outdoor background with bright lighting (c), and Greek letter “A” handform against complex outdoor background with bright lighting (d). The recognized Greek words or letters are displayed at the bottom left of each figure.
Table 6.
Handforms’ success rates for new users.
Table 7.
Overall success rates based on results in Table 6.
5.3. Performance Evaluation of the Greek Sign Language Recognition System
The metrics below are commonly used in classification problems, especially in evaluating machine learning models like YOLO11X-seg for Sign Language Recognition.
- True Positive (TP) is the number of images correctly recognized as belonging to a class.
- True Negative (TN) is the images correctly recognized as not belonging to a class.
- False Positive (FP) (Type I Error) is the images that are falsely recognized to belong to a class.
- False Negative (FN) (Type II Error) is the images falsely excluded from the class they belong.
Average Precision (AP) is defined as follows:
Table 8 presents the class-by-class evaluation metrics, including accuracy, recall, and F1-score, for each letter and word in the dataset. This information not only validates the effectiveness of our model, but also guides future improvements in sign language recognition technology.
Table 8.
AP, TP, FP, and FN metrics for overall test set.
To assess the effectiveness of the proposed Greek Sign Language (GSL) recognition system, a comprehensive evaluation is conducted using key performance metrics. These metrics provide insight into the accuracy, robustness, and efficiency of the model in recognizing hand gestures.
The overall precision, recall, and F1-score were calculated to measure classification accuracy, while mAP and IoU were used to evaluate the detection performance with the test set. True Positives (TPs), False Positives (FPs), and False Negatives (FNs) were analyzed to quantify the correct and incorrect predictions.
Precision indicates the proportion of correctly identified gestures among all the detected instances, while recall reflects the model’s ability to recognize valid gestures. The F1-score balances precision and recall, offering a comprehensive measure of the overall performance.
The definitions of the performance metric used are as follows:
Mean Average Precision (mAP):
The results listed in Table 9 demonstrate that the system achieves high recognition accuracy, with an mAP of 99.07% and an overall precision of 99.48%. These findings highlight the model’s effectiveness in real-time sign language recognition, although minor misclassifications suggest areas for improvement, particularly in challenging lighting conditions.
Table 9.
Performance metrics of the Greek Sign Language recognition system for the overall test set.
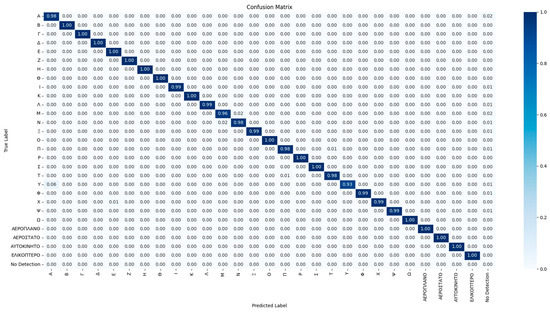
Figure 10.
Confusion matrix for overall test set.
5.4. Comparison with Related Works—Discussion
To assess the efficiency of the proposed system, we compared its accuracy with several state-of-the-art models from the existing literature addressing sign language recognition across various target languages and architectures. Our system attained an accuracy of 99.07%, surpassing those in the majority of the related works, as shown in Table 9. For example, systems employing LSTM and YOLOv6 for American Sign Language [6] reported accuracies of 92.0% and 96.0%, while a CNN-LSTM hybrid with MobileNetV2 [11] achieved only 84.65%. Advanced models such as ResNet-LSTM for Argentine Sign Language [7] and CNN-BiLSTM for Japanese Sign Language [13] reached accuracies of 86.25% and 84.13%, respectively. Although some individual architectures like Vision Transformers [8,9] reported very high accuracies (up to 99.98%), these often required extensive training with large datasets or multiple model ensembles. In contrast, our system maintains a competitive performance with a simpler and more efficient process. This demonstrates not only its superior accuracy, but also its extensibility across sign languages, as evidenced by its consistent performance and low error rates. Furthermore, our system outperforms technologies like YOLOv5 applied to British Sign Language [22], which reported only 70.0% accuracy, highlighting the robustness and applicability of our approach.
Concerning the number of signs recognized by each approach, it can be seen from Table 10 that most approaches recognized between 20 and 41 classes. Significantly larger numbers of classes are recognized in [11,12,13] (100, 744, and 78 signs, respectively). Latency for the recognition of a single sign is not reported in most cases. In [3], a large latency of more than 51 s is reported. The model developed in this approach was based on photographs of four women and four men at an age from 23 to 26. The fastest approach is found in [11], with only 30 ms per sign recognition. The dataset used in [11] comprises over 2000 words from over 100 signers, with 21,083 samples, and the authors experimented on a large subset of 100 glosses, with 2038 videos created by 97 signers. In [12], 116 ms is reported, which is much worse than the latency achieved with our architecture (42.7 ms). Six signers were used in [12]. The 42.7 ms latency of our approach stems from the fact that YOLO11X-seg inference needs between 36 ms and 38 ms, while 1.6 ms is needed for image preprocessing and about 3 ms for post-processing. This latency allows for a frame processing speed of about 23.4 fps.
Table 10.
Comparison of developed Greek Sign Language system with referenced approaches.
Although this development concerned the Greek alphabet and some Greek words, it is obvious that the exact system architecture and setup can be exploited for training different sign languages. This is due to the fact that no customized techniques have been applied for the identification of specific Greek handforms and gestures. Similar recognition accuracy results are expected if the system was trained with handforms that correspond to other alphabets and languages. Some sign recognition techniques that have been applied to multiple languages have been reported in [27,28]. The extension of the number of classes that is recognized in order to support more Greek words can be performed without significant degradation of the success rate in the recognition of letters and words. This was proven by the fact that the system was initially trained to recognize Greek letters only, and its recognition success rate did not become worse when an additional four Greek words were added in the set of recognizable handforms and gestures. However, the training time is exponentially increased when new handforms and gestures are added. Training with 1669 photographs required more than two days to complete on an Intel I7 9700K, Nvidia Gtx 1660 super GPU with 16 GB RAM platform.
The system is able to adapt to remote communication and supports a novel Region of Interest (ROI) mechanism to manage dynamic and static gestures. This research also identified challenges, including the need for a more diverse and extensive dataset to improve generalization, especially in varied lighting and hand orientation conditions. The initial dataset consisted of 1669 photographs from a single user (Figure 5). This dataset was used to train the model. However, other users also participated during testing, as shown in Figure 8 and Figure 9. The experimental results showed that the developed GSL system was able to recognize the signs from individuals who did not participate in the training process with almost the same accuracy (compare Table 4 with Table 6). This is explained by the fact that the system segments the input image and focuses on the hand of the user. Therefore, the other features of the user, such as his face and body type, do not affect the recognition results.
Although no sophisticated background separation techniques were employed in the context of the current work, it seems that the background of the hand did not affect the success rate much since complicated backgrounds had already been tested, as is shown in Figure 8c,d and Figure 9c,d. However, in our future work, we will investigate techniques that can be employed to separate backgrounds that resemble the color and shape of the hand.
Other recognition limitations, such as the model’s occasional difficulty to distinguish visually similar signs and its sensitivity to image quality and environmental factors, indicate areas for future improvement. This work establishes a practical foundation for the advancement of real-time sign language recognition technology, with the potential to assist deaf and hard-of-hearing individuals and to promote social inclusion through AI-driven solutions.
6. Conclusions
This study introduced and evaluated a real-time Greek Sign Language (GSL) recognition system using YOLO11X-seg and embedded computing platforms, addressing a gap in sign language research, particularly for less-frequently represented languages like Greek. The proposed architecture can be extended or simply trained to cover different sign languages. The system achieved a high mAP of 99.07% in recognizing both Greek letters and specific words and demonstrated the feasibility of deploying deep learning models. Furthermore, the developed system offers both mobility and scalable processing power since a portable module consisting of a camera connected to Raspberry Pi 4 communicates wirelessly to the main computer. Depending on the size of the trained GSL model, its inference can be executed either on an embedded device or on a main computer, which can be a GPU-featured server with high processing power. Therefore, fast execution of large GSL models can be achieved without sacrificing the mobility of the system.
In addition to its technical achievements, this research illustrates the potential of AI-powered sign language systems to improve accessibility and enable more inclusive communication for the deaf and hard-of-hearing communities. Future efforts should focus on expanding the dataset, refining the model architecture, and exploring hybrid deep learning models to enhance performance. Enhancing robustness under challenging conditions, integrating mobile and portable platforms, and incorporating complementary sensory inputs such as depth data will be investigated in our future research.
Author Contributions
Conceptualization, I.P., E.T. and L.H.; methodology, I.P. and E.T.; software, I.P.; validation, I.P., E.T., N.P. and L.H.; formal analysis, I.P. and N.P.; investigation, I.P. and E.T.; resources, I.P., E.T. and L.H.; data curation, I.P., E.T. and N.P.; writing—original draft preparation, I.P., E.T., N.P.; writing—review and editing, N.P., L.H.; visualization, I.P.; supervision, E.T. and L.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Cooper, H.; Ong, E.-J.; Pugeault, N.; Bowden, R. Sign Language Recognition Using Sub-Units. J. Mach. Learn. Res. 2012, 13, 2205–2231. [Google Scholar] [CrossRef]
- Ben Haj Amor, A.; El Ghoul, O.; Jemni, M. Sign Language Recognition Using the Electromyographic Signal: A Systematic Literature Review. Sensors 2023, 23, 8343. [Google Scholar] [CrossRef]
- Filipowska, A.; Filipowski, W.; Mieszczanin, J.; Bryzik, K.; Henkel, M.; Skwarek, E.; Raif, P.; Sieciński, S.; Doniec, R.; Mika, B.; et al. Pattern Recognition in the Processing of Electromyographic Signals for Selected Expressions of Polish Sign Language. Sensors 2024, 24, 6710. [Google Scholar] [CrossRef]
- Umut, İ.; Kumdereli, Ü.C. Novel Wearable System to Recognize Sign Language in Real Time. Sensors 2024, 24, 4613. [Google Scholar] [CrossRef] [PubMed]
- Liang, Y.; Jettanasen, C.; Chiradeja, P. Progression Learning Convolution Neural Model-Based Sign Language Recognition Using Wearable Glove Devices. Computation 2024, 12, 72. [Google Scholar] [CrossRef]
- Buttar, A.M.; Ahmad, U.; Gumaei, A.H.; Assiri, A.; Akbar, M.A.; Alkhamees, B.F. Deep Learning in Sign Language Recognition: A Hybrid Approach for the Recognition of Static and Dynamic Signs. Mathematics 2023, 11, 3729. [Google Scholar] [CrossRef]
- Huang, J.; Chouvatut, V. Video-Based Sign Language Recognition via ResNet and LSTM Network. J. Imaging 2024, 10, 149. [Google Scholar] [CrossRef]
- Alsharif, B.; Altaher, A.S.; Altaher, A.; Ilyas, M.; Alalwany, E. Deep Learning Technology to Recognize American Sign Language Alphabet. Sensors 2023, 23, 7970. [Google Scholar] [CrossRef] [PubMed]
- Kondo, T.; Narumi, S.; He, Z.; Shin, D.; Kang, Y. A Performance Comparison of Japanese Sign Language Recognition with ViT and CNN Using Angular Features. Appl. Sci. 2024, 14, 3228. [Google Scholar] [CrossRef]
- Noor, T.H.; Noor, A.; Alharbi, A.F.; Faisal, A.; Alrashidi, R.; Alsaedi, A.S.; Alharbi, G.; Alsanoosy, T.; Alsaeedi, A. Real-Time Arabic Sign Language Recognition Using a Hybrid Deep Learning Model. Sensors 2024, 24, 3683. [Google Scholar] [CrossRef] [PubMed]
- Kumari, D.; Anand, R.S. Isolated Video-Based Sign Language Recognition Using a Hybrid CNN-LSTM Framework Based on Attention Mechanism. Electronics 2024, 13, 1229. [Google Scholar] [CrossRef]
- Akdag, A.; Baykan, O.K. Enhancing Signer-Independent Recognition of Isolated Sign Language through Advanced Deep Learning Techniques and Feature Fusion. Electronics 2024, 13, 1188. [Google Scholar] [CrossRef]
- Lu, C.; Kozakai, M.; Jing, L. Sign Language Recognition with Multimodal Sensors and Deep Learning Methods. Electronics 2023, 12, 4827. [Google Scholar] [CrossRef]
- Gu, Y.; Oku, H.; Todoh, M. American Sign Language Recognition and Translation Using Perception Neuron Wearable Inertial Motion Capture System. Sensors 2024, 24, 453. [Google Scholar] [CrossRef]
- Wang, Y.; Jiang, H.; Sun, Y.; Xu, L. A Static Sign Language Recognition Method Enhanced with Self-Attention Mechanisms. Sensors 2024, 24, 6921. [Google Scholar] [CrossRef] [PubMed]
- Pu, M.; Lim, M.K.; Chong, C.Y. Siformer: Feature-Isolated Transformer for Efficient Skeleton-Based Sign Language Recognition. In Proceedings of the 32nd ACM International Conference on Multimedia, Melbourne, VIC, Australia, 28 October–1 November 2024; pp. 9387–9396. [Google Scholar] [CrossRef]
- Li, R.; Meng, L. Multi-View Spatial-Temporal Network for Continuous Sign Language Recognition. arXiv 2022. [Google Scholar] [CrossRef]
- Zuo, R.; Wei, F.; Mak, B. Towards Online Continuous Sign Language Recognition and Translation. arXiv 2024. [Google Scholar] [CrossRef]
- Srivastava, S.; Singh, S.; Pooja; Prakash, S. Continuous Sign Language Recognition System Using Deep Learning with MediaPipe Holistic. arXiv 2024. [Google Scholar] [CrossRef]
- Madhiarasan, M.; Roy, P.P. A Comprehensive Review of Sign Language Recognition: Different Types, Modalities, and Datasets. arXiv 2022. [Google Scholar] [CrossRef]
- Awaluddin, B.-A.; Chao, C.-T.; Chiou, J.-S. A Hybrid Image Augmentation Technique for User- and Environment-Independent Hand Gesture Recognition Based on Deep Learning. Mathematics 2024, 12, 1393. [Google Scholar] [CrossRef]
- Aldahir, R.; Grau, R.R. Using Convolutional Neural Networks for Visual Sign Language Recognition: Towards a System That Provides Instant Feedback to Learners of Sign Language. In Proceedings of the 21st International Web for All Conference, Singapore, 13–14 May 2024; pp. 70–74. [Google Scholar] [CrossRef]
- Sharma, A.; Guo, D.; Parmar, A.; Ge, J.; Li, H. Promoting Sign Language Awareness: A Deep Learning Web Application for Sign Language Recognition. In Proceedings of the 2024 8th International Conference on Deep Learning Technologies, Suzhou, China, 15–17 July 2024; pp. 22–28. [Google Scholar] [CrossRef]
- Bhadouria, A.; Bindal, P.; Khare, N.; Singh, D.; Verma, A. LSTM-Based Recognition of Sign Language. In Proceedings of the 2024 Sixteenth International Conference on Contemporary Computing, Noida, India, 8–10 August 2024; pp. 508–514. [Google Scholar] [CrossRef]
- Alayed, A. Machine Learning and Deep Learning Approaches for Arabic Sign Language Recognition: A Decade Systematic Literature Review. Sensors 2024, 24, 7798. [Google Scholar] [CrossRef] [PubMed]
- Borges-Galindo, E.A.; Morales-Ramírez, N.; González-Lee, M.; García-Martínez, J.R.; Nakano-Miyatake, M.; Perez-Meana, H. Sign Language Interpreting System Using Recursive Neural Networks. Appl. Sci. 2024, 14, 8560. [Google Scholar] [CrossRef]
- Antad, S.M.; Chakrabarty, S.; Bhat, S.; Bisen, S.; Jain, S. Sign Language Translation Across Multiple Languages. In Proceedings of the IEEE 2024 International Conference on Emerging Systems and Intelligent Computing (ESIC), Bhubaneswar, India, 9–10 February 2024; pp. 741–746. [Google Scholar] [CrossRef]
- Priyadharshini, D.S.; Anandraj, R.; Prasath, K.R.G.; Manogar, S.A.F. A Comprehensive Application for Sign Language Alphabet and World Recognition, Text-to-Action Conversion for Learners, Multi-Language Support and Integrated Voice Output Functionality. In Proceedings of the IEEE 2024 International Conference on Science Technology Engineering and Management (ICSTEM), Coimbatore, India, 26–27 April 2024; pp. 1–5. [Google Scholar] [CrossRef]
- Ultralytics. YOLO11 Documentation. 2025. Available online: https://docs.ultralytics.com/models/yolo11/ (accessed on 28 July 2025).
- Dataset Used in This Article. Available online: https://drive.google.com/drive/folders/1TVxQ6NtMGzTIhgr5rTOerL1RwtF9JksA?usp=sharing (accessed on 28 July 2025).
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).