
User Preference-Based Dynamic Optimization of Quality of Experience for Adaptive Video Streaming


Abstract
1. Introduction
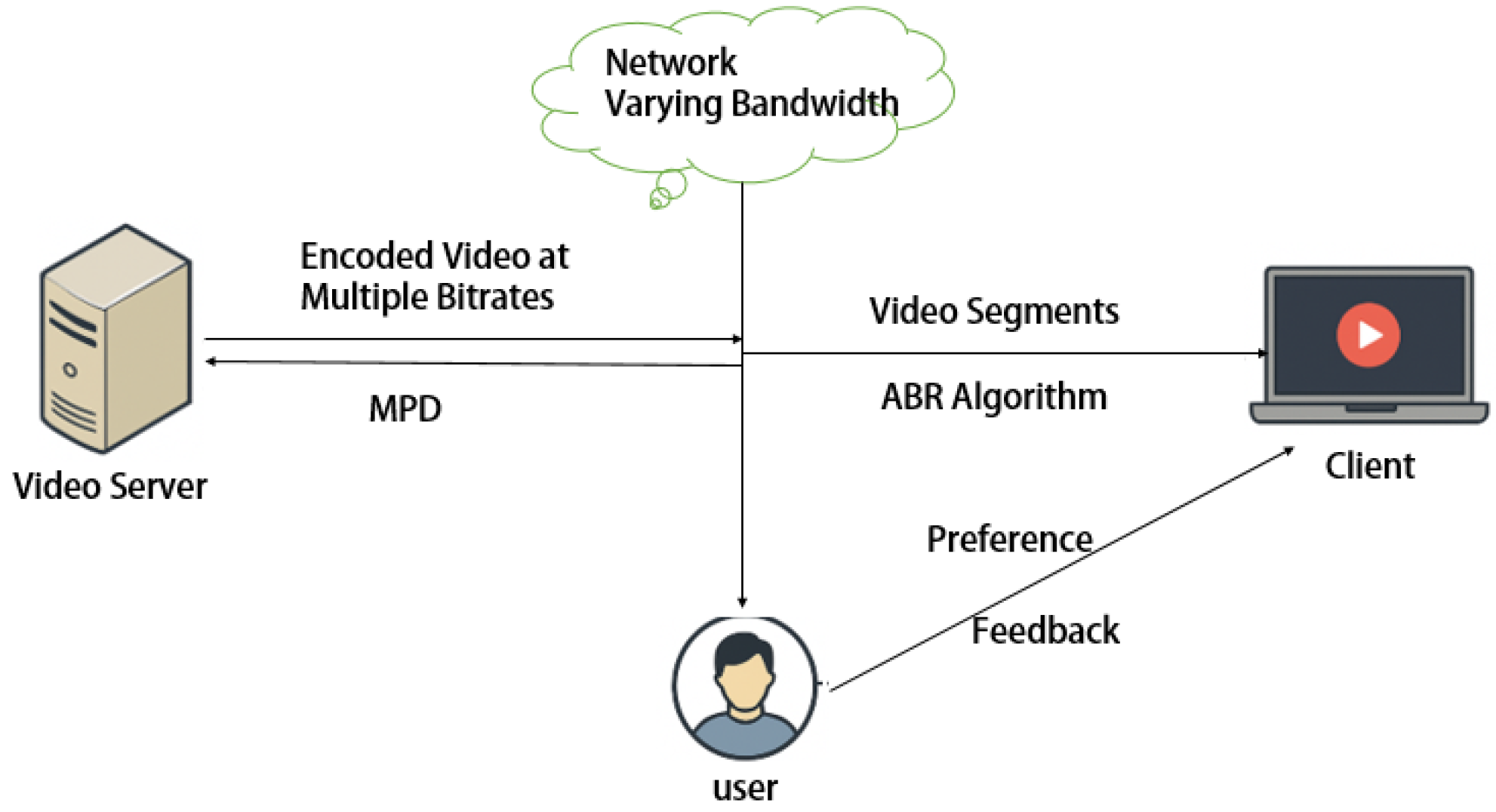
1.1. Research Background
1.2. Research Motivation
- (1)
- Aligning policy optimization with user perceptions;
- (2)
- Enabling dynamic, individualized reward signals;
- (3)
- Reducing manual reward tuning overhead;
- (4)
- Enhancing interpretability and adaptability of RL-based ABR strategies.
1.3. Research Contributions
- (1)
- Trajectory Sampling Module: Multiple ABR agents interact with a simulated environment to collect playback trajectories (states, actions, video metrics).
- (2)
- Preference Modeling Module: An LSTM-based preference network is trained to score trajectories via pairwise comparisons.
- (3)
- Policy Training Module: The preference model’s outputs replace traditional rewards, enabling PPO-based ABR policy training.
- (1)
- Designing a multi-dimensional state encoding and trajectory data structure for preference modeling;
- (2)
- Developing methods for generating preference pairs (automated and human-annotated);
- (3)
- Adapting the PPO framework for preference-driven policy updates;
- (4)
- Experimental validation of the strategy’s performance in quality, stalling control, and subjective consistency.
1.4. Thesis Structure
2. Literature Review
2.1. Evolution of Adaptive Bitrate Algorithms
2.2. User Experience Modeling and Preference Learning
2.2.1. QoE Metrics for DASH
- (1)
- Instantaneous Visual Quality: The visual quality of the current video segment plays a crucial role in QoE. Since video sequences are encoded at the server into different representations, the resulting impairments are typically quantified through Video Quality Assessment (VQA). From the perspective of original video availability, VQA methods can be categorized into three types: full-reference, reduced-reference, and no-reference approaches. In most cases, full-reference VQA provides the most accurate visual quality assessment. Therefore, this paper adopts the full-reference method, specifically Structural Similarity (SSIM), as the visual quality metric for QoE evaluation in DASH. Although computationally intensive, the SSIM values for each segment can be pre-computed on the video server and embedded in the MPD file before being requested by the client. Thus, Equations (1) and (2) can be expressed aswhere and represent the mean luminance values of image and image , respectively, and denote the standard deviations of luminance, and is the covariance, while and are small constants preventing division by zero. These constants take values and , where represents the pixel value dynamic range, with and .The Structural Similarity Index (SSIM) yields values within the range [0, 1], where values approaching 1 indicate higher inter-frame similarity and superior visual quality. To reduce computational complexity, this study precomputes SSIM values for all bitrate-encoded video segments at the server side and embeds them within the Media Presentation Description (MPD) file. During playback, clients directly retrieve these precomputed SSIM values as inputs for Quality of Experience (QoE) assessment.
- (2)
- Quality Oscillation: Furthermore, quality oscillation constitutes another critical QoE metric unique to DASH technology. The DASH adaptation mechanism dynamically adjusts bitrates based on real-time bandwidth conditions and client buffer status, which may cause significant visual quality variations across consecutive video segments. Such fluctuations substantially degrade QoE in DASH systems, making quality oscillation an essential metric for comprehensive QoE evaluation.
- (3)
- Rebuffering Events: As another fundamental QoE metric, rebuffering events have been widely adopted in existing DASH adaptation schemes. Minimizing rebuffering duration or frequency enhances playback smoothness, thereby reducing visual discomfort for viewers. Notably, users typically perceive rebuffering events as more disruptive than initial playback delays.
2.2.2. Preference Learning
- (1)
- Better alignment with human judgment paradigms (e.g., “Which do you prefer?”);
- (2)
- Superior suitability for modeling highly subjective problems;
- (3)
- Effective utilization of limited labeled data to generate high-quality training signals.
2.3. Mathematical Model of DASH
2.4. Summary and Analysis
- (1)
- Misaligned Policy Objectives: Uniform reward functions fail to address personalized user requirements.
- (2)
- Ineffective Preference Modeling: Existing methods predominantly depend on objective metric regression, overlooking preference judgment signals.
- (3)
- Limited Scalability and Adaptability: Fixed parameters cannot be effectively transferred to multi-user, multi-scenario environments.
3. System Design and Architecture
3.1. System Design Objectives
- (1)
- Personalization: Support subjective trade-offs between video quality and smoothness through preference modeling.
- (2)
- Adaptability: Enable reinforcement learning policies to continuously adjust to dynamic network conditions.
- (3)
- Modularity: Maintain a clearly layered system design for independent optimization and testing of components.
- (4)
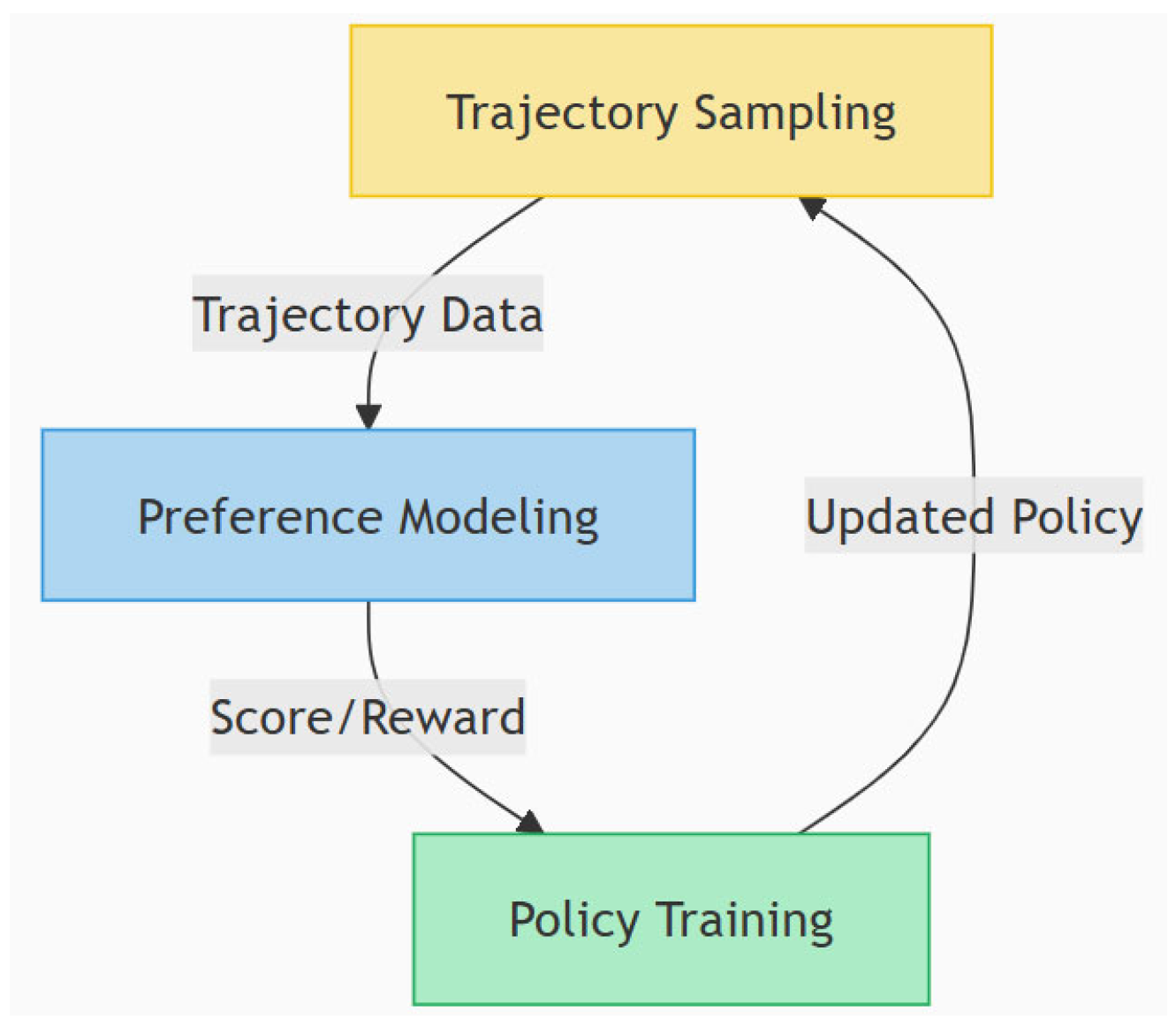
- Training Efficiency: Support parallel trajectory sampling and periodic policy updates to reduce training time. Based on these objectives, the system is divided into three functional modules: Trajectory Sampling Module Preference, Modeling Module, and Policy Training Module. These modules work together to form a closed-loop policy optimization process.
3.2. System Architecture
- (1)
- Trajectory Sampling Module (Agent + Simulated Env): Interacts with a simulated video playback environment to collect trajectory data comprising states, actions, and initial rewards.
- (2)
- Preference Modeling Module (Preference Net): Employs an LSTM network to score trajectories, capturing users’ subjective preferences for video streaming experiences.
- (3)
- Policy Training Module (PPO + Reward Reformulation): Performs PPO policy training, using preference scores as surrogate rewards to drive policy updates.
3.3. Trajectory Sampling Module
Trajectory Sampling
- (1)
- Policy synchronization: Updates the local network with the latest PPO policy parameters from the main process.
- (2)
- Environment interaction: Executes TRAIN_SEQ_LEN = 1000 steps per episode, recording the following: State: state ∈ ℝ^ {6 × 8}, Action: action ∈ {0, 1, …, 5} (bitrate index), and Reward: environment’s immediate reward.
- (3)
- Experience reporting: Sends trajectories (states/actions/policy probabilities) via inter-process queue.
- (4)
- Trajectory archiving: Stores trajectories as JSON files every 10 episodes; JSON trajectory structure (per step): state: 6-dimensional signal history (8-step matrix); action: selected bitrate index; reward: immediate environment reward; video_quality: quality metric; rebuffer_time: stalling duration; download_speed: measured bandwidth. This design ensures the following: sufficient policy–environment interaction, high-quality raw trajectory data for preference modeling.
3.4. Preference Modeling Module
3.4.1. Preference Data Construction
3.4.2. Preference Network Architecture
- (1)
- Input layer: The trajectory tensor is and first flattened to .
- (2)
- Temporal modeling layer: Stacked LSTM (Long Short-Term Memory) modules for extracting temporal dependencies in trajectories.
- (3)
- Score output layer: An MLP network that projects the final hidden state of the LSTM into a scalar score.
3.4.3. Training Method
- (1)
- Input: A set of trajectory pairs (, ).
- (2)
- Model output: Corresponding scores (score_i, score_j) for each trajectory.
- (3)
- Objective function: Computes BCE loss between the sigmoid-transformed score difference and preference labels.whereindicates preference for ;0 indicates preference for ;0.5 indicates uncertain preference.
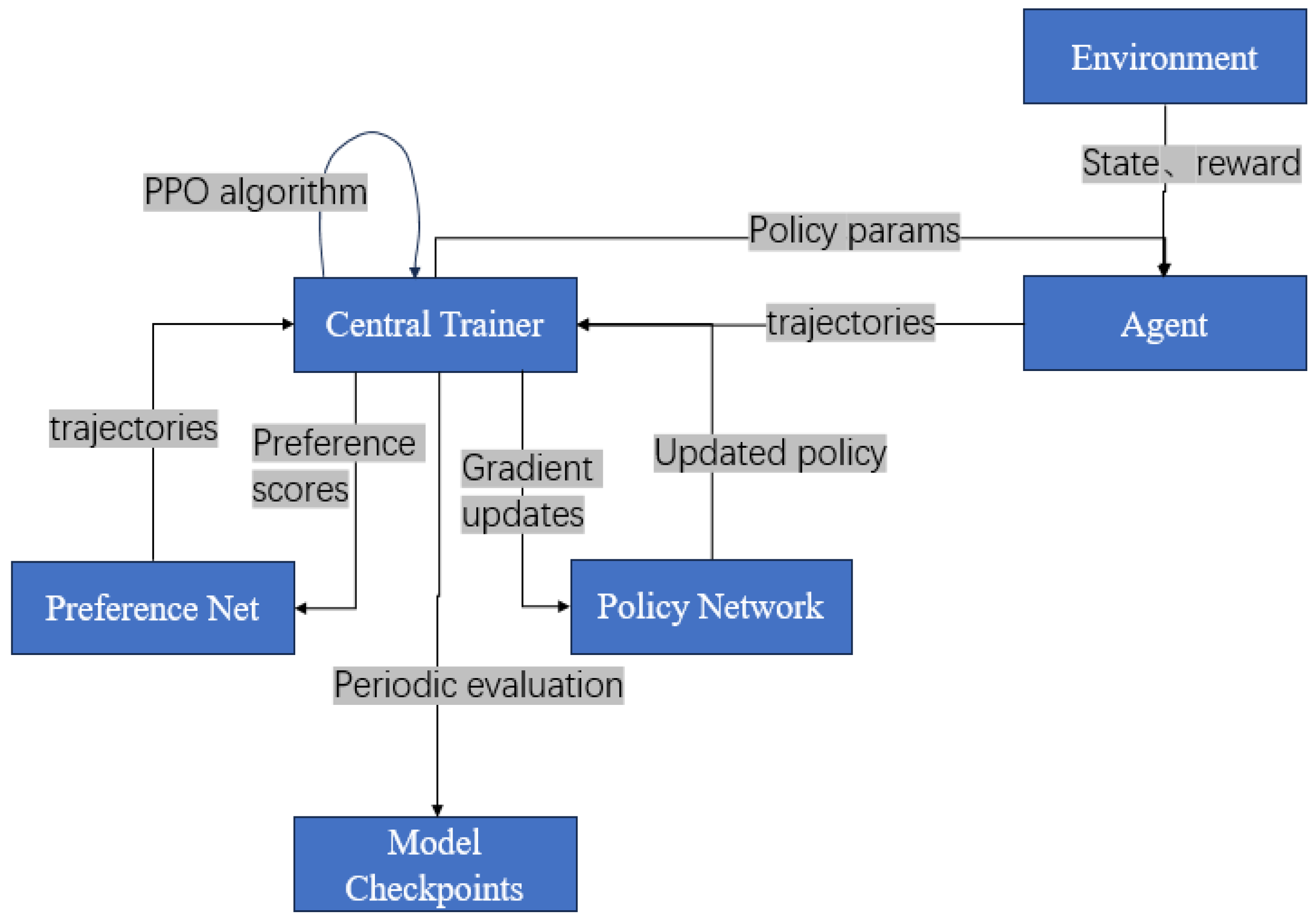
3.5. Main Training Module
- (1)
- Parameter Broadcasting: The main process distributes current policy network parameters to all sampling agents via queues;
- (2)
- Experience Collection: Waits for all agents to return sampled trajectories;
- (3)
- Preference Scoring: Uses the preference model to score each trajectory as alternative rewards for the current iteration;
- (4)
- Data Organization: Constructs batches of states (s_batch), actions (a_batch), probabilities (p_batch), and preference scores (v_batch);
- (5)
- Policy Optimization: Executes one policy update using the PPO network;
- (6)
- Periodic Testing: Conducts policy performance evaluation every few iterations, recording metrics such as test reward and entropy;
- (7)
- Model Saving: Periodically saves model parameters to local storage.
- (1)
- State: The agent’s observation state that comprises multiple dynamic metrics. The historical QoE metric reflects the user experience quality of the previous video segments. The buffer state quantifies the current buffer capacity, while the bandwidth estimate records real-time network throughput. The expected bandwidth requirement calculates the necessary bandwidth value to meet maximum switching conditions. Additionally, represents client-side QoE, reflecting end-users’ perceived quality level in real time.
- (2)
- Action: The agent’s action space is defined as a discrete set , where each value corresponds to a specific video bitrate option.
- (3)
- Reward: The system incorporates a preference modeling mechanism, where the trained Preference Net scores complete trajectories as shown in Equation (9).This reward substitution mechanism aligns the policy learning objective more closely with users’ subjective experience preferences, thereby constructing a user-oriented ABR strategy.
- (4)
- The policy network is defined as
3.6. Model Training
Module Coordination Workflow
- (1)
- Sampling Phase (Agent Sampling)Multiple agents concurrently interact with the ABREnv simulation environment. Each agent collects state–action–policy probability trajectories over multiple steps and transmits them to the central trainer. A subset of trajectories is saved as JSON files for preference model training.
- (2)
- Preference Modeling Phase (Preference Net Scoring)The central trainer invokes the preference network to assign scalar subjective scores to trajectories, which replace traditional rewards. This step directly incorporates user experience feedback into policy optimization.
- (3)
- Policy Optimization Phase (PPO Training)This aggregates state sequences (s_batch), actions (a_batch), policy probabilities (p_batch), and preference scores (v_batch) into training data. It executes one PPO policy update, with results distributed to agents for the next sampling round, closing the loop.
| Algorithm 1: A reinforcement learning training framework that integrates user preference modeling. |
| 1: Initialize policy network parameters , preference model, sampling agent set, and set initial parameters for the value network |
| 2: Complete the environment configuration for all agent |
| 3: for do: |
| 4: for each agent do: |
| 5: Each agent interacts with the simulated environment to collect trajectory “traj” 6: Upload trajectory data to the central training process 7: Save the trajectory as a JSON file for preference model training purposes 8: end for 8: The main process receives all trajectories “traj” 9: for each agent do: 10: Use preference model scoring to obtain alternative rewards “reward” 11: end for 12: Construct training batches “batch” 13: Calculating Advantage Estimation Based on PPO Algorithm 14: Update policy network parameters 15: Conduct strategy testing, record performance metrics, and save model parameters |
| 16: end for |
| 17: end for |
| 18: end for |
4. System Implementation and Experimental Design
4.1. Experimental Setup and Evaluation Metrics
4.2. Evaluation Metrics
- (1)
- Average Bitrate Quality Level: This metric calculates the mean bitrate quality of dynamically requested media segments to determine the actual visual quality level obtained by users. Higher average bitrate levels correspond to higher-resolution media content, directly reflecting QoE improvement. In adaptive streaming systems, this metric serves as a core optimization objective function parameter, enabling clients to dynamically adjust request strategies based on real-time network throughput to achieve balanced optimization of transmission quality and user experience.
- (2)
- Video Quality Switch Count: While DASH protocol adapts video bitrates dynamically to network changes, frequent large bitrate fluctuations may cause noticeable quality jumps that degrade viewing experiences. Optimization strategies must balance bandwidth utilization with visual consistency by reducing the frequency of significant bitrate switches to maintain stable perceived quality.
- (3)
- Rebuffering Time: This is the total pause duration during playback caused by insufficient buffering, representing one of the most significant factors affecting user experience. Each noticeable rebuffering event typically causes sharp declines in user satisfaction and is often incorporated as a negative value in reward calculations to penalize such behavior.
- (4)
- QoE: A comprehensive metric for evaluating video viewing experience that is primarily composed of three key elements: video quality, bitrate switch frequency/magnitude, and buffering events. It is calculated by combining these three components.
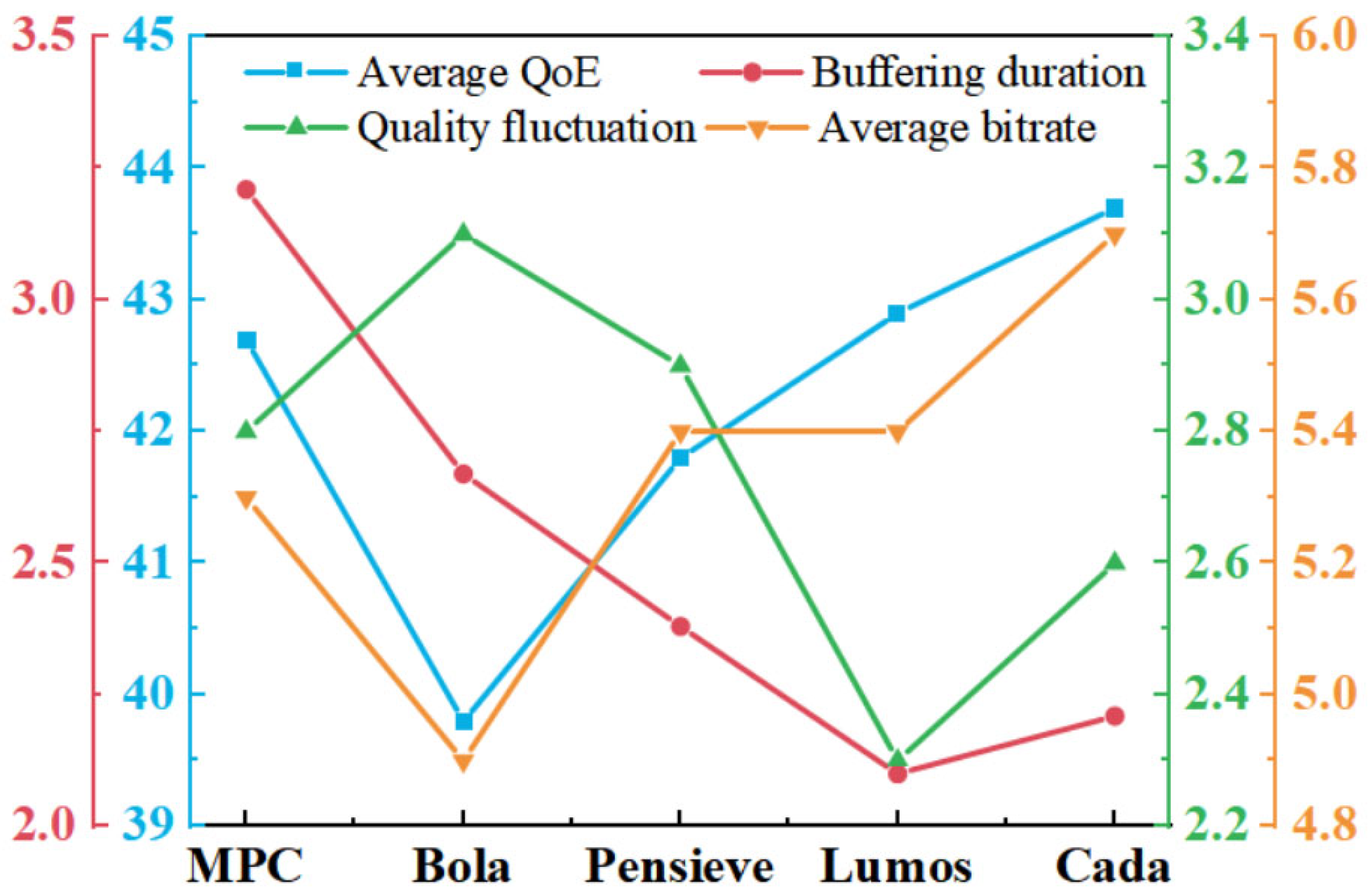
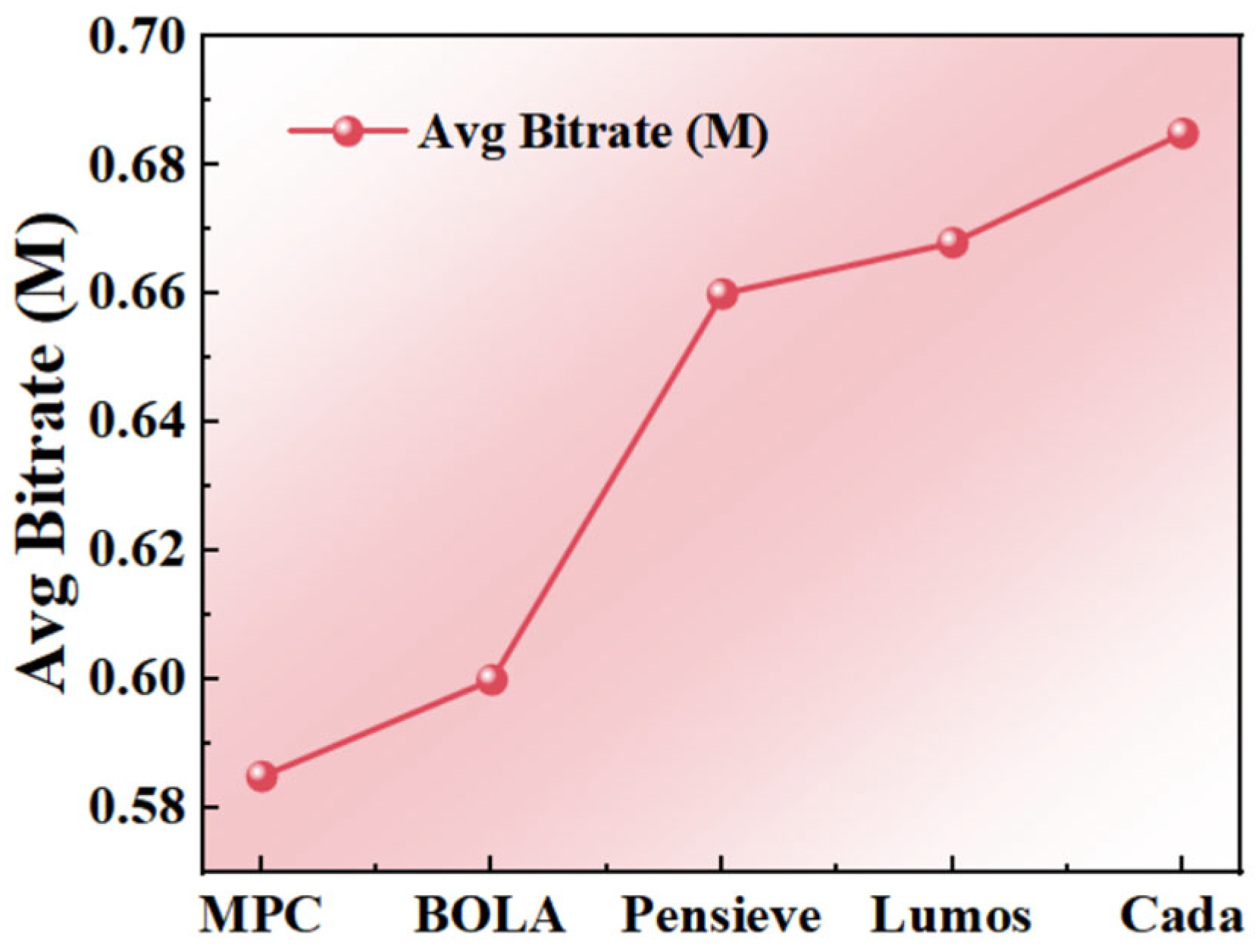
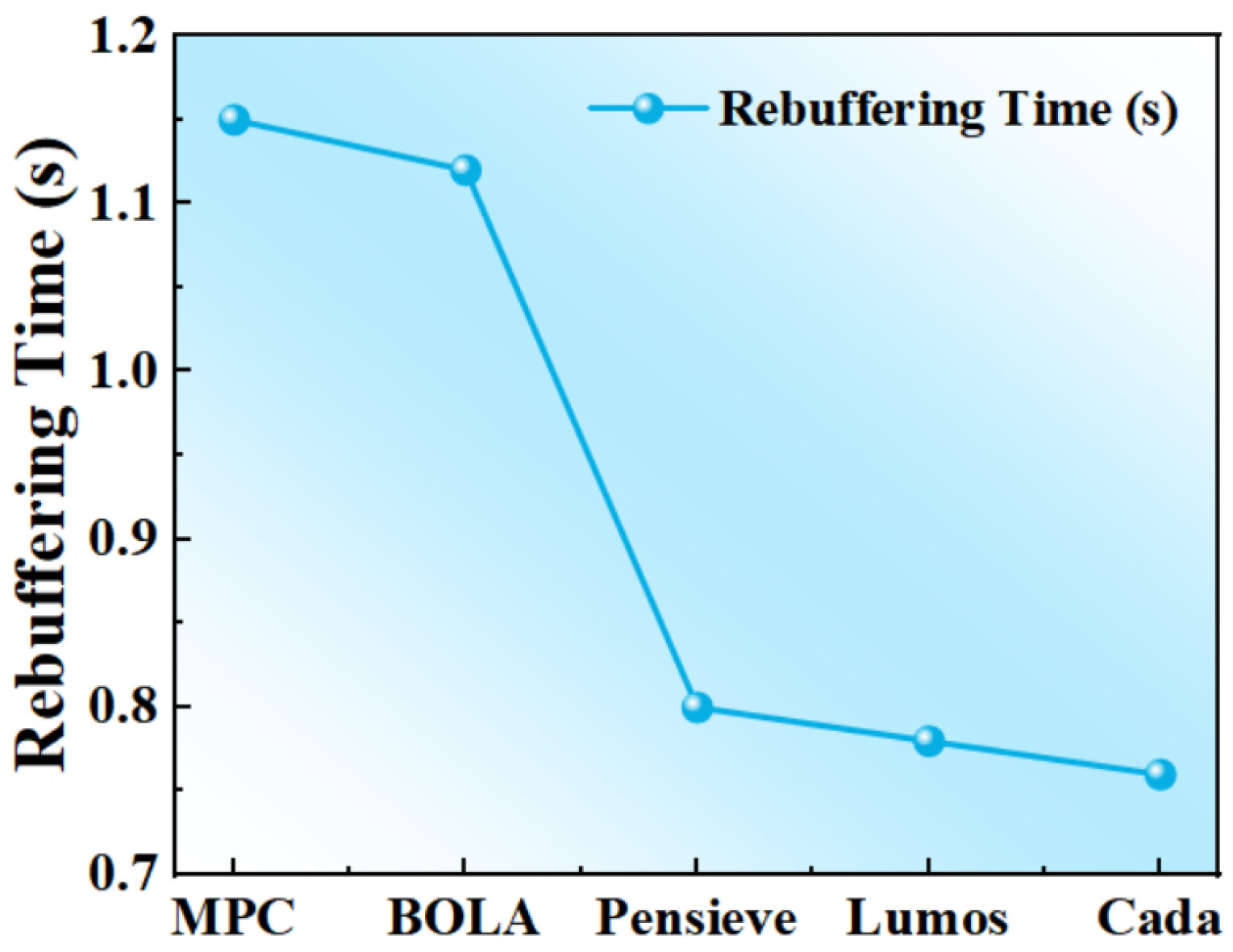
4.3. Comparative Experiments
- (1)
- MPC [13]: As a conventional bitrate adaptation algorithm, it employs multi-step prediction within a sliding time window to optimize bitrate decisions. Its core methodology involves the following: (i) forecasting future network conditions based on historical throughput measurements, (ii) constructing an optimization problem by integrating a dynamic buffer state model, and (iii) performing time-domain rolling optimization to balance video quality, rebuffering risk, and playback smoothness.
- (2)
- BOLA [9]: As a representative static heuristic algorithm, BOLA reformulates bitrate selection as a queue stability control problem within the Lyapunov optimization framework. Its key characteristics include the following: (i) employing a virtual buffer queue to enable smooth bitrate transitions, (ii) leveraging control-theoretic principles to guarantee system stability, and (iii) demonstrating exceptional buffer regulation performance in single-user scenarios. Owing to its mathematical rigor and implementation simplicity, BOLA is widely adopted as a benchmark algorithm in related research.
- (3)
- Pensieve [2]: A state-of-the-art ABR solution that leverages deep reinforcement learning for end-to-end bitrate decision optimization. Combining offline training and online inference, it improves bitrate selection accuracy in complex network environments and is considered a representative benchmark.
- (4)
- Lumos [26]: This is a decision tree-based throughput predictor designed to enhance bitrate selection accuracy in adaptive video streaming (ABR) algorithms, consequently optimizing Quality of Experience (QoE) by providing reliable throughput estimates for bandwidth-sensitive adaptation decisions.
- (5)
- Our Method (PPO + Preference Modeling): This incorporates a user preference network as the reward function to enhance training efficiency and policy rationality.
4.4. Ablation Study Analysis
- (1)
- Baseline Pensieve: Uses conventional environmental rewards, single-threaded trajectory sampling, and excludes preference modeling (original PPO-based Pensieve architecture).
- (2)
- Preference-Modeling Version (PPO + Preference Net): Replaces environmental rewards with Preference Net scores, optimizing for user preference. This version shows marked improvement in video quality and user satisfaction metrics, better approximating subjective user experience.
- (3)
- Complete Version (PPO + Multi-process + Preference Reward): Integrates all proposed modules as our final optimized strategy. It achieves optimal performance across QoE, average bitrate, and rebuffering time, demonstrating superior generalization capability and robustness.
4.5. Extended Experiments on Public Datasets
5. Conclusions and Future Work
- (1)
- Limited Automation in Preference Data Generation: Current trajectory pair construction depends on sampling quantity; future work could explore active learning and preference augmentation techniques.
- (2)
- Static Preference Model: The current Preference Net operates as a fixed scorer without joint optimization during policy training; future research could investigate online updates and co-optimization mechanisms.
- (3)
- Network Architecture Enhancement: Beyond LSTM, future work may explore Transformer-based encoders for better long-term dependency modeling and scoring accuracy.
- (4)
- More Realistic User Evaluation: Future studies could incorporate subjective ratings and real-world user feedback (e.g., click-through data) to further refine the preference model.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cisco, U. Cisco Annual Internet Report (2018–2023) White Paper; Cisco: San Jose, CA, USA, 2020; Volume 10, pp. 1–35. [Google Scholar]
- Mao, H.; Netravali, R.; Alizadeh, M. Neural Adaptive Video Streaming with Pensieve; ACM Special Interest Group on Data Communication; ACM: Singapore, 2017. [Google Scholar] [CrossRef]
- Wirth, C.; Akrour, R.; Neumann, G.; Fürnkranz, J. A survey of preference-based reinforcement learning methods. J. Mach. Learn. Res. 2017, 18, 1–46. [Google Scholar]
- Jiang, J.; Sekar, V.; Zhang, H. Improving fairness, efficiency, and stability in http-based adaptive video streaming with festive. In Proceedings of the 8th International Conference on Emerging Networking Experiments and Technologies, Florham Park, NJ, USA, 15 September 2012; pp. 97–108. [Google Scholar]
- Sun, Y.; Yin, X.; Jiang, J.; Sekar, V.; Lin, F.; Wang, N.; Liu, T.; Sinopoli, B. CS2P: Improving video bitrate selection and adaptation with data-driven throughput prediction. In Proceedings of the 2016 ACM SIGCOMM Conference, Florianópolis, Brazil, 22–26 August 2016; pp. 272–285. [Google Scholar]
- Akhtar, Z.; Nam, Y.S.; Govindan, R.; Rao, S.; Chen, J.; Katz-Bassett, E.; Ribeiro, B.; Zhan, J.; Zhang, H. Oboe: Auto-tuning video ABR algorithms to network conditions. In Proceedings of the 2018 Conference of the ACM Special Interest Group on Data Communication, Budapest, Hungary, 20–25 August 2018; pp. 44–58. [Google Scholar]
- Gao, X.; Song, A.; Hao, L.; Zou, J.; Chen, G.; Tang, S. Towards efficient multi-channel data broadcast for multimedia streams. IEEE Trans. Parallel Distrib. Syst. 2019, 30, 2370–2383. [Google Scholar] [CrossRef]
- Huang, T.Y.; Johari, R.; McKeown, N.; Trunnell, M.; Watson, M. A buffer-based approach to rate adaptation: Evidence from a large video streaming service. ACM 2014, 12, 187–198. [Google Scholar]
- Spiteri, K.; Urgaonkar, R.; Sitaraman, R.K. BOLA: Near-optimal bitrate adaptation for online videos. IEEE/ACM Trans. Netw. 2020, 28, 1698–1711. [Google Scholar] [CrossRef]
- Yadav, P.K.; Shafiei, A.; Ooi, W.T. Quetra: A queuing theory approach to dash rate adaptation. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 1130–1138. [Google Scholar]
- Zhou, C.; Lin, C.W.; Guo, Z. mDASH: A Markov decision-based rate adaptation approach for dynamic HTTP streaming. IEEE Trans. Multimed. 2016, 18, 738–751. [Google Scholar] [CrossRef]
- Xu, B.; Chen, H.; Ma, Z. Karma: Adaptive video streaming via causal sequence modeling. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 1527–1535. [Google Scholar]
- Yin, X.; Jindal, A.; Sekar, V.; Sinopoli, B. A control-theoretic approach for dynamic adaptive video streaming over HTTP. In Proceedings of the 2015 ACM Conference on Special Interest Group on Data Communication, London, UK, 17–21 August 2015; pp. 325–338. [Google Scholar]
- Li, Y.; Zheng, Q.; Zhang, Z.; Chen, H.; Ma, Z. Improving ABR performance for short video streaming using multi-agent reinforcement learning with expert guidance. In Proceedings of the 33rd Workshop on Network and Operating System Support for Digital Audio and Video, Vancouver, BC, Canada, 7–10 June 2023; pp. 58–64. [Google Scholar]
- Yan, F.Y.; Ayers, H.; Zhu, C.; Fouladi, S.; Hong, J.; Zhang, K.; Levis, P.; Winstein, K. Learning in situ: A randomized experiment in video streaming. In Proceedings of the 7th USENIX Symposium on Networked Systems Design and Implementation, Boston, MA, USA, 30 March–1 April 2011. [Google Scholar]
- O’Hanlon, P.; Aslam, A. Latency Target based Analysis of the DASH. js Player. In Proceedings of the 14th Conference on ACM Multimedia Systems, Vancouver, BC, Canada, 7–10 June 2023; pp. 153–160. [Google Scholar]
- Han, B.; Qian, F.; Ji, L.; Gopalakrishnan, V. MP-DASH: Adaptive video streaming over preference-aware multipath. In Proceedings of the 12th International on Conference on Emerging Networking EXperiments and Technologies, Irvine, CA, USA, 12–15 December 2016; pp. 129–143. [Google Scholar]
- Meng, Z.; Wang, M.; Bai, J.; Xu, M.; Mao, H.; Hu, H. Interpreting deep learning-based networking systems. In Proceedings of the Annual conference of the ACM Special Interest Group on Data Communication on the Applications, Technologies, Architectures, and Protocols for Computer Communication, Virtual Event, USA, 10–14 August 2020; pp. 154–171. [Google Scholar]
- Graves, A. Long short-term memory. Supervised Seq. Label. Recurr. Neural Netw. 2012, 385, 37–45. [Google Scholar]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A search space odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 2222–2232. [Google Scholar] [CrossRef] [PubMed]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. Int. Conf. Mach. Learn. PmLR 2016, 48, 1928–1937. [Google Scholar]
- Siami-Namini, S.; Tavakoli, N.; Namin, A.S. The performance of LSTM and BiLSTM in forecasting time series. In Proceedings of the 2019 IEEE International Conference on Big Data, Los Angeles, CA, USA, 9–12 December 2019; pp. 3285–3292. [Google Scholar]
- Nosouhian, S.; Nosouhian, F.; Khoshouei, A.K. A review of recurrent neural network architecture for sequence learning: Comparison between LSTM and GRU. Preprint 2021. [Google Scholar] [CrossRef]
- Kossi, K.; Coulombe, S.; Desrosiers, C. No-reference video quality assessment using transformers and attention recurrent networks. IEEE Access 2024, 12, 140671–140680. [Google Scholar] [CrossRef]
- Xing, F.; Wang, Y.G.; Tang, W.; Zhu, G.; Kwong, S. Starvqa+: Co-training space-time attention for video quality assessment. arXiv 2023, arXiv:2306.12298. [Google Scholar]
- Lv, G.; Wu, Q.; Wang, W.; Li, Z.; Xie, G. Lumos: Towards better video streaming qoe through accurate throughput prediction. In Proceedings of the IEEE INFOCOM 2022-IEEE Conference on Computer Communications, Virtual, 2–5 May 2022; pp. 650–659. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Name | Description | Version |
|---|---|---|---|
| 1 | Ubuntu | Linux OS | 18.04 |
| 2 | Anaconda | Package/environment manager | 5.0.0 |
| 3 | Python | Programming language | 3.7.10 |
| 4 | PyTorch | Deep learning framework | 1.4.0 |
| 5 | Pysyft | Federated learning library | 0.2.4 |
| 6 | TFlearn | Deep learning framework | 0.5.0 |
| 7 | TensorFlow | Deep learning framework | 2.4.0 |
| 8 | Nginx | Video server | 1.16.1 |
| 9 | Quiche | QUIC protocol implementation | 0.10.0 |
| 10 | Firefox | Video client | 94.0 |
| 11 | CPU | Central Processing Unit | i7-12700H |
| 12 | GPU | NVIDIA RTX graphics card | 4060 |
| Method | Average QoE | Buffering | Smoothness | Bitrate |
|---|---|---|---|---|
| MPC | 42.7 | 3.21 | 2.8 | 5.3 |
| Bola | 39.8 | 2.67 | 3.1 | 4.9 |
| Pensieve | 41.8 | 2.38 | 2.9 | 5.4 |
| Cada | 43.7 | 2.21 | 2.6 | 5.7 |
| Version | Preference NET | Multi-Process | Average QoE |
|---|---|---|---|
| Pensieve-PPO | No | No | 40.2 |
| Cada-1 | Yes | No | 44.6 |
| Cada-2 | Yes | Yes | 45.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, Z.; Liu, Y.; Zhang, H. User Preference-Based Dynamic Optimization of Quality of Experience for Adaptive Video Streaming. Electronics 2025, 14, 3103. https://doi.org/10.3390/electronics14153103
Feng Z, Liu Y, Zhang H. User Preference-Based Dynamic Optimization of Quality of Experience for Adaptive Video Streaming. Electronics. 2025; 14(15):3103. https://doi.org/10.3390/electronics14153103
Chicago/Turabian StyleFeng, Zixuan, Yazhi Liu, and Hao Zhang. 2025. "User Preference-Based Dynamic Optimization of Quality of Experience for Adaptive Video Streaming" Electronics 14, no. 15: 3103. https://doi.org/10.3390/electronics14153103
APA StyleFeng, Z., Liu, Y., & Zhang, H. (2025). User Preference-Based Dynamic Optimization of Quality of Experience for Adaptive Video Streaming. Electronics, 14(15), 3103. https://doi.org/10.3390/electronics14153103