Abstract
With the growing demand for ecological monitoring and geological exploration, high-quality satellite remote-sensing imagery has become indispensable for accurate information extraction and automated analysis. However, haze reduces image contrast and sharpness, significantly impairing quality. Existing dehazing methods, primarily designed for natural images, struggle with remote-sensing images due to their complex imaging conditions and scale diversity. Given this, we propose a novel Multi-Scale Contextual Attention Generative Adversarial Network (MCA-GAN), specifically designed for satellite image dehazing. Our method integrates multi-scale feature extraction with global contextual guidance to enhance the network’s comprehension of complex remote-sensing scenes and its sensitivity to fine details. MCA-GAN incorporates two self-designed key modules: (1) a Multi-Scale Feature Aggregation Block, which employs multi-directional global pooling and multi-scale convolutional branches to bolster the model’s ability to capture land-cover details across varying spatial scales; (2) a Dynamic Contextual Attention Block, which uses a gated mechanism to fuse three-dimensional attention weights with contextual cues, thereby preserving global structural and chromatic consistency while retaining intricate local textures. Extensive qualitative and quantitative experiments on public benchmarks demonstrate that MCA-GAN outperforms other existing methods in both visual fidelity and objective metrics, offering a robust and practical solution for remote-sensing image dehazing.
1. Introduction
With the rapid advancement of computing technologies, computer vision has demonstrated significant value across a variety of domains—including security surveillance, aerospace, medical diagnostics, and industrial automation [1,2,3,4]. In particular, high-quality satellite remote-sensing imagery is critical for environmental monitoring, disaster assessment, and resource management. However, under hazy atmospheric conditions, satellite images often exhibit reduced contrast, color distortion, blurred details, and even loss of critical information due to atmospheric scattering, which not only degrades visual interpretability but also undermines the accuracy and robustness of downstream tasks such as object detection and change monitoring. Therefore, there is an urgent need for efficient and reliable dehazing methods to enhance the quality of remote-sensing imagery under adverse weather and to improve the practicality and stability of vision-based systems in this context.
Early dehazing research primarily focused on natural scene images and employed enhancement-based techniques to alleviate haze-induced degradation [5,6,7,8]. For example, the Retinex theory simulates the human visual system’s perception of color and luminance, giving rise to classical algorithms such as the Single-Scale Retinex, Multi-Scale Retinex, and Multi-Scale Retinex with Color Restoration. Although these approaches can improve visual contrast, they lack a physical model of haze formation, resulting in limited dehazing performance and frequent issues such as detail loss or over-enhancement. To more accurately characterize the impact of haze on image quality, researchers adopted physics-based modeling approaches [9], utilizing the atmospheric scattering model and restoring haze-free images through inversion techniques. He et al. [10] subsequently leveraged the Dark Channel Prior (DCP) to estimate transmission and, in conjunction with the atmospheric scattering model, substantially improved restoration quality, although their method tends to under-brighten sky regions and introduce color artifacts. To address these shortcomings, Lu et al. [11] proposed a single-image dehazing method that segments bright and dark regions via an improved SLIC superpixel algorithm and applies multi-scale Retinex enhancement, yielding more natural results. Despite their strong theoretical underpinnings, these methods suffer from high computational complexity and sensitivity to parameter settings, limiting their applicability in practical remote-sensing scenarios. With the advent of deep learning, dehazing research has shifted toward data-driven approaches. DehazeNet is the first end-to-end convolutional neural network designed for transmission estimation and image dehazing. Zhang et al. [12] further designed a deep network that integrates multi-level feature extraction with attention mechanisms, eliminating the need for explicit estimation of atmospheric light and transmission map, streamlining the processing pipeline, and achieving superior dehazing performance. Despite the success of deep learning-based methods in natural scene dehazing, applying them to satellite remote-sensing imagery presents unique challenges:
- Complex imaging conditions: Satellite images are affected by factors including atmospheric thickness, solar angle, and sensor characteristics, leading to highly non-uniform haze distributions and locally dense fog patches.
- Resolution and scale diversity: Remote-sensing images cover expansive regions with heterogeneous land covers and varying spatial scales, demanding robust multi-scale perceptual capabilities.
- High global consistency requirements: As a primary data source for large-scale geographic analysis and change detection, preserving overall structural and color consistency is far more critical than in typical natural images.
In recent years, Generative Adversarial Networks (GANs) have become an active area of research in applying deep learning to remote-sensing image dehazing [13]. By leveraging the adversarial interplay between a generator and a discriminator, GANs can produce dehazed outputs with enhanced realism and more complete detail preservation—properties that are particularly advantageous for satellite imagery, which demands both fine details and global coherence. To address the limitations of existing deep-learning methods in multi-scale feature modeling, contextual information integration, and adaptability to complex remote-sensing scenarios, this paper proposes a Multi-Scale Contextual Attention GAN (MCA-GAN) for satellite image dehazing. The proposed method harnesses GAN’s strong reconstruction capability, incorporates multi-scale structures and contextual attention mechanisms to expand the receptive field and strengthen feature extraction, and guides attention allocation toward critical regions via contextual cues, thereby significantly improving the network’s expressive power and dehazing performance. The main contributions of this paper include the following points:
- To address the challenge of resolution and scale diversity in remote-sensing imagery, we propose a Multi-Scale Feature Aggregation Block (MFAB) that more accurately extracts and fuses object features across scales—from fine-grained to large-scale structures—thereby restoring land-cover details and enhancing overall visual quality.
- To satisfy the stringent global consistency requirements of remote-sensing images, we propose a Dynamic Contextual Attention Block (DCAB) that balances local detail refinement with global structural and chromatic coherence, ensuring that dehazed outputs preserve both scene integrity and color consistency.
- To demonstrate the efficacy of the proposed method in complex remote-sensing scenarios, we conduct experiments on the public benchmarks—RICE1 (uniform light haze) and RICE2 (non-uniform dense haze). Ablation studies confirm the individual contributions of MFAB and DCAB, and comparative evaluations verify that our method outperforms existing dehazing algorithms.
2. Related Works
In the domain of remote-sensing image dehazing, deep learning techniques have attracted extensive attention due to their end-to-end feature learning capabilities [14]. These approaches can automatically model the complex haze degradation process and significantly enhance model generalization performance through large-scale data-driven training. Early studies predominantly relied on convolutional neural networks (CNNs). Among them, DehazeNet [15] was the first to apply CNNs to the image-dehazing task, predicting the transmission map of hazy images via an end-to-end network and reconstructing clear images using the atmospheric scattering model. Subsequently, AOD-Net proposed by Li et al. [16] embedded key parameters of the atmospheric scattering model into the network architecture, enabling direct mapping from input to dehazed output. Although CNN-based methods effectively address the inaccuracies of parameter estimation in traditional physical models and improve image quality, they still face challenges when applied to remote-sensing imagery. On one hand, remote-sensing images exhibit significant scale diversity, requiring the model to simultaneously capture both fine details and global structures. On the other hand, accurate restoration of complex scenes depends heavily on global contextual information, which is difficult to achieve using local convolutional operations alone.
To overcome these limitations, various multi-scale feature modeling strategies have been proposed in recent years. Multi-scale convolutional networks leverage layers with different receptive fields to simultaneously capture local and global information. For instance, Liu et al. [17] introduced a Deep Multi-Scale Network that incorporates self-guided maps along with the original hazy image as inputs, optimizing feature representations at multiple scales to achieve more thorough dehazing. Li et al. [18] proposed a multi-scale dehazing network combining large-kernel convolutions with attention mechanisms, which enhances image quality and detail representation through parallel multi-scale feature extraction and channel-spatial attention refinement. Meanwhile, multi-scale feature fusion strategies employing parallel branch architectures have been adopted to alleviate the limitations of single-scale representations [19] and have shown impressive performance in detail preservation. For example, IDDNet proposed by Sun et al. [20] integrates a multi-scale fusion dehazing module and a specially designed dehazing loss function to improve image restoration quality. MAPF-Net, proposed by Huang et al. [21], combines multi-scale attention mechanisms with physical-aware feature fusion. It utilizes large-kernel convolutions and a dual-residual parallel attention mechanism to effectively extract and fuse multi-scale information, achieving superior adaptability to varying haze densities while maintaining low computational cost. In addition, Zhang et al. [22] designed a multi-scale feature fusion module based on Local Binary Patterns and introduced an error feedback mechanism to mitigate the loss of critical features caused by downsampling operations. Despite these advancements in detail reconstruction, the capability of these methods to model global semantic relationships remains limited, especially when dealing with uneven haze distribution and complex atmospheric conditions. To enhance semantic understanding, attention mechanisms have been widely integrated into dehazing models. For instance, Wang et al. [23] proposed the Recurrent Context Aggregation Network, which incorporates both global and local features to improve image restoration. Liang et al. [24] introduced a self-supervised depth-guided dehazing approach, which combines a hybrid attention mechanism to enhance global contextual awareness. However, existing attention mechanisms often exhibit a weak performance in recovering local details and suffer from insufficient multi-scale feature integration. Although multi-scale modeling and contextual awareness have achieved notable progress in detail recovery and semantic representation, respectively, deeply integrated solutions that jointly explore both aspects for remote-sensing dehazing remain scarce. Most existing approaches focus on optimizing a single aspect, making it difficult to simultaneously model multi-scale details and global semantics in complex remote-sensing scenes. Methods that prioritize multi-scale features while neglecting semantic correlations often result in color distortion and structural blurring. Conversely, approaches that rely heavily on contextual awareness but fail to capture local details struggle to restore fine structures in heavily hazed regions.
To address these challenges, GANs have emerged as a promising research direction. GANs can effectively model complex global semantic relationships while preserving fine-grained features, offering new possibilities for integrating multi-scale feature extraction with contextual reasoning in remote-sensing dehazing tasks. For example, Cloud-GAN [25] enforces structural and semantic consistency between hazy and clear images via adversarial loss and cycle-consistency constraints. SPA-GAN [26] employs a spatial attention mechanism to simulate human visual perception, significantly enhancing dehazing performance for remote-sensing imagery. However, these GAN-based methods still lack a coordinated optimization mechanism for multi-scale modeling and context fusion. As demonstrated in the comparative evaluation in Section 4.4.2, while SPA-GAN excels in haze localization and key region restoration, it still struggles with preserving fine textures and removing residual haze. Specifically, the generator architecture suffers from two key limitations: (1) the attention weights are derived solely from single-scale Identity Recurrent Neural Network (IRNN) features, making it difficult to capture both large-scale haze regions and fine haze structures; (2) the spatial attention mechanism only focuses on local neighborhoods within the feature maps, lacking guidance from global contextual information. This results in insufficient coordination between global consistency and local detail recovery.
To address the aforementioned issues, this paper improves the structure of the generator based on the traditional SPA-GAN network, aiming to enhance the model’s ability to perceive multi-scale details and model contextual information in remote-sensing scenes, thereby significantly improving its overall performance in complex remote-sensing image-dehazing tasks.
3. Method
This section presents an overview of the proposed MCA-GAN architecture, followed by an introduction to the MFAB for extracting and fusing multi-scale object features, and the DCAB that enhances local details while preserving global structural and color consistency.
3.1. Network Architecture
To address SPA-GAN’s suboptimal local feature extraction and loss of image details—while improving its robustness in edge preservation, texture reconstruction, and residual haze removal—a Multi-Scale Feature Aggregation Block (MFAB) is proposed, which is inserted before the Contextual Spatial Attentive Module (CSAM). The MFAB’s multi-directional global pooling and multi-scale convolutional branches substantially enhance the backbone network’s ability to capture fine details in complex remote-sensing scenarios. Simultaneously, to further address the inadequate contextual modeling in SPA-GAN, this paper proposes a Dynamic Contextual Attention Block (DCAB) to replace three consecutive convolutional layers in the Spatial Attentive Module (SAM), thereby forming CSAM. Within this module, the three-dimensional attention weight modeling mechanism and contextual representation method are organically fused via a gating mechanism, effectively balancing global consistency with local specificity and improving the backbone network’s capture and utilization of contextual information. The MFAB and DCAB are incorporated into the generator architecture to build a novel Multi-Scale Contextual Attention GAN (MCA-GAN).
As shown in Figure 1, the generator of MCA-GAN is a fully convolutional network. The workflow is as follows: First, a convolutional encoding layer is applied to the input hazy image to extract initial features. Then, three standard residual blocks preserve the feature map size while enhancing low-level information. Next, the data sequentially passes through four Multi-scale Contextual Attentive Blocks (MCABs), each consisting of a CSAM, a MFAB, and three Spatial Attentive Residual Blocks (SARBs). This is followed by two additional standard residual blocks that further integrate the attention-enhanced features. Finally, a convolutional layer maps the features back to the image space, producing a high-quality output image with clear details and no residual haze.
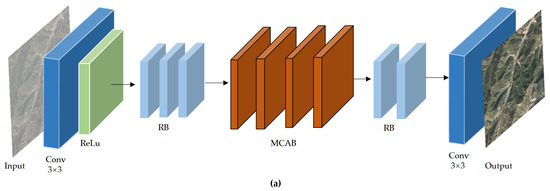
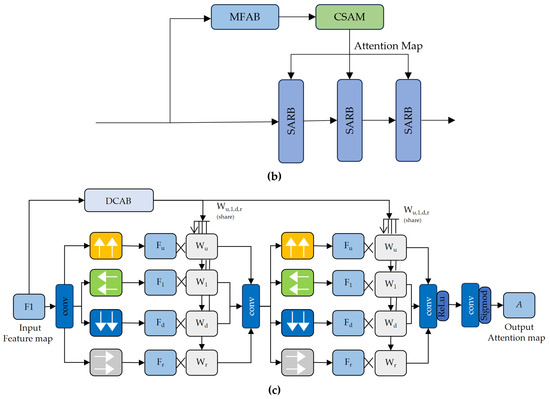
Figure 1.
This figure contains three panels: (a) Multi-Scale Contextual Attention Network (MCA-Net); (b) Multi-Scale Contextual Attentive Block (MCAB); (c) Contextual Spatial Attentive Module (CSAM).
3.2. Multi-Scale Feature Aggregation Block
MFAB is a hybrid attention unit centered on channel attention while also integrating spatial attention, designed to bolster the network’s ability to perceive critical regions in remote-sensing images. This module employs feature grouping and a parallel subnetwork architecture, sequentially introducing intra-group attention and positional attention reweighting mechanisms to adaptively highlight crucial semantic features and effectively capture multi-scale and multi-directional information in the image. Furthermore, MFAB integrates a multi-dimensional fusion strategy to further enhance the global representational capacity of extracted features. In remote-sensing image-dehazing tasks, the MFAB significantly enhances the model’s ability to identify haze and haze-affected regions, particularly in scenarios with complex backgrounds and coexisting multi-scale haze. By effectively strengthening key channel features, MFAB sharpens haze boundaries and reveals fine particulate details, thereby substantially improving dehazing quality and overall visual fidelity. This enables the model to better address the challenges posed by complex imaging conditions and scale variations commonly encountered in satellite remote sensing.
The overall structure of MFAB, shown in Figure 2, first partitions the input feature map into subgroups along the channel dimension to reduce the per-group computational load and enable parallel processing. Next, the module feeds each subgroup into a parallel subnetwork structure where four parallel paths are used to extract attention weights for the grouped feature maps. Specifically, two paths adopt average pooling branches in different directions, while the other two use 3 × 3 convolution branches. In the average pooling branches, each subgroup undergoes global average pooling along the spatial height and width to produce two one-dimensional projections; these projections are concatenated along the channel dimension, passed through a 1 × 1 convolution and a Sigmoid activation to obtain intra-group channel–direction attention weights, which capture cross-channel dependencies via element-wise reweighting. In the 3 × 3 branches, the subgroup features pass through two parallel 3 × 3 convolution branches to extract multi-scale local spatial information; the resulting multi-scale features are concatenated along the channel dimension to form merged features. The four outputs are subsequently concatenated and introduced into the multi-dimensional fusion unit, where long-range spatial dependencies are further captured to produce the final spatial attention weights; The feature is further re-weighted using the Sigmoid function, followed by a ReLU activation, and ultimately fused with the input through a residual connection to produce the output. The MFAB module, through its unique channel grouping and parallel subnetwork design, not only encodes inter-channel information to adjust the importance of different channels but also preserves precise spatial structure within the convolutional branches, enabling capture and representation of multi-scale, multi-directional key features, thereby effectively enhancing the network’s representational capacity.
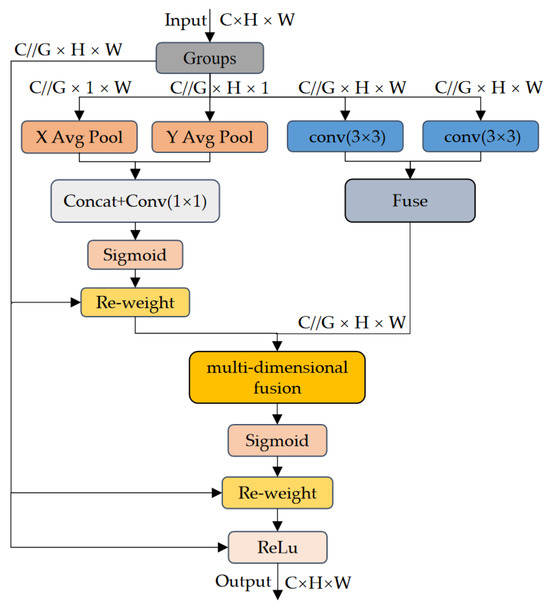
Figure 2.
MFAB structure diagram.
3.3. Dynamic Contextual Attention Block
DCAB is a composite attention module designed to enhance the backbone network’s ability to represent both complex semantic relationships and fine structural details in remote-sensing imagery by integrating global modeling and local perception. DCAB consists of two complementary attention branches: one dedicated to capturing global contextual information, and the other focused on extracting local structural features. This dual-path architecture enables the parallel extraction of multi-level semantic features from the input image. To achieve more fine-grained feature fusion, DCAB incorporates a gating mechanism that adaptively weights the outputs of the two attention branches. This mechanism dynamically adjusts their relative contributions based on the input features, thereby enhancing the model’s ability to distinguish local structures such as edges and textures while maintaining global semantic consistency. The fused features are subsequently compressed via a 1 × 1 convolution and passed through a nonlinear activation function, resulting in more robust and discriminative representations for subsequent dehazing tasks in remote sensing. Compared to the global context extraction branch in the original SAM module, DCAB effectively overcomes the limitations imposed by the strict global consistency requirements of satellite imagery. It not only captures long-range dependencies and intricate semantic structures more effectively but also improves local detail restoration. This ensures that the dehazed outputs preserve overall scene integrity while maintaining consistent color and structural fidelity.
The overall DCAB structure, shown in Figure 3, first feeds the input feature map x into two parallel branches: the local-detail perception branch computes and applies attention weights based on channel energy distributions to reinforce discriminative features, while the global-context extraction branch first generates static key features via grouped convolution, then concatenates the original features to generate dynamic spatial attention weights that are multiplied with value embeddings to extract contextual information. Next, the outputs from both branches are concatenated along the channel dimension and passed through a gating network consisting of a 1 × 1 convolution and a Softmax function to produce adaptive weights for each branch output. After weighting and concatenating, a 1 × 1 fusion convolution followed by a ReLU activation performs dimensionality reduction and nonlinear mapping, finally outputting fine-grained features that integrate channel-energy attention and contextual information. The DCAB not only maintains sensitivity to micro-level details but also preserves global contextual understanding, effectively enhancing the network’s feature representation capability in complex remote-sensing dehazing tasks. The processing details for the two branches are described in detail below.
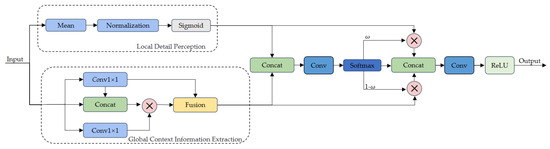
Figure 3.
DCAB structure diagram. denote local matrix multiplication.
The local detail perception branch can significantly enhance the sensitivity of the DCAB to local anomalies and fine structures without substantially increasing computational burden, thereby improving the backbone network’s ability to capture minute textures and edge features, enriching multi-level feature representation. As shown in Equation (1),
Here, ; .
Minimizing Equation (1) is equivalent to training the linear separability between unit t and other units within the same channel. Consequently, by binarizing the terms of Equation (1) and incorporating a regularization term, we obtain the final function, as shown in Equation (2):
where each channel has functions. Equation (2) has the following solution, as shown in Equation (3):
Here, ; .
Therefore, the following formula can be obtained, as shown in Equation (5):
Here, ; .
For Equation (5), the greater the difference between unit t and other units, the higher its importance. Therefore, the importance of the unit can be expressed as .
The global context information extraction branch enhances DCAB’s capability to model spatial structures and semantic relationships. For an input feature map of size (where is height, is width, and is the number of channels), it is first mapped into a query matrix , a key matrix , and a value matrix via three embedding matrices (, , ). Each embedding matrix is implemented as a convolution, preserving the original spatial resolution while focusing processing on channel-dimension interactions. Next, similarity between and within local windows is computed to produce a relation matrix , where denotes the number of heads, thereby capturing fine-grained contextual dependencies among neighboring regions. Specifically, as shown in Equation (6),
where denotes the local matrix multiplication operation.
This operation measures the pairwise relationships between each query and the corresponding key within every local grid in the spatial domain. Hence, for the -th spatial location, each feature in is a -dimensional vector composed of the local query–key relationship mappings across all heads. Positional information of each grid is then incorporated to enrich the local relation matrix , as shown in Equation (7):
where denotes the 2D relative positional embeddings within each grid.
The matrix is obtained by applying a Softmax operation to the enhanced spatially aware local relation matrix , normalizing across the channel dimension for each head, i.e., . After reshaping each spatial position’s feature vector in into local attention matrices, the final output feature map is computed within each grid, as shown in Equation (8):
The final output feature map is obtained by multiplying the value with the attention matrix . The local attention matrix for each head is specialized to aggregate uniformly distributed feature maps along the channel dimension. is the concatenation of the aggregated feature maps from all heads. This structure enables the network to effectively capture relationships between global and local contexts during visual processing, thereby enhancing model performance.
4. Experiments
4.1. Datasets
This study utilizes two sub-datasets from the widely used open-source Remote-Sensing Image Cloud Removal (RICE) dataset as the basis for training and evaluation. The RICE dataset, constructed by Lin et al. [27], is designed to support the research and development of remote-sensing image-dehazing algorithms, encompassing real-world scenes under diverse geographic and meteorological conditions and offering high representativeness. The dataset comprises two sub-datasets, RICE1 and RICE2, totaling 1236 image pairs. Specifically, RICE1 contains 500 pairs of thin haze scenes, while RICE2 includes 736 pairs of thick haze scenes. All images have a resolution of 512 × 512 pixels, with a spatial resolution of 5 m per pixel. RICE1 is sourced from Google Earth, containing diverse terrain and weather scenarios—including urban, mountain, and forested regions—with high image quality and extensive variety. RICE2 is constructed from Landsat 8 OLI/TIRS data using georeferenced Landsat-Look images, including natural-color and high-resolution imagery; haze images are generated by acquiring actual remote-sensing captures of the same area at least every 15 days. The RICE dataset provides paired hazy and haze-free images, facilitating quantitative evaluation of algorithm performance. The images in the RICE dataset are shown in Figure 4.

Figure 4.
RICE dataset. The haze column represents a blurred image with haze, and the label column represents a clear image without haze.
4.2. Experimental Details
The model validation experiments were conducted on a workstation equipped with an NVIDIA GeForce RTX 4060 Ti GPU (manufactured by NVIDIA Corporation, Santa Clara, California, United States) and were implemented using the PyTorch framework (version 2.4). The experiments employed the Adam optimizer, whose adaptive learning rate mechanism and efficient gradient update strategy facilitate faster model convergence and improved overall performance. The initial learning rate was set to 0.0002 and was dynamically adjusted using a cosine annealing learning rate scheduler. To prevent overfitting and enhance training efficiency, L2 regularization and an early stopping mechanism were applied: training was terminated early if the evaluation metrics on the validation set did not improve over successive epochs. Considering the dataset size and GPU memory constraints, the batch size is set to 2. Training runs for 100 epochs to ensure the model fully learns from limited data while mitigating overfitting. To enhance the model’s dehazing capability across diverse haze scenarios, the dataset is split so that 90% is used for training and 10% for testing. All input images are preprocessed to 512 × 512 × 3 before being fed into the network—that is, resized to 512 pixels in width and height while retaining all three RGB channels. The relevant settings are shown in Table 1.

Table 1.
Experimental setup.
4.3. Assessment Criteria
In the field of computer vision, classical image quality assessment methods include the Structural Similarity Index (SSIM) [28,29] and Peak Signal-to-Noise Ratio (PSNR) [30]. Some studies have also introduced improved evaluation metrics, such as QMSE and QPSNR [31,32]. In this experiment, we adopt SSIM and PSNR as the evaluation metrics to quantitatively analyze the performance of the proposed MCA-GAN network in image-dehazing tasks.
4.3.1. Structural Similarity Index
The SSIM measures the consistency of two images in terms of perceived visual quality by jointly analyzing similarities in luminance, contrast, and structure, thus more accurately reflecting visual distortions caused by changes in brightness, contrast differences, or structural distortions. The SSIM formula is as follows, as shown in Equation (9):
where and denote the pixel patches of the two images; and are the mean values of the pixel patches and ; and are the variances of and ; is the covariance of and ; and are constants used to prevent the denominator from being zero. The numerator measures the relationship among the means, variances, and covariance of and , while the denominator normalizes these terms, ensuring SSIM ranges between 0 and 1; values closer to 1 indicate greater similarity between the two images.
4.3.2. Peak Signal-to-Noise Ratio
PSNR is a widely used objective metric that quantifies the quality difference between an original image and its compressed, transmitted, or processed version. This metric derives from the MSE of two images and the image’s peak pixel value, translating the error into a decibel (dB) scale. The PSNR formula is as follows Equation (10):
Here, Max refers to the maximum pixel value of the image, and Mean Squared Error (MSE) quantifies the average squared difference between the predicted and ground truth values. It measures the overall deviation between two datasets, reflecting their numerical consistency. The mathematical definition of MSE is presented in Equation (11):
where is the total number of data points; and denote the -th data point of the ground truth and the corresponding prediction, respectively. Generally, a PSNR above 30 dB is considered to represent minor quality degradation, while values near or above 40 dB suggest excellent fidelity to the original signal.
4.4. Contrast Experiment
To validate the effectiveness of the proposed method, this study compares the MCA-GAN dehazing network with seven widely adopted dehazing algorithms—DCP [10] (2010), Retinex [33] (2019), FFA-Net [34] (2020), SPA-GAN [26] (2020), DehazeFormer [35] (2023), Trinity-Net [36] (2023), and MABDT [37] (2025)—on the RICE dataset under identical experimental conditions. The first two are classical non-learning-based methods, while the remaining five are deep learning-based approaches. All deep learning-based models were retrained using a unified training protocol to ensure a fair comparison. Through comprehensive experiments, both qualitative visual assessments and quantitative metric evaluations were conducted to highlight the performance differences among the compared methods, thereby demonstrating the superiority of MCA-GAN.
4.4.1. Experimental Evaluation Based on the RICE1 Dataset
In the qualitative visual quality assessment on the RICE1 dataset, Figure 5 presents four randomly selected images from the dataset under different algorithms as experimental results. In Figure 5, panel (a) shows the hazy remote-sensing image; (b) the ground-truth haze-free image; (c) the classical DCP dehazing result; (d) the classical Retinex dehazing result; (e) the FFA-Net dehazing result; (f) the SPA-GAN dehazing result; (g) the DehazeFormer dehazing result; (h) the Trinity-Net dehazing result; (i) the MABDT dehazing result; (j) the proposed MCA-GAN dehazing result.


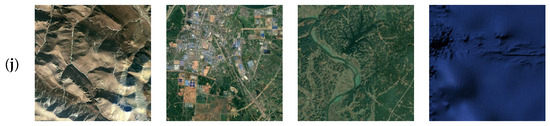
Figure 5.
Dehazed results of the proposed method on the RICE1. (a) Haze. (b) Clear. (c) DCP. (d) Retinex. (e) FFA-Net. (f) SPA-GAN. (g) DehazeFormer. (h) Trinity-net. (i) MABDT. (j) MCA-GAN. This set of images demonstrates the ability of MCA-GAN to remove thin haze.
As shown in Figure 5, in subjective evaluations, deep learning-based dehazing algorithms significantly outperform traditional dehazing methods in terms of dehazing effectiveness and visual quality. Images processed by traditional methods commonly exhibit color distortion and blurred details. For example, the classical DCP dehazing method based on a physical model (Figure 5c) produces processed images with low color saturation, noticeable color distortion, and overall insufficient brightness—particularly evident in the first and second images. In contrast, the classic Retinex-based dehazing method (Figure 5d), which relies on image enhancement techniques, introduces a warm color tone in the first three images, while the fourth image exhibits over-enhancement. Deep learning-based dehazing algorithms, such as the FFA-Net dehazing method (Figure 5e), significantly outperform traditional image processing in terms of clarity. However, some residual haze and information loss are still present. Compared to this, the SPA-GAN algorithm (Figure 5f) demonstrates substantial improvement in detail recovery, but severe color distortion is noticeable in the first three images. Although the DehazeFormer (Figure 5g) and Trinity-Net (Figure 5h) algorithms do not show noticeable color distortion, they still fall short in detail preservation, especially for the second test image. It is worth noting that the MABDT dehazing method (Figure 5i) makes significant progress in enhancing details, but it also faces issues with tone consistency. In contrast, the MCA-GAN algorithm (Figure 5j) not only avoids significant color distortion but also maintains a high level of information completeness and clarity.
To more intuitively demonstrate the performance differences between various dehazing methods, we selected the third-column image in Figure 5 (i.e., the forest scene) as the reference. Normalized error maps were then generated by computing the pixel-wise absolute differences between the dehazed images obtained from each method and the corresponding clear image. As shown in Figure 6, regions with higher brightness in the error maps indicate larger deviations from the ground truth, clearly revealing the residual errors present in each method. Experimental results further confirm that the MCA-GAN algorithm not only achieves a superior performance in terms of overall error, but also exhibits greater global consistency and outperforms other methods in preserving edge and texture details. This advantage is primarily attributed to the DCAB module, which helps the network to better understand the relationships between different regions, leading to more consistent color and texture features in the generated image. Additionally, the MFAB-extracted small-scale information allows for precise adjustment and restoration, making the final dehazed image more realistic and detailed.

Figure 6.
Comparison of error maps between different dehazing algorithms and the ground-truth images on the RICE1 dataset. (a) DCP. (b), Retinex. (c) FFA-Net. (d) SPA-GAN. (e) DehazeFormer. (f) Trinity-Net. (g) MABDT. (h) MCA-GAN.
As shown in Table 2, this experiment systematically evaluates eight dehazing algorithms using two objective image quality assessment metrics: PSNR and SSIM. According to the experimental results on the RICE1 sub-dataset, MCA-GAN achieves a PSNR value of 32.0126 dB and an SSIM value of 0.9578. Compared with traditional methods and mainstream deep learning models, MCA-GAN demonstrates a superior dehazing performance under thin haze conditions in terms of image color, saturation, and clarity. Meanwhile, to comprehensively evaluate the practicality of the models, the table also presents a comparison of computational complexity, including the number of trainable parameters (Pars), floating-point operations (FLOPs), and runtime. Experimental results show that compared with the second-best method, MABDT, MCA-GAN significantly reduces the model complexity from 11.83M to 3M parameters, while notably improving dehazing performance. This demonstrates a favorable balance between performance and efficiency, indicating strong potential for engineering applications.
Table 2.
Results of quantitative analysis on the RICE1 test set.
4.4.2. Experimental Evaluation Based on the RICE2 Dataset
When conducting a qualitative assessment of the visual quality of the RICE2 dataset, Figure 7 shows the effect diagrams of the experiments in this paper. These effect diagrams are obtained by processing four randomly selected images from the dataset using different algorithms. In Figure 7, panel (a) shows the hazy remote-sensing image; (b) the ground-truth haze-free image; (c) the classical DCP dehazing result; (d) the classical Retinex dehazing result; (e) the FFA-Net dehazing result; (f) the SPA-GAN dehazing result; (g) the DehazeFormer dehazing result; (h) the Trinity-Net dehazing result; (i) the MABDT dehazing result; (j) the proposed MCA-GAN dehazing result.


Figure 7.
Dehazed results of the proposed method on the RICE2. (a) Haze. (b) Clear. (c) DCP. (d) Retinex. (e) FFA-Net. (f) SPA-GAN. (g) DehazeFormer. (h) Trinity-net. (i) MABDT. (j) MCA-GAN. This group of images illustrates the superiority of MCA-GAN in dealing with dense haze.
As shown in Figure 7, compared with RICE1, the RICE2 dataset more clearly demonstrates the superior dehazing performance of deep learning-based methods over traditional approaches in subjective visual quality. Both image-enhancement-based and physics-based traditional methods fail to remove dense haze effectively in complex scenes, leading to severe color distortion, detail loss, and residual fog. For example, the physical-model-based DCP method (Figure 7c), due to inaccurate transmission estimation, causes overexposure in hazy regions of the first image and insufficient dehazing in the remaining three images. The classic Retinex method (Figure 7d) often produces unnatural color shifts under complicated lighting conditions, as clearly seen in the first image. Deep learning-based approaches such as FFA-Net (Figure 7e) achieve far superior clarity compared to traditional methods, yet still exhibit incomplete haze removal and information loss in the last three images, and introduce noticeable artifacts in the second and fourth images. SPA-GAN (Figure 7f) shows initial capability in removing non-uniform dense haze in the third image but leaves residual fog elsewhere. DehazeFormer (Figure 7g) and Trinity-Net (Figure 7h) improve on non-uniform haze removal compared to earlier methods; however, the second image still suffers from detail omission and edge blurring. The MABDT algorithm (Figure 7i) makes marked progress in detail enhancement for the second image but retains issues with tonal consistency. In contrast, the proposed MCA-GAN (Figure 7j) exhibits outstanding dehazing capability in complex remote-sensing scenarios, with no obvious color bias and color rendition closely matching the original haze-free images.
In reference to the second column of images in Figure 7 (i.e., the island scene), we generated the error comparison chart shown in Figure 8. The experimental results further confirm the MCA-GAN algorithm’s superior performance in maintaining global consistency and accurately handling edge details. This is evident from the high fidelity restoration of the edge details in the island area as seen in Figure 8h, which approaches the quality of the original haze-free image. This outstanding performance is largely attributed to the MFAB module within MCA-GAN, which effectively enhances the preservation of edge information in complex scenes through the implementation of multi-directional global pooling and multi-scale convolution operations, thereby ensuring that dehazed images are more realistic and finely detailed reproductions of the original scenes.

Figure 8.
Comparison of error maps between different dehazing algorithms and the ground-truth images on the RICE2 dataset. (a) DCP. (b), Retinex. (c) FFA-Net. (d) SPA-GAN. (e) DehazeFormer. (f) Trinity-Net. (g) MABDT. (h) MCA-GAN.
As shown in Table 3, the performance of each algorithm on the RICE2 sub-dataset is summarized, where MCA-GAN achieves a PSNR of 32.8245 dB and an SSIM of 0.8806. Compared to both traditional approaches and mainstream deep learning models, MCA-GAN consistently demonstrates a superior dehazing performance in terms of color fidelity, saturation, and clarity under dense haze conditions.
Table 3.
Results of quantitative analysis on the RICE2 test set.
4.4.3. Ablation Experiment
To rigorously validate the practical effectiveness of the proposed method and systematically evaluate the contribution of each module to the overall performance, we conducted ablation studies on the MCA-GAN framework. The experiments employed a controlled variable approach, selectively adding or removing specific modules and observing the resulting changes in performance metrics. This allowed for a scientific assessment of the effectiveness and practicality of each component in the image-dehazing task. The ablation experiments were carried out on the RICE2 dataset, where visual effects are more pronounced. The experimental results are summarized in Table 4. Compared with the baseline model, the proposed innovative modules significantly improved the overall performance, yielding substantial gains in objective evaluation metrics such as PSNR and SSIM. Notably, MCA-GAN achieves a 16.1% improvement in PSNR at the cost of only a 0.6% increase in the number of parameters, demonstrating extremely high efficiency and practicality, and significantly improving upon SPA-GAN’s limitations in local feature modeling and image detail restoration. MCA-GAN effectively enhances the model’s ability to preserve edge information and reconstruct texture structures in complex remote-sensing images. The comprehensive experimental results strongly validate the effectiveness and superiority of MCA-GAN, further confirming the critical role of each proposed module in enhancing the performance of dehazing methods for remote-sensing imagery.
Table 4.
Ablation study of MCA-GAN.
The following conclusions can be drawn from Table 4:
- Base + MFAB: After adding MFAB to the base network, PSNR increased from 28.2786 to 31.8028, and SSIM rose from 0.8512 to 0.8752. This indicates that the MFAB module enhances the backbone network’s capacity for multi-scale feature extraction, enabling a hierarchical approach to dehazing—first coarse removal of haze followed by fine restoration—and significantly improving both dehazing performance and image realism.
- Base + MFAB + DCAB: After adding DCAB, PSNR and SSIM further improved to 32.8245 and 0.8806, respectively. This indicates that the DCAB block augments the backbone network’s ability to represent complex semantic and structural details, aiding the model’s contextual understanding in intricate scenes and ensuring consistency of color and texture across regions, thereby further strengthening the quality restoration and feature representation accuracy of the generated remote-sensing images.
5. Conclusions
To address the key challenges faced by existing deep learning-based dehazing algorithms in processing satellite remote-sensing images—including complex imaging conditions, high scale diversity, and stringent global consistency requirements—this paper fully leverages the strengths of Generative Adversarial Networks (GANs) in image reconstruction. Building upon the SPA-GAN framework, we propose a novel Multi-Scale Contextual Attention Generative Adversarial Network (MCA-GAN), aiming to achieve accurate multi-scale feature extraction and effective global context modeling in complex scenes. To tackle the challenges posed by complex imaging conditions and scale diversity, we propose a Multi-Scale Feature Aggregation Block (MFAB). This module combines the advantages of multi-directional global pooling and multi-scale convolutional branches, enabling better extraction and integration of object information across different spatial scales, thereby enhancing the overall visual quality. Furthermore, to meet the strict global consistency requirements of remote-sensing images, we propose a Dynamic Contextual Attention Block (DCAB). This block dynamically adjusts the fusion of three-dimensional attention weights and contextual information through a gating mechanism, achieving collaborative modeling of local detail enhancement and global structure and color consistency. This ensures that the dehazing results preserve scene integrity while maintaining good color consistency. Experimental results on the publicly available RICE1 and RICE2 datasets demonstrate that MCA-GAN effectively captures multi-scale features and reconstructs fine details under both light and heavy haze conditions. Additionally, the method shows a superior performance in terms of PSNR and SSIM objective evaluation metrics. Ablation experiments further validate the effectiveness and practicality of the proposed modules.
In future research, we plan to employ adaptive techniques such as adversarial feature alignment and meta-learning [38], to reduce the dependence on paired training data and ensure the high robustness of generalization capability across different geographical regions and atmospheric conditions. Additionally, we will apply model compression techniques [39] to develop an efficient, hardware-friendly variant of MCA-GAN, capable of supporting on-board dehazing on micro-satellite platforms. This will enable rapid environmental perception in scenarios such as disaster response and geological exploration.
Author Contributions
Conceptualization, project administration S.Z.; methodology, writing—original draft preparation, formal analysis, visualization, software Y.Z.; data curation, validation Z.Y.; investigation S.Y.; writing review and editing H.K.; resources, supervision J.X.; All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Acknowledgments
Thanks to all the authors for writing this paper, we will make continuous efforts to write better papers.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Rahil, I.; Bouarifi, W.; Oujaoura, M. A Review of Computer Vision Techniques for Video Violence Detection and intelligent video surveillance systems. Int. J. Adv. Trends Comput. Sci. Eng. 2022, 11, 62–70. [Google Scholar] [CrossRef]
- Chen, Z.; Chen, H.; Gao, L.; Li, D.; Wang, C.; Xu, L.; Mollaee, S.; Li, J. SECBNet: Semantic Segmentation Enhanced Color Balance Network for Optical Satellite Images. IEEE Trans. Geosci. Remote Sens. 2024, 63, 4200313. [Google Scholar] [CrossRef]
- Xu, Y.; Khan, T.M.; Song, Y.; Meijering, E. Edge deep learning in computer vision and medical diagnostics: A comprehensive survey. Artif. Intell. Rev. 2025, 58, 93. [Google Scholar] [CrossRef]
- Zhou, L.; Zhang, L.; Konz, N. Computer vision techniques in manufacturing. IEEE Trans. Syst. Man Cybern. Syst. 2022, 53, 105–117. [Google Scholar] [CrossRef]
- Land, E. Lightness and retinex theory. J. Opt. Soc. Am. 1967, 58, 1428A. [Google Scholar] [CrossRef] [PubMed]
- Jobson, D.J.; Rahman, Z.U.; Woodell, G.A. Properties and performance of a center/surround retinex. IEEE Trans. Image Process. 1997, 6, 451–462. [Google Scholar] [CrossRef] [PubMed]
- Jobson, D.J.; Rahman, Z.U.; Woodell, G.A. A multiscale retinex for bridging the gap between color images and the human observation of scenes. IEEE Trans. Image Process. 1997, 6, 965–976. [Google Scholar] [CrossRef] [PubMed]
- Noori, H.; Gholizadeh, M.H.; Rafsanjani, H.K. Digital image defogging using joint Retinex theory and independent component analysis. Comput. Vis. Image Underst. 2024, 245, 104033. [Google Scholar] [CrossRef]
- Narasimhan, S.G.; Nayar, S.K. Vision and the atmosphere. Int. J. Comput. Vis. 2002, 48, 233–254. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar] [CrossRef]
- Lu, S.; Zhang, D.; Jin, X.; Guo, D. A Single Image Defogging Algorithm Based on Bright and Dark Region Segmentation. In Proceedings of the 2023 35th Chinese Control and Decision Conference (CCDC), Shenyang, China, 27–29 May 2023; pp. 1661–1667. [Google Scholar]
- Zhang, X.; Wang, T.; Luo, W.; Huang, P. Multi-level fusion and attention-guided CNN for image dehazing. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 4162–4173. [Google Scholar] [CrossRef]
- Singh, K.; Khare, V.; Agarwal, V.; Sourabh, S. A review on gan based image dehazing. In Proceedings of the 2022 6th International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 25–27 May 2022; pp. 1565–1571. [Google Scholar] [CrossRef]
- Liu, J.; Wang, S.; Wang, X.; Ju, M.; Zhang, D. A review of remote sensing image dehazing. Sensors 2021, 21, 3926. [Google Scholar] [CrossRef] [PubMed]
- Cai, B.; Xu, X.; Jia, K.; Qing, C.; Tao, D. Dehazenet: An end-to-end system for single image haze removal. IEEE Trans. Image Process. 2016, 25, 5187–5198. [Google Scholar] [CrossRef] [PubMed]
- Li, B.; Peng, X.; Wang, Z.; Xu, J.; Feng, D. Aod-net: All-in-one dehazing network. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4770–4778. [Google Scholar] [CrossRef]
- Liu, J.; Yu, H.; Zhang, Z.; Chen, C.; Hou, Q. Deep multi-scale network for single image dehazing with self-guided maps. Signal Image Video Process. 2023, 17, 2867–2875. [Google Scholar] [CrossRef]
- Li, X.; Hou, Y. Multi-Scale Image Dehazing Algorithm with Attention Mechanism. In Proceedings of the 2024 4th International Conference on Computer Science and Blockchain (CCSB), Shenzhen, China, 6–8 September 2024; pp. 460–465. [Google Scholar] [CrossRef]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient multi-scale attention module with cross-spatial learning. In Proceedings of the ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing(ICASSP), Rhodes, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Sun, S.; Han, S.; Xu, J.; Zhao, J.; Xu, Z.; Li, L.; Han, Z.; Mo, B. IDDNet: Infrared Object Detection Network Based on Multi-Scale Fusion Dehazing. Sensors 2025, 25, 2169. [Google Scholar] [CrossRef]
- Huang, G.; Zhang, J. MAPF-Net:Lightweight network for dehazing via multi-scale attention and physics-aware feature fusion. J. Supercomput. 2025, 81, 560. [Google Scholar] [CrossRef]
- Zhang, X.; Li, Y.; Li, J.; Hua, Z. LBP-based multi-scale feature fusion enhanced dehazing networks. Multimed. Tools Appl. 2024, 83, 20083–20115. [Google Scholar] [CrossRef]
- Wang, C.; Chen, R.; Lu, Y.; Yan, Y.; Wang, H. Recurrent context aggregation network for single image dehazing. IEEE Signal Process. Lett. 2021, 28, 419–423. [Google Scholar] [CrossRef]
- Liang, Y.; Li, S.; Cheng, D.; Wang, W.; Li, D.; Liang, J. Image dehazing via self-supervised depth guidance. Pattern Recognit. 2025, 158, 111051. [Google Scholar] [CrossRef]
- Singh, P.; Komodakis, N. Cloud-gan: Cloud removal for sentinel-2 imagery using a cyclic consistent generative adversarial networks. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 1772–1775. [Google Scholar] [CrossRef]
- Pan, H. Cloud removal for remote sensing imagery via spatial attention generative adversarial network. arXiv 2020, arXiv:2009.13015. [Google Scholar]
- Lin, D.; Xu, G.; Wang, X.; Wang, Y.; Sun, X.; Fu, K. A remote sensing image dataset for cloud removal. arXiv 2019, arXiv:1901.00600. [Google Scholar]
- Cao, Z.-H.; Liang, Y.-J.; Deng, L.-J.; Vivone, G. An Efficient Image Fusion Network Exploiting Unifying Language and Mask Guidance. IEEE Trans. Pattern Anal. Mach. Intell. 2025, 1–18. [Google Scholar] [CrossRef]
- Lu, C.; Su, C. Super Resolution Reconstruction of Mars Thermal Infrared Remote Sensing Images Integrating Multi-Source Data. Remote Sens. 2025, 17, 2115. [Google Scholar] [CrossRef]
- Hore, A.; Ziou, D. Image quality metrics: PSNR vs. SSIM. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar] [CrossRef]
- Lv, M.; Song, S.; Jia, Z.; Li, L.; Ma, H. Multi-Focus Image Fusion Based on Dual-Channel Rybak Neural Network and Consistency Verification in NSCT Domain. Fractal Fract. 2025, 9, 432. [Google Scholar] [CrossRef]
- Li, L.; Song, S.; Lv, M.; Jia, Z.; Ma, H. Multi-Focus Image Fusion Based on Fractal Dimension and Parameter Adaptive Unit-Linking Dual-Channel PCNN in Curvelet Transform Domain. Fractal Fract. 2025, 9, 157. [Google Scholar] [CrossRef]
- Zhou, J.; Zhang, D.; Zou, P.; Zhang, W.; Zhang, W. Retinex-based laplacian pyramid method for image defogging. IEEE Access 2019, 7, 122459–122472. [Google Scholar] [CrossRef]
- Qin, X.; Wang, Z.; Bai, Y.; Xie, X.; Jia, H. FFA-Net: Feature fusion attention network for single image dehazing. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Song, Y.; He, Z.; Qian, H.; Du, X. Vision transformers for single image dehazing. IEEE Trans. Image Process. 2023, 32, 1927–1941. [Google Scholar] [CrossRef]
- Chi, K.; Yuan, Y.; Wang, Q. Trinity-Net: Gradient-guided Swin transformer-based remote sensing image dehazing and beyond. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–14. [Google Scholar] [CrossRef]
- Ning, J.; Yin, J.; Deng, F.; Xie, L. MABDT: Multi-scale attention boosted deformable transformer for remote sensing image dehazing. Signal Process. 2025, 229, 109768. [Google Scholar] [CrossRef]
- Leng, Z.; Wang, M.; Wan, Q.; Xu, Y.; Yan, B.; Sun, S. Meta-learning of feature distribution alignment for enhanced feature sharing. Knowledge-Based Systems 2024, 296, 111875. [Google Scholar] [CrossRef]
- Liu, H.-I.; Galindo, M.; Xie, H.; Wong, L.-K.; Shuai, H.-H.; Li, Y.-H.; Cheng, W.-H. Lightweight deep learning for resource-constrained environments: A survey. ACM Comput. Surv. 2024, 56, 1–42. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).