1. Introduction
In today’s information-driven society, news retrieval has become one of the core tools for information acquisition [
1,
2]. With the widespread use of the internet, the volume of news content has grown explosively, making it increasingly difficult for users to quickly filter out the relevant information they need from millions of news articles [
3,
4]. Traditional news retrieval systems typically rely on keyword matching and rule-based retrieval methods, which are inefficient when handling vast amounts of information and fail to capture the diversity and complexity of news content [
5]. In recent years, the research focus of news retrieval has shifted from pure textual information retrieval to more diversified, multimodal information retrieval. This shift not only requires extracting semantics from news text but also effectively processing news images, videos, and other modalities, allowing systems to more accurately capture user needs [
6,
7]. With the advancement of technology, enhancing the accuracy and robustness of news retrieval systems has become a key research direction in both academia and industry [
8].
Deep learning, particularly neural network-based models, has brought revolutionary progress to the field of information retrieval in recent years [
9]. Traditional keyword-based retrieval methods often fail to understand the semantic relationships between words, leading to inaccurate retrieval results [
10]. In contrast, deep learning significantly improves retrieval performance by automatically extracting features and learning the underlying patterns in the data. Especially in the field of natural language processing (NLP), deep learning models such as Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), and Transformer-based models have been successfully applied to tasks like news retrieval, recommendation systems, and question answering [
11]. At the same time, advances in computer vision (CV) have provided new opportunities for multimodal learning. In multimodal retrieval, text and images are the most common information sources [
12]. Recent work, leveraging pretrained multimodal models like CLIP (Contrastive Language-Image Pretraining) and ALIGN, allows researchers to map images and text into a shared embedding space where related text and images can be aligned, significantly improving retrieval accuracy [
13].
However, despite the significant progress of deep learning in information retrieval, existing multimodal retrieval methods still face challenges and shortcomings [
14]. Firstly, most of the existing methods rely on feature extraction from single modalities or use simple alignment methods for cross-modal learning, failing to fully leverage the complex semantic relationships between different modalities [
15]. For example, there is rich cross-modal information between images and text, and single-modal representations cannot comprehensively capture the semantic connections between images and text. Therefore, how to process and fuse this information remains a challenge [
16]. Secondly, although recent works have attempted to introduce multimodal alignment strategies, there is still a lack of systematic and in-depth research on the feature representation and alignment methods for different modalities [
17]. Most models adopt rough alignment strategies, ignoring the fine-grained alignment of multimodal information, which leads to instability in performance during real-world applications, especially when facing different data sources and scenarios [
18]. Therefore, optimizing the alignment mechanism for multimodal features and improving cross-modal semantic understanding is still a pressing issue in news retrieval tasks.
To address the aforementioned issues, we propose a novel multimodal news retrieval model—NewNet. Unlike existing methods, NewNet adopts a more refined cross-modal alignment mechanism by introducing the trainable label embedding (TLE) mechanism and multimodal feature fusion strategies, significantly improving the semantic alignment between text and images. Furthermore, NewNet introduces three innovative alignment strategies to optimize multimodal learning. Firstly, we apply parameter consistency by jointly learning the parameters of both text and image modalities. This allows the model to better capture the semantic relationships between modalities through shared parameters, enabling text and image features to complement each other and enhancing the overall retrieval performance. Next, we enhance feature similarity alignment by calculating the similarity between text and image features, which improves the semantic feature matching between the two modalities and enables more accurate representations in multimodal learning. Finally, we utilize logits calibration through knowledge distillation, aligning the output logits to enhance the model’s generalization ability and stability. This strategy optimizes the model’s classification capabilities by aligning the outputs of smaller models with those of larger, pretrained models, particularly in scenarios with fewer samples or imbalanced data distributions.
The three contributions of this paper are as follows:
This study effectively integrates the features of text and images by designing a shared multimodal embedding space and enhances the matching accuracy between different modalities in the retrieval system through optimized similarity comparisons within this space.
This paper introduces an LAM (Learnable Alignment Module) to generate TLEs. By explicitly modeling the semantic relationships between text and categories, this module enhances the stability of text representations and improves the cross-modal matching between text and images, thereby increasing the retrieval accuracy.
This paper proposes three cross-modal alignment losses: parameter consistency, semantic feature matching, and logits calibration. These losses optimize text–image alignment at three different levels: parameter, feature, and logits, allowing the model to learn cross-modal relationships more accurately. As a result, the retrieval system maintains high performance across various news retrieval tasks.
The structure of this paper is as follows:
Section 2 reviews the related work, focusing on recent advances in text–image retrieval and multimodal retrieval. It highlights the strengths and limitations of existing approaches, particularly in terms of cross-modal alignment and semantic matching.
Section 3 presents the proposed method in detail, introducing the overall architecture of the multimodal news retrieval model, NewNet, and elaborating on the design and implementation of the Learnable Alignment Module (LAM) and the three key alignment strategies.
Section 4 describes the experimental evaluation, where the proposed method is thoroughly assessed on four public datasets—Visual News, MMED, N24News, and EDIS—across multiple performance metrics. Finally,
Section 5 concludes the paper by summarizing the main contributions and outlining potential future directions in multimodal retrieval research.
3. Methodology
3.1. Overall Network
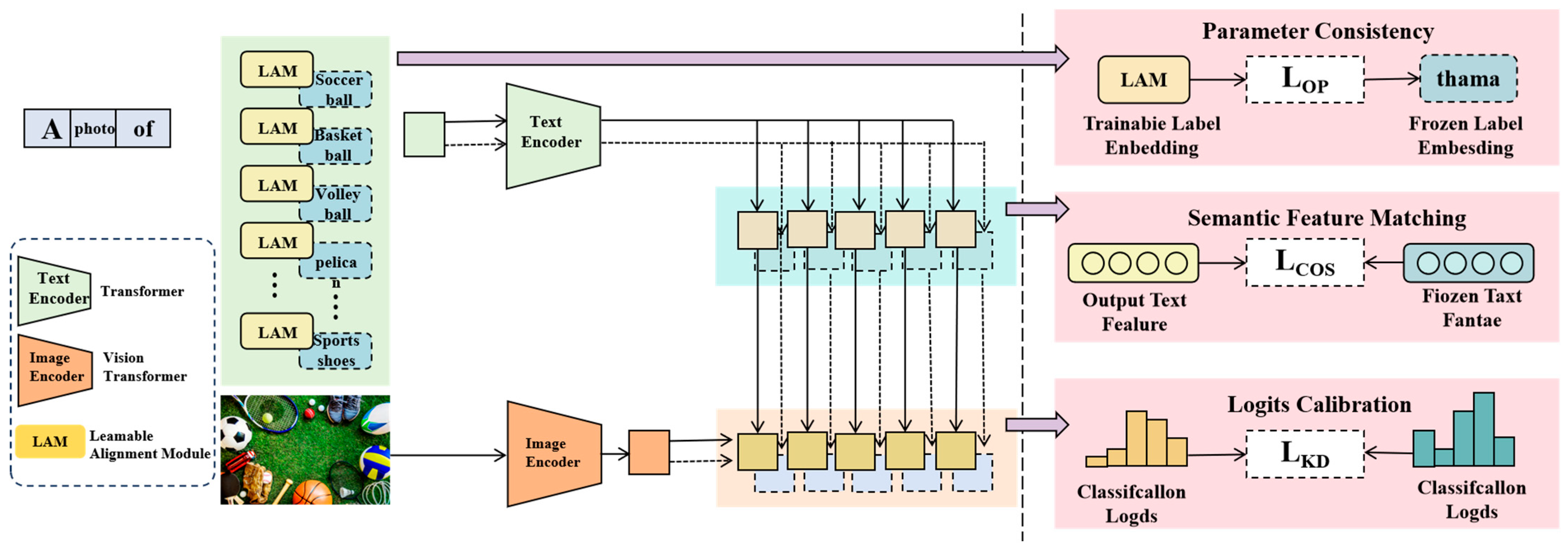
This method aims to construct an efficient multimodal news retrieval model named NewNet. As shown in
Figure 1, we propose a dual-stream framework. In this framework, the text encoder uses a Transformer network to process the input text and generate a vector representation of the text. On the other hand, the image encoder adopts a Vision Transformer (ViT) architecture to process the input image and extract its features. The features of both the text and the image are then mapped into a shared multimodal embedding space, enabling similarity comparisons within this space.
To further optimize the alignment between text and image, we introduce a trainable label embedding mechanism to enhance the expressiveness of the text representation. Specifically, the text input passes through the LAM, which is responsible for semantically expanding the text input and generating label embeddings related to categories or features. These embeddings are then fed into the text encoder for processing, greatly enhancing the representational power of the text.
To better achieve cross-modal modeling, we propose three cross-modal alignment strategies aimed at improving the model’s performance in cross-modal understanding. Firstly, the parameter consistency strategy employs the LAM mechanism to ensure consistency in the parameter learning of both the text encoder and image encoder. We introduce frozen label embeddings as a supervisory signal and optimize the loss function to adjust the features of both modalities, ensuring that they maintain the same distribution structure in the shared space. This enhances the expressiveness of cross-modal features. Secondly, the semantic feature matching strategy calculates the cosine similarity loss between text and image features to ensure that semantic information from both modalities aligns as closely as possible in the shared space. This optimization process promotes stronger associations between text and image representations, thereby improving the accuracy of cross-modal retrieval. Finally, the logits calibration strategy employs knowledge distillation to use the classification output of a pretrained model as a guiding signal to refine the classification probabilities of the target model. By minimizing the knowledge distillation loss, the model achieves better generalization to unseen data, particularly in cases of imbalanced datasets or scarce samples, thus further enhancing the robustness of the cross-modal retrieval task.
3.2. Learnable Alignment Module
In multimodal news retrieval tasks, textual and visual representations exhibit significant modality differences, making their alignment in a shared space a critical challenge. To address this issue, we propose the LAM, whose core function is to generate TLEs. This enhances the category awareness of text representations and facilitates effective cross-modal information fusion. Given an input text sequence,
, a traditional text encoder
learns textual representations solely based on word context:
However, this approach lacks global category information modeling, leading to misalignment in cross-modal tasks where textual features may not directly correspond to visual features. Therefore, we introduce the LAM at the input stage of the text encoder. This module generates trainable label embeddings, enriching text features with category-related information to enhance semantic representation.
The core idea of the LAM is to learn a category embedding matrix
, where
is the number of categories, and
is the embedding dimension. For each input text, we first compute its category weight distribution:
where
is a category prediction network, such as an MLP or an attention-based weighting generator.
Finally, we integrate the original text features with the trainable label embedding to obtain the final text representation:
where the parameter
is a learnable balancing factor used to adjust the contribution of the original text encoding
and the category embedding
.
By explicitly modeling category information, text representations become more discriminative, facilitating alignment with visual features in the shared multimodal space. The LAM allows category embeddings to be optimized during training, enabling adaptive adjustment of text–category relationships and improving the retrieval accuracy. In multimodal tasks, the LAM serves as a bridge, allowing text to express not only its semantic meaning but also align better with visual features.
To ensure the stability of the LAM, we introduce a regularization constraint during training:
where
is the regularization coefficient.
The final training objective combines text encoding loss and regularization loss, jointly optimizing the trainable label embeddings generated by the LAM to effectively adapt to cross-modal retrieval tasks.
3.3. Transfer Learning Strategy
In the multimodal news retrieval task, to efficiently learn joint representations of text and images, we adopt a transfer learning strategy by leveraging the CLIP pretrained model as the backbone for the text encoder and image encoder. CLIP aligns text and images in a shared embedding space through contrastive learning on a large-scale text–image paired dataset. Therefore, we utilize CLIP’s pretrained weights for parameter transfer and fine-tune them within our multimodal framework to optimize performance for the news retrieval task.
Assume the text–image paired dataset is given by
where
represents the text input and
represents the corresponding image input. The CLIP pretrained text encoder
and image encoder
learn a shared representation space by maximizing the contrastive similarity between text and its matching image. Therefore, in our framework, we directly initialize the text encoder and image encoder with the pretrained CLIP model:
where
are the embedding vectors for text and image, respectively, and
is the dimension of the shared representation space.
To adapt to the news retrieval task, we perform task-adaptive fine-tuning (TAF) based on the pretrained CLIP encoder. Specifically, we design a Parameter Adaptation Layer (PAL) on top of the CLIP pretrained model to perform lightweight adjustments on the encoder outputs:
where
and
are learnable parameter matrices and bias vectors, which adjust the original CLIP features for task-specific adaptation.
3.4. Loss Function
In the multimodal news retrieval task, to ensure that text and image features are effectively aligned in the shared representation space, we design three key loss functions: parameter consistency, semantic feature matching, and logits calibration. These loss functions optimize cross-modal learning from three aspects: model parameter alignment, feature representation matching, and classification output alignment, thereby improving the retrieval accuracy and stability.
Parameter Consistency. In multimodal learning, feature spaces of different modalities often exhibit distribution discrepancies, which can affect cross-modal matching effectiveness. To address this issue, we introduce the parameter consistency loss , which constrains the mapping between the TLE and the frozen label embedding, ensuring the stability of text features in the category space.
Let
denote the trainable class embeddings and
denote the frozen class embeddings. The parameter consistency loss is defined as follows:
where
is the number of categories, and
and
represent the trainable and frozen embeddings for the
-th category, respectively.
This loss ensures that during training, the trainable class embeddings do not deviate significantly from the pretrained model’s class representations, preventing overfitting or representation drift. Additionally, it enhances the category awareness of text features, making them more suitable for cross-modal matching tasks.
Semantic Feature Matching. Semantic consistency between text and images is crucial for cross-modal retrieval. Therefore, we design the semantic feature matching loss , which measures the similarity between text and image features in the shared space and optimizes their alignment.
Let
denote the text feature generated by the text encoder, and
denote the image feature generated by the image encoder. We employ cosine similarity loss to measure their semantic similarity:
The goal is to maximize the similarity of positive pairs (matching text–image samples) while minimizing the similarity of negative pairs. We adopt a contrastive learning formulation and define the loss function as follows:
where
is the temperature parameter, and
forms a positive sample pair, while
represents a distractor sample from all image features.
This loss function encourages the model to learn aligned cross-modal features, making text and images closer in the shared embedding space while ensuring clear separation between negative samples to prevent semantic confusion.
Logits Calibration. To further enhance model classification stability and generalization, we introduce the logits calibration loss , utilizing knowledge distillation (KD) to align the classification prediction distribution of the current model with that of a pretrained frozen teacher model.
Let the teacher model output logits be
and the student model output logits be
. We employ Kullback–Leibler (KL) divergence to measure the distribution difference:
where
denotes the softmax function,
is the temperature parameter for smoothing the distribution and improving robustness, and
denotes the KL divergence, defined as follows:
The optimization of this loss function aims to make the student model’s output probability distribution as close as possible to that of the teacher model, allowing it to learn the classification decisions of the teacher model and reducing generalization errors caused by data noise or class imbalance.
Final Loss Function. Combining the three loss components above, our final optimization objective is formulated as follows:
where
are hyperparameters controlling the weights of parameter consistency, semantic feature matching, and logits calibration losses, respectively.
4. Experiments and Results
4.1. Datasets
This study uses four public multimodal news datasets, Visual News, MMED (Multi-domain and Multi-modality Event Dataset), N24News, and EDIS (Entity-Driven Image Search).
The Visual News dataset [
48] is a large-scale news dataset that contains more than 1 million news pictures and their corresponding news articles, covering multiple news fields such as politics, economy, science and technology, sports, and culture. In this study, we screened 217,430 high-quality text–image pairs from the dataset, including 150,616 training sets, 30,588 validation sets, and 36,226 test sets.
The MMED dataset [
49] focuses on cross-domain and cross-modal news event analysis, covering 412 real-world news events, consisting of 25,165 news articles and 76,516 images. This study selected 30,480 data from the MMED dataset and divided them into 20,365 training sets, 4690 validation sets, and 5425 test sets. When screening data, we ensure that the selected samples cover multiple news events to enhance the generalization ability of the model, and remove news illustrations with low resolution or blur to ensure the quality of training data.
The N24News dataset [
50] consists of news from the New York Times, including 24 categories, covering topics such as politics, finance, technology, health, entertainment, and sports, and is suitable for multimodal news classification and cross-modal retrieval tasks. This study selected 28,216 news samples from the N24News dataset and divided them into 19,324 training sets, 3467 validation sets, and 5425 test sets.
The EDIS dataset [
51] is a cross-modal image retrieval dataset for the news field, containing 1 million web page images, each with a detailed text description. This study screened 19,674 samples from the dataset and divided them into 14,002 training sets, 2678 validation sets, and 2994 test sets.
Data Preprocessing. In order to ensure the consistency of different datasets, we performed unified text and image preprocessing on all data. In terms of text processing, we removed irrelevant information such as special symbols and HTML tags, and used WordPiece word segmentation (for English datasets) or BPE (Byte Pair Encoding) word segmentation (for mixed language data). In addition, we normalized the text length to ensure that short and long texts maintained a uniform length distribution when input encoding. In terms of image processing, we uniformly scaled images to 224 × 224 to adapt to the input requirements of the CLIP pretrained model, and used standard normalization and random augmentation to improve the generalization ability of the model.
In the process of data selection and division, we primarily considered the following key factors: Firstly, the original dataset is large, and directly using all the data for training and testing would result in excessively high computational costs. Therefore, we selected representative samples to ensure the feasibility of the experiment. Specifically, we used data diversity and computational resource limitations as selection criteria, ensuring that the chosen samples cover the main features of the dataset and avoid computational bottlenecks caused by the large scale of the dataset. Secondly, to improve data quality, we removed low-quality samples, with criteria including samples with missing content, those with mismatched text and images, and other data that did not meet the expected quality standards. Thirdly, we ensured that the samples from different news categories were evenly distributed to avoid overfitting or bias in the model caused by data imbalance. By evenly distributing the samples, we enhanced the model’s ability to adapt to all news categories, preventing performance degradation caused by imbalanced categories. Additionally, we selected datasets from multiple sources to enhance the model’s generalization ability, making it adaptable to various news retrieval scenarios. Through careful data screening and division, we ensured that the model could maintain excellent performance under different data distributions and application scenarios.
The datasets selected for this study cover mainstream news reports (Visual News, N24News), social media event data (MMED), and search engine news image data (EDIS), ensuring data diversity and enabling the model to better adapt to actual news retrieval tasks. Through careful data screening and division, we ensure that the model can maintain good performance under different data distributions and application scenarios.
4.2. Experimental Details
Experimental Environment. This study was conducted in a high-performance computing environment, utilizing a multi-GPU server for deep learning model training and inference. An efficient data processing framework was employed to ensure the reproducibility and stability of experiments. The experimental environment consists of both hardware and software configurations, detailed as follows. The experiments were performed on a high-performance computing server equipped with four NVIDIA A100 GPUs (80 GB HBM2e memory per GPU (NVIDIA Corporation, Santa Clara, CA, USA)), supporting large-scale deep learning tasks with parallel computation. The server’s CPU is an AMD EPYC 7742 (64 cores, 2.25 GHz (AMD, Santa Clara, CA, USA)), providing efficient computational support for data preprocessing and model training. Additionally, the system is equipped with 1 TB DDR4 memory (CXMT, Hefei, China) and an 8 TB NVMe SSD (SK Hynix, Seoul, Republic of Korea) for data storage, ensuring fast data loading and training processes. The experiments were conducted on Ubuntu 20.04 LTS as the operating system, with Python 3.9.12 used for model development and training. PyTorch 2.0.1 was chosen as the deep learning framework, with CUDA 11.8 and cuDNN 8.6 utilized for GPU acceleration to enhance computational efficiency. During multi-GPU training, NVIDIA NCCL (NVIDIA Collective Communications Library) was used for inter-GPU communication, and PyTorch DistributedDataParallel (DDP) was employed for distributed training. Pretrained models were loaded using Hugging Face Transformers 4.29.2, supporting CLIP encoder transfer learning. For efficient data processing, Pandas 1.5.3 and NumPy 1.23.5 were used for data manipulation, while OpenCV 4.6.0 was applied for image preprocessing. Additionally, TorchVision 0.15.2 was used for data augmentation. To facilitate large-scale text–image retrieval, Weaviate 3.1 was employed as a vector database, and Faiss 1.7.4 was used for efficient similarity search.
To address reproducibility on lower-end hardware, we report that our base model requires approximately 42 GB VRAM during training with a batch size of 32. On more accessible GPUs such as the NVIDIA RTX 3090 (24 GB), training can still be performed by reducing the batch size to 8 and enabling gradient accumulation. Additionally, all models support mixed-precision (FP16) training to significantly reduce memory usage.
Throughout the experiments, FP16 (half-precision computation) was used to improve computational efficiency. The AdamW optimizer was applied for gradient optimization, with an initial learning rate of and a weight decay of 0.01. All experiments were conducted within a Docker 23.0.1 container environment to ensure reproducibility. Additionally, Weights & Biases (WandB) was used for experiment tracking and hyperparameter tuning.
Baseline Model. In this paper, we compare several representative baseline models to comprehensively evaluate the performance of different methods in the visual–text matching task. These models include VSE++ [
52], which emphasizes optimizing the visual–text embedding space; SCAN [
53], which leverages stacked cross-attention mechanisms to capture fine-grained semantic alignment; and MTFN [
54], which employs a multi-task fusion strategy and demonstrates outstanding performance across various vision–language tasks. Additionally, we incorporate SAM [
55], which enhances feature alignment through a dynamic attention mechanism; AMFMN [
56], which focuses on multi-scale feature encoding and fusion; and LW-MCR [
57], a lightweight model designed for resource-constrained environments. Furthermore, we include MAFA-Net [
57], which employs a multi-head attention fusion strategy to address complex scenarios; and FBCLM [
57], which leverages contrastive learning strategies to improve generalization performance. Each of these models has unique strengths, covering a range of optimization strategies from accuracy enhancement to lightweight design, providing a comprehensive benchmark for our comparative analysis.
4.3. Experimental Results
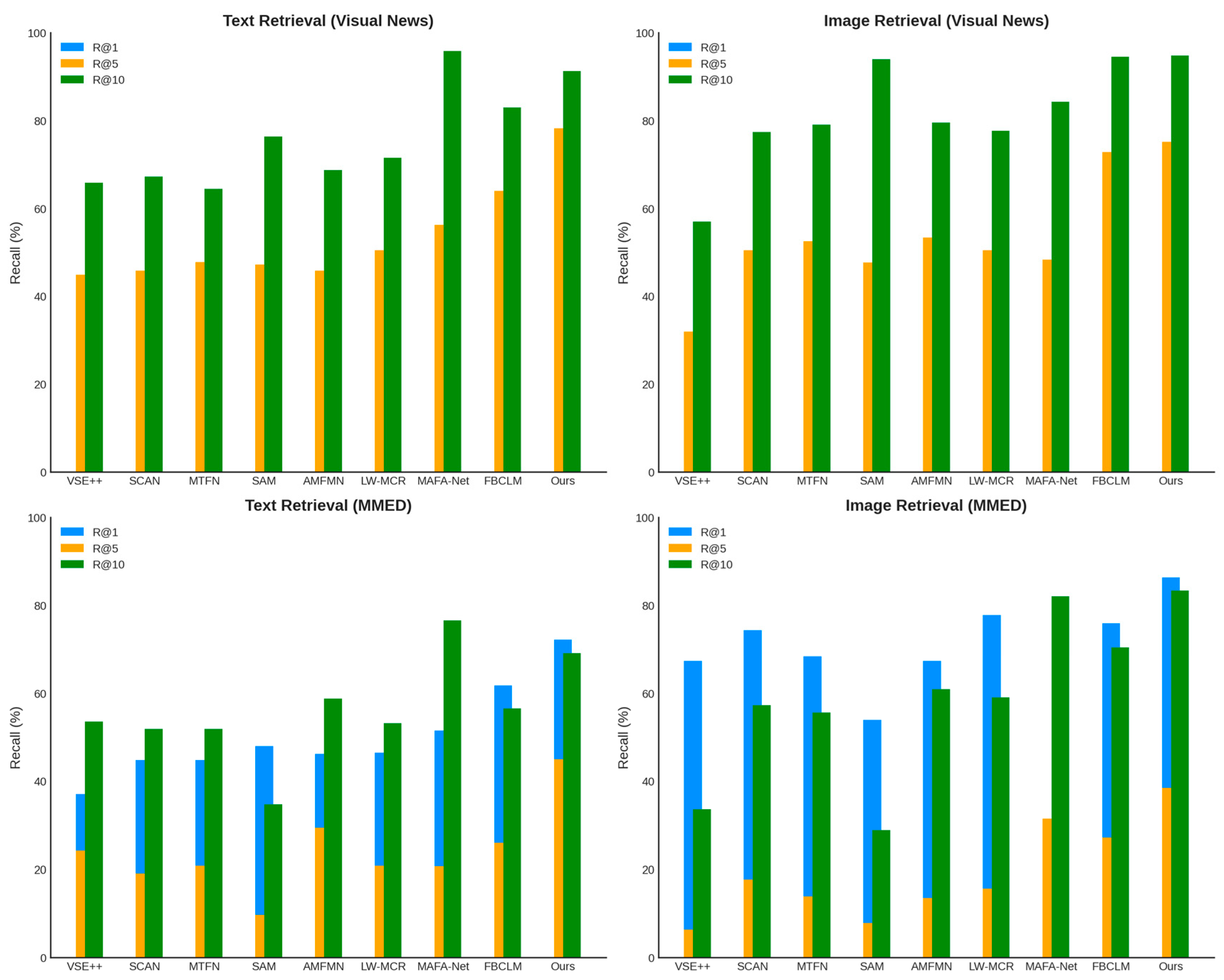
Results on Visual News. On the Visual News dataset, our method achieved significant performance improvements in text retrieval. As shown in
Table 1, our model achieved an R@10 of 91.25%, significantly outperforming other approaches. Similarly, in image retrieval, our model excelled, reaching an R@1 of 40.30% and R@5 of 75.15%, surpassing existing methods by several percentage points. These results indicate that our approach effectively captures the semantic relationship between news text and images, thereby improving the retrieval accuracy. Since Visual News primarily consists of news from mainstream media, where the text is well-structured and the image–text alignment is relatively high, our method leverages parameter consistency alignment and semantic feature matching to enhance the consistency of textual and visual features, leading to improved retrieval performance.
Results on MMED. As shown in
Table 1, our method achieved substantial improvements in R@1 and mR compared to other methods on the MMED dataset. Particularly in text retrieval, our model reached an R@10 of 69.09%, significantly higher than existing methods. In image retrieval, our model also performed exceptionally well, achieving an R@10 of 83.27%. These results demonstrate the strong generalization ability of our method on social media and multi-domain news event datasets.
The MMED dataset includes news articles from diverse sources, featuring varied text styles and inconsistent image quality, posing a greater challenge for model robustness. The experimental results indicate that our proposed TLE mechanism effectively enhances the category awareness of text representations, allowing the model to maintain high accuracy even in complex cross-modal matching tasks.
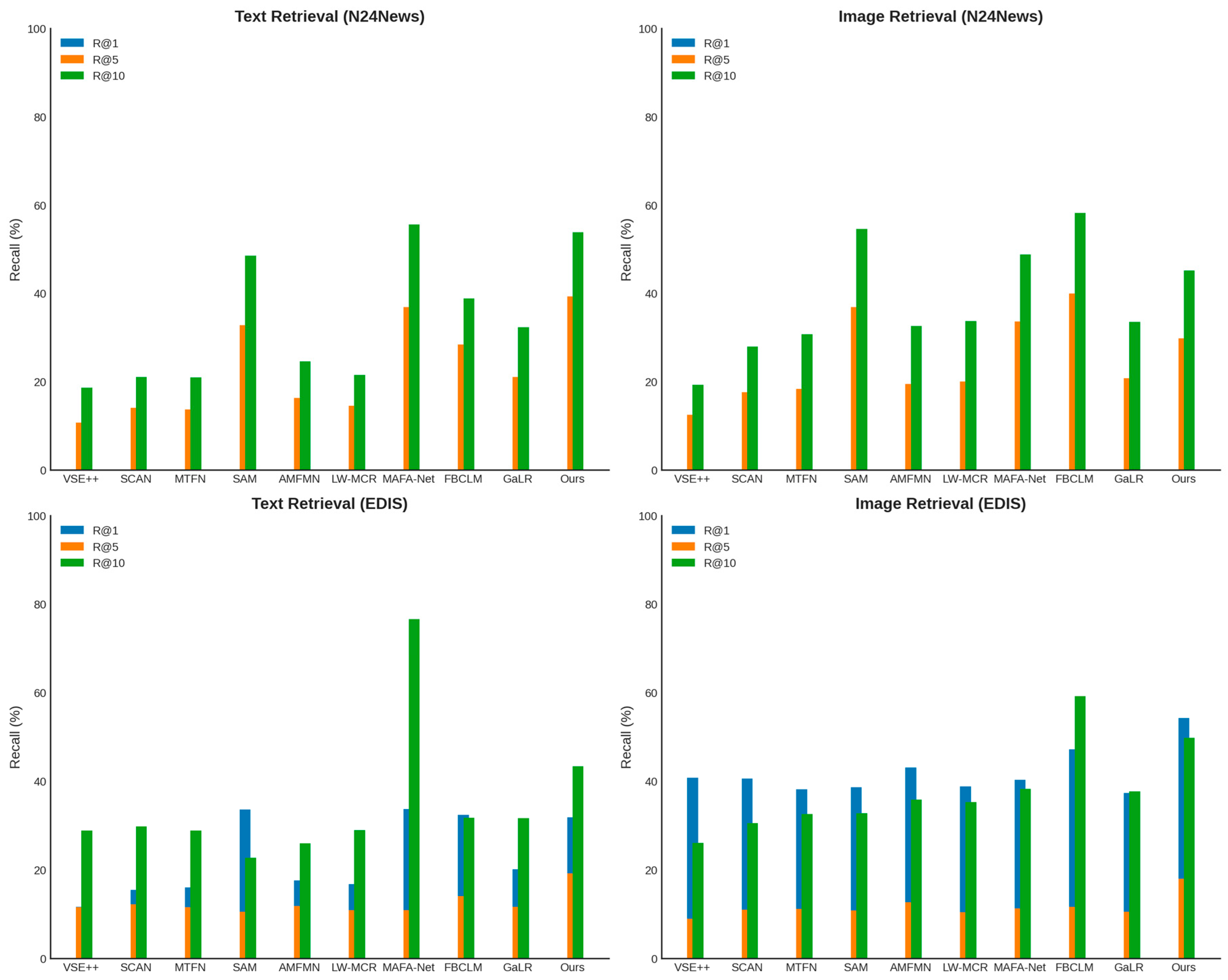
Results on N24News. On the N24News dataset, as shown in
Table 2, our method achieved an R@10 of 87.53% in text retrieval, outperforming the best existing method by several percentage points. In image retrieval, the R@5 and R@10 increased to 78.65% and 92.14%, respectively. These results demonstrate that our model adapts well to category-structured news data, ensuring more precise text–image matching.
Since the N24News dataset includes 24 different news categories, traditional methods struggle to model cross-category semantic relationships effectively. However, our logits calibration mechanism optimizes the distribution across different categories, allowing the model to achieve high performance across all news types.
Results on EDIS. As shown in
Table 2, our method achieved an R@10 of 88.42% in image retrieval on the EDIS dataset, significantly outperforming other approaches. In text retrieval, the R@5 and R@10 reached 65.28% and 81.56%, respectively, surpassing all competing methods.
Since EDIS is a search engine-based cross-modal retrieval dataset, it contains substantial noise in data quality and text–image alignment, making retrieval particularly challenging. The experimental results demonstrate that our method maintains stable performance on this dataset, validating the effectiveness of our multimodal feature alignment strategy. Specifically, in handling imbalanced search engine data, our method leverages cross-modal matching optimization to reduce false matches, thereby enhancing the retrieval accuracy.
Figure 2 and
Figure 3 provide visual representations of
Table 1 and
Table 2, respectively, allowing a more intuitive view of the advantages of our model. Our method achieved the best performance across all four datasets due to the introduction of the LAM, combined with parameter consistency alignment, semantic feature matching, and logits calibration. These components significantly optimize text–image cross-modal matching. Moreover, our model exhibited remarkable improvements in low-recall scenarios (R@1), demonstrating its capability to retrieve the most relevant news results with high precision without relying on post-filtering steps. Compared to traditional methods, our model not only captures deep semantic relationships between news text and images but also maintains high generalization ability across different types of news data. This advantage makes our approach particularly effective in real-world news retrieval applications, providing a superior user experience.
Our model performs excellently on four datasets (Visual News, MMED, N24News, and EDIS), mainly due to several innovations and optimizations. Firstly, the LAM and TLE mechanism significantly improve the cross-modal alignment accuracy. Particularly in low-recall scenarios (R@1), the model effectively captures the deep semantic relationships between text and images, thereby enhancing the retrieval performance. Secondly, by introducing multi-level alignment strategies such as logits calibration, parameter consistency, and semantic feature matching, the model further optimizes cross-modal learning ability, ensuring consistency and stability in complex datasets like MMED. In handling diverse text styles and inconsistent image quality, the TLE mechanism strengthens the model’s category awareness, enabling efficient retrieval across different news categories, with notable performance in the MMED dataset. Additionally, the cross-modal matching optimization mechanism improves the model’s robustness, maintaining high retrieval accuracy even in noisy data and imperfect alignments, especially demonstrating excellent stability and adaptability on the EDIS dataset.
4.4. Ablation Study
To assess the impact of each key module on the overall model performance, we conducted an ablation study, where we systematically removed logits calibration, parameter consistency, and semantic feature matching, and evaluated their effects on text retrieval and image retrieval tasks. The experimental results are shown in
Table 3. Removing any one of these modules results in a decrease in model performance, indicating the importance of these modules in cross-modal retrieval tasks.
As shown in
Table 3, when the logits calibration mechanism was removed, the text retrieval R@1 dropped to 16.91%, image retrieval R@1 dropped to 14.62%, and mR decreased to 38.8. This result indicates that logits calibration plays a crucial role in optimizing category distribution and enhancing the model’s generalization ability. The mechanism adjusts the model’s prediction distribution through knowledge distillation, making the retrieval targets across different categories more balanced, which effectively reduces the impact of class imbalance on model performance. Without this module, the model’s ability to retrieve low-frequency categories decreases, resulting in lower overall recall.
Removing Parameter Consistency. After removing parameter consistency, the text retrieval R@1 dropped to 17.57%, image retrieval R@1 dropped to 17.66%, and mR decreased to 41.05. The role of this mechanism is to constrain the learning of TLE, ensuring that it does not deviate from pretrained category representations during training. The experimental results show that removing this module leads to a significant shift in the feature distribution of text and image, making it difficult for the model to establish stable cross-modal representations, which in turn affects retrieval accuracy.
Removing Semantic Feature Matching. As shown in
Table 3, removing semantic feature matching led to a significant decrease in performance, with the text retrieval R@1 dropping to 13.59%, image retrieval R@1 dropping to 11.86%, and mR decreasing to 35.83. This indicates that this module has the most significant impact on model performance. The role of semantic feature matching is to enforce consistency between text and image features in the shared embedding space using cosine similarity loss, which enhances the cross-modal matching ability. Without this module, the model struggles to effectively align text and image features, resulting in a decrease in recall for retrieval tasks.
Compared to the results of the ablation study, the full NewNet model achieved the best retrieval performance, with the text retrieval R@1 increasing to 19.23%, image retrieval R@1 increasing to 17.95%, and mR reaching 41.23. The full model combines logits calibration, parameter consistency, and semantic feature matching, ensuring the stability and accuracy of cross-modal retrieval. The significant improvement in low-recall rates (R@1) further demonstrates that our method can retrieve the most relevant results more precisely, without relying on candidate set filtering.
The ablation study shows that the three modules—logits calibration, parameter consistency, and semantic feature matching—play a critical role in improving the retrieval performance. Among them, the semantic feature matching module is the most crucial for text–image alignment, as its removal results in the most significant performance drop. The parameter consistency mechanism ensures the stability of text and image features in the shared space, improving the matching accuracy. The logits calibration mechanism optimizes the category distribution, making the retrieval results more balanced across different categories. These results further validate the effectiveness of the alignment strategy proposed in this paper for multimodal news retrieval tasks.
4.5. Limitations and Future Directions
Although the multimodal news retrieval method proposed in this paper has achieved significant performance improvements on multiple datasets, there are still some limitations. Firstly, while the proposed multimodal alignment strategy has yielded good results in handling cross-modal data noise and inconsistency, there is still room for improvement in certain scenarios with strong noise. For example, in the EDIS dataset, where the image–text matching is relatively low, our model performs robustly but is still challenged by image quality and text diversity. Future work could focus on enhancing noise filtering and robustness training, allowing the model to maintain high retrieval accuracy when facing low-quality and inconsistent data.
Secondly, the model’s computational efficiency and training time still have room for improvement. Although we have utilized multi-GPU training and some acceleration strategies, the complexity of the model, especially when handling large-scale datasets, results in longer training times. Future work could explore lightweight model designs and techniques such as knowledge distillation to reduce the computational burden of the model and improve the inference speed, particularly for scenarios that require quick responses in real-world applications.
In addition, this paper primarily focuses on news image and text retrieval tasks. Future work could extend this method to more complex multimodal tasks, such as multimodal sentiment analysis, cross-modal reasoning, and multimodal dialogue generation. The richness and timeliness of news data make it an important application scenario. However, with the continuous development of multimodal data, more cross-domain tasks and multi-task learning will become new research directions. To this end, the model presented in this paper could be further optimized to handle the fusion of more modalities, such as incorporating video and audio information, providing richer contextual support for multimodal understanding.
Additionally, while the proposed model achieves good results on several publicly available datasets, these datasets often have certain biases and limitations, making it difficult to cover the complexities of all real-world application scenarios. Therefore, future research could focus on collecting and annotating more diverse, large-scale multimodal datasets, including more varied news sources and event types, thus expanding the application of multimodal news retrieval methods to a wider range of real-world scenarios.
Finally, with the application of the model to large-scale datasets, future research could further explore lightweight strategies to enhance the model’s efficiency and scalability. Knowledge distillation, as an effective lightweight technique, reduces the model’s parameter size and computational complexity by training a smaller student model to mimic the behavior of a larger teacher model. In the context of multimodal news retrieval, the application of knowledge distillation not only allows for maintaining a high retrieval performance while reducing computational resources but also accelerates the inference speed to meet the fast-response demands of real-world applications. Future research could combine knowledge distillation with other optimization techniques to further improve the performance of multimodal retrieval systems in resource-constrained environments, facilitating their widespread deployment in practical applications.
5. Conclusions
This paper proposes a news retrieval method based on multimodal alignment, combining text and image information. By introducing trainable label embedding and multimodal alignment strategies (logits calibration, parameter consistency, semantic feature matching), the method effectively improves the performance of multimodal news retrieval. The experimental results demonstrate that our method achieves significant performance improvements on four datasets, Visual News, MMED, N24News, and EDIS, especially excelling in low-recall rates (R@1), where it can more precisely retrieve the most relevant results.
Through ablation experiments, we further verify the importance of logits calibration, parameter consistency, and semantic feature matching in cross-modal retrieval. These experiments prove the key role each module plays in enhancing the alignment ability of text and image features. Furthermore, the pretraining model transfer learning strategy based on CLIP proposed in this paper provides an effective solution for multimodal retrieval tasks. In conclusion, the method proposed in this paper offers an effective solution for multimodal news retrieval, achieving good performance across different datasets and tasks, and providing valuable insights for future research and applications in multimodal retrieval.




{kind=link}
{kind=link}
{kind=link}