1. Introduction
Multimodal object detection plays an increasingly critical role in real-world applications such as surveillance [
1,
2], autonomous driving [
3], and nighttime perception [
4]. These scenarios are typically characterized by complex and dynamically changing visual conditions, including illumination variations, occlusion, and environmental interference such as smoke or fog. Under conditions of good visibility, visible images provide rich visual information such as texture, color, structure, and edge details, making them highly valuable for accurate object recognition. However, when exposed to adverse environments such as low-light scenes, severe occlusion, or strong backlighting, the representational capacity of RGB images degrades significantly, resulting in compromised detection performance. In contrast, infrared (IR) images capture thermal radiation emitted by objects and are independent of ambient light, allowing them to maintain stable perception under poor lighting conditions. Nevertheless, IR images often lack the detailed structural and textural cues available in RGB imagery. Therefore, relying solely on a single modality is often insufficient to address the diverse perceptual challenges in complex environments. By combining the fine-grained visual details of RGB with the illumination-invariant characteristics of IR, it is possible to exploit complementary information and enhance the reliability and adaptability of object detection systems across various environmental conditions.
Although multimodal fusion techniques have achieved considerable progress, current methods still suffer from the following three critical weaknesses:
Weakness 1: Lack of scene-aware modeling of modality reliability.
In practical applications, the perceptual effectiveness of each modality can fluctuate significantly with environmental factors such as illumination, occlusion, and thermal interference. However, most existing multimodal fusion methods—such as DenseFuse [
5], CDDFuse [
6], and CUFD [
7]—rely on fixed weighting schemes or static heuristic rules. These methods lack the capacity to model the relationship between scene semantics and modality reliability, making it difficult to dynamically adjust modality contributions in response to changing conditions. As a result, models often misidentify the dominant modality, for instance, by over-relying on RGB images in nighttime scenes or amplifying low-quality IR features in thermally cluttered environments, ultimately leading to reduced detection accuracy and unstable performance.
As shown in
Figure 1, RGB and IR modalities demonstrate distinct advantages under varying environmental conditions, highlighting their strong complementarity. In subfigure (a), under nighttime scenes with strong glare interference from vehicle headlights, the RGB image suffers from visual degradation and fails to reveal the pedestrian in the red-marked region, whereas the IR image clearly highlights the human target based on thermal radiation. Similarly, in subfigure (b), dense smoke causes severe occlusion in the RGB image, making it difficult to distinguish objects, while the IR modality still provides sufficient contrast to identify the pedestrian. In contrast, subfigures (c) and (d) depict well-lit daytime scenarios where the RGB modality excels. RGB images offer richer color, texture, and structure, allowing for more accurate recognition of dense crowds or small-scale pedestrians. In these cases, IR imagery may suffer from limited discriminability due to uniform thermal backgrounds or reduced temperature differences between targets and surroundings. These observations underscore the context-dependent superiority of each modality: IR is more effective in low-visibility or occluded environments, while RGB is preferable in scenes with sufficient illumination and complex structural information. They also reveal the limitations of static fusion strategies, which fail to fully exploit the complementary nature of RGB and IR under diverse conditions.
Therefore, it is crucial to design a scene-aware and dynamically adaptive fusion mechanism that can identify the dominant modality in real time, adjust modality contributions based on environmental semantics, and enable fine-grained cross-modal cooperation. This insight serves as a key motivation for the development of our proposed CLSANet framework.
Weakness 2: Static fusion strategies lack region-level adaptability.Most existing multimodal fusion methods apply a uniform fusion rule across the entire image [
5,
8,
9], without accounting for the fact that different semantic regions—such as foreground versus background or object boundaries versus interior areas—may exhibit distinct modality preferences. Specifically, foreground objects often rely on the rich texture, color, and shape cues provided by RGB images to support accurate localization and classification, while background or peripheral regions are typically better represented by the contour-preserving and illumination-insensitive characteristics of IR imagery, especially under challenging lighting conditions. Such spatially invariant fusion designs ignore the coupling between regional semantics and modality-specific advantages [
7,
10], leading to the inclusion of redundant or even conflicting features. This not only increases the burden of feature redundancy, but may also enhance background interference or blur object boundaries, ultimately limiting the model’s ability to fully exploit complementary multimodal information at a fine-grained spatial level.
Weakness 3: Lack of modality contribution modeling hinders interpretability of detection results.Most existing multimodal object detection methods do not explicitly model the individual contributions of RGB and IR modalities to the final decision [
11,
12,
13]. Instead, they typically generate highly entangled fused features by directly concatenating or weighting the modality-specific features. As a result, when the detector outputs bounding boxes or classification scores, it is difficult to determine which modality primarily influenced the decision. This lack of modality-level attribution limits the interpretability of the model, making it challenging to diagnose errors or performance fluctuations—particularly in failure cases. Moreover, current fusion strategies generally lack mechanisms to perceive and adapt to dynamic variations in modality quality. For example, under low-light conditions or when IR suffers from thermal interference, the model cannot selectively suppress noisy signals, which may degrade detection stability. In real-world applications such as nighttime surveillance or autonomous driving in adverse conditions, the inability to interpret and control modality behavior becomes a major obstacle to reliable deployment.
To address the above challenges, we propose a novel Cognitive Learning-based Self-Adaptive Feature Fusion Network (CLSANet). Inspired by the human perceptual ability to selectively focus on the most informative sensory input, CLSANet is designed to dynamically adjust modality contributions based on scene semantics and local visual complexity [
14]. It adopts a modular and lightweight front-fusion architecture tailored to efficient RGB-T(RGB-IR) object detection and consists of the following three components:
Dominant Modality Identification (DMI): This module analyzes global scene context in real time and selects the most informative modality as the dominant one, guiding the subsequent fusion process.
Modality Enhancement (ME): An attention-driven feature disentanglement mechanism is introduced to explicitly decompose modality features into shared and differential components, enhancing semantic specificity and cross-modal complementarity.
Self-Adaptive Fusion (SAF): This module incorporates both global semantics and local region complexity to dynamically regulate modality-wise fusion weights, enabling fine-grained, interpretable multimodal integration.
We conduct extensive experiments on three public RGB-T detection benchmarks—M3FD, LLVIP, and MSRS—to validate the effectiveness of CLSANet under varying environmental conditions, including illumination changes and thermal noise.
The main contributions of this work are summarized as follows:
We propose a cognitive learning-based adaptive fusion strategy that explicitly models the relationship between scene semantics and modality reliability, enabling dynamic dominant modality selection.
We design a region-aware Modality Enhancement Module that disentangles and reinforces shared and differential features, improving the discriminative power and reliability of the fused representation.
We develop a lightweight, interpretable, and detector-friendly RGB-T fusion framework that achieves state-of-the-art performance on multiple benchmarks, with high inference efficiency and deployment flexibility.
The remainder of this paper is organized as follows:
Section 2 reviews related work on multimodal fusion and object detection;
Section 3 presents the CLSANet architecture and key modules;
Section 4 details the experimental settings, datasets, and evaluation results;
Section 5 provides an in-depth discussion of the findings, analyzes their implications, and addresses potential limitations; and
Section 6 summarizes the main contributions and outlines future research directions.
3. The Proposed Method
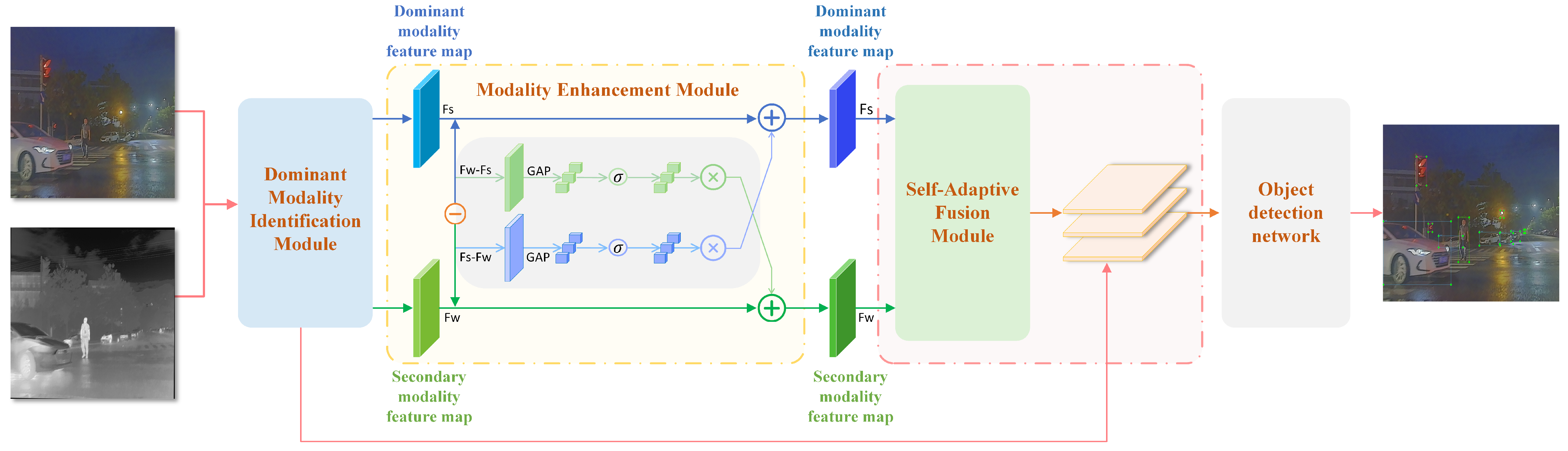
Our proposed CLSANet method dynamically adapts to the varying strengths of infrared and visible images across different environmental conditions, addressing key challenges in multimodal object detection. The framework is composed of three primary modules: the Dominant Modality Identification Module, the Modality Enhancement Module, and the Self-Adaptive Fusion Module. These components work synergistically to determine the dominant modality, enhance modality-specific features, and adaptively balance modality contributions in the fusion process to improve overall detection accuracy.
3.1. Problem Formulation
Let and denote the visible (RGB) and infrared (IR) images, where H, W, and C represent the image height, width, and number of channels, respectively. In this work, both modalities are mapped to three-channel representations () to ensure consistent dimensionality for fusion.
The goal of CLSANet is to generate a fused feature representation
that adaptively integrates complementary information from both modalities to enhance object detection performance under varying environmental conditions. As illustrated in
Figure 2, the overall pipeline comprises three key stages:
Dominant Modality Identification dynamically identifies the dominant modality by analyzing real-time environmental cues (e.g., lighting conditions, scene complexity). The network selects the modality with the most informative features for each scene, enhancing detection accuracy across varying conditions [
35].
Modality Enhancement refines modality-specific features by separating them into shared and differential components. This preserves unique modality characteristics while enhancing complementary information, improving feature quality and robustness for accurate multimodal detection.
Self-Adaptive Fusion integrates features from both modalities using an adaptive weighting mechanism that adjusts in real time based on scene complexity. This dynamic balancing ensures consistent performance across diverse conditions, maintaining detection reliability and accuracy in fluctuating scenarios.
3.2. Dominant Modality Identification Module
In multimodal object detection, the contribution of each modality to discriminative capability varies substantially across different scenes. To adaptively select the modality providing the most informative cues under varying conditions, we propose a Dominant Modality Identification (DMI) module that models global scene semantics to determine modality dominance.
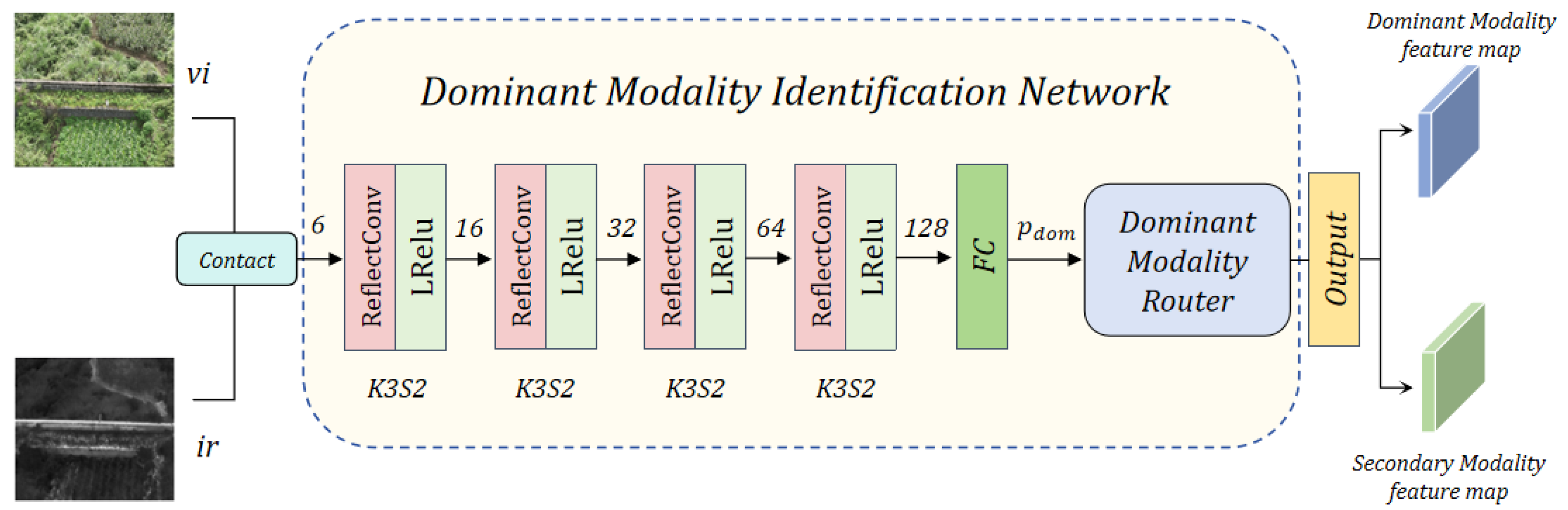
As illustrated in
Figure 3, the DMI module first concatenates the RGB image
and the infrared image
along the channel dimension to form a joint feature map:
Direct concatenation may introduce statistical inconsistencies due to differences in modality-specific distributions. Thus, we employ a lightweight convolutional encoder
comprising multiple
convolutional layers with a stride of 2, each followed by BatchNorm and LeakyReLU activation. The number of output channels progressively increases from 6 to 16, 32, 64, and 128. This design allows the encoder to extract cross-modal local structural information and project features into a unified representation space:
We apply global average pooling to
to obtain a scene-level semantic vector:
This vector is then passed through a fully connected layer with learnable weights
and bias
, followed by a sigmoid activation to produce the probability that the RGB modality is dominant under the current conditions:
Based on this probability, the dominant modality
is selected as
Here, quantifies the likelihood that the RGB modality provides superior discriminative cues relative to the infrared modality in the current scene. The selected dominant modality guides the subsequent fusion stage, while the secondary modality complements the feature representation. Through end-to-end training, the model learns optimal decision boundaries, ensuring accurate dominant modality selection across diverse environments and enhancing the performance and generalization capability of the multimodal detection framework.
3.3. Modality Enhancement Module
To enrich modality-specific representations and improve the discriminative capacity of fused features, we propose a lightweight yet effective
Modality Enhancement Module based on residual difference modeling with attention modulation [
36]. This module is designed to enhance both strong and weak modality streams by injecting complementary residual cues derived from their mutual differences, guided by channel-level importance weights.
Let
and
denote the feature maps of the strong and weak modalities, respectively, as determined in the modality selection stage (
Section 2.2). We compute bidirectional difference residuals:
Here, denotes global average pooling applied along the spatial dimensions to each channel independently, and represents sigmoid activation. These operations produce soft attention weights that highlight semantically informative channels in the difference tensors.
The final enhanced feature maps are obtained by injecting the residuals back into the original modality streams:
Through this mechanism, both modalities are simultaneously refined by the residual differences computed from the other, while the attention modulation ensures that only relevant, high-activation channels are emphasized.
3.4. Self-Adaptive Fusion Module
After obtaining the enhanced features
and
from the dominant and subordinate modalities, respectively (as described in
Section 3.3), we introduce a
Self-Adaptive Fusion Module to dynamically integrate them into a unified representation for detection.
Instead of using fixed or equal weights, the module learns a spatially adaptive weight map to determine the contribution of each modality at every spatial location. This allows the fusion to flexibly emphasize one modality over the other depending on the scene context, such as occlusion, lighting, or texture complexity.
The fusion weights are computed by first concatenating
and
along the channel dimension and applying a
convolution layer:
Here,
takes an input with
channels and outputs two channels, corresponding to the spatial weights
and
. A softmax is applied along the channel dimension at each spatial location to ensure that
Using the learned weights, the fused feature map is calculated as
To further refine the fused representation, we apply a non-linear transformation via a convolutional block:
where
is a
convolution layer with input and output channels equal to
C, and ReLU introduces non-linearity for noise suppression and salient feature enhancement.
The final refined output serves as input to the detection head, providing a balanced, semantically rich multimodal representation.
4. Experiments
In this section, we present a comprehensive evaluation of our proposed CLSANet method. We introduce the benchmark datasets, detail the experimental setup, and compare CLSANet with existing state-of-the-art methods. Furthermore, we perform ablation studies to investigate the contributions of each core component in the CLSANet architecture.
4.1. Datasets
To assess the effectiveness and generalization ability of CLSANet, we conduct experiments on three widely used multimodal object detection benchmarks, M
3FD [
37], LLVIP [
38], and MSRS [
39], as summarized in
Table 1. These datasets provide challenging and diverse scenarios in terms of illumination conditions, object categories, and environmental complexity, enabling fair and comprehensive comparisons with prior multimodal detection methods.
M3FD:This dataset comprises 4200 pairs of RGB-T images with a resolution of 1024 × 768. It covers diverse scenes, including daytime, nighttime, and smoke-covered environments. With six object categories, it serves as a strong benchmark for evaluating performance consistency under illumination variations and occlusions.
LLVIP: Specifically designed for low-light pedestrian detection, LLVIP contains 15,488 aligned RGB-T image pairs at 1280 × 1024 resolution. It focuses on challenging nighttime scenes with a single object class (pedestrian), making it ideal for validating performance under extremely poor visibility.
MSRS: The MSRS dataset includes 1569 high-quality, pixel-aligned image pairs collected under both day and night conditions. Each pair is annotated with bounding boxes from three object classes. Its balanced composition across modalities and scenes makes it suitable for evaluating detection precision and fusion generalization.
4.2. Experimental Setup
All experiments were conducted using the PyTorch (version 2.4.0) framework with CUDA 12.4, running on a system equipped with three NVIDIA A100 GPUs. and one A6000 GPU. Our framework first applies the proposed CLSANet module to extract and fuse features from aligned RGB and infrared images. The fused representation is then passed to the YOLOv7 detector for object prediction. This design enables CLSANet to enhance cross-modal representation before entering the detection stage.
The network was trained using the Adam optimizer with an initial learning rate of 0.01, decayed via a cosine annealing schedule to facilitate convergence. Input images were resized to resolution, and the batch size was adjusted according to available GPU memory. Each model was trained for 300 epochs to ensure adequate convergence.
For all datasets (M3FD, LLVIP, and MSRS), we adopted a random 80–20% split for training and testing. To enhance generalization, standard data augmentation techniques such as random flipping and color jittering were applied during training.
Evaluation followed the COCO object detection protocol using two standard metrics: mAP@50 and mAP@95. The mAP@50 measures mean average precision under a fixed IoU threshold of 0.5, indicating performance under lenient matching conditions. In contrast, mAP@95 averages precision over IoU thresholds from 0.5 to 0.95 (in steps of 0.05), reflecting the model’s ability to handle stricter localization requirements. All reported results are averaged over three independent runs to ensure statistical reliability.
4.3. Quantitative Analysis
We evaluate the performance of CLSANet on three widely used benchmark datasets: M3FD, LLVIP, and MSRS. The evaluation includes comparisons with several state-of-the-art multimodal fusion methods. Performance is measured using mean average precision at IoU thresholds of 50% () and 95% (), which assesses overall detection capability and localization precision under stricter conditions, respectively. This dual-metric setting provides a comprehensive view of the model’s accuracy and performance across diverse scenarios.
As shown in
Table 2, CLSANet achieves the highest
of 0.950 on the M
3FD dataset, significantly outperforming recent state-of-the-art methods such as MFMGF-Net (0.930) and TarDAL (0.927). Under the more stringent
criterion, CLSANet continues to exhibit superior performance with a score of 0.660. Furthermore, it achieves the best category-specific precision in challenging classes such as “Person” (0.924) and “Car” (0.964), demonstrating its strong capability to generalize across diverse and complex environments.
It is worth noting that several baseline methods, including DenseFuse and FusionGAN, adopt fixed-weight or simple concatenation strategies that fail to adaptively adjust to environmental changes. In contrast, models such as MFMGF-Net, TarDAL, and our CLSANet introduce scene-aware adaptive fusion mechanisms. Under identical evaluation settings, methods with adaptive fusion consistently outperform fixed-fusion baselines, providing quantitative evidence supporting the effectiveness and necessity of our proposed self-adaptive fusion module.
In addition to accuracy advantages, CLSANet exhibits excellent computational efficiency, requiring only 0.21M parameters and 1.19 GFLOPs—significantly less than heavier models like GANMcC (1002.56 GFLOPs) and MFMGF-Net (26.4 GFLOPs). This lightweight design substantially lowers deployment costs, making CLSANet particularly well-suited for real-time and resource-constrained application scenarios.
As shown in
Table 3, CLSANet achieves the highest
of 0.983 on the low-light LLVIP dataset, slightly surpassing MFMGF-Net (0.979), and maintains a strong
of 0.675. The consistent performance improvement over traditional fusion-based detectors such as GAFF and Fusion-Mamba highlights the effectiveness of our self-adaptive fusion mechanism, which dynamically adjusts modality contributions in response to varying illumination conditions.
On the MSRS dataset, CLSANet achieves the best performance across all methods, reaching an
of 0.943 and
of 0.896, as reported in
Table 4. These results validate its ability to maintain high detection precision across daytime and nighttime conditions, primarily due to its cognitive learning-based self-adaptive fusion mechanism, which dynamically balances the contributions of RGB and infrared inputs.
Overall, CLSANet demonstrates superior performance and computational efficiency across all three benchmarks, confirming its strong generalization, precision, and suitability for real-world multimodal detection tasks.
4.4. Qualitative Analysis
To further understand the behavior of the proposed CLSANet in complex environments, we present qualitative comparisons across four representative scenes in
Figure 4. These examples illustrate how the model adaptively integrates modality-specific cues based on scene characteristics.
In
Figure 4a, captured under low-light nighttime conditions, the baseline YOLOv7 model fails to detect the pedestrian in the center and incorrectly classifies a bus on the right, likely due to limited visibility in the RGB channel. CLSANet, by assigning higher attention to the infrared (IR) modality, is able to localize both the pedestrian and the bus more accurately, highlighting the model’s ability to respond to insufficient visible illumination by emphasizing thermographic cues.
Figure 4b depicts a scenario involving partial occlusion, where a pedestrian is obstructed by a foreground object. The IR stream alone fails to provide sufficient distinction, leading to a missed detection. In contrast, CLSANet leverages the RGB modality as the dominant source in this case, successfully identifying all pedestrians, indicating that the model can modulate modality emphasis based on contextual visibility.
Figure 4c illustrates a scene with smoke interference, which introduces noise and suppresses features in the RGB image. While the baseline method underperforms due to reduced RGB reliability, CLSANet allocates more attention to the IR channel, which is less affected by atmospheric scattering. This enables the model to maintain detection capability under degraded visible conditions.
Finally, in
Figure 4d, where strong glare leads to specular highlights and reflections in the visible image, both the RGB- and IR-only baselines incorrectly identify a non-existent motorcycle. CLSANet, through joint consideration of both modalities, is able to suppress such false positives and retain valid target detections, demonstrating its ability to reconcile conflicting modality cues.
These case studies confirm that CLSANet’s self-adaptive fusion strategy enables spatially varying modality selection and weighting, allowing the model to better preserve relevant semantic cues under varying environmental degradations.
4.5. Ablation Studies
To better understand the contribution of each component in CLSANet, we conduct comprehensive ablation experiments on the M3FD, LLVIP, and MSRS datasets. We investigate both the modular composition of the network and the effectiveness of the Dominant Modality Identification Module (DMIM) under varying scene conditions.
Component-wise ablation: We first evaluate the impact of three key modules:
(Dominant Modality Identification Module),
(Modality Enhancement Module), and
(Self-Adaptive Fusion Module).
Table 5 reports the results of models built by incrementally adding each component.
Model M1 (with only ) achieves better results than unimodal baselines but still underperforms compared to M2–M4, indicating that dominant modality selection alone is insufficient. Adding (M2) leads to consistent improvement across all datasets. Replacing it with (M3) yields further gains in , demonstrating that adaptive fusion improves stability to spatial variation. Model M4, which integrates all modules, delivers the best overall performance, validating the complementary nature of selection, enhancement, and fusion mechanisms.
Ablation under scene-specific conditions: To further evaluate the effectiveness of the Dominant Modality Identification Module (DMIM), we conduct fine-grained ablation under three typical challenging conditions from the M
3FD dataset: low light, occlusion, and strong light. We compare three strategies—fixed IR dominance, fixed RGB dominance, and adaptive selection via DMIM—as summarized in
Table 6.
In low-light scenarios, IR-Only performs better than RGB-Only (0.952 vs. 0.894 in ), confirming the utility of infrared features in visibility-limited environments. However, our adaptive DMIM strategy achieves a further improvement of +0.024 in and +0.044 in , demonstrating its ability to flexibly prioritize modality based on the scene.
Under occlusion, RGB-Only slightly outperforms IR-Only due to stronger edge preservation, yet CLSANet still yields the highest detection performance (0.933/0.637), benefiting from its dynamic modality weighting and local enhancement.
In strong-light conditions, RGB features are usually dominant, but IR remains complementary in high-reflection areas. CLSANet again surpasses both baselines, reaching 0.945 () and 0.644 (), showing resilience to brightness shifts.
Conclusions: These results confirm that DMIM’s scene-aware modality selection consistently improves detection performance across varied illumination and occlusion scenarios. It plays a crucial role in enabling CLSANet to dynamically balance visual cues for reliable perception perception in complex environments.
Module-wise ablation results and analysis. We further examine the contributions of three key components in CLSANet—DMI, the Modality Enhancement Module (ME), and Self-Adaptive Fusion (SAF)—through controlled ablation experiments under the same three scene types. For each run, one module is removed and the model is re-evaluated. The results are reported in
Table 7.
All modules positively contribute to the overall performance. Notably, removing SAF results in the most significant drop under low-light conditions (−0.045 in ), indicating its effectiveness in spatially adapting to complex brightness patterns. In occlusion scenarios, ME proves essential for preserving semantic richness.
These combined ablation experiments demonstrate that each module—DMI, ME, and SAF—plays a complementary and indispensable role in enhancing CLSANet’s performance across varied environmental conditions. Together, they support the model’s adaptability and effectiveness for real-world multimodal detection.
5. Discussion
This study introduced CLSANet, a cognitively inspired multimodal object detection framework designed to adaptively adjust fusion strategies by leveraging global scene semantics and local visual complexity. Our experimental results, obtained across diverse and challenging conditions—including low illumination, partial occlusion, and complex backgrounds—provide empirical support for the initial hypothesis that context-aware, dynamic fusion mechanisms can substantially improve detection performance in multimodal settings.
The findings presented herein are consistent with prior studies that have highlighted the limitations of static- or heuristic-based fusion approaches, particularly under variable and unpredictable environmental conditions. Previous work has demonstrated that simple fusion schemes often fail to fully exploit the complementary strengths of heterogeneous modalities. In contrast, CLSANet extends this line of research by incorporating modules that explicitly model modality contributions based on both global semantic cues and local scene complexity, enabling the framework to selectively prioritize and integrate modality-specific information according to the contextual requirements of each scene.
These contributions have broader implications for the design of multimodal perception systems in safety-critical and resource-constrained domains, such as autonomous driving, robotics, and intelligent surveillance. Specifically, the results underscore the necessity of incorporating adaptive components capable of modulating information integration in response to dynamic scene characteristics. Such mechanisms may play a crucial role in enhancing system performance and reliability in real-world deployments characterized by unpredictable and complex conditions.
Despite these advances, certain limitations warrant further investigation. CLSANet assumes precise spatial alignment between modalities and relies on large-scale annotated datasets for supervised training. These requirements may hinder its practical deployment, particularly in scenarios where sensor calibration is imperfect or annotated data is limited. Future research should examine methods that reduce sensitivity to modality misalignment, including the development of alignment correction modules or architectures that are inherently tolerant of imperfect calibration. Additionally, exploring semi-supervised and unsupervised learning paradigms may mitigate dependency on extensive human annotation and improve scalability.
In conclusion, the results presented support the efficacy of context-aware, adaptive fusion mechanisms in enhancing multimodal detection capabilities. We recommend that subsequent research explore the integration of additional sensing modalities, such as depth and radar, and investigate temporal modeling strategies to extend these insights to video-based detection tasks and continuous perception scenarios.
6. Conclusions and Future Work
In this paper, we proposed CLSANet, a cognitively inspired multimodal object detection framework that adaptively adjusts fusion strategies based on global scene semantics and local visual complexity. Extensive experimental results demonstrate that CLSANet achieves significant improvements in detection accuracy across challenging conditions such as low illumination, partial occlusion, and complex backgrounds. Moreover, CLSANet maintains a favorable balance between performance and computational efficiency, making it suitable for real-time and resource-constrained applications. These findings validate the effectiveness of context-aware, dynamic fusion mechanisms in enhancing multimodal detection performance and provide a solid foundation for developing perception systems capable of operating reliably in complex, dynamic environments.
In our future work, we plan to further enhance CLSANet by improving its ability to handle modality misalignment and incorporating additional sensing modalities, such as depth and radar, to strengthen environmental understanding under more challenging conditions. We also intend to investigate semi-supervised and unsupervised learning strategies to reduce dependence on large-scale annotated datasets and improve the model’s generalization across diverse scenarios. Additionally, we will extend CLSANet to video and continuous perception tasks by introducing temporal modeling mechanisms, aiming to improve detection stability and long-term deployment performance in dynamic environments.







{kind=link}
{kind=link}
{kind=link}
{kind=link}