1. Introduction
Medical image segmentation aims to accurately differentiate organ or lesion structures in images, providing key anatomical references for clinical diagnosis and treatment [
1]. The current clinical reliance on manual visual inspection has inherent limitations, such as low efficiency and high subjectivity, while the complexity of medical images further exacerbates the challenges of automated segmentation. For example, computed tomography (CT) [
2] is limited by noise and radiation dose, while there are sequence differences and motion artifacts in magnetic resonance imaging (MRI). Various types of modalities generally face problems [
3] such as blurred tissue boundaries, overlapping organ dynamics topology, and heterogeneous pathological structures, leading to more difficult modeling of semantic relationships between target and background, as well as between target and target.
Deep learning has revolutionized the field of image segmentation, especially through convolutional neural networks (CNNs), such as U-Net [
4] and its improved models [
5,
6,
7,
8,
9], which have achieved accurate parsing of medical images in hierarchical feature extraction through a unique encoder–decoder structure and jump-connection mechanism, and have demonstrated significant advantages in capturing complex structures. The model performance has been limited by this type of U-shaped network, as it also ignores the rich spatial position information included in the shallow network features and loses local detail information in the encoding stage. Moreover, it is difficult to model long-range contextual dependency due to the limited range of the sensory field. Unlike CNNs, the Transformer [
10] can capture global information through its self-attention mechanism and exhibits strong generalization. It has been quickly introduced into the field of medical image segmentation. Transformer-based models [
11,
12] appear to deal with targets of different sizes in multi-organ medical images by modeling global dependencies. Nevertheless, they lack detailed depictions of local features. Many studies have proposed hybrid architectures that combine Transformers with CNNs to fully utilize their advantages and encode target features through various hybrid approaches [
13,
14,
15]. However, these methods still have shortcomings in structural consistency modeling, and spatial semantic correlation mining of multi-scale features limits segmentation performance enhancement in complex medical scenarios.
Fine-grained segmentation of anatomical structures or lesion regions relies on accurate boundary segmentation, and current approaches have advanced somewhat through methods such as boundary-related prior knowledge [
16], geometric regularization [
17], and boundary point prediction [
18]. In addition, the uncertainty quantization-based approach [
19] leverages probabilistic modeling to evaluate boundary confidence, showing a unique advantage in weak contrast areas. Wang et al. [
20] proposed BA-Net to extract boundary features with multi-granularity information using the pyramid edge extraction module, allowing the network to more effectively understand and handle the target object’s edge region. FRBNet [
21] was proposed to enhance segmentation accuracy by complementarily fusing the rough prediction map and boundary features through the boundary detection and feedback refinement module. A boundary and mask guidance module and a boundary structure perception module are combined in CMR-BENet [
22] to boost network sensitivity to target boundaries and learn the connection between target boundaries and structures. To improve the accuracy of local fuzzy information evaluation, Chen et al. [
23] presented LD-UNet, which makes use of both global and local long-range sensing modules. The experimental performance in border fuzzy data is outstanding. However, there are still two major issues with the current approach, as follows: first, in severe boundary blur scenarios, it is hard to accurately capture morphological asymptotic information using the traditional boundary feature representation; second, it does not effectively use the boundary region’s inherent uncertainty features to guide the segmentation decision, which leads to limited localization accuracy of important anatomical targets.
Inspired by the considerations mentioned above, this study improves multi-organ segmentation performance on three levels, as follows: boundary structure identification, multi-scale feature fusion, and redundant interference removal. For multi-organ image segmentation, a boundary feature learning and enhancement network (BFLE-Net) is proposed. To utilize the convolutional layer and self-attention mechanism, the encoder of the established BFLE-Net serially fuses Transformer and Res2Net-50. The model also includes three essential modules for interference filtering, fuzzy boundary refinement, and target localization to effectively extract feature information from fuzzy medical images—the dynamic scale-aware context module (DSCM), the boundary learning module (BLM), and the channel and position compound attention (CPCA). To provide richer feature representations, the CPCA filters out noisy interferences and makes up for the information lost in higher-level features as a result of downsampling. To enhance the model’s capacity to discriminate between fuzzy border regions, BLM employs pixel-level confidence analysis to help the model learn the boundary details and boosts the model to focus more on uncertain boundaries. DSCM achieves collaborative optimization of multi-scale feature information by investigating the inherent connection between parallel features from different sensory fields and better leveraging the complementarities between multiple levels of features. The main contributions of this paper are as follows:
We design a novel attentional coding mechanism, CPCA, which can enhance the feature extraction ability of the coded part and filter out the interference of noise in the shallow information.
We construct a novel boundary learning module, BLM, which guides the decoder to focus on the fine-grained learning of the boundary region through the confidence and uncertainty weighting mechanism and realizes the enhancement of target subjects and boundary detail optimization. We propose a module named the dynamic scale-aware context module, DSCM. Breaking through the limitation of a fixed perceptual field, it enhances the representation of multi-scale features through adaptive fusion of multi-scale contexts.
We propose a novel hybrid model that fully utilizes the potential of CNNs and Transformers, aiming to address the challenges posed by complex backgrounds, noisy interferences, large-scale variations, and ambiguous boundaries. The effectiveness of BFLE-Net for multi-organ segmentation is demonstrated through extensive experiments on datasets and qualitative and quantitative comparisons with state-of-the-art methods.
3. Method
3.1. Overall Architecture
The framework structure of BFLE-Net is shown in
Figure 1; it is mainly composed of three parts—encoder, decoder, and hopping connection—and focuses on the design of the channel and position compound attention (CPCA), boundary learning module (BLM), and dynamic scale-aware context module (DSCM).
To take advantage of the convolutional layers and the self-attention mechanism, the encoder part serially fuses Res2Net-50 and the Transformer, and the Transformer part consists of a stack of 12 layers. Unlike TransUNet, which slices the token directly on the last convolutional feature map and feeds it to the Transformer, we designed the CPCA module before the Transformer layer in the encoder to preserve the shallow features extracted from the earlier coding layers and to filter out the interference of redundant information. Unlike simple decoding processes such as TransUNet, the decoder for this method dynamically mines the clues of fuzzy boundaries through the uncertainty-guided BLM module, and optimizes the semantic discriminative ability of fuzzy boundaries by combining the fine-grained global information fusion strategy. To achieve full-scale modeling from microscopic organizational features to macroscopic anatomical structure, the DSCM module is integrated into the jump-connected three-level feature transfer path. This allows for collaborative optimization of the dynamic calibration of multi-scale features, thereby creating a “local-global” feature optimization link. After training the optimization network to minimize the total primary and auxiliary losses, the network is optimized for convergence. The segmentation head then outputs the segmentation results.
3.2. Channel and Position Compound Attention
The CPCA module is designed before the Transformer layer of the original encoder part, which is compounded by the channel and positional attention in parallel in order to reduce the interference of redundant information in the encoding layer when extracting shallow features, and to preserve the intrinsic features of the input image. The specific structure is shown in
Figure 2.
On the one hand, the original input feature map is input into the positional attention module, and the input features are first transformed and augmented by convolution and batch normalization. The positional attention module then receives feature
as input. Three independent 1 × 1 convolution layers are used to obtain the three tensors,
,
,
. The spatial dimension
of the
and
tensors is then reshaped to
to obtain
and
. The attention weight matrix
is obtained by calculating and normalizing the dot products of
and
:
where
represents the influence of the
ith position on the
jth position, with a higher value indicating a closer association between pixels. Next, the resulting attention weight matrix
is matrix multiplied by the spread tensor
. To preserve information of the original features and prevent the attention mechanism from over-modifying the features, a learnable hyperparameter
is introduced as the weight in the matrix multiplication, and the obtained results are restored to the original spatial dimensions. Finally, they are weighted and output with the feature
after the residual linkage to obtain
, which has the following expression:
On the other hand, the feature is input to the channel attention module, and the feature is directlys used as the tensor , , , and its dimension is reshaped to . Then the dot product of the reshaped and is calculated, and the result is Softmax-normalized to obtain the attention weight matrix , where denotes the effect of the ith channel on the jth channel, and then is matrix-multiplied with the tensor to obtain multiplication, introducing the learnable hyperparameter , restoring the result to the original spatial dimensions. Finally, it is weighted with the feature through residual linkage to produce the output . Finally, the positional attention module output and the channel attention module output are summed element-by-element through the convolutional layers, and the fused features are translated to the output space through the last convolutional layer to generate the final . The designed CPCA module is able to refine the compressed high-level features to filter out noise and other redundant information interference, which helps the model to better understand the global structure in the image and generate richer feature representations.
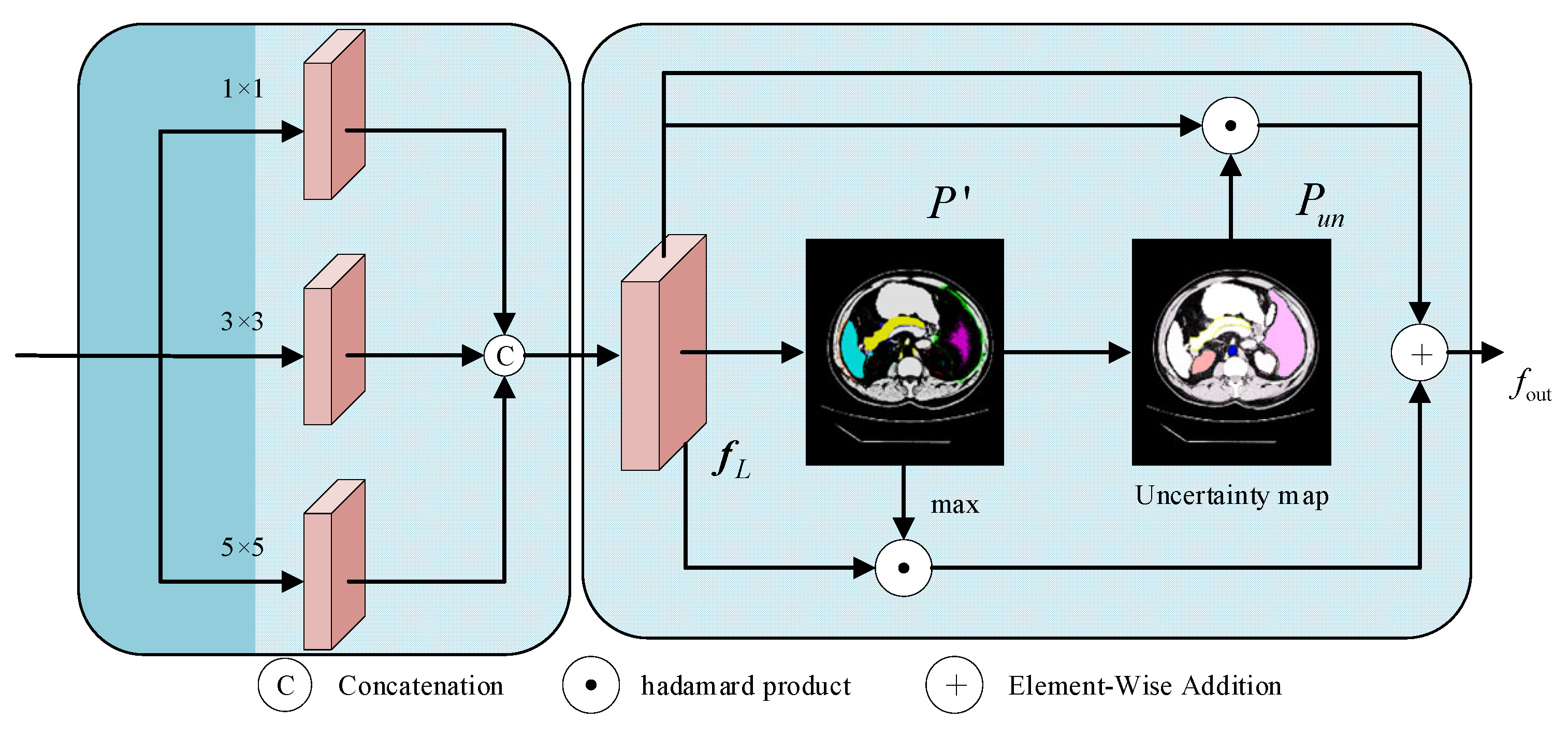
3.3. Boundary Learning Module
Fuzzy boundaries are characteristics of medical images that make it challenging for the model to accurately locate the target bounds. For the purpose of creating a pixel-level uncertainty map that guides the model to focus on the fine-grained learning of the boundary region and improves the network’s capacity to distinguish fuzzy boundaries, the boundary learning module combines data from the encoder and jump connections. During that time, to improve the model’s robustness in boundary modeling, the intermediate prediction results are limited early in the training process by the auxiliary supervision mechanism. The structure is shown in
Figure 3.
The module receives the global context features
output after 12 layers of the Transformer of the encoder and the local spatial detail features
from the shallow CNN of the encoder. The two types of features are spliced together and then passed through three parallel convolutional branches with kernels of 1 × 1, 3 × 3, and 5 × 5, which integrate the target location information in
and the spatial detail information in
, to obtain the locally augmented feature map
:
The
is then mapped to the number of categories
by convolution of the feature map, and the activation function is used to compute the category probabilities for each pixel location to obtain a multi-category preliminary prediction map
, and a confidence map
is computed for each pixel location
:
where
denotes the number of layers. The confidence map reflects the “confidence level” of the model in pixel classification, which is used to strengthen the feature representation of explicit regions; then the uncertainty map
is defined based on the normalized information entropy, and its expression is as follows:
The normalized entropy value can reflect the degree of uncertainty more intuitively—a larger value indicates that the classification of the position is more uncertain, which guides the model to pay more attention to the boundary region. Under the condition of retaining the original features, the confidence feature of the target region and the uncertainty feature of the boundary region are jointly used as the guidance information,
ensures the consistency of segmentation of the target subject, and
drives the refinement of the boundary contour; in order to avoid over-amplification of the feature response, the learnable parameter
is introduced, which is optimized by gradient descent and participates in the subsequent feature fusion process:
In the boundary learning module (BLM), the uncertainty map assumes the role of a “difficulty marker”, whose central role is to dynamically adjust the intensity of the network’s attention to different pixels. First, the network implicitly compares the consistency between the predicted probability distributions and the truth labels, which produces relatively high uncertainty values in the boundary fuzzy regions. Next, this information is used to implement a targeted weight mapping on the deep semantic feature map, specifically, pixel locations with high uncertainty are assigned greater gradient weights via the Hadamard product operation. Both strengthen the model’s semantic feature response to high-confidence regions (e.g., organ interiors) by focusing on the consistent representation of the target subject, while enhancing the model’s ability to learn the details of uncertain regions (e.g., organ boundary regions). They also optimize the prediction results of the fuzzy regions and enable focused modeling and fine-tuning of the boundary fuzzy regions.
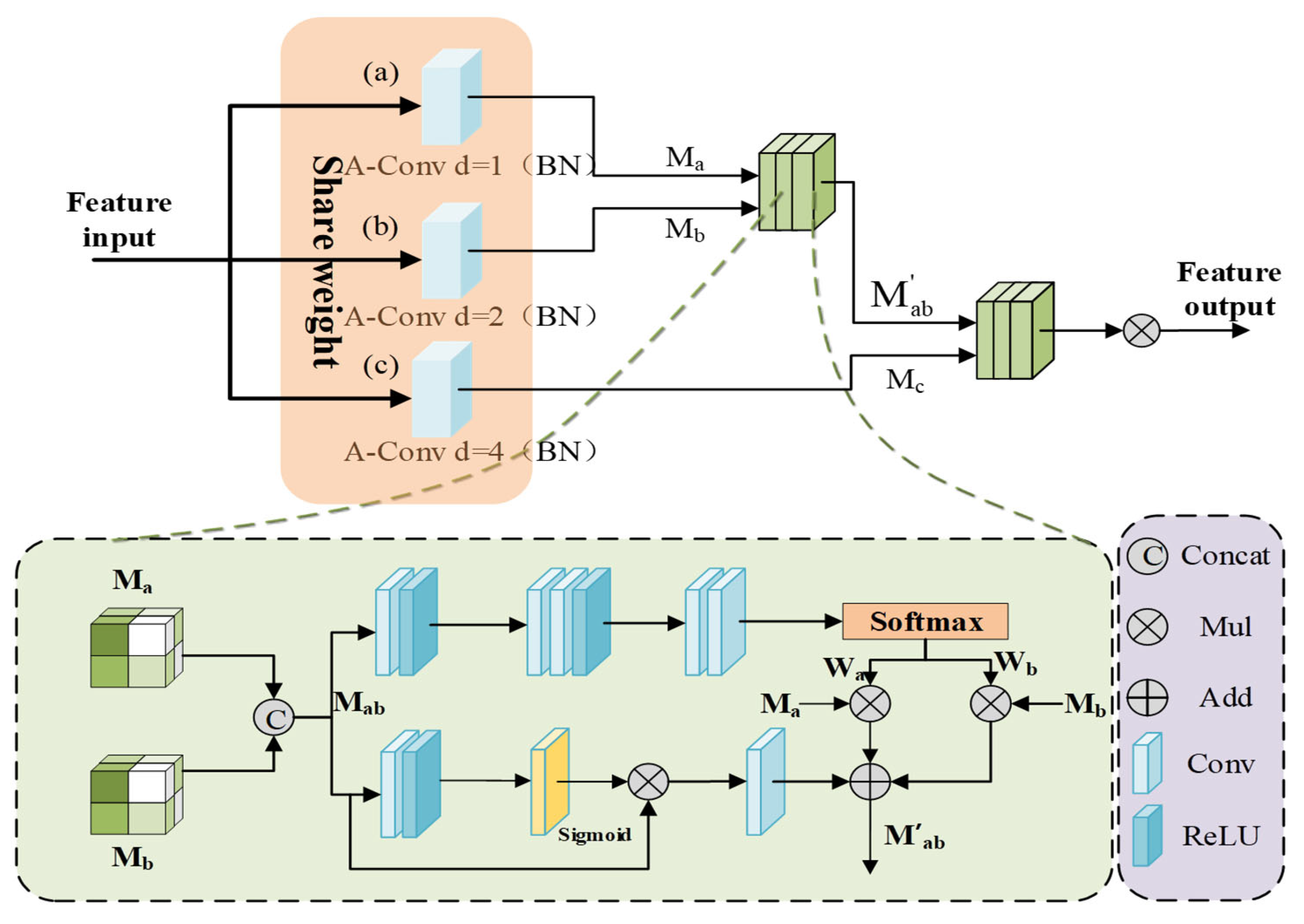
3.4. Dynamic Scale-Aware Context Module
The complexity of medical images is reflected in the large target scale differences and significant intra-class morphological differences. In this paper, we design a hierarchical embedding of the DSCM module and construct an adaptive multi-scale feature fusion mechanism to achieve dynamic calibration of local multi-scale contextual information while preserving the advantages of the Transformer’s global modeling, which significantly improves robustness in complex medical scenarios; the structure of the module is shown in
Figure 4.
First, a scale-continuous receptive field network is established through multi-scale feature sensing. In order to capture the target multi-scale features without introducing too much extra computation, the feature map
is processed in parallel by three sets of parameter-sharing dilated convolutions, which generate the multi-scale features
,
,
.
where
i,
j denote the feature maps of neighboring scales. By introducing the parameter-sharing strategy, the multi-scale generalized feature representation of network learning targets is achieved while reducing computational redundancy, and the generalization ability to unknown-scale targets can also be enhanced.
The spliced features are processed by dual paths to achieve context-aware scale selection, and in the spatial excitation path, the adjacent scale features are subjected to channel compression and spatial excitation operations to generate the spatial attention graph
, which realizes the dynamic allocation of feature weights:
where
denotes global mean pooling,
is the sigmoid function, and
is element-by-element multiplication. In the adaptive fusion path, the dynamic fusion weights
and
are learned through the gating mechanism, and the cross-scale feature representation
is obtained from the channel-by-channel spatial weight multiplication, which preserves the spatial details of the original features and dynamically focuses on the target-relevant scale information through the weights. Then the dual-path features are integrated by residual concatenation, and finally, the fused features of all scale pairs are aggregated by hierarchical contextual integration.
where
is the BN-RELU activation layer, and
,
are the spatial perception weight vectors. Different from the ASPP module with a fixed expansion rate, DSCM is able to realize the dynamic expansion of the sensory field through the parameter-sharing mechanism to capture the contextual information of different scales, solve the scale sensitivity problem caused by the traditional method due to the fixed sensory field, reduce the risk of over-segmentation, and enable the model to better utilize the complementarity between the features of different levels to generate more accurate segmentation results.
3.5. Loss Function
We optimize BFLE-Net using a composite loss function that consists of cross-entropy loss weighting and Dice loss. The total loss is a combination of the primary and auxiliary losses. The main loss is intended to reduce the discrepancy between the final segmentation maps and the ground truth. The auxiliary loss is incorporated in the preliminary prediction maps to guide the network’s attention on the target region and improve its capacity to refine boundaries. The following is the definition of the total loss:
where
and
are hyperparameters balancing the primary and auxiliary losses,
controls the cross-entropy and Dice loss weights;
and
denote the final segmentation map and Ground Truth;
and
denote the preliminary prediction map and downsampling labels.
4. Experiments and Discussion
4.1. Datasets and Evaluation Indicators
To evaluate the performance of the proposed approach, we use two publicly accessible medical image segmentation datasets—the Synapse dataset and the ACDC dataset. See
Table 1 and
Figure 5 for details.
Here are 30 abdominal CT scans in the Synapse dataset. Annotations of eight organs—liver, pancreas, spleen, stomach, right and left kidneys, aorta, and gallbladder—are included in the dataset, which consists of 3779 axial slices of abdominal CT scans. Every slice is 512 × 512 pixels in size. In this case, with reference to the TransUNet literature, the slices from 18 cases were used as the training set, and the remaining 12 cases were reserved for testing and evaluation.
Each of the 100 sets of cardiac magnetic resonance images in the ACDC dataset was annotated by a specialist with knowledge of the left atrium, right ventricle, and myocardium. In this investigation, we adhered to the data partitioning approach utilized in TransUnet, segregating the dataset into 70 cases for training, 10 for validation, and 20 for testing.
The experiments employ the Dice similarity coefficient (DSC) and 95% Hausdorff distance (HD95) as quantitative assessment metrics to fully evaluate the test results of the proposed model on the dataset.
4.2. Experimental Environment and Parameter Settings
The network employs a CNN–Transformer cascade architecture as the encoder. The CNN encoder is based on the Res2Net-50 backbone, while the Transformer component consists of a 12-layer stack. To enhance both convergence speed and segmentation performance, pre-trained weights from ImageNet-21k are utilized for both components. All experiments were conducted on a Linux (Ubuntu 20.04) operating system using a single RTX 3090 (24 GB) GPU, implemented with PyTorch 1.11.0, Python 3.8, and CUDA 11.3. The input images were resized to a consistent resolution of 224 × 224. Data augmentation techniques, including random rotation and flipping, were applied to improve the model’s generalization ability. During training, a batch size of 16 was used, with a total of 150 epochs. Model parameters were optimized using the SGD optimizer, with an initial learning rate of 0.01, momentum set to 0.9, and weight decay of 0.0001.
4.3. Results
4.3.1. Quantitative Experimental Analysis
To evaluate the accuracy of the BFLE-Net network in medical image segmentation tasks, a comprehensive comparison experiment is conducted between the proposed method and several state-of-the-art models on the Synapse multi-organ segmentation dataset and the ACDC dataset. The experimental results are presented in
Table 2 and
Table 3, where underlined values represent suboptimal results and bolded values denote the best results. As shown in
Table 2, BFLE-Net achieves optimal performance across the overall metrics, with an average DSC of 81.67%. Additionally, the average HD95 metric of BFLE-Net significantly outperforms other models, achieving a performance of 21.67 mm. For organ-specific segmentation tasks, BFLE-Net excels in the pancreas segmentation task, achieving an average DSC of 66.30%, which is 5.70 percentage points higher than the next best-performing model, TBP-Net. In the spleen segmentation task, BFLE-Net attains an average DSC of 91.36%, outperforming all other models. Similarly, for the segmentation of the left and right kidneys, BFLE-Net achieves average DSC values of 84.54% and 81.31%, respectively, maintaining high segmentation accuracy. These results comprehensively demonstrate the effectiveness of the proposed method in addressing the challenge of small target organ segmentation.
As shown in
Table 3, in the ACDC segmentation task, BFLE-Net demonstrates strong performance in maintaining a balanced segmentation accuracy across all structures, with an average DSC of 90.55%. This performance is 0.84 percentage points higher than the second-best model, TransUNet. Additionally, in the myocardial (MYO) segmentation task, BFLE-Net achieves an average DSC of 88.67%, significantly outperforming other models. These results highlight the superiority of BFLE-Net in handling thin-walled tissue segmentation tasks. Overall, the experimental findings provide strong evidence of the robustness and generalization capability of the proposed method in addressing complex medical image segmentation tasks.
4.3.2. Qualitative Experimental Analysis
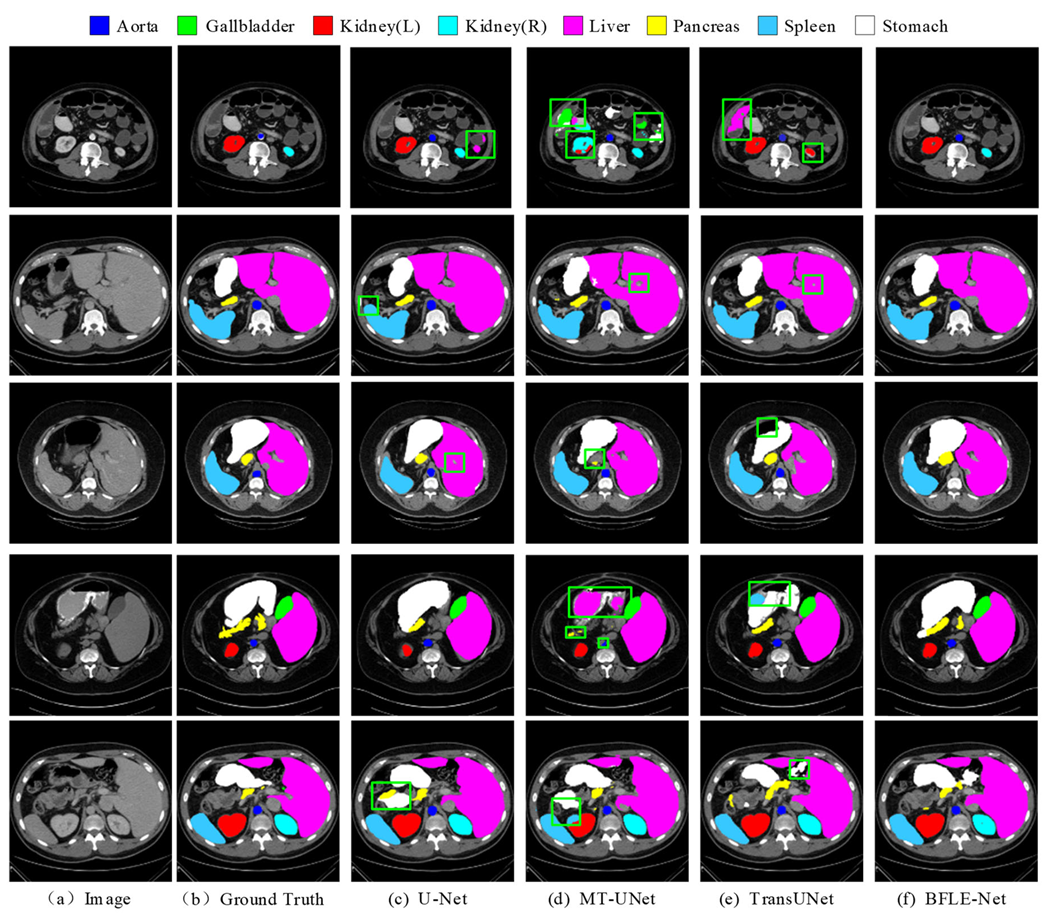
To further validate the segmentation performance of BFLE-Net, this section presents a systematic visualization and comparison experiment conducted on the Synapse and ACDC datasets. By visualizing the segmentation results, the advantages of BFLE-Net in handling complex anatomical structures are thoroughly analyzed.
In this study, the performance of various segmentation methods, including U-Net, MT-UNet, TransUNet, and BFLE-Net, is systematically compared on the Synapse and ACDC datasets. The experimental results reveal significant performance differences among the methods in segmenting complex anatomical structures. As shown in
Figure 6, in the multi-organ segmentation task on the Synapse dataset, both U-Net and MT-UNet suffer from considerable over-segmentation, particularly in the stomach region, where organ misclassification occurs. More notably, MT-UNet and TransUNet exhibit substantial topology confusion in the segmentation of the left and right kidneys, as well as inaccuracies in localizing the spatial relationship between the gallbladder and the liver. These issues highlight that current methods still face significant challenges in incorporating anatomical prior knowledge and modeling 3D spatial context dependencies for multiple organs. In contrast, the method proposed in this study substantially improves the completeness of segmentation and effectively addresses the problem of semantic confusion between organs, particularly in distinguishing neighboring organs (e.g., the liver and gallbladder) with similar grayscale features, thus demonstrating significant advantages.
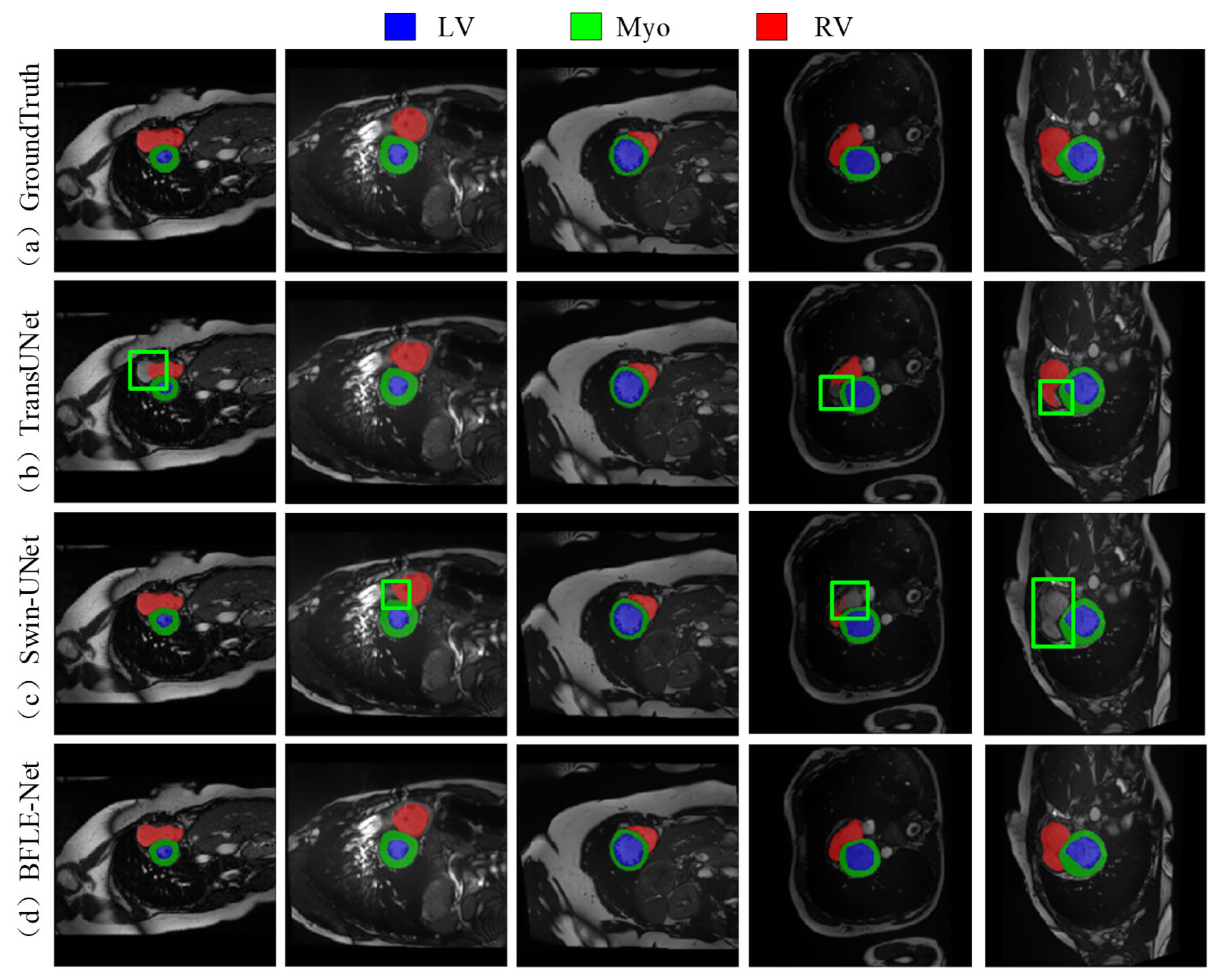
As shown in
Figure 7, the existing methods also show obvious limitations in the right ventricle segmentation task in the ACDC dataset. Both TransUNet and Swin-UNet struggle with missing the right ventricle structure. By adopting a dynamic feature calibration mechanism, the method in this study completely preserves the fine anatomical structural features of the right ventricle and significantly optimizes boundary continuity.
Through the above data comparison and visualization analysis, the experimental results show that the proposed CPCA, DSCM, and BLM modules synergistically significantly improve the model performance. The CPCA module effectively solves the redundancy problem of early feature information through shallow feature purification; the DSCM module makes multi-scale feature fusion efficient through three-level feature dynamic calibration, which significantly improves the segmentation performance of the fine structures (e.g., left kidney, right kidney, pancreas, and spleen). The boundary optimization strategy of the BLM module further enhances the boundary keeping performance of the model and enables fine segmentation of fuzzy boundary regions. Based on
Table 4, our model has 43.62 M parameters and 23.95 G FLOPs on the Synapse dataset. While its parameter count is moderate compared to other models, it stands out with a lower FLOP value, indicating better computational efficiency. Performance-wise, it achieves a Dice score of 81.67%, outperforming many models such as AttenUNet and TransUNet. This shows that our model maintains high accuracy while being computationally efficient, striking a strong balance between performance and resource usage. Overall, compared to larger models like TransUNet, our model offers advantages in both parameter count and FLOPs without sacrificing accuracy, making it highly suitable for environments with limited computing resources.
4.3.3. Ablation Experiment
To validate the effectiveness of the designed CPCA, BLM, and DSCM modules, a systematic ablation experiment was conducted. The performance contribution of each module to the overall model was quantitatively assessed by sequentially introducing each module. The detailed results of this analysis are presented in
Table 5 and
Figure 8 and
Figure 9.
The experimental results reveal that the introduction of the CPCA module alone leads to an improvement of 2.17 percentage points in the average DSC and a reduction of 10.65 mm in HD95, enhancing the segmentation performance of small organs through shallow feature purification. The BLM module alone improves the average DSC by 1.81 percentage points and reduces HD95 by 7.74 mm. Its boundary optimization strategy effectively enhances the sharpness of the segmentation boundaries. The introduction of the DSCM module alone improves the average DSC by 0.62 percentage points and reduces HD95 by 0.13 mm, with its multi-scale feature calibration mechanism enhancing the model’s adaptability to the overall anatomical structure.
In terms of combined module effects, the combination of CPCA and BLM achieves an average DSC of 81.33%, indicating that the synergy between interference filtering, feature purity enhancement, and adaptive information supplementation strengthens boundary segmentation performance. The combination of BLM and DSCM results in an average DSC of 80.42%, with HD95 reduced to 25.16 mm, significantly enhancing the model’s performance through the synergy of multi-scale features and boundary optimization. This combination improves the model’s ability to capture both local and global features, as well as its robustness in segmentation tasks.
When combining CPCA and DSCM modules, the average DSC is slightly lower than that of CPCA alone but still higher than that of DSCM alone, with a significant decrease in HD95. This suggests a trade-off when combining the modules, playing a crucial role in further optimizing boundary errors and complementing the segmentation task. The experimental results show that as the model becomes more comprehensive and complete, it can focus more on important information while suppressing the representation of irrelevant features, thereby enhancing its ability to handle complex segmentation tasks. The synergistic effect of each module has significantly improved performance, demonstrating the overall model’s boundary retention and scale adaptability while maintaining segmentation accuracy, strengthening boundary prediction capabilities, and validating the effectiveness of this method.
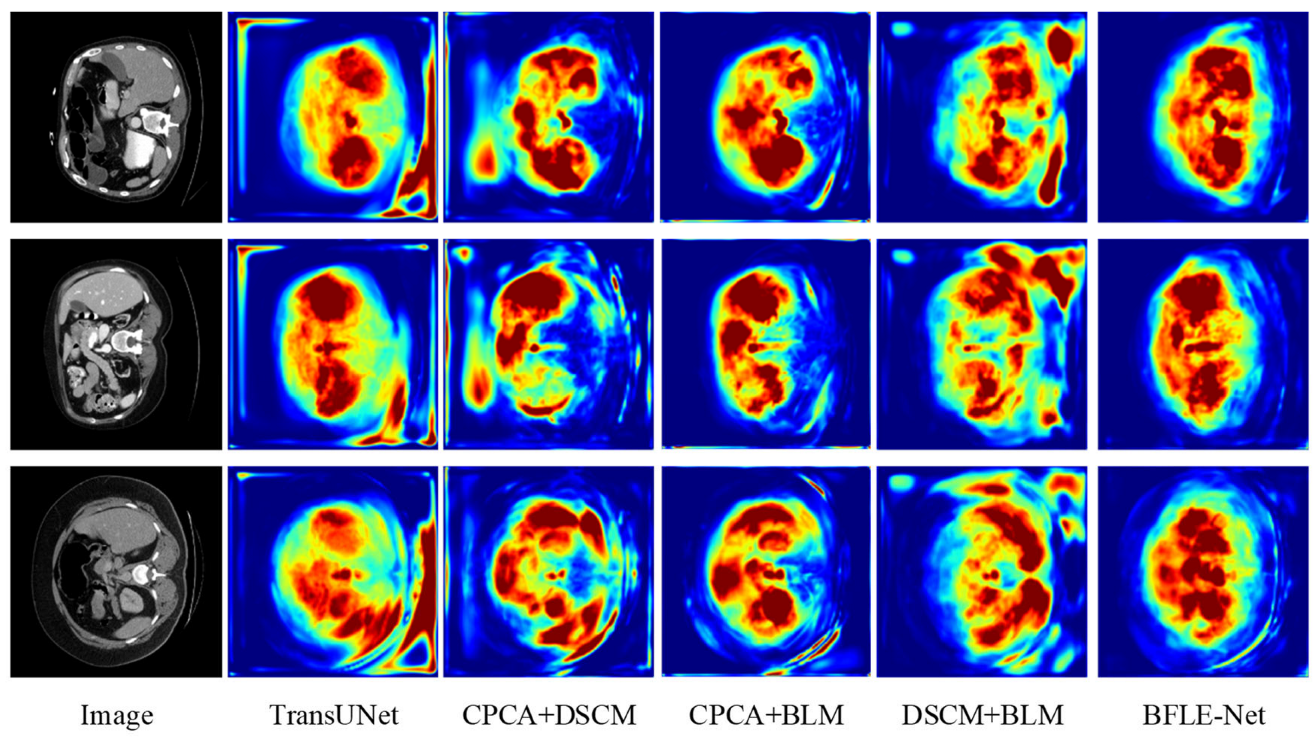
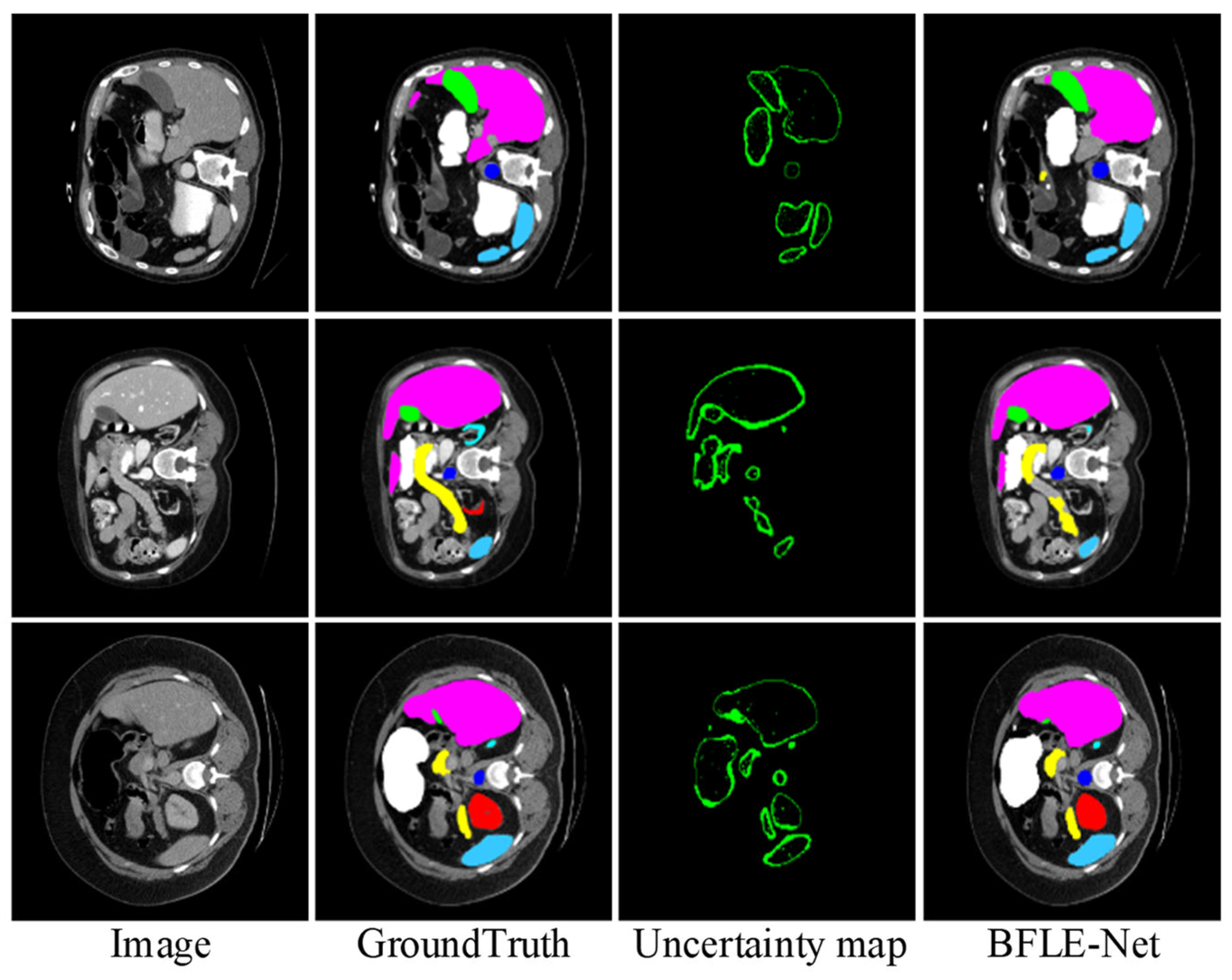
To further validate the effectiveness of the proposed BLM module, we visualize the uncertainty map in the BLM of the last layer at the decoder end, visualizing the uncertainty map side by side with the predicted segmentation mask and ground truth. As shown in
Figure 10, regions with high uncertainty values primarily appear at object boundaries or in ambiguous areas (such as weak edges or occluded structures), where pixel-level classification is inherently more challenging. These observations align with the design intent of BLM, which aims to allocate more attention to uncertain boundary regions. Based on the final results, the segmentation accuracy for the target boundary blurred areas achieved a relatively satisfactory effect.
6. Conclusions
In this paper, we propose a BFLE-Net model for medical image segmentation to enhance the model’s ability to represent fuzzy boundaries and capture detailed image information, addressing the issue of inaccurate boundary localization in target regions. The model utilizes a hybrid CNN and Transformer encoder, leveraging the strengths of both CNN and Transformer architectures. The CPCA module is designed to effectively reduce the interference of redundant information. Furthermore, confidence and uncertainty guidance methods are incorporated through the uncertainty-guided BLM module to improve the model’s ability to discriminate fuzzy boundaries and to achieve fine boundary segmentation. Additionally, the DSCM module is introduced to explore the intrinsic relationships between parallel features from different sensory fields, enabling the capture of contextual information across multiple scales.
To validate the effectiveness of the proposed approach, both quantitative and qualitative comparison experiments are conducted on publicly available datasets. The experimental results demonstrate that the proposed method performs excellently in medical image segmentation tasks, achieving advanced segmentation performance. It effectively addresses challenges related to fuzzy boundaries and multi-target semantic confusion, showcasing the model’s robustness and accuracy.
Our network shows promise for more accurate organ delineation in radiotherapy planning, surgical assessment, and disease monitoring, but it was only tested on two public datasets and may not generalize to other modalities or pathologies; moreover, its extra boundary/scale modules incur some computational cost. Future work will focus on domain adaptation, model compression, and uncertainty estimation to broaden applicability and speed up inference.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}