
Graph Convolution-Based Decoupling and Consistency-Driven Fusion for Multimodal Emotion Recognition
 , , ,
, , ,
Abstract
1. Introduction
- We introduce a novel Dynamic Weighted Graph Convolutional Network (DW-GCN) for multimodal feature decoupling, explicitly modeling dynamic and complex inter-modal relationships to extract robust common and private features.
- We propose the Cross-Attention Consistency-Gated Fusion (CACG-Fusion) module, effectively handling modality inconsistencies by adaptively integrating modality-specific and modality-invariant features through a novel gating mechanism.
- We conduct experiments on the widely used multimodal emotion recognition datasets MOSI and MOSEI. Our model achieves improvements of up to 2.5% and 1.0% in , respectively, compared to existing state-of-the-art approaches.
2. Related Works
2.1. Multimodal Emotion Recognition
2.2. Multimodal Feature Decoupling
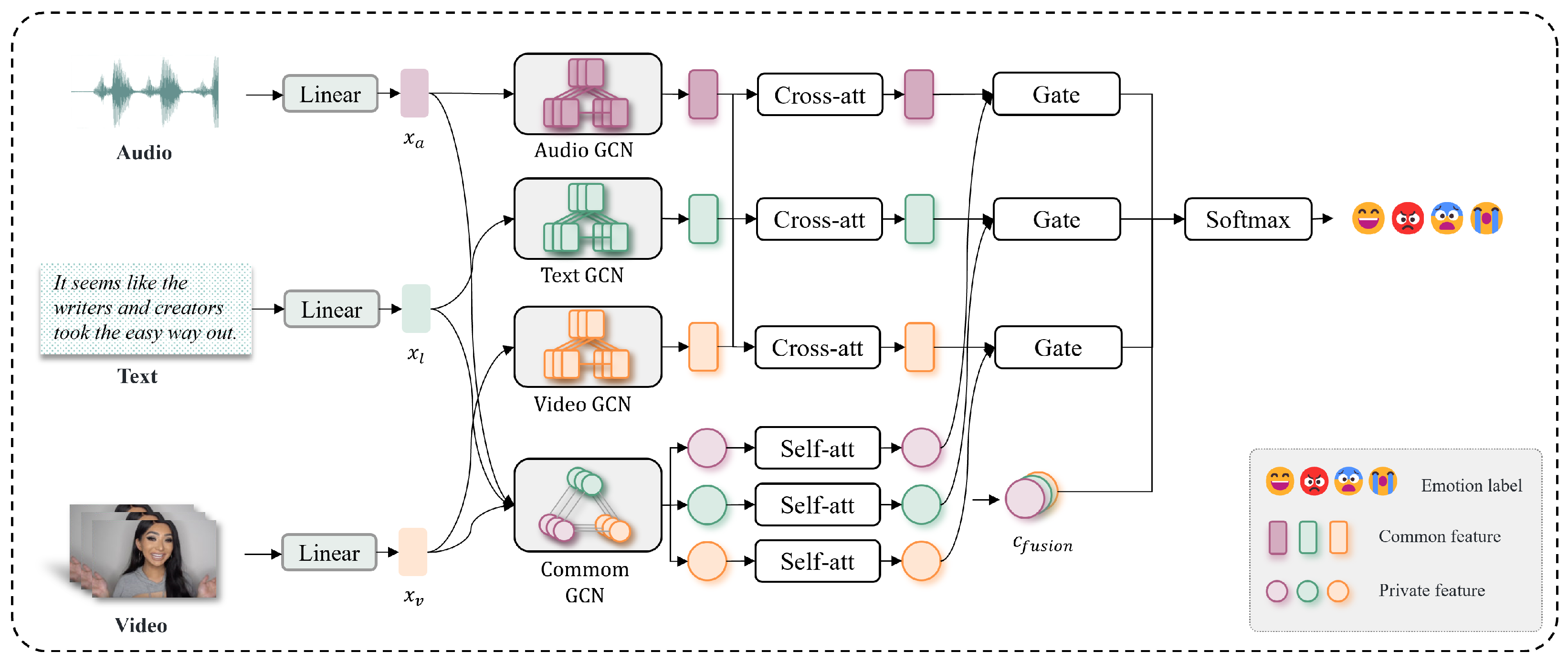
3. Methods
3.1. Multimodal Feature Extraction
3.1.1. Text Features
3.1.2. Video Features
3.1.3. Audio Features
3.1.4. Unified Feature Representation
3.2. DW-GCN for Multimodal Feature Disentanglement
3.2.1. Private Feature Extraction
3.2.2. Common Feature Extraction
3.2.3. Decoupling Losses
3.3. Cross-Attention Consistency-Gated Fusion (CACG-Fusion)
3.3.1. Self-Attention on Common Features
3.3.2. Cross-Attention on Private Features
3.3.3. Consistency-Gated Fusion
3.3.4. Classification Layer
4. Datasets and Metrics
4.1. Datasets
4.1.1. CMU-MOSI
4.1.2. CMU-MOSEI
4.2. Metrics
5. Experience and Results
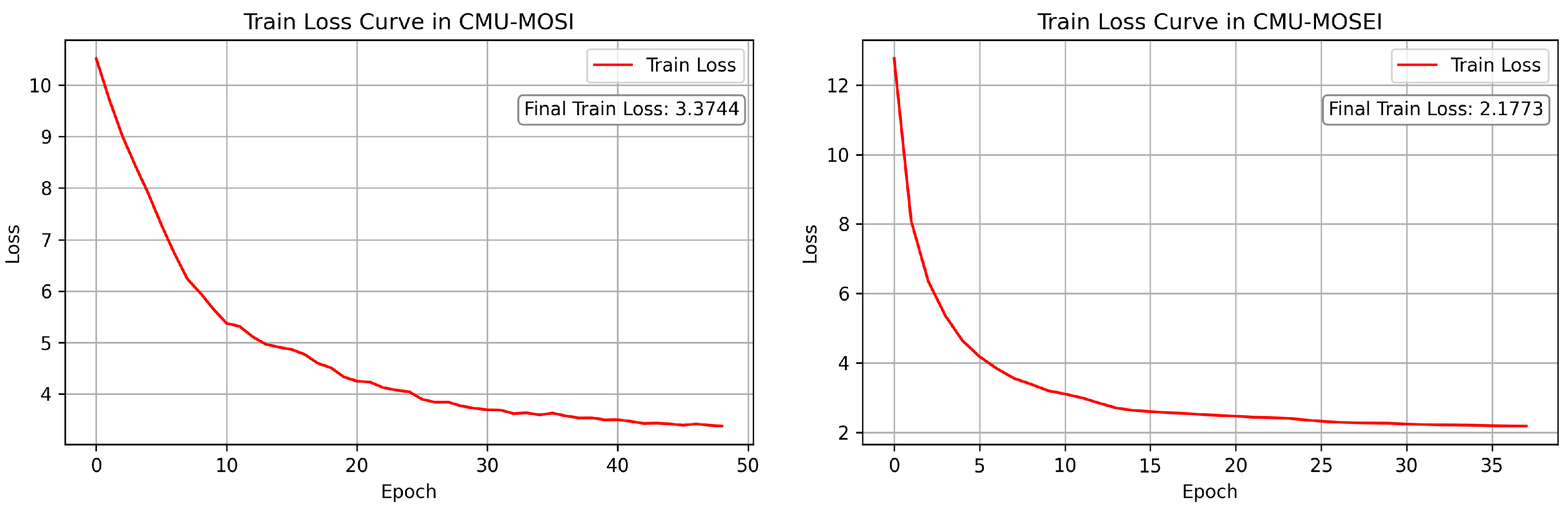
5.1. Experimental Setup
5.2. Baseline
- Multi-Attention Recurrent Network (MARN) [23]: MARN employs recurrent neural networks with multiple attention mechanisms to capture dynamic interactions between modalities over time.
- Memory Fusion Network (MFN) [24]: MFN utilizes memory attention mechanisms within LSTM structures to model intra-modal dynamics and inter-modal dependencies in sequential data.
- Context-Aware Interactive Attention (CIA) [25]: CIA integrates context-aware interactive attention by employing inter-modal reconstruction and BiGRU to fuse multimodal contextual clues effectively.
- Interaction Canonical Correlation Network (ICCN) [26]: ICCN leverages Deep Canonical Correlation Analysis to learn correlated embeddings across text, audio, and video modalities.
- Recurrent Attended Variation Embedding Network (RAVEN) [27]: RAVEN dynamically adjusts word embeddings using nonverbal behaviors, capturing fine-grained multimodal interactions.
- Progressive Modality Reinforcement (PMR) [28]: PMR progressively incorporates multimodal information through layered cross-modal interaction units, effectively capturing hierarchical multimodal interactions.
- Multimodal Transformer (MulT) [6]: MulT applies directional pairwise cross-modal attention mechanisms within the transformer framework, effectively modeling long-range dependencies without explicit alignment.
- Modality-Invariant and -Specific Representations (MISAs) [11]: MISA introduces a disentanglement framework that projects each modality into two subspaces: a modality-invariant space capturing shared semantic content and a modality-specific space retaining unique characteristics of each modality. The model incorporates distribution similarity constraints, orthogonality loss, and reconstruction loss to enhance the separation of common and private features. By explicitly modeling modality-specific variations and common semantics, MISA mitigates the effects of modality heterogeneity and supports more robust multimodal fusion.
- Feature Disentangled Multimodal Emotion Recognition (FDMER) [12]: FDMER explicitly constructs private and common encoders for each modality. A modality discriminator is employed to adversarially supervise the separation of modality-specific and modality-invariant representations. The private encoder learns distinct features, while the common encoder learns to generate representations that are indistinguishable across modalities. Additionally, FDMER introduces cross-modal attention mechanisms to integrate the disentangled features for emotion recognition, promoting both feature complementarity and independence.
- Decoupled Multimodal Distilling (DMD) [22]: DMD introduces a graph-based decoupling and distillation framework that separately encodes modality-invariant and modality-specific features. It employs two parallel graph distillation units to propagate knowledge across modalities—one for shared representations and another for private ones. These graphs are dynamically constructed based on inter-modal similarities, enabling adaptive and fine-grained feature transfer. This method enhances both the discriminative power and independence of disentangled features across modalities.
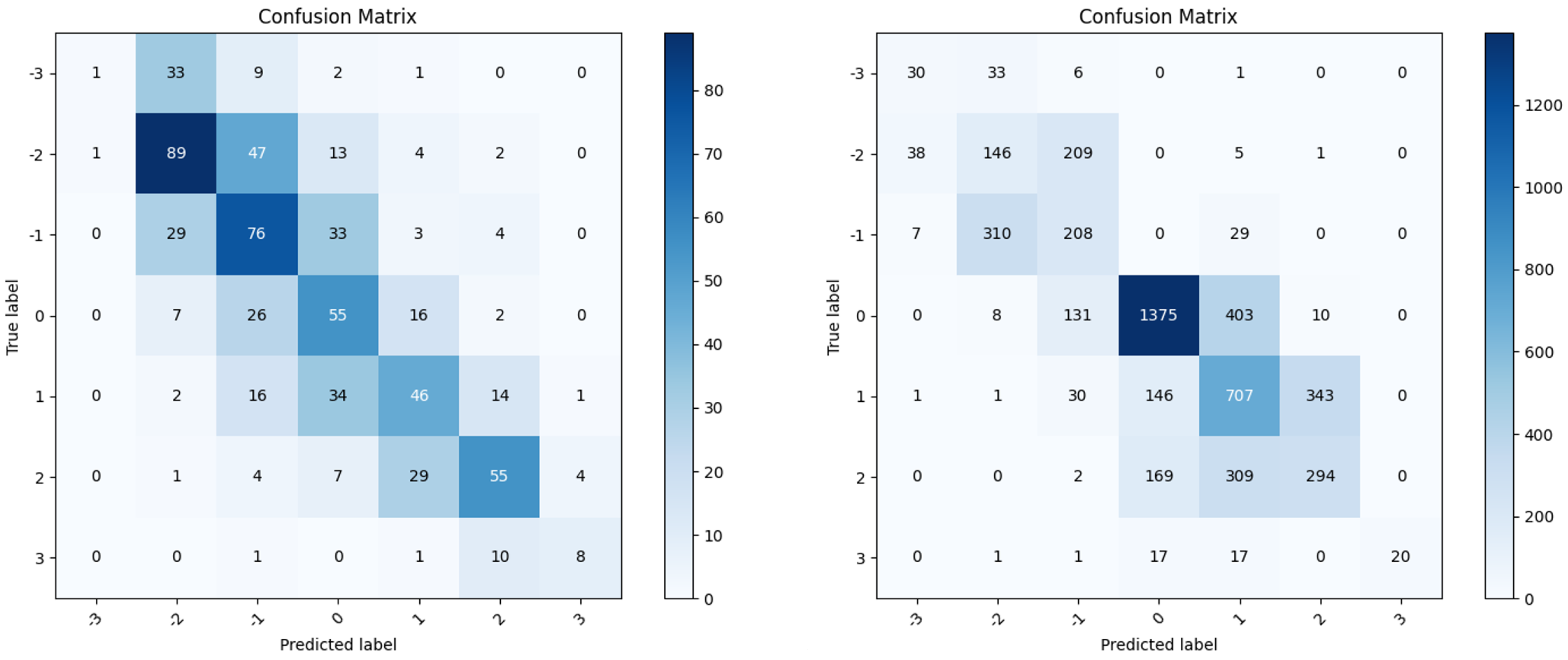
5.3. Results and Analysis
5.3.1. Overall Performance
5.3.2. Ablation Studies
- “only conv1d”: This setting aims to examine the effect of using simple convolutional feature extractors compared to graph-based modeling. By comparing it to the full model, we can evaluate the benefit of GCNs in capturing inter-modality relationships and improving feature disentanglement.
- “wo.dynamic-weight”: This ablation is designed to verify the effect of dynamic edge weighting on adaptively modeling the semantic relationships between modalities and enhancing the extraction of shared features.
- “wo.consistency-gate”: This setting is used to test whether the consistency gate mechanism improves the integration of common and private features, thereby enhancing overall model performance.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wu, J.; Zhao, T.; Zhang, Y.; Xie, L.; Yan, Y.; Yin, E. Parallel-inception CNN approach for facial sEMG based silent speech recognition. In Proceedings of the 2021 43rd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Guadalajara, Mexico, 31 October–4 November 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 554–557. [Google Scholar]
- Zadeh, A.; Chen, M.; Poria, S.; Cambria, E.; Morency, L.P. Tensor fusion network for multimodal sentiment analysis. arXiv 2017, arXiv:1707.07250. [Google Scholar]
- Liu, Z.; Shen, Y.; Lakshminarasimhan, V.B.; Liang, P.P.; Zadeh, A.; Morency, L.P. Efficient low-rank multimodal fusion with modality-specific factors. arXiv 2018, arXiv:1806.00064. [Google Scholar]
- Mai, S.; Hu, H.; Xing, S. Divide, conquer and combine: Hierarchical feature fusion network with local and global perspectives for multimodal affective computing. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 481–492. [Google Scholar]
- Chen, M.; Zhao, X. A Multi-Scale Fusion Framework for Bimodal Speech Emotion Recognition. In Proceedings of the Interspeech, Shanghai, China, 25–29 October 2020; pp. 374–378. [Google Scholar]
- Tsai, Y.H.H.; Bai, S.; Liang, P.P.; Kolter, J.Z.; Morency, L.P.; Salakhutdinov, R. Multimodal transformer for unaligned multimodal language sequences. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Volume 2019, p. 6558. [Google Scholar]
- Rahman, W.; Hasan, M.K.; Lee, S.; Zadeh, A.; Mao, C.; Morency, L.P.; Hoque, E. Integrating multimodal information in large pretrained transformers. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Seattle, WA, USA, 5–10 July 2020; Volume 2020, p. 2359. [Google Scholar]
- Poria, S.; Cambria, E.; Bajpai, R.; Hussain, A. A review of affective computing: From unimodal analysis to multimodal fusion. Inf. Fusion 2017, 37, 98–125. [Google Scholar] [CrossRef]
- Wu, W.; Zhang, C.; Woodland, P.C. Emotion recognition by fusing time synchronous and time asynchronous representations. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 6269–6273. [Google Scholar]
- Wang, Y.; Gu, Y.; Yin, Y.; Han, Y.; Zhang, H.; Wang, S.; Li, C.; Quan, D. Multimodal transformer augmented fusion for speech emotion recognition. Front. Neurorobot. 2023, 17, 1181598. [Google Scholar] [CrossRef] [PubMed]
- Hazarika, D.; Zimmermann, R.; Poria, S. Misa: Modality-invariant and-specific representations for multimodal sentiment analysis. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1122–1131. [Google Scholar]
- Yang, D.; Huang, S.; Kuang, H.; Du, Y.; Zhang, L. Disentangled representation learning for multimodal emotion recognition. In Proceedings of the 30th ACM International Conference on Multimedia, Lisbon, Portugal, 10–14 October 2022; pp. 1642–1651. [Google Scholar]
- Li, B.; Fei, H.; Liao, L.; Zhao, Y.; Teng, C.; Chua, T.S.; Ji, D.; Li, F. Revisiting disentanglement and fusion on modality and context in conversational multimodal emotion recognition. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 5923–5934. [Google Scholar]
- Shou, Y.; Meng, T.; Zhang, F.; Yin, N.; Li, K. Revisiting multi-modal emotion learning with broad state space models and probability-guidance fusion. arXiv 2024, arXiv:2404.17858. [Google Scholar]
- Fu, Y.; Huang, B.; Wen, Y.; Zhang, P. FDR-MSA: Enhancing multimodal sentiment analysis through feature disentanglement and reconstruction. Knowl.-Based Syst. 2024, 297, 111965. [Google Scholar] [CrossRef]
- Li, C.; Xie, L.; Wang, X.; Pan, H.; Wang, Z. A disentanglement mamba network with a temporally slack reconstruction mechanism for multimodal continuous emotion recognition. Multimed. Syst. 2025, 31, 169. [Google Scholar] [CrossRef]
- Han, Z.; Luo, T.; Fu, H.; Hu, Q.; Zhou, J.T.; Zhang, C. A principled framework for explainable multimodal disentanglement. Inf. Sci. 2024, 675, 120768. [Google Scholar] [CrossRef]
- Li, Z.; Yang, J.; Wang, X.; Lei, J.; Li, S.; Zhang, J. Uncertainty-aware disentangled representation learning for multimodal fake news detection. Inf. Process. Manag. 2025, 62, 104190. [Google Scholar] [CrossRef]
- Zadeh, A.; Zellers, R.; Pincus, E.; Morency, L.P. Mosi: Multimodal corpus of sentiment intensity and subjectivity analysis in online opinion videos. arXiv 2016, arXiv:1606.06259. [Google Scholar]
- Zadeh, A.B.; Liang, P.P.; Poria, S.; Cambria, E.; Morency, L.P. Multimodal language analysis in the wild: Cmu-mosei dataset and interpretable dynamic fusion graph. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; Volume 1, pp. 2236–2246. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics, Minneapolis, MN, USA, 3–5 June 2019; pp. 4171–4186. [Google Scholar]
- Li, Y.; Wang, Y.; Cui, Z. Decoupled multimodal distilling for emotion recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 6631–6640. [Google Scholar]
- Zadeh, A.; Liang, P.P.; Poria, S.; Vij, P.; Cambria, E.; Morency, L.P. Multi-attention recurrent network for human communication comprehension. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Zadeh, A.; Liang, P.P.; Mazumder, N.; Poria, S.; Cambria, E.; Morency, L.P. Memory fusion network for multi-view sequential learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Chauhan, D.S.; Akhtar, M.S.; Ekbal, A.; Bhattacharyya, P. Context-aware interactive attention for multi-modal sentiment and emotion analysis. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 5647–5657. [Google Scholar]
- Sun, Z.; Sarma, P.; Sethares, W.; Liang, Y. Learning relationships between text, audio, and video via deep canonical correlation for multimodal language analysis. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 8992–8999. [Google Scholar]
- Wang, Y.; Shen, Y.; Liu, Z.; Liang, P.P.; Zadeh, A.; Morency, L.P. Words can shift: Dynamically adjusting word representations using nonverbal behaviors. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 7216–7223. [Google Scholar]
- Lv, F.; Chen, X.; Huang, Y.; Duan, L.; Lin, G. Progressive modality reinforcement for human multimodal emotion recognition from unaligned multimodal sequences. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 2554–2562. [Google Scholar]
- Tsai, Y.H.H.; Liang, P.P.; Zadeh, A.; Morency, L.P.; Salakhutdinov, R. Learning factorized multimodal representations. arXiv 2018, arXiv:1806.06176. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
| Attribute | CMU-MOSI [19] | CMU-MOSEI [20] |
|---|---|---|
| Number of Speakers | 89 | 1000 |
| Number of Sentences | 2199 | 23,453 |
| Total Duration | 50 h | 65 h |
| Continuous Emotion Labels | [−3,3] | [−3,3] |
| Discrete Emotion Labels | - | Happiness, Sadness, Anger, Fear, Disgust, Surprise |
| Sentiment Polarity | −3 | −2 | −1 | 0 | +1 | +2 | +3 |
|---|---|---|---|---|---|---|---|
| Number of Samples | 80 | 385 | 404 | 403 | 379 | 463 | 85 |
| Emotion | Anger | Disgust | Fear | Happiness | Sadness | Surprise |
|---|---|---|---|---|---|---|
| Number of Samples | 4600 | 3755 | 1803 | 10,752 | 5601 | 2055 |
| Parameter | MOSI | MOSEI |
|---|---|---|
| 1284 | 16,326 | |
| 768 | 768 | |
| 5 | 74 | |
| 20 | 35 | |
| 0.0001 | 0.0001 | |
| 16 | 16 | |
| 5 | 5 | |
| 0.3 | 0.4 | |
| 0.5 | 0.5 | |
| 0.005 | 0.001 |
| Methods | Text Features | Audio Features | Video Features | Feature Extraction |
|---|---|---|---|---|
| MARN [23] | GloVe.840B.200d | 12 MFCCs | - | LSTM |
| MFN [24] | GloVe.840B.300d | 12 MFCCs | 35 AUs | LSTM |
| CIA [25] | - | - | - | Dense |
| ICCN [26] | BERT-Base | 74 features | 35 AUs | conv1d, LSTM, CNN |
| RAVEN [27] | GloVe.840B.300d | 74 features | 35 AUs | LSTM |
| PMR [28] | GloVe.840B.300d | 74 features | 35 AUs | Transformer |
| MulT [6] | GloVe.840B.300d | 12 MFCCs | 35 AUs | LSTM, transformer |
| MISA [11] | GloVe or Bert-base | 74 features | 35 AUs | Bert, LSTM, and transformer |
| FDMER [12] | Bert-base | 74 features | 35 AUs | Transformer |
| DMD [22] | Bert-base | 74 features | 35 AUs | conv1d |
| Methods | Common/Private Feature Extraction | Common/Private Feature Fusion |
|---|---|---|
| MISA [11] | Feed-forward neural layers | Self-attention |
| FDMER [12] | Two-layer perceptrons | Cross-attention |
| DMD [22] | conv1d | Cross-attention |
| Methods | ACC7 | ACC2 | F1 |
|---|---|---|---|
| TFN [2] | 32.1 | 73.9 | 73.4 |
| MARN [23] | 34.7 | 77.1 | 77.0 |
| MFN [24] | 34.1 | 77.4 | 77.3 |
| MFM [29] | 36.2 | 78.1 | 78.1 |
| CIA [25] | 38.9 | 79.8 | 79.1 |
| ICCN [26] | 39.0 | 83.0 | 83.0 |
| MulT [6] | 40.0 | 83.0 | 82.8 |
| MISA [11] | 42.3 | 83.4 | 83.6 |
| FDMER [12] | 44.1 | 84.6 | 84.7 |
| DMD [22] | 45.6 | 86.0 | 86.0 |
| OURS | 48.1 | 86.6 | 86.2 |
| Methods | ACC7 | ACC2 | F1 |
|---|---|---|---|
| RAVEN [27] | 50.0 | 79.1 | 79.5 |
| CIA [25] | 50.1 | 80.4 | 78.2 |
| TFN [2] | 50.2 | 82.5 | 82.1 |
| MFM [29] | 51.3 | 84.4 | 84.3 |
| ICCN [26] | 51.6 | 84.2 | 84.2 |
| MulT [6] | 51.8 | 82.5 | 82.3 |
| MISA [11] | 52.2 | 85.5 | 85.3 |
| PMR [28] | 52.5 | 83.3 | 82.6 |
| FDMER [12] | 54.1 | 86.1 | 85.8 |
| DMD [22] | 54.5 | 86.6 | 86.6 |
| OURS | 55.5 | 86.9 | 87.2 |
| Methods | ACC7 | ACC2 | F1 |
|---|---|---|---|
| only-conv1d | 45.8 | 84.6 | 84.6 |
| wo.dynamic-weight | 45.7 | 84.9 | 84.9 |
| wo.consistency-gate | 47.0 | 85.7 | 85.7 |
| ours | 48.1 | 86.6 | 86.2 |
| Methods | ACC7 | ACC2 | F1 |
|---|---|---|---|
| only-conv1d | 51.1 | 84.1 | 84.2 |
| wo.dynamic-weight | 51.2 | 84.7 | 84.5 |
| wo.consistency-gate | 52.0 | 85.1 | 85.0 |
| ours | 55.5 | 86.9 | 87.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, Y.; Li, C.; Gu, Y.; Zhang, H.; Liu, L.; Lin, H.; Wang, S.; Mo, H. Graph Convolution-Based Decoupling and Consistency-Driven Fusion for Multimodal Emotion Recognition. Electronics 2025, 14, 3047. https://doi.org/10.3390/electronics14153047
Deng Y, Li C, Gu Y, Zhang H, Liu L, Lin H, Wang S, Mo H. Graph Convolution-Based Decoupling and Consistency-Driven Fusion for Multimodal Emotion Recognition. Electronics. 2025; 14(15):3047. https://doi.org/10.3390/electronics14153047
Chicago/Turabian StyleDeng, Yingmin, Chenyu Li, Yu Gu, He Zhang, Linsong Liu, Haixiang Lin, Shuang Wang, and Hanlin Mo. 2025. "Graph Convolution-Based Decoupling and Consistency-Driven Fusion for Multimodal Emotion Recognition" Electronics 14, no. 15: 3047. https://doi.org/10.3390/electronics14153047
APA StyleDeng, Y., Li, C., Gu, Y., Zhang, H., Liu, L., Lin, H., Wang, S., & Mo, H. (2025). Graph Convolution-Based Decoupling and Consistency-Driven Fusion for Multimodal Emotion Recognition. Electronics, 14(15), 3047. https://doi.org/10.3390/electronics14153047