4.1. Experiment Setup
To construct a dataset for a keypad input recognition, we setup a CSI measurement environment as shown in
Figure 4. The experimental setup consists of a Wi-Fi transmitter, a CSI measurement device (CMD), and a commercial access point. We use an ESP8266 microcontroller as a transmitter, which has a low-power, cost-effective Wi-Fi chipset. We configure the ESP8266 in the station mode to enable connection to the AP. In our setup, the role of the transmitter is solely to generate periodic traffic for CSI measurement purposes, rather than to establish communication with its peer receiver. To achieve the goal, we take advantage of the connectionless nature of UDP, which enables a transmitter to send UDP packets irrespective of whether the destination host or the peer UDP process exists. In other words, we configure the transmitter through the UDP socket program to send packets to a non-existent IP address within the same subnet, eliminating the need to assign a destination MAC address. We configure the payload size of each UDP packet to be one byte. The communication protocols add protocol-specific headers at each layer in order to enable proper data transmission. Thus, as the UDP payload passes through the transmitter’s protocol stack, standard headers from the UDP, IP, and Wi-Fi layers are added, resulting in a complete Wi-Fi frame that is transmitted over the Wi-Fi channel. For the UDP packet transmission interval of the transmitter, we refer to commonly used values in prior studies [
35] and set it to 10 ms so that
ms. The Nexmon is installed on a Raspberry Pi 4B model to capture the CSI data whenever the transmitter sends a UDP packet. We use a ipTIME A2004SE as an access point. The role of the CMD is to measure the channel state information of Wi-Fi frames transmitted over the wireless channel. To enable this functionality, we configure the Wi-Fi interface of the CMD in the promiscuous mode and set it to monitor the same Wi-Fi channel used by both the transmitter and the AP. To measure only the channel state information of Wi-Fi frames sent by the transmitter, we also configure the CMD to collect CSI only when the source MAC address of a captured Wi-Fi frame matches that of the transmitter. All the devices follow the IEEE 802.11n standard and they operate on a channel with 20 MHz bandwidth in the 2.4 GHz frequency band where each channel has
= 52 data subcarriers. The distance between the transmitter and the CMD is configured as 50 cm, and a door-lock device with a keypad is placed at the midpoint between the transmitter and the CMD. Ten participants are recruited for the experiment. To construct a labeled dataset for sensing model training, we design a data collection process. Each participant is instructed to press a predefined keypad button
during a controlled measurement session in which the transmitter periodically emits UDP packets. During this interaction, the CMD records the corresponding CSI sequences. Each CSI segment collected under the condition of button
being pressed is labeled with the class
. This labeling procedure is applied across all the participants and all keypad buttons in the door lock, resulting in a labeled dataset wherein each CSI segment is explicitly annotated with its associated ground-truth class. Thereby, we are able to construct a labeled training dataset for supervised learning. Since each participant presses each digit in the door lock (0 to 9) for two minutes, twenty minutes of data are collected per participant, which results in a total 200 min of data. The measurement experiment has been conducted in a university seminar room. There are numerous access points in the building where the seminar room is located. Since the access points are managed by different authorities, their operating channels vary temporally. Therefore, during the measurement experiments, the surrounding Wi-Fi communication environment is not controlled. In other words, at each measurement instance, the Wi-Fi channel with the least observed congestion by the AP is selected for CSI measurement.
After constructing a raw CSI dataset, we feed it into the preprocessing module. We determine the length of the sliding window (i.e.,
) used for constructing
s by considering the impact of input image shape on the image classification performance of a deep learning model. Prior studies have reported that deep learning models tend to achieve better classification performance when the input image is square-shaped rather than rectangular [
39,
40]. The dimension of
is
. Since
ms and
, which are determined by Wi-Fi standards, we set
ms so that
s forms a square shape of size
. After coloring
s at the end of the preprocessing module, we obtain the set of data for the keypad input recognition model
, where
T denotes the time when the first channel state information of the last CSI image is measured. We split
into the training, validation, and test sets with a ratio of 8:1:1.
In this study, we configure the parameters of the proposed keypad input recognition model with reference to existing research findings. Specifically, guided by [
7], we design the feature extractor as follows. We set four convolution blocks for the feature extractor, each with a fixed stride of
. For each block
i, the number of output channels (i.e.,
) is set to
, and
, respectively. According to [
16], our KAN-based classifier uses B-splines, with a grid size of
and spline order of
. When we train the model, we set the size of mini-batch to 256 and the maximum number of epochs to 300. The training process may stop before the maximum number of epochs if the validation loss does not decrease for 30 consecutive epochs. In the case where the saliency map-based regularization is used, we configure
to search for each
. The learning rate is set to 0.001 whenever training a model.
4.2. Sensing Performance of CNN-KAN Without Loss Regularization
To verify the proposed keypad input sensing model, we compare the performance of our model to that of the CNN model, which is widely applied in Wi-Fi sensing scenarios [
7]. The CNN model consists of a feature extractor based on convolutional blocks and an MLP-based classifier. Both our keypad input recognition model and the CNN model extract features from the
s by using the convolutional blocks. Therefore, to focus on the influence of the KAN-based classifier, we configure the feature extractor of the CNN model identically to that in our model. Henceforth, we denote our keypad sensing model without loss regularization as
and the CNN model trained by the cross-entropy loss as
.
In
Table 3, we compare the sensing accuracy between
and
for varying
. We observe that the accuracy increases as
increases because the amount of CSI data increases with
. More importantly, we can see in this table that
achieves higher accuracy than
for all
. We note that under the data-scarce setting of
,
achieves an accuracy of
. In contrast,
attains an accuracy of
, yielding an accuracy improvement of
. To gain an intuitive understanding of these performance differences, in
Figure 5, we illustrate two-dimensional t-SNE plots for the logit vectors corresponding to each class when
. A logit vector for
is denoted as
, where
represents the logit value which indicates the confidence level of a classifier that
corresponds to a class
i. As shown in the figure, the MLP-based classifier in
exhibits ambiguous class boundaries, with substantial overlap between the features of different classes. In contrast, the KAN-based classifier in
shows clearer decision boundaries between classes than the MLP-based classifier. These results indicate that when processing distinct
s from the same class, our KAN-based classifier produces logit vectors that exhibit greater similarity than those generated by an MLP-based classifier. Accordingly, our KAN-based classifier increases the keypad input recognition accuracy by enhancing the inter-class separability compared to the MLP-based classifier in
. Since the t-SNE plot is generated by embedding high-dimensional logit vectors into two-dimensional space, there is information loss. Thus, to further inspect the difference in this visual representation, we introduce a metric called a confidence ratio (
). The confidence ratio is devised to quantify how strongly a classifier supports the correct class
c relative to its most confusing alternative. Formally,
is defined as the ratio between the probability assigned to the correct class
c by a classifier (denoted as
) and the highest probability determined by the classifier among all incorrect classes, which is expressed as
. In other words,
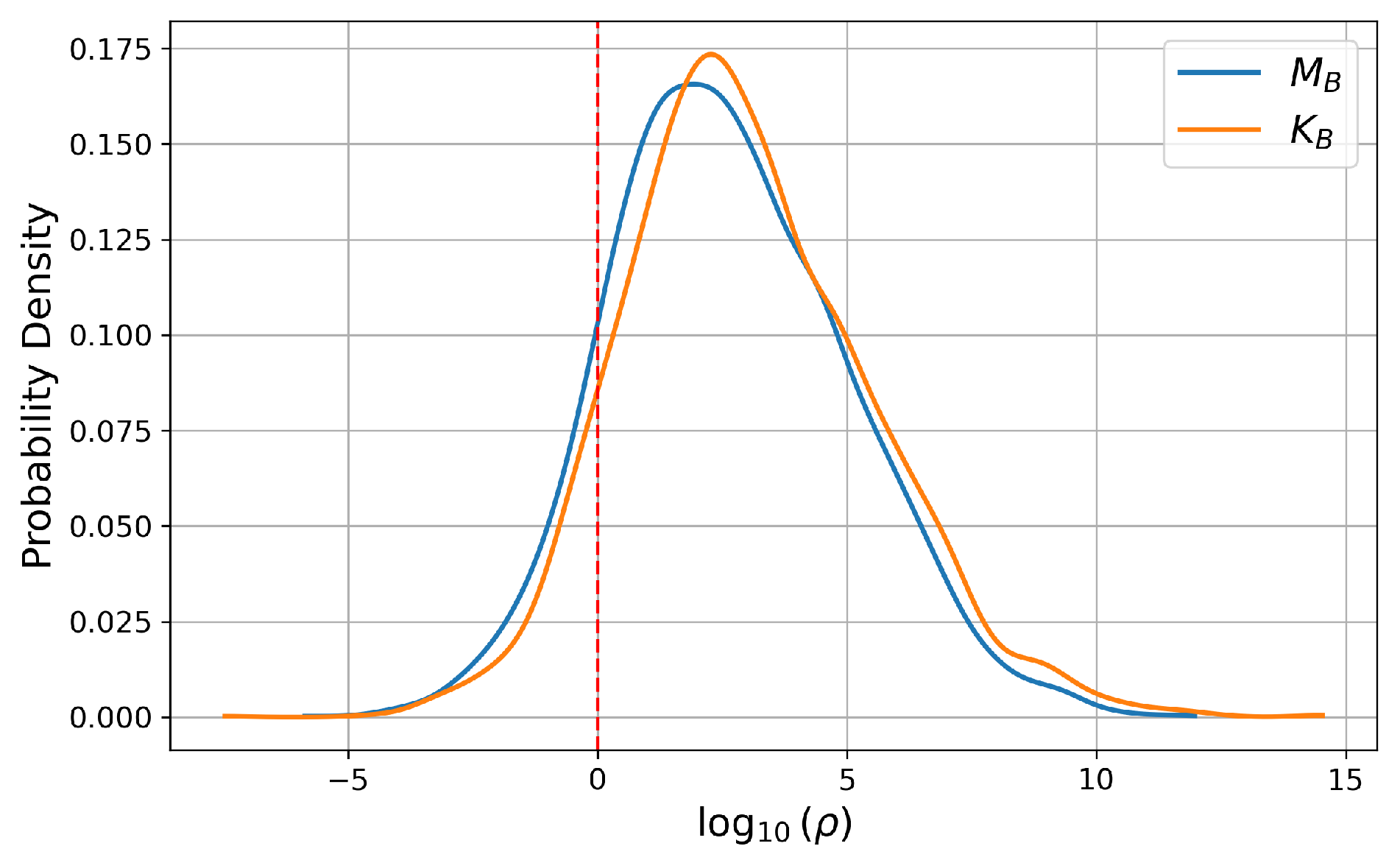
Figure 6 shows the probability density function of
for all classes estimated by using the data in our CSI dataset. As observed in the figure, the distribution is clearly more shifted to the right when our KAN-based classifier is applied than when the MLP-based classifier is used. In particular, compared to the MLP-based classifier, the KAN-based classifier reduces the region where
, which corresponds to the cases where the model assigns a higher probability to an incorrect class than to the correct one. These results indicate that our KAN-based classifier increases the correct keypad input recognition rate.
Table 3.
Sensing accuracy comparison between and for varying .
Table 3.
Sensing accuracy comparison between and for varying .
| Model | | | | |
|---|
| 74.49% | 80.73% | 87.68% | 96.92% |
| 77.85% | 81.11% | 90.07% | 98.01% |
Figure 5.
t-SNE plots for logit vectors produced by and when .
Figure 5.
t-SNE plots for logit vectors produced by and when .
Figure 6.
Probability distribution function of .
Figure 6.
Probability distribution function of .
To further compare the performance between
and
, in
Table 4, we compare the precision, recall, F1 score, and the number of parameters used to achieve these performance metrics when
. From this table, we can observe that our
consistently outperforms the
across all metrics. In terms of the sensing accuracy,
achieves
, while
achieves an accuracy of
, representing a 2.39 percentage point improvement. Furthermore, our
achieves the precision, recall, and F1 score values of
,
, and
, respectively, which are higher than those of
(
,
, and
, respectively). These results show that since the KAN-based classifier in our keypad input recognition model uses flexible edge-wise functions, it provides superior discriminative power compared to the classifier in
that uses a fixed node-wise activation. In addition to the performance improvement,
is also highly efficient in terms of the number of parameters used. The number of trainable parameters used to achieve the performance metrics in
Table 4 is 150,282 when
is used, while it is reduced only to 57,600 when
is applied. In other words, we accomplish approximately
reduction in the number of trainable parameters.
These results verify that, in contrast to , which learns linear relationships with fixed nonlinear activation functions, applying our , which learns nonlinear functions to delineate decision boundaries, can enhance the performance of the keypad input sensing and reduce the number of model parameters.
4.3. Impact of Loss Regularization
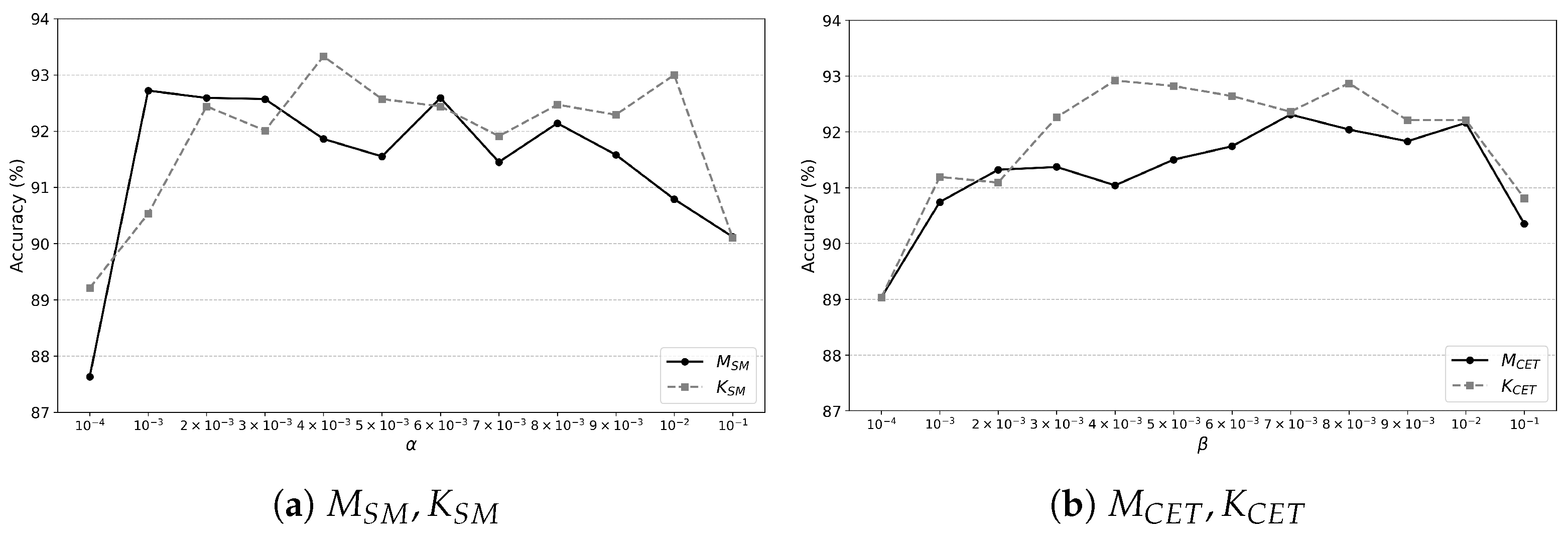
To investigate the impact of the training loss regularization, we apply and not only to but also to . Hereafter, we denote trained with as , while trained with is denoted as . We also refer to trained with as , while with is denoted as .
Since the weight
in
and
in
affect the sensing accuracy of a model, we investigate the accuracy sensitivity of a model with respect to these parameters. We vary
and
from
to
and measure the sensing accuracy of each model. Then, we present the results in
Figure 7. As illustrated in the figure, when the parameter values are too small or too large, the accuracy of the models decreases substantially. These results are attributed to the influence of these parameters on the total loss. As these parameters approach zero, the effect of loss regularization diminishes. This is equivalent to training each model solely with the cross-entropy loss, which leads to accuracy comparable to that of
or
. In contrast, as the value of these parameters increases, the influence of the regularization term in
and
becomes more significant. Consequently, the model prioritizes minimizing the intra-class distance of feature vectors over classification (i.e., sensing) accuracy, which decreases the sensing performance. In
Figure 7, we also observe that when the parameter values are neither too small nor too large, they do not significantly affect the accuracy of the sensing models. Based on these results, when the saliency map-based regularization is used, we set
, while we configure
when the center loss-based regularization is used.
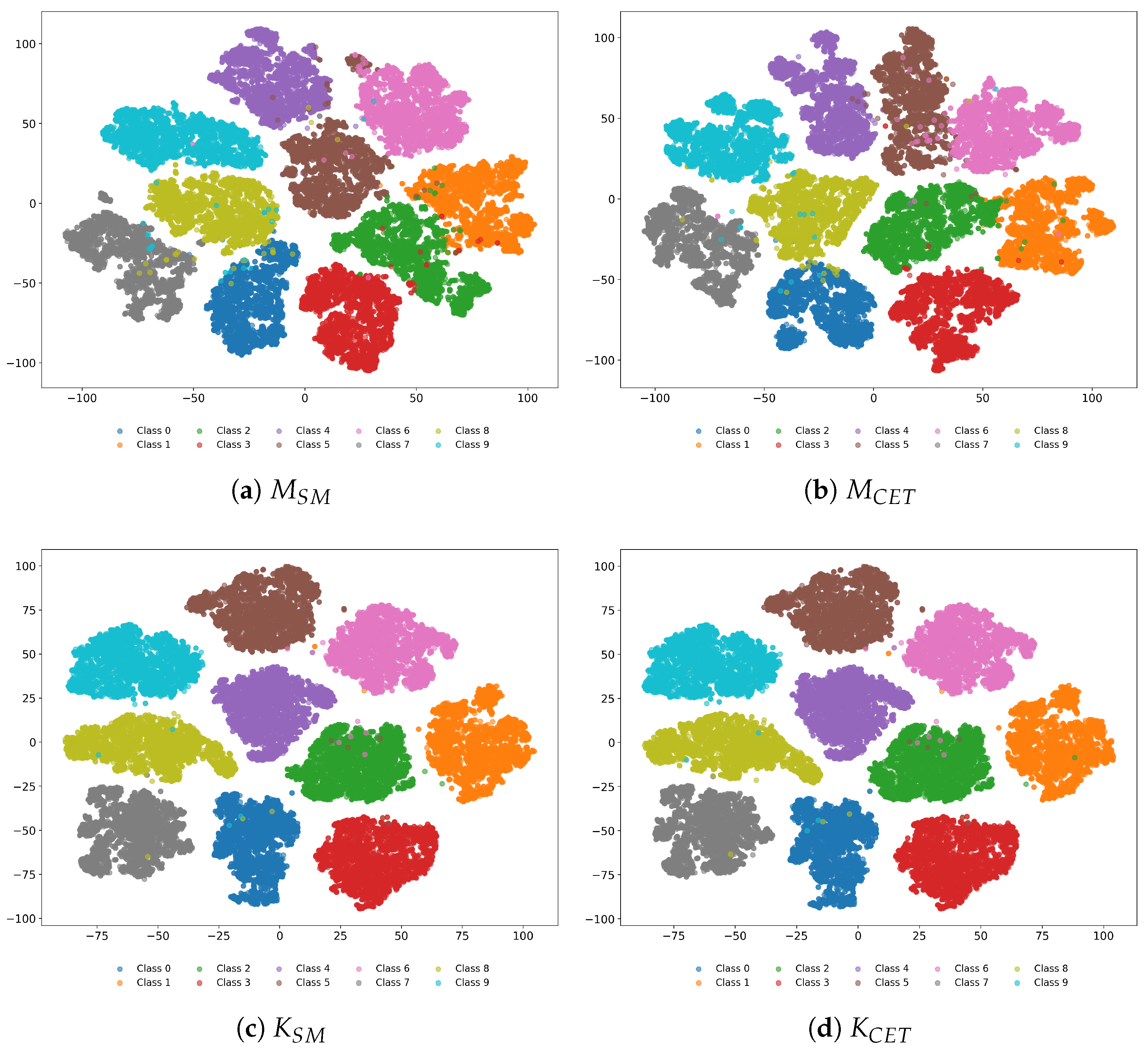
In
Figure 8, we illustrate the t-SNE plots for the logit vectors extracted from each model when
. Compared to the results in
Figure 5, we can see that logit vectors belonging to the same keypad input class are more tightly clustered when the loss regularization is applied than when only the cross-entropy loss is used. These structural differences are closely linked to the improvements in the keypad input recognition accuracy. As shown in the confusion matrices of
Figure 9, the models trained with the loss regularization exhibit higher accuracy compared to those without the loss regularization.
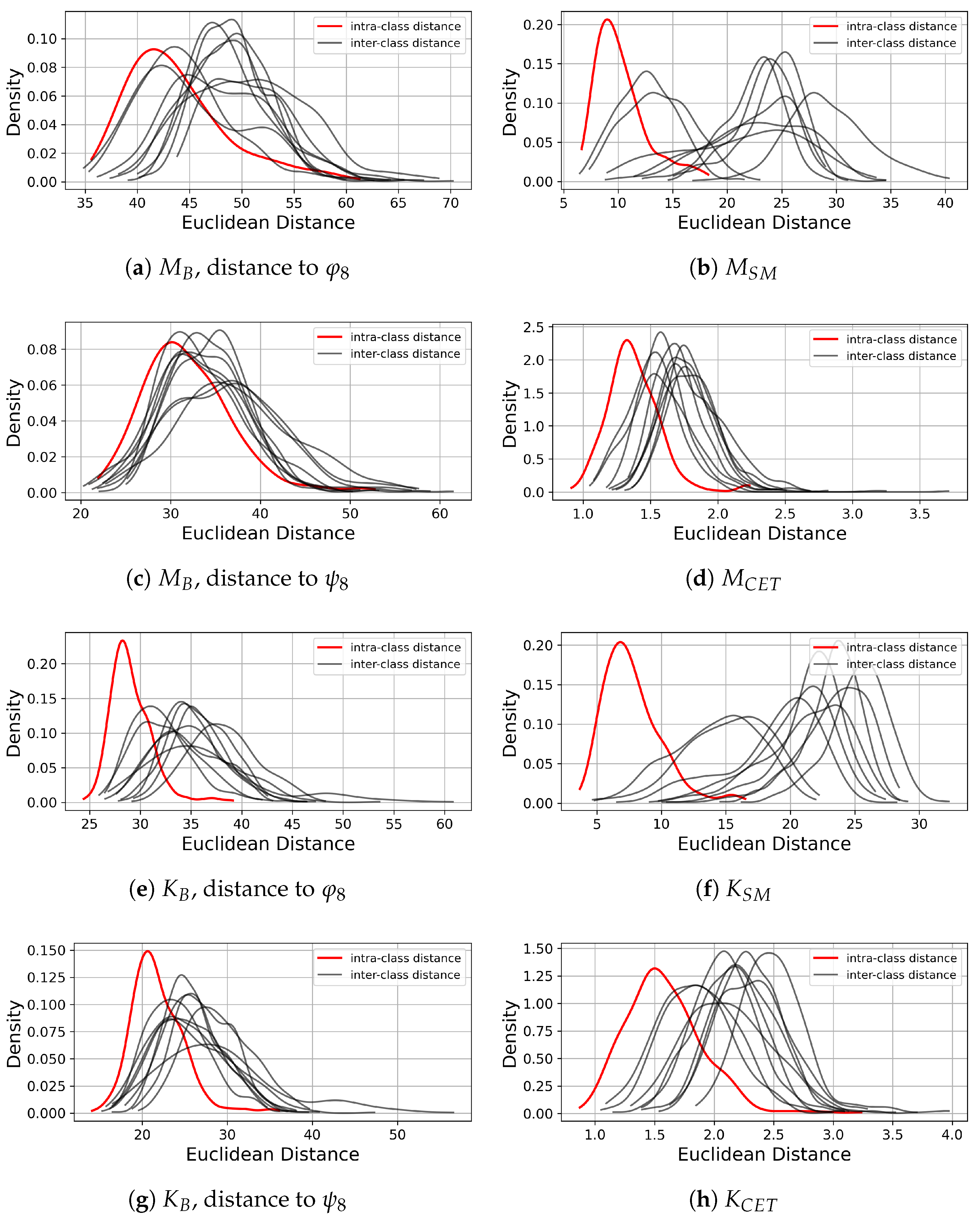
To further analyze the way that the loss regularization affects the class feature structure, in
Figure 10, we compare the intra-class distance distribution and the inter-class distance distribution between the feature vectors extracted by a model and the reference point of the class 8 (i.e.,
or
, depending on the regularization method used). If we denote the set of feature vectors belonging to class
i as
, the intra-class distance represents the Euclidean distance between a feature vector in
and the reference point of the class 8. The inter-class distance denotes the Euclidean distance between a feature vector belonging to a keypad input class
and the reference point of the class 8. Accordingly, the intra-class distance and the inter-class distance serve as a measure that quantifies the proximity of a feature vector to the reference point. In the case of
and
, to enable comparison with their respective counterparts trained with loss regularization, they are trained using only the cross-entropy loss. Then, the set of feature vectors of the test data are extracted by the trained models. After calculating the reference point of the class 8 among the extracted feature vectors, we compute the distances between the feature vectors of the test data and the reference point of the class 8. In
Figure 10, we can observe that when the loss regularization is applied, the distribution of intra-class distances is more concentrated toward smaller values compared to the case without the loss regularization. We can also observe that the use of the loss regularization leads to a rightward shift in the distribution of inter-class distances. These results show that the loss regularization encourages each
to be located close to the corresponding reference point of their class. Correspondingly, the loss regularization increases the intra-class compactness and the structural consistency of the feature space, which contributes to clear separation among classes.
In
Table 5, we compare the sensing accuracy of each model for varying
. The performance of all the models increases as the amount of CSI data increases. We observe that the loss regularization increases the sensing accuracy regardless of the type of sensing model for all
. We can also see that the proposed method achieves higher accuracy compared to the CNN models for all
and the types of loss regularization. When we compare the saliency map-based regularization and the center loss-based regularization, the former shows higher keypad input recognition accuracy. This is attributed to the way that the reference point is determined. As we can see in Equation (
11),
is determined by maximizing the logit value for its corresponding target class while minimizing the average logit value for all non-target classes. In contrast,
is selected based on the Euclidean distance between CSI feature vectors. Consequently, encouraging features of the same class to cluster around
, rather than
, leads to a higher probability of correct classification. However, as we can see in
Table 5, the accuracy difference between the saliency map-based regularization and the center loss-based regularization is not so significant. Thus, the center loss-based regularization is more practical than the saliency map-based regularization in that it can reduce the model training time by half.
Finally, to evaluate the practical applicability of the proposed method in a real computing environment, we evaluate its operational performance on a PC server, which is a common place where the proposed method operates. The server is equipped with an NVIDIA GeForce RTX 4070 SUPER with 12GB RAM, an Intel Core i5-14600KF CPU at 3.50GHz, and 32GB of system RAM. The proposed method is executed using CUDA version 12.7, Python version 3.12.7, and PyTorch version 2.5.1. We separately measure the performance of the CSI preprocessing module and the inference performance of the keypad input recognition module. When we measure the energy consumption, we use CodeCarbon [
41]. We present the measurement results in
Table 6, where we observe that the energy consumed during the preprocessing and inference is very low. We can also observe that the proposed method requires more time for CSI preprocessing than for keypad input inference, which limits the sensing throughput of 200.40 times per second. This is attributed to the fact that the CSI preprocessing is primarily handled by the CPU, while the inference is performed by the GPU. However, the total latency remains at 6.86 ms, which is shorter than the CSI measurement interval of 10 ms. In general, the CMD and the PC server are connected via a high-speed network and modern wired and wireless LANs typically support transmission speeds of over 100 Mbps.
is comprised of an in-phase component and a quadrature component. If we assume that each component is represented by four bytes, the size of a CSI data measured by a CMD becomes
bytes. Since
, the time required to transmit a CSI data from the CMD to the server is 33.28
s, which is negligibly small compared to the 6.86 ms of the total latency. Therefore, we believe that the proposed method is capable of producing sensing results every 10 ms and can be considered suitable for real-time applications.
4.4. Performance Comparison with Other Baselines and in Other Environment
To further evaluate the effectiveness of the proposed method, we compare its performance with those of two other baseline sensing models. The first baseline model is a 1D CNN model in [
26] and the second baseline model is based on a ViT (Vision Transformer) [
28]. We preserve the original architectures of these models and adjust only their input data formats to accommodate the measured CSI data. In
Table 7 and
Table 8, we show the results when
is 0 and 0.5, respectively. We observe in these tables that the performance of sensing models increases with the amount of training data. In addition, as evidenced by the results in these tables, the proposed approach which combines the KAN-based classifier with the loss regularization demonstrates superior performance compared to the baseline models in terms of the accuracy, precision, recall, and F1 score. We also note that even if the ViT demonstrates strong performance in classifying natural images recognizable by humans, it exhibits limited performance when applied to image representations of CSI data, which is consistent with the results reported in [
7].
We also evaluate the performance of our method in a different environment. Specifically, we change the measurement location from a seminar room to the lobby on the first floor of the building. In addition, unlike the previous setting where the keypad is attached to a plastic surface, the keypad is attached to a marble surface in the new environment. The relative positioning among the transmitter, CMD, and keypad is kept consistent with the setup used in the seminar room. To ensure that the CMD can measure CSI every 10 ms, the UDP packet transmission interval of the transmitter is set to 10 ms. Under this configuration, three users each press each keypad button for 4 min, yielding a total of 120 min of collected data. We show the experimental results with this lobby dataset in
Table 9. As observed in the table, the ViT achieves the lowest performance, whereas the 1D CNN and
demonstrate similar levels of performance. The proposed method consistently outperforms the other methods across all the evaluation metrics. In addition, consistent with the results in the seminar room environment, the loss regularization improves the performance of
in the lobby environment by encouraging more compact class feature representations.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}