
Zero-Shot 3D Reconstruction of Industrial Assets: A Completion-to-Reconstruction Framework Trained on Synthetic Data



Abstract
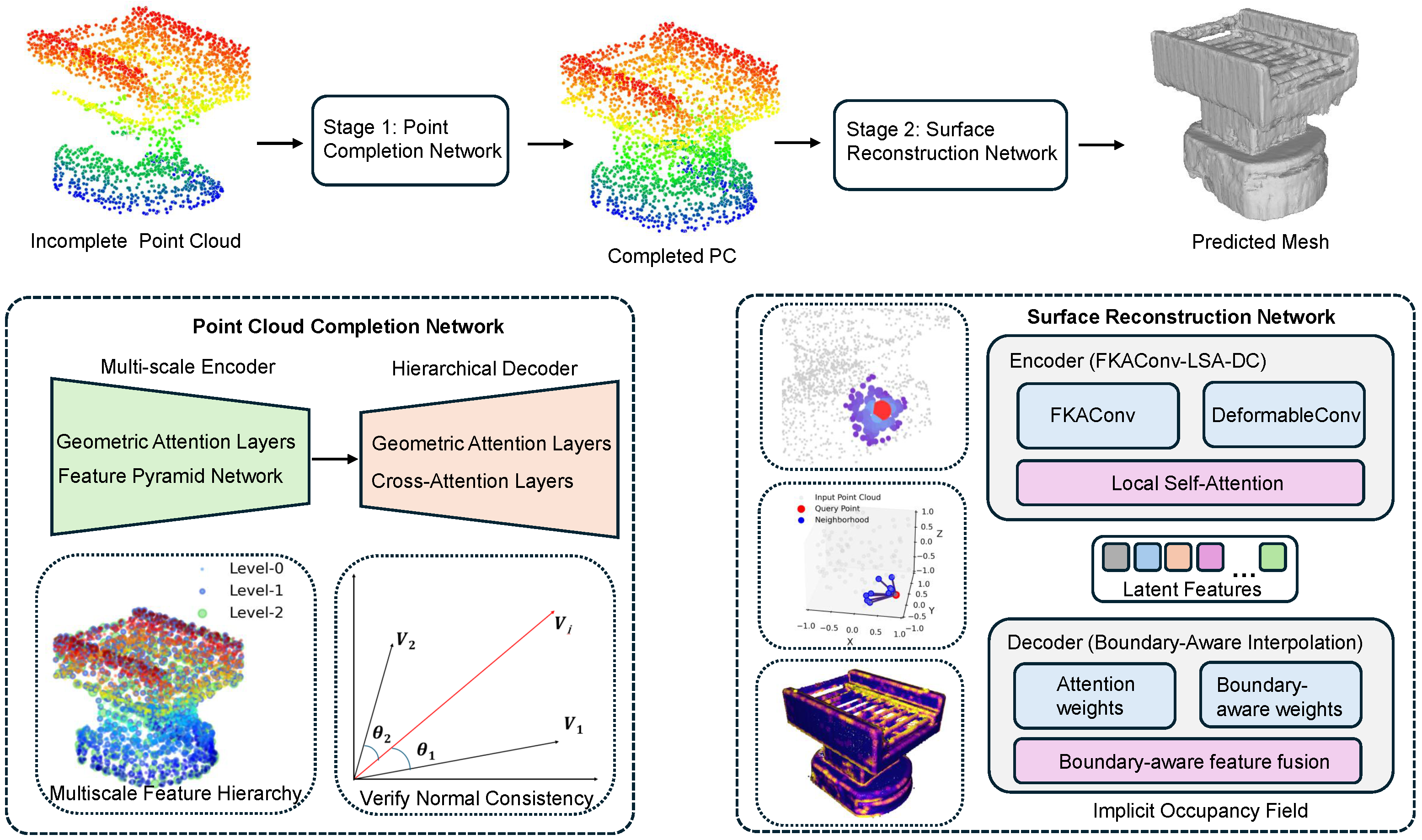
1. Introduction
- An enhanced encoder architecture, FKAConv-LSA-DC, that dynamically fuses fixed-kernel and deformable convolutions with a local self-attention mechanism. This hybrid design robustly captures both global structural context and fine-grained, adaptive local features, demonstrating superior performance on irregular and topologically complex shapes.
- A boundary-aware multi-head interpolation decoder that explicitly modulates attention weights based on proximity to geometric boundaries. This mechanism significantly enhances reconstruction fidelity for sharp edges, thin structures, and other challenging surface features where conventional methods typically fail.
- A comprehensive validation that demonstrates the framework’s strong zero-shot, cross-domain performance. Our model, trained solely on the ShapeNet synthetic benchmark, successfully reconstructs complex, unseen industrial assets from real-world scans without any fine-tuning, outperforming leading approaches and confirming its practical deployability.
2. Related Work
2.1. Self-Supervised Point Cloud Completion Methods
2.2. Surface Reconstruction
2.2.1. Surface-Based Interpolation Methods
2.2.2. Surface-Based Approximation Methods
2.2.3. Volume-Based Interpolation Methods
2.2.4. Volume-Based Approximation Methods
2.3. Research Gaps
3. Methods
3.1. Point Completion via FMPNet
3.2. Adaptive Point-to-Mesh Reconstruction Method
3.2.1. Local Self-Attention Encoder with Adaptive Deformable Convolution (FKAConv-LSA-DC)
3.2.2. Boundary-Aware Multi-Head Interpolation Decoder
4. Experiments
4.1. Datasets and Preprocessing
4.1.1. ShapeNet Benchmark Dataset
4.1.2. Industrial Workshop Dataset
4.2. Data Normalization and Augmentation
4.3. Stage 1: Point Cloud Completion via FMPNet
4.4. Stage 2: 3D Surface Reconstruction
4.4.1. Quantitative Evaluation
4.4.2. Qualitative Evaluation on ShapeNet
4.4.3. Zero-Shot Evaluation on Real-World Industrial Data
4.5. Ablation Study
4.5.1. Experimental Configurations
- Full Model: Encoder equipped with FKAConv, Deformable Convolution (DC), and Local Self-Attention (LSA); decoder incorporating boundary-aware weighting (BA).
- No DC: Encoder without Deformable Convolution; retains FKAConv and LSA.
- No LSA: Encoder without Local Self-Attention; retains FKAConv and DC.
- No-BA Decoder: Decoder without boundary-aware weighting (i.e., removing the modulation term in Equation (6)).
4.5.2. Quantitative Results
5. Discussion
5.1. Summary of Key Advantages and Contributions
5.2. Zero-Shot Generalization and Practical Implications
5.3. Limitations and Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tao, F.; Zhang, H.; Zhang, C. Advancements and challenges of digital twins in industry. Nat. Comput. Sci. 2024, 4, 169–177. [Google Scholar] [CrossRef]
- Kritzinger, W.; Karner, M.; Traar, G.; Henjes, J.; Sihn, W. Digital Twin in manufacturing: A categorical literature review and classification. Ifac-PapersOnline 2018, 51, 1016–1022. [Google Scholar] [CrossRef]
- Leng, J.; Zhu, X.; Huang, Z.; Li, X.; Zheng, P.; Zhou, X.; Mourtzis, D.; Wang, B.; Qi, Q.; Shao, H.; et al. Unlocking the power of industrial artificial intelligence towards Industry 5.0: Insights, pathways, and challenges. J. Manuf. Syst. 2024, 73, 349–363. [Google Scholar] [CrossRef]
- Sarkar, B.D.; Shardeo, V.; Dwivedi, A.; Pamucar, D. Digital transition from industry 4.0 to industry 5.0 in smart manufacturing: A framework for sustainable future. Technol. Soc. 2024, 78, 102649. [Google Scholar] [CrossRef]
- Tao, F.; Xiao, B.; Qi, Q.; Cheng, J.; Ji, P. Digital twin modeling. J. Manuf. Syst. 2022, 64, 372–389. [Google Scholar] [CrossRef]
- Lu, Y.; Liu, C.; Kevin, I.; Wang, K.; Huang, H.; Xu, X. Digital Twin-driven smart manufacturing: Connotation, reference model, applications and research issues. Robot. Comput. Integr. Manuf. 2020, 61, 101837. [Google Scholar] [CrossRef]
- Jin, L.; Zhai, X.; Wang, K.; Zhang, K.; Wu, D.; Nazir, A.; Jiang, J.; Liao, W.H. Big data, machine learning, and digital twin assisted additive manufacturing: A review. Mater. Des. 2024, 244, 113086. [Google Scholar] [CrossRef]
- Wang, S.; Zhang, J.; Wang, P.; Law, J.; Calinescu, R.; Mihaylova, L. A deep learning-enhanced Digital Twin framework for improving safety and reliability in human–robot collaborative manufacturing. Robot. Comput.-Integr. Manuf. 2024, 85, 102608. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, X.; Liu, A.; Zhang, J.; Zhang, J. Ontology of 3D virtual modeling in digital twin: A review, analysis and thinking. J. Intell. Manuf. 2025, 36, 95–145. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Li, Y.; Xiao, Z.; Li, J.; Shen, T. Integrating vision and laser point cloud data for shield tunnel digital twin modeling. Autom. Constr. 2024, 157, 105180. [Google Scholar] [CrossRef]
- Zhu, Q.; Fan, L.; Weng, N. Advancements in point cloud data augmentation for deep learning: A survey. Pattern Recognit. 2024, 153, 110532. [Google Scholar] [CrossRef]
- Xiao, A.; Zhang, X.; Shao, L.; Lu, S. A survey of label-efficient deep learning for 3d point clouds. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 9139–9160. [Google Scholar] [CrossRef]
- Sulzer, R.; Marlet, R.; Vallet, B.; Landrieu, L. A survey and benchmark of automatic surface reconstruction from point clouds. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 47, 2000–2019. [Google Scholar] [CrossRef]
- Wu, J.; Wyman, O.; Tang, Y.; Pasini, D.; Wang, W. Multi-view 3D reconstruction based on deep learning: A survey and comparison of methods. Neurocomputing 2024, 582, 127553. [Google Scholar] [CrossRef]
- Mescheder, L.; Oechsle, M.; Niemeyer, M.; Nowozin, S.; Geiger, A. Occupancy networks: Learning 3d reconstruction in function space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4460–4470. [Google Scholar]
- Peng, S.; Niemeyer, M.; Mescheder, L.; Pollefeys, M.; Geiger, A. Convolutional occupancy networks. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part III 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 523–540. [Google Scholar]
- Park, J.J.; Florence, P.; Straub, J.; Newcombe, R.; Lovegrove, S. Deepsdf: Learning continuous signed distance functions for shape representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 165–174. [Google Scholar]
- Shen, L.; Pauly, J.; Xing, L. NeRP: Implicit neural representation learning with prior embedding for sparsely sampled image reconstruction. IEEE Trans. Neural Netw. Learn. Syst. 2022, 35, 770–782. [Google Scholar] [CrossRef]
- Chen, Z.; Wang, Y.; Nan, L.; Zhu, X.X. Parametric Point Cloud Completion for Polygonal Surface Reconstruction. In Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR), Nashville, TN, USA, 11–15 June 2025; pp. 11749–11758. [Google Scholar]
- Zhao, Z.; Alzubaidi, L.; Zhang, J.; Duan, Y.; Gu, Y. A comparison review of transfer learning and self-supervised learning: Definitions, applications, advantages and limitations. Expert Syst. Appl. 2024, 242, 122807. [Google Scholar] [CrossRef]
- Gui, J.; Chen, T.; Zhang, J.; Cao, Q.; Sun, Z.; Luo, H.; Tao, D. A survey on self-supervised learning: Algorithms, applications, and future trends. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 9052–9071. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Zhu, H.; Honarvar Shakibaei Asli, B. A Self-Supervised Point Cloud Completion Method for Digital Twin Smart Factory Scenario Construction. Electronics 2025, 14, 1934. [Google Scholar] [CrossRef]
- Fu, K.; Gao, P.; Liu, S.; Qu, L.; Gao, L.; Wang, M. Pos-bert: Point cloud one-stage bert pre-training. Expert Syst. Appl. 2024, 240, 122563. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, F.; Hou, Z.; Mian, L.; Wang, Z.; Zhang, J.; Tang, J. Self-supervised learning: Generative or contrastive. IEEE Trans. Knowl. Data Eng. 2021, 35, 857–876. [Google Scholar] [CrossRef]
- Yu, X.; Tang, L.; Rao, Y.; Huang, T.; Zhou, J.; Lu, J. Point-bert: Pre-training 3d point cloud transformers with masked point modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 19313–19322. [Google Scholar]
- Pang, Y.; Wang, W.; Tay, F.E.; Liu, W.; Tian, Y.; Yuan, L. Masked autoencoders for point cloud self-supervised learning. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 604–621. [Google Scholar]
- Zhang, R.; Guo, Z.; Gao, P.; Fang, R.; Zhao, B.; Wang, D.; Qiao, Y.; Li, H. Point-m2ae: Multi-scale masked autoencoders for hierarchical point cloud pre-training. Adv. Neural Inf. Process. Syst. 2022, 35, 27061–27074. [Google Scholar]
- Xue, L.; Gao, M.; Xing, C.; Martín-Martín, R.; Wu, J.; Xiong, C.; Xu, R.; Niebles, J.C.; Savarese, S. Ulip: Learning a unified representation of language, images, and point clouds for 3d understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 1179–1189. [Google Scholar]
- Min, C.; Xiao, L.; Zhao, D.; Nie, Y.; Dai, B. Occupancy-mae: Self-supervised pre-training large-scale lidar point clouds with masked occupancy autoencoders. IEEE Trans. Intell. Veh. 2023, 9, 5150–5162. [Google Scholar] [CrossRef]
- Bernardini, F.; Mittleman, J.; Rushmeier, H.; Silva, C.; Taubin, G. The ball-pivoting algorithm for surface reconstruction. IEEE Trans. Vis. Comput. Graph. 2002, 5, 349–359. [Google Scholar] [CrossRef]
- Liu, M.; Zhang, X.; Su, H. Meshing point clouds with predicted intrinsic-extrinsic ratio guidance. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part VIII 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 68–84. [Google Scholar]
- Cazals, F.; Giesen, J. Delaunay triangulation based surface reconstruction. In Effective Computational Geometry for Curves and Surfaces; Springer: Berlin/Heidelberg, Germany, 2006; pp. 231–276. [Google Scholar]
- Rakotosaona, M.J.; Guerrero, P.; Aigerman, N.; Mitra, N.J.; Ovsjanikov, M. Learning delaunay surface elements for mesh reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 22–31. [Google Scholar]
- Bernardini, F.; Bajaj, C.L. Sampling and Reconstructing Manifolds Using Alpha-Shapes. In Proceedings of the 9th Canadian Conference on Computational Geometry (CCCG’97), Kingston, ON, Canada, 11–14 August 1997; pp. 193–198. [Google Scholar]
- Labatut, P.; Pons, J.P.; Keriven, R. Robust and efficient surface reconstruction from range data. In Proceedings of the Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2009; Volume 28, pp. 2275–2290. [Google Scholar]
- Sulzer, R.; Landrieu, L.; Marlet, R.; Vallet, B. Scalable Surface Reconstruction with Delaunay-Graph Neural Networks. In Proceedings of the Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2021; Volume 40, pp. 157–167. [Google Scholar]
- Kazhdan, M.; Hoppe, H. Screened poisson surface reconstruction. ACM Trans. Graph. (ToG) 2013, 32, 1–13. [Google Scholar] [CrossRef]
- Peng, S.; Jiang, C.; Liao, Y.; Niemeyer, M.; Pollefeys, M.; Geiger, A. Shape as points: A differentiable poisson solver. Adv. Neural Inf. Process. Syst. 2021, 34, 13032–13044. [Google Scholar]
- Boulch, A.; Marlet, R. Poco: Point convolution for surface reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 6302–6314. [Google Scholar]
- Boulch, A.; Puy, G.; Marlet, R. FKAConv: Feature-kernel alignment for point cloud convolution. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Chang, A.X.; Funkhouser, T.; Guibas, L.; Hanrahan, P.; Huang, Q.; Li, Z.; Savarese, S.; Savva, M.; Song, S.; Su, H.; et al. Shapenet: An information-rich 3d model repository. arXiv 2015, arXiv:1512.03012. [Google Scholar]
- Choy, C.B.; Xu, D.; Gwak, J.; Chen, K.; Savarese, S. 3d-r2n2: A unified approach for single and multi-view 3d object reconstruction. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part VIII 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 628–644. [Google Scholar]
- Dai, A.; Ruizhongtai Qi, C.; Nießner, M. Shape completion using 3d-encoder-predictor cnns and shape synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5868–5877. [Google Scholar]
- Lionar, S.; Emtsev, D.; Svilarkovic, D.; Peng, S. Dynamic plane convolutional occupancy networks. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 1829–1838. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method/Title | Category | Strengths | Weaknesses |
|---|---|---|---|
| BPA [31] | Surface interpolation | Simple and efficient on clean, uniform data | Fails under noise, occlusion; sensitive to radius |
| IER-Meshing [32] | Surface interpolation | Learns continuity from intrinsic–extrinsic distances | Still lacks manifold guarantee |
| Delaunay Triangulation [33] | Surface approximation | Handles non-uniform sampling and curvature | Non-manifold risk, lacks smoothness |
| DSE-Meshing [34] | Surface approximation | Improved fidelity via local projection | No watertight guarantee |
| Alpha Shapes [35] | Volume interpolation | Simple geometric formulation | Sensitive to resolution and parameters |
| Graph-Cut [36] | Volume interpolation | Robust to missing data and noise | Complex graph optimization |
| DGNN [37] | Volume interpolation | GNNs improve surface watertightness | Training complexity |
| SPSR [38] | Volume approximation | Smooth, watertight surfaces | Oversmooths fine details; needs clean normals |
| DeepSDF [18] | Volume approximation | Learned SDFs enable expressive shape modeling | Requires SDF supervision and per-instance optimization |
| ConvONet [17] | Volume approximation | Encodes local priors with 3D CNN | Voxelization limits detail and efficiency |
| SAP [39] | Volume approximation | Efficient Poisson-based implicit surface reconstruction | Requires oriented surface point prediction |
| POCO [40] | Volume approximation | Point-based convolution avoids voxelization | Needs high-quality local features and training data |
| Parameter | Value |
|---|---|
| Number of input points | 3000 |
| Latent feature dimensions | 32/64/128/256 |
| Decoder k-NN neighbors | 64 |
| Neighborhood size K | 16 |
| Attention heads H | 4 |
| Voxel resolution | |
| Batch size | 8 |
| Training iterations | 60,000 |
| Learning rate |
| Category | CD- ↓ | F-Score ↑ | IoU ↑ | Normal Consistency ↑ |
|---|---|---|---|---|
| Airplane | 0.993 | 0.903 | 0.940 | |
| Bench | 0.977 | 0.889 | 0.927 | |
| Cabinet | 0.987 | 0.969 | 0.962 | |
| Car | 0.945 | 0.933 | 0.909 | |
| Chair | 0.987 | 0.918 | 0.959 | |
| Display | 0.992 | 0.961 | 0.977 | |
| Lamp | 0.986 | 0.889 | 0.944 | |
| Phone | 0.997 | 0.967 | 0.984 | |
| Rifle | 0.997 | 0.915 | 0.948 | |
| Sofa | 0.986 | 0.963 | 0.964 | |
| Speaker | 0.981 | 0.975 | 0.962 | |
| Table | 0.992 | 0.937 | 0.964 | |
| Vessel | 0.993 | 0.938 | 0.950 | |
| Mean | 0.986 | 0.935 | 0.953 |
| Method | IoU ↑ | CD ↓ | NC ↑ | FS ↑ |
|---|---|---|---|---|
| ONet [16] | 0.761 | 0.891 | 0.785 | |
| ConvONet [17] | 0.884 | 0.938 | 0.942 | |
| DP-ConvONet [45] | 0.895 | 0.941 | 0.952 | |
| POCO [40] | 0.926 | 0.950 | 0.984 | |
| Proposed method | 0.935 | 0.953 | 0.986 |
| Metric | Mean Value |
|---|---|
| Chamfer Distance (L1) | 0.0109 |
| F-Score (1 cm) | 0.7694 |
| F-Score (1.5 cm) | 0.8275 |
| F-Score (2 cm) | 0.8610 |
| IoU | 0.1694 |
| Normal Consistency | 0.8145 |
| Model Configuration | Chamfer Distance (L1) ↓ | Normal Consistency ↑ | IoU ↑ | F-Score ↑ |
|---|---|---|---|---|
| Full Model | 0.952 | 0.928 | 0.987 | |
| No LSA | 0.881 | 0.847 | 0.899 | |
| No DC | 0.913 | 0.904 | 0.953 | |
| No-BA Decoder | 0.829 | 0.788 | 0.899 |
| Metric | ShapeNet (Synthetic) | Industrial Dataset (Real) |
|---|---|---|
| Chamfer Distance (L1) ↓ | ||
| F-Score ↑ | 0.9860 | 0.7694 |
| IoU ↑ | 0.9350 | 0.1694 |
| Normal Consistency ↑ | 0.9530 | 0.8145 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Y.; Zhu, H.; Honarvar Shakibaei Asli, B. Zero-Shot 3D Reconstruction of Industrial Assets: A Completion-to-Reconstruction Framework Trained on Synthetic Data. Electronics 2025, 14, 2949. https://doi.org/10.3390/electronics14152949
Xu Y, Zhu H, Honarvar Shakibaei Asli B. Zero-Shot 3D Reconstruction of Industrial Assets: A Completion-to-Reconstruction Framework Trained on Synthetic Data. Electronics. 2025; 14(15):2949. https://doi.org/10.3390/electronics14152949
Chicago/Turabian StyleXu, Yongjie, Haihua Zhu, and Barmak Honarvar Shakibaei Asli. 2025. "Zero-Shot 3D Reconstruction of Industrial Assets: A Completion-to-Reconstruction Framework Trained on Synthetic Data" Electronics 14, no. 15: 2949. https://doi.org/10.3390/electronics14152949
APA StyleXu, Y., Zhu, H., & Honarvar Shakibaei Asli, B. (2025). Zero-Shot 3D Reconstruction of Industrial Assets: A Completion-to-Reconstruction Framework Trained on Synthetic Data. Electronics, 14(15), 2949. https://doi.org/10.3390/electronics14152949