

Diffusion Preference Alignment via Attenuated Kullback–Leibler Regularization



Abstract
1. Introduction
- We introduce a higher-order divergence regularization method, incorporating a tunable coefficient and higher-order divergence terms into the conventional KL regularization. This enables a more refined implicit reward function design, surpassing previous approaches that rely solely on simple KL penalties.
- For diffusion models, we redefine the data likelihood and construct the xDPO framework, from which we derive a concise and efficient loss function to achieve direct preference optimization.
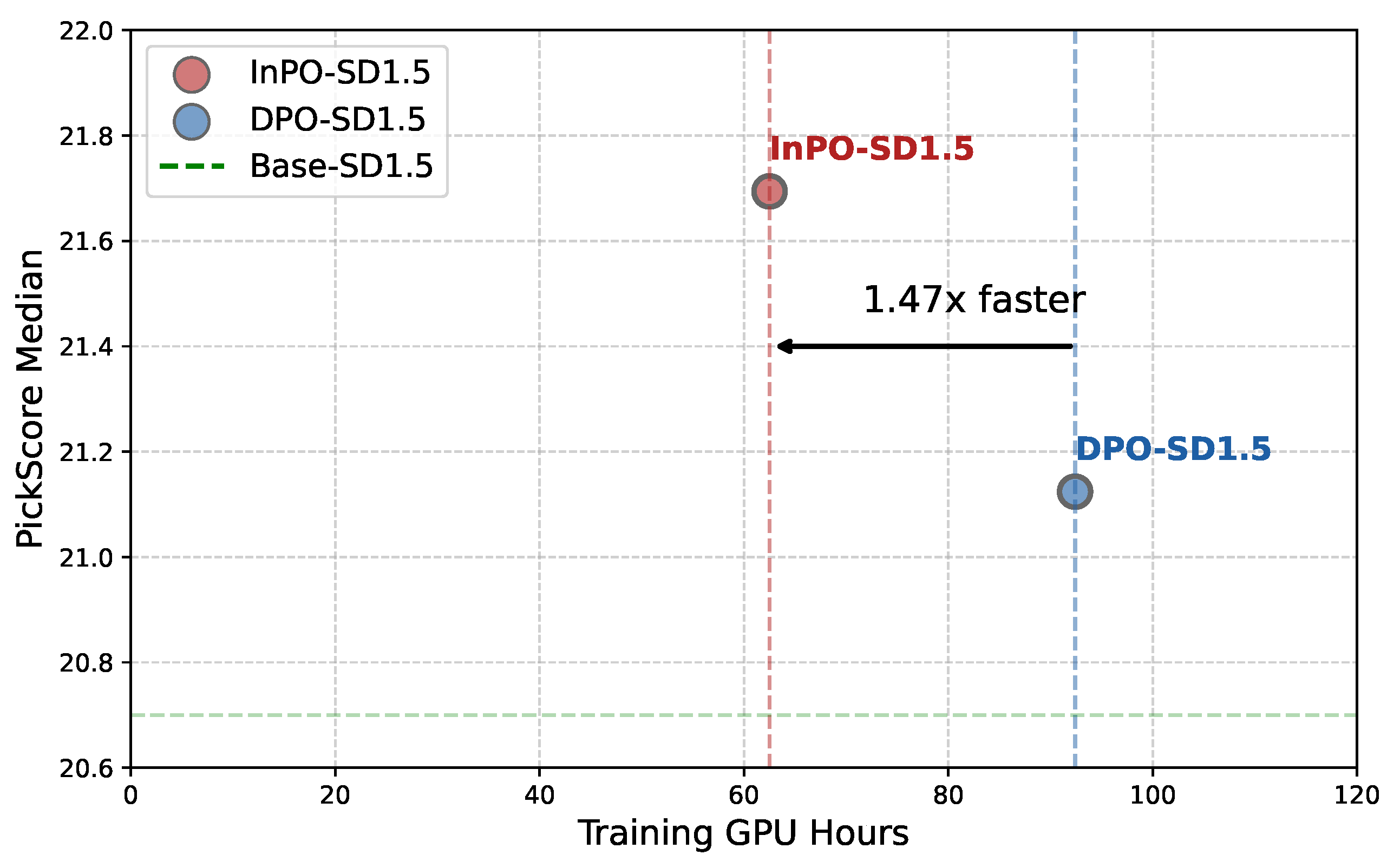
- Through comprehensive experiments, xDPO demonstrates approximately 1.6 times the training efficiency of Diffusion-DPO significantly improves the quality of generated images (see Figure 1), and receives consistent approval from both human evaluators and preference evaluation models.
2. Related Work
2.1. Text-to-Image Generative Models
2.2. Diffusion Models Alignment
3. Preliminaries
3.1. Diffusion Models
3.2. Human Preference Optimization
3.2.1. RLHF
3.2.2. Direct Preference Optimization
4. Method
5. Experiments
5.1. Model and Dataset
5.2. Hyperparameters
5.3. Evaluation
5.4. Quantitative Results
5.5. Qualitative Results
5.6. Ablations
6. Conclusions and Limitations
6.1. Conclusions
6.2. Limitations
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Further Qualitative Results


Appendix B. The Appendix Is an Optional Section

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Method |
|---|---|
| Figure 1, Row 1, Col1 | Pippi is tethered to the international space station in her space suit amidst stars and galaxies. |
| Figure 1, Row 1, Col2 | Two girls holding hands while watching the world burn in the style of various artists. |
| Figure 1, Row 1, Col3 | A galaxy-colored DnD dice is shown against a sunset over a sea, in artwork by Greg Rutkowski and Thomas Kinkade that is trending on Artstation. |
| Figure 1, Row 1, Col4 | Image of Earth reflected in a human eye, rendered with Octane, in high resolution. |
| Figure 1, Row 1, Col5 | A full body portrait of a sorceress with a long glowing hooded cloak, by Maciej Kuciara and Jason Chan. |
| Figure 1, Row 1, Col6 | Portrait of a young goth girl in warhammer armor, art by Kuvshinov Ilya, Wayne Barlowe, Gustav Klimt, Artgerm, and Wlop. |
| Figure 1, Row 2, Col1 | A metal bat bird with a red heart head, golden body, joints, and wings as if it is taking off. |
| Figure 1, Row 2, Col2 | A stylized image of fish resembling mythical fantasy creatures in the style of Moebius. |
| Figure 1, Row 2, Col3 | Goro Fujita’s illustration depicts a big city on the left and a forest on the right, separated by a highway filled with cars leaving the city. |
| Figure 1, Row 2, Col4 | The image is a concept art character design sheet featuring anime-style women in tek gear, French maid, pinup, cyberpunk, sci-fi, and fantasy styles by various artists. |
| Figure 1, Row 2, Col5 | Lionel Messi portrayed as a sitcom character. |
| Figure 1, Row 2, Col6 | A forest scene depicted in the morning light by Rumiko Takahashi. |
| Figure 1, Row 3, Col1 | A sailboat emoji with a rainbow-colored sail. |
| Figure 1, Row 3, Col2 | A girl in a school uniform playing an electric guitar. |
| Figure 1, Row 3, Col3 | A cute plush griffon with a lion body and seagull head. |
| Figure 1, Row 3, Col4 | The image depicts a person playing Warhammer. |
| Figure 1, Row 3, Col5 | A comical magazine poster of an ancient golden palace. |
| Figure 1, Row 3, Col6 | Anime character holding a axolotl with a black mouth mask. |
| Figure 1, Row 4, Col1 | A cat inside a rocket on a planet with cactuses. |
| Figure 1, Row 4, Col2 | A yellow striped monster panics while using a laptop. |
| Figure 1, Row 4, Col3 | A head-on centered symmetrical portrait of Elisha Cuthbert as a holy paladin, wearing steel armour and with blonde hair, depicted in a highly detailed digital painting with dramatic lighting, in the style of Artgerm and Anna Podedworna. |
| Figure 1, Row 4, Col4 | Dwayne Johnson depicted as a philosopher king in an academic painting by Greg Rutkowski. |
| Figure 1, Row 4, Col5 | Illustration of a cottage designed by Salvador Dali in a blooming forest during spring with a nearby stream, created by Goro Fujita. |
| Figure 1, Row 4, Col6 | An oil painting of Audrey Hepburn portraying Cersei Lannister from Game of Thrones. |
| Figure 1, Row 5, Col1 | A sunset panorama showing a graveyard of souls, with backlight and painted by Frazetta. |
| Figure 1, Row 5, Col2 | The image is of Roman ruins featuring silver and gold artifacts, depicted in hyper-detailed art style by artists Greg Rutkowski and Gustave Dore, and has been shared on various online platforms including Artstation, Worth1000.com, CGSociety, and DeviantArt. |
| Figure 1, Row 5, Col3 | A detailed digital painting of an ancient overgrown statue in a clearing, with vibrant colors and mystical lighting. |
| Figure 1, Row 5, Col4 | A bald general with an angry expression in an intricately detailed and elegant digital painting. |
| Figure 1, Row 5, Col5 | A beautiful Arabian angel wearing a niqab and adorned with jewelry by various artists. |
| Figure 1, Row 5, Col6 | Psytrance artwork by HR Giger. |
Appendix C. The xDPO Training Objective
References
- Sohl-Dickstein, J.; Weiss, E.; Maheswaranathan, N.; Ganguli, S. Deep unsupervised learning using nonequilibrium thermodynamics. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 2256–2265. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Song, Y.; Ermon, S. Generative Modeling by Estimating Gradients of the Data Distribution. Adv. Neural Inf. Process. Syst. 2019, 32, 11918–11930. [Google Scholar]
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. Training language models to follow instructions with human feedback. Adv. Neural Inf. Process. Syst. 2022, 35, 27730–27744. [Google Scholar]
- Ziegler, D.M.; Stiennon, N.; Wu, J.; Brown, T.B.; Radford, A.; Amodei, D.; Christiano, P.; Irving, G. Fine-tuning language models from human preferences. arXiv 2019, arXiv:1909.08593. [Google Scholar]
- Rafailov, R.; Sharma, A.; Mitchell, E.; Manning, C.D.; Ermon, S.; Finn, C. Direct Preference Optimization: Your Language Model is Secretly a Reward Model. In Proceedings of the Advances in Neural Information Processing Systems; Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2023; Volume 36, pp. 53728–53741. [Google Scholar]
- Wallace, B.; Dang, M.; Rafailov, R.; Zhou, L.; Lou, A.; Purushwalkam, S.; Ermon, S.; Xiong, C.; Joty, S.; Naik, N. Diffusion Model Alignment Using Direct Preference Optimization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 8228–8238. [Google Scholar]
- Song, Y.; Swamy, G.; Singh, A.; Bagnell, J.A.; Sun, W. Understanding Preference Fine-Tuning Through the Lens of Coverage. arXiv 2024, arXiv:2406.01462. [Google Scholar] [CrossRef]
- Wu, X.; Hao, Y.; Sun, K.; Chen, Y.; Zhu, F.; Zhao, R.; Li, H. Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis. arXiv 2023, arXiv:2306.09341. [Google Scholar]
- Yu, J.; Xu, Y.; Koh, J.Y.; Luong, T.; Baid, G.; Wang, Z.; Vasudevan, V.; Ku, A.; Yang, Y.; Ayan, B.K.; et al. Scaling autoregressive models for content-rich text-to-image generation. arXiv 2022, arXiv:2206.10789. [Google Scholar]
- Dhariwal, P.; Nichol, A. Diffusion models beat gans on image synthesis. Adv. Neural Inf. Process. Syst. 2021, 34, 8780–8794. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- Huang, Y.; Huang, J.; Liu, Y.; Yan, M.; Lv, J.; Liu, J.; Xiong, W.; Zhang, H.; Cao, L.; Chen, S. Diffusion model-based image editing: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2025, 47, 4409–4437. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.; Xia, M.; He, Y.; Zhang, Y.; Cun, X.; Yang, S.; Xing, J.; Liu, Y.; Chen, Q.; Wang, X.; et al. Videocrafter1: Open diffusion models for high-quality video generation. arXiv 2023, arXiv:2310.19512. [Google Scholar]
- Poole, B.; Jain, A.; Barron, J.T.; Mildenhall, B. Dreamfusion: Text-to-3d using 2d diffusion. arXiv 2022, arXiv:2209.14988. [Google Scholar]
- Bai, Y.; Jones, A.; Ndousse, K.; Askell, A.; Chen, A.; DasSarma, N.; Drain, D.; Fort, S.; Ganguli, D.; Henighan, T.; et al. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv 2022, arXiv:2204.05862. [Google Scholar] [CrossRef]
- Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S.; et al. Gpt-4 technical report. arXiv 2023, arXiv:2303.08774. [Google Scholar] [CrossRef]
- Schuhmann, C. LAION-AESTHETICS. 2022. Available online: https://laion.ai/blog/laion-aesthetics/ (accessed on 10 November 2023).
- Xu, J.; Liu, X.; Wu, Y.; Tong, Y.; Li, Q.; Ding, M.; Tang, J.; Dong, Y. Imagereward: Learning and evaluating human preferences for text-to-image generation. Adv. Neural Inf. Process. Syst. 2024, 36, 15903–15935. [Google Scholar]
- Kirstain, Y.; Polyak, A.; Singer, U.; Matiana, S.; Penna, J.; Levy, O. Pick-a-pic: An open dataset of user preferences for text-to-image generation. Adv. Neural Inf. Process. Syst. 2023, 36, 36652–36663. [Google Scholar]
- Fan, Y.; Watkins, O.; Du, Y.; Liu, H.; Ryu, M.; Boutilier, C.; Abbeel, P.; Ghavamzadeh, M.; Lee, K.; Lee, K. Reinforcement learning for fine-tuning text-to-image diffusion models. In Proceedings of the Thirty-Seventh Conference on Neural Information Processing Systems (NeurIPS) 2023, New Orleans, LA, USA, 10–16 December 2023. [Google Scholar]
- Black, K.; Janner, M.; Du, Y.; Kostrikov, I.; Levine, S. Training diffusion models with reinforcement learning. arXiv 2023, arXiv:2305.13301. [Google Scholar]
- Dai, X.; Hou, J.; Ma, C.Y.; Tsai, S.; Wang, J.; Wang, R.; Zhang, P.; Vandenhende, S.; Wang, X.; Dubey, A.; et al. Emu: Enhancing image generation models using photogenic needles in a haystack. arXiv 2023, arXiv:2309.15807. [Google Scholar] [CrossRef]
- Lee, K.; Liu, H.; Ryu, M.; Watkins, O.; Du, Y.; Boutilier, C.; Abbeel, P.; Ghavamzadeh, M.; Gu, S.S. Aligning text-to-image models using human feedback. arXiv 2023, arXiv:2302.12192. [Google Scholar]
- Wu, X.; Sun, K.; Zhu, F.; Zhao, R.; Li, H. Better aligning text-to-image models with human preference. arXiv 2023, arXiv:2303.14420. [Google Scholar]
- Betker, J.; Goh, G.; Jing, L.; Brooks, T.; Wang, J.; Li, L.; Ouyang, L.; Zhuang, J.; Lee, J.; Guo, Y.; et al. Improving image generation with better captions. Comput. Sci. 2023, 2, 8. [Google Scholar]
- Segalis, E.; Valevski, D.; Lumen, D.; Matias, Y.; Leviathan, Y. A picture is worth a thousand words: Principled recaptioning improves image generation. arXiv 2023, arXiv:2310.16656. [Google Scholar] [CrossRef]
- Yang, K.; Tao, J.; Lyu, J.; Ge, C.; Chen, J.; Shen, W.; Zhu, X.; Li, X. Using human feedback to fine-tune diffusion models without any reward model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 8941–8951. [Google Scholar]
- Yang, S.; Chen, T.; Zhou, M. A dense reward view on aligning text-to-image diffusion with preference. arXiv 2024, arXiv:2402.08265. [Google Scholar]
- Li, S.; Kallidromitis, K.; Gokul, A.; Kato, Y.; Kozuka, K. Aligning diffusion models by optimizing human utility. Adv. Neural Inf. Process. Syst. 2024, 37, 24897–24925. [Google Scholar]
- Ethayarajh, K.; Xu, W.; Muennighoff, N.; Jurafsky, D.; Kiela, D. Kto: Model alignment as prospect theoretic optimization. arXiv 2024, arXiv:2402.01306. [Google Scholar] [CrossRef]
- Huang, A.; Zhan, W.; Xie, T.; Lee, J.D.; Sun, W.; Krishnamurthy, A.; Foster, D.J. Correcting the mythos of kl-regularization: Direct alignment without overparameterization via chi-squared preference optimization. arXiv 2024, arXiv:2407.13399. [Google Scholar]
- Song, J.; Meng, C.; Ermon, S. Denoising diffusion implicit models. arXiv 2020, arXiv:2010.02502. [Google Scholar]
- Wang, C.; Jiang, Y.; Yang, C.; Liu, H.; Chen, Y. Beyond Reverse KL: Generalizing Direct Preference Optimization with Diverse Divergence Constraints. In Proceedings of the The Twelfth International Conference on Learning Representations, Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Kingma, D.; Salimans, T.; Poole, B.; Ho, J. Variational diffusion models. Adv. Neural Inf. Process. Syst. 2021, 34, 21696–21707. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021. [Google Scholar]
- Zhang, D.; Lan, G.; Han, D.J.; Yao, W.; Pan, X.; Zhang, H.; Li, M.; Chen, P.; Dong, Y.; Brinton, C.; et al. SePPO: Semi-Policy Preference Optimization for Diffusion Alignment. arXiv 2024, arXiv:2410.05255. [Google Scholar]




| Diffusion-DPO (Reverse KL) | ||
| xDPO |
| Dataset | Method | HPSV2 ↑ | PickScore ↑ | Image Reward ↑ | CLIP ↑ | Aesthetic ↑ |
|---|---|---|---|---|---|---|
| HPSV2 | SD v1-5 [12] | 26.97 | 20.690 | 0.125 | 0.349 | 5.46 |
| Diffusion-DPO [7] | 27.28 | 21.124 | 0.315 | 0.354 | 5.56 | |
| Diffusion-KTO [30] | 21.332 | 0.696 | 0.352 | 5.69 | ||
| SePPO [38] | 27.88 | 21.496 | 0.616 | 0.354 | ||
| xDPO (ours) | 27.98 | 5.66 | ||||
| PartiPrompts | SD v1-5 [12] | 26.956 | 21.240 | 0.244 | 0.336 | 5.260 |
| Diffusion-DPO [7] | 27.193 | 21.489 | 0.396 | 0.341 | 5.339 | |
| Diffusion-KTO [30] | 21.544 | 0.633 | 0.339 | 5.473 | ||
| SePPO [38] | 27.611 | 21.667 | 0.572 | 0.338 | ||
| xDPO (ours) | 5.439 |
| Median (HPDv2) | ||||
|---|---|---|---|---|
| HPSV2 | PickScore | Image Reward | CLIP | |
| Base-SD1.5 | 26.97 | 20.690 | 0.125 | 0.349 |
| DPO-SD1.5 | 27.28 | 21.124 | 0.315 | 0.354 |
| , , | ||||
| , , | 21.62 | 0.644 | 0.355 | |
| , , | 27.88 | 21.57 | 0.653 | 0.355 |
| , , | 27.98 | 21.70 | 0.702 | 0.355 |
| , , | 27.97 | 0.731 | ||
| , , | 27.98 | 21.694 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Xiang, W. Diffusion Preference Alignment via Attenuated Kullback–Leibler Regularization. Electronics 2025, 14, 2939. https://doi.org/10.3390/electronics14152939
Zhang X, Xiang W. Diffusion Preference Alignment via Attenuated Kullback–Leibler Regularization. Electronics. 2025; 14(15):2939. https://doi.org/10.3390/electronics14152939
Chicago/Turabian StyleZhang, Xinjian, and Wei Xiang. 2025. "Diffusion Preference Alignment via Attenuated Kullback–Leibler Regularization" Electronics 14, no. 15: 2939. https://doi.org/10.3390/electronics14152939
APA StyleZhang, X., & Xiang, W. (2025). Diffusion Preference Alignment via Attenuated Kullback–Leibler Regularization. Electronics, 14(15), 2939. https://doi.org/10.3390/electronics14152939