

A Robust and Energy-Efficient Control Policy for Autonomous Vehicles with Auxiliary Tasks

Abstract
1. Introduction
- We design a novel algorithm to create frame-to-frame difference images (FDIs) from raw visual sequences. Each FDI highlights the intensity change in the pixels caused by the change in vehicle movement. Taking FDIs as input can facilitate reliability when learning driving behaviors.
- We propose an end-to-end convolutional neural network to learn current and future driving controls based on the most distinct FDI features.
- We combine the control commands for the current and the upcoming time to achieve an energy-efficient control policy. In addition, we deploy a mobile robot in an outdoor environment to evaluate the performance of different control policies in terms of instantaneous power consumption.
2. Related Works
3. Overview
4. Methods
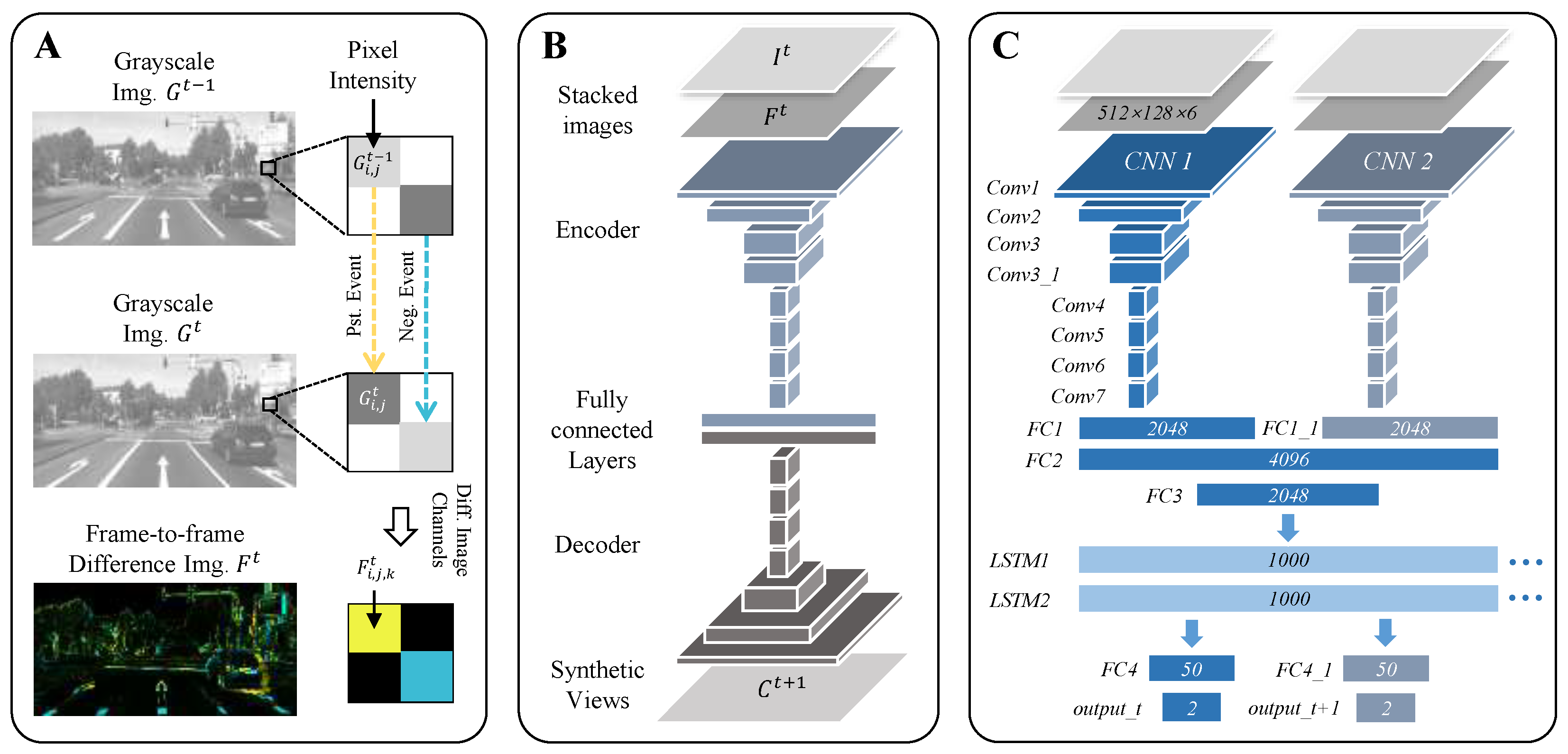
4.1. Frame-to-Frame Difference Image
4.2. Upcoming-View Synthesis
4.3. Autonomous Driving Model
4.4. Energy-Efficient Control Policy
5. Results and Discussion
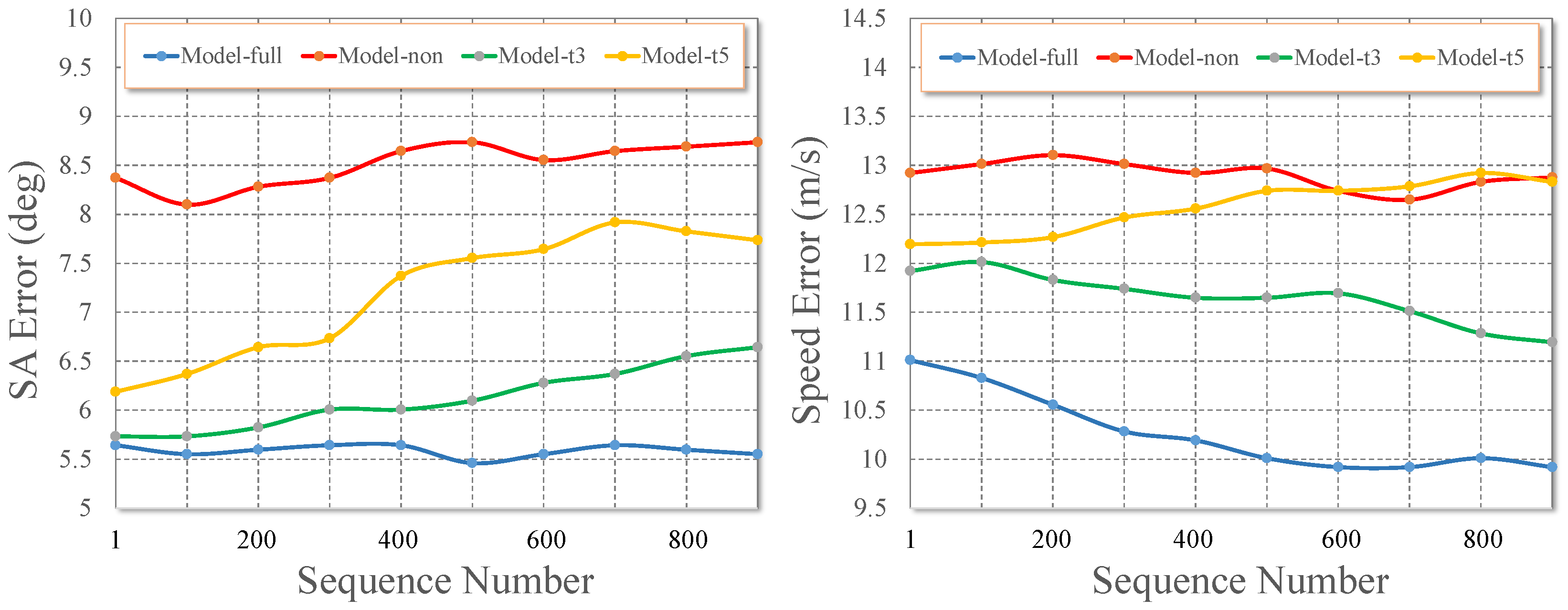
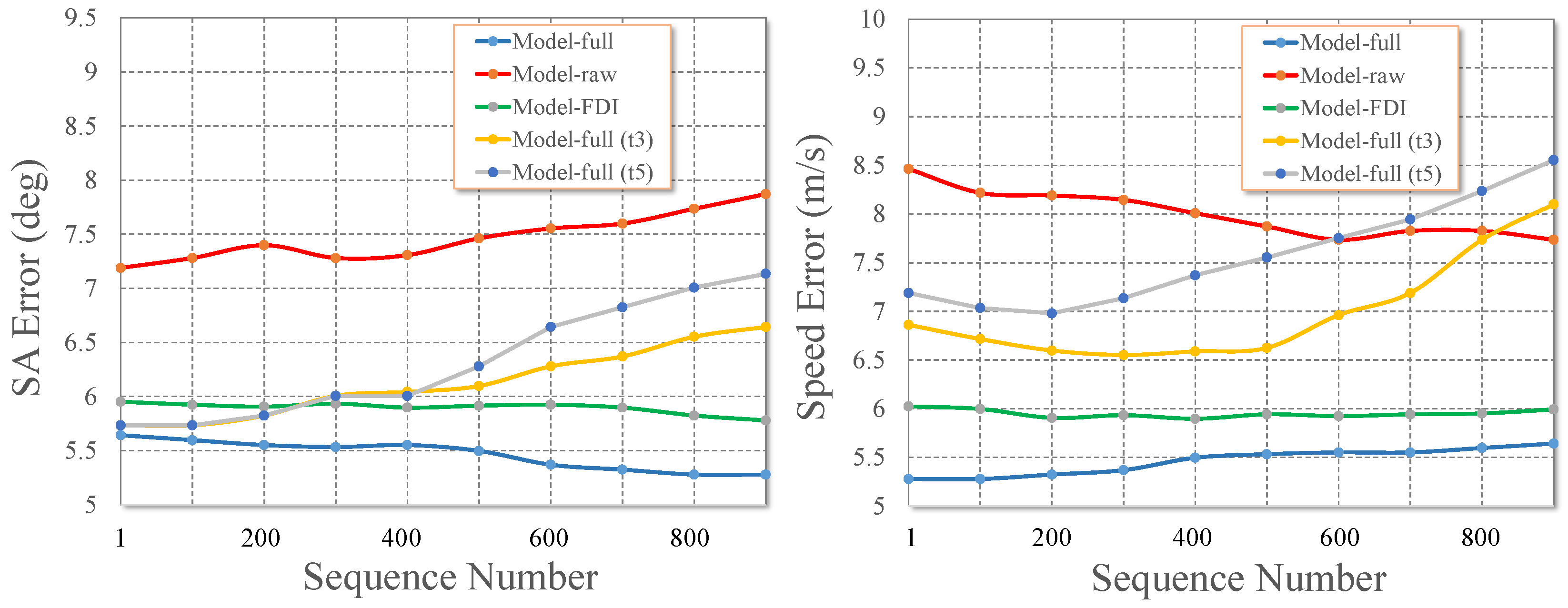
5.1. Accuracy Evaluation on Benchmarks
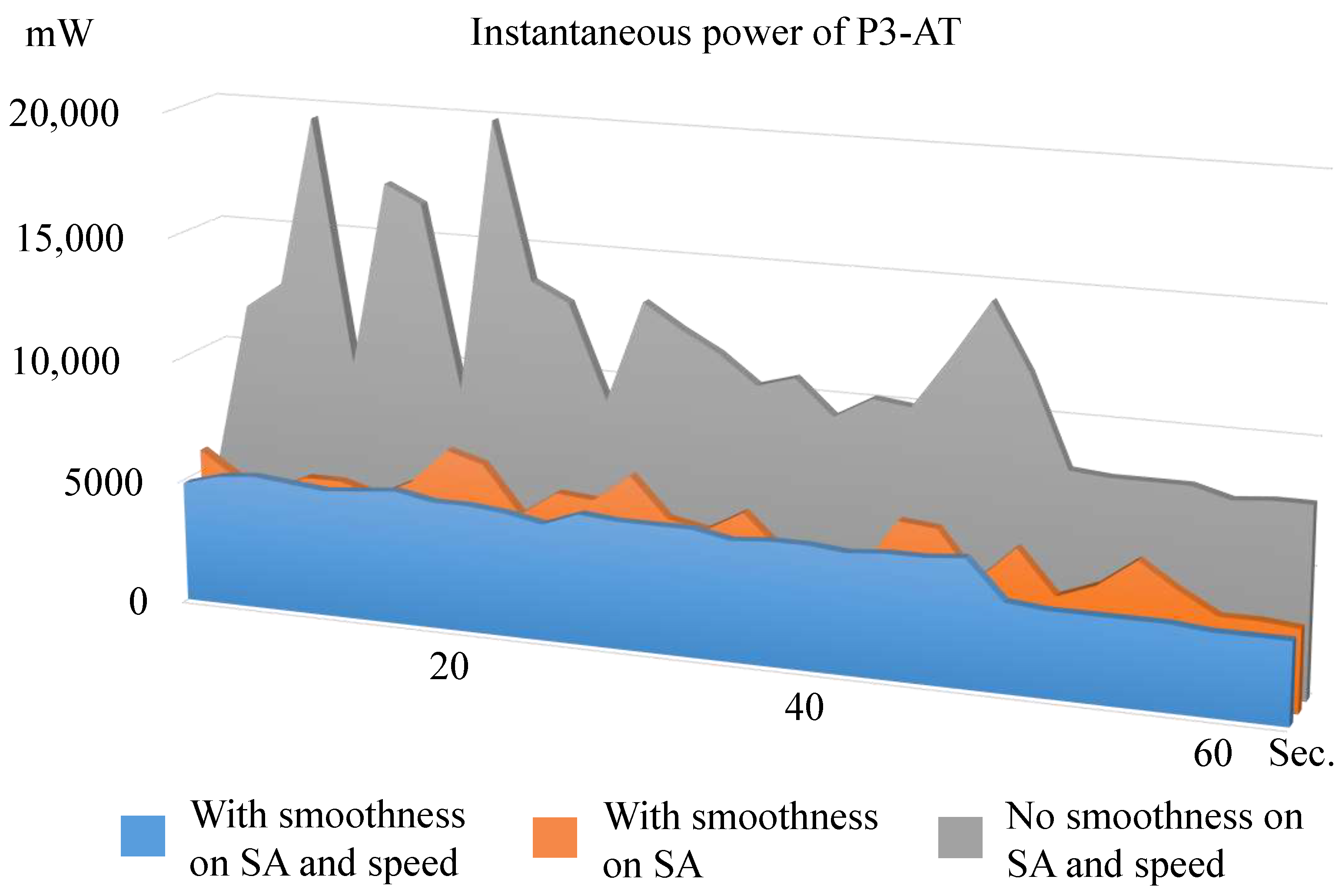
5.2. Evaluation of Energy-Efficiency
5.3. Efficiency of Driving Behavior
6. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, B.; Bessaad, N.; Xu, H.; Zhu, X.; Li, H. Mergeable Probabilistic Voxel Mapping for LiDAR–Inertial–Visual Odometry. Electronics 2025, 14, 2142. [Google Scholar] [CrossRef]
- Zhang, T.; Xia, Z.; Li, M.; Zheng, L. DIN-SLAM: Neural Radiance Field-Based SLAM with Depth Gradient and Sparse Optical Flow for Dynamic Interference Resistance. Electronics 2025, 14, 1632. [Google Scholar] [CrossRef]
- Zhang, Y.; Shi, P.; Li, J. 3d lidar slam: A survey. Photogramm. Rec. 2024, 39, 457–517. [Google Scholar] [CrossRef]
- Kato, S.; Takeuchi, E.; Ishiguro, Y.; Ninomiya, Y.; Takeda, K.; Hamada, T. An open approach to autonomous vehicles. IEEE Micro 2015, 35, 60–68. [Google Scholar] [CrossRef]
- Zhu, F.; Ma, L.; Xu, X.; Guo, D.; Cui, X.; Kong, Q. Baidu apollo auto-calibration system-an industry-level data-driven and learning based vehicle longitude dynamic calibrating algorithm. arXiv 2018, arXiv:1808.10134. [Google Scholar]
- Bojarski, M.; Testa, D.D.; Dworakowski, D.; Firner, B.; Flepp, B.; Goyal, P.; Jackel, L.D.; Monfort, M.; Muller, U.A.; Zhang, J.; et al. End to End Learning for Self-Driving Cars. arXiv 2016, arXiv:1604.07316. [Google Scholar] [CrossRef]
- Wang, S.; Clark, R.; Wen, H.; Trigoni, N. DeepVO: Towards end-to-end visual odometry with deep Recurrent Convolutional Neural Networks. In Proceedings of the International Conference on Robotics and Automation, Shanghai, China, 29–31 December 2017; pp. 2043–2050. [Google Scholar]
- Wang, S.; Clark, R.; Wen, H.; Trigoni, N. End-to-end, sequence-to-sequence probabilistic visual odometry through deep neural networks. Int. J. Robot. Res. 2018, 37, 513–542. [Google Scholar] [CrossRef]
- Xu, H.; Gao, Y.; Yu, F.; Darrell, T. End-to-End Learning of Driving Models from Large-Scale Video Datasets. In Proceedings of the Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3530–3538. [Google Scholar]
- Huval, B.; Wang, T.; Tandon, S.; Kiske, J.; Song, W.; Pazhayampallil, J.; Andriluka, M.; Rajpurkar, P.; Migimatsu, T.; Chengyue, R.; et al. An Empirical Evaluation of Deep Learning on Highway Driving. arXiv 2015, arXiv:1504.01716. [Google Scholar] [CrossRef]
- Chen, X.; Kundu, K.; Zhang, Z.; Ma, H.; Fidler, S.; Urtasun, R. Monocular 3D Object Detection for Autonomous Driving. In Proceedings of the Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2147–2156. [Google Scholar]
- Chen, C.; Seff, A.; Kornhauser, A.; Xiao, J. DeepDriving: Learning Affordance for Direct Perception in Autonomous Driving. In Proceedings of the The IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 2722–2730. [Google Scholar]
- Posch, C.; Serrano-Gotarredona, T.; Linares-Barranco, B.; Delbruck, T. Retinomorphic Event-Based Vision Sensors: Bioinspired Cameras With Spiking Output. Proc. IEEE 2014, 102, 1470–1484. [Google Scholar] [CrossRef]
- Mueggler, E.; Rebecq, H.; Gallego, G.; Delbruck, T.; Scaramuzza, D. The Event-Camera Dataset and Simulator: Event-based Data for Pose Estimation, Visual Odometry, and SLAM. Int. J. Robot. Res. 2017, 36, 142–149. [Google Scholar] [CrossRef]
- Ghosh, R.; Mishra, A.; Orchard, G.; Thakor, N.V. Real-time object recognition and orientation estimation using an event-based camera and CNN. In Proceedings of the IEEE 2014 Biomedical Circuits and Systems Conference, BioCAS 2014, Lausanne, Switzerland, 22–24 October 2014; pp. 544–547. [Google Scholar]
- Maqueda, A.I.; Loquercio, A.; Gallego, G.; Garcla, N.; Scaramuzza, D. Event-Based Vision Meets Deep Learning on Steering Prediction for Self-Driving Cars. In Proceedings of the The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 5419–5427. [Google Scholar]
- Lotter, W.; Kreiman, G.; Cox, D.D. Deep Predictive Coding Networks for Video Prediction and Unsupervised Learning. arXiv 2016, arXiv:1605.08104. [Google Scholar]
- Tatarchenko, M.; Dosovitskiy, A.; Brox, T. Single-view to Multi-view: Reconstructing Unseen Views with a Convolutional Network. arXiv 2015, arXiv:1511.06702. [Google Scholar]
- Zhou, T.; Tulsiani, S.; Sun, W.; Malik, J.; Efros, A.A. View Synthesis by Appearance Flow. In Proceedings of the European Conference on Computer Vision (2016), Amsterdam, The Netherlands, 11–14 October 2016; pp. 286–301. [Google Scholar]
- Baras, N.; Nantzios, G.; Ziouzios, D.; Dasygenis, M. Autonomous Obstacle Avoidance Vehicle Using LIDAR and an Embedded System. In Proceedings of the 2019 8th International Conference on Modern Circuits and Systems Technologies (MOCAST), Thessaloniki, Greece, 13–15 May 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Li, Y.; Ma, L.; Zhong, Z.; Liu, F.; Chapman, M.A.; Cao, D.; Li, J. Deep Learning for LiDAR Point Clouds in Autonomous Driving: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 3412–3432. [Google Scholar] [CrossRef] [PubMed]
- Hane, C.; Heng, L.; Lee, G.H.; Fraundorfer, F.; Furgale, P.; Sattler, T.; Pollefeys, M. 3D visual perception for self-driving cars using a multi-camera system: Calibration, mapping, localization, and obstacle detection. Image Vis. Comput. 2017, 68, 14–27. [Google Scholar] [CrossRef]
- Mathew, A.; Mathew, J. Monocular depth estimation with SPN loss. Image Vis. Comput. 2020, 100, 103934. [Google Scholar] [CrossRef]
- Chen, J.; Bai, T. SAANet: Spatial adaptive alignment network for object detection in automatic driving. Image Vis. Comput. 2020, 94, 103873. [Google Scholar] [CrossRef]
- Costante, G.; Mancini, M.; Valigi, P.; Ciarfuglia, T.A. Exploring Representation Learning With CNNs for Frame-to-Frame Ego-Motion Estimation. IEEE Robot. Autom. Lett. 2016, 1, 18–25. [Google Scholar] [CrossRef]
- Amini, A.; Gilitschenski, I.; Phillips, J.; Moseyko, J.; Banerjee, R.; Karaman, S.; Rus, D. Learning Robust Control Policies for End-to-End Autonomous Driving From Data-Driven Simulation. IEEE Robot. Autom. Lett. 2020, 5, 1143–1150. [Google Scholar] [CrossRef]
- Kim, J.; Canny, J. Interpretable learning for self-driving cars by visualizing causal attention. In Proceedings of the The IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2942–2950. [Google Scholar]
- Hyndman, R.; Koehler, A.B.; Ord, J.K.; Snyder, R.D. Forecasting with Exponential Smoothing: The State Space Approach; Springer Science and Business Media: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Yang, Z.; Zhang, Y.; Yu, J.; Cai, J.; Luo, J. End-to-end multi-modal multi-task vehicle control for self-driving cars with visual perception. In Proceedings of the International Conference on Pattern Recognition (ICPR), Beijing, China, 10–24 August 2018. [Google Scholar]
- Rebecq, H.; Gehrig, D.; Scaramuzza, D. In Proceedings of the ESIM: An Open Event Camera Simulator, Zürich, Switzerland, 29–31 October 2018.
- Yang, J.; Zhao, Y.; Jiang, B.; Lu, W.; Gao, X. No-Reference Quality Evaluation of Stereoscopic Video Based on Spatio-Temporal Texture. IEEE Trans. Multimed. 2019, 22, 2635–2644. [Google Scholar] [CrossRef]
- Li, Z.; Hu, H.; Zhang, W.; Pu, S.; Li, B. Spectrum Characteristics Preserved Visible and Near-Infrared Image Fusion Algorithm. IEEE Trans. Multimed. 2020, 23, 306–319. [Google Scholar] [CrossRef]
- Shepard, R.N.; Metzler, J. Mental Rotation of Three-Dimensional Objects. Science 1971, 171, 701–703. [Google Scholar] [CrossRef] [PubMed]
- Li, K.; Wu, Y.; Xue, Y.; Qian, X. Viewpoint Recommendation Based on Object Oriented 3D Scene Reconstruction. IEEE Trans. Multimed. 2020, 23, 257–267. [Google Scholar] [CrossRef]
- Li, L.; Zhou, Y.; Wu, J.; Li, F.; Shi, G. Quality Index for View Synthesis by Measuring Instance Degradation and Global Appearance. IEEE Trans. Multimed. 2020, 23, 320–332. [Google Scholar] [CrossRef]
- Rosin, P.; Ellis, T. Image difference threshold strategies and shadow detection. In Proceedings of the British Machine Vision Conference, Birmingham, UK, 11–14 September 1995. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? the kitti vision benchmark suite. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Maddern, W.; Pascoe, G.; Linegar, C.; Newman, P. 1 Year, 1000 km: The Oxford RobotCar Dataset. Int. J. Robot. Res. (IJRR) 2017, 36, 3–15. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Kreuzig, R.; Ochs, M.; Mester, R. DistanceNet: Estimating Traveled Distance From Monocular Images Using a Recurrent Convolutional Neural Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; pp. 69–77. [Google Scholar]
- Lefevre, S.; Carvalho, A.; Borrelli, F. A Learning-Based Framework for Velocity Control in Autonomous Driving. IEEE Trans. Autom. Sci. Eng. 2016, 13, 32–42. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Pei, Y.; Sun, B.; Li, S. Multifeature Selective Fusion Network for Real-Time Driving Scene Parsing. IEEE Trans. Instrum. Meas. 2021, 70, 5008412. [Google Scholar] [CrossRef]
- Hu, H.; Zhao, T.; Wang, Q.; Gao, F.; He, L.; Gao, Z. Monocular 3-D Vehicle Detection Using a Cascade Network for Autonomous Driving. IEEE Trans. Instrum. Meas. 2021, 70, 5012213. [Google Scholar] [CrossRef]
- Seff, A.; Xiao, J. Learning from Maps: Visual Common Sense for Autonomous Driving. arXiv 2016, arXiv:1611.08583. [Google Scholar] [CrossRef]
- Yan, Z.; Zhang, C.; Yang, Y.; Liang, J. A Novel In-Motion Alignment Method Based on Trajectory Matching for Autonomous Vehicles. IEEE Trans. Veh. Technol. 2021, 70, 2231–2238. [Google Scholar] [CrossRef]




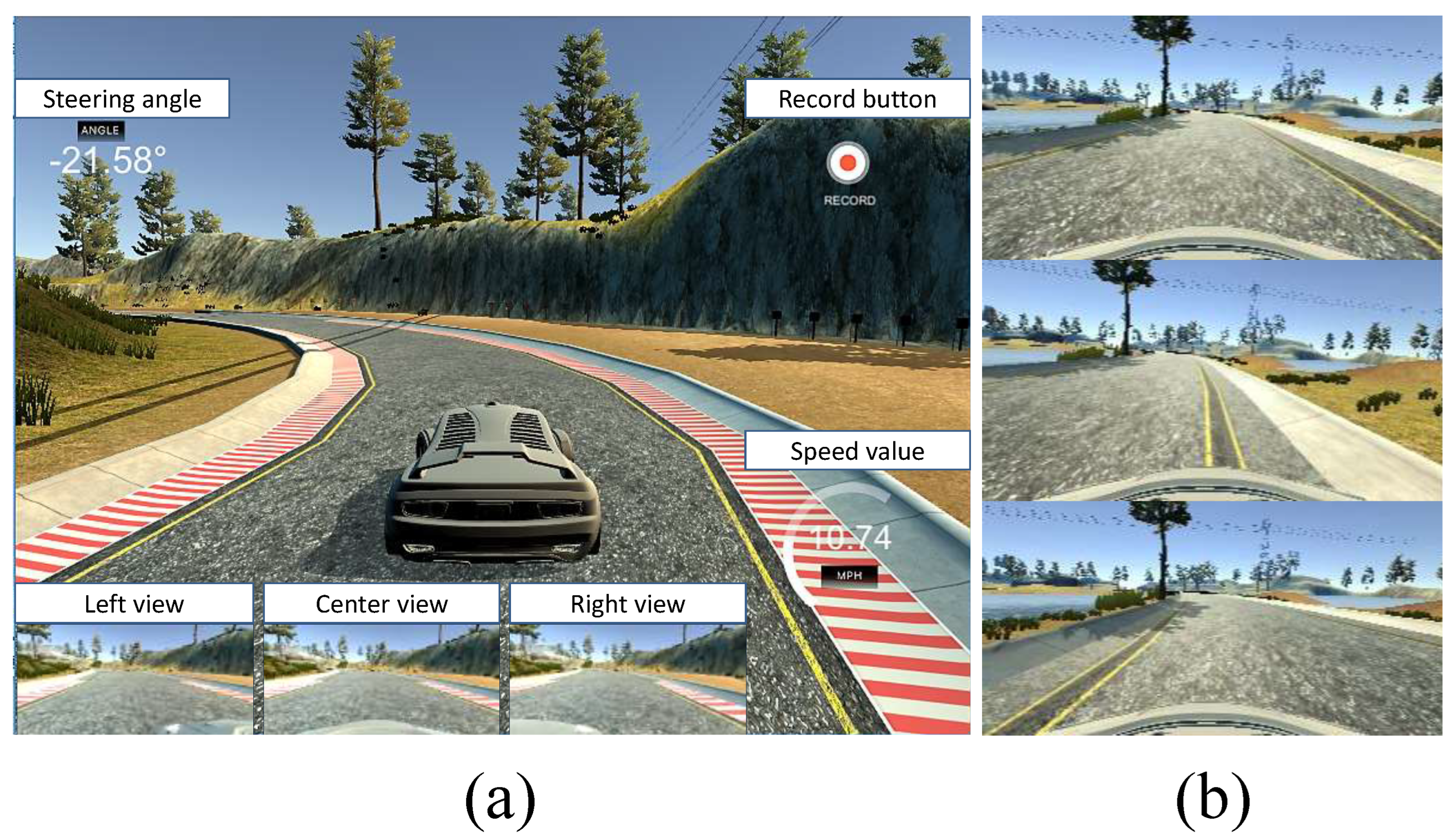
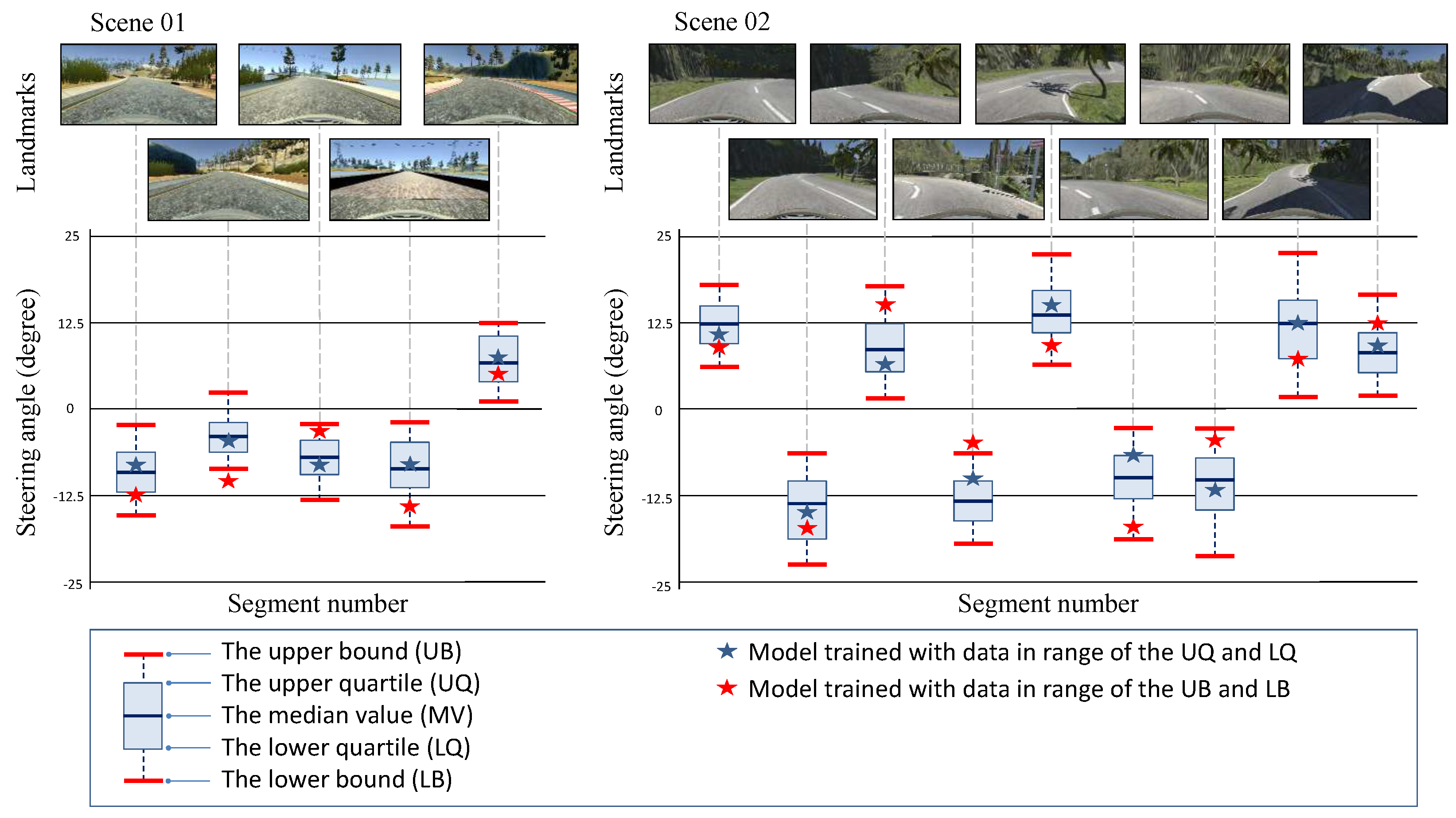

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Receptive Field | Padding | Stride | Kernels | Feature Map Size |
|---|---|---|---|---|---|
| 7 × 7 | 3 | 2 | 64 | 256 × 64 × 64 | |
| 5 × 5 | 2 | 2 | 128 | 128 × 32 × 128 | |
| 5 × 5 | 2 | 1 | 256 | 64 × 16 × 256 | |
| 3 × 3 | 1 | 2 | 256 | 64 × 16 × 256 | |
| 3 × 3 | 1 | 2 | 512 | 32 × 8 × 512 | |
| 3 × 3 | 1 | 2 | 512 | 16 × 4 × 512 | |
| 3 × 3 | 1 | 2 | 512 | 8 × 2 × 512 | |
| 3 × 3 | 1 | 2 | 512 | 4 × 1 × 512 |
| Seq. | Our Model | DeepVO | PCNN | PilotNet | Cg Network | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| SA (deg) | SPD (m/s) | SA (deg) | SPD (m/s) | SA (deg) | SPD (m/s) | SA (deg) | SPD (m/s) | SA (deg) | SPD (m/s) | |
| KITTI/City/2011-09-26-drive-0009 | 7.89 | 9.86 | 7.72 | 10.99 | 7.68 | 11.69 | 12.57 | 13.85 | 17.64 | 21.74 |
| KITTI/Residential/2011-09-26-drive-0019 | 4.60 | 7.39 | 7.35 | 11.50 | 8.76 | 17.18 | 14.54 | 17.48 | 19.16 | 26.55 |
| KITTI/Road/2011-09-26-drive-0028 | 6.72 | 8.95 | 8.84 | 12.39 | 7.44 | 15.12 | 16.97 | 19.45 | 20.84 | 21.29 |
| RobotCar/2014-06-25-16-22-15-sun | 5.79 | 7.20 | 5.52 | 9.59 | 5.83 | 12.49 | 12.51 | 16.28 | 15.24 | 19.08 |
| RobotCar/2014-12-05-11-09-10-rain | 4.32 | 7.75 | 6.19 | 13.14 | 7.08 | 14.75 | 15.43 | 17.75 | 21.07 | 26.22 |
| RobotCar/2015-02-03-08-45-10-snow | 3.36 | 5.78 | 7.46 | 12.35 | 8.16 | 17.06 | 14.35 | 21.96 | 13.15 | 18.94 |
| RobotCar/2015-02-03-19-43-11-night | 6.12 | 10.80 | 12.68 | 18.41 | 17.52 | 22.75 | 12.89 | 27.59 | 23.28 | 28.67 |
| Average | 5.54 | 8.25 | 7.97 | 12.62 | 8.92 | 15.86 | 14.18 | 19.19 | 18.63 | 23.21 |
| Seq. | Policy-v1 | Policy-v2 | Policy-v3 | DeepVO |
|---|---|---|---|---|
| Path 01 | 12,593.43 | 13,584.53 | 13,511.37 | 13,409.21 |
| Path 02 | 8576.61 | 9712.62 | 8945.49 | 10,246.49 |
| Path 03 (daytime) | 6174.95 | 6651.74 | 6784.08 | 6718.05 |
| Path 03 (nighttime) | 6645.28 | 7059.08 | 6916.15 | 7162.57 |
| Average | 8497.57 | 9251.99 | 9039.27 | 9384.08 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Y.; Yang, C.; Gong, X. A Robust and Energy-Efficient Control Policy for Autonomous Vehicles with Auxiliary Tasks. Electronics 2025, 14, 2919. https://doi.org/10.3390/electronics14152919
Xu Y, Yang C, Gong X. A Robust and Energy-Efficient Control Policy for Autonomous Vehicles with Auxiliary Tasks. Electronics. 2025; 14(15):2919. https://doi.org/10.3390/electronics14152919
Chicago/Turabian StyleXu, Yabin, Chenglin Yang, and Xiaoxi Gong. 2025. "A Robust and Energy-Efficient Control Policy for Autonomous Vehicles with Auxiliary Tasks" Electronics 14, no. 15: 2919. https://doi.org/10.3390/electronics14152919
APA StyleXu, Y., Yang, C., & Gong, X. (2025). A Robust and Energy-Efficient Control Policy for Autonomous Vehicles with Auxiliary Tasks. Electronics, 14(15), 2919. https://doi.org/10.3390/electronics14152919