
ANHNE: Adaptive Multi-Hop Neighborhood Information Fusion for Heterogeneous Network Embedding


Abstract
1. Introduction
- (1)
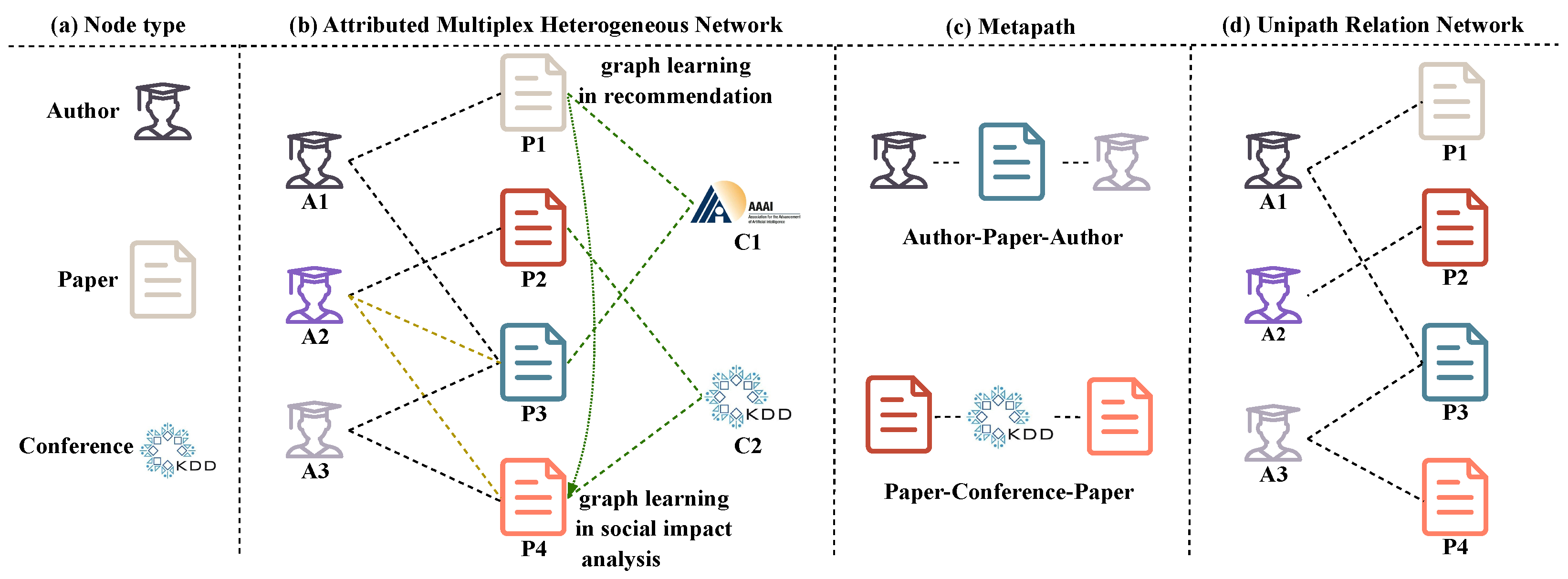
- Inadequate information mining along metapaths: Most metapath-based heterogeneous network representations [16,25,26] focus only on the information of the nodes at the two ends of the metapath and ignore the information of the intermediary nodes, which are also crucial for representation learning. As shown in Figure 1b, two authors in the ‘APA’ metapath can collaborate on different papers (A2 and A3), and neglecting the information related to these papers hampers the accurate mining of the relation between the authors. Some state-of-the-art approaches [18,27,28] address this by emphasizing message passing to capture various relations between nodes. However, these methods rely on stacking multiple layers of GNNs to aggregate neighbor information, which can lead to performance degradation and excessive smoothing.
- (2)
- The common method of determining walking paths through predefined metapaths introduces bias in network structure construction. On the one hand, the learning of network structure heavily depends on the quality of manually designed metapaths, which must be specified in advance based on experience or domain knowledge (e.g., the ‘APA’ and ‘PCP’ metapaths in Figure 1c, which indicate that two authors collaborated on a paper and two papers were presented at the same conference, respectively). Yet, they cannot autonomously extract valuable metapaths tailored to specific task scenarios. Especially for unknown HINs, valid metapaths cannot always be pre-identified [29]. Differently defined metapaths in the same dataset affect GCN performance due to varying semantics and values across different scenarios. On the other hand, the lack of effective integration of different metapaths is not conducive to extracting the network structure for learning. To illustrate, ‘APA’ signifies a scenario where two authors have co-authored a paper, whereas ‘APCPA’ indicates that articles by two authors are featured in the same conference or journal. Different metapaths represent diverse meanings and have varying importance, making their effective integration crucial for improvement.
- (3)
- Most metapath-based embedding models ignore potential semantic associations between node attributes. Current studies [17,18,30] only learn network embedding representations from primitive network structures. While the primitive structure reflects explicit node relations, it does not encompass all possible relations, missing many implicit relations between nodes. For instance, as depicted in Figure 1b, interdisciplinary papers P1 and P4 may not directly cite each other and lack connecting metapaths owing to their authors and topics originating from different fields. However, they share the same heterogeneous network embedding technique, indicating a latent semantic relation. Capturing these potential correlations between nodes allows for the exploration of deeper semantic relations, resulting in a more comprehensive network structure and improved node representation.
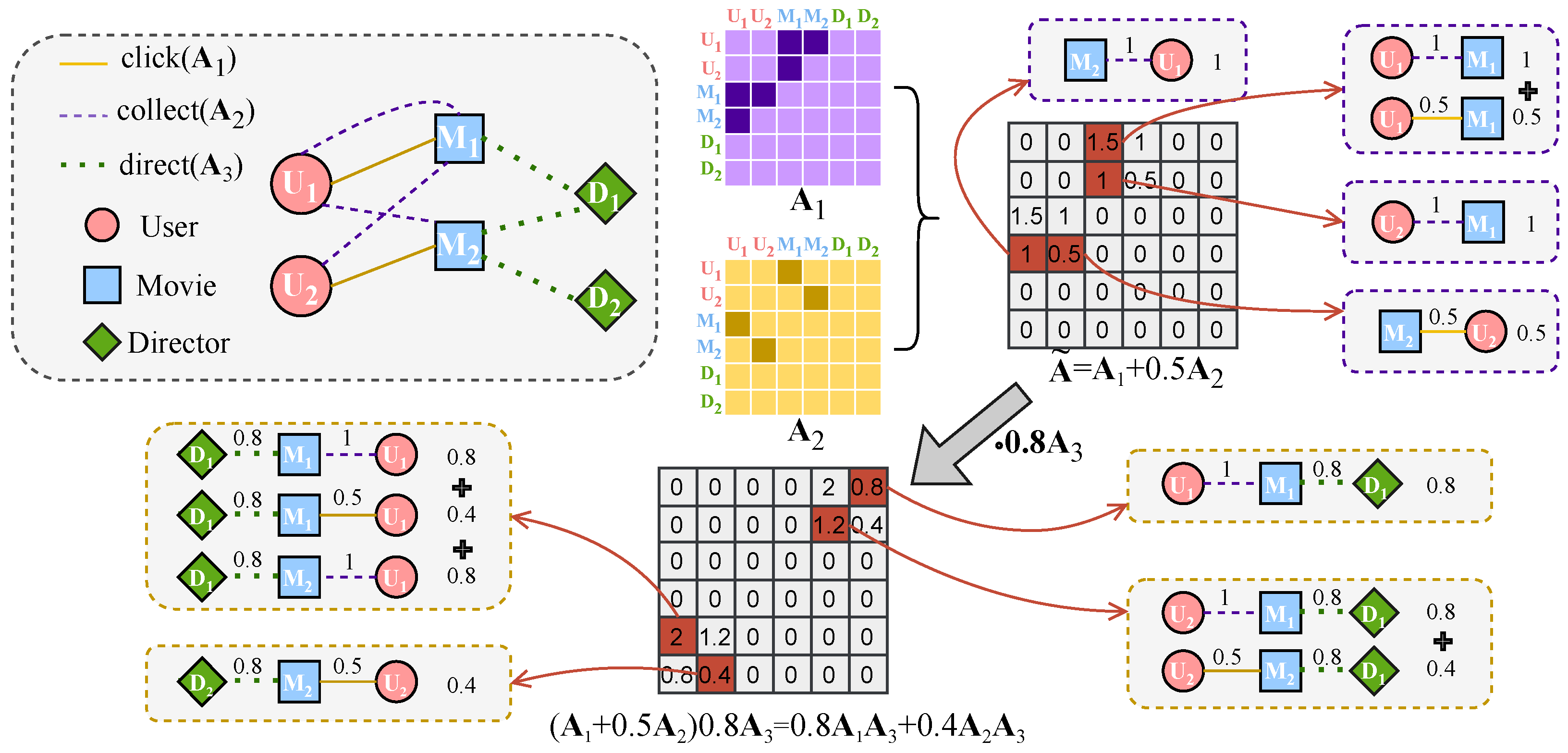
- To the best of our knowledge, this paper presents the concept of composite metapaths for the first time. Unlike the commonly accepted notion of metapaths, composite metapaths are soft combinations of different relations for specific task scenarios, where the topological information of all nodes on the path can be aggregated through the matrix product of unipath relations with different weights.
- We develop a hierarchical semantic attention aggregation model that autonomously determines the relative importance of valuable composite metapaths of specific lengths and selectively aggregates information across different hierarchical levels of neighboring nodes.
- We propose a semantic information enhancement module that mines potential relations between nodes and extensively extracts implicit semantic relations without direct connectivity, enhancing feature representation learning to obtain high-quality representations.
- We conduct extensive experiments on three real-world datasets to indicate the advantage of each module and demonstrate the superiority of our proposal to the state of the art for multiplex heterogeneous networks.

2. Related Work
2.1. Graph Convolutional Networks (GCNs)
2.2. Heterogeneous Network Representation Learning
3. Methodology
3.1. Preliminaries
3.2. Overall Framework
3.3. Multipath Relation Aggregation
3.4. Composite Metapath Autonomous Extraction Model (CMAE)
- A distinctive aspect of our approach is that relation weights do not require manual specification; rather, they are autonomously learned while considering the specific task scenarios. This allows for dynamic adjustment of weights based on the actual effects of embedding. For instance, in the academic network shown in Figure 1b, if the collaboration between authors holds more significance, the relations in the ‘APA’ path will carry higher weights. Conversely, if differences in research areas among authors are more important, the relations in the ‘APCPA’ path should have higher weights. This enables us to more precisely capture complex semantic information.
- Our method enables automatic semantic mining. The composite metapaths learnd by CMAE are essentially soft combinations of various relations and can consider numerous sub-metapaths with specific semantics. Consequently, by multiplying and superimposing unipath relation adjacency matrices with varying weights, CMAE can autonomously extract l-layer metapaths, thereby overcoming the limitations of existing methods that require predefined metapaths. Unlike GTN [23], which generates metapaths via multiplication of adjacency matrices, our composite metapaths are weighted combinations of multipath relations.
- We gather multi-layer relation topology information by multiplying matrices with weights, and then proceed to feature aggregation via GCN instead of stacking multi-layer GNNs. This not only reduces computational demands, but also avoids performance degradation due to over-smoothing.
3.5. Hierarchical Semantic Attention Aggregation Model (HSAA)
3.6. Semantic Information Enhancement Model (SIE)

3.7. Model Efficiency Analysis
4. Experiments and Results Analysis
4.1. Dataset
- ACM (http://dl.acm.org (accessed on 3 July 2025)): This widely recognized open-source citation network dataset comprises nodes that represent papers, authors, and topics. The initial features of the papers are obtained through a bag-of-words model applied to the paper keywords, where each node is characterized by 1870 attributes.
- DBLP (https://dblp.uni-trier.de (accessed on 3 July 2025)): This dataset features a citation network with nodes categorized into four types: papers, authors, conferences, and topics. For our experiments, we extracted a subset of the DBLP dataset, selecting 4057 nodes for analysis, which includes three types of paper nodes: information extraction, data mining, and artificial intelligence.
- IMDB (https://www.imdb.com (accessed on 3 July 2025)): This dataset includes a citation network comprising nodes classified into four categories: papers, authors, conferences, and topics. For our experimental analysis, we selected a subset of the DBLP dataset, comprising 4057 nodes, which encompasses three types of paper nodes: information extraction, data mining, and artificial intelligence.
4.2. Baselines
- GCN [10]: Extends traditional CNNs to non-Euclidean network structures, synthesizing neighbor node information at each layer through specific aggregation strategies (e.g., averaging or summing), and enabling in-depth exploration of the graph’s intrinsic properties and structural relations via feature analysis.
- GAT [15]: Aggregates information from single-layer neighbors through an attention mechanism, allowing each node to assess the importance of its one-hop neighbors based on their features. However it can only aggregate information within one-hop neighbors.
- HAN [16]: Learns the importance of nodes and their metapath-based neighbors, introducing semantic-level attention to fuse representations under different metapaths based on GAT, thus facilitating hierarchical feature aggregation through metapath neighbors.
- MAGNN [49]: It projects attributes of heterogeneous nodes into a shared semantic space, then performs intra-metapath and inter-metapath information aggregation to capture the structural and semantic nuances of the network.
- GTN [23]: Learns to softly select combined relations to generate useful metapaths and control lengths automatically. Its metapath generation module shares functionalities with the CMAE model in this study.
- MHGCN [24]: Utilizes an attributed multi-order graph convolutional network to capture multi-relational structural information, explores different metapaths automatically, and employs both unsupervised and semi-supervised learning techniques to learn and derive the final node embeddings.
- AMOGCN [45]: Constructs different order adjacency matrices containing various metapath relations, selectively fuses information from these matrices via SGC, and extracts final node embeddings through supervised learning that incorporates node semantic and labeling information.
- ANHNE. Our proposed method.
4.3. Implementation Details
4.4. Performance on Embedding
4.5. Ablation Experiment
- Only manual metapath aggregation (OMMA), which replaces composite metapaths with manual and fixed ones. This variant aggregates information of multi-hop nodes across common manually defined metapaths instead of composite metapaths with diverse sub-metapaths.
- No layer-level attention aggregation (NOAA), which omits the HSAA module. This variant does not differentiate the semantics of different neighbor layers but aggregates all layers of neighborhood information equally.
- No semantic information enhancement (NOSIE), which overlooks potential inter-node information. This variant discards the consideration of node homogeneity and relies solely on the embedding learned through HSAA outlined in Section 3.5 as the final network representation.
4.6. Analysis Experiment
- (1)
- Do the composite metapaths learned by the CMAE module enable automatic semantic mining? We recorded the fusion weights of different relations in the CMAE module. We multiply the weights of different unipath relations with the hierarchical attention, set them to the weights of different sub-metapath relations, and select the paths with the top three weights. As can be seen from Table 6, our approach not only learns the commonly used metapaths in various domains, which are often used as a priori information for metapath-based models (e.g., HAN), but also further mines metapaths containing rich information to enhance the representation of nodes. For instance, the ‘APAPA’ metapath in DBLP, which represents two authors who have collaborated with the same author on different papers, can be mined for higher-order collaborations. Authors involved in such higher-order collaborations are more likely to be part of the same research field, significantly enhancing the performance of node classification and clustering.Overall, the CMAE module is able to extract sub-metapaths containing different semantic information, and can autonomously regulate their weights to enhance semantic information aggregation. Meanwhile, the experimental results in Section 4.5 show that the automatic discovery of composite metapaths is more conducive to embedding performance than defining metapaths manually.
- (2)
- Does our proposed HSAA module effectively distinguish the semantic features of different hopping neighbors? To confirm the efficacy of integrating the information from nodes within the composite metapath, we conducted experiments on the relation between the attention weights of the neighbor information of different layers and the clustering performance of the corresponding layers. Figure 6 illustrates the attention weights for single-layer information alongside the clustering performance of the respective layer. Due to space limitations, we display results only for the ACM and IMDB datasets; however, the DBLP dataset exhibits an identical trend. There is a conspicuous positive correlation between the attention weights and clustering performance. This demonstrates that the model effectively prioritizes the neighborhood information of critical layers, substantially enhancing the overall performance and confirming the efficacy of the HSAA module introduced in Section 3.5. On the other hand, the intermediate layer node information also has higher attention and contribution to the model performance, proving the importance of the metapath internal node information. It is in line with the initial hypothesis that the metapath internal node information can help to accurately mine the complex relationship between the start and destination nodes and improve the model performance.
- (3)
- Does our proposed ANHNE model effectively enhance the distinction among network representations? We carried out visualization experiments to evaluate the quality of these representations, a standard method for assessing network representation tasks. Employing T-SNE, we compressed the node feature embeddings into a two-dimensional space to benchmark our model against leading techniques in the field. Figure 7 illustrates the distribution of nodes for various models on the DBLP dataset, where different colors denote different node types. In conjunction with the findings presented in Section 4.4, we contend that the low-dimensional feature space distributions generated by all approaches accurately demonstrate the relationships with node classes. Obviously, the homogeneous model GCN has the worst performance, where different types of nodes are mixed together and clusters of nodes do not form clear boundaries. HAN improves on it to a certain extent, but the improvement is not obvious; although the red clusters are clearly separated, the yellow clusters of nodes are collocated with the green and purple clusters of nodes and do not form clear boundaries. In comparison, the performance of AMOGCN is significantly improved, with the node clusters of all four colors forming their own compact regions; however, unfortunately, it has various types of nodes intertwined in the middle region. Compared with the baseline model, our model more effectively compacts the spatial distribution of nodes with identical labels and minimizes the cross-over between nodes of different categories, resulting in a more distinct boundary. This indicates that our model excels in differentiating between various node types, possesses enhanced generalization capabilities, and offers robust support for downstream tasks.
4.7. Hyperparameter Study
4.8. Convergence Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, D.; Yin, J.; Zhu, X.; Zhang, C. Network representation learning: A survey. IEEE Trans. Big Data 2018, 6, 3–28. [Google Scholar] [CrossRef]
- Taskar, B.; Wong, M.F.; Abbeel, P.; Koller, D. Link prediction in relational data. Adv. Neural Inf. Process. Syst. 2003, 16, 1–8. [Google Scholar]
- Bhagat, S.; Cormode, G.; Muthukrishnan, S. Node Classification in Social Networks; Springer: Berlin/Heidelberg, Germany, 2011; pp. 115–148. [Google Scholar]
- Fan, W.; Ma, Y.; Li, Q.; He, Y.; Zhao, E.; Tang, J.; Yin, D. Graph neural networks for social recommendation. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 417–426. [Google Scholar]
- Qiu, J.; Tang, J.; Ma, H.; Dong, Y.; Wang, K.; Tang, J. Deepinf: Social influence prediction with deep learning. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 2110–2119. [Google Scholar]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. Deepwalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 701–710. [Google Scholar]
- Tang, J.; Qu, M.; Wang, M.; Zhang, M.; Yan, J.; Mei, Q. Line: Large-scale information network embedding. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 1067–1077. [Google Scholar]
- Grover, A.; Leskovec, J. node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery And Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 855–864. [Google Scholar]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. In Proceedings of the NIPS’17: Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional neural networks on graphs with fast localized spectral filtering. arXiv 2016, arXiv:1606.09375. [Google Scholar]
- Atwood, J.; Towsley, D. Diffusion-convolutional neural networks. arXiv 2016, arXiv:1511.02136. [Google Scholar]
- Chen, Y.; Chen, F.; Wu, Z.; Chen, Z.; Cai, Z.; Tan, Y.; Wang, S. Heterogeneous Graph Embedding with Dual Edge Differentiation. Neural Netw. 2025, 183, 106965. [Google Scholar] [CrossRef]
- Chen, Y.; Song, A.; Yin, H.; Zhong, S.; Chen, F.; Xu, Q.; Wang, S.; Xu, M. Multi-view incremental learning with structured hebbian plasticity for enhanced fusion efficiency. In Proceedings of the AAAI Conference on Artificial Intelligence, Philadelphia, PA, USA, 25 February–4 March 2025; Volume 39, pp. 1265–1273. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. In Proceedings of the ICLR 2018 Conference Track 6th International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Wang, X.; Ji, H.; Shi, C.; Wang, B.; Ye, Y.; Cui, P.; Yu, P.S. Heterogeneous graph attention network. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 2022–2032. [Google Scholar]
- Park, C.; Han, J.; Yu, H. Deep multiplex graph infomax: Attentive multiplex network embedding using global information. Knowl.-Based Syst. 2020, 197, 105861. [Google Scholar] [CrossRef]
- Jing, B.; Park, C.; Tong, H. Hdmi: High-order deep multiplex infomax. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 2414–2424. [Google Scholar]
- Zhao, M.; Yu, J.; Zhang, S.; Jia, A.L. Relation-aware multiplex heterogeneous graph neural network. Knowl.-Based Syst. 2025, 309, 112806. [Google Scholar] [CrossRef]
- Su, H.; Li, Q.; Gong, Y.; Liu, Y.; Jiang, X. Attribute Disturbance for Attributed Multiplex Heterogeneous Network Embedding. In Proceedings of the 2024 5th International Conference on Big Data & Artificial Intelligence & Software Engineering (ICBASE), Wenzhou, China, 20–22 September 2024; pp. 455–462. [Google Scholar]
- Ding, L.; Li, M.; Wang, Y.; Shi, P.; Zhang, F. AMIRLe: Attribute-enhanced multi-interaction representation learning fore-commerce heterogeneous information networks. Int. J. Mach. Learn. Cybern. 2024, preprint. [Google Scholar] [CrossRef]
- Cen, Y.; Zou, X.; Zhang, J.; Yang, H.; Zhou, J.; Tang, J. Representation learning for attributed multiplex heterogeneous network. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 1358–1368. [Google Scholar]
- Yun, S.; Jeong, M.; Kim, R.; Kang, J.; Kim, H.J. Graph transformer networks. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Yu, P.; Fu, C.; Yu, Y.; Huang, C.; Zhao, Z.; Dong, J. Multiplex heterogeneous graph convolutional network. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 14–18 August 2022; pp. 2377–2387. [Google Scholar]
- Dong, Y.; Chawla, N.V.; Swami, A. metapath2vec: Scalable representation learning for heterogeneous networks. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 135–144. [Google Scholar]
- Hu, Z.; Dong, Y.; Wang, K.; Sun, Y. Heterogeneous graph transformer. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 2704–2710. [Google Scholar]
- Jin, B.; Gao, C.; He, X.; Jin, D.; Li, Y. Multi-behavior recommendation with graph convolutional networks. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, 25–30 July 2020; pp. 659–668. [Google Scholar]
- Qin, X.; Sheikh, N.; Reinwald, B.; Wu, L. Relation-aware graph attention model with adaptive self-adversarial training. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 9368–9376. [Google Scholar]
- Etta, G.; Cinelli, M.; Galeazzi, A.; Valensise, C.M.; Quattrociocchi, W.; Conti, M. Comparing the impact of social media regulations on news consumption. IEEE Trans. Comput. Soc. Syst. 2022, 10, 1252–1262. [Google Scholar] [CrossRef]
- Ren, Y.; Liu, B.; Huang, C.; Dai, P.; Bo, L.; Zhang, J. Heterogeneous deep graph infomax. arXiv 2019, arXiv:1911.08538. [Google Scholar]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Philip, S.Y. A comprehensive survey on graph neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4–24. [Google Scholar] [CrossRef]
- Manchanda, S.; Zheng, D.; Karypis, G. Schema-aware deep graph convolutional networks for heterogeneous graphs. In Proceedings of the 2021 IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 15–18 December 2021; pp. 480–489. [Google Scholar]
- Wang, X.; Zhu, M.; Bo, D.; Cui, P.; Shi, C.; Pei, J. Am-gcn: Adaptive multi-channel graph convolutional networks. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual, 6–10 July 2020; pp. 1243–1253. [Google Scholar]
- Min, Y.; Wenkel, F.; Wolf, G. Scattering gcn: Overcoming oversmoothness in graph convolutional networks. Adv. Neural. Inf. Process. Syst. 2020, 33, 14498–14508. [Google Scholar] [PubMed]
- Huang, W.; Hao, F.; Shang, J.; Yu, W.; Zeng, S.; Bisogni, C.; Loia, V. Dual-LightGCN: Dual light graph convolutional network for discriminative recommendation. Comput. Commun. 2023, 204, 89–100. [Google Scholar] [CrossRef]
- Feng, F.; He, X.; Zhang, H.; Chua, T.S. Cross-GCN: Enhancing Graph Convolutional Network with k-Order Feature Interactions. IEEE Trans. Knowl. Data Eng. 2021, 35, 225–236. [Google Scholar] [CrossRef]
- Wu, F.; Souza, A.; Zhang, T.; Fifty, C.; Yu, T.; Weinberger, K. Simplifying graph convolutional networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6861–6871. [Google Scholar]
- Zhang, X.; Liu, H.; Li, Q.; Wu, X.M. Attributed graph clustering via adaptive graph convolution. arXiv 2019, arXiv:1906.01210. [Google Scholar]
- Wang, X.; Liu, N.; Han, H.; Shi, C. Self-supervised Heterogeneous Graph Neural Network with Co-contrastive Learning. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, New York, NY, USA, 14–18 August 2021; pp. 1726–1736. [Google Scholar] [CrossRef]
- Park, C.; Kim, D.; Han, J.; Yu, H. Unsupervised attributed multiplex network embedding. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 5371–5378. [Google Scholar]
- Fang, Y.; Zhao, X.; Chen, Y.; Xiao, W.; de Rijke, M. PF-HIN: Pre-Training for Heterogeneous Information Networks. IEEE Trans. Knowl. Data Eng. 2022, 35, 8372–8385. [Google Scholar]
- Yuan, R.; Wu, Y.; Tang, Y.; Wang, J.; Zhang, W. Meta-path infomax joint structure enhancement for multiplex network representation learning. Knowl.-Based Syst. 2023, 275, 110701. [Google Scholar] [CrossRef]
- Shi, C.; Hu, B.; Zhao, W.X.; Philip, S.Y. Heterogeneous information network embedding for recommendation. IEEE Trans. Knowl. Data Eng. 2018, 31, 357–370. [Google Scholar] [CrossRef]
- Mei, G.; Pan, L.; Liu, S. Heterogeneous graph embedding by aggregating meta-path and meta-structure through attention mechanism. Neurocomputing 2022, 468, 276–285. [Google Scholar] [CrossRef]
- Chen, Z.; Wu, Z.; Zhong, L.; Plant, C.; Wang, S.; Guo, W. Attributed Multi-order Graph Convolutional Network for Heterogeneous Graphs. Neural Netw. 2024, 174, 106225. [Google Scholar] [CrossRef]
- Xue, H.; Sun, X.K.; Sun, W.X. Multi-hop hierarchical graph neural networks. In Proceedings of the 2020 IEEE International Conference on Big Data and Smart Computing (BigComp), Busan, Republic of Korea, 19–22 February 2020; pp. 82–89. [Google Scholar]
- Sun, Y.; Zhu, D.; Du, H.; Tian, Z. MHNF: Multi-hop heterogeneous neighborhood information fusion graph representation learning. IEEE Trans. Knowl. Data Eng. 2022, 35, 7192–7205. [Google Scholar] [CrossRef]
- Zhu, Y.; Xu, W.; Zhang, J.; Du, Y.; Zhang, J.; Liu, Q.; Yang, C.; Wu, S. A survey on graph structure learning: Progress and opportunities. arXiv 2021, arXiv:2103.03036. [Google Scholar]
- Fu, X.; Zhang, J.; Meng, Z.; King, I. Magnn: Metapath aggregated graph neural network for heterogeneous graph embedding. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 2331–2341. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notations | Explanations |
|---|---|
| The identity matrix. | |
| The activation function. | |
| The type of node i. | |
| The r-th node relation. | |
| The initial feature matrix of the node of type . | |
| The projected node feature of type . | |
| The adjacency matrix under the relation . | |
| The adjacency matrix of the l-layer composite metapath. | |
| The feature mapping matrix for the type . | |
| The trainable weight matrix of l-layer GCN. | |
| The weight of relation i in the composite metapath. | |
| The composite metapath-based hierarchical attention weight for l-layer neighbors. | |
| The learning parameter to modulate the contribution of auxiliary information. | |
| The latent graph structure adjacency matrix. | |
| The ndoe embedding of composite metapath based l-layer neighbors. | |
| The node embedding of multi-layer neighbors. | |
| The latent graph structure node embedding. | |
| The final node embedding. | |
| Ground truth. |
| Datasets | Num.Nodes | Attributes | Node Types | Classes | Train/Val/Test |
|---|---|---|---|---|---|
| ACM | Paper(3025) | 1870 | Paper(P)/Author(A)/Subject(S) | 3 | 600/300/2125 |
| DBLP | Paper(4057) | 334 | Paper(P)/Author(A)/Conference(C)/Term(T) | 4 | 800/400/2857 |
| IMDB | Movie(3550) | 1232 | Movie(M)/Actor(A)/Director(D)/Year(Y) | 3 | 600/300/2660 |
| Methods | Attri. | Hetero. | Learnable. | Multi-Order. |
|---|---|---|---|---|
| GCN | ✓ | × | × | × |
| GAT | ✓ | × | × | × |
| HAN | ✓ | ✓ | × | × |
| MAGNN | ✓ | ✓ | × | × |
| GTN | ✓ | ✓ | × | × |
| MHGCN | ✓ | ✓ | ✓ | ✓ |
| AMOGCN | ✓ | ✓ | ✓ | ✓ |
| ANHNE | ✓ | ✓ | ✓ | ✓ |
| Datasets | Metrics | Training | GCN | GAT | HAN | MAGNN | GTN | MHGCN | AMOGCN | ANHNE |
|---|---|---|---|---|---|---|---|---|---|---|
| ACM | Macro-F1 | 20% | 86.92 | 87.87 | 87.94 | 90.79 | 92.57 | 92.64 | 92.18 | 93.78 |
| 40% | 87.73 | 88.44 | 88.68 | 90.96 | 92.53 | 92.56 | 92.37 | 94.01 | ||
| 60% | 87.86 | 89.25 | 89.15 | 91.03 | 92.84 | 93.28 | 92.28 | 94.11 | ||
| 80% | 88.08 | 89.55 | 89.80 | 91.08 | 92.65 | 92.69 | 92.30 | 94.02 | ||
| Micro-F1 | 20% | 86.72 | 87.69 | 87.67 | 90.63 | 92.44 | 92.56 | 92.07 | 93.71 | |
| 40% | 87.55 | 88.28 | 88.42 | 90.78 | 92.55 | 92.61 | 92.40 | 94.04 | ||
| 60% | 87.69 | 89.12 | 88.92 | 90.86 | 92.56 | 93.38 | 92.38 | 94.05 | ||
| 80% | 87.94 | 89.43 | 89.60 | 90.89 | 92.91 | 92.72 | 92.38 | 94.04 | ||
| DBLP | Macro-F1 | 20% | 90.96 | 90.05 | 91.66 | 92.02 | 90.46 | 91.99 | 92.31 | 93.33 |
| 40% | 91.37 | 91.20 | 91.88 | 92.17 | 90.69 | 92.23 | 92.91 | 93.80 | ||
| 60% | 91.61 | 91.35 | 92.09 | 92.20 | 90.99 | 92.65 | 92.90 | 93.86 | ||
| 80% | 91.86 | 91.44 | 92.10 | 92.17 | 90.93 | 93.11 | 93.42 | 93.97 | ||
| Micro-F1 | 20% | 91.84 | 91.70 | 92.61 | 92.92 | 91.08 | 92.48 | 93.10 | 93.60 | |
| 40% | 92.18 | 92.15 | 92.78 | 93.06 | 91.28 | 92.73 | 93.34 | 94.09 | ||
| 60% | 92.43 | 92.31 | 93.00 | 93.10 | 91.56 | 93.10 | 93.11 | 94.33 | ||
| 80% | 92.66 | 92.37 | 93.07 | 93.06 | 91.49 | 93.33 | 93.58 | 94.07 | ||
| IMDB | Macro-F1 | 20% | 45.73 | 49.44 | 50.00 | 51.98 | 51.13 | 52.17 | 51.07 | 53.43 |
| 40% | 48.01 | 50.64 | 52.71 | 52.55 | 52.07 | 53.64 | 52.65 | 57.67 | ||
| 60% | 49.15 | 51.90 | 54.24 | 54.11 | 54.29 | 54.84 | 53.62 | 57.32 | ||
| 80% | 51.81 | 52.99 | 54.38 | 54.59 | 54.68 | 53.86 | 52.99 | 57.49 | ||
| Micro-F1 | 20% | 49.78 | 55.28 | 59.16 | 60.77 | 60.10 | 62.81 | 63.07 | 63.18 | |
| 40% | 51.71 | 55.91 | 60.83 | 61.37 | 60.32 | 65.06 | 64.64 | 65.48 | ||
| 60% | 52.29 | 56.44 | 62.35 | 61.77 | 60.33 | 66.12 | 66.65 | 66.74 | ||
| 80% | 54.16 | 56.97 | 63.44 | 62.76 | 60.33 | 66.95 | 66.11 | 67.36 |
| Datasets | Metrics | GCN | GAT | HAN | MAGNN | GTN | MHGCN | AMOGCN | ANHNE |
|---|---|---|---|---|---|---|---|---|---|
| ACM | NMI | 58.78 | 63.19 | 66.49 | 72.03 | 74.92 | 75.83 | 72.54 | 78.09 |
| ARI | 62.65 | 67.75 | 70.56 | 76.56 | 79.80 | 81.59 | 78.88 | 83.05 | |
| DBLP | NMI | 71.55 | 74.22 | 75.49 | 77.01 | 77.27 | 79.30 | 79.88 | 81.25 |
| ARI | 76.31 | 79.43 | 81.32 | 81.39 | 82.10 | 83.42 | 83.91 | 85.01 | |
| IMDB | NMI | 9.59 | 10.02 | 13.08 | 15.59 | 17.69 | 16.83 | 17.09 | 17.92 |
| ARI | 6.59 | 8.69 | 10.94 | 13.36 | 18.68 | 23.67 | 22.69 | 25.29 |
| Datasets | Common Metapath | Learned Metapath |
|---|---|---|
| ACM | PSP, PAP | PAP, APA, PSP |
| DBLP | APA, APAPA | APA, APAPA, APCPA |
| IMDB | MDM, MAM | MAM, AMA, MDM |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, H.; Shao, H.; Wang, L.; Song, C. ANHNE: Adaptive Multi-Hop Neighborhood Information Fusion for Heterogeneous Network Embedding. Electronics 2025, 14, 2911. https://doi.org/10.3390/electronics14142911
Xie H, Shao H, Wang L, Song C. ANHNE: Adaptive Multi-Hop Neighborhood Information Fusion for Heterogeneous Network Embedding. Electronics. 2025; 14(14):2911. https://doi.org/10.3390/electronics14142911
Chicago/Turabian StyleXie, Hanyu, Hao Shao, Lunwen Wang, and Changjian Song. 2025. "ANHNE: Adaptive Multi-Hop Neighborhood Information Fusion for Heterogeneous Network Embedding" Electronics 14, no. 14: 2911. https://doi.org/10.3390/electronics14142911
APA StyleXie, H., Shao, H., Wang, L., & Song, C. (2025). ANHNE: Adaptive Multi-Hop Neighborhood Information Fusion for Heterogeneous Network Embedding. Electronics, 14(14), 2911. https://doi.org/10.3390/electronics14142911