

An Optimized Semantic Matching Method and RAG Testing Framework for Regulatory Texts


Abstract
1. Introduction
- The knowledge base construction process is complex. Professional texts such as financial regulations [7] exhibit high clause interconnectivity and logical rigor. Conventional text segmentation methods [8] tend to fracture critical contextual relationships, resulting in fragmented retrieval outcomes. Concurrently, the high-frequency update characteristic of regulatory provisions requires the knowledge base to support real-time updates and version control capabilities. Recent improvements in knowledge base construction are primarily achieved through two approaches: structured data storage [4,9] and verification of clause-level logical consistency. Common knowledge processing methods include, but are not limited to, text chunking, information extraction [10,11,12], knowledge graphs [13], and Knowledge-Augmented Generation (KAG). Optimization methods for knowledge base construction have also been devised. For instance, dynamic semantic segmentation (such as dependency parsing in the txtai library [14]) has been adopted to address the strong logical coherence of regulatory provisions. This approach has progressively replaced fixed-length text chunking [15] with dynamic semantic segmentation techniques. This method applies dynamic segmentation to knowledge base texts, where clause boundaries are identified through dependency parsing using frameworks such as SpaCy 3.0.0, as proposed by Kumar et al. [16,17]. This ensures logical units maintain integrity as discrete chunks during storage. Regarding knowledge structure construction, multi-hop clause citation networks are developed by integrating information extraction with knowledge graphs [18]. Zuo et al. [19] demonstrated this approach by constructing datasets using the Scrapy framework and storing knowledge graphs in Neo4j, thereby establishing traceable knowledge-augmented structures [20]. Liang et al. [21] proposed KAG, which enhances the synergy between knowledge representation and retrieval through a logic-guided hybrid reasoning engine. Concurrently, Jiang et al. [22] introduced knowledge-augmented dialog generation, which employs a divergent knowledge selector to pre-optimize candidate knowledge and a knowledge-aware decoder to generate contextually coherent, knowledge-rich responses. To ensure the timeliness of regulatory knowledge bases, researchers have introduced a version control mechanism. This approach utilizes twin networks (e.g., MERIT) where the target network caches historical clause representations, achieving smooth version transitions through momentum updates [23] while preventing the inclusion of repealed provisions in the knowledge base. Under this mechanism, outdated provisions are tagged as “abrogated” and replaced by updated versions, enabling automated identification of content modifications during regulatory revisions [24,25].
- Semantic retrieval accuracy in general-domain technical solutions is constrained. General-domain embedding models [26] exhibit limited representational capacity for vectorizing domain-specific terminology. The implicit logical complexity of regulatory provisions poses significant challenges for both high-dimensional sparse vector representations [27] and traditional cosine similarity algorithms [28,29], leading to critical omissions during regulatory queries and potentially invalidating analytical outcomes. Current research primarily concentrates on domain-adapted embedding models and improvements in retrieval accuracy [30]. General-domain embedding models exhibit constrained representational capacity for relevant terminology, resulting in insufficient retrieval accuracy. Additionally, different embedding models demonstrate varied capacities for representing domain-specific terms [31], which necessitates comparative testing of domain-adapted models [32] (e.g., bge-m3, mxbai-embed-large) to improve matching precision and enhance comprehension of context-specific semantics. Furthermore, Weller et al. [5,33,34,35,36] proposed a reranking model that enables multi-level semantic reranking, thereby improving the precision of retrieved passages. Simultaneously, Bai et al. [37] developed a multi-hop reasoning approach incorporating relative temporal encoding to enhance path retrieval capability for complex regulatory logic.
- Stringent demands are imposed on response generation control. The generation phase must strictly adhere to inter-provision citation logic, and outputs must be traceable and interpretable to ensure credibility. Regarding generation control, current research efforts are focused on domain-constrained generation [38] and interpretability enhancement [39]. Prompt engineering optimization techniques, exemplified by the Collaborative Legal Expert Framework [40,41], ensure that generated content complies with regulatory formatting and citation logic through intent identification and legal foundation tracing. Additionally, a multi-tier posterior verification mechanism has been introduced [42] to validate provision validity through knowledge graph backtracking. This is further integrated with reasoning path visualization tools, such as ReasonGraph developed by Li et al. [43], which generated reasoning graphs that visualize the full trace: “problem keywords” → “retrieved provisions” → “generation basis”, thereby significantly enhancing the traceability of generated results [44] while markedly improving their credibility and auditability.
- An open-source regulatory RAG testing framework has been constructed. Multiple embedding models are deployed to preprocess knowledge fragments, with similarity computation strategies configured to facilitate test in regulatory text semantic matching.
- A semantic matching optimization method based on dimensionality reduction has been proposed. Within the RAG testing framework, semantic matching accuracy for regulatory texts has been enhanced through denoising high-dimensional sparse vectors.
- Developed a retrieval optimization method based on information reasoning. By inferring potential questions, this approach enhances the accuracy of knowledge fragment matching.
- The applicability of different knowledge base processing methods and retrieval strategies for regulatory question-answering tasks has been validated using real-world regulatory datasets.
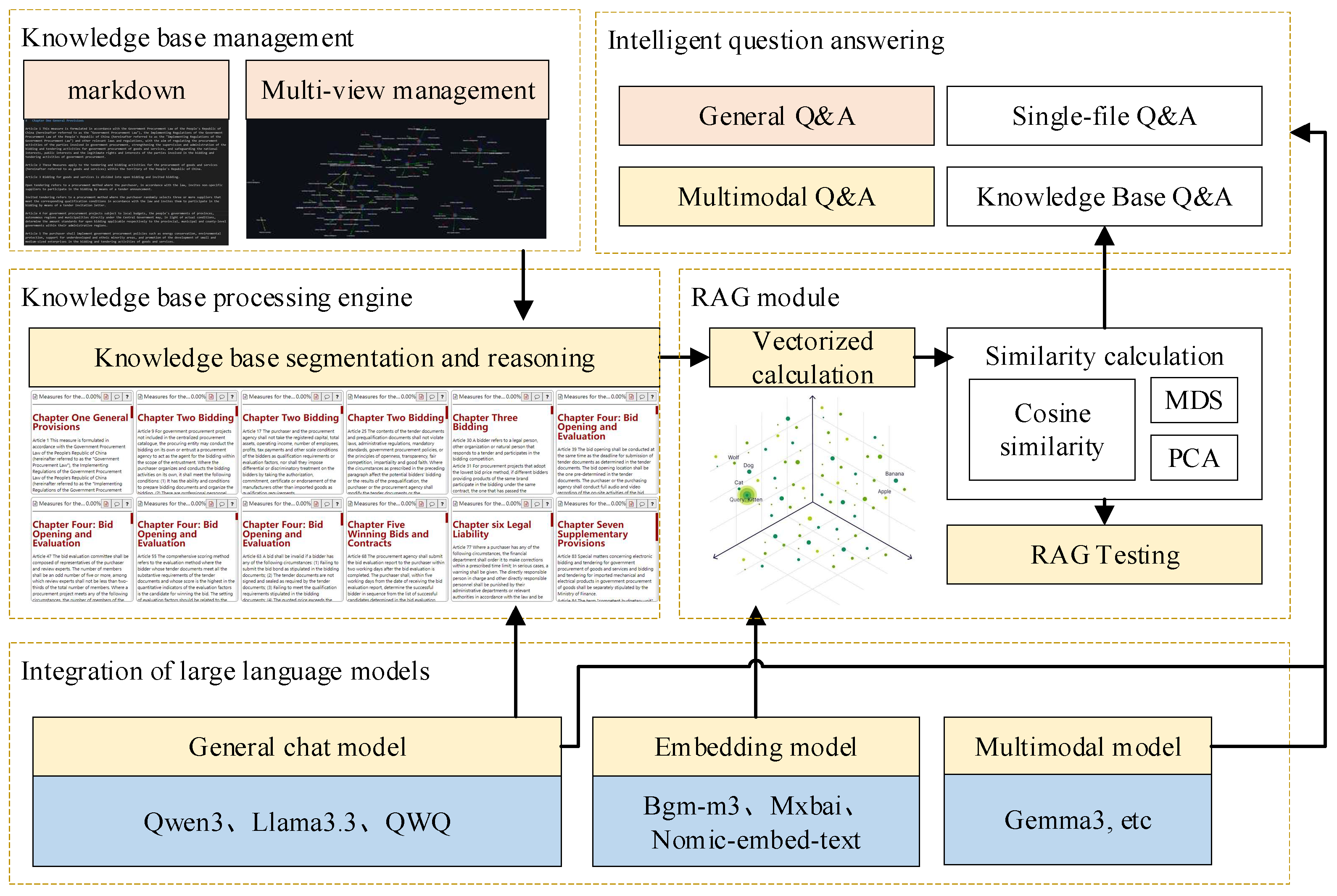
2. RAG Testing Framework Design
- LLM Deployment. The software implements localized deployment and invocation of latest LLM through the Ollama 0.9.5 platform, with support extended to general-purpose language models (e.g., Deepseek-R1, LLaMA3.3), embedding models including bge-m3 and nomic-embed-text, and multimodal models such as Gemma3. This architecture enables rapid integration of newly released LLM products while reducing access barriers via standardized deployment interfaces, ensuring operational simplicity and flexibility in model deployment.
- Knowledge Base Management. The software converts structured text into multiple interactive interfaces such as tree diagrams, tag-based classification views, knowledge graphs, and mind maps by parsing Markdown documents. Efficient browsing, editing, and maintenance of the knowledge base are enabled through these views. Additionally, the knowledge base can be subjected to various preprocessing operations, including intelligent segmentation of Markdown documents, vectorization using custom embedding models, and semantic enhancement through information reasoning.
- RAG Module. The integration of embedding models with similarity computation enables high-precision knowledge retrieval, while domain-specific answers are generated by LLM based on the knowledge base. Fundamental matching between queries and knowledge fragments is implemented through cosine similarity, with semantic information reasoning being further enhanced through latent semantic information extraction. For a given knowledge segment, the software can automatically infer relevant information or expand contextual meaning through manual annotation, followed by similarity computation that combines original text with information reasoning. Additionally, the integrated MDS-based semantic similarity measurement method enhances semantic matching capability by eliminating interference from irrelevant semantic dimensions.
- Evaluation and Debugging Module. The software implements visual debugging, supporting the graphical display of both cosine similarity computation results and Dimensionality reduction results. Configuration of slicing strategies, switching between embedding models, comparison of similarity algorithms and hidden information editing capabilities are enabled to establish a debugging workflow covering parameter configuration, experiment execution, result visualization, and performance comparison, providing intuitive support for technical optimization decisions.
- The directory containing the target knowledge base is selected. The knowledge base primarily consists of files in Markdown format. Documents in other formats, such as PDF, can be converted using open-source tools such as MinerU 0.4.1.0. Manual verification and editing of Markdown files may be conducted to improve textual accuracy and consistency.
- The knowledge base is segmented using predefined delimiters, such as consecutive line breaks. If the segmentation results are determined to be suboptimal, manual refinement of the Markdown structure can be applied to enhance the segmentation quality.
- Vectors corresponding to each segmented knowledge fragment are computed using the specified embedding model and stored in the database.
- For each knowledge fragment, implicit semantic information is extracted using the configured large language model. By default, this process involves prompt-based question generation to derive potential questions associated with the corresponding content. Alternatively, customized prompt instructions can be applied to elicit semantically enriched outputs. The extracted information may also be manually refined to enhance the semantic granularity of key content. (This step is optional and may be selectively executed depending on task requirements.)
- Vectors are computed for both the original knowledge fragments and the associated implicit information using the designated embedding model, and subsequently stored in the database.
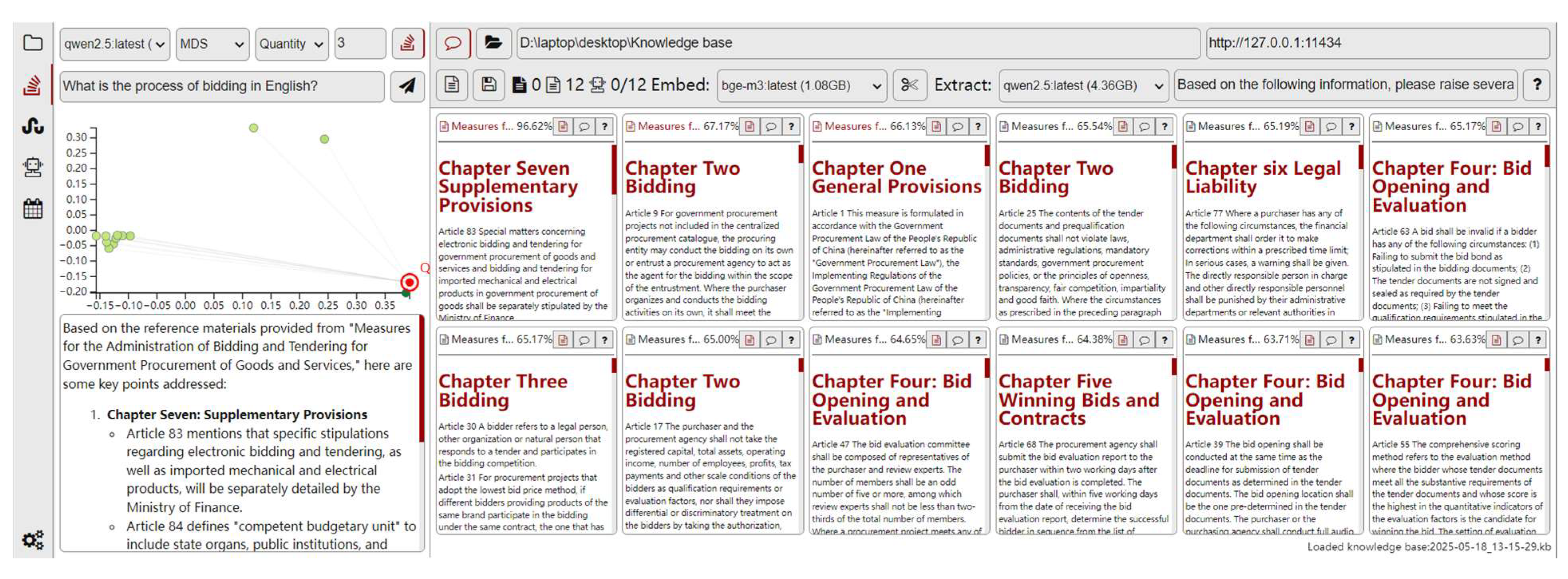
- For user-submitted queries, similarity computations are performed using either cosine similarity or dimensionality reduction based on MDS. Vectors corresponding to the original knowledge fragments, implicit information, and queries are calculated and ranked in descending order according to similarity scores.
- Relevant knowledge fragments are retrieved according to one of three predefined recall strategies: similarity-based recall, top-k recall, or length-constrained recall. Prompt templates are constructed accordingly, and each knowledge fragment is annotated with metadata such as regulatory source and temporal information to improve interpretability and ensure that updated regulations maintain backward traceability.
- The finalized prompts are processed by the LLM to generate responses aligned with the regulatory knowledge base, thereby enhancing domain relevance and answer precision.
3. Embedding Models Testing
- The knowledge base incorporates regulations such as the “Government Procurement Goods and Services Bidding Management Measures” for preliminary testing of LLM and embedding model performance. Multiple embedding models are selected for comparative evaluation.
- The test question dataset comprised 50 financial regulation domain questions. This dataset is generated using DeepSeek-V3-0324 based on the knowledge base, followed by manual verification.
- The selected embedding models are listed in Table 1. These models are evaluated using a streamlined regulatory corpus to assess their performance.
- Cosine similarity is employed to calculate the similarity between user-submitted questions and knowledge base segments. The matching accuracy of embedding models is evaluated by setting recall thresholds. A question is considered correctly answered if its corresponding knowledge segment is matched under the specified recall threshold, with accuracy rates are calculated accordingly.
- The framework implemented three distinct retrieval strategies: (1) similarity-based retrieval, where knowledge segments are recalled when their similarity scores exceed a predetermined threshold; (2) Top-k retrieval, which selects a fixed number of top-ranked knowledge segments sorted by descending similarity; and (3) length-constrained retrieval, where segments are similarly ranked by similarity but are dynamically aggregated through prompt engineering until reaching a predefined character count limit.
4. Semantic Matching Optimization Methodology
4.1. Cosine Similarity
4.2. MDS
- During the knowledge base processing phase, structured Markdown documents are utilized as the primary data source. These documents are segmented into text fragments based on predefined rules, such as paragraph boundaries, section headings, or fixed-length chunking. Each text fragment is then transformed into a high-dimensional vector using designated embedding models (for example, mxbai-embed-large or bge-m3), which are designed to capture deep semantic features. The resulting vectors are stored in a vector database along with their corresponding text fragments to support efficient similarity-based retrieval. To preprocess n vectors of dimension m, a cosine distance matrix is computed, where each element is given by the following:
- The classical MDS method is then applied for dimensionality reduction. A centering matrix is constructed as follows:and used to double centering the squared distance matrix , yielding the inner product matrix:This transformation ensures that both the row and column sums of the matrix are zero, which eliminates dependence on the coordinate origin and facilitates subsequent eigen decomposition. In this context, denotes the identity matrix of dimension ; is a column vector of ones with dimension ; is an matrix with all entries equal to one; and represents the element-wise squared distance matrix. Matrix is then subjected to eigendecomposition:where is the diagonal matrix of eigenvalues. The eigenvectors associated with the two largest eigenvalues (ranked in descending order) are selected to construct the projection matrix. The low-dimensional coordinate of each data point is obtained from the corresponding row of the projection matrix. This approach is justified by the fact that eigenvalues quantify the variance explained along each dimension. Larger eigenvalues correspond to directions with greater variance (thus carrying more significant semantic information), while smaller eigenvalues correspond to less informative directions, which can be interpreted as semantic noise. Selecting only the top eigenvectors enables preservation of the most meaningful geometric relationships while suppressing irrelevant components.
- The semantic similarity between texts can be obtained by calculating the Euclidean distances between different coordinate points. Following the same methodology, the embedding vector corresponding to the user’s query (denoted as undergoes centralization and projection transformation to be mapped into the low-dimensional space as . This process effectively preserves the original spatial distance relationships in the reduced-dimensional space. Finally, the semantic similarity between the retrieved knowledge segments and the user’s query is determined through distance computation, with detailed operations specified in Formula (6).
4.3. Principal Component Analysis
- During the knowledge base processing phase, structured Markdown documents are segmented into text fragment collections according to predefined rules. Each text fragment is then transformed into a high-dimensional semantic vector using an embedding model.
- The computational procedure involves the following steps: first, compute the mean vector and perform centralization: , constructing the centralized matrix .
- Next, calculate the covariance matrix: . Subsequently, decompose the covariance matrix: where and is the eigenvector matrix. The target dimension is determined based on the cumulative explained variance ratio. Finally, generate the dimensionality reduction projection matrix by selecting the top k eigenvectors, and project into the lower-dimensional space: .
- For user query q, its embedding vector is similarly generated, and dimensionality reduction is applied: . In the low-dimensional space, retrieval is performed using cosine similarity: .
4.4. Experimental Analysis
5. Retrieval Method Based on Information Reasoning
- The mxbai embedding model is utilized, which demonstrates optimal performance for this domain according to the tests in Section 3.
- The Top-k recall strategy is implemented, and shows broader applicability based on the test results in Section 3.
- The financial regulation knowledge base and query dataset specifications are detailed in Table 3.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ji, S.; Liu, L.; Xi, J.; Zhang, X.; Li, X. KLR-KGC: Knowledge-Guided LLM Reasoning for Knowledge Graph Completion. Electronics 2024, 13, 5037. [Google Scholar] [CrossRef]
- Fan, W.; Ding, Y.; Ning, L.; Wang, S.; Li, H.; Yin, D.; Chua, T.-S.; Li, Q. A Survey on RAG Meeting LLMs: Towards Retrieval-Augmented Large Language Models. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Barcelona, Spain, 25–29 August 2024; pp. 6491–6501. [Google Scholar]
- He, Y.; Zhu, X.; Li, D.; Wang, H. Enhancing Large Language Models for Specialized Domains: A Two-Stage Framework with Parameter-Sensitive LoRA Fine-Tuning and Chain-of-Thought RAG. Electronics 2025, 14, 1961. [Google Scholar] [CrossRef]
- Yang, W.; Some, L.; Bain, M.; Kang, B. A comprehensive survey on integrating large language models with knowledge-based methods. Knowl.-Based Syst. 2025, 318, 113503. [Google Scholar] [CrossRef]
- Silva, L.; Barbosa, L. Improving dense retrieval models with LLM augmented data for dataset search. Knowl.-Based Syst. 2024, 294, 111740. [Google Scholar] [CrossRef]
- Ghali, M.-K.; Farrag, A.; Won, D.; Jin, Y. Enhancing knowledge retrieval with in-context learning and semantic search through generative AI. Knowl.-Based Syst. 2025, 311, 113047. [Google Scholar] [CrossRef]
- Araci, D. FinBERT: Financial Sentiment Analysis with Pre-trained Language Models. arXiv 2019, arXiv:1908.10063. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, W.; Liu, Z.; Lin, X. Keyword search on structured and semi-structured data. In Proceedings of the 2009 ACM SIGMOD International Conference on Management of Data, Providence, RI, USA, 29 June–2 July 2009; pp. 1005–1010. [Google Scholar]
- Chang, F.; Dean, J.; Ghemawat, S.; Hsieh, W.C.; Wallach, D.A.; Burrows, M.; Chandra, T.; Fikes, A.; Gruber, R.E. Bigtable: A Distributed Storage System for Structured Data. ACM Trans. Comput. Syst. 2008, 26, 4. [Google Scholar] [CrossRef]
- Grishman, R. Information Extraction. IEEE Intell. Syst. 2015, 30, 8–15. [Google Scholar] [CrossRef]
- Nasar, Z.; Jaffry, S.W.; Malik, M.K. Information extraction from scientific articles: A survey. Scientometrics 2018, 117, 1931–1990. [Google Scholar] [CrossRef]
- Singh, S. Natural Language Processing for Information Extraction. arXiv 2018, arXiv:1807.02383. [Google Scholar] [CrossRef]
- Ji, S.; Pan, S.; Cambria, E.; Marttinen, P.; Yu, P.S. A Survey on Knowledge Graphs: Representation, Acquisition, and Applications. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 494–514. [Google Scholar] [CrossRef] [PubMed]
- Bayer, O.; Ulu, E.N.; Sarkın, Y.; Sütçü, E.; Çelik, D.B.; Karamanlıoglu, A.; Karakaya, I.; Demirel, B. A REGNLP Framework: Developing Retrieval-Augmented Generation for Regulatory Document Analysis. In Proceedings of the 31st International Conference on Computational Linguistics (COLING 2025), Abu Dhabi, United Arab Emirates, 19–24 January 2025; 97p. [Google Scholar]
- Xia, W.; Zou, X.; Jiang, H.; Zhou, Y.; Liu, C.; Feng, D.; Hua, Y.; Hu, Y.; Zhang, Y. The Design of Fast Content-Defined Chunking for Data Deduplication Based Storage Systems. IEEE Trans. Parallel Distrib. Syst. 2020, 31, 2017–2031. [Google Scholar] [CrossRef]
- Jugran, S.; Kumar, A.; Tyagi, B.S.; Anand, V. Extractive Automatic Text Summarization using SpaCy in Python & NLP. In Proceedings of the 2021 International Conference on Advance Computing and Innovative Technologies in Engineering (ICACITE), Greater Noida, India, 4–5 March 2021; pp. 582–585. [Google Scholar]
- Kumar, M.; Chaturvedi, K.K.; Sharma, A.; Arora, A.; Farooqi, M.S.; Lal, S.B.; Lama, A.; Ranjan, R. An Algorithm for Automatic Text Annotation for Named Entity Recognition Using SpaCy Framework; Research Square: Durham, NC, USA, 2023. [Google Scholar] [CrossRef]
- Kau, A.; He, X.; Nambissan, A.; Astudillo, A.; Yin, H.; Aryani, A. Combining Knowledge Graphs and Large Language Models. arXiv 2024, arXiv:2407.06564. [Google Scholar] [CrossRef]
- Zuo, J.; Niu, J. Construction of Journal Knowledge Graph Based on Deep Learning and LLM. Electronics 2025, 14, 1728. [Google Scholar] [CrossRef]
- Gao, Y.; Xiong, Y.; Gao, X.; Jia, K.; Pan, J.; Bi, Y.; Dai, Y.; Sun, J.; Wang, H.; Wang, H. Retrieval-augmented generation for large language models: A survey. arXiv 2023, arXiv:2312.10997. [Google Scholar]
- Liang, L.; Bo, Z.; Gui, Z.; Zhu, Z.; Zhong, L.; Zhao, P.; Sun, M.; Zhang, Z.; Zhou, J.; Chen, W.; et al. KAG: Boosting LLMs in Professional Domains via Knowledge Augmented Generation. In Proceedings of the Companion Proceedings of the ACM on Web Conference 2025, Sydney, NSW, Australia, 28 April–2 May 2025; pp. 334–343. [Google Scholar]
- Jiang, B.; Yang, J.; Yang, C.; Zhou, W.; Pang, L.; Zhou, X. Knowledge Augmented Dialogue Generation with Divergent Facts Selection. Knowl.-Based Syst. 2020, 210, 106479. [Google Scholar] [CrossRef]
- Jin, M.; Zheng, Y.; Li, Y.-F.; Gong, C.; Zhou, C.; Pan, S. Multi-Scale Contrastive Siamese Networks for Self-Supervised Graph Representation Learning. arXiv 2021, arXiv:2105.05682. [Google Scholar] [CrossRef]
- Aumiller, D.; Almasian, S.; Lackner, S.; Gertz, M. Structural text segmentation of legal documents. In Proceedings of the Eighteenth International Conference on Artificial Intelligence and Law, São Paulo, Brazil, 21–25 June 2021; pp. 2–11. [Google Scholar]
- Balinsky, A.; Balinsky, H.; Simske, S. Rapid change detection and text mining. In Proceedings of the 2nd Conference on Mathematics in Defence (IMA), Defence Academy, Swindon, UK, 20 October 2011. [Google Scholar]
- Zhang, L.; Xiang, T.; Gong, S. Learning a Deep Embedding Model for Zero-Shot Learning. arXiv 2016, arXiv:1611.05088. [Google Scholar] [CrossRef]
- Peng, Q.; Cao, B.; Xie, X.; Ye, H.; Liu, J.; Li, Z. LLMSRec: Large language model with service network augmentation for web service recommendation. Knowl.-Based Syst. 2025, 323, 113710. [Google Scholar] [CrossRef]
- Li, B.; Han, L. Distance Weighted Cosine Similarity Measure for Text Classification. In Proceedings of the Intelligent Data Engineering and Automated Learning—IDEAL 2013, Hefei, China, 20–23 October 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 611–618. [Google Scholar]
- Xia, P.; Zhang, L.; Li, F. Learning similarity with cosine similarity ensemble. Inf. Sci. 2015, 307, 39–52. [Google Scholar] [CrossRef]
- Ma, L.; Zhou, Y.; Ma, Y.; Yu, G.; Li, Q.; He, Q.; Pei, Y. Defying Multi-model Forgetting in One-shot Neural Architecture Search Using Orthogonal Gradient Learning. IEEE Trans. Comput. 2025, 74, 1678–1689. [Google Scholar] [CrossRef]
- Nguyen, D.Q.; Sirts, K.; Qu, L.; Johnson, M. STransE: A novel embedding model of entities and relationships in knowledge bases. arXiv 2016, arXiv:1606.08140. [Google Scholar] [CrossRef]
- Kadhim, A.K.; Jiao, L.; Shafik, R.; Granmo, O.-C. Omni TM-AE: A Scalable and Interpretable Embedding Model Using the Full Tsetlin Machine State Space. arXiv 2025, arXiv:2505.16386. [Google Scholar] [CrossRef]
- Weller, O.; Ricci, K.; Yang, E.; Yates, A.; Lawrie, D.; Van Durme, B. Rank1: Test-Time Compute for Reranking in Information Retrieval. arXiv 2025, arXiv:2502.18418. [Google Scholar] [CrossRef]
- Liu, Q.; Wang, B.; Wang, N.; Mao, J. Leveraging Passage Embeddings for Efficient Listwise Reranking with Large Language Models. In Proceedings of the ACM on Web Conference 2025, Sydney, NSW, Australia, 28 April–2 May 2025; pp. 4274–4283. [Google Scholar]
- Tymoshenko, K.; Moschitti, A. Shallow and Deep Syntactic/Semantic Structures for Passage Reranking in Question-Answering Systems. ACM Trans. Inf. Syst. 2018, 37, 8. [Google Scholar] [CrossRef]
- Aktolga, E.; Allan, J.; Smith, D.A. Passage Reranking for Question Answering Using Syntactic Structures and Answer Types. In Advances in Information Retrieval, ECIR 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 617–628. [Google Scholar]
- Bai, L.; Xiao, Q.; Zhu, L. Multi-hop path reasoning of temporal knowledge graphs based on generative adversarial imitation learning. Knowl.-Based Syst. 2025, 316, 113421. [Google Scholar] [CrossRef]
- Feng, Y.; Li, C.; Ng, V. Legal Judgment Prediction via Event Extraction with Constraints. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022; pp. 648–664. [Google Scholar]
- Cao, X.; Liu, Y.; Sun, F. Predict, pretrained, select and answer: Interpretable and scalable complex question answering over knowledge bases. Knowl.-Based Syst. 2023, 278, 110820. [Google Scholar] [CrossRef]
- Li, B.; Fan, S.; Zhu, S.; Wen, L. CoLE: A collaborative legal expert prompting framework for large language models in law. Knowl.-Based Syst. 2025, 311, 113052. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, S.; Sun, J.; Du, Y.; Wen, Y.; Wang, X.; Pan, W. Cooperative Open-ended Learning Framework for Zero-Shot Coordination. In Proceedings of the 40th International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; Proceedings of Machine Learning Research. pp. 20470–20484. [Google Scholar]
- Guan, X.; Liu, Y.; Lin, H.; Lu, Y.; He, B.; Han, X.; Sun, L. Mitigating large language model hallucinations via autonomous knowledge graph-based retrofitting. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 26–27 February 2024; pp. 18126–18134. [Google Scholar]
- Li, Z.; Shareghi, E.; Collier, N. ReasonGraph: Visualisation of Reasoning Paths. arXiv 2025, arXiv:2503.03979. [Google Scholar] [CrossRef]
- Desnos, A. Android: Static analysis using similarity distance. In Proceedings of the 2012 45th Hawaii International Conference on System Sciences, Maui, HI, USA, 4–7 January 2012; pp. 5394–5403. [Google Scholar]
- Laiho, M.; Poikonen, J.H.; Kanerva, P.; Lehtonen, E. High-dimensional computing with sparse vectors. In Proceedings of the 2015 IEEE Biomedical Circuits and Systems Conference (BioCAS), Atlanta, GA, USA, 22–24 October 2015; pp. 1–4. [Google Scholar]
- Chen, J.; Yang, S.; Wang, Z.; Mao, H. Efficient Sparse Representation for Learning With High-Dimensional Data. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 4208–4222. [Google Scholar] [CrossRef]
- mxbai-embed-large-v1. Available online: https://gitcode.com/hf_mirrors/ai-gitcode/mxbai-embed-large-v1 (accessed on 28 May 2025).
- Chen, J.; Xiao, S.; Zhang, P.; Luo, K.; Lian, D.; Liu, Z. M3-Embedding: Multi-Linguality, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation. In Proceedings of the 62nd Annual Meeting of the Findings of the Association for Computational Linguistics: ACL 2024, Bangkok, Thailand, 11–16 August 2024; pp. 2318–2335. [Google Scholar]
- Yin, C.; Zhang, Z. A Study of Sentence Similarity Based on the All-minilm-l6-v2 Model with “Same Semantics, Different Structure” After Fine Tuning. In Proceedings of the 2024 2nd International Conference on Image, Algorithms and Artificial Intelligence (ICIAAI 2024), Singapore, 9–11 August 2024; pp. 677–684. [Google Scholar]
- Nussbaum, Z.; Morris, J.X.; Duderstadt, B.; Mulyar, A. Nomic Embed: Training a Reproducible Long Context Text Embedder. arXiv 2024, arXiv:2402.01613. [Google Scholar] [CrossRef]
- McInnes, L.; Healy, J.; Melville, J. UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction. arXiv 2018, arXiv:1802.03426. [Google Scholar] [CrossRef]
- Sainburg, T.; McInnes, L.; Gentner, T.Q. Parametric UMAP Embeddings for Representation and Semisupervised Learning. Neural Comput. 2021, 33, 2881–2907. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Huang, H.; Rudin, C.; Shaposhnik, Y. Understanding how dimension reduction tools work: An empirical approach to deciphering t-SNE, UMAP, TriMAP, and PaCMAP for data visualization. J. Mach. Learn. Res. 2021, 22, 1–73. [Google Scholar]
- Allaoui, M.; Kherfi, M.L.; Cheriet, A. Considerably Improving Clustering Algorithms Using UMAP Dimensionality Reduction Technique: A Comparative Study. In Image and Signal Processing; Springer: Cham, Switzerland, 2020; pp. 317–325. [Google Scholar]
- Arora, S.; Hu, W.; Kothari, P.K. An Analysis of the t-SNE Algorithm for Data Visualization. In Proceedings of the 31st Conference On Learning Theory, Stockholm, Sweden, 6–9 July 2018; Proceedings of Machine Learning Research. pp. 1455–1462. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Parameters | Default Dimensions | Context Length | Features |
|---|---|---|---|---|
| mxbai-embed-large | 335M | 1024 | 512 tokens | The model supports multilingual retrieval and is well-suited for short-text tasks, though its capability for processing long texts is relatively limited [47]. |
| Bge-m3 | 420M | 1024 | 8192 tokens | The model demonstrates strong capabilities in long-text processing and cross-lingual tasks, making it particularly suitable for knowledge base question-answering, though its larger model size results in higher resource consumption [48]. |
| ALL-MiniLM | 33M | 384 | 256 tokens | The model supports deployment on lightweight devices with primary English-language support, though it exhibits performance degradation on long-text processing [49]. |
| Nomic-embed-text | 137M | 768 | 8192 tokens | The model features transparent training data and processes, while demonstrating average performance on complex tasks [50]. |
| Recall Strategy | Embedded Model | Threshold | ||||
|---|---|---|---|---|---|---|
| 0.58 | 0.55 | 0.52 | 0.49 | 0.46 | ||
| Similarity-based recall | mxbai | 100.00% | 100.00% | 100.00% | 100.00% | 100.00% |
| bge-m3 | 18.00% | 20.00% | 24.00% | 30.00% | 46.00% | |
| all-minilm | 14.00% | 24.00% | 36.00% | 54.00% | 70.00% | |
| nomic | 58.00% | 70.00% | 84.00% | 98.00% | 100.00% | |
| 2 | 3 | 4 | 5 | 6 | ||
| Top-k recall | mxbai | 48.00% | 54.00% | 62.00% | 68.00% | 78.00% |
| bge-m3 | 24.00% | 40.00% | 54.00% | 62.00% | 72.00% | |
| all-minilm | 40.00% | 50.00% | 58.00% | 66.00% | 74.00% | |
| nomic | 36.00% | 44.00% | 52.00% | 62.00% | 74.00% | |
| 2500 | 3000 | 3500 | 4000 | 4500 | ||
| Length-constrained recall | mxbai | 38.00% | 42.00% | 48.00% | 50.00% | 54.00% |
| bge-m3 | 30.00% | 38.00% | 40.00% | 40.00% | 44.00% | |
| all-minilm | 32.00% | 34.00% | 38.00% | 46.00% | 50.00% | |
| nomic | 28.00% | 38.00% | 42.00% | 42.00% | 46.00% | |
| Regulation | Name of Regulation | Number of Fragments | Number of Questions |
|---|---|---|---|
| Regulation 1 | Regulations on the Bidding and Tendering Process for Government Procurement of Goods and Services | 12 | 50 |
| Regulation 2 | Financial Department Supervision Measures | 6 | 36 |
| Regulation 3 | Fiscal Bill Management Measures | 7 | 35 |
| Regulation 4 | Management Measures for Loans and Grants from International Financial Institutions and Foreign Governments | 7 | 39 |
| Regulation 5 | Administrative Measures for the Transfer of State-owned Assets in Financial Enterprises | 8 | 64 |
| Regulation 6 | Approval and Supervision Measures for Asset Appraisal Institutions | 6 | 48 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, B.; Wen, H.; Wang, S.; Hu, T.; Liang, X.; Luo, X. An Optimized Semantic Matching Method and RAG Testing Framework for Regulatory Texts. Electronics 2025, 14, 2856. https://doi.org/10.3390/electronics14142856
Li B, Wen H, Wang S, Hu T, Liang X, Luo X. An Optimized Semantic Matching Method and RAG Testing Framework for Regulatory Texts. Electronics. 2025; 14(14):2856. https://doi.org/10.3390/electronics14142856
Chicago/Turabian StyleLi, Bingjie, Haolin Wen, Songyi Wang, Tao Hu, Xin Liang, and Xing Luo. 2025. "An Optimized Semantic Matching Method and RAG Testing Framework for Regulatory Texts" Electronics 14, no. 14: 2856. https://doi.org/10.3390/electronics14142856
APA StyleLi, B., Wen, H., Wang, S., Hu, T., Liang, X., & Luo, X. (2025). An Optimized Semantic Matching Method and RAG Testing Framework for Regulatory Texts. Electronics, 14(14), 2856. https://doi.org/10.3390/electronics14142856