Enhancing Healthcare Assistance with a Self-Learning Robotics System: A Deep Imitation Learning-Based Solution




Abstract
1. Introduction
2. Related Work
2.1. Healthcare Robotics: Current Trends and Limitations
2.2. Self-Learning Robotics in Healthcare
2.3. Deep Imitation Learning: The Backbone of Adaptability
2.4. Applications and Efficacy of Self-Learning Robots in Healthcare
2.5. Research Gaps and Challenges
- ▪
- Lack of a Dataset: Collecting and annotating healthcare demonstrations are difficult due to privacy concerns, data ownership, and variation across institutions [20].
- ▪
- General Limitations: Systems trained on narrow demonstration sets often perform poorly in unfamiliar environments or with unexpected task variations [17].
- ▪
- Human–Robot Interaction (HRI): Natural, intuitive communication between robots and patients or clinicians is still underdeveloped, despite its critical importance [1].
- ▪
- Safety and Ethics: Ensuring fail-safe operation in sensitive contexts remains a major concern, particularly when an SLRS interacts directly with patients [6].
3. SLRS Architecture, Functioning Principles, Control Blocks, and Implementation
3.1. SLRS System Architecture
- ▪
- ▪
- ▪
3.2. Learning Framework and Policy Acquisition
3.2.1. Data Acquisition and Preprocessing
- ▪
- ▪
- ▪
3.2.2. The Policy Learning Framework
- ▪
- Feature trajectories are extracted.
- ▪
- An affinity matrix is computed based on motion similarity.
- ▪
- Spectral clustering is applied to group motion patterns into clusters.
- ▪
- Segment boundaries are determined based on changes in motion labels.
- ▪
- Valid segments are grouped using a similarity threshold θ to form higher-level motion categories.
| Algorithm 1: Behavioural Segmentation Algorithm |
| start Read the set of Demonstrations D = {D1, D2, …, Dₙ}; for each Demonstration Di in D do Extract Feature Trajectories Ti from Di; Compute Affinity Matrix Ai using motion similarity between Ti; Apply Spectral Clustering on Ai to obtain Cluster Labels: Ci; Initialize Segment Boundaries = ∅; Set PrevLabel = Ci[0], StartIndex = 0; for j = 1 to length(Ci) − 1 do if Ci[j] ≠ PrevLabel and (j − StartIndex) ≥ minLen then Append j to Segment Boundaries; Set StartIndex = j; Set PrevLabel = Ci[j]; else if Slice Demonstration Di using Segment Boundaries; for each Segment s in Sliced Di do else if Segment s is Valid (based on θ and motion consistency) then Add s to Segment List; for each pair of Segments (si, sⱼ) in Segment List do else Motion Similarity(si, sⱼ) ≥ θ then Merge si and sⱼ into same Motion Group; end end end end Output all Behavioural Segments; end |
- ▪
- ▪
- Classification is performed via SoftMax.
- ▪
- If confidence is low, feature vectors are compared using Euclidean distance.
- ▪
- RGB values are also used to confirm object identity.
| Algorithm 2: Object Detection and Colour Recognition Algorithm | ||||||||
| start | ||||||||
| Read the Object Image from input Device; | ||||||||
| Apply the pre-processing Algorithm; | ||||||||
| Apply Resnet-50 on the Object Image: ; | ||||||||
| Apply the ReLU Activation Function: ; | ||||||||
| Apply the CNN Algorithm: ; | ||||||||
| Apply SoftMax Function: ; | ||||||||
| Extract the RGB features of Object Image: ; | ||||||||
| if Object Identified then | ||||||||
| Print “Pick Object” | ||||||||
| else if | ||||||||
| for I = 1 to N do //N is the number of DS images; | ||||||||
| Read the Datasets (DS) image features: ; | ||||||||
| Calculate the distance between the two feature vectors; | ||||||||
| else if (Classified Threshold Satisfied) then | ||||||||
| Print “Place Object to Destination;” | ||||||||
| else | ||||||||
| Print “Object not Identified with DS Images;” | ||||||||
| end | ||||||||
| end | ||||||||
| end | ||||||||
| end | ||||||||
| end | ||||||||
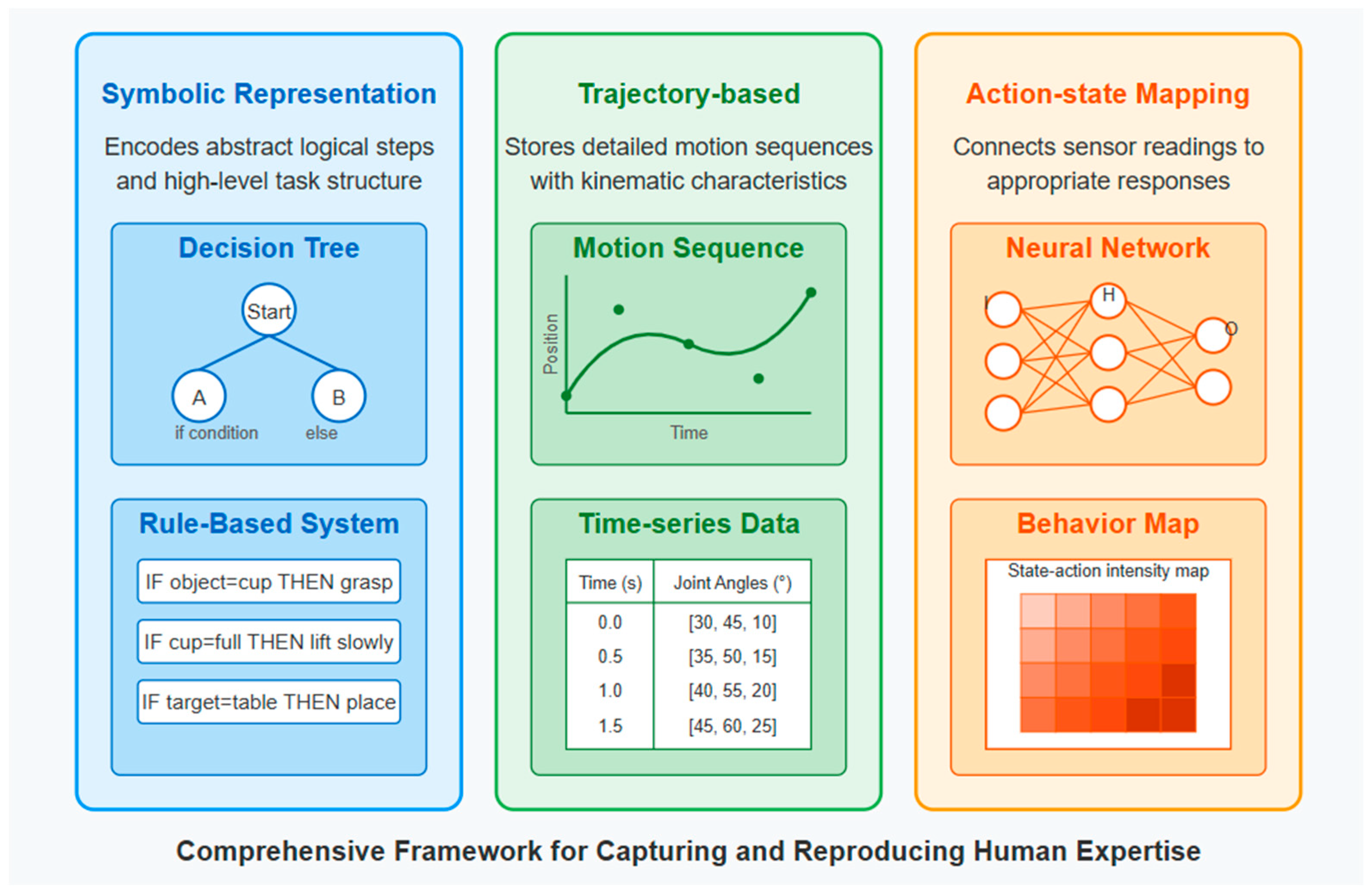
- ▪
- ▪
- ▪
- ▪
- ▪
- Action–state mappings directly link sensor input to motor responses, enabling real-time reactivity in dynamic environments [23].
3.2.3. Context-Aware Perception
- ▪
- Object Detection: The system uses the YOLOv8 algorithm, fine-tuned on a domain-specific healthcare dataset prepared via Roboflow [21,25]. YOLOv8 was selected for its speed (91 FPS) and high detection accuracy, particularly under dynamic conditions common in clinical environments. Detected objects include assistive items such as bananas, toothbrushes, and medicine bottles, which are classified and localised in the robot’s workspace in real time.
- ▪
- Pose Estimation: To detect and classify human hand pose, a MediaPipe–LSTM framework is used. MediaPipe extracts 3D skeletal key points, while LSTM networks model the temporal dynamics of these key points to classify gesture sequences. This enables the robot to interpret motion over time, for example, distinguishing between reaching and giving gestures. The system processes 1662 pose features per second (55 key points × 30 FPS), enabling fine-grained motion tracking and real-time interpretation of human intent.
- ▪
- Temporal Synchronisation and Feature Alignment: The outputs of object and action recognition pipelines are temporally synchronised to ensure consistent alignment between observed behaviours and environmental states. This is essential for policy learning, where the robot must understand both what action is required and how it is executed within a specific context.
- ▪
- System Performance Evaluation: Figure 7 presents a performance evaluation of the perception system under various lighting conditions and object occlusions. Detection accuracy and frame processing time were benchmarked for three representative object classes:
- ▪
- Banana: Highest accuracy (up to 9%), even under occlusion.
- ▪
- Orange: Moderate accuracy across conditions.
- ▪
- Toothbrush: Lower accuracy in cluttered scenes, dropping to 79%.
- ▪
- What actions to perform (object and goal recognition);
- ▪
- How they should be performed (human gestures and motion recognition).
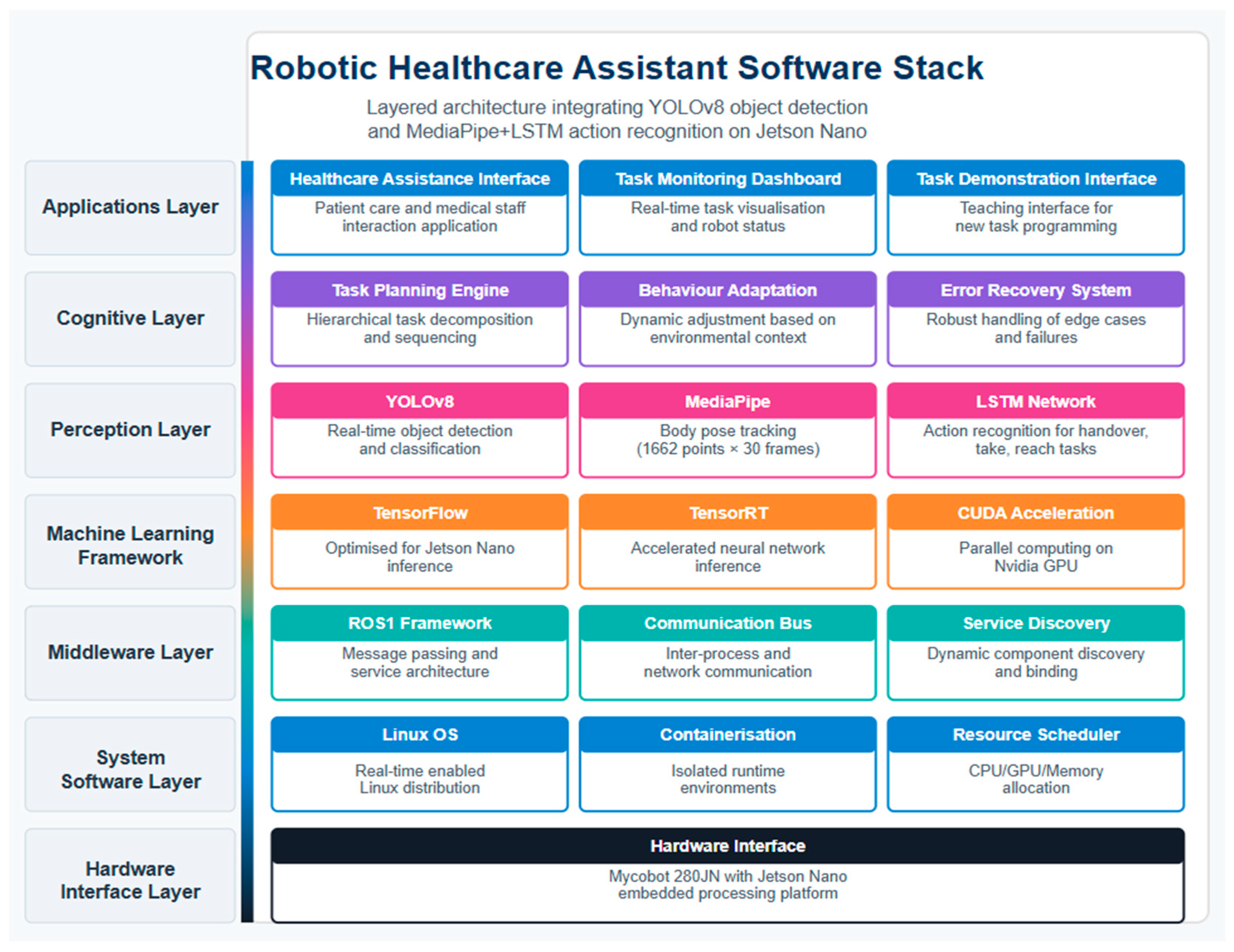
3.3. Implementation and System Integration
3.3.1. Hardware Platform
- ▪
- Manipulator: MyCobot 280, with six DOF for flexible articulation.
- ▪
- ▪
- Sensing Suite: Stereo vision cameras, RGB-D sensors for 3D depth mapping, and webcams for high-resolution RGB input.
3.3.2. Software Platform
- ▪
- ▪
- Deep Learning Pipelines:
- ○
- YOLOv8 for object detection;
- ○
- MediaPipe + LSTM for human gesture/action recognition [49];
- ○
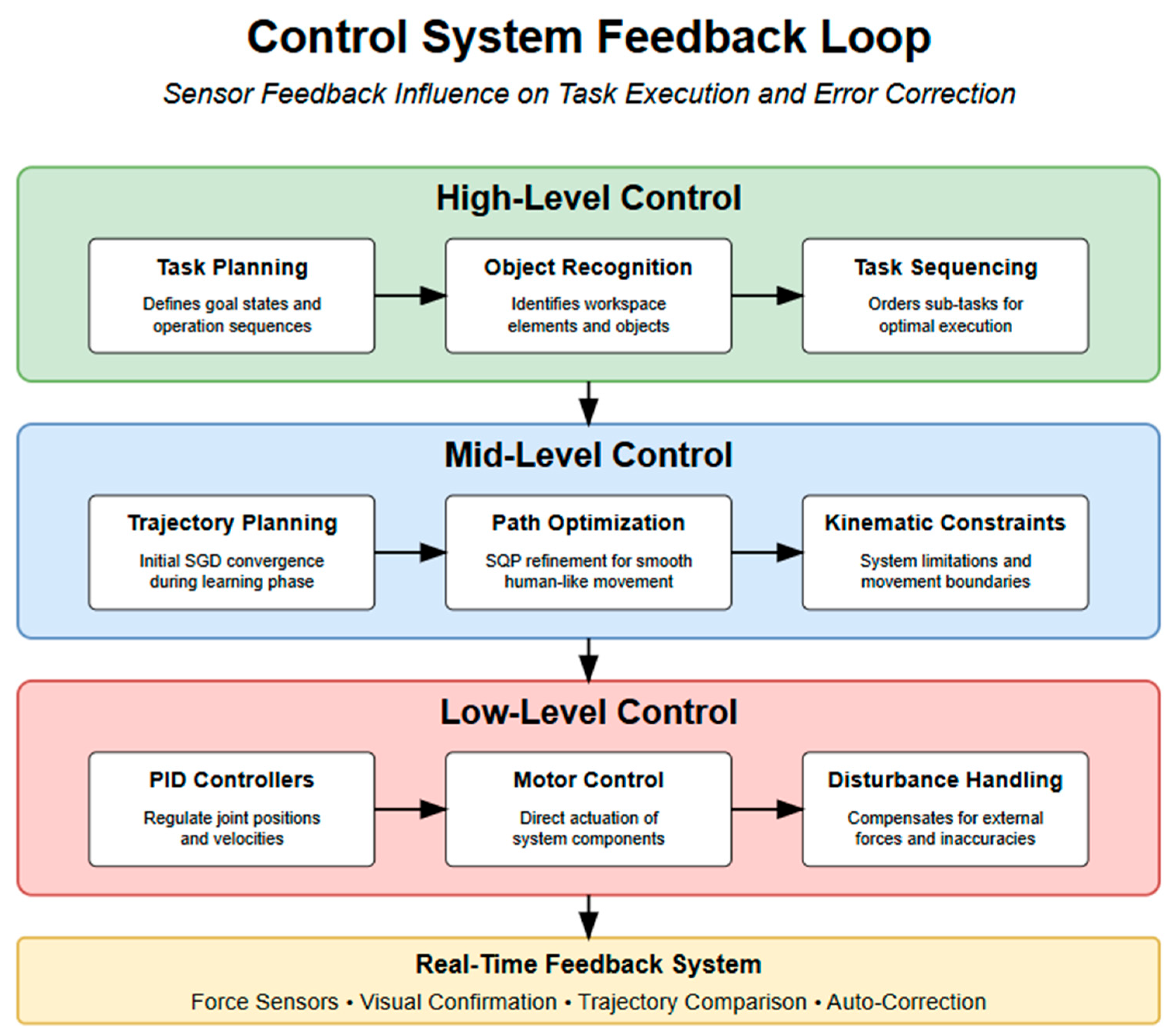
3.3.3. Control System Implementation
- ▪
- High level controller: The SLRS control system adopts a hierarchical structure comprising three levels. At the high level, task planning is informed by detected objects and recognised actions, allowing for the robot to determine the optimal sequence of operation to achieve the desired task outcome [3,12,38].
- ▪
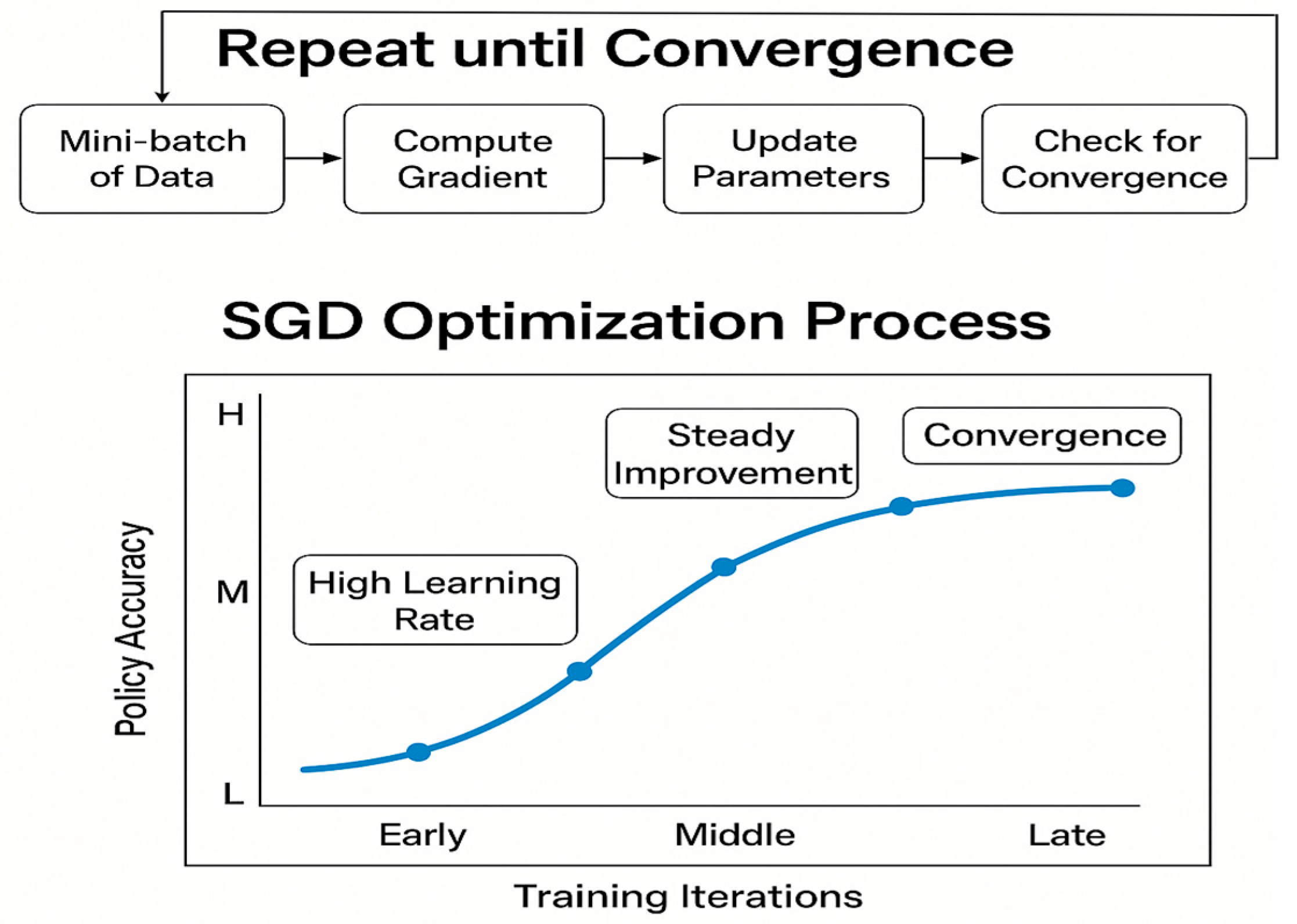
- Mid-level controller: This handles the trajectory generation, combining Stochastic Gradient Descent (SGD) for initial optimisation with Sequential Quadratic Programming (SQP) for fine-tuned trajectory refinement [24,36,43]. This hybrid approach produces smooth and biologically plausible motion patterns while respecting the robotic system’s kinematic constraints [13].
- ▪
- Low level controller: This is a PID controller that regulates the robotic arm’s joint positions and velocities, ensuring accurate execution of planned trajectories [6,11,20]. This classical control foundation, while complemented by learning-based approaches, provides deterministic safety and robustness under variable environmental conditions. A multimodal feedback loop is implemented, enabling auto-correction based on real-time visual feedback to recover from minor failures without requiring human intervention [22,27,38].
3.4. Evaluation Methodology and Experimental Design
3.4.1. Training and Testing Protocol
- ▪
- RGB-D video streams capturing human motion and object states;
- ▪
- 3D skeletal pose data from MediaPipe;
- ▪
- Annotated task phases, including reach, grasp, transfer, and release.
3.4.2. Model Training Procedure
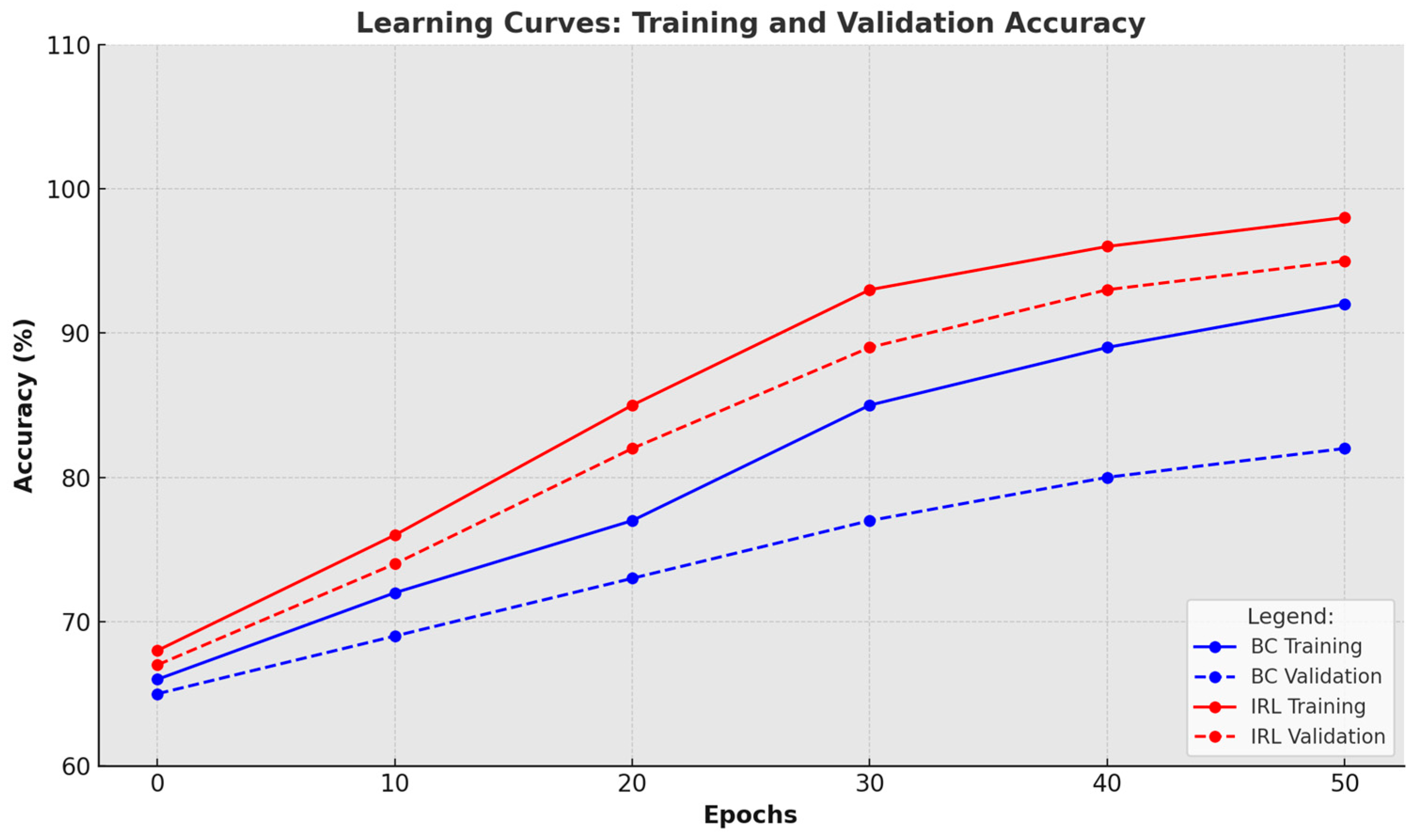
- ▪
- Behavioural Cloning (BC) policy using supervised learning;
- ▪
- Inverse Reinforcement Learning (IRL) policy using learned reward functions.
- ▪
- Learning rate: 0.001
- ▪
- Batch size: 32
- ▪
- Epochs: 100
- ▪
- Optimiser: Adam
3.5. SLRS CAD Simulation and Real Applications Case Studies Evaluation
3.5.1. Surgical Health Assistance
- ▪
- A surgical tray setup with identifiable tools;
- ▪
- Timed request prompts from the operator;
- ▪
- Lighting and spatial constraints reflecting operating theatre conditions.
3.5.2. Daily Living Health Assistance
3.5.3. Rehabilitation and Care Support (Adaptive Interaction Trials)
4. SLRS Testing, Validation, Results, and Discussion
SLRS Performance Results
- ▪
- First, the training dataset was relatively small, consisting of 20 demonstration videos totalling 8.5 h.
- ▪
- Second, the evaluated tasks were confined to object handovers, excluding more complex healthcare interactions such as patient mobility support or natural language communication.
- ▪
- Third, all trials were conducted in simulated environments and did not include clinical staff or real patients, limiting external validity.
- ▪
- Finally, the system’s performance was not benchmarked against other published SLRS implementations, making it difficult to assess relative advancement beyond the rule-based baseline.
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| CNN | Convolutional Neural Network |
| DIL | Deep Imitation Learning |
| DOF | Degrees of Freedom |
| GAIL | Generative Adversarial Imitation Learning |
| HRI | Human–Robot Interaction |
| IL | Imitation Learning |
| IRL | Inverse Reinforcement Learning |
| LSTM | Long Short-Term Memory |
| MATLAB | Matrix Laboratory (MathWorks software) |
| MDP | Markov Decision Process |
| PID | Proportional–Integral–Derivative (controller) |
| PvD | Program via Demonstration |
| RGB-D | Red–Green–Blue with Depth (sensor) |
| RL | Reinforcement Learning |
| ROS | Robot Operating System |
| SGD | Stochastic Gradient Descent |
| SLRS | Self-Learning Robotic System |
| SSD | Single Shot Multi-mid-Box Detector |
| YOLOv8 | You Only Look Once version 8 |
References
- Yang, G.; Pang, Z.; Deen, M.J.; Dong, M. Homecare robotic systems for healthcare 4.0: Visions and enabling technologies. IEEE J. Biomed. Health Inform. 2020, 24, 2759–2771. [Google Scholar] [CrossRef] [PubMed]
- Raj, R.; Kos, A. An Extensive Study of Convolutional Neural Networks: Applications in Computer Vision for Improved Robotics Perceptions. Sensors 2025, 25, 1033. [Google Scholar] [CrossRef]
- Shah, S.I.H.; Coronato, A.; Naeem, M.; De Pietro, G. Learning and assessing optimal dynamic treatment regimes through cooperative imitation learning. IEEE Access 2022, 10, 84045–84060. [Google Scholar] [CrossRef]
- Al-Hamadani, M.N.A.; Fadhel, M.A.; Alzubaidi, L.; Harangi, B. Reinforcement learning algorithms and applications in healthcare and robotics: A comprehensive and systematic review. Sensors 2024, 24, 2461. [Google Scholar] [CrossRef] [PubMed]
- Alshammari, R.F.N.; Arshad, H.; Rahman, A.H.A.; Albahri, O.S. Robotics utilization in automatic vision-based assessment systems from artificial intelligence perspective: A systematic review. IEEE Access 2022, 10, 145621–145635. [Google Scholar] [CrossRef]
- Alatabani, L.E.; Ali, E.S.; Saeed, R.A. Machine Learning and Deep Learning Approaches for Robotics Applications. In Lecture Notes in Networks and Systems; Springer: Berlin/Heidelberg, Germany, 2023; Volume 519. [Google Scholar]
- Jadeja, Y.; Shafik, M.; Wood, P. An industrial self-learning robotic platform solution for smart factories using machine and deep imitation learning. In Advances in Manufacturing Technology XXXIV; IOS Press: Amsterdam, The Netherlands, 2021; pp. 63–68. [Google Scholar]
- Zare, M.; Kebria, P.M.; Khosravi, A.; Nahavandi, S. A Survey of Imitation Learning: Algorithms, Recent Developments, and Challenges. IEEE Trans. Neural Netw. Learn. Syst. 2024, 54, 7173–7186. [Google Scholar] [CrossRef]
- Pan, Y.; Cheng, C.-A.; Saigol, K.; Lee, K.; Yan, X.; A Theodorou, E.; Boots, B. Imitation learning for agile autonomous driving. Int. J. Robot. Res. 2020, 39, 515–533. [Google Scholar] [CrossRef]
- Mahajan, H.B.; Uke, N.; Pise, P.; Shahade, M.; Dixit, V.G.; Bhavsar, S.; Deshpande, S.D. Automatic robot manoeuvres detection using computer vision and deep learning techniques. Multimed. Tools Appl. 2023, 82, 21229–21255. [Google Scholar] [CrossRef]
- Siciliano, B.; Khatib, O. Springer Handbook of Robotics, 2nd ed.; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Jadeja, Y.; Shafik, M.; Wood, P. A comprehensive review of robotics advancements through imitation learning for self-learning systems. In Proceedings of the 2025 9th International Conference on Mechanical Engineering and Robotics Research (ICMERR), Barcelona, Spain, 15–17 January 2025. [Google Scholar]
- Jadeja, Y.; Shafik, M.; Wood, P. Computer-aided design of self-learning robotic system using imitation learning. In Advances in Manufacturing Technology; IOS Press: Amsterdam, The Netherlands, 2022; pp. 47–53. [Google Scholar]
- Argall, B.D.; Chernova, S.; Veloso, M.; Browning, B. A survey of robot learning from demonstration. Robot. Auton. Syst. 2009, 57, 469–483. [Google Scholar] [CrossRef]
- Tonga, P.A.; Ameen, Z.S.; Mubarak, A.S. A review on on-device privacy and machine learning training. IEEE Access 2022, 10, 115790–115805. [Google Scholar]
- Calp, M.H.; Butuner, R.; Kose, U.; Alamri, A. IoHT-based deep learning controlled robot vehicle for paralyzed patients of smart cities. J. Supercomput. 2022, 78, 17635–17657. [Google Scholar] [CrossRef]
- Butuner, R.; Kose, U. Application of artificial intelligence algorithms for robot development. In AI in Robotics and Automation; CRC Press: Boca Raton, FL, USA, 2023. [Google Scholar]
- Otamajakusi. YOLOv8 on Jetson Nano. i7y.org. 2023. Available online: https://i7y.org/en/yolov8-on-jetson-nano/ (accessed on 14 July 2023).
- Fang, Y.; Xie, J.; Li, M.; Maroto-Gómez, M.; Zhang, X. Recent advancements in multimodal human–robot interaction: A systematic review. Front. Neurorobotics 2023, 17, 1084000. [Google Scholar]
- Smarr, C.A.; Prakash, A.; Beer, J.M.; Mitzner, T.L.; Kemp, C.C.; Rogers, W.A. Older Adults’ Preferences for and Acceptance of Robot Assistance for Everyday Living Tasks. Proc. Hum. Factors Ergon. Soc. Annu. Meet. 2014, 56, 153–157. [Google Scholar] [CrossRef]
- Kruse, T.; Pandey, A.K.; Alami, R.; Kirsch, A. Human-aware Robot Navigation: A Survey. Robot. Auton. Syst. 2013, 61, 1726–1743. [Google Scholar] [CrossRef]
- Chen, X.; Wang, Z.; Zhang, Z.; Wang, X.; Yang, R. A Deep Learning Approach to Grasp Type Recognition for Robotic Manipulation in Healthcare. IEEE Robot. Autom. Lett. 2023, 8, 2358–2365. [Google Scholar]
- Kyrarini, M.; Lygerakis, F.; Rajavenkatanarayanan, A.; Sevastopoulos, C.; Nambiappan, H.R.; Chaitanya, K.K.; Babu, A.R.; Mathew, J.; Makedon, F. A Survey of Robots in Healthcare. Technologies 2021, 9, 8. [Google Scholar] [CrossRef]
- Banisetty, S.B.; Feil-Seifer, D. Towards a Unified Framework for Social Perception and Action for Social Robotics. ACM Trans. Hum. Robot Interact. 2022, 11, 1–26. [Google Scholar]
- Gao, Y.; Chang, H.J.; Demiris, Y. User Modelling for Personalised Dressing Assistance by Humanoid Robots. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 1840–1847. [Google Scholar]
- Muelling, K.; Venkatraman, A.; Valois, J.-S.; Downey, J.E.; Weiss, J.; Javdani, S.; Hebert, M.; Schwartz, A.B.; Collinger, J.L.; Bagnell, J.A. Autonomy Infused Teleoperation with Application to Brain Computer Interface Controlled Manipulation. Auton. Robot. 2017, 41, 1401–1422. [Google Scholar] [CrossRef]
- Johansson, D.; Malmgren, K.; Murphy, M.A. Wearable Sensors for Clinical Applications in Epilepsy, Parkinson’s Disease, and Stroke: A Mixed-Methods Systematic Review. J. Neurol. 2022, 265, 1740–1752. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv8: An Incremental Improvement. arXiv 2023, arXiv:2304.00501. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Maddox, T.; Fitzpatrick, J.M.; Guitton, A.; Maier, A.; Yang, G.Z. The Role of Human-Robot Interaction in Intelligent and Ethical Healthcare Delivery. Nat. Med. 2022, 28, 1098–1102. [Google Scholar]
- Fang, B.; Jia, S.; Guo, D.; Xu, M.; Wen, S.; Sun, F. Survey of Imitation Learning for Robotic Manipulation. Int. J. Intell. Robot. Appl. 2021, 5, 3–15. [Google Scholar] [CrossRef]
- Manzi, F.; Sorgente, A.; Massaro, D. Acceptance of Robots in Healthcare: State of the Art and Suggestions for Future Research. Societies 2022, 12, 143. [Google Scholar]
- Draper, H.; Sorell, T. Ethical Values and Social Care Robots for Older People: An International Qualitative Study. Ethics Inf. Technol. 2022, 19, 49–68. [Google Scholar] [CrossRef]
- Jokinen, K.; Wilcock, G. Multimodal Open-Domain Conversations with Robotic Platforms. In Computer Vision and Pattern Recognition, Multimodal Behavior Analysis in the Wild; Academic Press: Cambridge, MA, USA, 2019; pp. 9–16. [Google Scholar]
- Shin, H.V.; Tokmouline, M.; Shah, J.A. Design Guidelines for Human-AI Co-Learning: A Mixed Methods Participatory Approach. Proc. ACM Hum. Comput. Interact. 2023, 7, 1–26. [Google Scholar]
- Azeta, J.; Bolu, C.; Abioye, A.A.; Oyawale, F.A. A Review on Humanoid Robotics in Healthcare. MATEC Web Conf. 2018, 153, 02004. [Google Scholar]
- Breazeal, C.; DePalma, N.; Orkin, J.; Chernova, S.; Jung, M. Crowdsourcing Human-Robot Interaction: New Methods and System Evaluation in a Public Environment. J. Hum. Robot Interact. 2022, 2, 82–111. [Google Scholar] [CrossRef]
- Yang, G.-Z.; Cambias, J.; Cleary, K.; Daimler, E.; Drake, J.; Dupont, P.E.; Hata, N.; Kazanzides, P.; Martel, S.; Patel, R.V.; et al. Medical Robotics—Regulatory, Ethical, and Legal Considerations for Increasing Levels of Autonomy. Sci. Robot. 2017, 2, eaam8638. [Google Scholar] [CrossRef]
- Tosun, O.; Aghakhani, M.; Chauhan, A.; Sefidgar, Y.S.; Hoffman, G. Trust-Aware Human-Robot Interaction in Healthcare Settings. Int. J. Soc. Robot. 2023, 15, 479–496. [Google Scholar]
- Ho, J.; Ermon, S. Generative Adversarial Imitation Learning. Adv. Neural Inf. Process. Syst. 2016, 29, 4565–4573. [Google Scholar]
- Celemin, C.; Ruiz-del-Solar, J. Interactive imitation learning: A survey of human-in-the-loop learning methods. arXiv 2022, arXiv:2203.03101. [Google Scholar]
- Alotaibi, B.; Manimurugan, S. Humanoid robot-assisted social interaction learning using deep imitation in smart environments. J. Ambient. Intell. Humaniz. Comput. 2022, 13, 2511–2525. [Google Scholar]
- Rösmann, M.; Hoffmann, F.; Bertram, T. Trajectory modification considering dynamic constraints of autonomous ROBOTIK 2012. In Proceedings of the 7th German Conference on Robotics, Munich, Germany, 21–22 May 2012; p. 16. [Google Scholar]
- NVIDIA. Jetson Nano Developer Kit: Datasheet and Power Performance Guide. 2022. Available online: https://developer.nvidia.com/embedded/jetson-nano (accessed on 25 January 2023).
- Tsuji, T.; Lee, Y.; Zhu, Y. Imitation learning for contact-rich manipulation in assistive robotics. Robot. Auton. Syst. 2025, 165, 104390. [Google Scholar]
- Developers, R.O. MoveIt: Motion Planning Framework for ROS2. 2022. Available online: https://moveit.ros.org (accessed on 9 January 2023).
- Lugaresi, C.; Tang, J.; Nash, H.; McClanahan, C.; Uboweja, E.; Hays, M.; Zhang, F.; Chang, C.L.; Yong, M.G.; Lee, J.; et al. MediaPipe: A Framework for Building Perception Pipelines. arXiv 2019, arXiv:1906.08172. [Google Scholar]
- Zhang, H.; Thomaz, A.L. Learning social behaviour for assistive robots using human demonstrations. ACM Trans. Hum.-Robot. Interact. 2020, 9, 1–25. [Google Scholar] [CrossRef]
- Sharma, S.; Sing, R.K.; Fryazinov, O.; Adzhiev, V. K-means based stereo vision clustering for 3D object localization in robotics. IEEE Access 2022, 10, 112233–112245. [Google Scholar]
- Caldwell, M.; Andrews, J.T.A.; Tanay, T.; Griffin, L.D. AI-Enabled Future Surgical Healthcare: Ethics Principles and Epistemic Gaps. AI Soc. 2023, 38, 1–16. [Google Scholar]
- Sharma, S.; Sing, R.K.; Fryazinov, O.; Adzhiev, V. Computer Vision Techniques for Robotic Systems: A Systematic Review. IEEE Access 2022, 10, 29486–29510. [Google Scholar]
- Robotics, E. MyCobot 280 Jetson Nano: Robotic Arm Specification Sheet. 2023. Available online: https://www.elephantrobotics.com/product/mycobot-280-jetson-nano/ (accessed on 14 July 2023).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Aspect | Behaviour Cloning (BC) | Inverse Reinforcement Learning (IRL) |
|---|---|---|
| Definition | Learns a policy by directly mimicking expert demonstrations | Infers the reward function underlying expert behaviour |
| Learning Target | Policy function | Reward function (then derive policy via reinforcement learning) |
| Supervision Type | Supervised learning | Combination of supervised + reinforcement learning |
| Data Requirement | Requires a large and diverse set of expert trajectories | Requires fewer demonstrations but needs exploration capability |
| Generalisation | Poor generalisation outside seen states | Better generalisation by learning the underlying intent (reward) |
| Robustness to Noise | Sensitive to imperfect demonstrations | More robust to suboptimal or noisy expert actions |
| Exploration | No exploration; purely imitation-based | Includes exploration as part of reward function optimisation |
| Implementation | Simpler and faster to implement | Computationally expensive and complex |
| Advantages | Easy to implement, Fast training | Learns the intent of the expert, Better long-term behaviour |
| Limitations | Prone to compounding errors, Does not learn intent | Complex optimisation, Needs RL to derive policy from reward |
| Typical Use Cases | Autonomous driving, robotics with ample data | Strategic planning, robotics with sparse demonstrations |
| Category | Value |
|---|---|
| Expert Demonstration Videos | 20 |
| Total Images | 1500 |
| Task Types | 3 (Fruits Handover, Vegetables Handover, Daily Use Items Handover) |
| Example Items | Apples, Oranges, Bananas, Carrots, Cucumbers, Toothbrushes, etc. |
| Total Recorded Data | 8.5 h |
| Number of Expert Subjects | 5 |
| Testing Environments | 2 (Laboratory Setting, Home Environment) |
| Robot Platform Used | 1 (Assistive Robotic Arm) |
| Metric | Threshold | Justification |
|---|---|---|
| Trajectory Accuracy | <10 mm deviation | Ensures sufficient precision for household object handover tasks |
| Task Completion Success Rate | >90% | Required reliability for daily assistance operations |
| Execution Time | <2.0× human time | Balance between efficiency and safety for household tasks |
| Grasp Success Rate | >85% | Reliable grasping of varied objects (fruits, vegetables, daily items) |
| Adaptability Score | >80% | Ensures robustness in varying home lighting and object placement |
| Safety Metric (Emergency Stop Response) | <300 ms | Rapid response to unexpected situations |
| User Satisfaction Rating | >3.8/5.0 | Acceptance criteria for home assistance users |
| Object Recognition Accuracy | >92% | Ability to correctly identify various household items |
| Handover Position Accuracy | <15 cm | Comfortable handover zone for human users |
| Algorithm | Detection Accuracy (%) | Processing Time (ms) | Reliability in Dynamic Settings |
|---|---|---|---|
| YOLOv8 | 94.3 | 18.7 | High |
| YOLOv5 | 89.7 | 22.4 | Moderate |
| SSD | 86.2 | 27.9 | Moderate |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jadeja, Y.; Shafik, M.; Wood, P.; Makkar, A. Enhancing Healthcare Assistance with a Self-Learning Robotics System: A Deep Imitation Learning-Based Solution. Electronics 2025, 14, 2823. https://doi.org/10.3390/electronics14142823
Jadeja Y, Shafik M, Wood P, Makkar A. Enhancing Healthcare Assistance with a Self-Learning Robotics System: A Deep Imitation Learning-Based Solution. Electronics. 2025; 14(14):2823. https://doi.org/10.3390/electronics14142823
Chicago/Turabian StyleJadeja, Yagna, Mahmoud Shafik, Paul Wood, and Aaisha Makkar. 2025. "Enhancing Healthcare Assistance with a Self-Learning Robotics System: A Deep Imitation Learning-Based Solution" Electronics 14, no. 14: 2823. https://doi.org/10.3390/electronics14142823
APA StyleJadeja, Y., Shafik, M., Wood, P., & Makkar, A. (2025). Enhancing Healthcare Assistance with a Self-Learning Robotics System: A Deep Imitation Learning-Based Solution. Electronics, 14(14), 2823. https://doi.org/10.3390/electronics14142823