Image Captioning Method Based on CLIP-Combined Local Feature Enhancement and Multi-Scale Semantic Guidance

Abstract
1. Introduction
- Local Relation Modeling and Feature Enhancement: How to model relationships among multiple local-region objects in images, differentiate their relative importance, and subsequently enhance fine-grained local features while computing object-specific weights to improve semantic accuracy in generated text.
- Multi-scale Semantic Alignment: How to map the correspondence between global image semantics and global text semantics, as well as local region image semantics and local text semantics, and thereby guide GPT-2 to generate more accurate descriptions.
- A novel architecture combining CLIP encoder, Faster R-CNN local visual encoder, and GPT-2 text decoder.
- A K-Nearest Neighbors (KNN) graph constructed from local image features to model inter-object relationships, enhanced via GAT to refine local feature representation—providing a new approach for image detail characterization.
- A multi-scale semantic guidance mechanism that computes global and local semantic weights to enhance the richness and accuracy of complex scene descriptions and attribute details generated by the GPT-2 decoder.
2. Related Works
2.1. Local Feature Extraction and Relationship Modeling in Image Captioning
2.2. Challenges of Multi-Scale Alignment
2.3. Necessity of Feature Fusion
3. Model Design
3.1. Model Structure
3.2. Visual Encoder Module and Text Encoder Module
3.2.1. Visual Encoder Module Based on ViT and Faster R-CNN
- 1.
- Global Image Feature Extraction Based on ViT
- 2.
- Local Region Feature Extraction and Node Definition based on Faster R-CNN
- 3.
- Graph Structure Modeling for Local Region Features based on KNN Graph
3.2.2. Text Encoder Module Based on BERT
3.3. Image Local Region Object Feature Enhancement Module Based on Graph Attention Network
3.3.1. Graph Attention Network
- Local Object Relationship Modeling: Based on the KNN graph built from Faster R-CNN’s local object features, GAT dynamically computes attention weights between nodes (region object feature vectors), capturing co-occurrence and spatial relationships between objects (e.g., “person-riding horse-grassland”), enhancing scene understanding capabilities.
- Fine-grained Local Feature Enhancement: Through multi-layer message passing, GAT performs high-order relational reasoning on local object features, effectively compensating for CLIP’s global features’ lack of detail in descriptions.
- Dynamic Attention Allocation for Local Objects: Using an adaptive attention mechanism, GAT assigns differentiated weights to different local objects (e.g., highlighting the main object “person”, weakening the background “cloud”), improving the semantic accuracy of the generated text.
3.3.2. Node Attention Coefficient Calculation
3.3.3. Node Feature Update
3.3.4. Image Global-Local Region Multi-Scale Feature Fusion
3.4. Multi-Scale Semantic Guidance Module
3.4.1. Global Semantic Guidance
3.4.2. Local Semantic Guidance
3.5. Text Decoder Module Based on GPT-2
3.6. Model Joint Training and Fine-Tuning
- 1.
- Text Generation Loss: Uses cross-entropy loss to constrain the match between the generated text and the ground truth description, defined as in Equation (16):where represents the t-th generated token, is the history token sequence, and is the visual encoding feature.
- 2.
- Semantic Alignment Loss: Utilizes CLIP’s contrastive loss to force alignment between image features and text embeddings in a joint semantic space, as shown in Equation (17):where and represent the global image feature vector and the text embedding vector, respectively.):
- 3.
- Gating Sparsity Constraint Loss: L1 regularization prevents excessive activation of gating weights, as shown in Equation (18):where is the weight matrix of the gating module, and is the regularization coefficient.
- 4.
- Total Loss Function: The weighted sum of the above three loss functions, as shown in Equation (19):where the weight hyperparameters are set to = 0.7, = 0.3.
- 5.
- Training Strategy: This paper employs a phased training strategy. In the pre-training stage, CLIP parameters are frozen, and the GAT and gating modules are trained separately to optimize local semantic extraction capabilities. In the joint fine-tuning stage, partially unfreeze certain CLIP parameters (e.g., the last two Transformer layers), and the GAT, gating module, and GPT-2 are jointly optimized to improve cross-modal alignment. The training process achieves high-precision image description generation through multi-scale feature fusion and dynamic gating filtering, combining CLIP’s cross-modal alignment capability, GAT’s local relationship modeling, and GPT-2’s generation capability. The core lies in balancing the text generation loss and semantic alignment constraints, while the phased training strategy improves model convergence efficiency, ensuring the generated image descriptions are both accurate and semantically coherent.
4. Experiments
4.1. Experimental Setup
4.2. Data Preprocessing
4.2.1. Visual Modal Preprocessing
4.2.2. Text Modal Preprocessing
4.2.3. Dataset Partitioning and Validation Strategy
4.3. Model Evaluation
4.3.1. Experimental Comparison on MSCOCO and Flickr30k Datasets
4.3.2. Ablation Study
- Effectiveness of the Local Feature Enhancement Module in Graph Attention Network
- 2.
- Effectiveness of the Multi-Scale Semantic Guidance Module
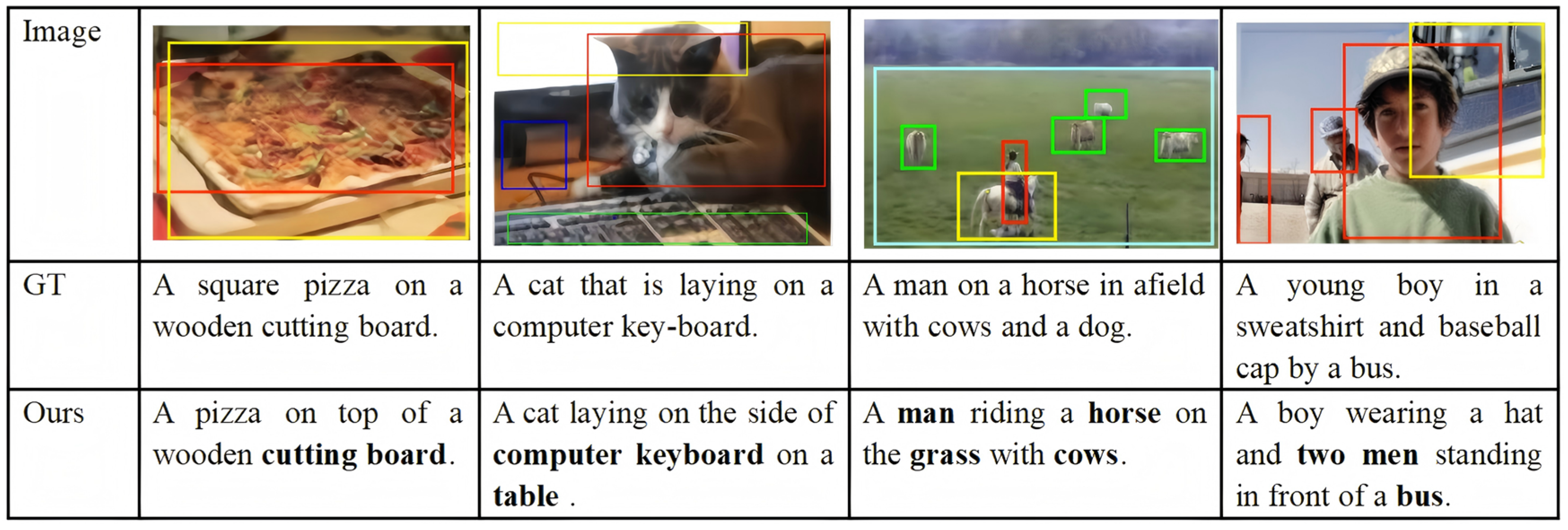
4.3.3. Qualitative Result Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bernardi, R.; Cakici, R.; Elliott, D.; Erdem, A.; Erdem, E.; Ikizler-Cinbis, N.; Keller, F.; Muscat, A.; Plank, B. Automatic Description Generation from Images: A Survey of Models, Datasets, and Evaluation Measures. J. Artif. Intell. Res. 2016, 55, 409–442. [Google Scholar] [CrossRef]
- Hossain, M.Z.; Sohel, F.; Shiratuddin, M.F.; Laga, H. A Comprehensive Survey of Deep Learning for Image Captioning. ACM Comput. Surv. 2019, 51, 1–36. [Google Scholar] [CrossRef]
- Mokady, R.; Hertz, A.; Bermano, A.H. ClipCap: CLIP Prefix for Image Captioning. arXiv 2021, arXiv:2111.09734. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models from Natural Language Supervision. arXiv 2021, arXiv:2103.00020. [Google Scholar] [CrossRef]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019. Available online: https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf (accessed on 1 June 2024).
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Zhong, Y.; Yang, J.; Zhang, P.; Li, C.; Codella, N.; Li, L.H.; Zhou, L.; Dai, X.; Yuan, L.; Li, Y.; et al. RegionCLIP: Region-based Language-Image Pretraining. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 16772–16782. [Google Scholar] [CrossRef]
- Li, M.; Xu, R.; Wang, S.; Zhou, L.; Lin, X.; Zhu, C.; Zeng, M.; Ji, H.; Chang, S.-F. CLIP-Event: Connecting Text and Images with Event Structures. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 16399–16408. [Google Scholar] [CrossRef]
- Qian, K.; Pan, Y.; Xu, H.; Tian, L. Transformer Model Incorporating Local Graph Semantic Attention for Image Caption. Vis. Comput. 2024, 40, 6533–6544. [Google Scholar] [CrossRef]
- Wang, Q.; Deng, H.; Wu, X.; Yang, Z.; Liu, Y.; Wang, Y.; Hao, G. LCM-Captioner: A Lightweight Text-Based Image Captioning Method with Collaborative Mechanism between Vision and Text. Neural Netw. 2023, 162, 318–329. [Google Scholar] [CrossRef]
- Li, J.; Li, D.; Savarese, S.; Hoi, S. BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models. arXiv 2023, arXiv:2301.12597. [Google Scholar] [CrossRef]
- Ramos, L.; Casas, E.; Romero, C.; Rivas-Echeverría, F.; Morocho-Cayamcela, M.E. A Study of ConvNeXt Architectures for Enhanced Image Captioning. IEEE Access 2024, 12, 13711–13728. [Google Scholar] [CrossRef]
- Ma, F.; Zhou, Y.; Rao, F.; Zhang, Y.; Sun, X. Image Captioning with Multi-Context Synthetic Data. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; pp. 4089–4097. [Google Scholar] [CrossRef]
- Yang, X.; Yang, Y.; Ma, S.; Li, Z.; Dong, W.; Woźniak, M. SAMT-generator: A second-attention for image captioning based on multi-stage transformer network. Neurocomputing 2024, 593, 127823. [Google Scholar] [CrossRef]
- Mandava, M.; Vinta, S.R. Image Captioning with Neural Style Transfer Using GPT-2 and Vision Transformer Architectures. In Machine Vision and Augmented Intelligence; Kumar Singh, K., Singh, S., Srivastava, S., Bajpai, M.K., Eds.; Springer Nature: Singapore, 2025; pp. 537–548. ISBN 978-981-97-4359-9. [Google Scholar] [CrossRef]
- Ramesh, A.; Dhariwal, P.; Nichol, A.; Chu, C.; Chen, M. Hierarchical Text-Conditional Image Generation with CLIP Latents. arXiv 2022, arXiv:2204.06125. [Google Scholar] [CrossRef]
- Barraco, M.; Cornia, M.; Cascianelli, S.; Baraldi, L.; Cucchiara, R. The Unreasonable Effectiveness of CLIP Features for Image Captioning: An Experimental Analysis. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), New Orleans, LA, USA, 19–24 June 2022; pp. 4661–4669. [Google Scholar] [CrossRef]
- Su, Y.; Lan, T.; Liu, Y.; Liu, F.; Yogatama, D.; Wang, Y.; Kong, L.; Collier, N. Language Models Can See: Plugging Visual Controls in Text Generation. arXiv 2022, arXiv:2205.02655. [Google Scholar] [CrossRef]
- Fei, J.; Wang, T.; Zhang, J.; He, Z.; Wang, C.; Zheng, F. Transferable Decoding with Visual Entities for Zero-Shot Image Captioning. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–6 October 2023; pp. 3113–3123. [Google Scholar] [CrossRef]
- Vishniakov, K.; Shen, Z.; Liu, Z. ConvNet vs Transformer, Supervised vs CLIP: Beyond ImageNet Accuracy. arXiv 2023, arXiv:2311.09215. [Google Scholar] [CrossRef]
- Vrahatis, A.G.; Lazaros, K.; Kotsiantis, S. Graph Attention Networks: A Comprehensive Review of Methods and Applications. Future Internet 2024, 16, 318. [Google Scholar] [CrossRef]
- Xu, B.; Wang, N.; Chen, T.; Li, M. Empirical Evaluation of Rectified Activations in Convolutional Network. arXiv 2015, arXiv:1505.00853. [Google Scholar] [CrossRef]
- Clevert, D.-A.; Unterthiner, T.; Hochreiter, S. Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs). arXiv 2015, arXiv:1511.07289. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef]
- Bisong, E. The Multilayer Perceptron (MLP). In Building Machine Learning and Deep Learning Models on Google Cloud Platform: A Comprehensive Guide for Beginners; Apress: Berkeley, CA, USA, 2019; pp. 401–405. [Google Scholar] [CrossRef]
- Cornia, M.; Stefanini, M.; Baraldi, L.; Cucchiara, R. Meshed-Memory Transformer for Image Captioning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10575–10584. [Google Scholar] [CrossRef]
- Ji, J.; Luo, Y.; Sun, X.; Chen, F.; Luo, G.; Wu, Y.; Gao, Y.; Ji, R. Improving Image Captioning by Leveraging Intra- and Inter-layer Global Representation in Transformer Network. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual Conference, USA, 2–9 February 2021; Volume 35, pp. 1655–1663. [Google Scholar] [CrossRef]
- Zhang, J.; Fang, Z.; Sun, H.; Wang, Z. Adaptive Semantic-Enhanced Transformer for Image Captioning. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 1785–1796. [Google Scholar] [CrossRef]
- Wang, Y.; Xu, J.; Sun, Y. End-to-End Transformer Based Model for Image Captioning. arXiv 2022, arXiv:2203.15350. [Google Scholar] [CrossRef]
- Zhang, H.; Xu, C.; Xu, B.; Jian, M.; Liu, H.; Li, X. TSIC-CLIP: Traffic Scene Image Captioning Model Based on Clip. Inf. Technol. Control 2024, 53, 35095. [Google Scholar] [CrossRef]
- Chen, L.; Li, K. Multi-Modal Graph Aggregation Transformer for Image Captioning. Neural Netw. 2025, 181, 106813. [Google Scholar] [CrossRef] [PubMed]
- Cao, S.; An, G.; Cen, Y.; Yang, Z.; Lin, W. CAST: Cross-Modal Retrieval and Visual Conditioning for Image Captioning. Pattern Recognit. 2024, 153, 110555. [Google Scholar] [CrossRef]
- Wang, P.; Yang, A.; Men, R.; Lin, J.; Bai, S.; Li, Z.; Ma, J.; Zhou, C.; Zhou, J.; Yang, H. OFA: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework. In Proceedings of the 39th International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; Chaudhuri, K., Jegelka, S., Song, L., Szepesvari, C., Niu, G., Sabato, S., Eds.; PMLR: San Diego, CA, USA, 2022; Volume 162, pp. 23318–23340. Available online: https://proceedings.mlr.press/v162/wang22al.html (accessed on 11 July 2025).
- Yu, J.; Wang, Z.; Vasudevan, V.; Yeung, L.; Seyedhosseini, M.; Wu, Y. CoCa: Contrastive Captioners are Image-Text Foundation Models. arXiv 2022, arXiv:2205.01917. [Google Scholar] [CrossRef]
- Kuo, C.-W.; Kira, Z. Beyond a Pre-Trained Object Detector: Cross-Modal Textual and Visual Context for Image Captioning. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 17948–17958. [Google Scholar] [CrossRef]
- Wang, J.; Wang, W.; Wang, L.; Wang, Z.; Feng, D.D.; Tan, T. Learning Visual Relationship and Context-Aware Attention for Image Captioning. Pattern Recognit. 2020, 98, 107075. [Google Scholar] [CrossRef]
- Zhou, L.; Palangi, H.; Zhang, L.; Hu, H.; Corso, J.; Gao, J. Unified Vision-Language Pre-Training for Image Captioning and VQA. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 13041–13049. [Google Scholar] [CrossRef]
- Liu, X.; Li, H.; Shao, J.; Chen, D.; Wang, X. Show, Tell and Discriminate: Image Captioning by Self-retrieval with Partially Labeled Data. In Computer Vision—ECCV 2018, Proceedings of the 15th European Conference, Munich, Germany, 8–14 September 2018; Proceedings, Part XV; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; pp. 353–369. [Google Scholar] [CrossRef]
- Zeng, Z.; Xie, Y.; Zhang, H.; Chen, C.; Chen, B.; Wang, Z. MeaCap: Memory-Augmented Zero-shot Image Captioning. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–21 June 2024; pp. 14100–14110. [Google Scholar] [CrossRef]
- Tu, H.; Yang, B.; Zhao, X. ZeroGen: Zero-Shot Multimodal Controllable Text Generation with Multiple Oracles. In Natural Language Processing and Chinese Computing, Proceedings of the 12th National CCF Conference, NLPCC 2023, Foshan, China, 12–15 October 2023; Proceedings, Part II; Liu, F., Duan, N., Xu, Q., Hong, Y., Eds.; Springer: Berlin/Heidelberg, Germany, 2023; pp. 494–506. [Google Scholar] [CrossRef]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res. 2020, 21, 5485–5551. Available online: http://www.jmlr.org/papers/v21/20-074.html (accessed on 11 July 2025).
- Alayrac, J.-B.; Donahue, J.; Luc, P.; Miech, A.; Barr, I.; Hasson, Y.; Lenc, K.; Mensch, A.; Millican, K.; Reynolds, M.; et al. Flamingo: A Visual Language Model for Few-Shot Learning. Adv. Neural Inf. Process. Syst. 2022, 35, 23716–23736. [Google Scholar] [CrossRef]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. LoRA: Low-Rank Adaptation of Large Language Models. arXiv 2021, arXiv:2106.09685. [Google Scholar] [CrossRef]
- Wang, J.; Tang, J.; Li, C.; Ma, Z.; Yang, J.; Fu, Q. Modeling and Analysis in the Industrial Internet with Dual Delay and Nonlinear Infection Rate. Electronics 2025, 14, 2058. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experimental Environment | Specific Information |
|---|---|
| Operating System | Windows 10 |
| GPU | NVIDIA GeForce RTX 4090 (24 GB GDDR6X) (NVIDIA, Santa Clara, CA, USA) |
| CPU | Intel Core i9-13900K (24 cores/32 threads) (Intel, Santa Clara, CA, USA) |
| Memory | 128 GB DDR5 |
| Development Language | Python 3.9 |
| Development platform | Pytorch 1.11.0 |
| Parameter Name | Parameter Value |
|---|---|
| lr (Learning Rate) | 1 × 10−4 |
| lr Decay | 0.9 |
| lr_step_size | 1 |
| batch-size | 64 |
| optimizers | AdamW |
| beam size | 5 |
| CLIPViT | VIT-B/32 |
| CLIPBERT_ENcoder_dim | 512 |
| GPT-2_dim | 768 |
| epochs | 30 |
| K | 5 |
| Anchor_scale | [64, 128, 256] |
| RoI pooling size | 7 × 7 |
| RPN_POST_NMS_TOP_N_TEST | 100 |
| CrossModal_Adapter_dim | 2048 → 512 |
| Method Categories | Methods | B-1 | B-4 | M | R | C | S |
|---|---|---|---|---|---|---|---|
| Semantic capture enhancement models | M2 Transformer [27] | 80.8 | 39.1 | 29.2 | 58.6 | 131.2 | 22.6 |
| GET(w/MAC) [28] | 81.5 | 39.5 | 29.3 | 58.9 | 131.6 | 22.8 | |
| AS-Transformer(w/vinvl) [29] | 82.3 | 41.0 | 29.8 | 60.0 | 136.1 | 23.8 | |
| Multimodal feature fusion models | PureT [30] | 82.1 | 40.9 | 30.2 | 60.1 | 138.2 | 24.2 |
| TSIC-CLIP [31] | - | 40.3 | 30.1 | 59.6 | 137.9 | - | |
| MMGAT [32] | 83.9 | 42.5 | 31.1 | 60.8 | 144.6 | 24.6 | |
| CAST [33] | 83.1 | 42.2 | 30.8 | 60.6 | 140.6 | 24.7 | |
| Pre-training-based cross-modal representation models | CLIPCap [3] | - | 32.2 | 27.1 | - | 108.4 | 21.2 |
| OFA [34] | - | 43.5 | 31.9 | - | 149.6 | 26.1 | |
| CoCa [35] | - | 40.9 | 33.9 | - | 143.6 | 24.7 | |
| Robustness-enhanced models | PTOD [36] | 81.5 | 39.7 | 30.0 | 59.5 | 135.9 | 23.7 |
| The method of this article | Ours | * 82.9 | * 42.5 | * 32.8 | * 60.6 | * 156.7 | * 24.1 |
| Method Categories | Methods | B-1 | B-4 | M | R | C | S |
|---|---|---|---|---|---|---|---|
| Semantic capture enhancement models | A_R_L [37] | 69.8 | 27.7 | 21.5 | 48.5 | 57.4 | - |
| Multimodal feature fusion models | TSIC-CLIP [31] | - | 26.8 | 23.3 | 48.1 | 63.4 | - |
| Pre-training-based cross-modal representation models | Unified VLP [38] | 30.1 | - | 23.0 | - | 67.4 | 17.0 |
| Robustness-enhanced models | SR-PL [39] | 72.9 | 29.3 | 21.8 | 49.9 | 65.0 | 15.8 |
| Unsupervised/weakly supervised zero-shot generation models | MeaCap [40] | - | 15.3 | 20.6 | - | 50.2 | 14.5 |
| MAGIC [19] | 44.5 | 6.4 | 13.1 | 31.6 | 20.4 | 7.1 | |
| ZeroGen [41] | 54.9 | 13.1 | 15.2 | 37.4 | 26.4 | 8.3 | |
| The method of this article | Ours | * 75.8 | * 34.1 | * 33.9 | * 52.3 | * 78.6 | - |
| Baseline | GAT-LFE | MSG | B-1 | B-4 | M | R | C | S | SUM |
|---|---|---|---|---|---|---|---|---|---|
| √ | 80.2 | 39.8 | 28.3 | 57.9 | 134.5 | 22.4 | 363.1 | ||
| √ | √ | 81.2 | 41.5 | 30.4 | 58.8 | 143.3 | 22.9 | 378.1 | |
| √ | √ | √ | * 82.9 | * 42.5 | * 32.8 | * 60.6 | * 156.7 | * 24.1 | * 399.6 |
| Baseline | GAT-LFE | MSG | B-1 | B-4 | M | R | C | SUM |
|---|---|---|---|---|---|---|---|---|
| √ | 74.5 | 32.4 | 29.1 | 49.7 | 65.8 | 251.5 | ||
| √ | √ | 75.3 | 32.9 | 29.7 | 51.8 | 71.4 | 261.1 | |
| √ | √ | √ | * 75.8 | * 34.1 | * 33.9 | * 52.3 | * 78.6 | * 274.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Zhang, M.; Jiao, M.; Chen, E.; Ma, Y.; Wang, J. Image Captioning Method Based on CLIP-Combined Local Feature Enhancement and Multi-Scale Semantic Guidance. Electronics 2025, 14, 2809. https://doi.org/10.3390/electronics14142809
Wang L, Zhang M, Jiao M, Chen E, Ma Y, Wang J. Image Captioning Method Based on CLIP-Combined Local Feature Enhancement and Multi-Scale Semantic Guidance. Electronics. 2025; 14(14):2809. https://doi.org/10.3390/electronics14142809
Chicago/Turabian StyleWang, Liang, Mengxue Zhang, Meiqing Jiao, Enru Chen, Yuru Ma, and Jun Wang. 2025. "Image Captioning Method Based on CLIP-Combined Local Feature Enhancement and Multi-Scale Semantic Guidance" Electronics 14, no. 14: 2809. https://doi.org/10.3390/electronics14142809
APA StyleWang, L., Zhang, M., Jiao, M., Chen, E., Ma, Y., & Wang, J. (2025). Image Captioning Method Based on CLIP-Combined Local Feature Enhancement and Multi-Scale Semantic Guidance. Electronics, 14(14), 2809. https://doi.org/10.3390/electronics14142809