1. Introduction
The extraction and evaluation of coherent narrative sequences from large document collections has become increasingly important in knowledge discovery and information retrieval applications [
1,
2,
3]. Narrative coherence [
4]—the degree to which a sequence of documents forms a logical, thematically consistent story—is traditionally measured using mathematical metrics based on embedding similarities and topic distributions [
5].
However, these metrics require significant computational resources and domain expertise for interpretation and may not capture the nuanced aspects of coherence that human readers perceive. Thus, these metrics create significant barriers to practical adoption. When a coherence score is 0.73, what does this actually mean for narrative quality? Domain experts such as journalists, intelligence analysts, and researchers often lack the mathematical background to interpret angular similarities in embedding spaces or Jensen–Shannon divergence calculations [
6], limiting their ability to assess and improve extracted narratives.
A fundamental distinction exists between narrative extraction and narrative generation that shapes all evaluation considerations. Narrative generation creates new fictional text from prompts or outlines, producing content that can be evaluated against reference stories or quality metrics. In contrast, narrative extraction identifies and sequences existing documents from collections to reveal underlying stories.
We note that
narrative extraction as a task differs fundamentally from
narrative generation: while generation seeks to create new stories from scratch, extraction seeks to discover the underlying stories by selecting and ordering documents from document collections [
1]. This distinction is crucial: while generation benefits from established metrics like BLEU [
7] or ROUGE [
8] that compare against reference texts, extraction faces a unique challenge—there are no “correct” narratives to serve as ground truth. Multiple valid narratives can be extracted from any document collection, making traditional evaluation paradigms inapplicable. This is not an oversight but a fundamental characteristic of the extraction task. Thus, evaluating extracted narratives requires assessing document selection and ordering quality, not generated text quality.
The field has seen significant advances in timeline summarization [
9,
10,
11] and event-based narrative extraction [
12], with coherence measurement remaining a central challenge. Recent surveys have analyzed the landscape of narrative extraction methods [
1,
2,
3] establishing relevant taxonomies for representations, extraction methods, and evaluation approaches. However, there are several challenges that remain to be solved, such as having effective evaluation metrics and approaches that do not require extensive human evaluation or expensive computations [
1].
Building upon the graph-based approaches pioneered by Shahaf and Guestrin’s
Metro Maps [
13] and Keith and Mitra’s
Narrative Maps [
4] methods, the
Narrative Trails algorithm [
5] addresses narrative extraction by formulating it as a
maximum capacity path problem, where paths maximize the minimum coherence between consecutive documents. This coherence metric [
4] combines angular similarity in high-dimensional embedding spaces with topic similarity based on cluster distributions, which requires a deep understanding of information theory and embedding spaces for interpretation. Although this approach produces mathematically optimal narratives, evaluating their quality remains a challenge [
1]. The field currently has no standardized evaluation methods beyond mathematical coherence metrics. Surveys of narrative extraction [
1] reveal that existing works either use these opaque mathematical metrics or create custom evaluation approaches that cannot be compared across studies. This evaluation gap severely limits the practical adoption of narrative extraction tools.
Recent advances in large language models (LLMs) have demonstrated their capability to perform complex evaluation tasks. The emergence of
LLM-as-a-judge approaches has shown promise in various domains, from creative writing evaluation [
14] to narrative messaging analysis [
15]. Multi-agent evaluation frameworks have shown superior performance over single-agent approaches [
16], while reliability studies have revealed both the strengths and limitations of LLM-based evaluation [
17,
18].
In this article, we investigate whether LLMs can serve as effective proxies for mathematical coherence metrics in the evaluation of narratives defined as sequences of events. This approach could democratize narrative evaluation by providing interpretable assessments without requiring deep technical knowledge of embedding spaces or coherence formulations. In particular, our work makes three primary contributions to the field of narrative extraction evaluation:
We demonstrate that LLM-as-a-judge approaches can serve as effective proxies for mathematical coherence metrics in narrative extraction, achieving meaningful correlations while maintaining high inter-rater reliability across different evaluation modes.
We show that simple evaluation prompts achieve a comparable performance to complex approaches, reaching 85–90% of their effectiveness while using substantially fewer computational resources, providing practical guidance for implementation.
We provide the first scalable evaluation method for narrative extraction that does not require technical expertise in embedding spaces or information theory, making narrative quality assessments accessible to domain experts.
More specifically, we conducted experiments on two contrasting data sets: (1) a focused collection of news articles about Cuban protests and (2) a diverse collection of visualization research papers that span three decades. Our analysis reveals that LLM-based evaluations achieve stronger correlations with mathematical coherence for the heterogeneous scientific paper data set (up to ) compared to the topically focused news data set (up to ). Furthermore, our multi-agent design addresses known biases in LLM evaluation, achieving reliability levels that exceed typical human annotation studies. These findings suggest that simple, well-designed LLM evaluation can bridge the gap between mathematical optimization and practical narrative assessment. Finally, we demonstrate that a simple evaluation achieves a performance comparable to complex approaches, even outperforming them for focused data sets while achieving more than 90% of their performance for diverse data sets. Thus, simple evaluation prompts provide the best cost–performance trade-off.
3. Methodology
3.1. Narrative Extraction
We extract narrative sequences using two contrasting methods to establish a clear quality gradient for evaluation. Max capacity paths represent optimal narratives that maximize the minimum coherence between consecutive documents, extracted using the Narrative Trails algorithm [
5]. These paths solve the maximum capacity path problem on a sparse coherence graph where edge weights represent document-to-document coherence.
Random chronological paths serve as baselines, created by randomly sampling documents in chronological order between the source and target endpoints. For each source–target pair, we sample intermediate documents from those that occur temporally between the endpoints, maintaining chronological order but without coherence optimization. The path length follows a normal distribution that matches the mean and standard deviation of the length of the max capacity paths to ensure a fair comparison.
3.2. Endpoint Sampling Strategy
To ensure a diverse and representative evaluation, we employ a stratified endpoint sampling strategy. This strategy considers multiple approaches to select endpoints with the goal of generating diverse narratives to test our evaluation approaches.
Figure 1 illustrates the coverage achieved by our sampling approach in both data sets.
The sampling strategy balances six different approaches to capture various types of narratives. Within-cluster short temporal paths (20%) select endpoints from the same topical cluster with minimal temporal distance, testing coherence for focused narratives. Within-cluster long temporal paths (20%) choose endpoints from the same cluster but separated by significant time, evaluating how well the system handles topic evolution. Cross-cluster close temporal paths (20%) select endpoints from different clusters within similar time periods, assessing thematic transitions. Cross-cluster far temporal paths (20%) combine different clusters and time periods, testing the system’s ability to bridge diverse content. Hub-to-peripheral paths (10%) connect highly connected documents to sparsely connected ones, evaluating navigation from central to niche topics. Spatial extremes (10%) select endpoints that are maximally separated in the embedding space, testing coherence across semantic distances.
The sampling process also ensures connectivity within the sparse coherence graph, rejecting endpoint pairs without valid paths. We generated 200 endpoint pairs for the news data set and 100 endpoint pairs for the scientific papers data set.
3.3. LLM-as-a-Judge Framework Overview
We evaluate narratives using GPT-4.1 with four distinct evaluation modes, each designed to capture different aspects of narrative coherence. To ensure reliability and measure consistency, we employ K independent LLM agents ( for news and for scientific articles) with variable temperature settings (0.3 to 0.7) and different random seeds. We note that we initially evaluated the news data set using agents to ensure that the results were reliable and consistent between the different agents. We note that the resulting high inter-rater reliability (ICC(2,1) > 0.96) demonstrated that even single agents provide consistent evaluations. Based on this empirical evidence, we reduced the value of K to simply three agents for the VisPub data set to manage computational costs while maintaining statistical reliability. This decision was validated by similarly high ICC values (>0.92) for the scientific papers data set, which confirmed that three agents provide sufficient coverage for a reliable evaluation.
We note that our election of OpenAI’s GPT-4.1 is based on empirical evidence demonstrating its effectiveness in narrative and coherence assessment tasks. Recent studies have shown that GPT-4 achieves human-level performance in evaluating discourse coherence [
54], with agreement rates exceeding 80% with human judgments [
55]. The G-Eval framework demonstrated that GPT-4 achieves Spearman correlations of 0.514 with human evaluations on creative text tasks [
34], while maintaining high inter-rater reliability (ICC > 0.94) across evaluation periods [
56]. While newer models may offer incremental improvements, comparative studies show that GPT-4 already operates within the range of human inter-rater reliability for adjacent narrative assessment tasks [
14], making further improvements marginal for our purposes.
Furthermore, the model’s training data (through 2021) encompasses our evaluation period, ensuring familiarity with both news events (2016–2021) and scientific literature evolution (1990–2022). Critically, OpenAI’s stable API availability addresses reproducibility concerns that plague rapidly evolving language model research [
57]. By establishing our methodology with GPT-4, we enable direct comparison with future work, as newer models can be evaluated against this baseline. Finally, we note that our objective is not to use the latest state-of-the-art models to maximize evaluation performance, but to demonstrate that LLM-as-a-judge approaches can serve as effective proxies for mathematical coherence metrics in narrative extraction. In this context, GPT-4’s documented capabilities are more than sufficient to achieve this goal [
58,
59].
3.4. Evaluation Modes and Prompt Design Rationale
Our four evaluation modes were designed following principles derived from both narrative theory and LLM evaluation best practices. Each mode tests different hypotheses about what constitutes effective narrative evaluation.
3.4.1. Simple Evaluation
The simple evaluation tests whether minimal instruction suffices for narrative assessment. By requesting only a coherence score without additional guidance, we establish a baseline that relies entirely on the model’s pre-trained understanding of narrative quality. This approach minimizes prompt engineering effects and computational costs while testing whether sophisticated evaluation frameworks are necessary.
In particular, the simple mode requests a single coherence score (1 to 10) based on the way the articles flow together. The prompt emphasizes the general flow of the narrative without requiring detailed analysis, making it the most efficient approach. We show the prompt used in this case in
Figure 2.
3.4.2. Chain-of-Thought (CoT) Evaluation
The Chain-of-Thought approach applies reasoning transparency principles to narrative evaluation. By explicitly decomposing the evaluation into steps that examine consecutive connections, overall flow, and jarring transitions, we test whether structured reasoning improves correlation with mathematical coherence. This design follows evidence that step-by-step analysis improves LLM performance on complex tasks while providing interpretable reasoning traces.
In particular, the CoT mode guides the model through systematic analysis by examining connections between consecutive articles, assessing the general narrative flow, identifying jarring transitions, and synthesizing these observations into a final score. This structured approach aims to improve the quality of the evaluation through explicit reasoning. We show the prompt used in this case in
Figure 3.
3.4.3. Standard Evaluation
The standard evaluation operationalizes narrative quality through four fundamental dimensions drawn from narrative theory: logical flow (causal connections), thematic consistency (topical coherence), temporal coherence (chronological ordering), and narrative completeness (story arc). These dimensions map to key components of the mathematical coherence metric while remaining interpretable to non-technical users.
In particular, the standard mode evaluates four specific dimensions: logical flow (how well articles connect logically), thematic consistency (the consistency of themes throughout), temporal coherence (whether events follow a reasonable timeline), and narrative completeness (whether the sequence tells a complete story). The overall score averages these dimensions. We show the prompt used in this case in
Figure 4.
3.4.4. Complex Evaluation
The complex evaluation extends assessments to six fine-grained criteria, testing whether additional granularity improves evaluation quality. The criteria—semantic coherence, topic evolution, information density, causal relationships, narrative arc, and contextual relevance—capture nuanced aspects of narrative quality that might be overlooked in simpler evaluations.
In particular, the complex mode assesses six detailed criteria: semantic coherence (conceptual flow between articles), topic evolution (the smoothness of topic transitions), information density (the appropriateness of pacing), causal relationships (the clarity of cause–effect connections), narrative arc (the completeness of story structure), and contextual relevance (the relevance of each article to the overall narrative). We show the prompt used in this case in
Figure 5.
3.4.5. Experimental Design
Our experimental design inherently provides both ablation analysis and robustness testing. The four evaluation modes (simple, Chain-of-Thought, standard, and complex) constitute a systematic ablation study where each mode progressively adds evaluation complexity. This allows us to isolate the contribution of different prompt components: from minimal instruction (simple) to structured reasoning (CoT) to multi-dimensional assessment (standard and complex). Additionally, our multi-agent approach with K independent evaluators using different temperature settings (0.3 to 0.7) and random seeds provides robustness testing across model parameters, ensuring our results are not artifacts of specific sampling configurations. This progression from simple to complex allows us to empirically determine the optimal trade-off between evaluation complexity and practical efficiency.
3.4.6. Chain-of-Thought Usage
We note that Chain-of-Thought reasoning could be applied to the standard and complex evaluation modes, requiring step-by-step analysis for each dimension. However, we decided against this combination for several reasons. First, the standard and complex modes already provide structured decomposition through their multiple evaluation criteria, achieving similar benefits to Chain-of-Thought by guiding the model through specific aspects of narrative quality. Adding explicit reasoning steps for each dimension would introduce redundancy rather than additional insight. Second, the computational cost would increase substantially, requiring 4–6 times more tokens for complete reasoning traces across all dimensions. Third, maintaining these as separate evaluation modes provides clearer experimental comparisons, allowing us to isolate the effects of structured reasoning (CoT) versus multi-dimensional assessment (standard/complex). Our results validate this decision, as the standard and complex modes achieve strong performance without explicit reasoning steps, suggesting that dimensional decomposition alone provides a sufficient evaluation structure.
3.4.7. Score Calibration
We note that we intentionally varied the score anchoring guidance across evaluation modes to test the robustness of LLM evaluation to different scoring frameworks. The Chain-of-Thought mode defines moderate coherence as scores 4–6, while the complex mode shifts this range to 5–7. Similarly, what constitutes “very poor” versus ”exceptional” narratives receives different numerical mappings across modes. This variation tests whether LLM evaluators can maintain consistent quality assessments despite different calibration instructions, which is a critical concern for practical deployment where users might provide varying scoring guidelines.
Our results validate this approach: despite different score anchoring, all evaluation modes achieve high inter-rater reliability (ICC > 0.92) and significant correlations with mathematical coherence. The multi-agent design further demonstrates that independent evaluators converge on consistent quality gradients regardless of specific numerical guidance. This robustness to prompt variations suggests that LLMs assess narrative quality based on learned representations rather than merely following numerical instructions, making the approach resilient to variations in evaluation setup.
Furthermore, we note that the evaluation modes intentionally employ different scoring guidance strategies, which serve as a test of the robustness of LLM evaluation to different point anchoring strategies:
Simple evaluation: provides no explicit score definitions, relying entirely on the model’s pre-trained understanding of a 1–10 scale.
Chain-of-Thought: defines explicit ranges (1–3 for very poor, 4–6 for moderate, 7–9 for good, and 10 for excellent).
Standard evaluation: offers point anchors (5 = adequate, 7 = good, and 10 = exceptional) without defining ranges.
Complex evaluation: uses behavioral descriptions (e.g., “random sequences should score low”).
This diversity, which includes cases with no explicit guidance, ranges, and point estimates, tests whether a coherent evaluation emerges from the model’s understanding rather than rigid adherence to numerical instructions. Despite these variations, all modes achieve high inter-rater reliability (ICC > 0.92) and significant correlations with mathematical coherence, demonstrating that LLMs can maintain consistent quality assessment across different calibration approaches. This robustness is crucial for practical deployment, where users may provide varying levels of scoring guidance.
5. Results
5.1. Extracted Narrative Lengths
The narratives extracted exhibit distinct characteristics that reflect both the underlying document collections and the extraction methods used.
Table 1 presents the path length statistics for both data sets and extraction methods.
Although we designed random chronological path generation to match the length distribution of maximum capacity paths following a normal distribution, in practice, this goal was only achieved for the VisPub data set (difference of 0.27, ). For the news data set, the random paths were significantly shorter (difference of 0.73, ), though this represents less than one document on average. Given that path lengths are discrete positive integers, this means that random paths in the news data set typically contain one fewer document than their maximum capacity counterparts.
Despite this length discrepancy, the comparison remains informative. In fact, the shorter random paths in the news data set could theoretically have an advantage in maintaining coherence, yet maximum capacity paths still achieve substantially higher coherence scores. VisPub narratives are on average 25 to 44% longer than news narratives depending on the method, reflecting the greater temporal span and topical diversity of the scientific literature collection.
5.2. Overall Performance Comparison
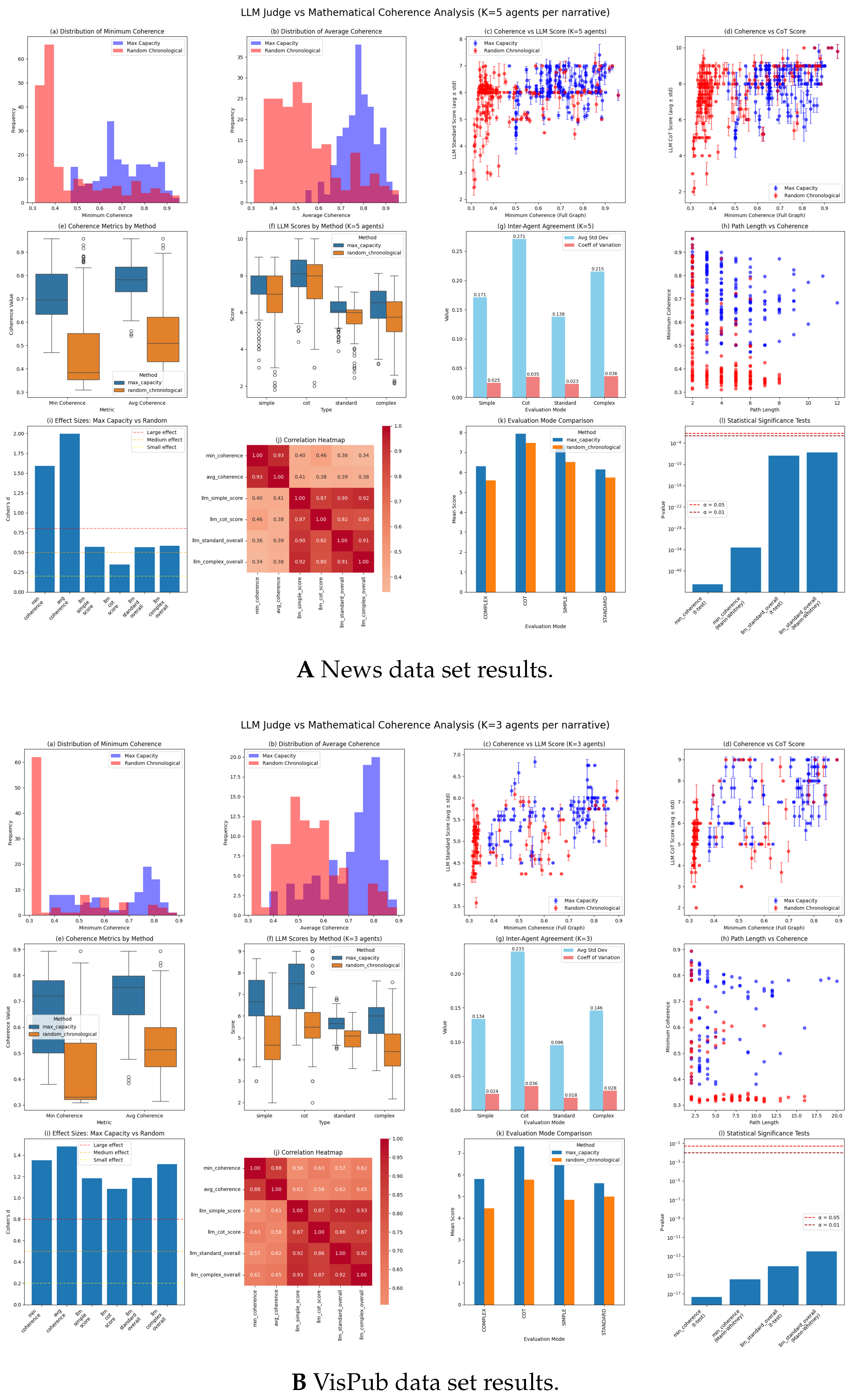
Figure 8 presents the analysis of the LLM judge performance in both data sets. Several key patterns emerge from this comparison. In general, both data sets show clear discrimination between maximum capacity and random paths, with stronger correlations observed in the diverse VisPub data set. In detail,
Figure 8 shows the following key results:
- (a)
The distribution of minimum coherence values comparing the maximum capacity paths and random chronological paths, showing the frequency of minimum coherence scores for each path extraction method.
- (b)
The distribution of the average coherence values comparing the maximum capacity paths and random chronological paths, showing the frequency of mean coherence scores along entire paths for each path extraction method.
- (c)
Scatter plots with error bars showing the relationship between minimum coherence and LLM judge evaluation scores using the simple approach, with error bars representing the standard deviation in the evaluation of the K agents.
- (d)
Scatter plots with error bars displaying the relationship between minimum coherence and LLM judge evaluation scores using the Chain-of-Thought approach, with error bars representing the standard deviation in the evaluation of the K agents.
- (e)
Box plots comparing the distribution of minimum and average coherence metrics between max capacity and random chronological path extraction methods.
- (f)
Box plots showing the distribution of LLM evaluation scores across different evaluation modes (simple, CoT, standard, and complex) for both path extraction methods.
- (g)
Bar charts displaying inter-agent agreement metrics, showing the average standard deviation and coefficient of variation across K agents for each evaluation mode.
- (h)
Scatter plots examining the relationship between path length (the number of documents) and minimum coherence, color-coded by path extraction method.
- (i)
Bar charts showing Cohen’s d effect sizes for each metric, comparing the ability to discriminate between the maximum capacity and random paths, with reference lines for small, medium, and large effects.
- (j)
Heat maps showing Pearson correlation coefficients between mathematical coherence metrics and LLM evaluation scores in different modes.
- (k)
Grouped bar charts comparing mean LLM evaluation scores between path extraction methods across different evaluation modes (simple, CoT, standard, and complex).
- (l)
Bar graphs showing p-values of the statistical significance tests (t-test and Mann–Whitney U) for each metric, with reference lines at significance levels and .
The distribution of mathematical coherence values differs substantially between data sets. The coherence distribution of the news data set shows that maximum capacity paths are concentrated around 0.70–0.75 minimum coherence, while random paths cluster around 0.47. The VisPub data set exhibits broader distributions, with maximum capacity paths ranging from 0.4 to 0.9 and random paths showing much lower minimum coherence values in general, as shown by the high frequency of 0.30 minimum coherence paths. This difference reflects the focused nature of the news content versus the topical diversity of scientific papers.
The average coherence metrics reveal consistent patterns in both data sets. Max capacity paths achieve mean minimum coherence of 0.705 (news) and 0.648 (papers), compared to 0.470 and 0.433 for random paths, respectively. The effect sizes (Cohen’s d) for mathematical coherence are 1.59 (news) and 1.35 (papers), indicating strong discrimination between path types.
5.3. Correlation Analysis
Table 2 reveals the underlying differences between the data sets. The VisPub data set consistently shows stronger correlations between LLM evaluations and mathematical coherence, with the complex evaluation mode achieving
with average coherence. The news data set peaks at
using the Chain-of-Thought evaluation approach with minimum coherence.
These differences suggest that LLM judges perform better in diverse, heterogeneous content where they can leverage broader knowledge to identify thematic connections. The focused nature of the news data set, covering a single topic over a short time span, may limit the discriminative signals available to LLM evaluators, as even a random sample might suffice to describe a coherent narrative when there is not much freedom of choice.
5.4. Inter-Agent Agreement
Our experimental design used agents for the news data set and for the VisPub data set. We note that this difference arose from our sequential experimental approach: initial results from the news data set demonstrated high inter-rater reliability (ICC(2,1) = 0.961), indicating that fewer agents would suffice for reliable evaluation. Therefore, we reduced the number of agents to for the computationally more expensive VisPub data set. We note that this decision was validated by consistent high reliability metrics (ICC(2,1) > 0.92) across both data sets. These results suggest that even K = 3 provides more than adequate statistical power for the narrative evaluation based on LLMs.
In general,
Table 3 demonstrates high inter-rater reliability in all evaluation modes. The values of ICC(2,
K) exceed 0.97 for all conditions, indicating that the average of the
K agents provides highly reliable scores. ICC(2,1) values all exceed 0.92 in all conditions, thus showing that even if we followed a single-agent approach, the LLM-as-a-judge approach to evaluate narrative extraction has remarkably high consistency. Krippendorff’s alpha values above 0.92 confirm substantial agreement even when accounting for chance.
The simple evaluation mode achieves the highest exact agreement rates (>81%), while the complex modes show lower exact agreement but maintain near-perfect within-1 point agreement. This pattern suggests that, while agents may differ in precise scores in complex evaluations, they consistently identify the same quality gradients.
For practitioners, our analysis of results suggests that agents represent an optimal balance between reliability and computational cost, as the marginal improvement from additional agents is negligible given the ICC(2,K) values already exceed 0.97. Indeed, the ICC(2,1) values above 0.92 indicate that even single-agent evaluation could be sufficient for many practical applications, offering a cost-effective alternative without substantial reliability loss.
5.5. Discrimination Between Path Types
Table 4 reveals that LLM evaluations successfully discriminate between high-quality and baseline narratives, although with varying effectiveness between data sets. For the VisPub data set, the complex LLM evaluation achieves discrimination (
) that is close to that of mathematical coherence (
). The news data set shows weaker discrimination for all LLM modes (
d = 0.35–0.58), suggesting that focused, temporally constrained narratives pose greater challenges for LLM evaluation.
The AUC-ROC values confirm these patterns, with VisPub achieving values near 0.80 for most LLM modes, comparable to mathematical metrics. The news data set shows moderate discrimination (AUC 0.59–0.66), still significantly better than chance but indicating room for improvement.
5.6. Cost–Performance Trade-Offs
Table 5 presents detailed computational requirements for each evaluation mode based on smaller-scale experiments with the VisPub data set using 60 narratives evaluated with a single agent (
) to isolate the per-evaluation costs. The narratives were generated by taking 30 endpoint pairs and generating narratives using both the max capacity and the random path approaches. Token counts were measured using OpenAI’s
tiktoken library and include both the evaluation prompt and the narrative content (article titles formatted as a numbered list).
The simple evaluation approach uses approximately 123 input tokens per narrative, while the complex evaluation approach requires approximately 225 tokens. Token usage for Chain-of-Thought evaluation is highest at 279 tokens due to the structured reasoning steps. While timing measurements show low variance (0.016 to 0.114 s standard deviation), token usage exhibits higher variability (±53.9 tokens) due to the diverse narrative lengths in our sample (5.6 ± 3.4 documents).
The variability in our results reflects real-world usage patterns, where narratives naturally vary in length. The 60-narrative sample captures this distribution adequately, as larger samples would show similar variance patterns rather than converging to a tighter estimate. The consistent mean token differences between the evaluation modes (123 for simple vs. 279 for CoT) demonstrate that the sample size is sufficient to distinguish computational requirements between approaches. We note that these measurements reflect input tokens only and do not include the model’s response tokens.
The relationship between cost and performance is non-linear. For the VisPub data set, where our computational measurements were conducted, the progression from the simple evaluation approach () to the complex evaluation approach () represents a 7% improvement at 83% increased token usage. Chain-of-Thought evaluation shows particularly poor cost-effectiveness, requiring 127% more tokens than simple evaluation while achieving a lower correlation (). Although we did not measure computational costs on the news data set, the correlation patterns observed suggest even weaker cost–performance benefits from increased complexity. While Chain-of-Thought achieves the highest correlation for news () compared to simple evaluation (), this 12% improvement would come at the cost of 127% more tokens if token usage patterns are similar across data sets, which is a reasonable assumption given comparable prompt structures. Complex evaluation performs worst on news (), suggesting that increased complexity does not guarantee better performance.
Beyond token usage, we note that the temporal costs vary substantially across evaluation modes. Chain-of-Thought evaluation requires 6.001 s per narrative, approximately 9.3 times longer than simple evaluation (0.647 s), while achieving mixed results across data sets. Standard and complex evaluations require 0.867 and 1.034 s, respectively, representing 34% and 60% increases over the simple evaluation. These timing measurements used a single agent () to isolate the per-evaluation costs; our main experiments used agents for news and for VisPub, multiplying these costs proportionally.
The practical implications become apparent at scale. Evaluating 1K narratives with a single agent would require approximately 11 min with simple evaluation versus 1.7 h with Chain-of-Thought. Our main experiments, which evaluated 600 narratives across four evaluation modes with multiple agents, required approximately 12 h of execution time in total. However, we note that this includes network latency, API rate limiting, and data processing overhead.
In theory, using only the simple evaluation mode would reduce this to approximately 1.5 to 2 h. For studies processing larger narrative collections, the selection of the evaluation mode significantly impacts computational feasibility. These findings suggest that simple evaluation provides the best balance between computational efficiency and evaluation quality, achieving 85–90% of complex approach performance while requiring minimal resources.
5.7. Out-of-Distribution Robustness
To test whether our approach correctly identifies adversarial narratives, we created 60 out-of-distribution (OOD) narratives by mixing documents from news articles and scientific papers. We generated two types of adversarial sequences: (1) alternating narratives that switch between domains at every step, and (2) random mixed narratives that select documents randomly from the combined corpus. In particular, we generated 30 OOD narratives of each type for our evaluation.
Both OOD narrative types received significantly lower scores than typical narratives in our main experiments. Alternating narratives achieved mean LLM scores of and mathematical coherence of , while random mixed narratives scored slightly higher at and , respectively. These scores fall well below the coherent narrative baselines observed in our main experiments (typically 6–8 for LLM scores and 0.6–0.8 for mathematical coherence).
Notably, the correlation between mathematical coherence and LLM scores remains strong even for these adversarial examples (, ), demonstrating that the LLM-as-a-judge approach maintains its validity outside normal operating conditions. The significant difference between alternating and random mixed narratives (, , Cohen’s ) suggests that LLMs can distinguish between different types of incoherence, with strictly alternating domain switches being recognized as particularly disruptive to narrative flow.
These results confirm that our approach exhibits appropriate behavior when faced with adversarial inputs, correctly identifying incoherent narratives regardless of how they were constructed. Thus, the ability of the proposed LLM-as-a-judge approach to maintain a strong correlation with mathematical metrics while providing interpretable assessments in an adversarial context provides further support for its use in practical applications.
5.8. Follow-Up Analyses
Figure 9 summarizes extensive follow-up analyses on the main results that provide a deeper understanding of the evaluation behavior of LLMs. In detail,
Figure 9 shows the following results:
- (a)
A bar graph comparing the performance of predictive modeling ( scores) obtained by different regression models to predict LLM evaluation scores from mathematical coherence metrics.
- (b)
A bar chart displaying the average standard deviation of agent evaluations across different evaluation modes, illustrating the level of inter-agent disagreement for each approach.
- (c)
A scatter plot examining the relationship between temporal span (in days/years) and minimum coherence, with points colored by LLM standard evaluation scores to show how temporal distance affects both mathematical and LLM-based coherence assessments.
- (d)
A hexbin density plot showing the relationship between path complexity scores (derived from coherence variance, path efficiency, and weak link ratio) and LLM standard evaluation scores, revealing how narrative complexity impacts evaluation.
- (e)
A histogram showing the distribution of evaluation errors (the difference between normalized LLM scores and normalized mathematical coherence), with a vertical reference line at zero indicating perfect agreement.
- (f)
A grouped bar chart comparing mean mathematical coherence and mean LLM evaluation scores (scaled) between max capacity and random chronological path generation methods, providing a summary comparison of method performance.
5.8.1. Predictive Modeling
Random forest models that predict LLM scores from mathematical coherence metrics achieve
values of 0.40 to 0.55 for the VisPub data set, compared to 0.29 to 0.41 for news data. A feature importance analysis reveals that
average coherence along the path contributes more to predictions (52–62% importance) than
minimum coherence (27–36%) or
path length (8–13%). This suggests that LLMs consider the overall narrative flow rather than focusing solely on the weakest links.
Table 6 shows the performance of the evaluated models and
Table 7 shows the analysis of the importance of the characteristics for the best model (random forests).
5.8.2. Agent Disagreement Patterns
Agent disagreement varies systematically with score ranges and evaluation modes. The Chain-of-Thought evaluation approach shows the highest disagreement, with a mean standard deviation of 0.27 for news articles and 0.23 for scientific articles. In contrast, the simple evaluation approach maintains the lowest variations with standard deviations of 0.17 and 0.13, respectively. Disagreement peaks for narratives that receive medium scores (5–7 range) and decreases for very high or very low scores, suggesting greater consensus on clearly good or bad narratives.
Table 8 summarizes the results of agent disagreement patterns.
5.8.3. Temporal Analysis
Temporal span shows minimal correlation with coherence for both mathematical metrics and LLM evaluations. We note that news data spans are measured in days and publication data spans are measured in years. The news data set does not show significant temporal effects. In contrast, the VisPub data set reveals slight negative correlations ( to ) between the temporal span and the coherence scores, indicating that narratives that span many years face modest coherence challenges. However, optimal coherence occurs for moderate temporal spans (3–5 years), balancing topical evolution with maintaining connections.
5.8.4. Path Complexity Effects
An analysis of path complexity beyond simple length reveals interesting patterns. The coherence variance along paths correlates negatively with LLM scores ( to ), indicating that consistent quality throughout the narrative matters more than achieving high peak coherence. The weak link ratio (edges below median coherence) shows the strongest negative correlation with LLM scores (), confirming that LLMs penalize narratives with notable weak points.
5.9. Cross-Validation Stability
Five-fold cross-validation confirms the stability of our findings. The correlation between mathematical coherence and LLM evaluations shows minimal differences between train and test sets in all folds (mean absolute difference < 0.05), indicating a stable generalization. The effect sizes for the discriminating path types remain stable across folds, with standard deviations below 0.2 for Cohen’s d values. These results indicate that our findings generalize well within each data set and are not artifacts of particular endpoint selections.
6. Discussion
6.1. Data Set Characteristics and LLM Performance
The substantial performance difference between the data sets (maximum for VisPub versus for news) illuminates when the LLM-as-a-judge approach excels. The VisPub data set spans 30 years and 171 topics, providing a rich semantic space for LLMs to identify meaningful connections. Topics range from early volume rendering research to modern applications of machine learning in visualization, offering diverse conceptual bridges for narrative construction.
In contrast, the focus on the Cuban protests within a single year constrains the semantic space associated with the news data set. Although this provides a clear temporal narrative structure, it can limit the distinctiveness of features that LLMs use for quality assessment. The bimodal distribution of coherence scores in the news data set suggests that even random paths within this focused collection maintain reasonable coherence, making discrimination more challenging.
6.2. Evaluation Mode Effectiveness
The Chain-of-Thought evaluation shows interesting data-set-dependent behavior, achieving the best performance for both data sets in terms of minimum coherence (i.e., max capacity coherence). In particular, this method obtained a higher correlation in the scientific papers data set () compared to the news data set (). However, in terms of average coherence, we see that the other approaches provide a better result in terms of correlations. The best approach for the news data set is the simple prompt and for the scientific papers data set is the complex prompt.
However, in general, we found that the simple evaluation achieves a performance of 85–90% of the more complex evaluation approaches—including CoT and complex versions of judge prompts—while requiring less computational resources, which has important practical implications. For large-scale narrative evaluation tasks, simple prompts provide an efficient solution without substantial quality sacrifice. The marginal improvements from complex evaluation modes may not justify their computational costs for most applications.
6.3. Reliability and Consistency
The high inter-rater reliability (ICC > 0.96) across all conditions demonstrates that LLM evaluations are highly reproducible when using multiple agents with controlled variation. The near-perfect within-1 point agreement (>98%) indicates that while agents may differ in exact scores, they consistently identify quality gradients. This reliability is crucial for practical applications where consistent evaluation standards are required.
The lower exact agreement for complex evaluation modes (25–30%) compared to simple modes (>81%) suggests that increased evaluation complexity introduces more subjective interpretation. However, the maintained high correlation with mathematical metrics indicates that this variation occurs around consistent quality assessments rather than fundamental disagreements.
It should be noted that multi-agent systems show diminishing returns for most evaluation tasks [
61]. In particular, as the number of agents increases, further coordination structures are required to obtain significant performance improvements [
62].
6.4. Implications for Narrative Evaluation
Our results suggest different strategies for different content types. For diverse, long-spanning document collections, such as research papers, LLM-as-a-judge approaches provide effective proxies for mathematical coherence, potentially replacing complex calculations with interpretable assessments. For focused collections with limited topical variation, mathematical metrics may remain necessary to capture subtle coherence distinctions that LLMs struggle to identify.
The success of simple evaluation modes democratizes narrative assessment, making it accessible to practitioners without deep technical expertise. Rather than understanding embedding spaces and information theory, users can leverage LLM evaluations to assess narrative quality in natural language terms.
6.5. Limitations and Future Directions
Several limitations warrant consideration. Our evaluation uses a single LLM family (GPT-4), and performance may vary between different architectures. The English-only evaluation leaves unanswered questions about the multilingual narrative assessment. The two data sets, while contrasting and providing an appropriate baseline for news data and scientific papers data, do not represent all types of document collection.
Additionally, we do not propose new model architectures, training paradigms, or data collection strategies; instead, our contribution lies in demonstrating that existing LLMs can effectively evaluate narrative extraction without requiring specialized models or training data, which itself has practical value for immediate deployment.
Furthermore, although recent work by Chen et al. [
18] has documented significant biases in LLM judges including position bias, verbosity bias, and self-enhancement bias, these limitations can be partially mitigated through multi-agent evaluation and careful prompt design.
Future work should explore performance across different LLM architectures, including open-source models that enable a deeper analysis of evaluation mechanisms. Multilingual evaluation presents unique challenges, as narrative coherence could manifest differently across languages and cultures. Domain-specific fine-tuning could potentially improve performance for specialized collections while maintaining general capabilities.
Hybrid approaches that combine mathematical and LLM-based metrics merit investigation. LLMs could provide interpretable explanations for mathematical coherence scores, or mathematical metrics could guide LLM attention to critical narrative elements. Such combinations might achieve better performance than either approach alone while maintaining interpretability.
7. Conclusions
We demonstrate that LLM-as-a-judge approaches provide effective proxies for mathematical coherence metrics in narrative evaluation, with performance strongly influenced by data set characteristics. For diverse document collections spanning multiple topics and time periods, LLM evaluations achieve correlations up to 0.65 with mathematical coherence while successfully discriminating between algorithmically optimized and random narratives with effect sizes exceeding 1.0. For focused collections with limited topical variation, the correlations remain moderate (up to 0.46) but still significant.
Simple evaluation prompts emerge as the most practical choice, achieving 85–90% of complex mode performance with lower computational costs. Combined with high inter-rater reliability (ICC > 0.96) and near-perfect within-1 point agreement, this makes LLM evaluation accessible for large-scale narrative assessment tasks.
These findings have immediate practical applications for the digital humanities, investigative journalism, and reviews of the literature in scientific research, where understanding the narrative connections between document collections is crucial. By providing interpretable assessments without requiring technical expertise in embeddings or information theory, LLM-as-a-judge approaches democratize narrative evaluation while maintaining strong alignment with mathematical quality metrics. As LLM capabilities continue to advance, these evaluation approaches will likely become increasingly central to narrative understanding and knowledge discovery applications.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}