
Model-Driven Meta-Learning-Aided Fast Beam Prediction in Millimeter-Wave Communications





Abstract
1. Introduction
1.1. Relevant Research
1.2. Contribution
- Firstly, we use experience replay to select key data for storage, supporting effective learning while retaining old tasks. Then, we optimize neural network parameters to balance new task adaptation and old task retention.
- In addition, we propose an optimization strategy for beam prediction based on MER. The data samples selected through the experience playback strategy are fed back to the main hierarchy to influence the update of the weights . This model is able to learn a new task while maintaining the memory of the old task, realizing the goal of continuous learning.
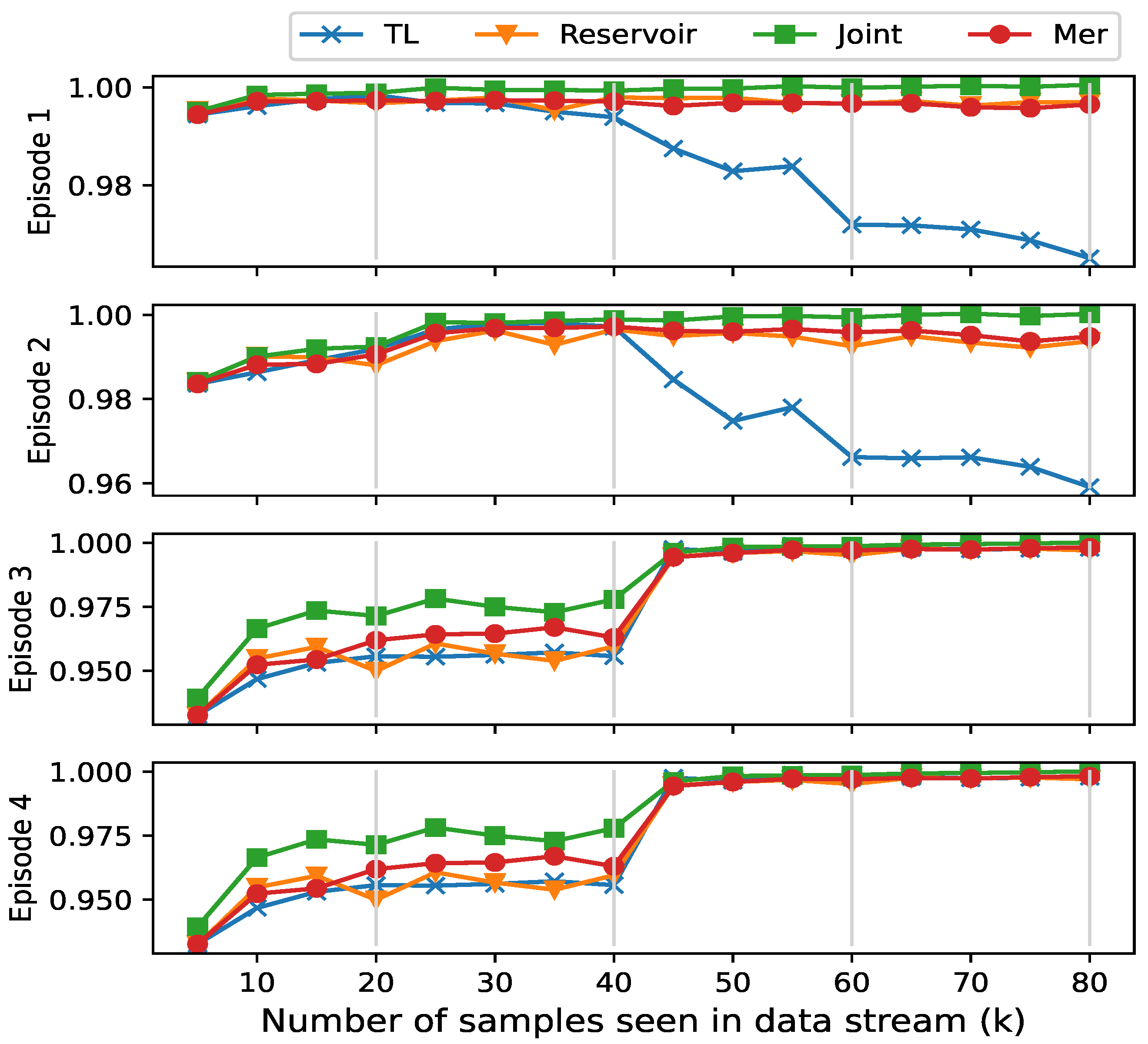
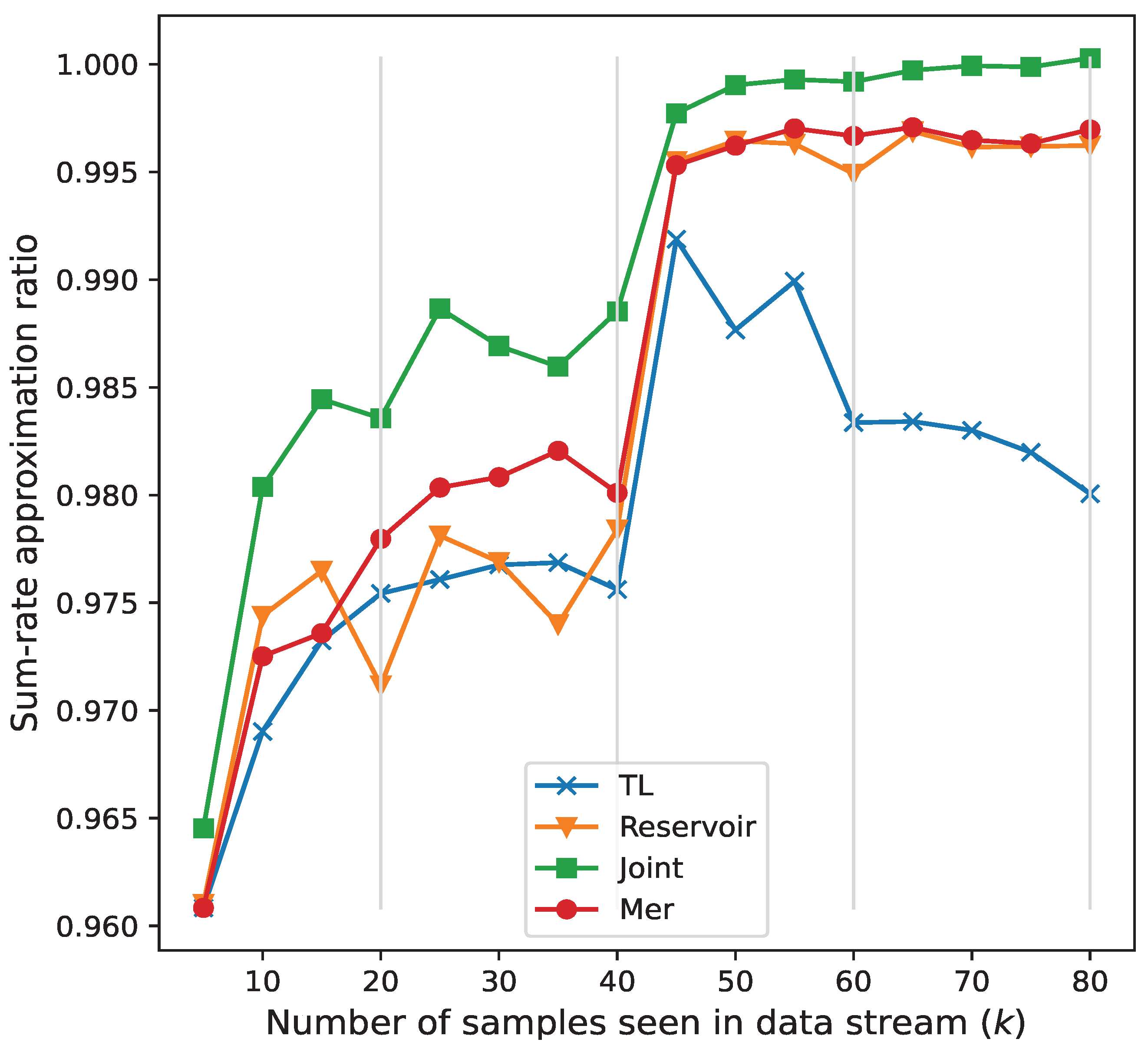
- Finally, we propose an MER-based continuous learning beam prediction model for dynamic downlink multiple-input single-output (MISO) systems. The model uses meta-learning to optimize beamforming and adapt quickly to dynamic environments. Experiments show that it outperforms transfer learning (TL) [26] and Reservoir [34], maintaining strong performance in dynamic task assignments.
- Notations: The boldface lowercase letters and capital letters are used to represent column vectors and matrices, respectively. is the square of the modulus used to compute the vector, and the notation represents the trace operator of the matrix. The notation denotes the Hermitian conjugate transpose of a vector, and denotes the Gaussian distribution.
2. System Model and Problem Formulation
3. MER-Based Beam Prediction Optimization
3.1. Beamforming Vector Decomposition
3.2. A System for Learning to Learn Without Forgetting
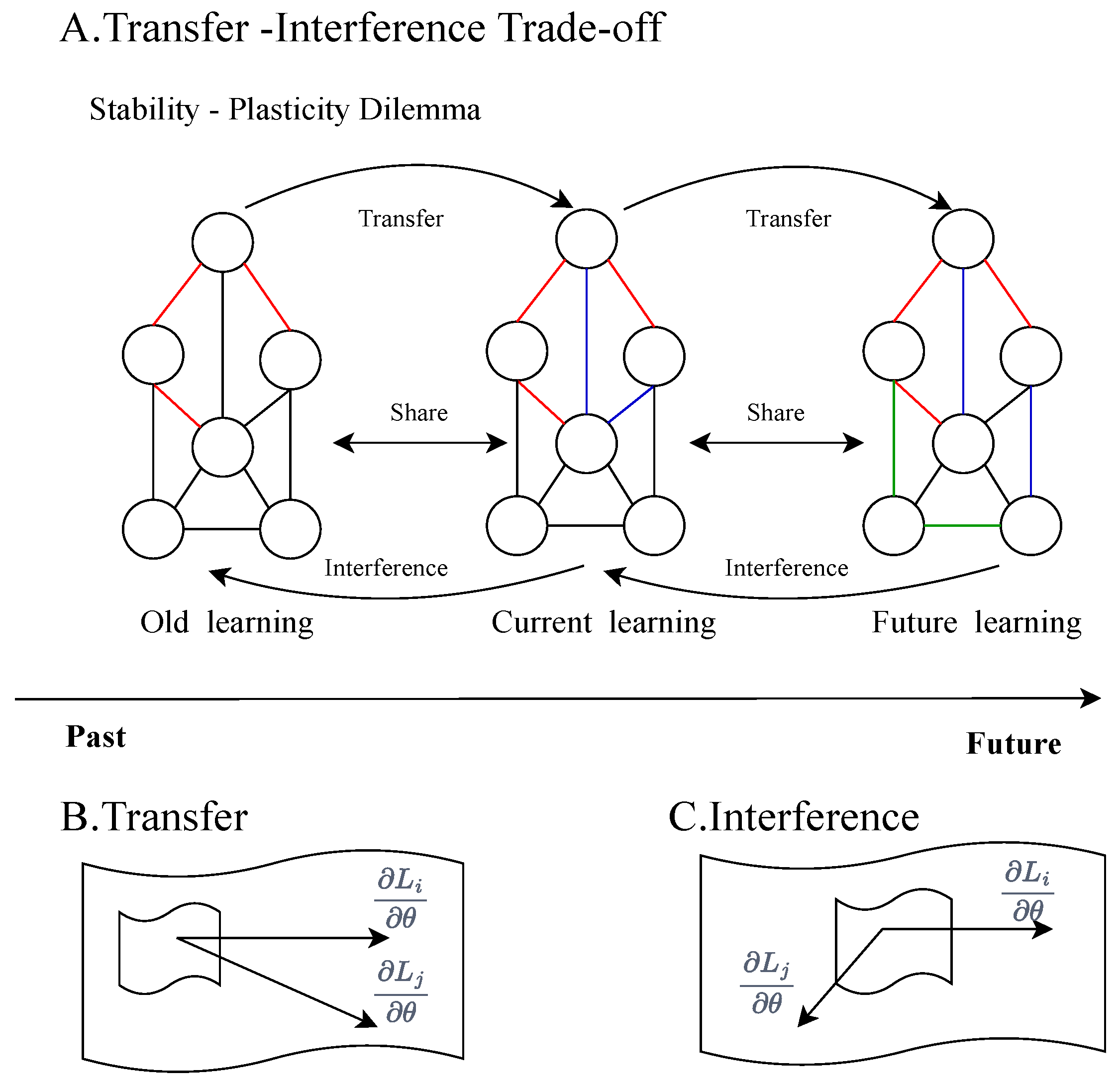
- (A)
- The trade-off between stability and malleability is a long-standing challenge in the field of machine learning, especially in continuous or lifelong learning scenarios. This dilemma concerns how to effectively maintain stability with respect to old knowledge while learning the current task. If a learning system is too stable, it may exhibit low plasticity when integrating new knowledge, making it difficult to adapt to new tasks or environmental changes. Conversely, if a system is too malleable, it may quickly forget old tasks as it learns new ones, a phenomenon known as catastrophic forgetting [39,40,41]. To address this problem, researchers have been exploring how to find the right balance between stability and plasticity so that the learning system can learn new knowledge while maintaining mastery of old knowledge. This balance is crucial for improving the overall performance and adaptability of learning systems, especially in application scenarios that require long-term memory and rapid adaptation to new situations.
- (B)
- A portion of what is shown in the figure reveals the phenomenon of shifting in the weight space, a phenomenon that indicates the potential positive impact that may be exerted on older tasks when learning the current task. In machine learning models, if the gradient directions of different tasks are the same or very close to each other, learning one of them may not only improve the performance of that task but may also positively contribute to the performance of other tasks. This phenomenon is particularly important in multi-task learning or continuous learning environments because it implies that the efficiency and effectiveness of the model in dealing with diverse tasks can be improved by effectively sharing and transferring knowledge. The consistency of this gradient can be viewed as the existence of some form of knowledge association between different tasks, allowing the model to reuse existing knowledge when learning a new task, leading to faster adaptation and better generalization capabilities.
- (C)
- The other part describes the interference phenomenon in the weight space, which is the opposite of transfer and refers to the negative impact on the old task when learning the current task. When the gradients of the old and new tasks are in opposite or conflicting directions, learning the new task may result in forgetting the knowledge of the old task or performance degradation. All in all, this figure aims to illustrate how to maintain the memory of the old task while learning the new task in a CL environment and how to balance the learning of the old and new tasks by sharing the weights in a reasonable way to avoid catastrophic forgetting. The algorithm proposed in the paper is designed to address this problem by optimizing this trade-off through experience playback and meta-learning.
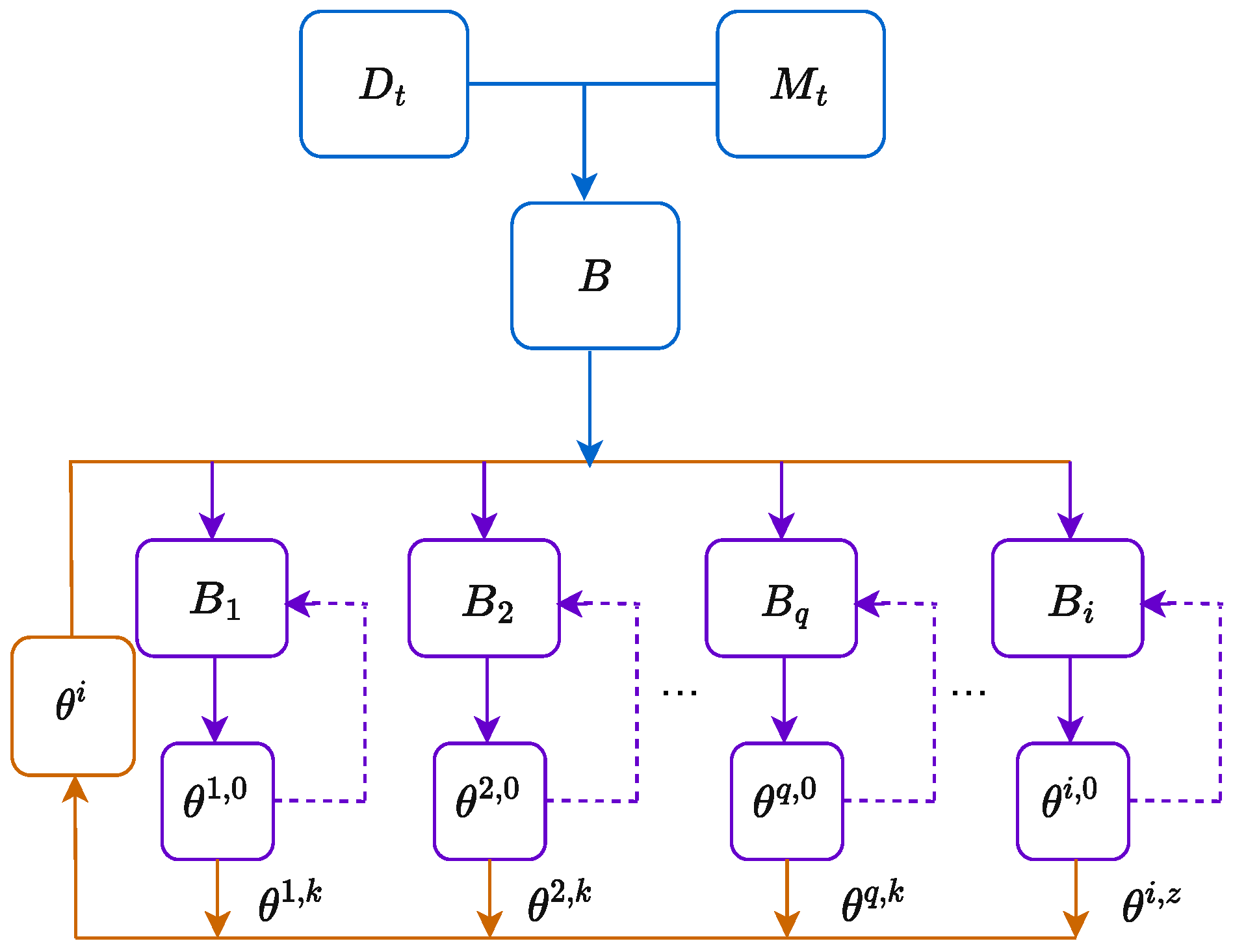
3.3. Experience Reply Based CL
| Algorithm 1 Proposed MER-Based Beam Prediction Strategy |
|
3.4. Meta-Learning Based Experience Replay Optimization
3.5. Computational Complexity Analysis
4. Simulation Results
4.1. Implementation Details
4.2. Randomly Generated Channel
- Under Rayleigh fading conditions, the downlink channel of a user is modeled as , whose coefficients are randomly drawn from a standard normal distribution; i.e., for all users k, the channel coefficients follow the complex Gaussian distribution .
- Under Rician fading conditions, the user’s downlink channel is constructed as a Gaussian process with a 0 dB K-factor; i.e., for all users k, the channel coefficients follow the distribution .
- Under the geometric channel condition, all users are uniformly and randomly distributed in an region. The channel gain follows a path loss function, i.e., , where is the small-scale fading coefficient.
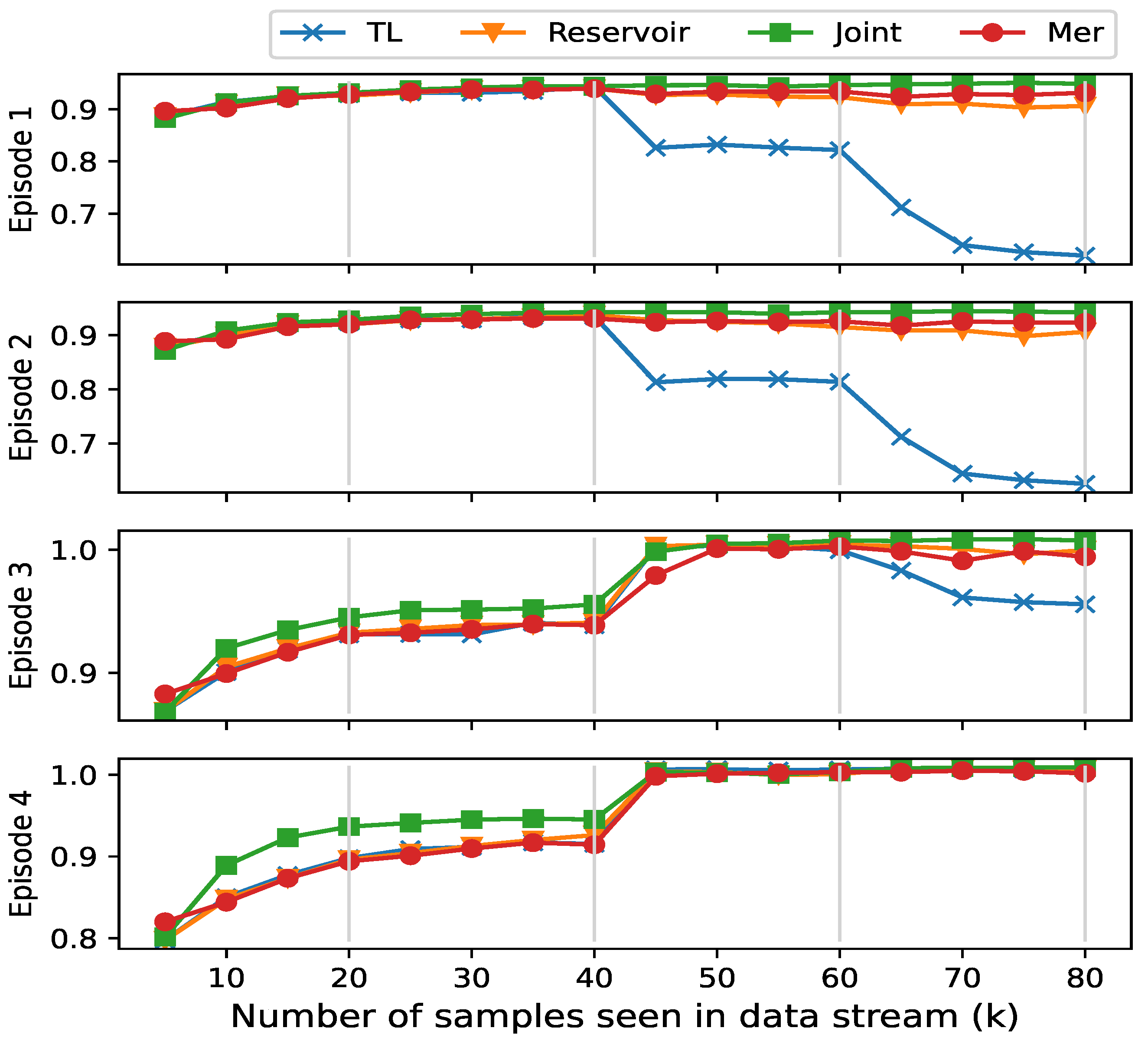
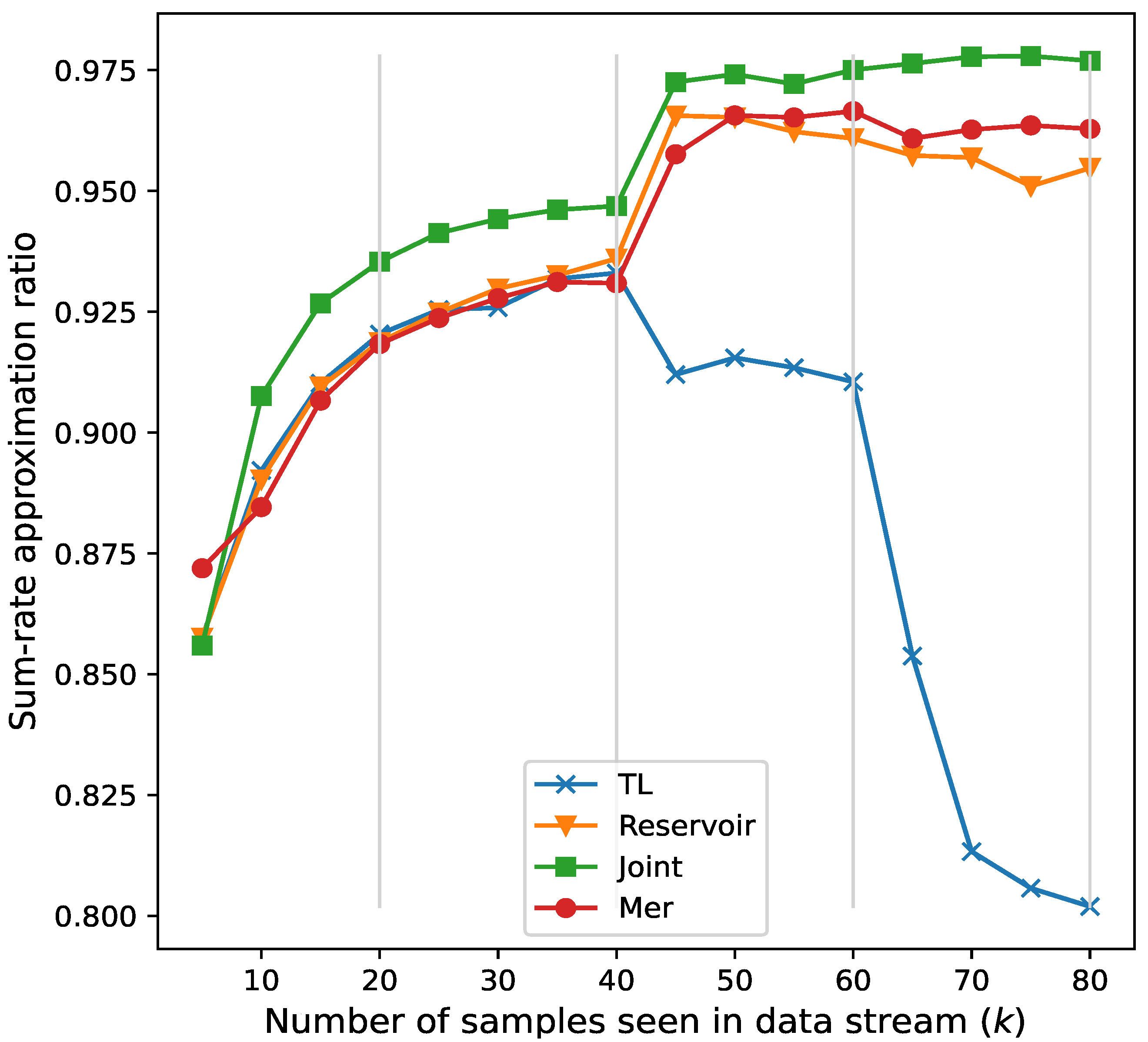
- TL [26]: Only the current moment is used for training, i.e., transfer learning;
- Reservoir [34]: Random sampling will be performed from the previous data of the current training in the memory, i.e., reservoir sampling;
- Joint: Training all the data from the entire training process, i.e., joint training.
4.3. Real Measured Channel
- Hyperparameters Settings: In our experimental setup, we prepared a total of 80,000 training data points and 4000 testing data points. Each channel is treated as an independent set and we learn and evaluate them in each training phase. The training set consists of the concatenated set of the current training data sets = 2000 and . In addition, the test set is divided into four subsets based on the distribution. At the beginning of each training phase, the training set is randomly disordered. We used a small batch of 100 samples for training and trained for 100 cycles. We adopt the Adam optimizer for optimization and set the learning rate to be = 0.01, = 0.001, and = 0.001.
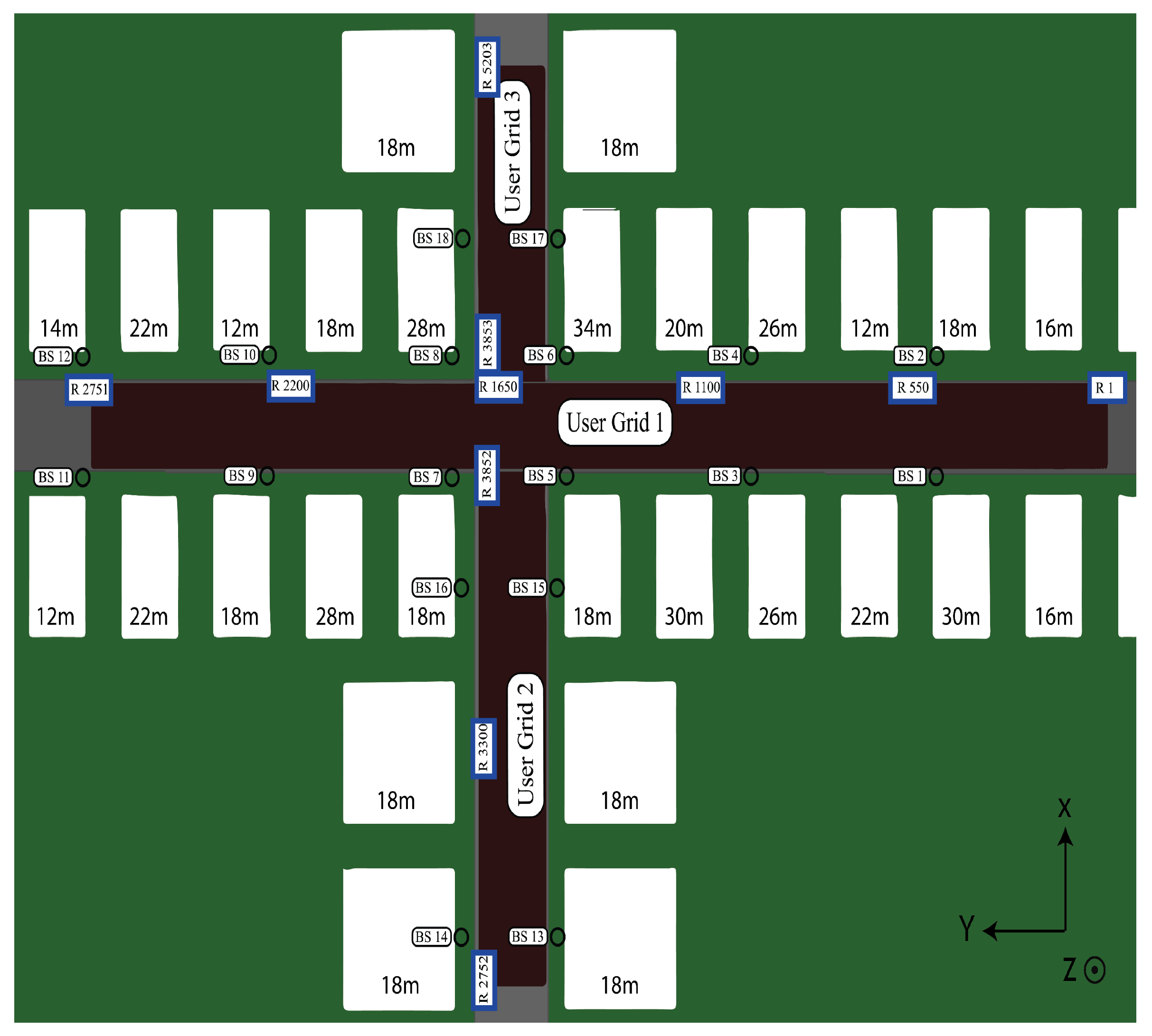
- Dataset Settings: The DeepMIMO dataset, generated by the Remcom Wireless Insite tool [46], is used to verify the effectiveness of our method through three distinct scenarios. As shown in Figure 6, in the DeepMIMO dataset, “O1_28” represents a specific simulation scenario. Specifically, “O1_28” is an outdoor environment at 28 GHz with two streets and an intersection. In this scenario, a total of 18 base stations (BS1-BS18) are deployed on both sides of the street, and the mobile users (MS) are located in three uniform x-y grids. Columns are indexed from C1 on the far right to C2751 on the far left. For each episode, 20,000 channel realizations are generated for training and 1000 for testing, derived from a configuration of 10 base stations with randomly selected K = 10 user positions from a predefined set. The scenarios are as follows: Episode 1 features UEs within rows 550 to 700 served by BS 1; Episode 2 has UEs within rows 800 to 1050, also served by BS 1; Episode 3 includes UEs within rows 1000 to 1250 served by BS 9; and Episode 4 involves UEs within rows 1300 to 1550 served by BS 9.
5. Conclusions
6. Future Work
Feasibility of Hardware Integration
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tariq, F.; Khandaker, M.R.; Wong, K.-K.; Imran, M.A.; Bennis, M.; Debbah, M. A speculative study on 6G. IEEE Wirel. Commun. 2020, 27, 118–125. [Google Scholar] [CrossRef]
- Dai, G.; Huang, R.; Yuan, J.; Hu, Z.; Chen, L.; Lu, J.; Fan, T.; Wan, D.; Wen, M.; Hou, T.; et al. Towards Flawless Designs: Recent Progresses in Non-Orthogonal Multiple Access Technology. Electronics 2023, 12, 4577. [Google Scholar] [CrossRef]
- Mao, B.; Liu, Y.; Guo, H.; Xun, Y.; Wang, J.; Liu, J.; Kato, N. On a hierarchical content caching and asynchronous updating scheme for non-terrestrial network-assisted connected automated vehicles. IEEE J. Sel. Areas Commun. 2025, 43, 64–74. [Google Scholar] [CrossRef]
- Li, X.; Jin, S.; Suraweera, H.A.; Hou, J.; Gao, X. Statistical 3-D beamforming for large-scale MIMO downlink systems over Rician fading channels. IEEE Trans. Commun. 2016, 64, 1529–1543. [Google Scholar] [CrossRef]
- Chen, S.; Gu, J.; Duan, W.; Wen, M.; Zhang, G.; Ho, P.-H. Hybrid Near-and Far-Field Communications for RIS-UAV System: Novel Beamfocusing Design. IEEE Trans. Intell. Transp. Syst. 2025, 1, 1–13. [Google Scholar] [CrossRef]
- Cao, Y.; Maghsudi, S.; Ohtsuki, T.; Quek, T.Q.S. Mobility-aware routing and caching in small cell networks using federated learning. IEEE Trans. Commun. 2024, 72, 815–829. [Google Scholar] [CrossRef]
- Yuan, Y.; Zhou, W.; Fan, M.; Wu, Q.; Zhang, K. Deformable Perfect Vortex Wave-Front Modulation Based on Geometric Metasurface in Microwave Regime. Chin. J. Electron. 2025, 34, 64–72. [Google Scholar] [CrossRef]
- Ohtsuki, T. Machine learning in 6G wireless communications. IEICE Trans. Commun. 2023, 106, 75–83. [Google Scholar] [CrossRef]
- Larsson, E.G.; Edfors, O.; Tufvesson, F.; Marzetta, T.L. Massive MIMO for next generation wireless systems. IEEE Commun. Magezine 2014, 52, 186–195. [Google Scholar] [CrossRef]
- El Ayach, O.; Rajagopal, S.; Abu-Surra, S.; Pi, Z.; Heath, R.W. Spatially sparse precoding in millimeter wave MIMO systems. IEEE Trans. Wirel. Commun. 2014, 13, 1499–1513. [Google Scholar] [CrossRef]
- Wang, T.; Wen, C.-K.; Wang, H.; Gao, F.; Jiang, T.; Jin, S. Deep learning for wireless physical layer: Opportunities and challenges. China Communucations 2017, 14, 92–111. [Google Scholar] [CrossRef]
- Zhang, C.; Patras, P.; Haddadi, H. Deep learning in mobile and wireless networking: A survey. IEEE Commun. Surv. Tutor. 2019, 21, 2224–2287. [Google Scholar] [CrossRef]
- He, H.; Wen, C.-K.; Jin, S.; Li, G.Y. Deep learning-based channel estimation for beamspace mmWave massive MIMO systems. IEEE Wirel. Commun. Lett. 2018, 7, 852–855. [Google Scholar] [CrossRef]
- Liang, F.; Shen, C.; Wu, F. An iterative BP-CNN architecture for channel decoding. IEEE J. Sel. Top. Signal Process. 2018, 12, 144–159. [Google Scholar] [CrossRef]
- Elbir, A.M.; Mishra, K.V.; Shankar, B.; Ottersten, B.E. A family of deep learning architectures for channel estimation and hybrid beamforming in multi-carrier mm-wave massive MIMO. IEEE Trans. Cogn. Commun. Netw. 2019, 8, 642–656. [Google Scholar] [CrossRef]
- Elbir, A.M.; Papazafeiropoulos, A.K. Hybrid precoding for multiuser millimeter wave massive MIMO systems: A deep learning approach. IEEE Trans. Veh. Technol. 2020, 69, 552–563. [Google Scholar] [CrossRef]
- Liang, F.; Shen, C.; Yu, W.; Wu, F. Towards optimal power control via ensembling deep neural networks. IEEE Trans. Commun. 2020, 68, 1760–1776. [Google Scholar] [CrossRef]
- Sun, H.; Chen, X.; Shi, Q.; Hong, M.; Fu, X.; Sidiropoulos, N.D. Learning to optimize: Training deep neural networks for interference management. IEEE Trans. Signal Process. 2017, 66, 5438–5453. [Google Scholar] [CrossRef]
- Hassan, S.U.; Mir, T.; Alamri, S.; Khan, N.A.; Mir, U. Machine Learning-Inspired Hybrid Precoding for HAP Massive MIMO Systems with Limited RF Chains. Electronics 2023, 12, 893. [Google Scholar] [CrossRef]
- Zhang, T.; Dong, A.; Zhang, C.; Yu, J.; Qiu, J.; Li, S.; Zhou, Y. Hybrid Beamforming for MISO System via Convolutional Neural Network. Electronics 2022, 11, 2213. [Google Scholar] [CrossRef]
- Echigo, H.; Cao, Y.; Bouazizi, M.; Ohtsuki, T. A deep learning-based low overhead beam selection in mmWave communications. IEEE Trans. Veh. Technol. 2021, 70, 682–691. [Google Scholar] [CrossRef]
- Jang, S.; Lee, C. DNN-driven single-snapshot near-field localization for hybrid beamforming systems. IEEE Trans. Veh. Technol. 2024, 73, 10799–10804. [Google Scholar] [CrossRef]
- Cao, Y.; Ohtsuki, T.; Maghsudi, S.; Quek, T.Q.S. Deep learning and image super-resolution-guided beam and power allocation for mmWave networks. IEEE Trans. Veh. Technol. 2023, 72, 15080–15085. [Google Scholar] [CrossRef]
- Xia, W.; Zheng, G.; Zhu, Y.; Zhang, J.; Wang, J.; Petropulu, A.P. A deep learning framework for optimization of MISO downlink beamforming. IEEE Trans. Commun. 2020, 68, 1866–1880. [Google Scholar] [CrossRef]
- Cao, Y.; Ohtsuki, T.; Quek, T.Q.S. Dual-ascent inspired transmit precoding for evolving multiple-access spatial modulation. IEEE Trans. Commun. 2020, 68, 6945–6961. [Google Scholar] [CrossRef]
- Shen, Y.; Shi, Y.; Zhang, J.; Letaief, K.B. LORM: Learning to optimize for resource management in wireless networks with few training samples. IEEE Trans. Wirel. Commun. 2020, 19, 665–679. [Google Scholar] [CrossRef]
- Zeng, J.; Sun, J.; Gui, G.; Adebisi, B.; Ohtsuki, T.; Gacanin, H.; Sari, H. Downlink CSI Feedback Algorithm With Deep Transfer Learning for FDD Massive MIMO Systems. IEEE Trans. Cogn. Commun. Netw. 2021, 7, 1253–1265. [Google Scholar] [CrossRef]
- Zhang, B.; Li, H.; Liang, X.; Gu, X.; Zhang, L. Model Transmission-Based Online Updating Approach for Massive MIMO CSI Feedback. IEEE Commun. Lett. 2023, 27, 1609–1613. [Google Scholar] [CrossRef]
- Cui, Y.; Guo, J.; Wen, C.-K.; Jin, S.; Han, S. Unsupervised Online Learning in Deep Learning-Based Massive MIMO CSI Feedback. IEEE Commun. Lett. 2022, 26, 2086–2090. [Google Scholar] [CrossRef]
- Guo, J.; Zuo, Y.; Wen, C.-K.; Jin, S. User-Centric Online Gossip Training for Autoencoder-Based CSI Feedback. IEEE J. Sel. Top. Signal Process. 2022, 16, 559–572. [Google Scholar] [CrossRef]
- Zhou, H.; Xia, W.; Zhao, H.; Zhang, J.; Ni, Y.; Zhu, H. Continual learning-based fast beamforming adaptation in downlink MISO systems. IEEE Wirel. Commun. Lett. 2023, 12, 36–39. [Google Scholar] [CrossRef]
- Sun, H.; Pu, W.; Fu, X.; Chang, T.-H.; Hong, M. Learning to continuously optimize wireless resource in a dynamic environment: A bilevel optimization perspective. IEEE Trans. Signal Process. 2022, 70, 1900–1917. [Google Scholar] [CrossRef]
- Sun, H.; Pu, W.; Zhu, M.; Fu, X.; Chang, T.-H.; Hong, M. Learning to Continuously Optimize Wireless Resource in Episodically Dynamic Environment. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 4945–4949. [Google Scholar]
- Isele, D.; Cosgun, A. Selective experience replay for lifelong learning. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 226–231. [Google Scholar]
- Cao, Y.; Lu, W.; Ohtsuki, T.; Maghsudi, S.; Jiang, X.-Q.; Tsimenidis, C. Memristor-based meta-learning for fast mmWave beam prediction in non-stationary environments. arXiv 2025, arXiv:2502.09244. [Google Scholar]
- Lyu, M.; Ng, B.K.; Lam, C.-T. Downlink beamforming prediction in MISO system using meta learning and unsupervised learning. In Proceedings of the ICCT, Wuxi, China, 20–22 October 2023; pp. 188–194. [Google Scholar]
- Lopez-Paz, D.; Ranzato, M. Gradient Episodic Memory for Continual Learning. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Chaudhry, A.; Dokania, P.K.; Ajanthan, T.; Torr, P.H. Riemannian Walk for Incremental Learning: Understanding Forgetting and Intransigence. arXiv 2018, arXiv:1801.10112. [Google Scholar]
- Hintze, A. The role weights play in catastrophic forgetting. In Proceedings of the 2021 8th International Conference on Soft Computing & Machine Intelligence (ISCMI), Cario, Egypt, 26–27 November 2021; pp. 160–166. [Google Scholar]
- Masarczyk, W.; Tautkute, I. Reducing catastrophic forgetting with learning on synthetic data. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 1019–1024. [Google Scholar]
- Zhang, M.; Li, H.; Pan, S.; Chang, X.; Zhou, C.; Ge, Z.; Su, S. One-shot neural architecture search: Maximising diversity to overcome catastrophic forgetting. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 2921–2935. [Google Scholar] [CrossRef]
- Riemer, M.; Cases, I.; Ajemian, R.; Liu, M.; Rish, I.; Tu, Y.; Tesauro, G. Learning to learn without forgetting by maximizing transfer and minimizing interference. arXiv 2018, arXiv:1810.11910. [Google Scholar]
- Lahiri, S.; Ganguli, S. A memory frontier for complex synapses. In Proceedings of the NeurIPS, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 1034–1042. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the ICML, Sydney, NSW, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Nichol, A.; Schulman, J. Reptile: A scalable metalearning algorithm. arXiv 2018, arXiv:1803.02999. [Google Scholar]
- Alkhateeb, A. DeepMIMO: A generic deep learning dataset for millimeter wave and massive MIMO applications. In Proceedings of the Information Theory and Applications Workshop (ITA), San Diego, CA, USA, 10–15 February 2019. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Proposed | Reservoir | Joint | TL |
|---|---|---|---|---|
| Memory Cost | 0.76 M | 0.76 M | 30.4 M | 0 M |
| Randomly Generated Channel Time Loss | 0.15 s | 0.17 s | 0.33 s | 0.35 s |
| Real Channel Time Loss | 0.12 s | 0.15 s | 0.35 s | 0.37 s |
| Method | Proposed | Reservoir | Joint | TL |
|---|---|---|---|---|
| Average Sum-rate | 0.975 | 0.955 | 0.960 | 0.990 |
| Standard Deviation | 0.015 | 0.025 | 0.020 | 0.030 |
| p-value | - | <0.001 | 0.003 | 0.012 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, W.; Jiang, X.; Cao, Y.; Ohtsuki, T.; Bai, E. Model-Driven Meta-Learning-Aided Fast Beam Prediction in Millimeter-Wave Communications. Electronics 2025, 14, 2734. https://doi.org/10.3390/electronics14132734
Lu W, Jiang X, Cao Y, Ohtsuki T, Bai E. Model-Driven Meta-Learning-Aided Fast Beam Prediction in Millimeter-Wave Communications. Electronics. 2025; 14(13):2734. https://doi.org/10.3390/electronics14132734
Chicago/Turabian StyleLu, Wenqin, Xueqin Jiang, Yuwen Cao, Tomoaki Ohtsuki, and Enjian Bai. 2025. "Model-Driven Meta-Learning-Aided Fast Beam Prediction in Millimeter-Wave Communications" Electronics 14, no. 13: 2734. https://doi.org/10.3390/electronics14132734
APA StyleLu, W., Jiang, X., Cao, Y., Ohtsuki, T., & Bai, E. (2025). Model-Driven Meta-Learning-Aided Fast Beam Prediction in Millimeter-Wave Communications. Electronics, 14(13), 2734. https://doi.org/10.3390/electronics14132734