1. Introduction
Indoor localization techniques are becoming increasingly important for applications such as smart navigation, unmanned aerial vehicle (UAV) control, and mobile robot tracking. However, the Global Positioning System (GPS) often fails to operate reliably in indoor environments [
1], where factors such as structural complexity, limited signal propagation, insufficient infrastructure deployment, and uncorrected errors can severely degrade positioning accuracy—especially under non-line-of-sight (NLOS) conditions. To address these challenges, various alternative indoor localization methods have been proposed, including WiFi [
2,
3], Bluetooth [
4,
5], visible light communication (VLC) [
6,
7], ultra-wideband (UWB) [
8,
9], and pedestrian dead reckoning (PDR) based on inertial navigation [
10,
11].
Among these technologies, ultra-wideband (UWB) has received widespread attention due to its high accuracy, strong stability, and robust anti-interference capability. However, UWB’s ranging performance significantly degrades under non-line-of-sight (NLOS) conditions, resulting in large positioning errors. Meanwhile, inertial measurement units (IMUs), commonly used in pedestrian dead reckoning (PDR) systems, offer advantages such as a compact size, a lightweight design, and immunity to external signal interference. They can maintain relatively stable positioning over short periods. Nevertheless, long-term use leads to cumulative errors [
12,
13,
14], with heading angle data being particularly susceptible to magnetic field disturbances and attitude fluctuations, causing drift or sudden deviations [
15], which adversely affect positioning accuracy. Furthermore, most existing fusion methods [
16,
17] are based on filtering algorithms that, despite their strong noise suppression and drift correction capabilities, suffer from two main limitations. First, they heavily depend on strict assumptions about system models and noise distributions, limiting their adaptability to the uncertainty and dynamics of real-world environments. Second, filtering approaches require numerical integration of IMU data to estimate displacement, which is vulnerable to initial biases and acceleration drifts that may destabilize the system.
To comprehensively enhance the performance of UWB–IMU fusion systems, researchers have conducted in-depth investigations focusing on data fusion algorithms. Commonly used approaches include the Kalman Filter (KF), Extended Kalman Filter (EKF), Complementary Kalman Filter (CKF), and Unscented Kalman Filter (UKF) [
18,
19,
20,
21]. These methods effectively mitigate inconsistencies among multi-sensor data by integrating state prediction with observation updates. In practical applications, to address the challenges of localization in complex indoor environments, researchers have continuously refined traditional filtering frameworks and proposed various fusion strategies to resolve typical issues encountered in UWB–IMU integration.
Experimental results demonstrate that these enhanced fusion methods perform effectively in complex indoor environments involving both line-of-sight (LOS) and non-line-of-sight (NLOS) conditions, with performance under NLOS scenarios being particularly critical. To address errors caused by NLOS conditions, ref. [
22] proposed a two-stage detection algorithm that identifies LOS/NLOS states based on signal features and dynamically adjusts the ranging strategy, maintaining high accuracy even when LOS anchors are limited. For dynamic occlusions, ref. [
23] developed a human body shadowing model for UWB ranging errors, which was integrated into a particle filter alongside smartphone gyroscope data. This approach reduced the 2D localization error by 41.91% compared to trilateration. Building on this, ref. [
24] distinguished between spatial and human occlusions using LOS/NLOS mapping, spatial priors, and IMU data. Their method applies visibility checks and error correction models within a particle filter, enabling robust positioning under complex occlusions. To handle time-varying, non-Gaussian NLOS errors, ref. [
25] proposed an adaptive strategy that updates measurement noise covariance in real time based on residuals within an EKF. This method improved localization accuracy by 46.15% over traditional tightly coupled systems and introduced a feedback mechanism for UWB preprocessing, forming a closed-loop optimization framework. Additionally, ref. [
26] combined Least Squares (LS) and Adaptive Kalman Filtering (AKF) for tightly coupled fusion of UWB and IMU-based PDR, effectively mitigating UWB errors and IMU drift, thereby enhancing real-time performance in dynamic indoor environments.
Despite the performance improvements achieved by the aforementioned filtering and compensation strategies, the overall system effectiveness in complex environments remains highly dependent on the proper tuning of parameters. For example, ref. [
27] conducted a systematic evaluation of optimal parameter settings for UWB–IMU sensor fusion under non-line-of-sight (NLOS) conditions. Their study demonstrated that applying high-pass filtering prior to Extended Kalman Filter (EKF) and Unscented Kalman Filter (UKF) processing not only enhances system robustness but also provides valuable guidance for parameter optimization. However, traditional filtering methods inherently struggle to model highly nonlinear environments with severe interference, which has driven increasing interest in neural network-based fusion approaches. Compared to conventional filters, neural networks exhibit superior nonlinear modeling capabilities and adaptability, enabling more effective handling of complex phenomena such as multipath propagation and dynamic occlusions. For instance, ref. [
28] proposed a deep Long Short-Term Memory (LSTM)-based UWB localization method that leverages extracted ranging features to significantly enhance temporal modeling and improve positioning accuracy. In [
29], a neural network architecture was developed to correct direction-induced ranging errors without relying on signal strength or channel response parameters, reducing the 3D ranging root mean square error (RMSE) by nine centimeters. Furthermore, ref. [
30] integrated UWB, IMU, and time-of-flight (TOF) data with an OptiTrack motion capture system through an artificial neural network (ANN)-based fusion framework, achieving correlation coefficients exceeding 99% in both the X and Y coordinates, effectively mitigating drift errors and maintaining high-precision localization. In summary, neural network-based fusion methods offer significant advantages in accuracy and robustness against environmental variability and signal interference. Nonetheless, their increased computational complexity and real-time processing demands pose ongoing challenges for practical deployment, necessitating further optimization.
Taking all these considerations into account, this paper proposes a neural network-based indoor localization method that fuses ultra-wideband (UWB) and inertial measurement unit (IMU) data. Leveraging the strong feature extraction and nonlinear modeling capabilities of neural networks, the method effectively integrates the global spatial position information provided by UWB with dynamic motion features extracted from the IMU, such as acceleration and heading angle, achieving efficient and robust multimodal sensor fusion for indoor positioning. Compared to existing approaches, it effectively mitigates non-line-of-sight (NLOS) effects and sensor drift, reduces reliance on precise system models and noise assumptions, and maintains high localization accuracy even with relatively simple hardware configurations. Moreover, to better assess the model’s performance, experiments are conducted in complex indoor environments featuring typical NLOS characteristics, including static obstacles and dynamic occlusions caused by human movement. With deep learning’s ability to model complex nonlinear relationships and process multimodal data, neural network-based fusion methods have become a powerful approach to improving localization accuracy while reducing dependence on traditional modeling assumptions.
The main contributions of this work are summarized as follows:
- (1)
We propose a neural network-based end-to-end learning strategy to replace traditional filtering methods. Specifically, the xLSTM model is employed to extract time-series features from multimodal sensor data, capturing both short-term and long-term dependencies in temporal dynamics, thereby enhancing fusion modeling capability.
- (2)
A residual fusion module and an enhanced attention mechanism are introduced to achieve effective feature-level fusion of UWB ranging data, acceleration signals, and heading angles. This approach compensates for the limitations of single-sensor systems in terms of accuracy and stability.
- (3)
Comprehensive experimental evaluations are conducted in complex real-world indoor environments, including scenarios with static and dynamic obstacles. The proposed method is compared with traditional and neural network-based fusion approaches in terms of localization accuracy and system robustness.
The remainder of this paper is organized as follows:
Section 2 reviews the technical approaches and related research in indoor localization, and provides a detailed description of the proposed multi-sensor fusion-based localization system.
Section 3 presents the experimental implementation and results, followed by an evaluation of the performance and stability of the proposed method. Finally,
Section 4 concludes the paper and discusses future research directions.
2. Materials and Methods
2.1. UWB Ranging Principle
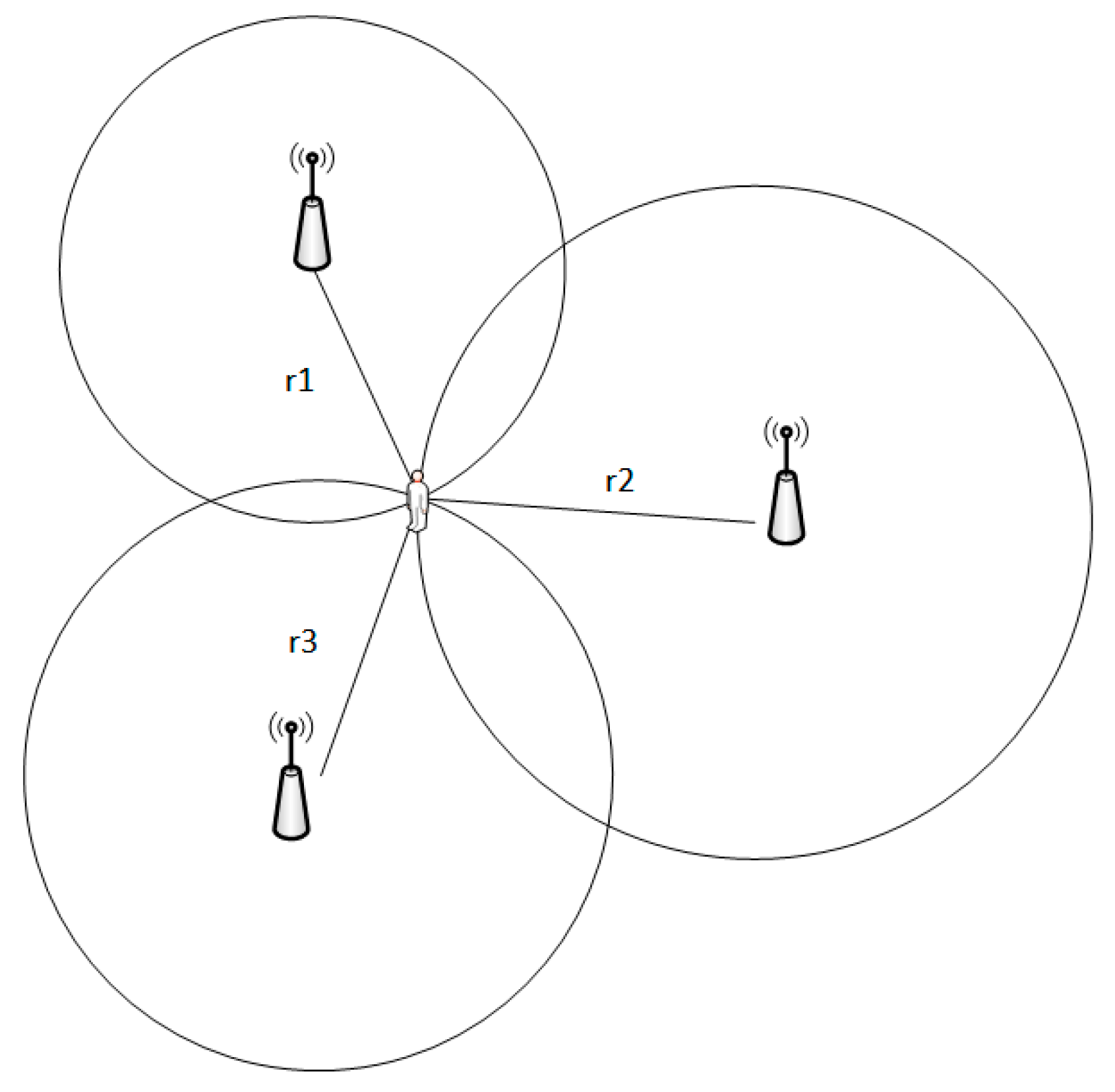
In this experiment, a time-of-arrival (TOA)-based localization method is employed to estimate the point-to-point distance between the tag and the base station by measuring the time of flight of the wireless signal through the air. The localization principle is illustrated in
Figure 1.
As shown in
Figure 1, the localization principle is based on the time-of-arrival (TOA) method. The tag transmits a wireless signal, which is received by multiple base stations at different times due to varying distances. The circles in the figure represent the range measurements from each base station to the tag, and their intersection corresponds to the estimated tag position. Based on the figure, Equation (1) can be formulated as follows:
Here,
denotes the coordinates of the
-th base station,
represents the coordinates of the unknown tag position, and
is the measured distance between the tag and the
base station. Expanding the quadratic terms in Equation (1) yields
To simplify the expressions, it is assumed that
and
, and then Equation (2) can be rewritten as
For
= 1, 2, 3, Equation (3) leads to the following matrix form:
From the system of equations in Equation (4), the coordinates (x, y) can be found.
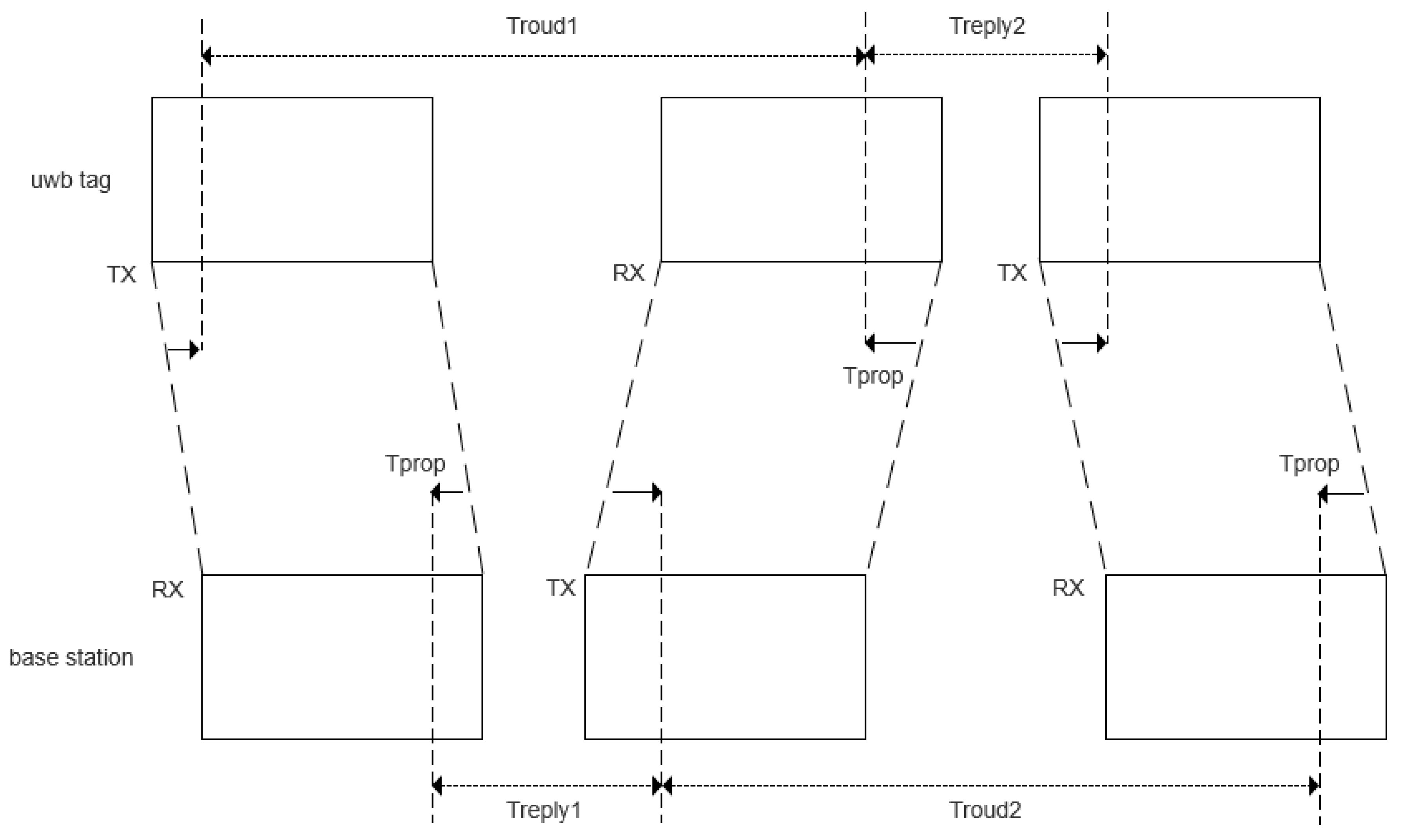
This scheme only needs the timestamps of each time point in the ranging process, and then the signal transmission time TOF can be calculated based on the difference of the timestamps, but due to the influence of the base station and tag clock independence, the result of directly calculating TOF will lead to a large ranging error, so the SDS-TWR algorithm is used to solve the distance based on TOA; the principle is shown in
Figure 2.
The bilateral bidirectional ranging flight time is as follows:
Step 1: The tag sends an rng message to the base station and records this timestamp based on the base station registry obtained during the search phase, and opens the reception.
Step 2: The base station in the listening state receives an rng message from a tag, records this timestamp , and then replies to the tag with an res message timestamped and opens reception.
Step 3: The tag receives the res message and records the timestamp , fills the packet with , and to send the finish message, and then enters the next ranging cycle.
Step 4: The base station receives the fin message to record the timestamp and performs unpacking to obtain the timestamp of each point to calculate the distance.
As can be seen in
Figure 2,
can be obtained from Equations (5) and (6).
The flight time can be introduced from Equations (7) and (8).
2.2. Proposed Methodology
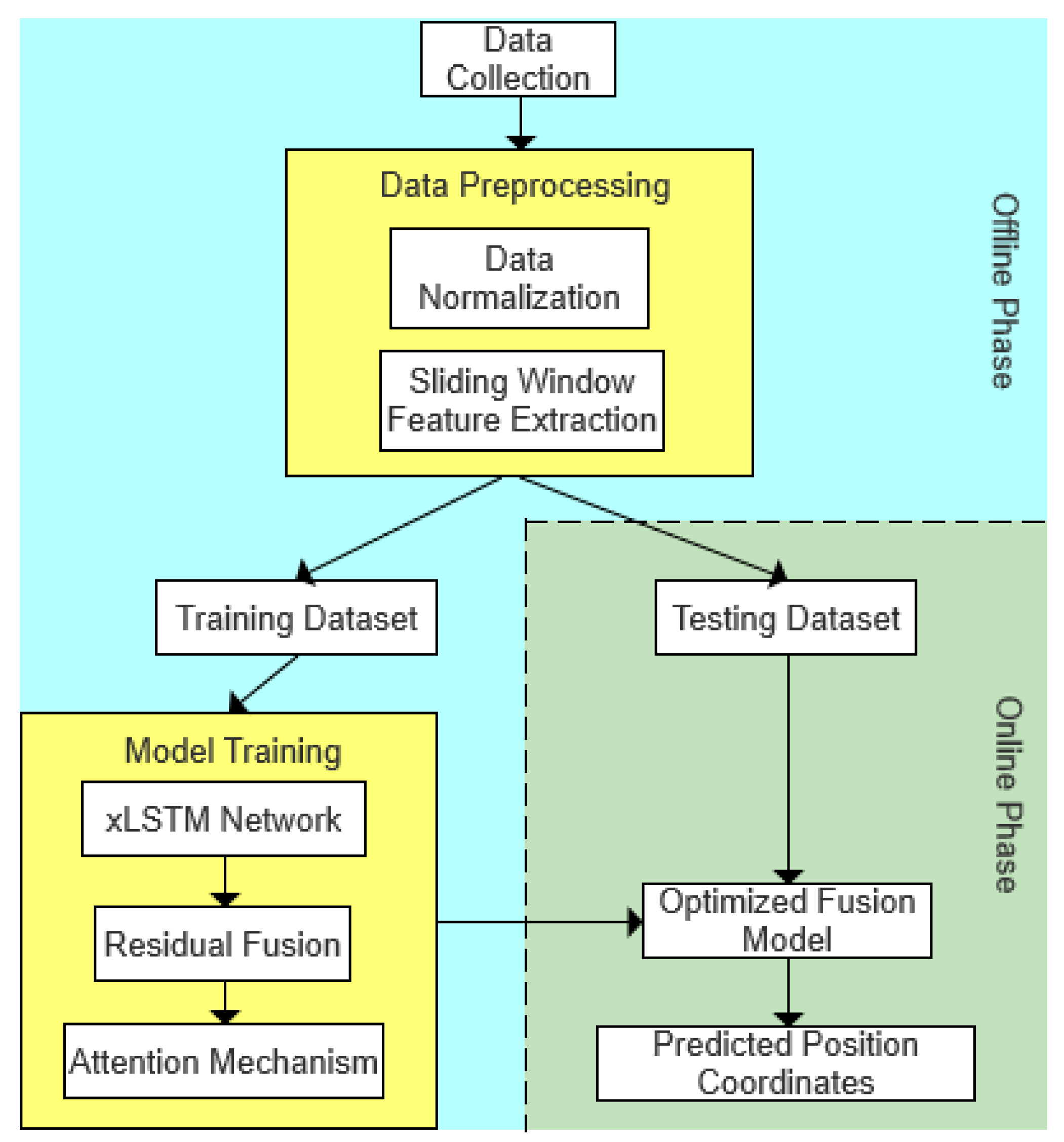
This paper proposes a multimodal-data-fusion-based positioning system that leverages the complementary strengths of UWB ranging, acceleration, and heading angle signals. The overall model architecture, illustrated in
Figure 3, consists of an offline training phase and an online prediction phase. During the offline phase, statistical features—including the maximum, minimum, 25th percentile, and 50th percentile—are extracted from sliding windows applied to UWB, IMU acceleration, and heading angle data, following the approach described in [
31]. The sliding window is set to 10 samples with a 50% overlap, and the data sampling rate is 16.67 Hz. These extracted features are then input into the xLSTM network for deep temporal feature learning. Subsequently, a residual fusion module and an attention-based fusion mechanism are incorporated to further enhance the feature representation, ultimately producing a robust model for accurate localization. In the online phase, the trained model is deployed to perform real-time localization predictions on streaming sensor data.
Meanwhile, the pseudocode illustrating the modification of the deep learning architecture is presented in Algorithm 1. The overall process is introduced here, while the detailed implementation of each module will be elaborated in the subsequent sections of this chapter.
| Algorithm 1 Pseudocode of proposed multimodal positioning architecture. |
| Input: UWB data U, Acc data A, Angle data G, Target coordinates Y |
| Output: Predicted coordinates
|
| 1:Procedure MultiModal Localization Training |
| 2: repeat |
3: Forward Propagation
(U) Extract global feature extraction |
(A) Extract local feature extraction
(G) Extract local feature extraction |
for enhanced local feature fusion
← Apply cross-modality fusion:
(local) via residual module
through KANLinear layer for coordinate prediction
13: Backward Propagation |
14: Loss ← Compute L(,Y) using MSELoss
15: Conduct backward pass to compute gradients
16: Update weights and biases using Adam optimizer
17: Until training loss converges
18: return |
The system first collects ranging data from multiple UWB anchors using an efficient time-of-flight (ToF) method and applies a sliding window technique for temporal preprocessing. Simultaneously, acceleration and heading angle data are acquired from IMU sensors. Due to significant differences in dynamic characteristics and temporal dependencies among these three modalities, conventional LSTM networks often fail to effectively capture their distinct temporal patterns, resulting in suboptimal fusion performance. To address this limitation, a three-branch xLSTM network is designed to independently model the temporal sequences of UWB, acceleration, and heading angle data. This architecture preserves the unique dynamic information of each modality while simultaneously capturing both short-term and long-term dependencies, thereby enhancing the representational capacity for heterogeneous multimodal time-series data.
During multimodal feature fusion, simple concatenation or shallow fusion techniques fail to fully leverage the complementary information across modalities and are susceptible to noise interference. To overcome these limitations, a three-stage hierarchical residual fusion module composed of one-dimensional residual blocks (ResidualBlock1D) is proposed. This module progressively strengthens cross-modal interactions through its hierarchical structure and incorporates learnable modality transformation weights. These weights dynamically adjust the contribution of each modality based on its reliability and contextual relevance, thereby improving the quality and robustness of the fused features.
The fused features are further refined using an Enhanced Semantic Attention Module, which dynamically balances global spatial information from the UWB modality and local motion cues from the IMU modalities via multi-head cross-attention and self-attention mechanisms. This strategy not only harmonizes global and local spatial contexts but also enhances the discriminative capacity of the features, significantly improving the model’s localization accuracy and robustness in dynamic and occluded environments.
Finally, the enhanced multimodal features are mapped to the localization output through a Kernel-based Activation Network (KAN). The KAN is a novel neural activation mechanism first systematically introduced in [
32]. Unlike traditional activation functions such as ReLU or GELU, the KAN replaces fixed-form activations with learnable kernel functions (e.g., B-spline interpolation), enabling flexible modeling of complex nonlinear relationships. This approach allows the network to better capture intricate dependencies within multimodal data, ultimately improving localization accuracy and generalization performance.
In summary, the proposed xLSTM module, hierarchical residual fusion structure, and enhanced semantic attention mechanism specifically address the challenges posed by heterogeneous multimodal time-series data. They respectively resolve issues related to temporal disparities across modalities, cross-modal information integration, and semantic feature enhancement, culminating in an efficient and robust framework for indoor localization feature extraction and fusion.
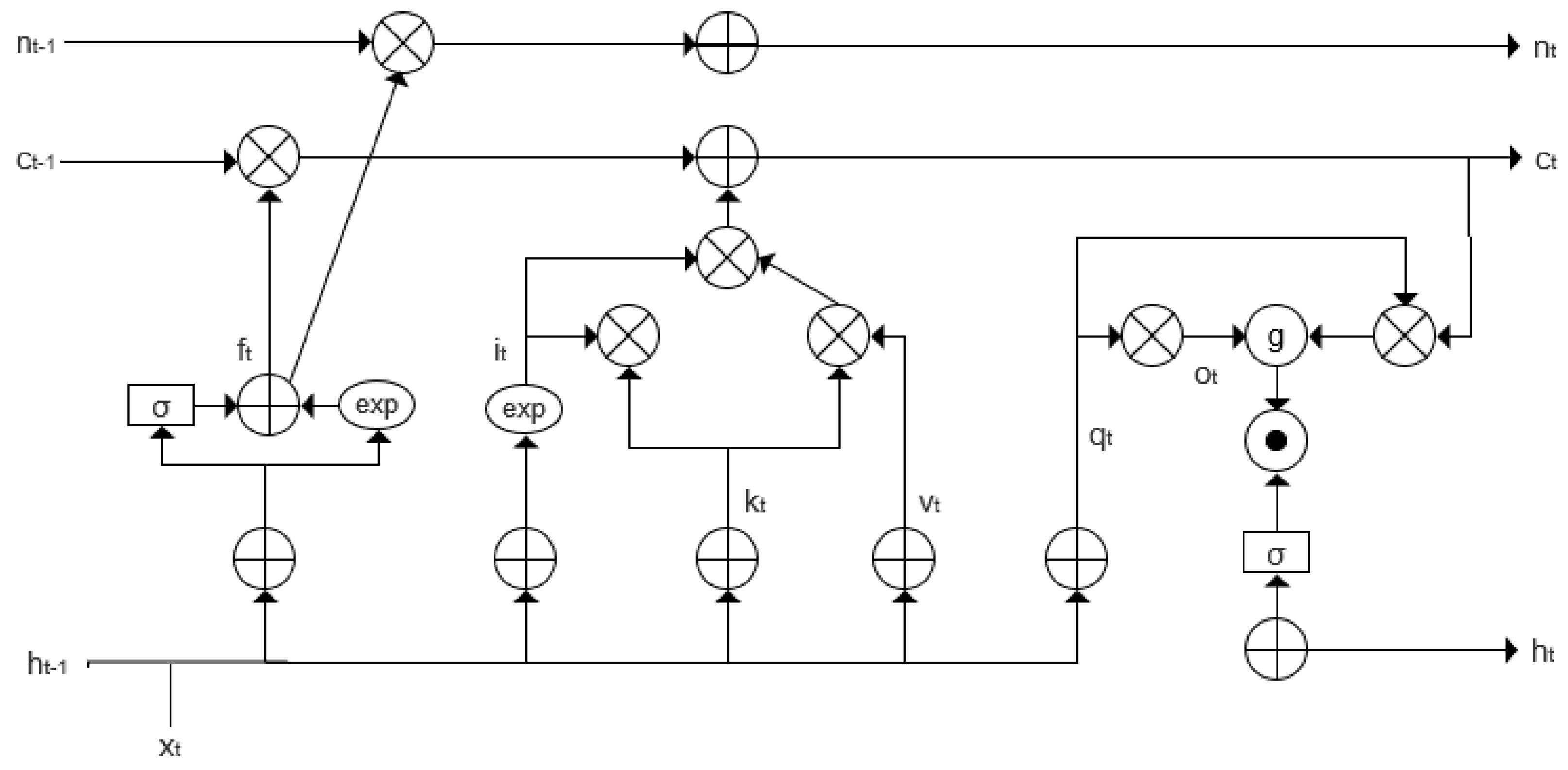
2.2.1. Application of xLSTM Network in Time-Series Feature Capture
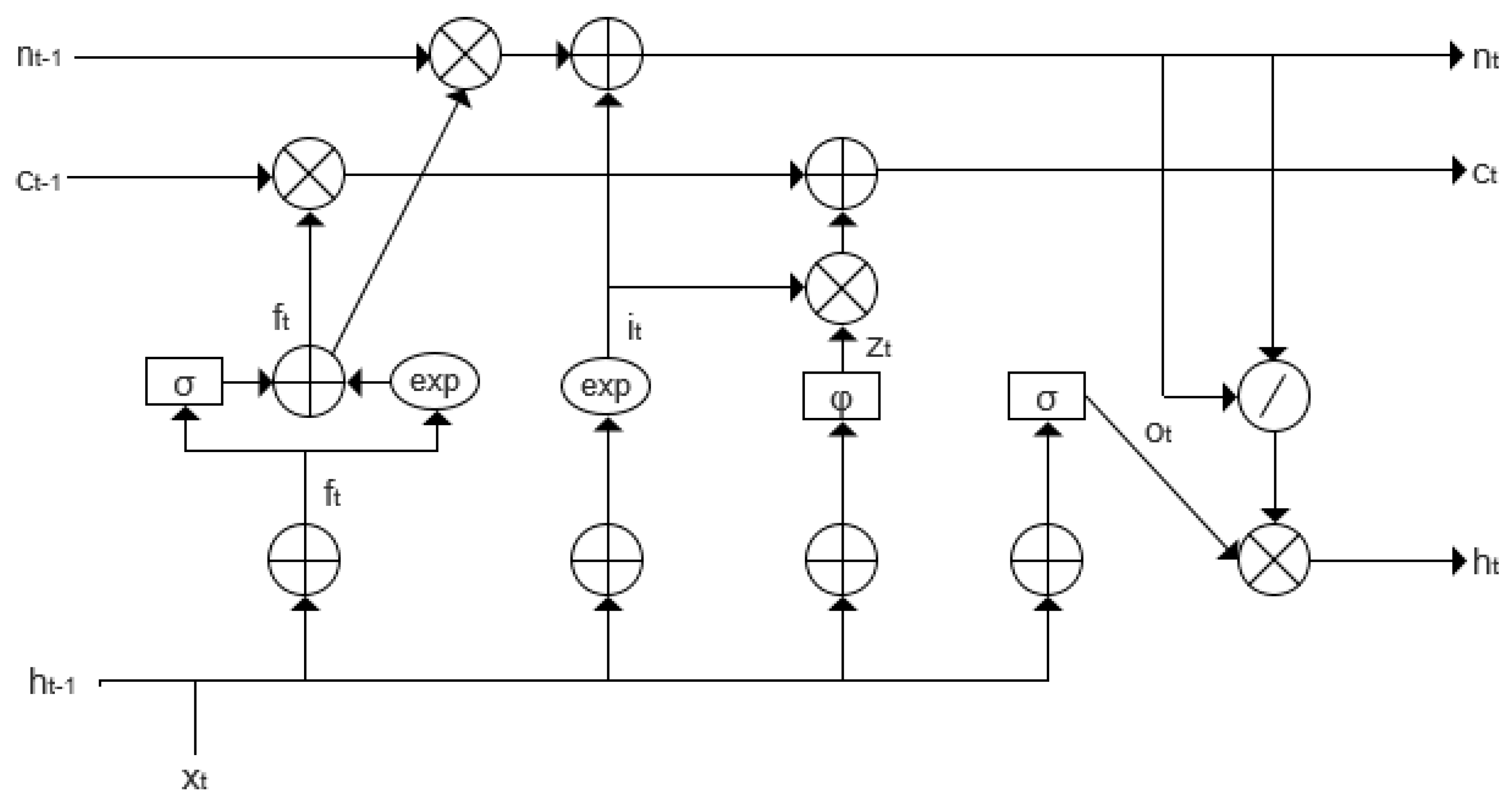
The xLSTM network is constructed as a stacked combination of the Scalar LSTM (sLSTM) and Matrix LSTM (mLSTM) architectures, both of which were specifically designed to address limitations of the original LSTM network. The mathematical formulations of sLSTM and mLSTM are detailed in [
33]. To enhance the LSTM’s ability to dynamically adjust memory storage decisions, the Scalar LSTM introduces several improvements over the conventional LSTM structure. The internal architecture of its basic computational unit is illustrated in
Figure 4.
- (1)
Introducing exponential gating, so that the input and forget gates have an exponential activation function.
- (2)
Introducing the stabilization gate , which prevents the exponential activation function from leading to the overflow of values that are too large.
- (3)
Introducing the normalized state, which acts similarly to the stabilization gate.
Unlike the standard LSTM, sLSTM adopts an exponential reparameterization for the input and forget gates:
To suppress the numerical instability caused by exponential growth, a logarithmic-domain stabilizer is introduced:
Based on this stabilizer, the input and forget gates are re-normalized as
The stabilized gates are then used to update the cell state and hidden state:
where
denotes the cell input at time
t,
is the output gate, and
is a learnable normalization factor used to suppress magnitude explosion.
This stabilized structure significantly mitigates gradient vanishing and explosion in long-sequence modeling, thereby improving the training stability and generalization ability of the model in temporal dependency tasks.
To enhance the storage capacity of the LSTM network, Matrix LSTM (mLSTM) introduces several improvements over the standard LSTM architecture. The internal structure of its basic computational unit is depicted in
Figure 5.
- (1)
Increasing the memory unit from scalar to matrix, and also introducing the covariance update mechanism for key–value pair storage.
- (2)
Using the same stabilization gate mt as slstm to prevent the exponential activation function from leading to the overflow of values that are too large.
Specifically, the input feature
is mapped to the query, key, and value vectors as shown in Equations (17)–(19).
Similar to sLSTM, a stabilizer state
is introduced to rescale the input and forget gates. Finally, the hidden state
is determined by the output gate and the normalized attention weights, as shown in Equation (20).
The matrices , , and the bias vectors , , are the linear projection parameters for the query, key, and value vectors, respectively. The memory matrix is represented as , and the normalization vector is denoted by .
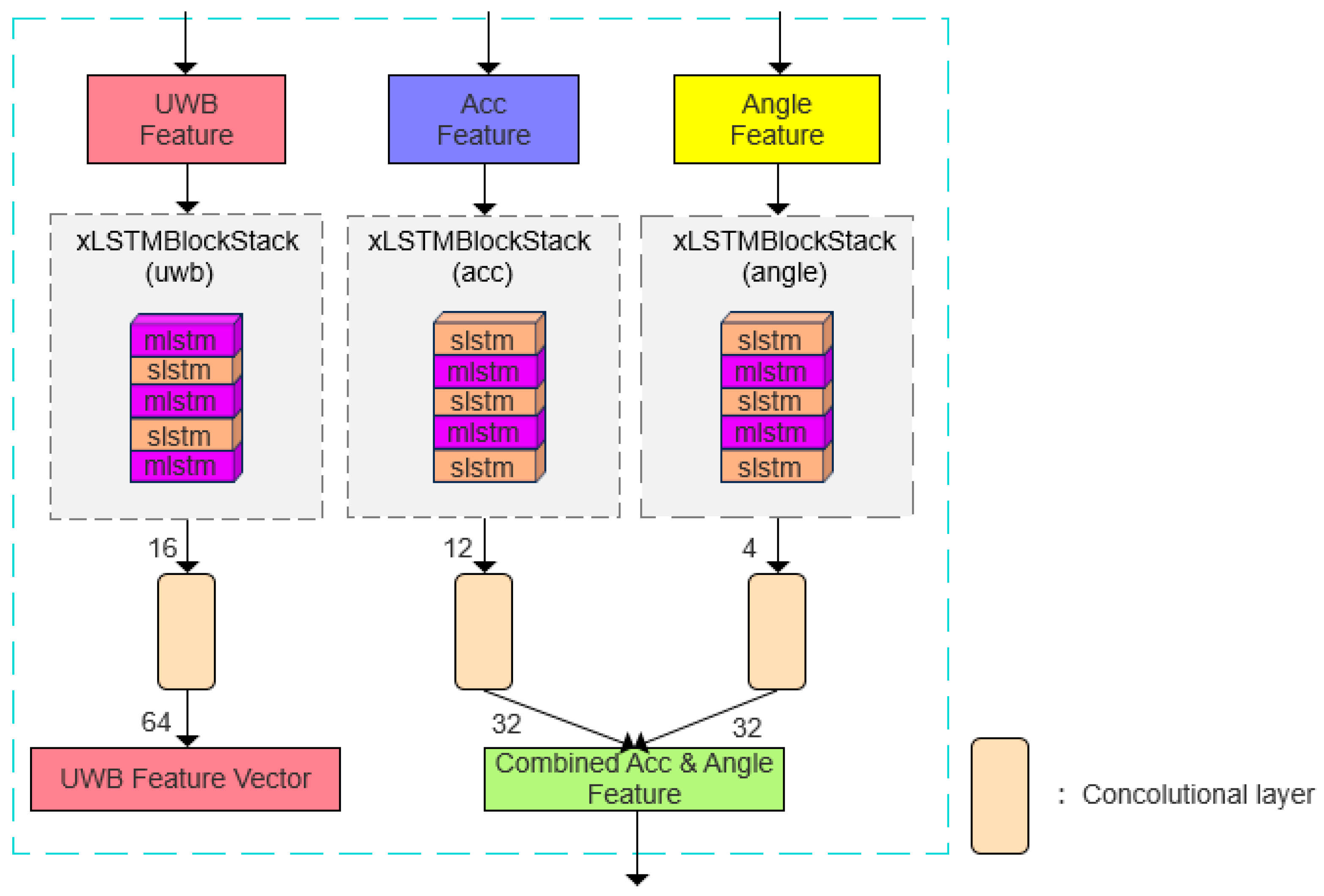
The xLSTM architecture not only alleviates the common issues of gradient vanishing and information loss encountered by traditional LSTM networks in long-sequence modeling but also provides distinct structural advantages for processing multi-sensor data. It employs a flexible stacking configuration comprising Scalar LSTM (sLSTM) and Matrix LSTM (mLSTM) units, enabling parallel modeling and differentiated feature extraction across multiple modality-specific data channels. By leveraging the temporal characteristics of various sensor inputs, xLSTM permits customization of the type and number of substructures for each modality, thereby achieving adaptive and effective modeling of heterogeneous time-series data. Moreover, the parallel architecture improves computational efficiency during the feature extraction stage. Consequently, following the extraction of basic statistical features, this study incorporates the xLSTM network for deep temporal feature learning and carefully designs its stacking configuration based on the characteristics of each data modality, as illustrated in
Figure 6.
Specifically, the sLSTM layers for the UWB modality are positioned at the first and third layers, whereas the sLSTM layers for the IMU modalities—namely acceleration and heading angle—are assigned to the zeroth, second, and fourth layers. At the end of each modality branch, a one-dimensional convolutional layer with a kernel size of four is applied to extract localized temporal patterns. In the UWB branch, the convolutional output is expanded to sixteen channels and subsequently projected into a sixty-four-dimensional UWB feature vector. For the acceleration and heading angle branches, the outputs are compressed into thirty-two-dimensional vectors, which are then fused into a unified Combined Acceleration and Angle Feature. This hierarchical architecture substantially enhances the model’s capacity to capture complex temporal dependencies across heterogeneous sensor modalities.
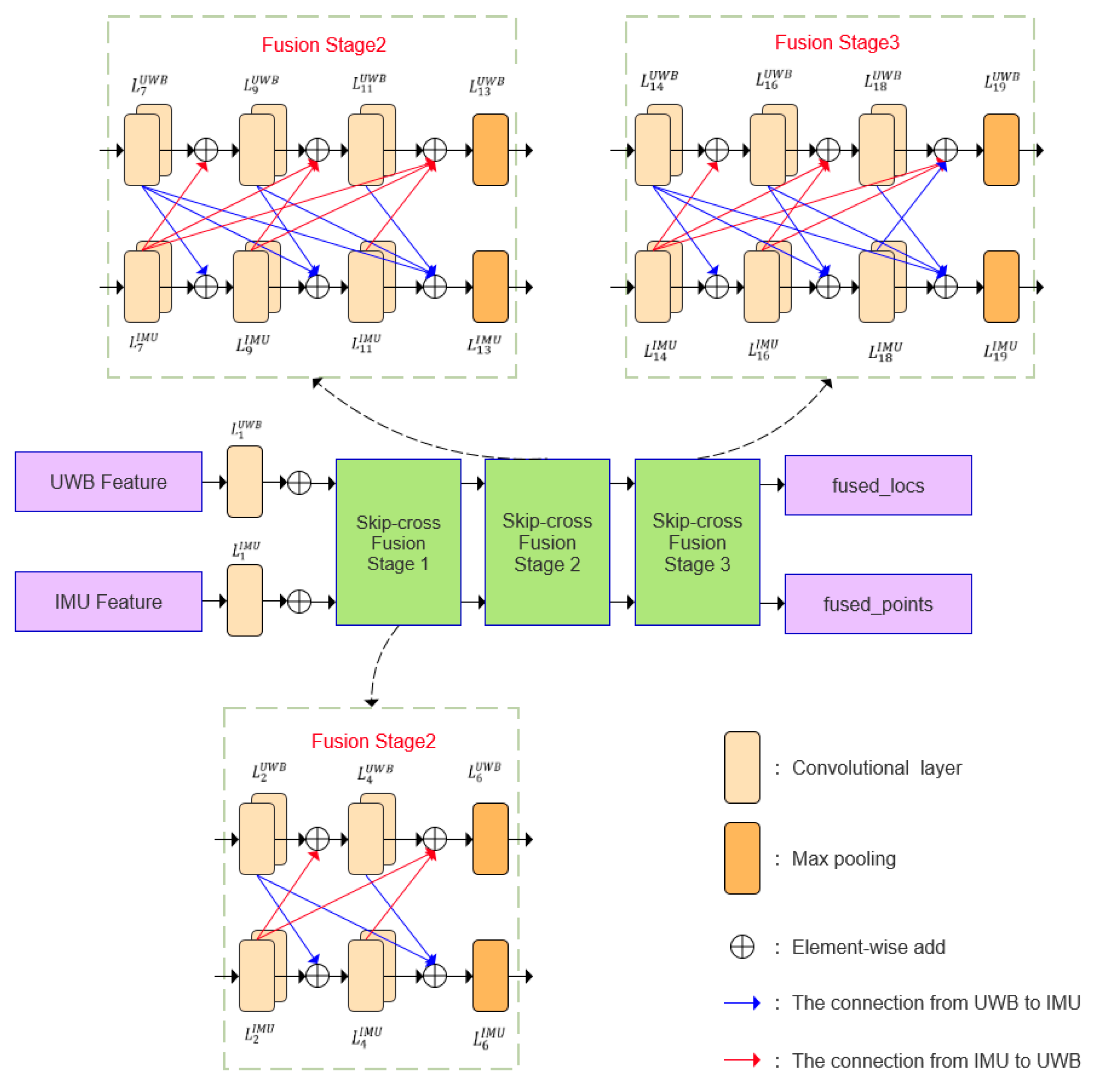
2.2.2. Residual Module for Data Fusion
To enhance the complementarity of information across different data modalities, a residual fusion module is employed for cross-modal integration of UWB and IMU features. The inputs to this module are the temporal features extracted from the respective xLSTMBlockStack branches. These features are initially expanded via convolutional layers into higher-dimensional representations, denoted as
and
, where the superscript indicates the modality and the subscript represents the layer index within each fusion stage. The overall fusion process consists of three stages—early fusion, intermediate fusion, and late fusion—implemented as Skip-cross Fusion Stages 1, 2, and 3, respectively. Each stage contains a residual fusion block that applies multi-scale convolutional processing to extract rich temporal representations from both UWB and IMU inputs. Specifically, each fusion unit employs parallel one-dimensional convolution kernels with sizes
,
,
to capture features across multiple receptive fields, as detailed in Equation (21).
The obtained multiscale convolution results are summed and processed with batch normalization and activation function to obtain the output as shown in Equation (22).
The primary fusion stage utilizes a two-layer multiscale convolutional residual block to process UWB and IMU features, whereas the intermediate and late fusion stages employ three-layer multiscale convolutional residual blocks to progressively strengthen interactions among different features. Furthermore, fusion weights at each stage are dynamically generated by a weight generator, which optimizes the weighted fusion to balance the complementary information from various sensors. Specifically, the dynamic weight generator calculates weights based on the average values of each feature, allowing effective regulation of the weighted fusion across diverse feature sources and enhancing overall fusion performance. In the interaction diagram, red dashed lines indicate information flow from UWB to IMU, while blue dashed lines represent information flow from IMU to UWB. Finally, the module outputs the fused feature vectors,
and
, as defined in Equations (23) and (24).
They primarily retain the information from the positional feature source (UWB data) and the local feature source (IMU data, including acceleration and heading angle), respectively. Here,
and
denote the outputs after processing through the residual block, while
and
represent the results obtained after the application of the learnable weight matrix. The residual fusion module plays a critical role in cross-modal information integration within the proposed model. It is specifically designed to generate more representative global and local features, which serve as enriched inputs for the subsequent attention mechanism. The detailed data processing flow of this module is illustrated in
Figure 7.
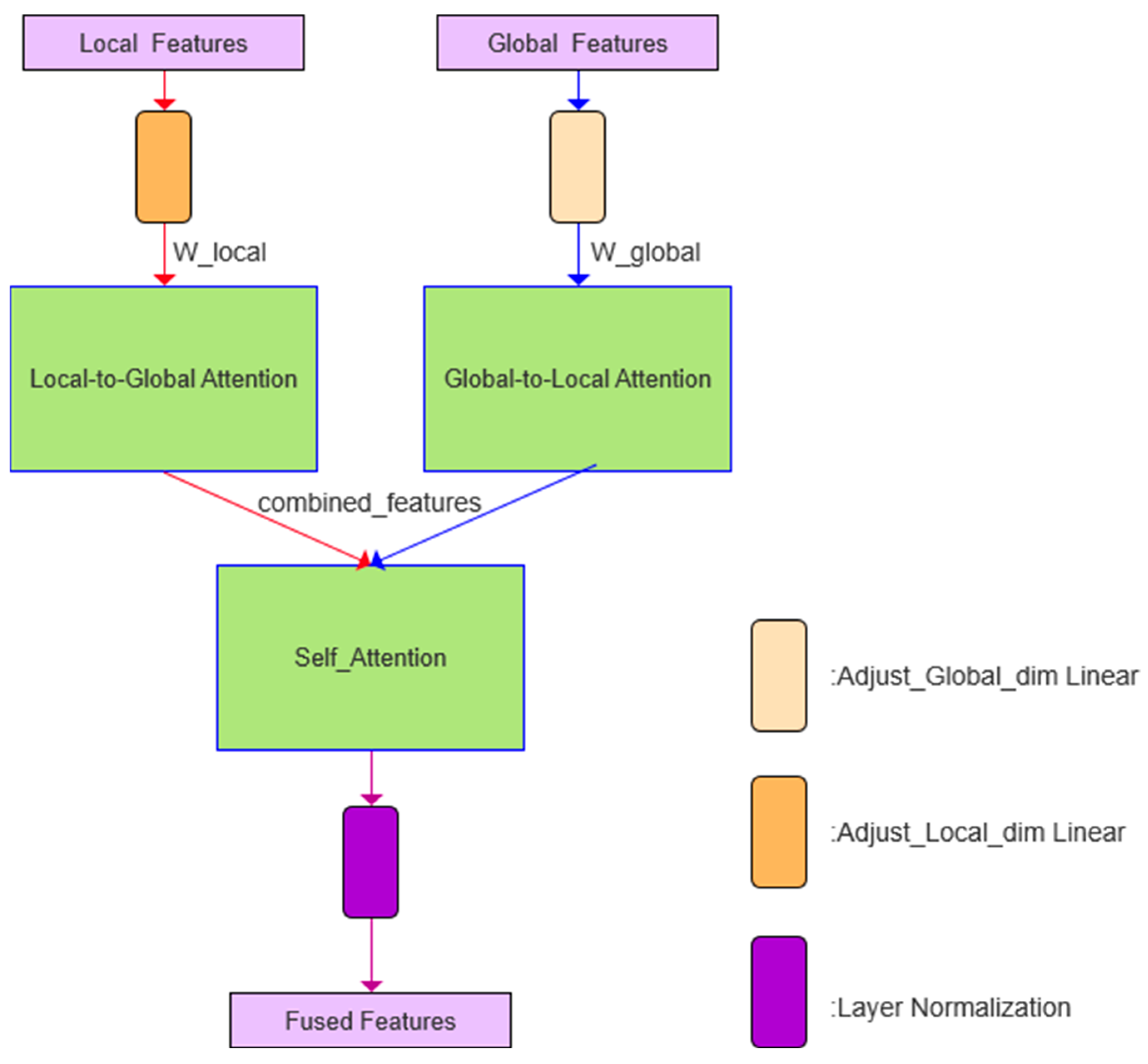
2.2.3. Application of Enhanced Attention Mechanism Module
Due to the varying reliability of different data sources under diverse non-line-of-sight (NLOS) conditions—such as static and dynamic occlusions—an attention mechanism incorporating global–local interactive attention, self-attention, and weighted fusion is employed to enhance the model’s adaptability to complex environments, as illustrated in
Figure 8.
The outputs of the residual module are first adjusted via linear transformation layers to align the UWB features (
) as global features and the IMU features (
) as local features, mapping both to the same dimensional space. These calibrated features are then fed into the global and local attention modules, respectively. During the global-to-local attention computation, local features act as queries while global features serve as keys and values; this operation is reversed for the local-to-global attention computation. These two processes are described by the multi-head attention formula in Equation (25), where Q denotes the query matrix, K denotes the key matrix, V denotes the value matrix,
denotes the key dimension, and the Softmax function ensures that the attention weights sum to 1.
Unlike traditional attention mechanisms with fixed weights, this method introduces learnable weights, as shown in Equations (26) and (27), to regulate the interaction strength between global and local features, where α and β serve as the weighting coefficients.
In contrast to conventional attention mechanisms with fixed weighting schemes, the proposed approach introduces learnable weights to dynamically modulate the interaction strength between global and local features. These weights are applied to the outputs of both global-to-local and local-to-global attention operations, allowing the model to adaptively adjust the fusion ratio based on the characteristics of the input data. This design enables a more flexible and data-driven modeling of cross-modal interactions. A key advantage of this strategy lies in its ability to autonomously calibrate the relative importance of global and local information through learning. For example, when the UWB signal is stable, the model tends to assign higher weights to global features, whereas it shifts its focus toward local features derived from IMU data when the UWB signal becomes unreliable. The resulting weighted global and local features are concatenated and subsequently refined using a self-attention mechanism, which further enhances their interdependencies. This refinement process is formulated in Equation (28), where
denotes the concatenated feature vector representing the integrated global–local interaction.
4. Discussion
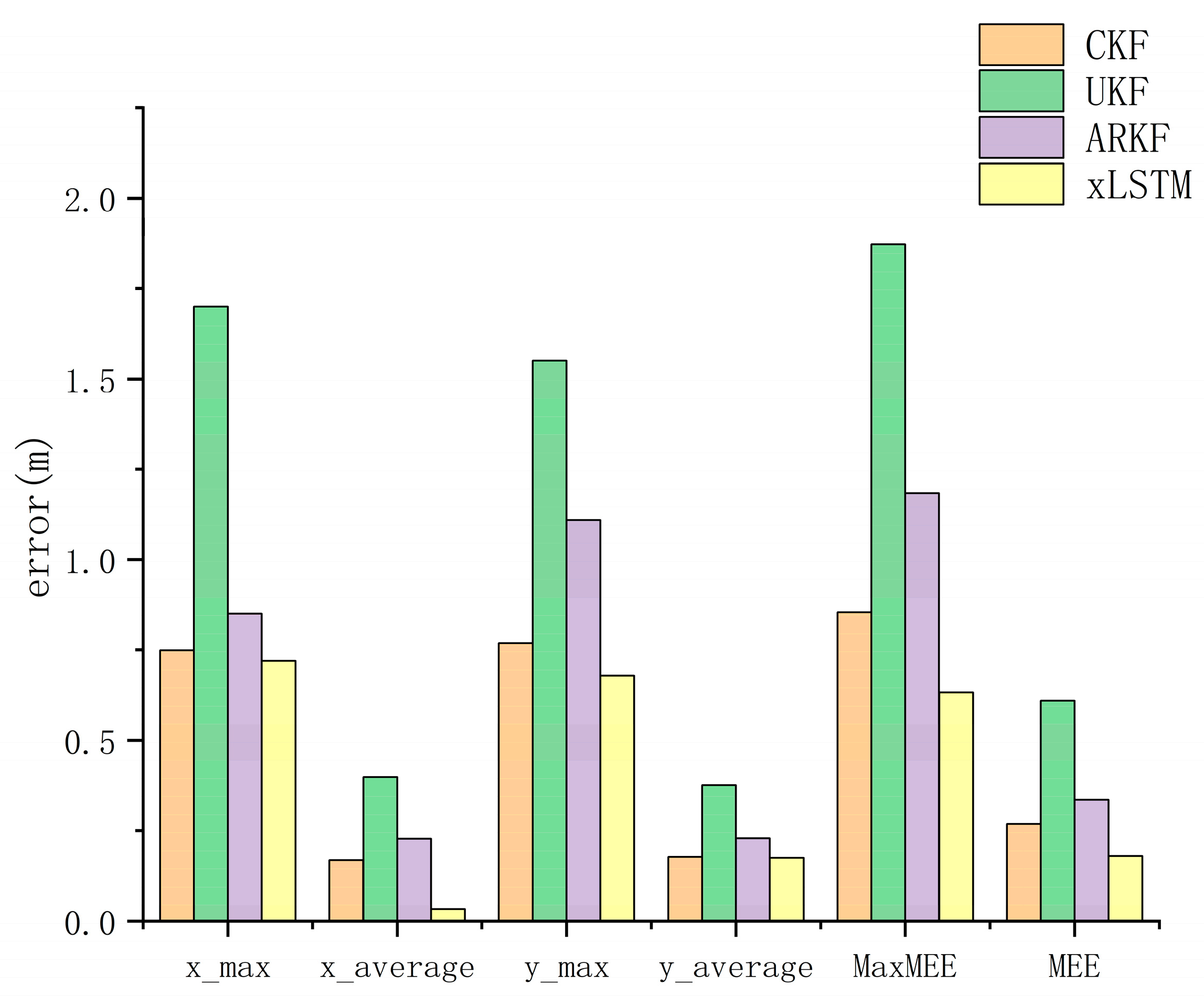
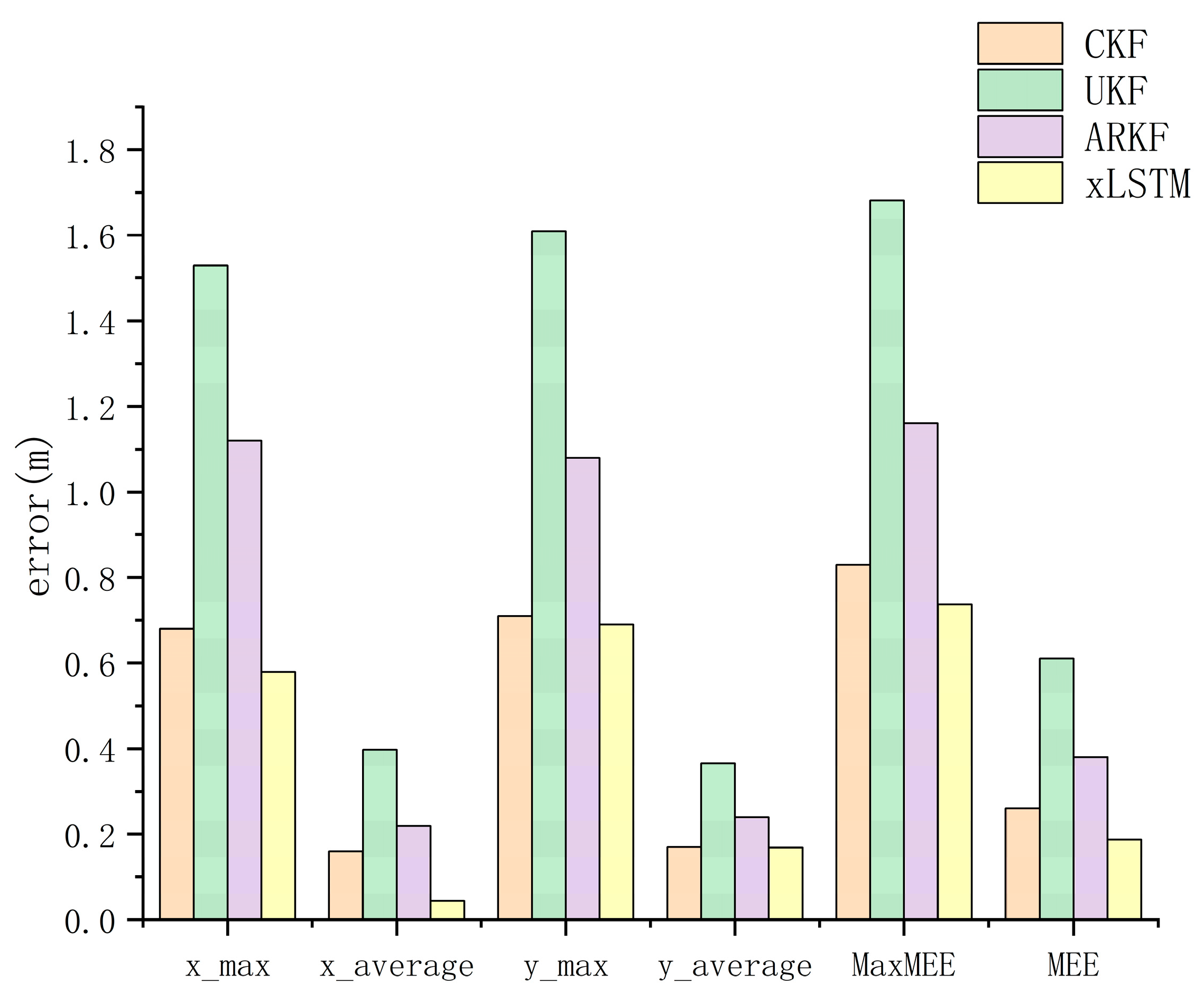
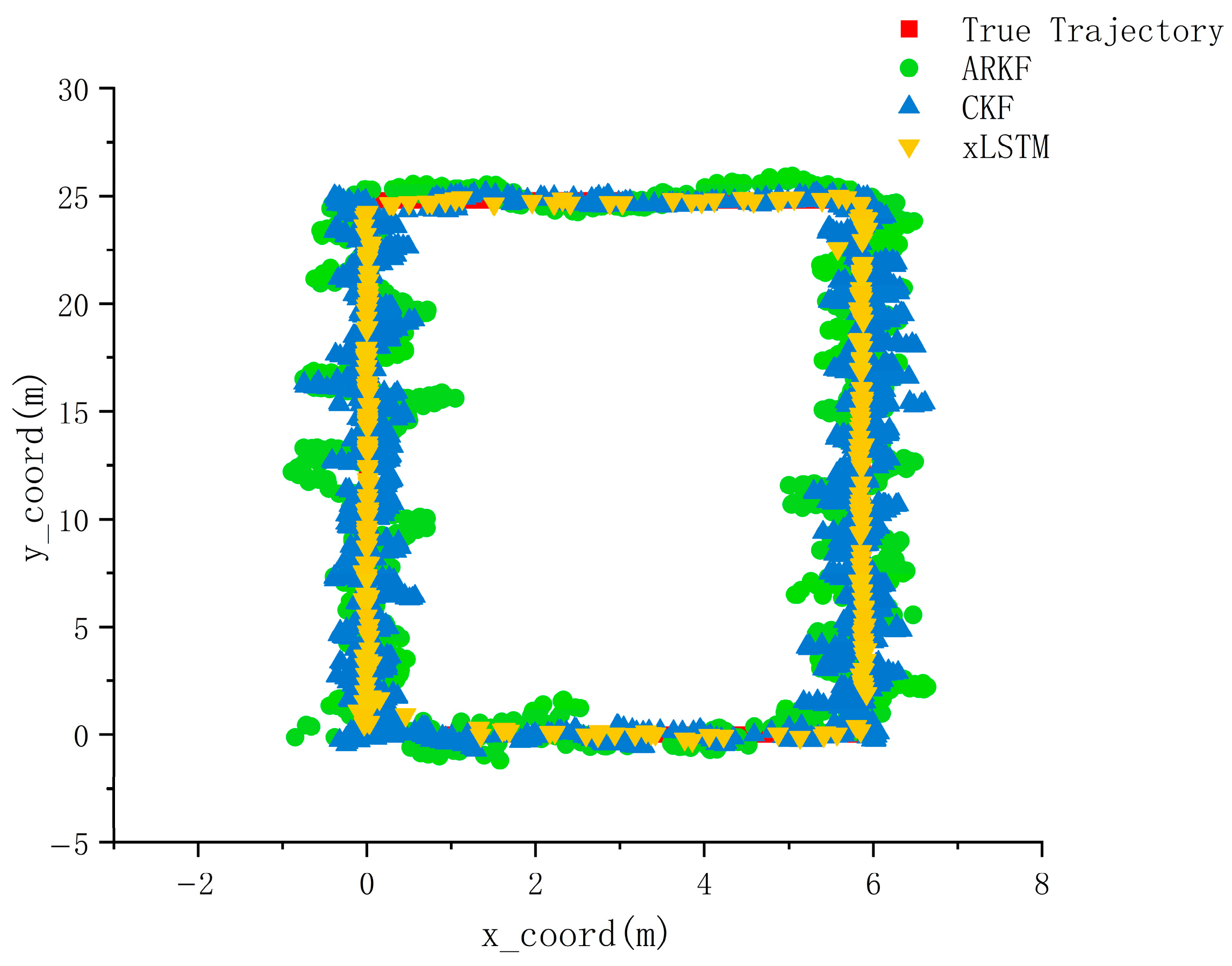
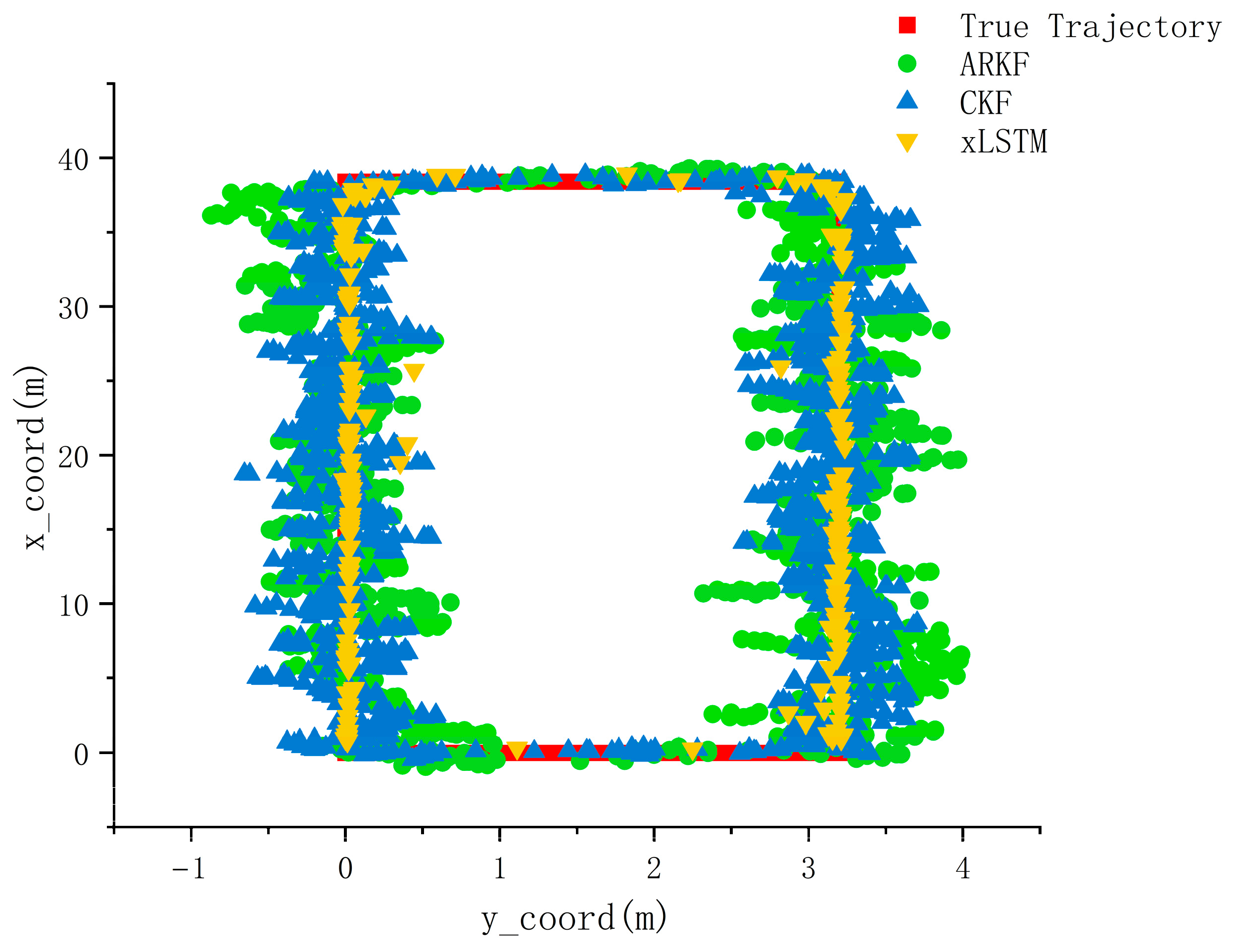
This study presents a high-precision indoor localization method based on multimodal data fusion, achieving intelligent integration of heterogeneous sources and lightweight deployment through a deep neural network architecture. The proposed approach eliminates the heavy reliance of traditional filtering algorithms on parameters such as noise covariance matrices and state equations, while also avoiding the complexity of implementation and deployment caused by extensive hardware setups. Experimental results demonstrate that, compared with various conventional fusion-based localization algorithms, the proposed neural network fusion method significantly improves localization accuracy and environmental adaptability in complex and dynamic scenarios. This work provides new insights and opportunities for applying deep learning techniques to multimodal fusion and high-precision localization tasks.
Nevertheless, several limitations remain. First, although multimodal fusion can effectively reduce estimation errors to some extent, real-world applications often involve alternating line-of-sight (LOS) and non-line-of-sight (NLOS) conditions. Second, the current method relies on supervised learning and therefore requires a considerable amount of labeled data, which may be costly or impractical to obtain in real-world scenarios. Moreover, a systematic hyperparameter search for optimizing network depth and architectural configuration has not yet been conducted.
To address these challenges, future work will focus on incorporating NLOS detection mechanisms and adaptive error compensation strategies. Additionally, we will explore semi-supervised and self-supervised learning paradigms to reduce dependence on labeled data and enhance the model’s robustness and generalization across diverse and challenging environments. We also plan to integrate automated hyperparameter optimization techniques to systematically investigate improved layer configurations and architectural designs, further unlocking the model’s performance potential.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}