

Privacy-Preserving Data Sharing via PCA-Based Dimensionality Reduction in Non-IID Environments


Abstract
1. Introduction
- A privacy-preserving data-sharing mechanism is proposed to mitigate the non-IID problem.
- The proposed mechanism was comprehensively evaluated in terms of accuracy, memory usage, and privacy protection performance, demonstrating superior performance compared with conventional methods.
- The performance was analyzed from both attacker and legitimate user perspectives through experiments simulating data leakage scenarios, verifying that the proposed method effectively prevents privacy exposure.
2. Related Work
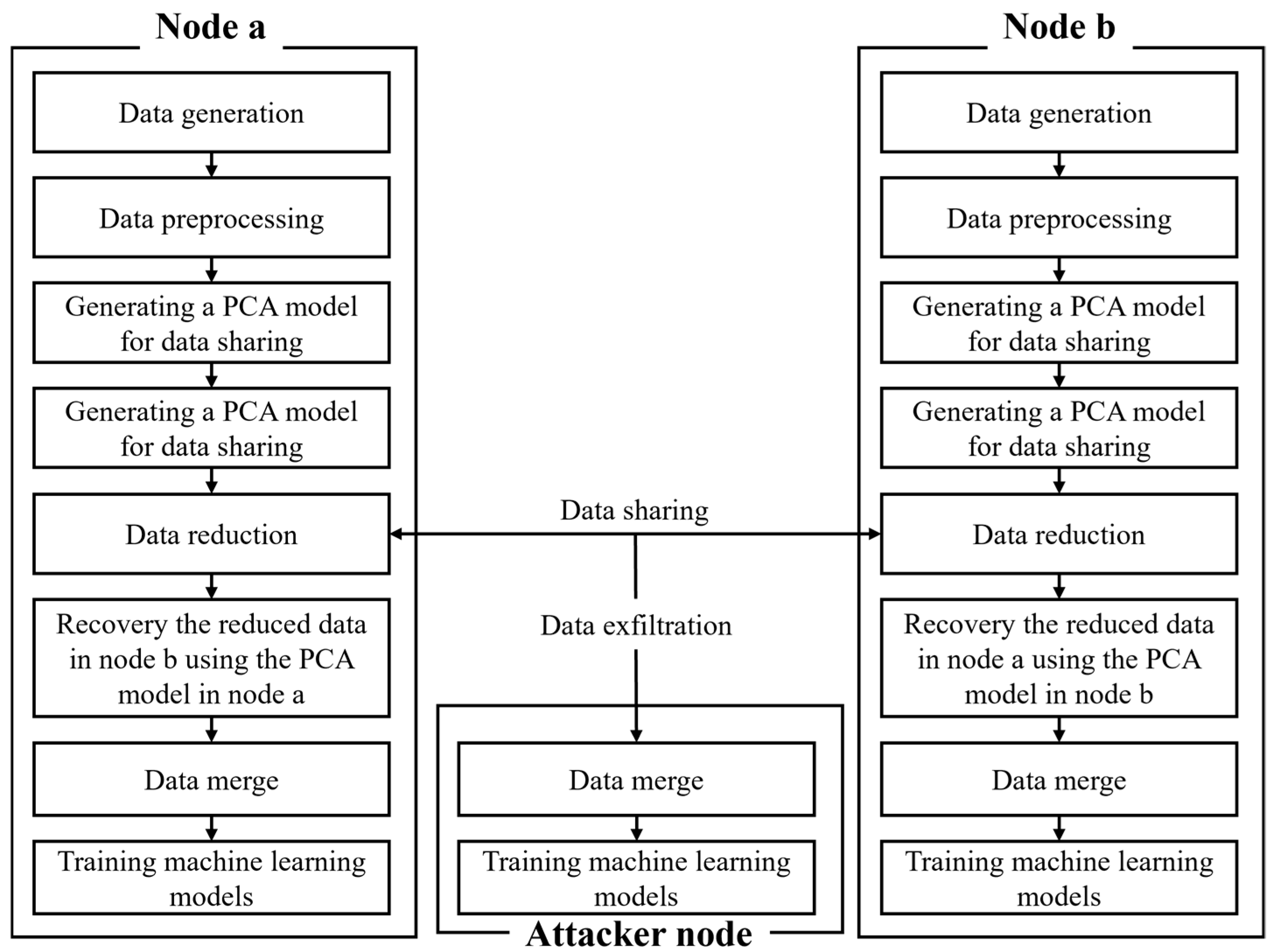
3. Privacy-Preserving Data Sharing via PCA-Based Dimensionality Reduction
4. Evaluation
4.1. Experimental Environment and Dataset
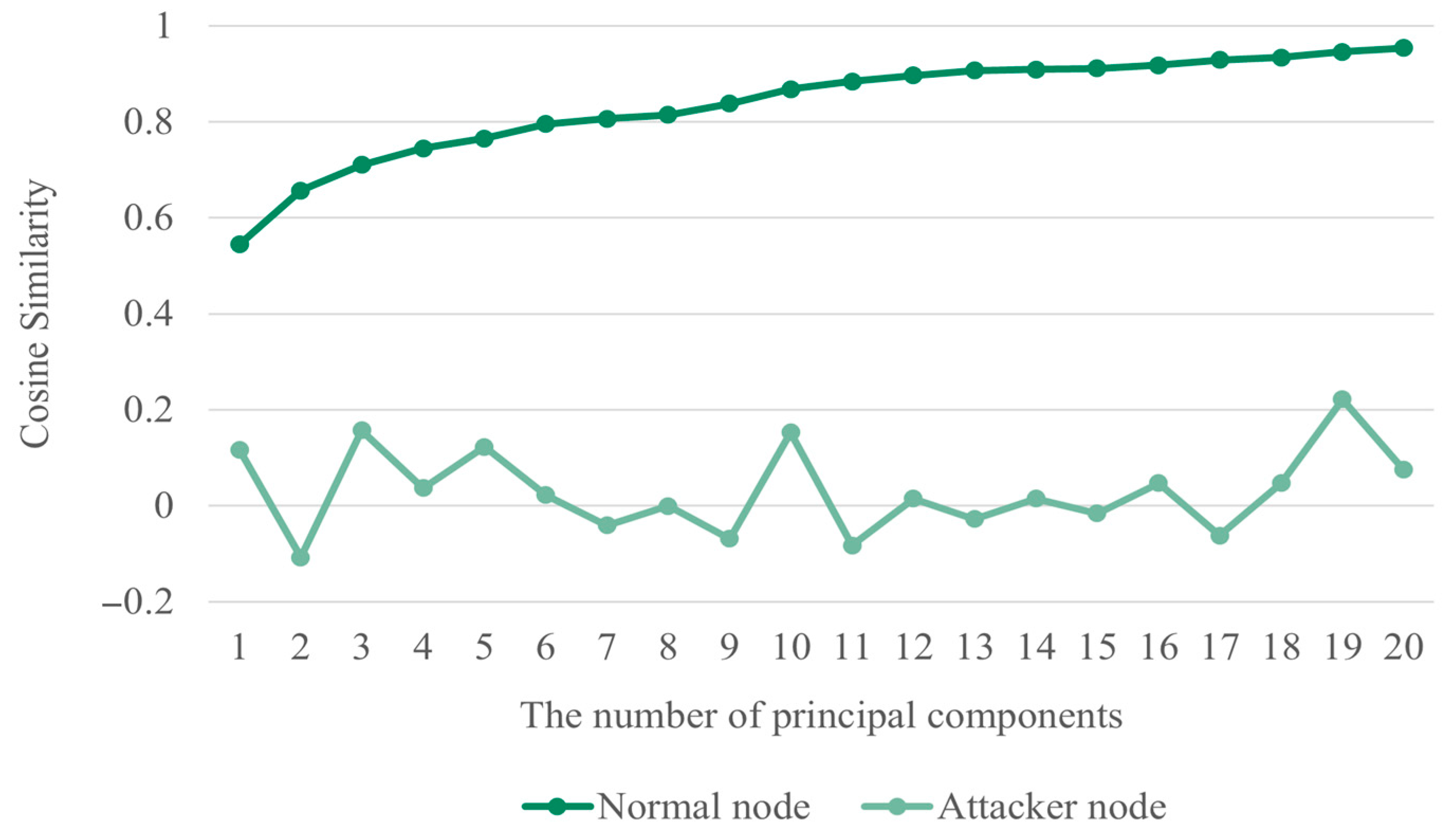
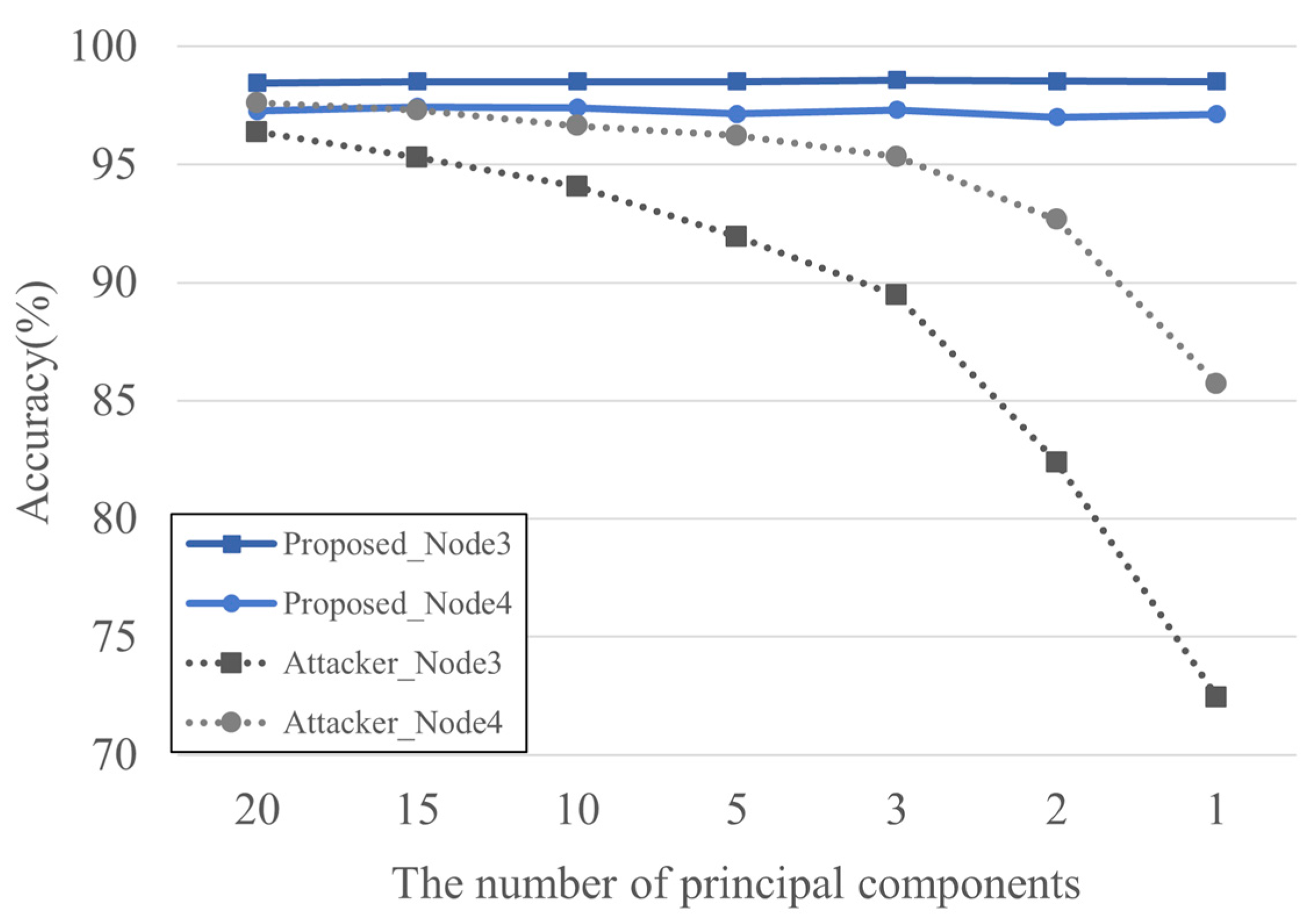
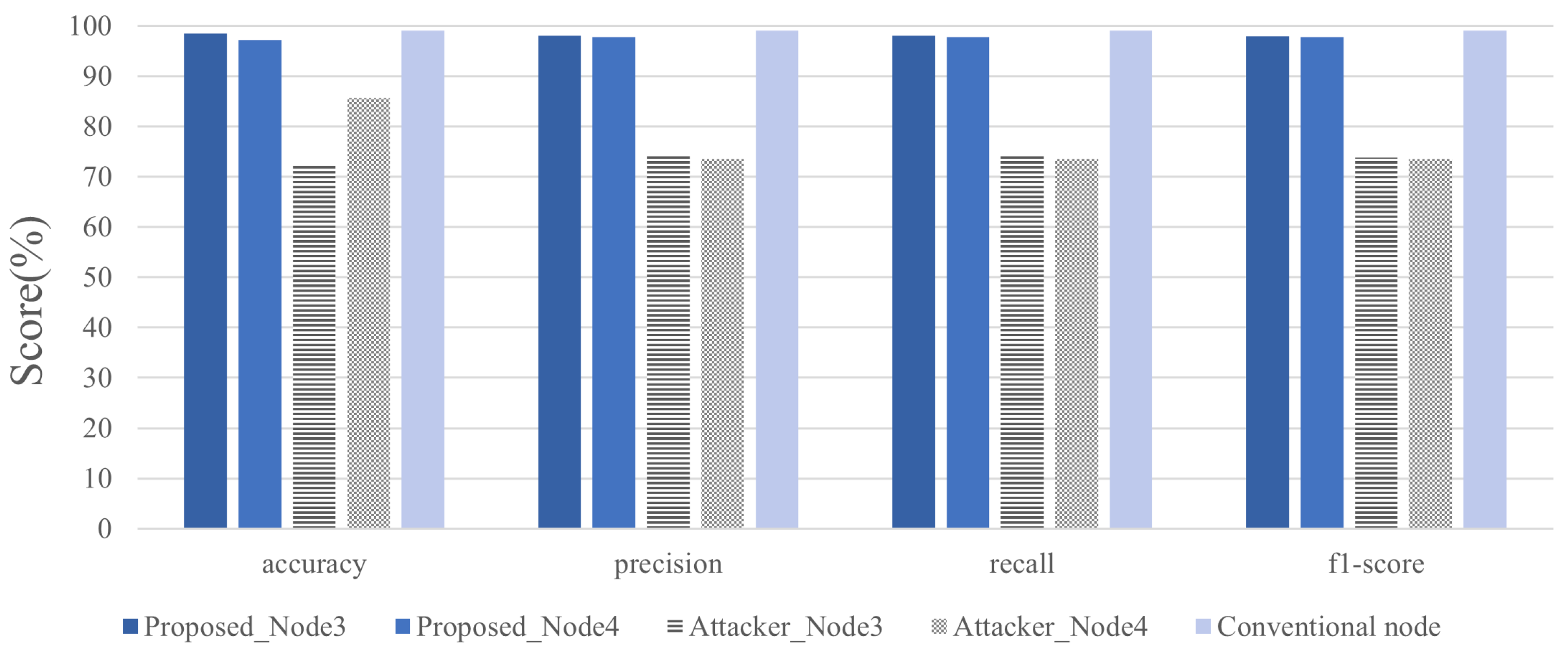
4.2. Experiment and Analysis of Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| IBE | identity-based encryption |
| ICBM | IoT, cloud, big data, and mobile |
| IID | independent and identically distributed |
| IoNT | Internet of Nano-Things |
| IoT | Internet of Things |
| IPFS | InterPlanetary File System |
| LWE | learning with errors |
| MITM | man-in-the-middle |
| PBDL | permissioned blockchain and deep learning |
| PCA | principal component analysis |
References
- Kankanhalli, A.; Charalabidis, Y.; Mellouli, S. IoT and AI for smart government: A research agenda. Gov. Inf. Q. 2019, 36, 304–309. [Google Scholar] [CrossRef]
- Allam, Z.; Dhunny, Z.A. On big data, artificial intelligence and smart cities. Cities 2019, 89, 80–91. [Google Scholar] [CrossRef]
- Ahmad, T.; Zhang, D.; Huang, C.; Zhang, H.; Dai, N.; Song, Y.; Chen, H. Artificial intelligence in sustainable energy industry: Status quo, challenges and opportunities. J. Clean. Prod. 2021, 289, 125834. [Google Scholar] [CrossRef]
- Dlamini, Z.; Francies, F.Z.; Hull, R.; Marima, R. Artificial intelligence (AI) and big data in cancer and precision oncology. Comp. Struct. Biotechnol. J. 2020, 18, 2300–2311. [Google Scholar] [CrossRef]
- Betty, J.J.; Ganesh, E.N. Big data and internet of things for smart data analytics using machine learning techniques. In Proceedings of the International Conference on Computer Networks Big Data and IoT (ICCBI-2019), Madurai, India, 19–20 December 2019; Pandian, A., Palanisamy, R., Ntalianis, K., Eds.; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Ma, X.; Zhu, J.; Lin, Z.; Chen, S.; Qin, Y. A state-of-the-art survey on solving non-IID data in Federated Learning. Future Gener. Comput. Syst. 2022, 135, 244–258. [Google Scholar] [CrossRef]
- Criado, M.F.; Casado, F.E.; Iglesias, R.; Regueiro, C.V.; Barro, S. Non-IID data and Continual Learning processes in Federated Learning: A long road ahead. Inf. Fusion 2022, 88, 263–280. [Google Scholar] [CrossRef]
- Al-Turjman, F.; Zahmatkesh, H.; Shahroze, R. An overview of security and privacy in smart cities’ IoT communications. Trans. Emerg. Telecommun. Technol. 2022, 33, e3677. [Google Scholar] [CrossRef]
- Ioannidou, I.; Sklavos, N. On general data protection regulation vulnerabilities and privacy issues, for wearable devices and fitness tracking applications. Cryptography 2021, 5, 29. [Google Scholar] [CrossRef]
- Zheng, X.; Cai, Z. Privacy-preserved data sharing towards multiple parties in industrial IoTs. IEEE J. Sel. Areas Commun. 2020, 38, 968–979. [Google Scholar] [CrossRef]
- Holla, H.; Sasikumar, A.A.; Gutti, C.; Thumula, K. Advanced privacy and security techniques in federated learning against sophisticated attacks. In Proceedings of the 13th International Symposium on Digital Forensics and Security (ISDFS), Boston, MA, USA, 24–25 April 2025; IEEE: New York, NY, USA, 2024. [Google Scholar]
- Xie, Q.; Jiang, S.; Jiang, L.; Huang, Y.; Zhao, Z.; Khan, S.; Dai, W.; Liu, Z.; Wu, K. Efficiency optimization techniques in privacy-preserving federated learning with homomorphic encryption: A brief survey. IEEE Internet Things J. 2024, 11, 24569–24580. [Google Scholar] [CrossRef]
- Thantharate, P.; Bhojwani, S.; Thantharate, A. DPShield: Optimizing differential privacy for high-utility data analysis in sensitive domains. Electronics 2024, 13, 1233. [Google Scholar] [CrossRef]
- Ahmed, E.O.; Ahmed, A. Differential privacy for deep and federated learning: A survey. IEEE Access 2022, 10, 22359–22380. [Google Scholar] [CrossRef]
- Frimpong, E.; Nguyen, K.; Budzys, M.; Khan, T.; Michalas, A. GuardML: Efficient privacy-preserving machine learning services through hybrid homomorphic encryption. In Proceedings of the 39th ACM/SIGAPP Symposium on Applied Computing (SAC ‘24), Avila, Spain, 8–12 April 2024; Association for Computing Machinery: New York, NY, USA, 2024; pp. 953–962. [Google Scholar] [CrossRef]
- Ishiyama, T.; Suzuki, T.; Yamana, H. Latency-aware inference on convolutional neural network over homomorphic encryption. In Proceedings of the International Conference on Information Integration and Web Intelligence (iiWAS 2022), Virtual Event, 28–30 November 2022; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2022; Volume 13635, pp. 324–337. [Google Scholar] [CrossRef]
- Maćkiewicz, A.; Ratajczak, W. Principal components analysis (PCA). Comput. Geosci. 1993, 19, 303–342. [Google Scholar] [CrossRef]
- Fugkeaw, S. A secure and efficient data sharing scheme with outsourced signcryption and decryption in mobile cloud computing. In Proceedings of the IEEE International Conference on Joint Cloud Computing (JCC), Oxford, UK, 23–26 August 2021. [Google Scholar]
- Singh, A.K.; Saxena, D. A cryptography and machine learning based authentication for secure data-sharing in federated cloud services environment. J. Appl. Sec. Res. 2022, 17, 385–412. [Google Scholar] [CrossRef]
- Athanere, S.; Thakur, R. Blockchain based hierarchical semi-decentralized approach using IPFS for secure and efficient data sharing. J. King Saud Univ. Comput. Inf. Sci. 2022, 34, 1523–1534. [Google Scholar] [CrossRef]
- Kumar, R.; Kumar, P.; Tripathi, R.; Gupta, G.P.; Islam, A.K.M.N.; Shorfuzzaman, M. Permissioned blockchain and deep learning for secure and efficient data sharing in industrial healthcare systems. IEEE Trans. Ind. Inform. 2022, 18, 8065–8073. [Google Scholar] [CrossRef]
- Prajapat, S.; Rana, A.; Kumar, P.; Das, A.K. Quantum safe lightweight encryption scheme for secure data sharing in Internet of Nano Things. Comput. Electr. Eng. 2024, 117, 109253. [Google Scholar] [CrossRef]
- Junqin, H.; Linghe, K.; Jingwei, W.; Guihai, C.; Jianhua, G.; Gang, H.; Muhammad, K.K. Secure data sharing over vehicular networks based on multi-sharding blockchain. ACM Trans. Sens. Netw. 2024, 20, 1–23. [Google Scholar] [CrossRef]
- Thanh, L.N.; Nguyen, L.; Hoang, T.; Bandara, D.; Wang, Q.; Lu, Q.; Xu, X.; Zhu, L.; Chen, S. Blockchain-empowered trustworthy data sharing: Fundamentals, applications, and challenges. ACM Comput. Surv. 2025, 57, 1–36. [Google Scholar] [CrossRef]
- Kumar, K.P.; Prathap, B.R.; Thiruthuvanathan, M.M.; Murthy, H.; Pillai, V.J. Secure approach to sharing digitized medical data in a cloud environment. Data Sci. Manag. 2024, 7, 108–118. [Google Scholar] [CrossRef]
- Halder, S.; Newe, T. Enabling secure time-series data sharing via homomorphic encryption in cloud-assisted IIoT. Future Gener. Comput. Syst. 2022, 133, 351–363. [Google Scholar] [CrossRef]
- Nour, M.; Jill, S. UNSW-NB15: A comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set). In Proceedings of the 2015 Military Communications and Information Systems Conference (MilCIS), Canberra, Australia, 10–12 November 2015; IEEE: New York, NY, USA, 2015. [Google Scholar]
- Nour, M.; Jill, S. The evaluation of Network Anomaly Detection Systems: Statistical analysis of the UNSW-NB15 dataset and the comparison with the KDD99 dataset. Inf. Sec. J. Glob. Perspect. 2016, 25, 18–31. [Google Scholar] [CrossRef]
- Nour, M.; Jill, S.; Gideon, C. Novel geometric area analysis technique for anomaly detection using trapezoidal area estimation on large-scale networks. IEEE Trans. Big Data 2017, 5, 481–494. [Google Scholar] [CrossRef]
- Nour, M.; Gideon, C.; Jill, S. Big Data Analytics for Intrusion Detection System: Statistical Decision-Making Using Finite Dirichlet Mixture Models. In Data Analytics and Decision Support for Cybersecurity; Springer: Cham, Switzerland, 2017; pp. 127–156. [Google Scholar]
- Mohanad, S.; Siamak, L.; Nour, M.; Marius, P. NetFlow datasets for machine learning-based network intrusion detection systems. In Big Data Technologies and Applications, Proceedings of the BDTA WiCON 2020 2020, Virtual Event, 11 December 2020; Deze, Z., Huang, H., Hou, R., Rho, S., Chilamkurti, N., Eds.; Lecture Notes of the Institute for Computer Sciences, Social Informatics and Telecommunications Engineering; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Kil, Y.S.; Lee, Y.J.; Jeon, S.E.; Oh, Y.S.; Lee, I.G. Optimization of privacy-utility trade-off for efficient feature selection of secure Internet of things. IEEE Access 2024, 12, 142582–142591. [Google Scholar] [CrossRef]

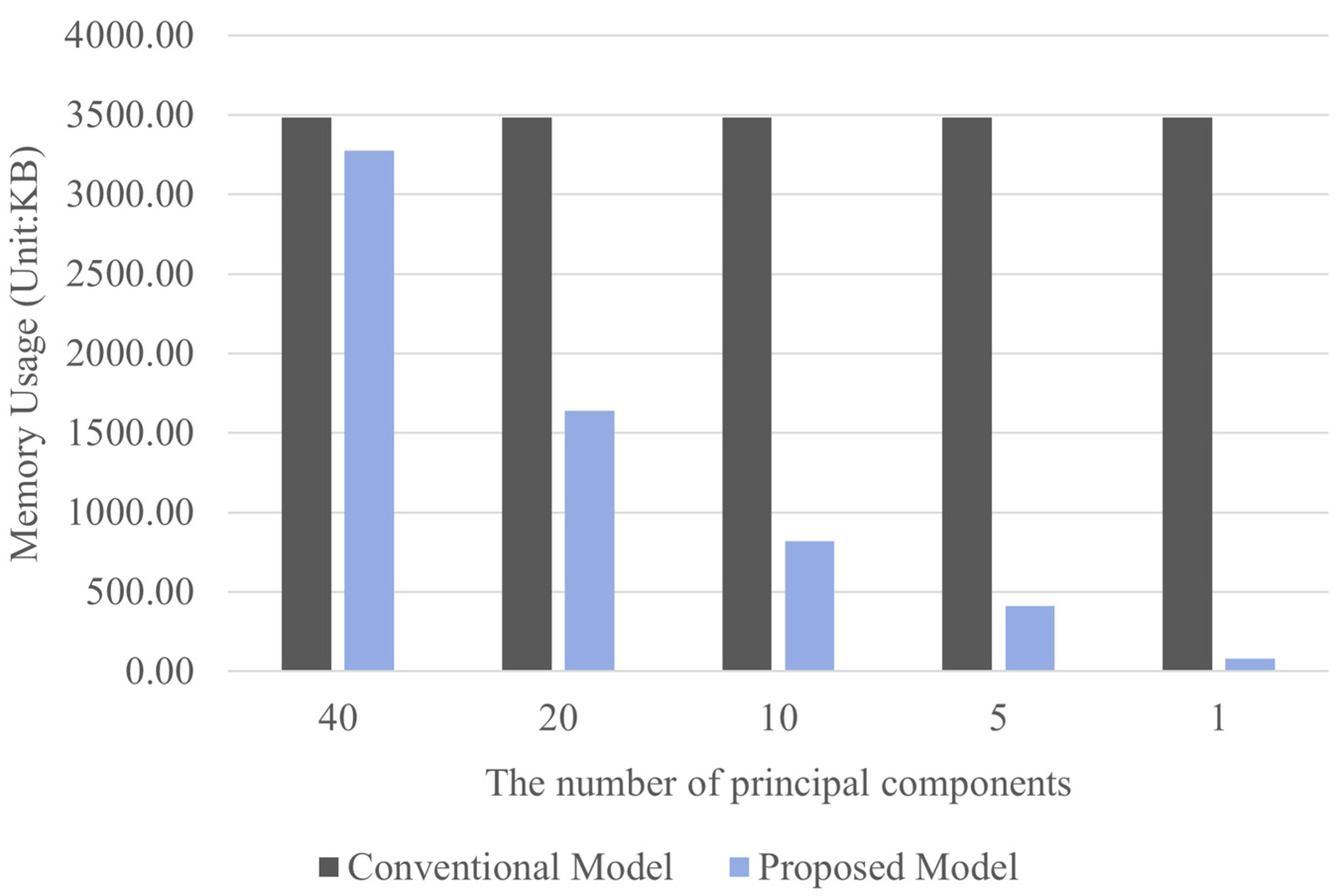
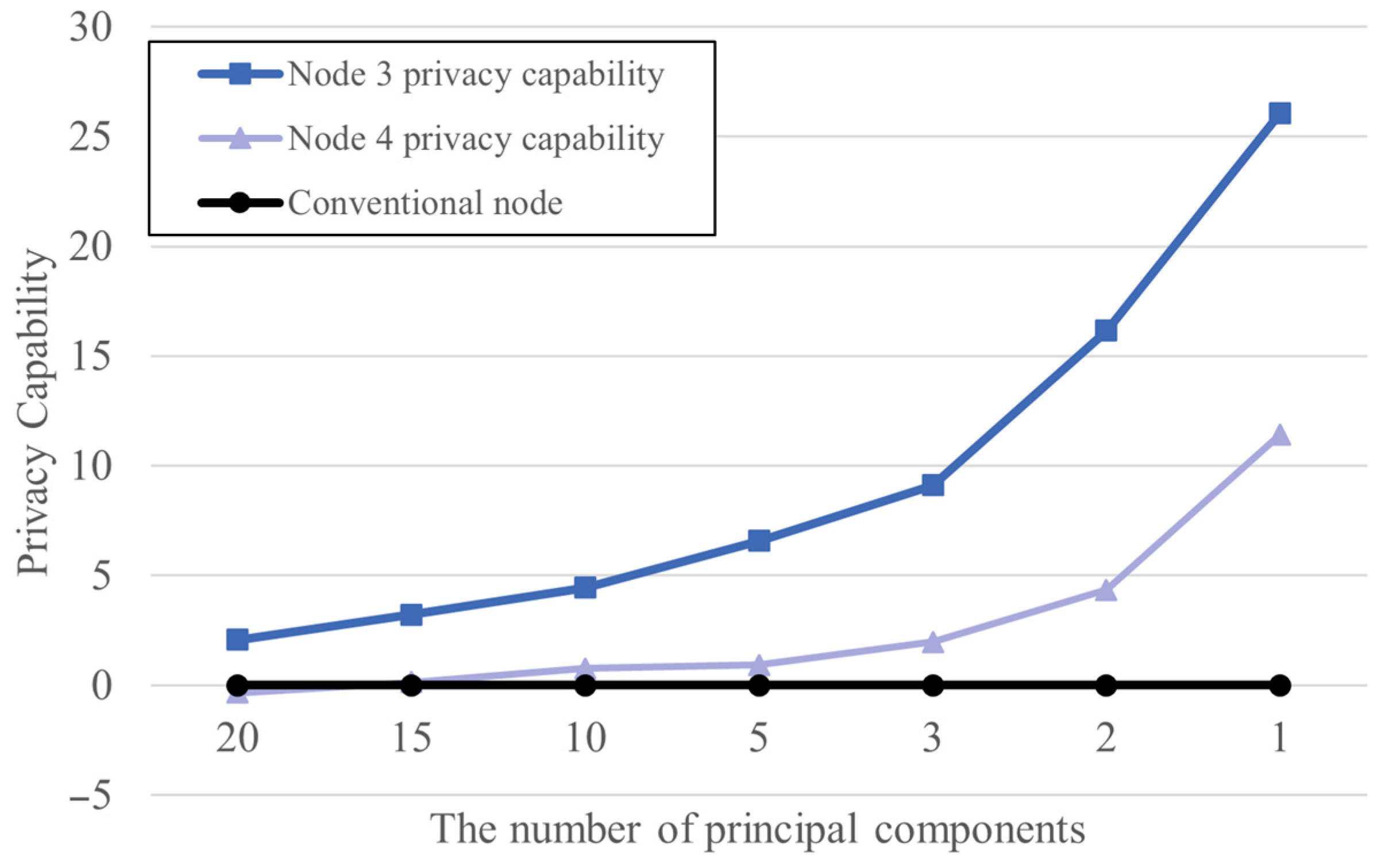

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Privacy | Cost | Usability |
|---|---|---|---|
| [18] | ✔ | ✘ | ✘ |
| [19] | ✔ | ✘ | ✘ |
| [20] | ✔ | ✔ | △ |
| [21] | ✔ | ✘ | ✘ |
| [22] | ✘ | ✔ | ✔ |
| [23] | ✘ | ✔ | ✔ |
| [24] | ✔ | △ | △ |
| [25] | ✔ | ✘ | △ |
| [26] | ✔ | ✔ | ✘ |
| Proposed method | ✔ | ✔ | ✔ |
| Non-IID Ratio | Node | Label: 0 | Label: 1 | Label: 2 | Total |
|---|---|---|---|---|---|
| 1:20 | Node_1 | 5000 | 250 | 5000 | 10,250 |
| Node_2 | 5000 | 5000 | 250 | 10,250 | |
| 1:10 | Node_3 | 5000 | 500 | 5000 | 10,500 |
| Node_4 | 5000 | 5000 | 500 | 10,500 | |
| 1:5 | Node_5 | 5000 | 1000 | 5000 | 11,000 |
| Node_6 | 5000 | 5000 | 1000 | 11,000 | |
| 1:2 | Node_7 | 5000 | 2500 | 5000 | 12,500 |
| Node_8 | 5000 | 5000 | 2500 | 12,500 |
| Non-IID Ratio | Node Type | |||
|---|---|---|---|---|
| Before Sharing | After Sharing | |||
| 1:20 | Node1 | Node2 | Node1 | Node2 |
| 98.04 | 93.86 | 98.06 | 93.82 | |
| 1:10 | Node3 | Node4 | Node3 | Node4 |
| 98.48 | 96.97 | 98.53 | 97.02 | |
| 1:5 | Node5 | Node6 | Node5 | Node6 |
| 98.11 | 97.28 | 98.15 | 97.41 | |
| 1:2 | Node7 | Node8 | Node7 | Node8 |
| 98.06 | 97.82 | 98.04 | 97.82 | |
| Accuracy (%) | Number of Principal Components | |||||||
|---|---|---|---|---|---|---|---|---|
| Node Name | 20 | 15 | 10 | 5 | 3 | 2 | 1 | |
| Before sharing | Node 1 | 98.02 | 98.02 | 98.04 | 98.08 | 98.06 | 98.15 | 98.06 |
| Node 2 | 94.08 | 94.15 | 94.33 | 93.82 | 94.11 | 94.11 | 94.266 | |
| After sharing | Node 1 | 95.31 | 94.43 | 94.76 | 93.85 | 89.43 | 84.87 | 74.47 |
| Node 2 | 97.82 | 98.27 | 97.85 | 97.98 | 96.91 | 94.76 | 90 | |
| Before sharing | Node 3 | 98.46 | 98.51 | 98.51 | 98.51 | 98.57 | 98.53 | 98.51 |
| Node 4 | 97.26 | 97.44 | 97.4 | 97.15 | 97.31 | 97 | 97.13 | |
| After sharing | Node 3 | 96.38 | 95.3 | 94.06 | 91.93 | 89.46 | 82.38 | 72.44 |
| Node 4 | 97.6 | 97.3 | 96.63 | 96.22 | 95.33 | 92.66 | 85.71 | |
| Before sharing | Node 5 | 98.06 | 98.02 | 98.08 | 98.17 | 97.86 | 97.95 | 98.11 |
| Node 6 | 97.44 | 97.57 | 97.4 | 97.6 | 97.44 | 97.53 | 97.4 | |
| After sharing | Node 5 | 95.27 | 95.03 | 94.6 | 92.3 | 89.06 | 95.51 | 69.45 |
| Node 6 | 96.72 | 96.39 | 96.39 | 94.27 | 93.12 | 90.3 | 82.24 | |
| Before sharing | Node 7 | 97.97 | 97.97 | 97.84 | 97.91 | 97.8 | 97.62 | 97.97 |
| Node 8 | 97.26 | 97.44 | 97.4 | 97.15 | 97.31 | 97 | 97.13 | |
| After sharing | Node 7 | 96.38 | 95.3 | 94.06 | 91.93 | 89.46 | 82.38 | 72.44 |
| Node 8 | 97.65 | 97.3 | 96.63 | 96.22 | 95.33 | 92.66 | 85.71 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, Y.-J.; Shin, N.-Y.; Lee, I.-G. Privacy-Preserving Data Sharing via PCA-Based Dimensionality Reduction in Non-IID Environments. Electronics 2025, 14, 2711. https://doi.org/10.3390/electronics14132711
Lee Y-J, Shin N-Y, Lee I-G. Privacy-Preserving Data Sharing via PCA-Based Dimensionality Reduction in Non-IID Environments. Electronics. 2025; 14(13):2711. https://doi.org/10.3390/electronics14132711
Chicago/Turabian StyleLee, Yeon-Ji, Na-Yeon Shin, and Il-Gu Lee. 2025. "Privacy-Preserving Data Sharing via PCA-Based Dimensionality Reduction in Non-IID Environments" Electronics 14, no. 13: 2711. https://doi.org/10.3390/electronics14132711
APA StyleLee, Y.-J., Shin, N.-Y., & Lee, I.-G. (2025). Privacy-Preserving Data Sharing via PCA-Based Dimensionality Reduction in Non-IID Environments. Electronics, 14(13), 2711. https://doi.org/10.3390/electronics14132711