1. Introduction
Efficient management of specialized tools is critical to ensuring both production safety and product quality in aviation manufacturing, particularly during frequent and complex boarding operations. Residual tools or foreign objects left in the aircraft after maintenance or assembly can severely impact the safety and reliability of the aircraft, posing significant risks to operations. This makes tool management an essential aspect of maintaining safety standards and operational efficiency in aviation manufacturing environments. Traditional manual methods for tool tracking and analysis are hindered by inefficiencies, low accuracy, and a lack of comprehensive electronic records, making it difficult to meet the evolving demands of modern production environments. As the need for automation and real-time decision-making in industrial operations grows, it becomes clear that these traditional methods are insufficient to support the high-speed and high-accuracy requirements of contemporary aviation manufacturing.
Recent advancements in deep learning [
1,
2] have significantly improved the performance of computer vision-based systems for tool detection and management. Discriminative vision models such as YOLO have been widely used for real-time object detection. However, in practical industrial applications, challenges such as accuracy degradation under diverse conditions, computational overhead on edge devices [
3], and a lack of semantic understanding for decision support still limit their full potential.
To address these limitations, our proposed framework integrates multiple components to ensure end-to-end intelligent tool management. First, to enhance robustness across variable tool types and scales, a self-attention mechanism (SAM) is employed for multi-scale feature fusion. Second, knowledge distillation [
4,
5,
6] and pruning [
7,
8,
9,
10,
11,
12,
13] are adopted to compress models, enabling efficient inference on resource-constrained edge devices without compromising accuracy. Third, to support semantic-level interaction, generative large language models (LLMs), such as those based on retrieval-augmented generation (RAG), are used to transform user queries into executable SQL statements and retrieve structured results from the database. These modules collectively operate through an agent-based mechanism that bridges low-level perception and high-level decision-making. This unified architecture forms a practical and scalable pipeline from real-time edge-side detection to intelligent data-driven management, particularly suited for tool tracking and safety supervision in high-end equipment manufacturing.
Figure 1 presents sample images from the aircraft boarding tool (ABT) dataset used in our detection tasks.
In this study, we introduce a novel approach to enhance the feature representation capability of networks for target datasets by incorporating a self-attention mechanism (SAM) for multi-scale feature fusion. This mechanism enables the network to effectively capture object-related information in the feature space of a target dataset. Furthermore, we propose a compression method that combines knowledge distillation with pruning techniques to construct a compact and efficient network. This optimized model is specifically designed to meet the constraints of deployment resources while maintaining high performance on the target dataset. In addition, to address the complex and dynamic demands of tool management in aviation manufacturing, a single detection model is insufficient. Rather than designing an isolated detection module, this study proposes an integrated framework that combines lightweight computer vision models with retrieval-augmented large language models (LLMs). We integrate an LLM, enhanced by retrieval-augmented generation (RAG), to analyze tool detection results, enabling the system to rapidly provide relevant information about operational tools for management personnel and facilitating intelligent monitoring and control.
The main aims of this study are as follows:
Introduce the SAM module for multi-scale feature fusion to enhance the extraction of object-related information in the target dataset.
Propose an attention-based and channel distillation strategy to improve feature transfer while maintaining model compactness.
Develop a dynamic sparsity-based pruning approach with a one-shot pruning scheme to achieve efficient model compression.
Integrate an LLM enhanced by retrieval-augmented generation (RAG) to reconstruct knowledge from detection results, enabling intelligent monitoring and decision-making.
2. Related Work
2.1. Visual Recognition
Visual recognition technology has evolved from early handcrafted feature-based methods to modern deep learning approaches. Traditional techniques, such as Scale-Invariant Feature Transform (SIFT) [
14] and Histogram of Oriented Gradients (HOG) [
15], relied on manually designed feature extraction but lacked generalization capability. Machine learning methods like Principal Component Analysis (PCA) [
16] and Support Vector Machines (SVMs) [
17] improved recognition accuracy by learning discriminative representations. Deep learning made visual recognition an end-to-end process, with convolutional neural networks (CNNs) automatically extracting hierarchical features from raw images. The success of AlexNet [
18] in the 2012 ImageNet Challenge marked a turning point, leading to more advanced architectures such as VGGNet [
1], GoogLeNet [
19], and ResNet [
20], which introduced deeper networks and residual connections to improve training stability and accuracy. Object detection, an important task in visual recognition, has evolved from traditional methods to CNN-based models, greatly improving accuracy and efficiency. R-CNN [
21] and its successors, Fast R-CNN [
22] and Faster R-CNN [
23], improved detection efficiency through region proposal networks. To further enhance real-time performance, single-stage detectors like YOLO [
24] and SSD [
25] eliminated the need for region proposals, enabling the direct prediction of object locations and classifications in a single pass. Recently, the YOLO series [
26,
27,
28] has improved the balance between speed and accuracy by optimizing architecture and feature fusion techniques. These advancements have significantly expanded the applications of visual recognition in industrial automation.
2.2. Model Compression
Deep convolutional neural networks have shown great results in computer vision, but their large size and complexity limit use in industrial settings. Model compression helps reduce costs, speed up inference, and lower memory usage, making them more suitable for resource-limited environments. Knowledge distillation is a technique used to transfer knowledge from a large, complex model (the teacher) to a smaller model (the student) to improve the student’s performance without significant accuracy loss. The student imitates the teacher by leveraging information from the teacher’s activations, neurons, and features, enabling competitive results even in resource-constrained environments like mobile devices [
4]. Hinton et al. [
29] introduced knowledge distillation, transferring knowledge from an ensemble of large models to a smaller model to improve performance and deploymentease. Tung et al. [
30] proposed similarity-preserving knowledge distillation, where the student network focuses on maintaining its own representation space while ensuring similar inputs lead to similar activations, unlike traditional methods that require mimicking the teacher’s representation space. Additionally, network pruning has made notable progress recently, as it effectively decreases model size while yielding more efficient networks. Network pruning [
7,
8] can reduce computational overhead while maintaining model performance by reducing network parameters and structural complexity. In recent years, many studies have focused on how to implement more efficient pruning algorithms, including pruning criteria [
9], sparsity optimization [
12], and dynamic pruning strategies [
13,
31]. With the development of hardware accelerators, the application of structured pruning in practice is becoming increasingly widespread.
2.3. Large Language Models
Large language models (LLMs), particularly those based on decoder-only Transformer models, have become central to advancing Artificial General Intelligence (AGI) [
32]. Large language models have also been increasingly applied across various domains. In aerospace, LLMs with retrieval-augmented generation (RAG) are used to access standards and technical documentation efficiently [
33]. In healthcare, RAG helps mitigate hallucinations by incorporating peer-reviewed studies and internal guidelines [
34]. In tourism, LLM-RAG systems support personalized recommendations and quality-aware evaluation [
35]. Recently, the building engineering field has also leveraged RAG with hybrid indexing strategies to support structured reasoning and lifecycle knowledge management [
36]. These applications highlight the versatility of LLMs when combined with domain-specific retrieval. By predicting words, LLMs undergo pre-training on large datasets, enabling them to perform various tasks, such as key information extraction and content generation. Subsequent improvements through supervised fine-tuning (SFT) [
37] and preference optimization (DPO) [
38] have enhanced their ability to follow user instructions and engage in versatile conversations. The LLaMA series models have set a benchmark for open-source LLM performance [
39]. Research on scaling laws is crucial for advancing AGI, as it helps determine the optimal balance of model size, data, and compute resources [
40]. Retrieval-augmented generation (RAG) methods include information indexing and retrieval, information augmentation, and answer generation. For example, PGRA [
41] uses a retriever to search and re-rank context data before generating a response. Additionally, some studies focus on optimizing the retrieval process using previous answers [
42] or expanding the knowledge base with search engines to include the latest information [
43]. Therefore, by using RAG-based methods, LLMs can dynamically retrieve detection information from tool-identified data in real time, ensuring accurate and up-to-date responses.
3. Methods
This section provides a detailed description of the proposed method. We present the architecture of our proposed method. We proposed a lightweight detection model for industrial applications based on the YOLOv8 architecture, introducing a self-attention mechanism (SAM) for multi-scale feature fusion within the student network to enhance its feature segmentation capability on the target dataset. The self-attention mechanism effectively improves detection accuracy for targets of different sizes. We employed attention distillation and feature distillation techniques for model training, utilizing a pre-trained teacher network to provide soft targets and attention guiding for the knowledge distillation process. To further compress the model, we applied dynamic sparsity training and pruning to the trained student network, resulting in a more compact segmentation detection model. Furthermore, we integrated a large language model (LLM), enhanced through retrieval-augmented generation (RAG) to analyze segmentation detection results, enabling the system to quickly provide relevant prompt information to management personnel.
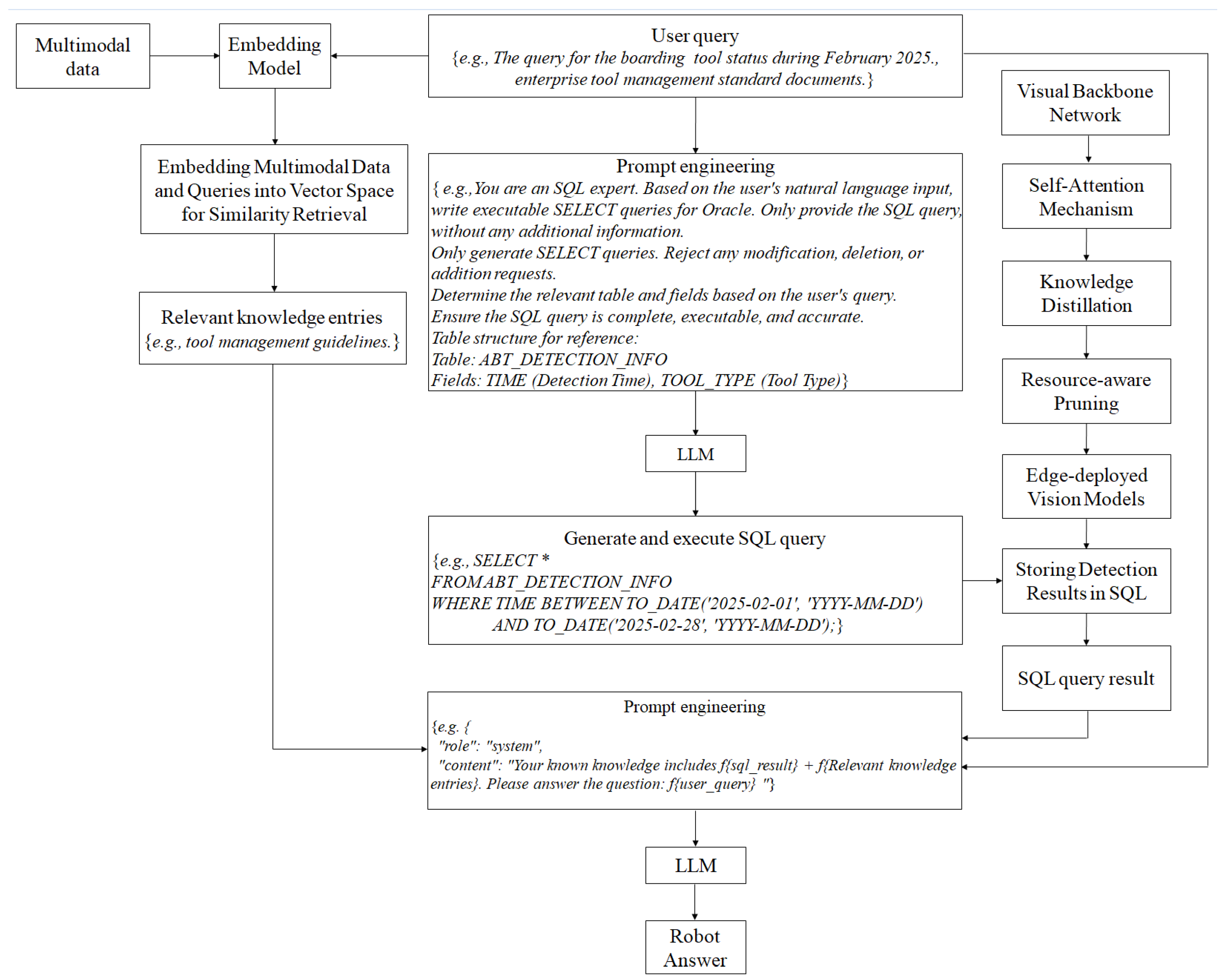
The entire workflow process of model architecture, distillation, pruning, and LLM is shown in
Figure 2. To ensure that the proposed tool identification system does not become an isolated functional component, the entire framework is designed as an integrated and scalable pipeline that connects real-time detection with enterprise-level decision-making. The system combines lightweight computer vision algorithms, efficient model compression strategies, and a retrieval-augmented language model for semantic-level analysis. This integration supports not only accurate detection but also dynamic monitoring, traceability, and data-driven management, making it a complete solution for tool safety supervision in complex manufacturing scenarios. The complexity of the proposed system reflects its functional breadth—from robust feature extraction to edge inference and semantic reasoning—offering a practical and unified solution for high-stakes manufacturing environments.
In contrast to conventional single-purpose detection models, the complexity of the proposed system reflects the real-world demands of aviation manufacturing, where safety, efficiency, and traceability must be achieved simultaneously. Rather than adding complexity for its own sake, each component in the system—from multi-scale detection to knowledge-driven reasoning—addresses a specific industrial need. The RAG-based LLM module enables high-level understanding and query-based interaction, turning raw detection outputs into actionable insights for decision support. This end-to-end solution ensures interoperability across digital systems, facilitating integration into enterprise workflows.
Our proposed framework integrates discriminative vision edge models (e.g., YOLO and SAM) for real-time tool detection, combined with model compression techniques such as knowledge distillation and pruning to support efficient deployment in resource-constrained edge environments. On the cloud side, generative LLM modules (including RAG and LLM) are employed to interpret detection results, generate SQL queries via prompt-based reasoning, and retrieve relevant information from structured databases. These components are orchestrated through an agent-based mechanism that enables intelligent query understanding and provides decision-making support. This unified architecture establishes a complete pipeline from edge-side visual recognition to cloud-based intelligent management, offering a scalable and practical solution for tool tracking and safety management in high-end equipment manufacturing.
3.1. Self-Attention Mechanism
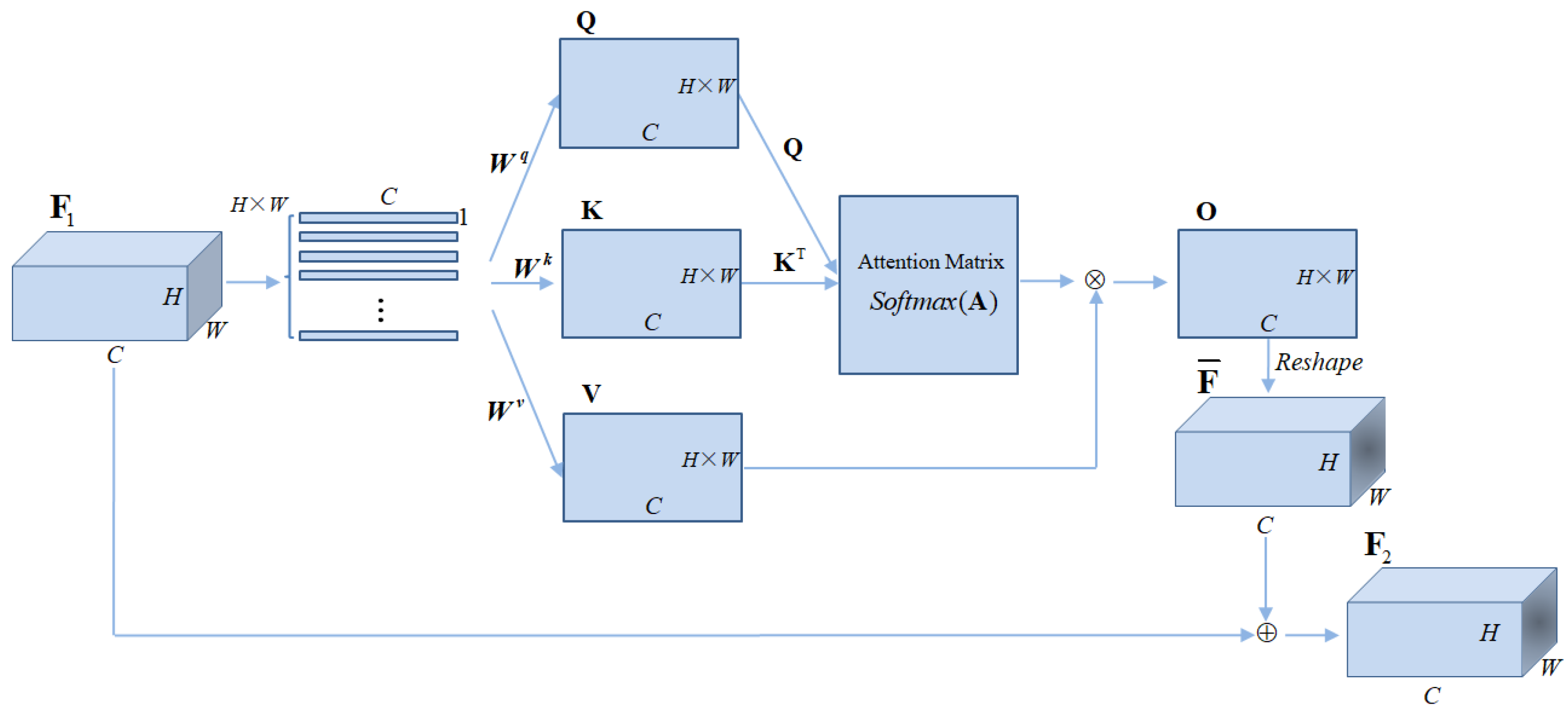
The direct concatenation of multi-scale features lacks the description of the spatial position relationship within the features. In order to enhance the fusion capability of multi-scale features and enable the neural network to focus more on target regions, we proposed a feature fusion method based on the self-attention mechanism (SAM). This method computes the correlations between feature space content and target objects, effectively improving object detection performance.
We designed a self-attention mechanism, as illustrated in
Figure 3. Specifically, the input feature
has a size of
. It is reshaped along the spatial dimensions
H ×
W into
H ×
W feature vectors of size 1 ×
C, denoted as
I. Each vector represents the feature characteristics at a specific spatial location. Subsequently, these vectors are transformed using learnable weight matrices
,
, and
to generate the corresponding Query (
Q), Key (
K), and Value (
V) representations, which are computed as follows:
where the multiplication between the learnable weight matrices
,
, and
and the input feature vector
I is a standard matrix multiplication operation. The self-attention matrix
and the feature map
are then computed as follows:
Subsequently, the feature map is reshaped to obtain . Finally, by performing an element-wise addition of with the feature map , the adjusted feature map is obtained, thereby refining the original feature representation.
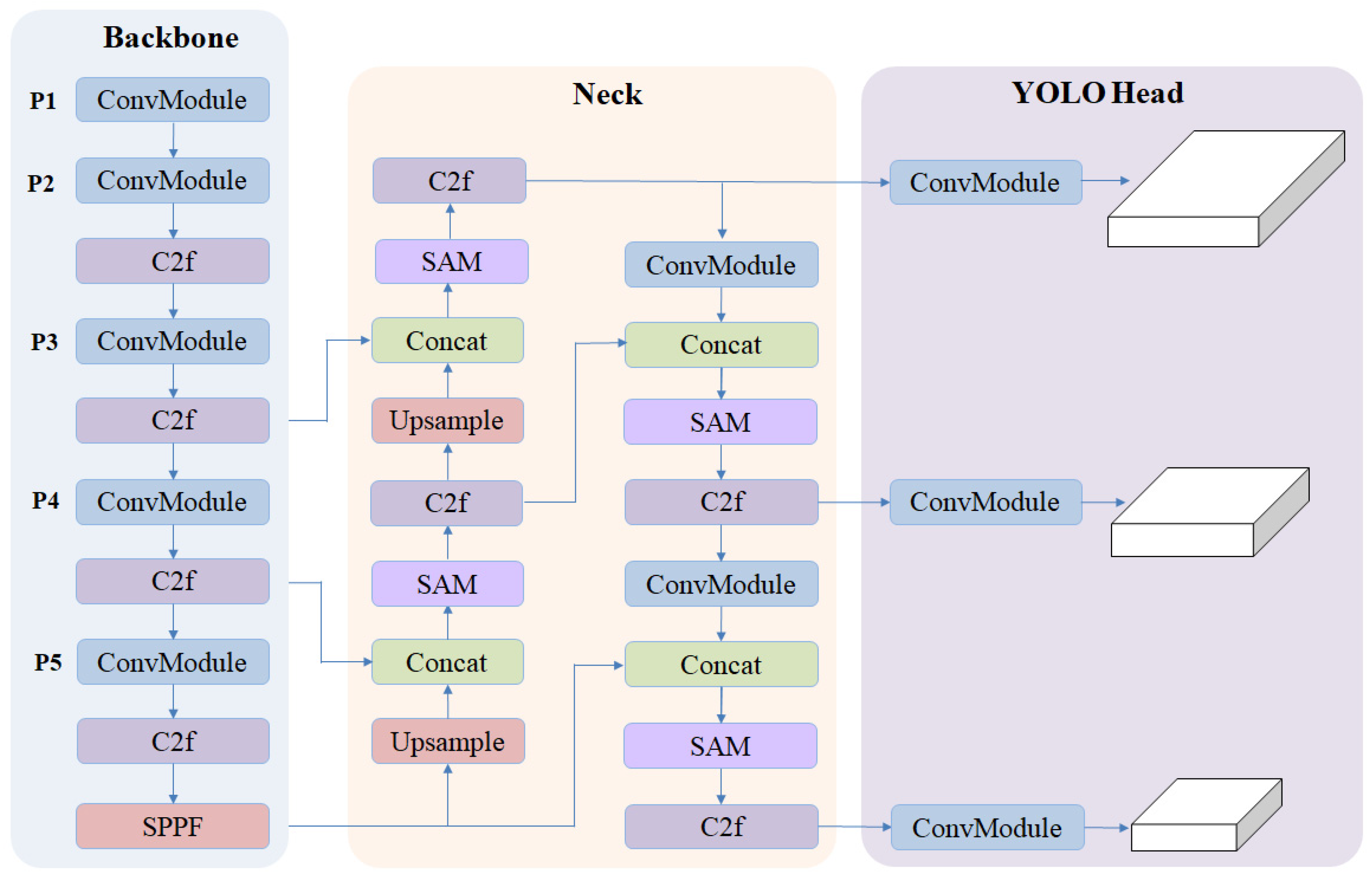
We placed the self-attention mechanism module in the Neck section of the YOLOv8 network, as shown in
Figure 4. We incorporated the proposed self-attention mechanism (SAM) after each concatenation of multi-scale features, called YOLOv8-SAM. By effectively merging features from different scales, the self-attention mechanism enhances spatial correlation information. This mechanism helps to extract more precise target features and capture fine-grained details, significantly improving the network’s robustness in complex environments. The self-attention mechanism is designed to enrich feature representation by capturing spatial dependencies across various regions, thus enhancing the model’s ability to focus on the most relevant information while suppressing irrelevant details.
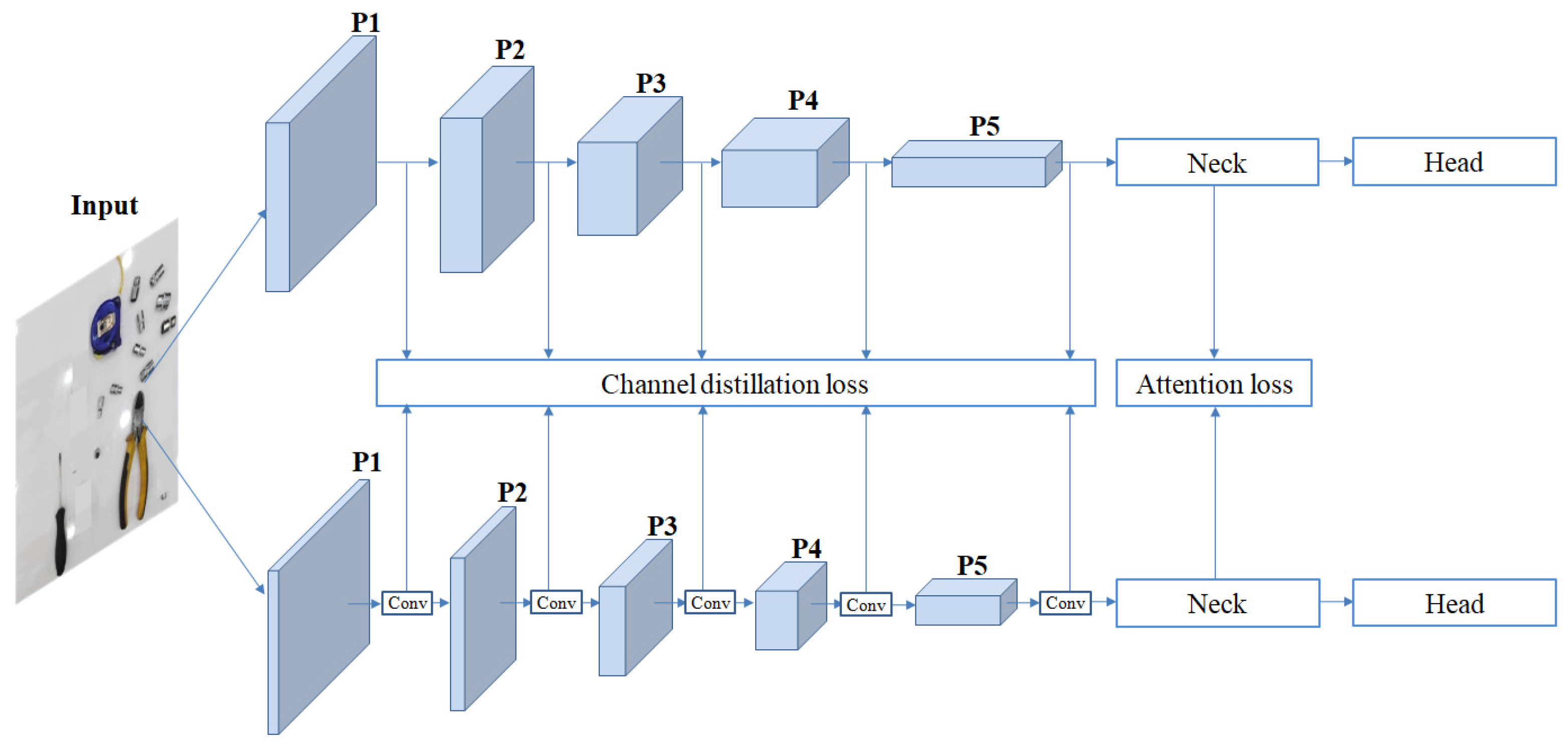
3.2. Knowledge Distillation
In the engineering application of deep neural network models, there are often high demands for computational real-time performance, resource efficiency, and detection accuracy. To deploy the detection model under limited computational resources while ensuring detection precision, we adopted knowledge distillation as the initial step in model lightweighting. We designed feature attention distillation and channel distillation loss for model training, leveraging a pre-trained teacher network to guide the knowledge distillation process. The distillation workflow is shown in
Figure 5.
We utilized the previously introduced YOLOv8l-SAM model as a high-performance teacher network and YOLOv8m-SAM as the student network for distillation. The teacher model was pre-trained on the dataset to learn more generalized feature representations. Subsequently, the teacher network’s feature distributions on the target dataset were used as soft targets to guide the learning of the student network. Through this strategy, the student network inherits the knowledge acquired by the teacher model from large-scale datasets. To maximize the integration of the teacher network’s output features into the student model, we employed feature attention distillation and channel distillation techniques for model training. The pre-trained teacher network was leveraged to provide soft targets and attention guidance throughout the knowledge distillation process. During knowledge distillation, we proposed an attention distillation method based on the self-attention distribution matrix
in the SAM structure, which serves as the attention distillation loss function. This loss function effectively guides the feature representation capability of the student network by focusing on critical feature regions in the spatial dimension. The attention distillation loss function is defined as follows:
where N represents the number of samples, and
and
denote the attention matrices of the teacher and student models, respectively.
represents the squared Euclidean distance (L2 norm).
To further enhance the effectiveness of knowledge transfer, we designed a channel distillation loss to ensure that the student network’s feature representations remain we llaligned with those of the teacher network. This alignment facilitates the effective transfer of the teacher network’s rich feature representation capabilities, leading to a significant improvement in the student network’s performance in detection tasks. Due to the structural differences between the teacher and student networks, particularly the varying number of channels in their corresponding feature outputs, the loss cannot be directly computed. We incorporated a 1 × 1 convolutional layer into the student model, allowing it to adapt its output channel dimensions to match those of the teacher model. This adjustment ensures proper alignment and enables more effective knowledge distillation, ultimately enhancing both the accuracy and efficiency of the student network. The channel distillation loss function is defined as follows:
where
and
represent the feature values at the
i-th spatial location and
c-th channel of the teacher and student models, respectively.
denotes the output channel number of the teacher network.
3.3. Dynamic Sparsity Training and Pruning
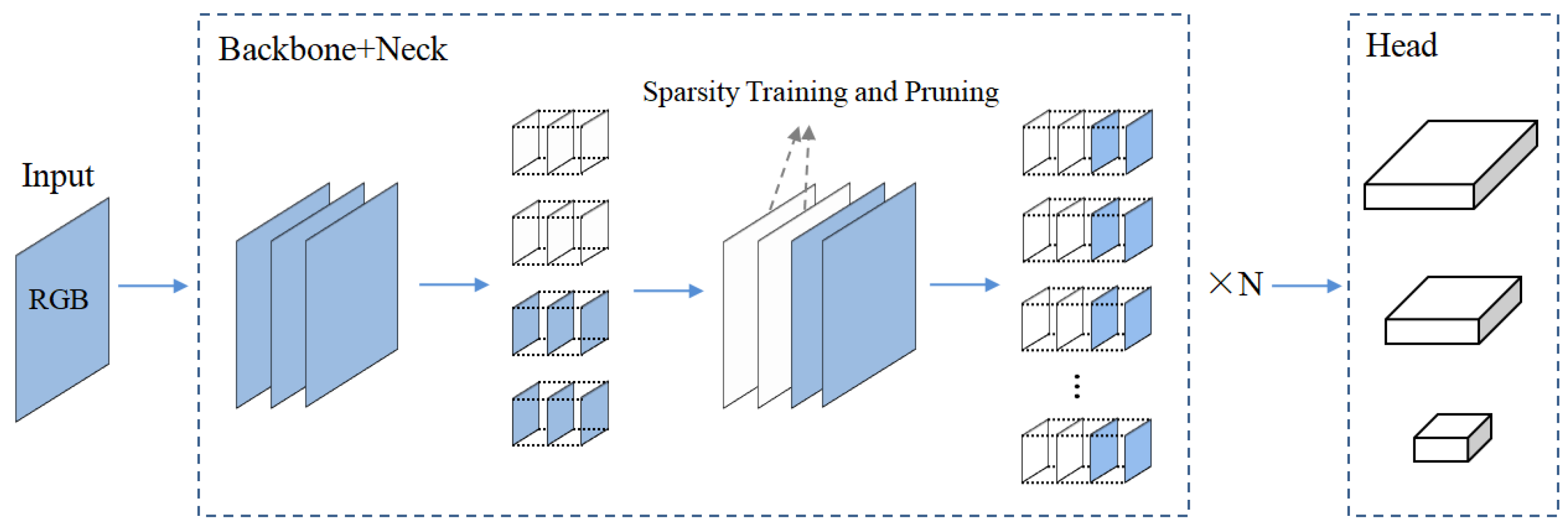
To further meet the lightweight and efficient detection requirements of industrial scenarios, we proposed a novel regularization technique, Dynamic Sparsity Regularization (DSR), which is designed to compress the model and adapt it to industrial needs. Building on the trained student network, DSR dynamically selects the least activated channels based on their L1 norms and applies L2 penalization to enhance feature sparsity. The sparsified channels are then pruned, as shown in
Figure 6. This process results in a model that is more compact and efficient, while still retaining the required performance for practical applications.
In the dynamic sparsity training process, we applied the regularization technique to the Backbone and Neck of the network, where we identified the least activated feature channels based on their L1 norms. Once the channels have been selected, the corresponding L2 norms of these features are calculated and added as a regularization term to the training loss function. This sparsity regularization encourages the network to focus on the most important features, effectively reducing unnecessary computations and enabling a more efficient model. The sparsity regularization term is defined as follows:
where
represents the selected feature maps in the
i-th layer that are subjected to sparsity regularization, and
denotes the weight for each regularization term associated with each layer in the network. This term is added to the overall training loss to ensure that the model is both accurate and efficient, enabling better adaptation to industrial constraints.
After applying sparsity regularization, a one-time structural pruning process is required to remove the weight channels associated with the pruned feature channels. Specifically, the output channels of the preceding layer and the input channels of the subsequent layer corresponding to the pruned feature channels must be eliminated. This structural pruning reduces network complexity, resulting in a more compact and computationally efficient model while preserving its effectiveness.
3.4. RAG-Based LLM
Retrieval-augmented generation (RAG) is an emerging natural language processing method that combines the strengths of information retrieval and generative models [
37]. Traditional large language models (LLMs) typically rely on knowledge acquired during pre-training to address specific issues, which can lead to hallucination. Moreover, this knowledge is static and may not be updated in real time, limiting the model’s effectiveness in adapting to the continuously evolving data in intelligent systems.
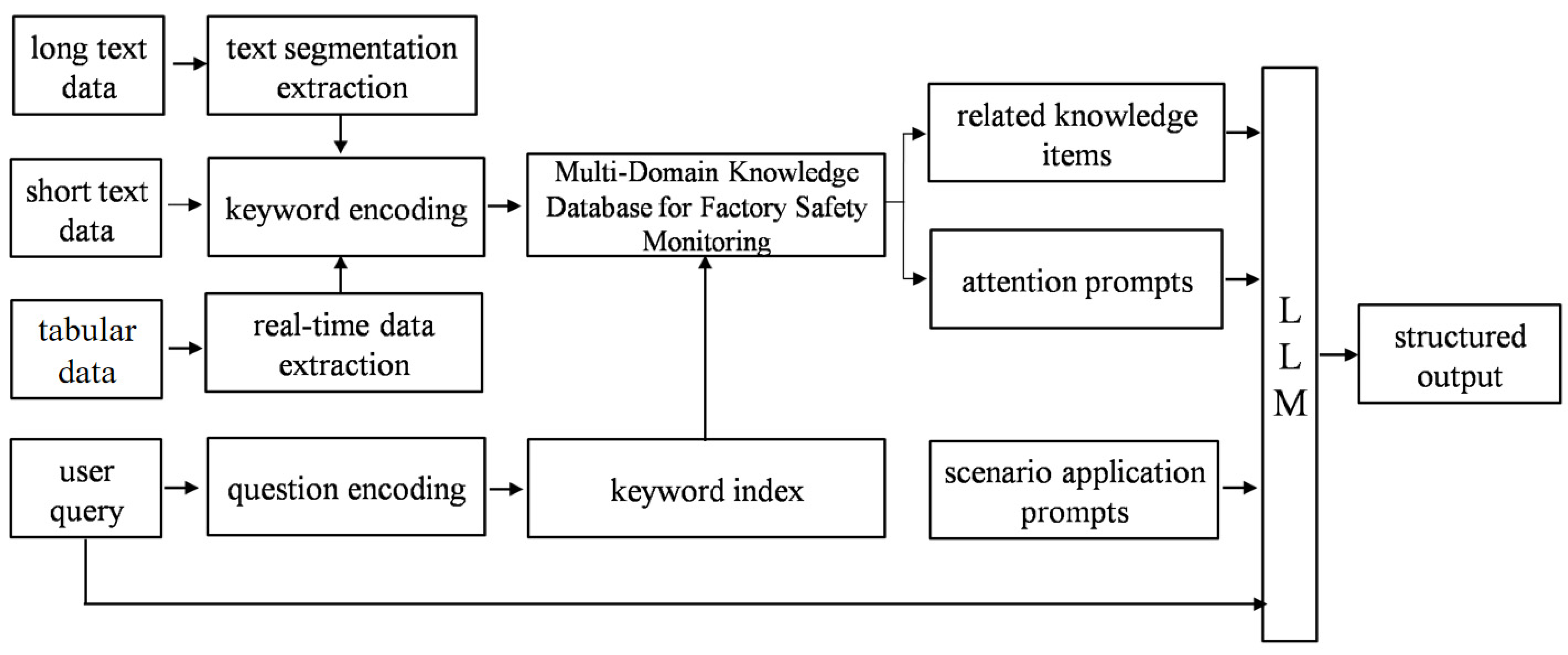
We introduced a real-time retrieval method for dynamically updated data, enhanced by similarity-based relevance, as illustrated in
Figure 7. During the retrieval enhancement phase, this method can extract and store data in realtime from relevant business platforms and both long and short texts. It indexes and ranks related knowledge fragments based on their similarity, generating corresponding attention-guided prompts according to similarity scores. These prompts guide the large models to optimize their results. This process facilitates the real-time acquisition of dynamically updated data, ensuring that the most relevant information is prioritized and returned to users, thereby improving the efficiency and accuracy of the retrieval.
Real-time monitoring data are obtained from professional tool detection results. A pre-trained text embedding model is used to convert the natural language text in the knowledge base into vector representations, which are then stored in a vector database. The vector representations are normalized to have unit length, and the processed data are inserted into the specified collection of the vector database. The normalization method for the vectors is as follows:
where
is the original vector.
is the L2 norm of vector
. For a given vector
, its L2 norm is calculated as follows:
. Therefore, each component of the normalized vector
is calculated as follows:
Using a pre-trained text embedding model, user queries in natural language are converted into vector representations, specifically utilizing the general text embedding (GTE) model. Subsequently, vector retrieval techniques are employed to retrieve the knowledge entries from the vector knowledge database that are most similar to the query vector. The vector retrieval algorithm employs approximate nearest neighbor search, using the inner product as a similarity measure to find the knowledge entries most similar to the query vector. The approach for approximate nearest neighbor search is as follows:
where
is the query vector, and
is the similarity calculated between the query vector
and each vector
in the collection, using the inner product. From the
n vectors in the collection, the
k vectors most similar to the query vector
are selected, resulting in the set of the
k vectors with the highest similarity
. By utilizing the retrieved knowledge entries as contextual information, the enhanced natural language output is generated by combining the Transformer-based large language model architecture with the retrieved highly relevant knowledge entries. Special characters in the output natural language, such as quotes, parentheses, slashes, and delimiters, are displayed or processed in a specific format to form structured natural language text, ensuring the accuracy and tidiness of the content.
4. Experiments
In this section, we evaluate the effectiveness of the proposed methods through a series of experiments conducted on various benchmark datasets. The experimental settings, configurations, and dataset details are provided in
Section 4.1. In
Section 4.2, we compare the proposed lightweight model with other state-of-the-art algorithms and present visualization results of the detection performance. Additionally, we present the effectiveness of the proposed large model in information extraction tasks. In
Section 4.3, we conduct ablation studies to systematically analyze the impact of the self-attention mechanism (SAM) module and different knowledge distillation strategies on model performance.
4.1. Experimental Details
Experiments were conducted on two datasets, i.e., the COCO dataset [
44] and the aircraft boarding tool dataset, to evaluate the performance of the proposed methods. The COCO 2017 dataset (Common Objects in Context) is a large-scale open-source computer vision dataset. It consists of over 200,000 labeled images with over 80 category labels. COCO 2017 is known for its complex real-world scenes, high-quality annotations, and support for multiple vision tasks, making it a key benchmark for evaluating deep learning models. The COCO dataset, used for both training and evaluation, contains approximately 118,000 training images, 5000 validation images, and 20,000 test images, with detailed annotations for object detection tasks. Some representative sample images from the dataset are shown in
Figure 8. To enhance the management of aircraft boarding tools, we constructed the ABT dataset, which includes 22 types of specialized tools used in various professional boarding operations. The ABT dataset consists of 1232 images, collected from real-world scenarios featuring specialized tools used for aircraft maintenance and servicing. The data collection process was conducted using industrial cameras, which were installed in designated tool operation recording areas. The camera angles and positions were fixed to maintain consistency, and lighting compensation devices were deployed to ensure stable and adequate illumination. This setup guarantees high-quality image capture, providing a reliable dataset for research and management of aircraft boarding tools. Regarding training details, the YOLOv8 training process employs an initial learning rate of 0.01 with a final decay factor of 0.01. It supports multiple optimizers, including SGD and Adam, with the momentum set to 0.937 and a weight decay of 0.0005. A warmup strategy is applied for 3 epochs to stabilize training, using a warmup momentum of 0.8. Early stopping is enabled with a patience of 100 epochs, ensuring efficient and stable convergence. The experiments were implemented using the PyTorch v2.3.0 framework. For performance evaluation, we report accuracy and resource cost metrics. The hardware utilized included an Intel (R) Xeon (R) Silver 4110 CPU at 2.10 GHz with 64 GB of memory, and the GPU was the NVIDIA GeForce RTX 3090. In addition, deployment on edge devices was tested using the NVIDIA Jetson Xavier NX to verify the framework’s applicability under resource-constrained conditions.
4.2. Performance Evaluation
To obtain the pre-trained teacher model, YOLOv8l-SAM, we froze the YOLOv8 Backbone Network pre-trained on COCO and fine-tuned the Neck and Head components, which include the SAM, to ensure that the loss function converged to an acceptable level. For distilling the student model, YOLOv8m-SAM, we initialized the network weights using the pre-trained YOLOv8m model on the COCO dataset. The lightweight model, obtained through self-attention, distillation, and pruning, is referred to as the YO-SAM-P model. For the COCO dataset, we report mAP@50-95, which represents the mean average precision (mAP) calculated across multiple IoU thresholds, ranging from 0.5 to 0.95. Additionally, we present the number of parameters and FLOPs as metrics for measuring the model’s size, which directly reflects its complexity and computational cost.
We evaluated the effectiveness of our proposed YO-SAM-P method by comparing its performance with other state-of-the-art (SOTA) algorithms. In industrial applications, model size and computational complexity are critical factors. Here, we provide a detailed report on the model’s parameter count and FLOPs to assess its efficiency. As shown in
Table 1, our model outperforms the strong baseline YOLOv8m in terms of mAP@50-95 metrics. Specifically, YO-SAM-P achieves an mAP@50-95 of 51.0%, which is higher than the mAP@50-95 of 50.2%achieved by YOLOv8m. This indicates that the incorporation of the self-attention mechanism, distillation, and pruning techniques results in improved feature extraction and model performance, without significant increase in model size or computational cost. In terms of computational complexity, YO-SAM-P achieves a 24.1 million parameter count and 73.7 billion FLOPs, which are lower than YOLOv8m’s 25.9 million parameters and 78.9 billion FLOPs. This shows that YO-SAM-P not only outperforms YOLOv8m in terms of accuracy but also maintains a smaller model size and reduces computational cost, which is critical for deployment in resource-constrained industrial environments. Moreover, a detailed analysis of the comparison with other models (e.g., YOLOv5, DESTR-DC5-R101) further highlights the advantages of our method. For instance, although YOLOv5l has a slightly higher mAP@50-95 (49.0%), its 109.1 billion FLOPs and 46.5 million parameters make it significantly less efficient compared to our YO-SAM-P model, which achieves a better balance between accuracy and computational efficiency. Similarly, while the DESTR-DC5-R101 model achieves a higher mAP of 46.4, its 299.0 billion FLOPs and 88.0 million parameters make it unsuitable for real-time applications, especially in industrial environments with limited processing resources. These results demonstrate that our YO-SAM-P method not only achieves better performance than other state-of-the-art models but also optimizes the trade-off between detection accuracy and computational efficiency, making it an ideal solution for real-time, resource-constrained industrial applications.
For the safety helmet dataset, we conducted experiments to evaluate the effectiveness of our proposed method. The dataset contains 11,000 images with an original resolution of 1920 × 1080, and includes bounding box annotations in the PASCAL VOC [
47] format for three classes: Helmet, Person, and Head. Overall, 80% of the dataset was allocated to the training–validation set, while the remaining 20% was used as the test set to evaluate the model’s performance. The number of instances for each class in the safety helmet dataset is as follows: Helmet: 9600; Person: 23,800; and Head: 14,200. We tested the YO-SAM-P model, optimized using self-attention, distillation, and pruning, and assessed its performance using mAP@50, as well as the model latency. The results, presented in
Table 2, show that our method exceeds the performance of other common industrial vision models, achieving higher accuracy with a smaller model size and reduced computational cost. These findings demonstrate that our approach strikes a balance between detection performance and efficiency, making it suitable for deployment in real-time, resource-constrained industrial environments.
For the aircraft boarding tool (ABT) dataset, we aimed to obtain a high-performing pre-trained teacher model, namely, YOLOv8l-SAM-seg. Specifically, the model was initialized using the Backbone weights of YOLOv8l-seg, pre-trained on the COCO dataset. We then conducted end-to-end training on the ABT dataset to adapt the model to the specific characteristics of this domain. Furthermore, through a combination of knowledge distillation and pruning, we derived a more compact and efficient version of the model, referred to as YO-SAM-P-seg. We compared our proposed method with other models such as YOLOv8-Seg and Mask R-CNN on the aircraft boarding tool (ABT) dataset. The comparative experiments were conducted to evaluate the performance of our approach in comparison to these well-established models. The results of the experiments, which show the strengths and weaknesses of each model, are presented in
Table 3. Frames Per Second (FPS) is a widely used metric in real-time computer vision applications and helps assess the practical deployment capability of detection models in industrial environments. This comparison highlights the performance of our method in terms of both accuracy and efficiency on the ABT dataset.
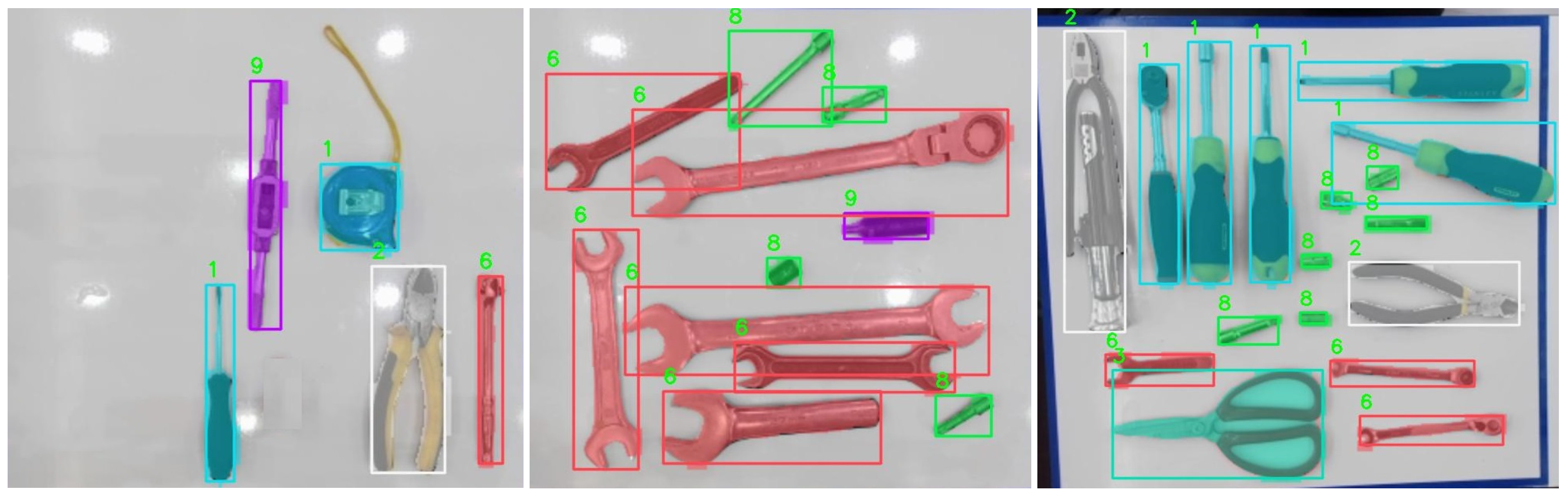
Our model overall outperformed other models using the ABT dataset. We incorporated a self-attention mechanism (SAM) for multi-scale feature fusion, which significantly enhanced the model’s ability to detect object features more accurately. This improvement was further observed through the following ablation study. Our approach also maintained a high level of inference speed, while achieving accuracy comparable to the teacher model, demonstrating its lightweight design and high performance. The detection results of our model on the ABT dataset are shown in
Figure 9.
4.3. Ablation Studies
To evaluate the performance improvements contributed by each module, we conducted ablation experiments on the ABT dataset. These experiments primarily analyzed the contributions of the self-attention mechanism (SAM), knowledge distillation, and pruning techniques. The ablation results for the SAM are shown in
Table 4. Using the YOLOv8l-seg network as the baseline, we compared the performance with and without the SAM. As seen in
Table 4, incorporating the SAM enhanced the model’s ability to represent object features, leading to improved recognition accuracy. The SAM showed its effectiveness in helping the model focus on important features in the image, which played a key role in improving its accuracy. By adding the SAM, the model became better at detecting objects, especially in situations where distinguishing fine details is important. These results suggest that the SAMhelps the model better represent features and overall improves its performance, making it an important part of our approach.
As previously mentioned, we obtained a pre-trained teacher model, namely, YOLOv8l-SAM-seg, on the ABT dataset. We applied attention distillation and channel distillation during the model training process. To verify the effectiveness of the knowledge distillation strategy, we designed an ablation experiment focusing on the distillation methods. In this experiment, we compared the performance contributions of attention distillation and channel distillation on the ABT dataset. Additionally, we also reported the pruning performance in this experiment. The experimental results are presented in
Table 5.
4.4. Proposed RAG in Practice
The detection results for boarding tools need to be organized and summarized for submission to the management, which presents a significant challenge for extracting target information from complex datasets. To support intelligent interaction and data-driven decision-making, our framework incorporates large language models (LLMs) at multiple stages. Specifically, we utilize the Qwen2.5-32B pre-trained model to generate executable SQL queries based on natural language prompts. This component enables the transformation of user intent into structured queries, allowing seamless access to detection results stored in relational databases. Qwen2.5 was selected for its strong performance in instruction-following and structured data comprehension tasks, which aligns with the requirements of industrial tool management systems. Furthermore, we employ the DeepSeek-32B pre-trained model in the final reasoning stage. This module is responsible for synthesizing the user query, detection results, and relevant knowledge entries retrieved from multiple sources (including structured databases and document corpora). It supports complex question answering and knowledge grounding, making it wellsuited for providing domain-specific intelligent recommendations in high-end manufacturing scenarios. Both models are based on publicly available pre-trained weights and are integrated via an agent-based mechanism. This modular design allows the system to interpret user queries, generate SQL, retrieve data, and synthesize responses in a stepwise and semantically consistent manner.
In our retrieval-augmented generation (RAG) system, we adopt a dense retrieval approach powered by the Milvus vector database. Textual knowledge entries—sourced from multi-source enterprise knowledge such as process documents and technical manuals—are embedded using GTE-large-zh, a general-purpose Chinese sentence embedding model trained through multi-stage contrastive learning. This model produces 1024-dimensional vectors with a maximum sequence length of 512 tokens. The generated vectors are normalized to unit vectors and indexed in Milvus using the IVF_PQ algorithm with inner product (IP) as the similarity metric. This setup ensures efficient large-scale approximate nearest neighbor (ANN) search and provides high recall retrieval capabilities, forming a solid foundation for subsequent language model generation. We use Precision@k and Recall@k as the primary evaluation metrics. Precision@k reflects the proportion of relevant documents among the top-k retrieved results, indicating the accuracy of the retrieval. Recall@k represents the proportion of relevant documents in the knowledge base that are successfully retrieved within the top-k, reflecting the coverage of the retrieval process. We conducted experiments using a domain-specific corpus from our enterprise knowledge base and report the retrieval performance at different values of k (number of retrieved passages). The results are summarized in
Table 6. The results show that Recall increases with the number of retrieved passages, indicating broader retrieval coverage. Conversely, Precision tends to decrease with higher k, as more irrelevant documents may be included. This reflects the typical trade-off between precision and recall in dense retrieval, and highlights the importance of choosing an appropriate k value to balance retrieval quality and downstream generation performance. These findings support the reliability of dense retrieval in enterprise-level question-answering tasks and provide a solid foundation for downstream integration with large language models.
The intelligent question-answering system based on the proposed RAG large language model can extract detailed data from the tool detection system in real time, including time, location, and relevant tool information. By efficiently integrating these data, the system provides management with fast and accurate judgment criteria and decision support, as shown in
Figure 10. The in-depth analysis and processing of these data enable managers to monitor and identify potential risks associated with boarding tools in realtime, allowing them to take timely preventive measures. This intelligent system not only significantly enhances the efficiency of safety management but also reduces the occurrence of excess tools on board, effectively ensuring the safe operation of the work environment.
To better understand the role of the RAG-based large language model component in our system, we conducted a comparative analysis by examining the system’s behavior with and without this module. When the RAG module—which includes Qwen2.5 for generating SQL queries from natural language prompts and DeepSeek-32B for reasoning over multi-source data—is removed, the system loses its ability to interpret user intent, access structured data on demand, and provide coherent, domain-specific responses. This significantly limits user interaction and weakens the system’s ability to support intelligent decision-making. Through this comparison, we observed noticeable declines in both response accuracy and system usability, demonstrating the essential contribution of the RAG-based component in enabling real-time, interactive, and explainable query-answering capabilities in complex industrial environments.
5. Conclusions and Future Work
In this study, we introduced a novel approach to enhance feature representation in networks by incorporating a self-attention mechanism (SAM) for multi-scale feature fusion. The SAM significantly improves the extraction of object-related information from the feature space of the target dataset. We also proposed a compression method that combines knowledge distillation with pruning techniques, resulting in a compact and efficient model. This optimized network is specifically designed to meet deployment constraints while maintaining high performance on the target dataset. Furthermore, we integrated a large language model (LLM), enhanced by retrieval-augmented generation (RAG), to analyze tool detection results. This enables the system to rapidly provide relevant information to management personnel, facilitating intelligent monitoring and decision-making processes.
In future research, we aim to further refine our model compression techniques to enhance the efficiency and performance of target recognition systems. Additionally, we plan to integrate more domain-specific knowledge into the LLM-enhanced system, incorporating relevant documents and real-time data, to offer streamlined and intelligent guidance services for operational management.
Author Contributions
Conceptualization, A.Z. and W.W.; methodology, A.Z.; software, W.W.; validation, W.W. and Z.G.; formal analysis, A.Z. and J.Y.; investigation, A.Z., W.W. and L.Z.; resources, A.Z.; data curation, W.W.; writing—original draft preparation, A.Z. and W.W.; writing—review and editing, J.Y. and L.Z.; visualization, A.Z. and W.W.; supervision, J.Y. and L.Z.; project administration, A.Z. and J.Y.; funding acquisition, A.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Acknowledgments
We sincerely thank the anonymous reviewers for their critical comments and suggestions for improving the manuscript.
Conflicts of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest. Authors Anan Zhao, Jia Yin, Wei Wang and Zhonghua Guo were employed by the company Avic Xi’an Aircraft Industry Group Company Ltd.
References
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: New York, NY, USA, 2009; pp. 248–255. [Google Scholar]
- Su, J.; Fraser, N.J.; Gambardella, G.; Blott, M.; Durelli, G.; Thomas, D.B.; Leong, P.; Cheung, P.Y.K. Accuracy to throughput trade-offs for reduced precision neural networks on reconfigurable logic. In Applied Reconfigurable Computing. Architectures, Tools, and Applications; Voros, N., Huebner, M., Keramidas, G., Goehringer, D., Antonopoulos, C., Diniz, P.C., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 29–42. [Google Scholar]
- Gou, J.; Yu, B.; Maybank, S.J.; Tao, D. Knowledge distillation: A survey. Int. J. Comput. Vis. 2021, 129, 1789–1819. [Google Scholar] [CrossRef]
- Liu, S.; Shen, H.; Law, E.K.L.; Lam, C.-T. Mutual Knowledge Distillation-Based Communication Optimization Method for Cross-Organizational Federated Learning. Electronics 2025, 14, 1784. [Google Scholar] [CrossRef]
- Chen, D.; Mei, J.P.; Zhang, H.; Wang, C.; Feng, Y.; Chen, C. Knowledge distillation with the reused teacher classifier. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11933–11942. [Google Scholar]
- LeCun, Y.; Denker, J.S.; Solla, S.A. Optimal brain damage. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 1989; pp. 598–605. [Google Scholar]
- Diao, H.; Li, G.; Xu, S.; Kong, C.; Wang, W.; Liu, S.; He, Y. Self-distillation enhanced adaptive pruning of convolutional neural networks. Pattern Recognit. 2025, 157, 110942. [Google Scholar] [CrossRef]
- Li, H.; Kadav, A.; Durdanovic, I.; Samet, H.; Graf, H.P. Pruning flters for efcient convnets. In Proceedings of the International Conference on Learning Representations ICLR, Toulon, France, 24–26 April 2017. [Google Scholar]
- Pinto, V.; Severo, V.; Madeiro, F. Optimizing Multi-View CNN for CAD Mechanical Model Classification: An Evaluation of Pruning and Quantization Techniques. Electronics 2025, 14, 1013. [Google Scholar] [CrossRef]
- Wang, W.; Zhu, L.; Guo, B. Reliable identification of redundant kernels for convolutional neural network compression. J. Vis. Commun. Image Represent. 2019, 63, 102582. [Google Scholar] [CrossRef]
- Wang, W.; Zhu, L. Structured feature sparsity training for convolutional neural network compression. J. Vis. Commun. Image Represent. 2020, 71, 102867. [Google Scholar] [CrossRef]
- Chen, J.; Chen, S.; Pan, S.J. Storage efficient and dynamic flexible runtime channel pruning via deep reinforcement learning. Adv. Neural Inf. Process. Syst. 2020, 33, 14747–14758. [Google Scholar]
- Lindeberg, T. Scale invariant feature transform. In Scholarpedia; Scholarpedia Corporation: San Diego, CA, USA, 2012; Volume 7, p. 10491. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), Washington, DC, USA, 20–25 June 2005; IEEE: New York, NY, USA, 2005; Volume 1, pp. 886–893. [Google Scholar]
- Maćkiewicz, A.; Ratajczak, W. Principal components analysis (PCA). Comput. Geosci. 1993, 19, 303–342. [Google Scholar] [CrossRef]
- Hearst, M.A.; Dumais, S.T.; Osuna, E.; Platt, J.; Scholkopf, B. Support vector machines. IEEE Intell. Syst. Their Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, CL, USA, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Computer Vision–ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14; Springer Cham: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Jocher, G.; Stoken, A.; Borovec, J.; Liu, C.; Hogan, A.; Diaconu, L.; Ingham, F.; Poznanski, J.; Fang, J.; Yu, L.; et al. Ultralytics/Yolov5, version 3.0; Zenodo: Brussel, Belgium, 2020.
- Terven, J.; Córdova-Esparza, D.M.; Romero-González, J.A. A comprehensive review of yolo architectures in computer vision: From yolov1 to yolov8 and yolo-nas. Mach. Learn. Knowl. Extr. 2023, 5, 1680–1716. [Google Scholar] [CrossRef]
- Hinton, G.E.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Tung, F.; Mori, G. Similarity-Preserving Knowledge Distillation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1365–1374. [Google Scholar]
- Wang, W.; Zhang, Y.; Zhu, L. DRF-DRC: Dynamic receptive field and dense residual connections for model compression. Cogn. Neurodynamics 2023, 17, 1561–1573. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17), Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA; pp. 6000–6010. [Google Scholar]
- Yadav, S. AeroQuery RAG and LLM for Aerospace Query in Designs, Development, Standards, Certifications. In Proceedings of the 2024 IEEE International Conference on Electronics, Computing and Communication Technologies (CONECCT), Bangalore, India, 12–14 July 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Ng, K.K.Y.; Matsuba, I.; Zhang, P.C. RAG in health care: A novel framework for improving communication and decision-making by addressing LLM limitations. NEJM AI 2025, 2, AIra2400380. [Google Scholar] [CrossRef]
- Ahmed, B.S.; Baader, L.O.; Bayram, F.; Jagstedt, S.; Magnusson, P. Quality Assurance for LLM-RAG Systems: Empirical Insights from Tourism Application Testing. arXiv 2025, arXiv:2502.05782. [Google Scholar]
- Wang, Z.; Liu, Z.; Lu, W.; Jia, L. Improving knowledge management in building engineering with hybrid retrieval-augmented generation framework. J. Build. Eng. 2025, 103, 112189. [Google Scholar] [CrossRef]
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. Training language models to follow instructions with human feedback. Adv. Neural Inf. Process. Syst. 2022, 35, 27730–27744. [Google Scholar]
- Rafailov, R.; Sharma, A.; Mitchell, E.; Ermon, S.; Manning, C.D.; Finn, C. Direct preference optimization: Your language model is secretly a reward model. arXiv 2023, arXiv:2305.18290. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.-A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. LLaMA: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Hoffmann, J.; Borgeaud, S.; Mensch, A.; Buchatskaya, E.; Cai, T.; Rutherford, E.; Hendricks, L.A.; Welbl, J.; Clark, A.; Hennigan, T.; et al. Training compute-optimal large language models. arXiv 2022, arXiv:2203.15556. [Google Scholar]
- Guo, Z.; Cheng, S.; Wang, Y.; Li, P.; Liu, Y. Prompt-guided retrieval augmentation for non-knowledge-intensive tasks. In Proceedings of the Findings of the Association for Computational Linguistics: EACL2023, Dubrovnik, Croatia, 2–6 May 2023; pp. 10896–10912. [Google Scholar]
- Wang, Y.; Li, P.; Sun, M.; Liu, Y. Self-knowledge guided retrieval augmentation for large language models. arXiv 2023, arXiv:2310.05002. [Google Scholar]
- Liu, L.; Meng, J.; Yang, Y. LLM technologies and information search. J. Econ. Technol. 2024, 2, 269–277. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft coco: Common objects in context. In Computer Vision—ECCV 2014, Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part v 13; Springer Cham: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- He, L.; Todorovic, S. DESTR: Object detection with split transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 9377–9386. [Google Scholar]
- Khow, Z.J.; Tan, Y.F.; Karim, H.A.; Rashid, H.A.A. Improved YOLOv8 Model for a comprehensive approach to object detection and distance estimation. IEEE Access 2024, 12, 63754–63767. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Zhou, C. Yolact++ better real-time instance segmentation. University of California, Davis, 2020. arXiv 2019, arXiv:1912.06218. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies setsnew state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
Figure 1.
Sample images fromthe aircraft boarding tool (ABT) dataset.
Figure 1.
Sample images fromthe aircraft boarding tool (ABT) dataset.
Figure 2.
End-to-end framework combining edge vision models and generative LLMs. The symbol * in the SQL query indicates that all columns from the table are selected.
Figure 2.
End-to-end framework combining edge vision models and generative LLMs. The symbol * in the SQL query indicates that all columns from the table are selected.
Figure 3.
The self-attention mechanism. This mechanism processes the input features through channel-wise operations, followed by the computation of attention weights, enabling the model to focus on the most relevant spatial information while suppressing less important details.
Figure 3.
The self-attention mechanism. This mechanism processes the input features through channel-wise operations, followed by the computation of attention weights, enabling the model to focus on the most relevant spatial information while suppressing less important details.
Figure 4.
An illustration of the integration of the self-attention mechanism (SAM) in the Neck section of the network. The module is applied after the concatenation of multi-scale features, enhancing spatial correlation and improving feature extraction. This design enables the network to capture fine-grained details, leading to better robustness and adaptability in complex environments.
Figure 4.
An illustration of the integration of the self-attention mechanism (SAM) in the Neck section of the network. The module is applied after the concatenation of multi-scale features, enhancing spatial correlation and improving feature extraction. This design enables the network to capture fine-grained details, leading to better robustness and adaptability in complex environments.
Figure 5.
The knowledge distillation workflow. The diagram shows the workflow of the knowledge distillation process, where a pre-trained teacher network guides the student network through feature attention and channel distillation techniques, optimizing model performance while maintaining efficiency.
Figure 5.
The knowledge distillation workflow. The diagram shows the workflow of the knowledge distillation process, where a pre-trained teacher network guides the student network through feature attention and channel distillation techniques, optimizing model performance while maintaining efficiency.
Figure 6.
An illustration of the sparsity and pruning process. This figure depicts the procedure of applying sparsity regularization followed by structural pruning to achieve a more compact and efficient model.
Figure 6.
An illustration of the sparsity and pruning process. This figure depicts the procedure of applying sparsity regularization followed by structural pruning to achieve a more compact and efficient model.
Figure 7.
The working principle of automated fiber placement (AFP).
Figure 7.
The working principle of automated fiber placement (AFP).
Figure 8.
Sample images from the COCO dataset.
Figure 8.
Sample images from the COCO dataset.
Figure 9.
The instance segmentation results of the model on the ABT dataset.
Figure 9.
The instance segmentation results of the model on the ABT dataset.
Figure 10.
Real-time professional tool detection Q&A system based on RAG-LLM.
Figure 10.
Real-time professional tool detection Q&A system based on RAG-LLM.
Table 1.
The results obtained with the COCO dataset comparing our proposed method with other algorithms. Bold font is used to denote relatively better performance values.
Table 1.
The results obtained with the COCO dataset comparing our proposed method with other algorithms. Bold font is used to denote relatively better performance values.
| Methods | Size | AP@0.5:0.95 | Params (M) | FLOPs(B) |
|---|
| YOLOv5l | 640 | 49.0% | 46.5 | 109.1 |
| YOLOv5m | 640 | 45.4% | 21.2 | 49.0 |
| DESTR-DC5-R101 [45] | - | 46.4% | 88.0 | 299.0 |
| YOLOv8-CAW [46] | 640 | 47.2% | 26.1 | - |
| YOLOv8m | 640 | 50.2% | 25.9 | 78.9 |
| YO-SAM-P | 640 | 51.0% | 24.1 | 73.7 |
Table 2.
The performance evaluation on the safety helmet dataset comparing our proposed model with other algorithms. Bold font is used to denote relatively better performance values.
Table 2.
The performance evaluation on the safety helmet dataset comparing our proposed model with other algorithms. Bold font is used to denote relatively better performance values.
| Model | mAP | Latency (ms) |
|---|
| RefineDet [44] | 84.6% | 25 |
| ResNet101-CenterNet [45] | 82.1% | 23 |
| DLA34-CenterNet [45] | 84.9% | 20 |
| YOLOv5m [46] | 94.7% | 14 |
| YO-SAM-P | 96.2% | 17 |
Table 3.
The results evaluated on the ABT dataset comparing our proposed method with other algorithms. Bold font is used to denote relatively better performance values.
Table 3.
The results evaluated on the ABT dataset comparing our proposed method with other algorithms. Bold font is used to denote relatively better performance values.
| Methods | Size | | | Params (M) | FPS |
|---|
| YOLACT++ [48] | 550 | 0.873 | 0.862 | 34.1 | 33 |
| Mask R-CNN [49] | 550 | 0.916 | 0.908 | 43.9 | 20 |
| YOLOv7-seg [50] | 448 | 0.964 | 0.950 | 37.8 | 56 |
| YOLOv8m-seg | 448 | 0.931 | 0.912 | 27.3 | 90 |
| YO-SAM-P-Seg | 448 | 0.971 | 0.953 | 24.9 | 97 |
Table 4.
Results of the ablation study on the self-attention mechanism. √ indicates the application of the corresponding SAM, while × indicates its absence. Bold font is used to denote relatively better performance values.
Table 4.
Results of the ablation study on the self-attention mechanism. √ indicates the application of the corresponding SAM, while × indicates its absence. Bold font is used to denote relatively better performance values.
| Methods | SAM | | | Params (M) | FPS |
|---|
| YOLOv8l-seg | × | 0.969 | 0.958 | 46.0 | 71 |
| YOLOv8l-SAM-seg | √ | 0.976 | 0.962 | 55.8 | 65 |
Table 5.
Results of the ablation study on different distillation methods, comparing the impact of different distillation loss functions on experimental performance. √ indicates the application of the corresponding loss function, while × indicates its absence. Bold font is used to denote relatively better performance values.
Table 5.
Results of the ablation study on different distillation methods, comparing the impact of different distillation loss functions on experimental performance. √ indicates the application of the corresponding loss function, while × indicates its absence. Bold font is used to denote relatively better performance values.
| Methods | Attention | Channel | Pruning | | | Params (M) | FPS |
|---|
| YOLOv8m-SAM-seg | √ | × | × | 0.965 | 0.950 | 34.8 | 82 |
| YOLOv8m-SAM-seg | × | √ | × | 0.957 | 0.946 | 34.8 | 82 |
| YOLOv8m-SAM-seg | √ | √ | × | 0.978 | 0.959 | 34.8 | 82 |
| YO-SAM-P-Seg | √ | √ | √ | 0.971 | 0.953 | 24.9 | 97 |
Table 6.
Evaluation metrics at different retrieval sizes.
Table 6.
Evaluation metrics at different retrieval sizes.
| Retrieved Passages (k) | Recall | Precision |
|---|
| 10 | 0.308 | 0.400 |
| 20 | 0.538 | 0.350 |
| 40 | 0.846 | 0.275 |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}