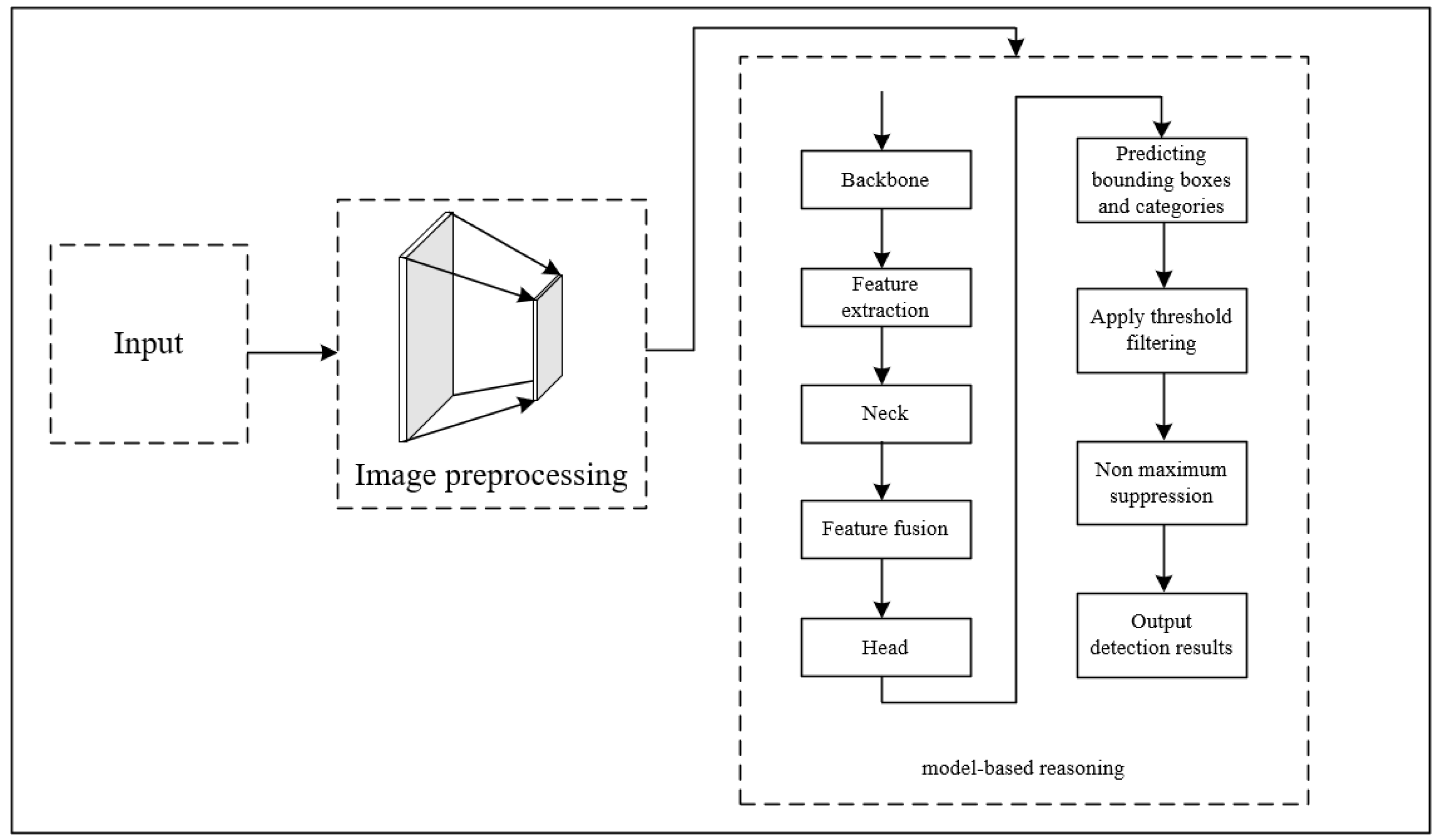
1. Introduction
Remote sensing target detection is an important foundation for the application of remote sensing technology in land use, urban planning, and natural disaster detection [
1]. The principle is to use computer vision algorithms to classify and detect targets in remote sensing images, determine their precise location, and extract their feature information [
2]. Unlike natural images, remote sensing images have characteristics such as fragmented distribution of target information, diverse and complex backgrounds, and significant differences in target scales, which further increase the difficulty of detection. Traditional detection methods, such as Histogram of Oriented Gradients (HOG) [
3] and Scale-Invariant Feature Transform (SIFT) [
4], can only recognize specific single-class objects and have limited effectiveness in certain scenarios. When the environment changes, the recognition efficiency is low.
Advances in artificial intelligence have led to the extensive application of deep learning techniques in the field of computer vision. In the domain of object detection, convolutional neural networks (CNNs) have exhibited remarkable performance, primarily attributed to their hierarchical network architectures and robust feature representation capabilities. The current CNN-based object detection algorithms are mainly divided into two types: one-stage object detection methods and two-stage object detection methods. The latter, including fast R-CNN [
5], faster R-CNN [
6], and cascade R-CNN [
7], use a regional proposal network (RPN) to generate candidate regions and classify them as background or target object regions; then, the RPN output is transported to the detection head and mapped to the appropriate position on the feature map for the final classification and regression process. The most influential one-stage object detection models are SSD [
8], RetinaNet [
9], and the YOLO series [
10,
11,
12,
13,
14,
15]; unlike the R-CNN series algorithms, these methods directly regress the position of objects on the feature map, transforming the localization problem into a regression problem.
The above methods are mainly designed for use in natural images. Detection in remotely sensed imagery, however, focuses on different aspects compared to natural image detection, owing to its distinctive top-down viewpoint and the considerable imaging distances involved. In the scenario of remote sensing imagery analysis, background information and comprehensive information often play an auxiliary role in target recognition, as they may contain clues that help distinguish targets. However, for natural scene images, these same types of information may be considered to be interference factors because they may not be directly related to the target task and may even introduce noise or confusing signals, thereby affecting the accuracy of recognition. This inherent characteristic of remote sensing data makes object detection in such scenarios more challenging than conventional detection tasks. Weiya et al. [
16] solved the problem of small-object detection in remote sensing images by introducing a cross-layer attentional fusion module and a weighted multi-acceptance domain null-space pyramid pooling module to address the issues of deep feature loss and background interference. Xu and Wu [
17] developed an efficient anchor-free remote sensing target detector based on YOLO, which allows for the high-precision detection of small targets on account of an improved CJAM and other feature extraction modules, as well as lightweight auxiliary networks and Swin Transformers. Tang et al. [
18] adopted a combined module to enhance channel information and added a new detection head to develop the HIC-YOLOv5 algorithm. Li et al. [
19] enhanced the YOLOv8 network by using the concepts of dual-channel feature fusion and BiFPN [
20] to improve small-object detection performance; they also replaced some CSP bottlenecks with two convolution (C2f) modules of the Ghostblock V2 [
21] structure to minimize feature loss during network transmission.
While the detection accuracy for small objects has seen notable improvement in recent algorithms, the marginal effect of model parameters relative to accuracy improvement is rarely considered, indicating a lack of practical consideration. Therefore, we propose a small-object detection algorithm based on the scale characteristics of small objects in high-resolution remote sensing images and drone aerial images, as well as the structural characteristics of baseline algorithms. The contributions of this study can be summarized as follows:
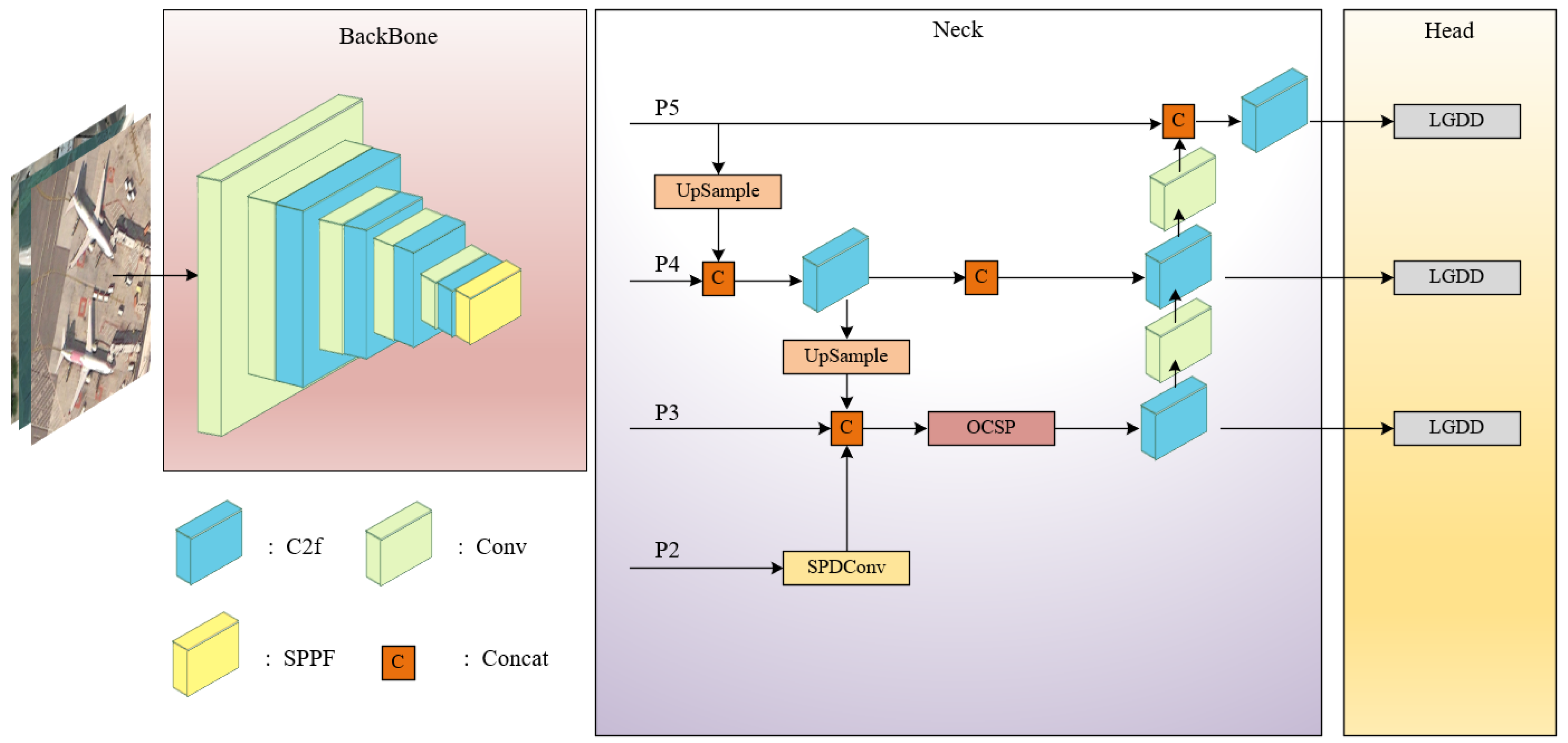
(1) A resource-efficient feature pyramid named SMP is proposed; it uses SPConv instead of the spanning convolutional layer and pooling layer, allowing the P3 layer to obtain features richer in small-target information. The module is designed to efficiently capture feature representations spanning global-to-local hierarchies, integrating contextual information with localized semantic cues with the designed Omni Cross Stage Partial (OCSP) module for feature integration, ultimately improving performance in small-target detection.
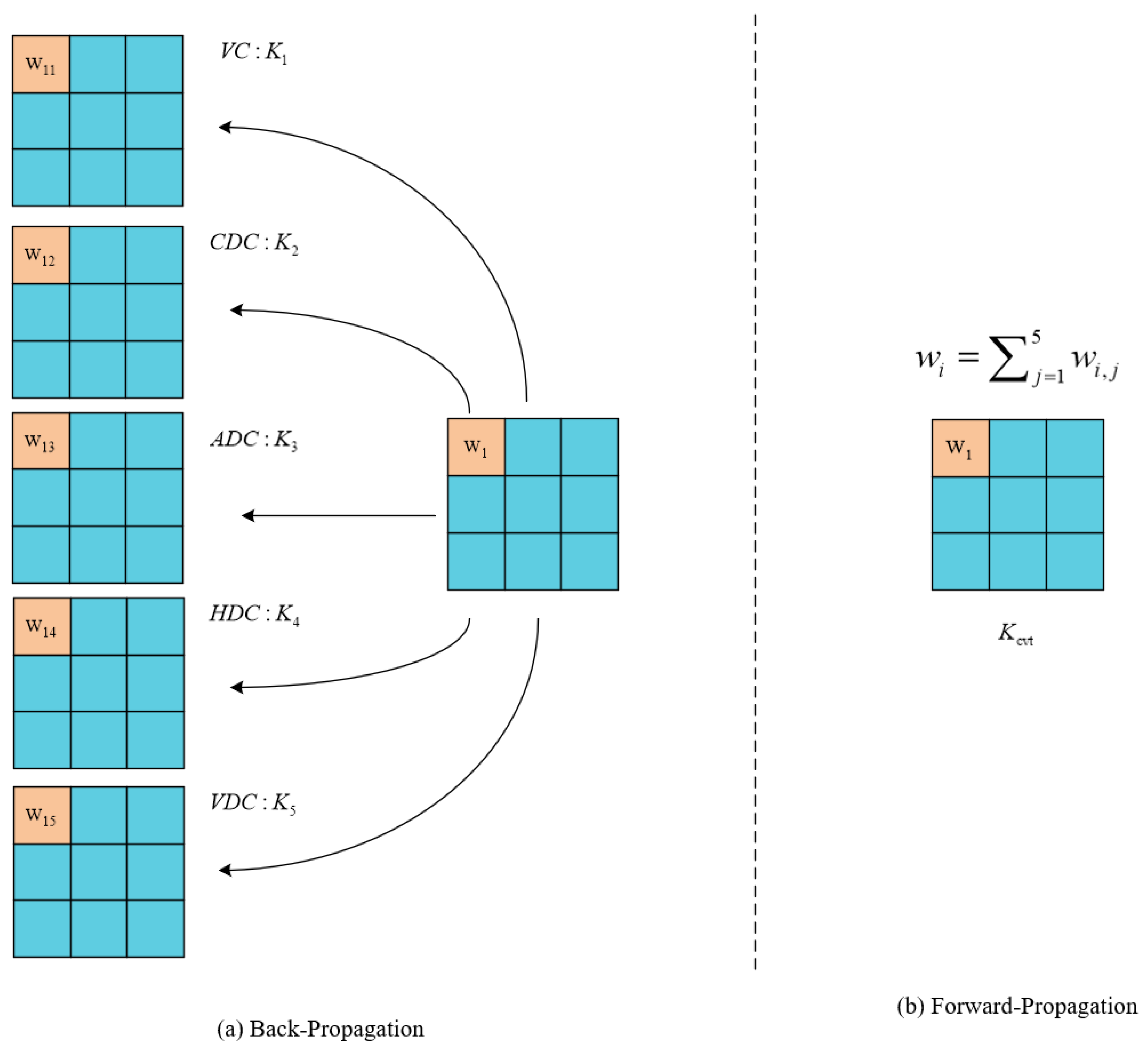
(2) We propose a lightweight detection head called LGDD (Lightweight Generalized Detection Head) that employs three key innovations for efficient object detection: First, it utilizes shared convolution to dramatically reduce parameter count. Second, it incorporates a Scale layer to normalize feature responses across different detection heads, effectively addressing scale inconsistency in target detection. Third, it introduces DEConv (Detail-Enhanced Convolution), a novel operation that enhances detail capture through two phases: (1) during training, it integrates prior knowledge into standard convolutional layers to boost representation capacity, and (2) during inference, it transforms into regular convolution via reparameterization. This dual-phase design achieves improved generalization without introducing additional parameters or computational overhead, maintaining the model’s lightweight architecture.
The rest of this article is organized as follows: In
Section 2, we provide the current state of research on the YOLOv8 algorithm and feature pyramid. In
Section 3, we introduce the CIMB-YOLO model, and in
Section 4, we present the dataset we used and the corresponding experiments and analysis. Finally, the conclusions are drawn in the
Section 5.
4. Experimental Results
4.1. Experimental Setup
We used an Intel Xeon Platinum 8352V CPU (manufactured by Intel Corporation, Santa Clara, CA, USA) and an NVIDIA GeForce RTX 3090 GPU (manufactured by NVIDIA Corporation, Santa Clara, CA, USA), with 6TB of memory. with 32 GB of video memory. The experimental operating system was Windows 11, Python 3.9.7, PyTorch 1.11.0 was selected as the deep learning framework, and CUDA 11.3 was used to accelerate inference. The experiment was conducted by using the batch training method, whereby each dataset was divided into multiple batches for experimentation, with batch sizes set to 32 or 16, depending on the size of the dataset. The learning rate of the experimental model was 0.01, the weight decay rate was 0.0005, the training configuration parameters were set to 300 epochs, the optimizer used was stochastic gradient descent (SGD), and the image input size was uniformly 640 × 640.
The dataset was partitioned into training (80%), validation (10%), and test (10%) sets following an 8:1:1 ratio. To ensure representative sampling, we conducted the following: (1) maintained balanced class distributions across all splits, (2) guaranteed sample independence through randomized index shuffling before partitioning, and (3) rigorously separated the data usage, employing the training set for model optimization, the validation set for hyperparameter tuning, and reserving the test set exclusively for final performance assessment.
4.2. Experimental Datasets
We validated the method on three datasets: DIOR [
36], DOTA [
37], and NWPU VHR-10 [
38].
DIOR: The DIOR dataset is a large-scale benchmark dataset proposed by Northwestern Polytechnical University for object detection in optical remote sensing images. It contains 23,463 remote sensing images and 190,288 instances, divided into 20 categories.
DOTA: The DOTA dataset is an aerial image dataset jointly developed by Wuhan University and Huazhong University of Science and Technology. It contains 2806 remote sensing images with a total of 188,282 instances, divided into 15 categories.
NWPU VHR-10: The NWPU VHR-10 dataset was constructed by Northwestern Polytechnical University and consists of 650 positive examples and 150 negative examples (backgrounds); the latter do not contain any given object class, while the positive examples contain at least 1 instance, resulting in a total of 3651 target instances. It includes 10 categories.
Figure 9 shows example images of the selected datasets.
4.3. Evaluation Metrics
We used
mAP as the evaluation index for the experiment; it is calculated based on average accuracy (
AP), Precision (
P), and Recall (
R).
P represents the proportion of correctly predicted positive instances among all positive instances in the predicted results, calculated as
R represents the proportion of correctly predicted positive instances among all positive instances of the sample being predicted, calculated as
In the above context, TP denotes the count of correctly predicted positive instances, FP refers to the number of incorrectly predicted negative instances (false positives), and FN signifies the quantity of incorrectly predicted positive instances (false negatives).
During the training process, the tradeoff between
P and
R is plotted as a P-R (Precision–Recall) curve, where
AP is the area of each target category enclosed by the horizontal and vertical axes on the P-R curve. Its calculation formula is
mAP is the average area defined by the horizontal and vertical coordinates on the P-R curve for all target categories, calculated as
Above, n represents the number of detected categories and i represents the i-th detection target.
FPS (frames per second) was calculated by averaging the inference time over 1000 forward passes on an NVIDIA GeForce RTX 3090 GPU, with an input image size of 640 × 640.
4.4. Analysis of Experimental Results
We compared CIMB-YOLO with its baseline, YOLOv8, to demonstrate the effectiveness of our model and recorded the experimental results in
Table 1,
Table 2 and
Table 3. To maintain consistency with established YOLO benchmarks, we evaluate our model using both mAP@50 (single IoU threshold of 0.5) and mAP@50:95 (averaged across IoU thresholds from 0.5 to 0.95 at 0.05 intervals). Compared to the baseline, our method demonstrates consistent improvements across all metrics: +1.2%, +0.7%, and +1.7% in mAP@50, along with +1.4%, +0.9%, and +0.5% in mAP@50:95 - while simultaneously achieving a 14% reduction in parameter count. At the same time, the FPS is within an acceptable range, ensuring real-time performance, demonstrating the superiority of our method.
Table 4,
Table 5 and
Table 6 show the performance of the baseline model and CIMB-YOLO in each category (the performance fluctuations of some small categories in the NWPU VHR-10 dataset, such as Basketball Court and Tennis Court, are mainly due to insufficient sample size). In almost all categories, compared with the baseline, CIMB-YOLOv8 shows higher accuracy, recall, and mAP@50.
Figure 10 shows a comparison between the CIMB-YOLO and YOLOv8n P-R curves of the DIOR dataset, indicating that our model allows for a significant improvement in performance, particularly in categories such as ships, vehicles, helicopters, dams, and ports, which have a large number of dense small target objects. The experimental results fully demonstrate the effectiveness of SMP. The SPConv module downsamples the feature map without losing learnable information, fully utilizing the features of small targets. The OK module effectively learns the feature representations from global to local levels through the utilization of the global, large, and local branches. At the same time, the LGDD detection head makes the entire model lightweight without losing accuracy. The CIMB-YOLOv8 algorithm effectively reduces false alarms and missed detection instances, greatly improving the detection accuracy for dense small targets in remote sensing images. The experimental results show that the algorithm can capture complex details well and significantly improve the detection accuracy in complex scenes.
Table 7 presents a comparative analysis of the proposed CIMB-YOLO algorithm and current mainstream object detection algorithms on the DIOR dataset. As shown in the figure, compared with the two-stage Faster R-CNN algorithm, CIMB-YOLO performs better in mAP@50. The detection accuracy is significantly improved (by 9.7%, the number of parameters is much lower, and the FPS is greatly improved. This suggests that the CIMB-YOLO algorithm achieves notable improvements in both detection accuracy and operational efficiency, rendering it better suited for deployment on resource-constrained devices. Compared with the one-stage detection algorithm SSD, there are significant improvements in the metrics of mAP@50, parameter count, and FPS. Compared with other versions of YOLO and the newer DConvTransLGA model, our model also has significant advantages. This indicates that the proposed CIMB-YOLO model simultaneously allows for an improvement in accuracy and makes the model lightweight.
Figure 11 shows an example of inference by CIMB-YOLO on the DIOR dataset. It can be clearly seen from the figure that the confidence level of our model in detecting targets is mostly around 0.9.
Figure 12 shows the corresponding heatmap of the example, where the first row is the output of the CIMB-YOLO, and the second row is that of YOLOv8 baseline model. The heatmap visualization reveals distinct performance characteristics of our model compared to the baseline. Three key observations emerge: (1) the darker coloration in high-value regions quantitatively confirms stronger activation magnitudes in our model; (2) the spatial concentration of these high-value responses demonstrates precise spatial attention to target features; (3) this focused activation pattern effectively suppresses background noise. These visual patterns not only validate our architectural design principles but also provide empirical evidence for the model’s enhanced feature discrimination capability.
Figure 13 shows the detection results of CIMB-YOLO on the DOTA and NWPU VHR-10 datasets.
4.5. Ablation Study
We conducted additional ablation experiments to evaluate the effectiveness and impact of integrating SMP and LGDD in the YOLOv8 model, with each module’s contribution being indicated by a Y. The evaluation indicators include mAP, parameter quantity, FLOP, and FPS, and the results are shown in
Table 8. In Experiment 1, we integrated the SMP module to better capture important feature information. In Experiment 2, we introduced the LGDD module, and the results show that it reduced computational complexity by 20% and the parameter count by 2% without compromising accuracy and FPS, demonstrating its effectiveness. In Experiment 3, we combined the two modules to compensate for the negative impact of the SMP module on the increase in parameter count and computational complexity. Compared with YOLOv8, our model improved accuracy by 1.2% while reducing parameter count by 14%. These ablation experiments demonstrate the importance of each module within the CIMB-YOLO framework, highlighting their complementarity and effectiveness in enhancing YOLOv8’s performance.
5. Discussion and Conclusions
In the context of the increasing demand for lightweight models and precise object detection in remote sensing images, our method provides a feasible solution that balances accuracy and computational constraints. In this study, we propose CIMB-YOLO, a lightweight RSOD network designed to address the above unique challenges. Firstly, SMP was developed as an improvement to the original PAN-FPN; it is capable of extracting small-target-rich features for fusion and efficiently learning hierarchical feature representations across global-to-local scales, thereby enhancing small-target detection performance. Secondly, we designed a novel detection head, LGDD, in order to make the model lightweight and more suitable for deployment requirements. Using shared convolution allowed us to significantly reduce the number of parameters, making the model more lightweight, which is especially significant for its implementation on resource-limited devices. Furthermore, we improved its accuracy by using DEConv to enhance the detail capture ability of the detection head. The experimental results show that the CIMB-YOLO algorithm performs well on the DIOR, DOTA, and NWPU datasets in terms of mAP@50. The recognition rates of the CIMB-YOLOv8 algorithm are 85.3%, 68.8%, and 82.9%, respectively, which are 1.2%, 0.7%, and 1.7% higher than those of the baseline YOLOv8 algorithm. A total of 14% of the parameter reduction in the model is achieved through shared convolution, which eliminates redundant multi-scale convolutions while maintaining feature diversity. Compared with current mainstream algorithms, the CIMB-YOLO model outperforms other object detection methods in terms of object detection performance while having a smaller number of parameters and lower computational complexity, which fully attests to the effectiveness of the algorithm.
While demonstrating promising results, this study presents several limitations that merit discussion. First, although the SMP module enhances small-target detection capability, the modest 1.4% improvement in mAP@50:95 compared to the 1.2% gain in mAP@50 suggests suboptimal feature discrimination at higher IoU thresholds. Second, while the LGDD head achieves a 14% parameter reduction through shared convolutions, its real-time inference efficiency on resource-constrained edge devices (<1GB memory) remains unverified. Third, the current single-modal design limits applicability in multi-modal sensing scenarios that increasingly dominate modern remote sensing applications (e.g., SAR-optical fusion for all-weather monitoring).
To advance this research, we propose two key development directions:
1. Hierarchical Feature Enhancement: We will design a multi-stage feature refinement network with adaptive receptive field control to improve localization precision across IoU thresholds, specifically targeting a >5% increase in mAP@50:95 performance. This module will incorporate boundary-aware attention and scale-adaptive feature fusion to address current limitations in high-IoU detection.
2. Ultra-Efficient Deployment Optimization: Building upon our parameter-efficient design, we will investigate hybrid compression techniques combining (i) quantization-aware training (8-bit fixed-point), (ii) attention-guided pruning, and (iii) neural architecture search to achieve sub-50MB memory footprint while maintaining <1% accuracy drop, enabling deployment on next-generation IoT edge devices.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}