
Adaptive Temporal Action Localization in Video

Abstract
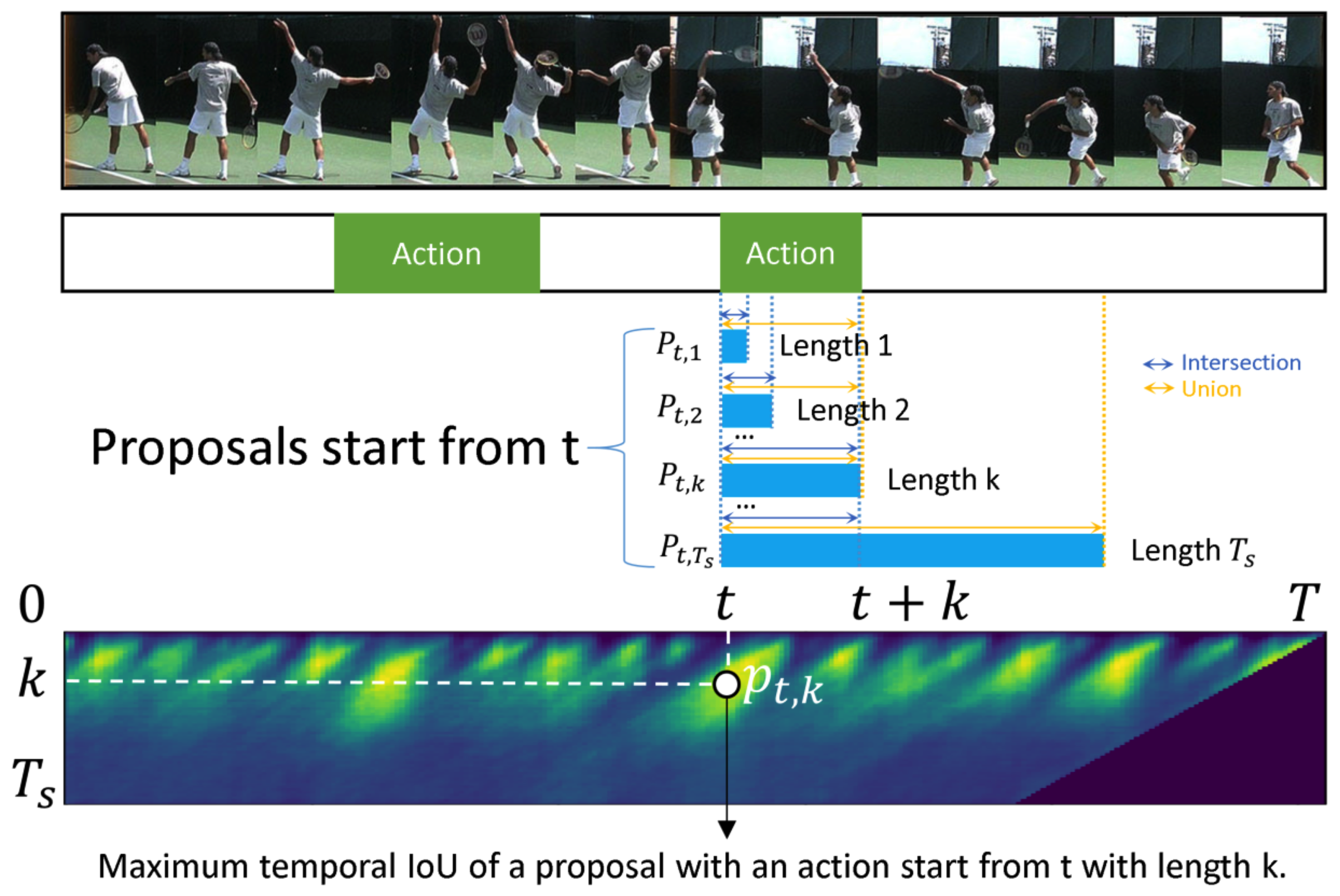
1. Introduction
- A novel deep learning architecture, namely an adaptive template-guided self-attention network, is proposed by introducing a template-guided self-attention to formulate proposal representations adaptively without prior assumptions.
- We propose a two-level scheme to derive a fine probability map from a coarse one by establishing a shortcut connection in pursuit of smooth and continuous properties.
- Comprehensive experiments demonstrate the effectiveness of our proposed method. It achieved state-of-the-art performance on two benchmark datasets: 32.6% mAP@Iou 0.7 on THUMOS-14 and 9.35% mAP@IoU 0.95 on ActivityNet-1.3.
2. Related Work
3. Proposed Method
3.1. Problem Formulation
3.2. Global and Local Encoders
3.3. Density Adaptive Sampler
3.4. Probability Map Estimation
3.5. Localization Loss
3.6. Proposal Selection
4. Experimental Results and Discussion
4.1. Datasets and Evaluation Metrics
4.2. Implementation Details
4.3. Comparison with the State of the Art
4.4. Ablation Study on Density Adaptive Sampler
4.5. Impacts of the Sliding Window Size
4.6. Qualitative Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Gao, J.; Yang, Z.; Chen, K.; Sun, C.; Nevatia, R. TURN TAP: Temporal Unit Regression Network for Temporal Action Proposals. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Xu, H.; Das, A.; Saenko, K. R-C3D: Region Convolutional 3D Network for Temporal Activity Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Liu, Q.; Wang, Z. Progressive boundary refinement network for temporal action detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11612–11619. [Google Scholar]
- Dai, X.; Singh, B.; Zhang, G.; Davis, L.S.; Qiu Chen, Y. Temporal Context Network for Activity Localization in Videos. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Chao, Y.; Vijayanarasimhan, S.; Seybold, B.; Ross, D.A.; Deng, J.; Sukthankar, R. Rethinking the Faster R-CNN Architecture for Temporal Action Localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1130–1139. [Google Scholar]
- Zhao, Y.; Xiong, Y.; Wang, L.; Wu, Z.; Tang, X.; Lin, D. Temporal Action Detection with Structured Segment Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Lin, T.; Zhao, X.; Su, H.; Wang, C.; Yang, M. BSN: Boundary Sensitive Network for Temporal Action Proposal Generation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Zhao, P.; Xie, L.; Ju, C.; Zhang, Y.; Wang, Y.; Tian, Q. Bottom-up temporal action localization with mutual regularization. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 539–555. [Google Scholar]
- Zeng, R.; Huang, W.; Tan, M.; Rong, Y.; Zhao, P.; Huang, J.; Gan, C. Graph Convolutional Networks for Temporal Action Localization. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Lin, T.; Liu, X.; Li, X.; Ding, E.; Wen, S. BMN: Boundary-matching network for temporal action proposal generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3889–3898. [Google Scholar]
- Xu, M.; Zhao, C.; Rojas, D.S.; Thabet, A.; Ghanem, B. G-tad: Sub-graph localization for temporal action detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10156–10165. [Google Scholar]
- Lin, C.; Li, J.; Wang, Y.; Tai, Y.; Luo, D.; Cui, Z.; Wang, C.; Li, J.; Huang, F.; Ji, R. Fast learning of temporal action proposal via dense boundary generator. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11499–11506. [Google Scholar]
- Long, F.; Yao, T.; Qiu, Z.; Tian, X.; Luo, J.; Mei, T. Gaussian temporal awareness networks for action localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 344–353. [Google Scholar]
- Kanwal, S.; Mehta, V.; Dhall, A. Large Scale Hierarchical Anomaly Detection and Temporal Localization. In Proceedings of the ACM International Conference on Multimedia, Online, 12–16 October 2020; pp. 4674–4678. [Google Scholar]
- Deng, Z.; Guo, Y.; Han, C.; Ma, W.; Xiong, J.; Wen, S.; Xiang, Y. AI Agents Under Threat: A Survey of Key Security Challenges and Future Pathways. ACM Comput. Surv. 2025, 57, 1–36. [Google Scholar] [CrossRef]
- Chen, X.; Li, C.; Wang, D.; Wen, S.; Zhang, J.; Nepal, S.; Xiang, Y.; Ren, K. Android HIV: A study of repackaging malware for evading machine-learning detection. IEEE Trans. Inf. Forensics Secur. 2019, 15, 987–1001. [Google Scholar] [CrossRef]
- Zhu, X.; Zhou, W.; Han, Q.L.; Ma, W.; Wen, S.; Xiang, Y. When software security meets large language models: A survey. IEEE/CAA J. Autom. Sin. 2025, 12, 317–334. [Google Scholar] [CrossRef]
- Zhou, W.; Zhu, X.; Han, Q.L.; Li, L.; Chen, X.; Wen, S.; Xiang, Y. The security of using large language models: A survey with emphasis on ChatGPT. IEEE/CAA J. Autom. Sin. 2024, 12, 1–26. [Google Scholar] [CrossRef]
- Chen, J.; Lv, Z.; Wu, S.; Lin, K.Q.; Song, C.; Gao, D.; Liu, J.W.; Gao, Z.; Mao, D.; Shou, M.Z. Videollm-online: Online video large language model for streaming video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 18407–18418. [Google Scholar]
- Zhao, Y.; Misra, I.; Krähenbühl, P.; Girdhar, R. Learning video representations from large language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 6586–6597. [Google Scholar]
- Liberatori, B.; Conti, A.; Rota, P.; Wang, Y.; Ricci, E. Test-time zero-shot temporal action localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 18720–18729. [Google Scholar]
- Zhang, Q.; Fang, J.; Yuan, R.; Tang, X.; Qi, Y.; Zhang, K.; Yuan, C. Weakly Supervised Temporal Action Localization via Dual-Prior Collaborative Learning Guided by Multimodal Large Language Models. In Proceedings of the Computer Vision and Pattern Recognition Conference, Honolulu, HI, USA, 19–25 October 2025; pp. 24139–24148. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Wu, B.; Xu, C.; Dai, X.; Wan, A.; Zhang, P.; Tomizuka, M.; Keutzer, K.; Vajda, P. Visual transformers: Token-based image representation and processing for computer vision. arXiv 2020, arXiv:2006.03677. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision. Springer, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS — Improving Object Detection with One Line of Code. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5562–5570. [Google Scholar]
- Jiang, Y.G.; Liu, J.; Roshan Zamir, A.; Toderici, G.; Laptev, I.; Shah, M.; Sukthankar, R. THUMOS Challenge: Action Recognition with a Large Number of Classes. 2014. Available online: http://crcv.ucf.edu/THUMOS14/ (accessed on 8 October 2024).
- Heilbron, F.C.; Escorcia, V.; Ghanem, B.; Niebles, J.C. ActivityNet: A Large-Scale Video Benchmark for Human Activity Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 961–970. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal segment networks: Towards good practices for deep action recognition. In Proceedings of the European Conference on Computer Vision. Springer, Amsterdam, The Netherlands, 11–14 October 2016; pp. 20–36. [Google Scholar]
- Xiong, Y.; Wang, L.; Wang, Z.; Zhang, B.; Song, H.; Li, W.; Lin, D.; Qiao, Y.; Van Gool, L.; Tang, X. CUHK & ETHZ & SIAT submission to activitynet challenge 2016. arXiv 2016, arXiv:1608.00797. [Google Scholar]
- Wang, L.; Xiong, Y.; Lin, D.; Van Gool, L. UntrimmedNets for Weakly Supervised Action Recognition and Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6402–6411. [Google Scholar]
- Qiu, H.; Zheng, Y.; Ye, H.; Lu, Y.; Wang, F.; He, L. Precise temporal action localization by evolving temporal proposals. In Proceedings of the ACM on International Conference on Multimedia Retrieval, Yokohama, Japan, 11–14 June 2018; pp. 388–396. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 |
|---|---|---|---|---|---|
| TURN [1] | 44.1 | 34.9 | 25.6 | - | - |
| TCN [4] | - | 33.3 | 25.6 | 15.9 | 0.9 |
| R-C3D [2] | 44.8 | 35.6 | 28.9 | - | - |
| SSN [6] | 51.9 | 41.0 | 29.8 | 19.6 | 10.7 |
| BSN [7] | 53.5 | 45.0 | 36.9 | 28.4 | 20.0 |
| TAL-NET [5] | 53.2 | 48.5 | 42.8 | 33.8 | 20.8 |
| GTAN [13] | 57.8 | 47.2 | 38.8 | - | - |
| BMN [10] | 56.0 | 47.4 | 38.8 | 29.7 | 20.5 |
| BSN+PGCN [9] | 63.6 | 57.8 | 49.1 | - | - |
| PBRNet [3] | 58.5 | 54.6 | 51.3 | 41.8 | 29.5 |
| ETP [33] | 48.2 | 42.4 | 34.2 | 23.4 | 13.9 |
| G-TAD [11] | 54.5 | 47.6 | 40.2 | 30.8 | 23.4 |
| G-TAD+PGCN [11] | 66.4 | 60.4 | 51.6 | 37.6 | 22.9 |
| DBG [12] | 57.8 | 49.4 | 39.8 | 30.2 | 21.7 |
| BU-TAL [8] | 53.9 | 50.7 | 45.4 | 38.0 | 28.5 |
| Uniform Sampling * | 42.0 | 36.5 | 29.9 | 21.2 | 13.6 |
| Ours | 66.0 | 60.7 | 53.7 | 44.16 | 32.6 |
| Methods | 0.5 | 0.75 | 0.95 | Avg |
|---|---|---|---|---|
| TCN [4] | 37.49 | 23.47 | 4.47 | 23.58 |
| SSN [6] | 43.26 | 28.70 | 5.63 | 28.28 |
| BSN [7] | 46.45 | 29.96 | 8.02 | 30.03 |
| TAL-NET [5] | 38.23 | 18.30 | 1.30 | 20.22 |
| GTAN [13] | 52.61 | 34.14 | 8.91 | 34.31 |
| BMN [10] | 50.07 | 34.78 | 8.29 | 33.85 |
| PBRNet [3] | 53.96 | 34.97 | 8.98 | 35.01 |
| G-TAD [11] | 50.36 | 34.60 | 9.02 | 34.09 |
| BU-TAL [8] | 43.47 | 33.91 | 9.21 | 30.12 |
| Ours | 42.11 | 30.21 | 9.35 | 30.0 |
| Ordered | Mask | Noise | |||||
|---|---|---|---|---|---|---|---|
| Attention | Frame | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | |
| ✗ | ✗ | ✗ | 61.7 | 57.2 | 50.6 | 39.7 | 28.2 |
| ✓ | ✗ | ✗ | 62.7 | 58.4 | 50.5 | 40.9 | 28.7 |
| ✗ | ✓ | ✗ | 63.0 | 58.5 | 50.9 | 40.8 | 30.3 |
| ✗ | ✗ | ✓ | 63.4 | 59.3 | 52.3 | 43.1 | 30.9 |
| ✓ | ✓ | ✓ | 66.0 | 60.7 | 53.7 | 44.2 | 32.6 |
| # of Noise Frames | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 |
|---|---|---|---|---|---|
| 1 | 63.4 | 59.3 | 52.3 | 43.1 | 30.9 |
| 4 | 62.4 | 58.5 | 52.2 | 42.8 | 30.4 |
| 16 | 64.8 | 60.6 | 54.3 | 43.0 | 30.5 |
| Sliding Windows Size | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 |
|---|---|---|---|---|---|
| 48 | 63.4 | 58.8 | 50.4 | 40.4 | 28.4 |
| 64 | 66.0 | 60.7 | 53.7 | 44.2 | 32.6 |
| 80 | 65.6 | 60.8 | 53.5 | 41.9 | 30.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Z.; Lu, Z.; Ding, Y.; Tian, L.; Liu, S. Adaptive Temporal Action Localization in Video. Electronics 2025, 14, 2645. https://doi.org/10.3390/electronics14132645
Xu Z, Lu Z, Ding Y, Tian L, Liu S. Adaptive Temporal Action Localization in Video. Electronics. 2025; 14(13):2645. https://doi.org/10.3390/electronics14132645
Chicago/Turabian StyleXu, Zhiyu, Zhuqiang Lu, Yong Ding, Liwei Tian, and Suping Liu. 2025. "Adaptive Temporal Action Localization in Video" Electronics 14, no. 13: 2645. https://doi.org/10.3390/electronics14132645
APA StyleXu, Z., Lu, Z., Ding, Y., Tian, L., & Liu, S. (2025). Adaptive Temporal Action Localization in Video. Electronics, 14(13), 2645. https://doi.org/10.3390/electronics14132645