1. Introduction
The rapid proliferation of data in modern industrial environments, driven by the Internet of Things (IoT) and Industry 4.0, has led to an unprecedented deluge of information, with data volumes already reaching multiple petabytes and projected to grow to zettabytes in the coming years [
1,
2]. This exponential growth presents both opportunities and challenges. On one hand, it supports the analysis of large-scale industrial datasets, offering opportunities to enhance predictive maintenance strategies and resource allocation in smart factory settings; on the other, it places significant strain on existing big data management systems, particularly in terms of scalability, latency, and real-time processing capabilities.
In industrial IoT (IIoT) scenarios, where data is generated at the edge from sensors, machines, and other connected devices, the need for efficient distributed data processing has become indispensable. To meet time-based quality-of-service (QoS) requirements, such as reduced latency and high throughput, big data workflows are increasingly being deployed in distributed environments, including clusters, clouds, and edge computing systems. These environments must handle the dual challenges of processing massive data volumes while maintaining the low-latency demands of industrial applications [
3].
Over the past decade, several big data processing paradigms have emerged to address these challenges. Among them, the MapReduce paradigm and its initial implementation, Apache Hadoop [
4] have been widely adopted for various real-world applications. However, the limitations of disk-based processing have led to the rise of in-memory systems like Apache Spark [
5], which offer significantly faster data processing by keeping data in memory. These systems are typically deployed in large clusters of bare-metal devices or virtual machines, operating in a parallel computing fashion. Meanwhile, High-Performance Computing (HPC) systems, known for their fast computation power and high-performance capabilities, are gaining traction for big data processing in industrial settings. HPC systems, with their thousands of nodes and multiple processing cores, are particularly appealing for handling the massive data loads generated in modern factories.
Despite their potential, HPC systems and big data processing frameworks have traditionally been designed with different architectures. HPC systems follow a compute-centric paradigm, where data is separated from computing resources, while big data systems like Apache Spark [
5] employ a data-centric approach, co-locating data with computing resources to enable data parallelization. This architectural difference poses a significant challenge when integrating big data processing frameworks into HPC environments, as the frequent data transfers between parallel file systems and computation nodes can introduce latency, impacting QoS requirements [
6].
Recent research has explored the performance of deploying big data processing frameworks, such as Apache Spark [
5], on HPC hardware [
6,
7,
8]. However, these studies have not addressed the performance of such frameworks on ARM-based HPC architectures, particularly those utilizing vector instructions like Scalable Vector Extensions (SVEs). This gap is critical, as ARM-based architectures are increasingly being adopted in edge and cloud computing environments due to their energy efficiency and scalability, making them well-suited for industrial IoT applications.
This paper explores two central aspects of deploying big data processing frameworks on ARM-based HPC architectures: first, the extent to which current software stacks support advanced vectorization features like SVEs, and second, how these architectural capabilities influence the performance of in-memory processing systems like Apache Spark. First, we investigated the extent to which current big data processing software stacks, such as Apache Spark 3.0.2, support vector instructions (SVEs) for ARM-based HPC architectures. Second, we assessed the performance of in-memory big data processing systems, specifically Apache Spark, on ARM-based HPC systems leveraging SVE instructions. To answer these questions, we conducted a first-of-its-kind extensive performance evaluation on an ARM-based HPC deployment with JVM SVE support. This study aims to equip researchers and system architects with empirically derived deployment guidance and performance optimization strategies for big data frameworks operating on ARM-based HPC systems, particularly within industrial IoT and edge computing contexts.
This study aims to investigate the performance and feasibility of deploying Apache Spark, a widely adopted in-memory big data processing framework, on ARM-based High-Performance Computing (HPC) systems equipped with Scalable Vector Extensions (SVEs). Specifically, we seek to address two key objectives: (1) to evaluate the extent to which current big data software stacks support vectorized instructions such as SVEs on ARM-based HPC architectures, and (2) to assess the performance characteristics of Apache Spark when executing industrial IoT workloads on ARM-based HPC systems leveraging SVE capabilities. These objectives shape the direction of our experimental evaluation and help identify key performance factors and configuration strategies for deploying big data frameworks in energy-efficient and scalable computing settings.
In this study, we characterized the performance of Apache Spark on an ARM-based HPC system using representative big data benchmarking workloads. We analyzed the impact of various configuration settings and provided recommendations for optimizing performance in industrial IoT scenarios.
The remainder of this paper is organized as follows.
Section 2 provides an overview of the theoretical foundations and relevant background.
Section 3 describes the system architecture and methodology used for testing.
Section 4 presents the deployment, test cases, and results of our performance evaluation.
Section 5 discusses the implications of our findings, while
Section 6 reviews related work in the field. Finally,
Section 7 concludes the paper with recommendations for future research.
2. Overview and Theoretical Foundations
The modern industrial landscape is undergoing a profound transformation driven by the pervasive adoption of Internet of Things (IoT) technologies and the emergence of Industry 4.0 paradigms. This transformation has created an urgent need for sophisticated computing architectures capable of processing vast streams of industrial data while meeting stringent requirements for real-time responsiveness, scalability, and energy efficiency. As industrial environments become increasingly instrumented with sensors and connected devices, computational challenges have shifted from traditional batch processing to dynamic, distributed analytics that must operate across the cloud–edge continuum. This section establishes the theoretical foundations for understanding how contemporary computing paradigms can address these challenges, with particular attention to their applications in industrial IoT scenarios.
2.1. Workflows and Pipelines for the Management of Data/Compute-Intensive Applications
Industrial IoT systems generate complex workflows that fundamentally differ from traditional scientific computing pipelines in their operational requirements and constraints. Where scientific workflows might prioritize absolute computational accuracy with flexible timelines, industrial workflows must balance computational precision with hard real-time constraints, fault tolerance, and seamless integration across heterogeneous hardware platforms. These workflows typically manifest as directed acyclic graphs (DAGs) that orchestrate data ingestion, preprocessing, distributed computation, and decision-making across the entire manufacturing ecosystem. A typical smart factory deployment might involve thousands of such workflows operating concurrently, processing data streams from production line sensors, quality control systems, and supply chain monitoring tools.
The computational demands of these industrial workflows have led to innovative hybrid architectures that combine the strengths of High-Performance Computing (HPC) systems with data-intensive scalable computing (DISC) frameworks. HPC systems, traditionally the domain of scientific simulations, are finding new applications in industrial scenarios such as digital twin implementations and complex process modeling. Meanwhile, DISC frameworks like Apache Spark [
9] have become indispensable for handling the data-parallel aspects of industrial analytics, particularly for the real-time processing of sensor data and equipment telemetry. However, this convergence of computing paradigms introduces significant challenges in resource management, particularly when workflows must span from resource-constrained edge devices to powerful cloud-based computation nodes while maintaining strict quality-of-service guarantees.
2.2. Computing Paradigms and Storage Architectures for Industrial IoT
The digital transformation of industrial environments has necessitated a fundamental rethinking of computing architectures to accommodate the unique demands of IoT-enabled manufacturing. Traditional centralized computing models, while still relevant for certain edge applications requiring deterministic latency (such as robotic control loops or safety-critical shutdown systems), are increasingly being supplanted by heterogeneous architectures that distribute computation across the cloud–edge continuum. This shift reflects the growing recognition that industrial workloads exhibit varying—and often conflicting—requirements for processing latency, data locality, and computational intensity. A vibration monitoring system in a smart factory, for instance, might demand sub-millisecond response times for anomaly detection (favoring edge processing) while simultaneously requiring teraflop-scale computational resources for predictive maintenance models (favoring cloud or HPC backends).
At the heart of this architectural evolution lies the dichotomy between data-intensive and compute-intensive processing paradigms. Data-intensive workloads, characteristic of most industrial IoT deployments, prioritize the high-throughput ingestion and transformation of sensor data streams, typically leveraging shared-nothing architectures exemplified by Apache Spark’s Resilient Distributed Datasets (RDDs). These architectures excel at horizontal scaling across commodity hardware but often struggle with the fine-grained parallelism required for complex physical simulations. Conversely, compute-intensive workloads—such as digital twin simulations or computational fluid dynamics analyses—traditionally rely on HPC systems featuring shared-memory architectures and high-bandwidth interconnects like NVLink or InfiniBand. The emerging challenge for Industry 4.0 lies in seamlessly integrating these paradigms, enabling workflows where real-time sensor analytics (data-intensive) can trigger and interact with high-fidelity simulations (compute-intensive) without prohibitive latency penalties.
Storage architectures constitute an equally critical dimension of industrial computing systems, where design decisions profoundly influence system-wide performance characteristics. Modern industrial deployments employ a stratified storage hierarchy that mirrors the cloud–edge compute continuum:
Edge-tier storage employs lightweight embedded databases (e.g., SQLite) and in-memory buffers to support ultra-low-latency processing for resource-constrained devices. These systems prioritize write throughput and deterministic access patterns, often implementing specialized data reduction techniques (such as dead-band compression or adaptive sampling) to mitigate the “edge data deluge.”
Fog-layer storage typically utilizes distributed key-value stores (e.g., Redis) or time-series databases (e.g., InfluxDB) to aggregate and preprocess data from multiple edge devices. This layer introduces support for transactional semantics and limited analytics capabilities, serving as a critical bridge between edge and cloud tiers.
Cloud/HPC-tier storage leverages scalable object stores (e.g., Ceph) and parallel file systems (e.g., Lustre) to support batch analytics and large-scale simulations. Notably, the growing adoption of computational storage devices—which embed processing capabilities within storage media—is blurring the traditional boundaries between storage and computing in industrial HPC deployments.
The interplay between these storage tiers is governed by sophisticated data movement policies that must account for multiple constraints: bandwidth limitations in factory networks, data sovereignty requirements, and the temporal characteristics of analytical queries. For instance, a predictive maintenance system might retain raw vibration data at the edge for only 24 h (to support real-time anomaly detection), while shipping compressed features to fog nodes for medium-term trend analysis, and eventually archiving aggregated statistics in cloud storage for long-term model retraining. This hierarchical approach exemplifies the Industrial Data Fabric concept, which seeks to optimize data placement and movement across the entire computing continuum.
The emergence of 5G/6G-enabled industrial networks has further complicated this architectural landscape by introducing new possibilities—and challenges—for distributed storage systems. Network slicing capabilities allow for dedicated virtual networks with a guaranteed quality of service (QoS), enabling novel use cases like distributed erasure coding across edge devices. However, these advancements also exacerbate existing tensions between consistency and availability in distributed storage systems, particularly in safety-critical applications where stale data could have catastrophic consequences. Recent research has explored hybrid consistency models that employ physical-time-based reconciliation, leveraging synchronized industrial clocks (e.g., via the IEEE 1588 Precision Time Protocol) to resolve conflicts in sensor data replication.
Looking ahead, the convergence of storage-class memory (e.g., Intel Optane) and near-data processing architectures promises to further reshape industrial computing paradigms. These technologies enable novel approaches to real-time analytics, such as executing streaming algorithms directly on the memory bus or performing the in-storage processing of time-series data. For industrial IoT systems, this could dramatically reduce the latency and energy overhead associated with traditional von Neumann architectures, particularly for applications like high-frequency condition monitoring or adaptive process control. However, these innovations also demand corresponding advances in programming models and system software to fully realize their potential in industrial settings.
2.3. Pipelines Parallelism
The efficient execution of industrial IoT workflows demands sophisticated parallelism strategies that account for the unique constraints of distributed manufacturing environments. Unlike traditional batch-oriented scientific pipelines, industrial applications must balance real-time responsiveness with computational efficiency across heterogeneous edge and cloud resources. This challenge has given rise to adaptive parallelism models that dynamically adjust to workload characteristics and infrastructure capabilities.
Coarse-grained parallelism dominates industrial workflows where task dependencies enforce sequential execution patterns. A typical predictive maintenance pipeline exemplifies this approach, where raw sensor data undergoes staged processing: initial cleaning and normalization at edge nodes precedes feature extraction on fog-layer servers, with final inference executed in the cloud. Each stage depends on outputs from its predecessor, creating a task-sequential workflow that mirrors traditional HPC pipelines but with stricter latency constraints. This pattern proves particularly valuable in digital twin implementations, where physics-based simulations must await preprocessed inputs from distributed sensor networks.
In contrast, fine-grained parallelism enables the high-throughput processing required for industrial streaming applications. Modern smart factories leverage data parallelism to distribute homogeneous operations—such as visual inspection or vibration analysis—across edge devices or GPU-equipped fog nodes. The emergence of 5G-enabled edge computing has further enhanced this capability, allowing microsecond-scale task scheduling that supports latency-critical applications like closed-loop robotic control. Advanced manufacturing plants now implement hierarchical parallelism models that combine both approaches. For instance, a distributed energy grid monitoring system might employ fine-grained parallelism for real-time phasor measurement analysis across edge devices, while reserving coarse-grained orchestration for downstream fault localization simulations that trigger only when anomalies exceed predefined thresholds. This dual approach exemplifies the industrial cloud–edge continuum, where parallelism strategies must continuously adapt to fluctuating workloads and resource availability [
10].
2.4. The Convergence of HPC and DISC in Industrial IoT Systems
The integration of High-Performance Computing and data-intensive scalable computing paradigms is reshaping industrial IoT architectures, enabling previously unattainable synergies between real-time analytics and high-fidelity simulations. This convergence addresses a fundamental challenge in smart manufacturing: the need to reconcile the data-driven nature of distributed sensor networks with the computational demands of physical process modeling.
Traditional HPC systems, while unparalleled for compute-intensive tasks like computational fluid dynamics or materials science simulations, often struggle with the data-locality requirements of industrial IoT deployments. The inherent latency in transferring terabyte-scale sensor data from edge devices to centralized HPC resources can undermine time-sensitive applications. Conversely, DISC frameworks like Apache Spark excel at distributed ETL and stream processing for equipment condition monitoring or supply chain optimization, but lack the numerical precision required for complex physical simulations.
Modern industrial systems are overcoming these limitations through innovative hybrid architectures that strategically distribute workloads across the cloud–edge continuum. In automotive battery manufacturing, for example, Spark-based edge clusters preprocess and compress real-time test data from assembly lines before selectively triggering HPC-resident electrolyte flow simulations. This workflow optimization reduces data movement overhead while maintaining simulation accuracy. The programming model divide between HPC’s MPI/OpenMP and DISC’s data-parallel abstractions persists, but emerging tools like Spark-MPI are bridging this gap by enabling HPC simulations to execute as managed stages within Spark pipelines. Storage architectures are similarly converging, with Lustre-over-HDFS hybrids allowing seamless data sharing between paradigms.
This technological synthesis supports Industry 5.0’s vision of sustainable, human-centric manufacturing by enabling real-time edge analytics to inform high-precision simulations, and vice versa. As ARM-based edge computing matures and 5G networks reduce communication latency, the boundaries between HPC and DISC in industrial settings will continue to blur, creating new opportunities for optimizing manufacturing processes through integrated analytics and simulation [
11,
12,
13].
2.5. Apache Spark Architecture
Apache Spark has emerged as a versatile open-source engine for distributed data processing, designed specifically to handle the massive data streams characteristic of industrial IoT environments. Building upon the MapReduce paradigm [
14], Spark extends its capabilities through an advanced execution model that combines in-memory processing with flexible workflow orchestration. At its core, Spark utilizes Resilient Distributed Datasets (RDDs) [
5] as its fundamental programming abstraction—fault-tolerant collections of objects partitioned across cluster nodes that enable the parallel processing of industrial data streams. This architecture addresses the critical requirements of modern manufacturing systems by supporting both the batch processing of historical production data and the micro-batch processing of real-time sensor streams [
15,
16], making it equally suitable for quality control analytics and equipment condition monitoring.
The framework’s directed acyclic graph (DAG) execution model provides particular value for industrial applications by enabling complex pipeline logic while maintaining fault tolerance. Spark constructs these DAGs lazily, deferring transformations (such as filter or map operations) until it encounters terminal actions (analogous to reduce operations in MapReduce). This approach allows for significant optimization opportunities in industrial deployments, where processing workflows often involve multiple stages of data enrichment and analysis. For instance, a smart factory might implement a DAG that first cleans vibration sensor data, extracts spectral features, applies machine learning models for anomaly detection, and finally triggers maintenance alerts—all as a single optimized pipeline.
A key advantage in industrial settings is Spark’s sophisticated data movement optimization. The framework employs specialized block and shuffle managers to control data transfer between partitions, with the shuffle manager handling reduce-like operations that require data redistribution across nodes. Industrial deployments particularly benefit from performance-aware programming techniques, such as preferring reduceByKey over groupByKey transformations. The former computes local aggregations before shuffling data, significantly reducing the network overhead when processing massive equipment telemetry datasets—a common scenario in production monitoring systems. This optimization proves crucial in manufacturing environments where network bandwidth may be constrained by legacy infrastructure or shared with time-sensitive control systems. Therefore, reduceByKey transfers much less data as compared with groupByKey across the cluster network. In most cases, reduceByKey outperforms a combination that is composed of groupByKey and mapValues transformations.
Figure 1 illustrates this idea.
Spark’s architecture also addresses several industrial-specific challenges. Its high-level APIs in Java, Scala, and Python allow for integration with existing manufacturing software ecosystems, while its evolving support for ARM-based architectures enables energy-efficient edge computing deployments. This capability aligns with Industry 5.0’s sustainability goals, allowing Spark to run on everything from cloud clusters to resource-constrained edge devices. The framework’s ability to minimize data movement through partitioning strategies and advanced join algorithms (like shuffled hash joins via cogroup operations [
17,
18]) makes it particularly suitable for distributed factory environments where data locality impacts system responsiveness.
Looking ahead, Spark’s integration with emerging computing architectures—including ARM-based HPC systems as explored in this research—promises to further enhance industrial analytics capabilities. This combination could deliver the computational power needed for sophisticated applications like plant-wide digital twins while maintaining the energy efficiency required for large-scale deployments.
2.6. The Context of the EPI Project
The European Processor Initiative (EPI) (
https://www.european-processor-initiative.eu/ accessed on 15 June 2023) is a large European project that aims to create, design, and develop a new, highly efficient processor family for extreme scale computing, high-performance big data, intensive virtualization, and a large plethora of other applications. The EPI is funded by the European High Performance Computing Joint Undertaking (JU). The JU receives support from the European Union’s Horizon 2020 research and innovation program and from many European states. The EPI is a multi-stage project that puts its focus on developing supercomputing technologies for EU members to enable the design, implementation, and marketing of world-class competitive HPC. In more detail, the EPI promotes the exploitation of microprocessors’ accelerator technologies with drastically better performance and power efficiency for impactful ICT applications like big data, and virtualization.
The EPI is in stage two, which runs from 2022 to 2025, while the first phase ran from 2019 to 2021. The first stage targeted the design of new low-power, high-performance processors through the implementation of vector instructions and specific accelerators with high bandwidth memory access. The EPI project, in this first phase, focused on the design and the development of a complete software stack and a common platform on which to build the new processor prototype. This stack and the common platform were validated through the massive and intensive use of simulation and tested on V1 Arm cores HBM, DDR5, and PCIeG5/CXL/CCIX. The EPI brings together partners encompassing academia, research, industrials, system developers, and system integrators to deliver, in its first step, a competitive chip that can effectively address the requirements of the HPC, AI, automotive, and trusted IT infrastructure markets.
The EPI is now in the second phase, which aims to finalize the development of the first generation of low-power microprocessor units and accelerators, enhancing existing technologies to target the incoming European Exa-scale machines, developing the second generation and ensuring paths for the industrialization and commercialization of these technologies. The EPI’s roadmap for phase two is depicted in
Figure 2. More in detail, the EPI aims to finalize the development of the processor chip prototype designed with the common platform (the Rhea Platform) developed in the first project phase. The outcome of phase one is a Rhea General Purpose Processor (Rhea-GPP), which is planned to be developed, expanded, and updated in phase two according to the roadmap. Within this context, there is Work Package 1 (WP1), in which our contribution is placed. WP1 is responsible for testing new and modern applications on the developed Rhea-GPP, like big data or virtualization applications, and studying the performance and how it responds to their loads. Our contribution focuses on the test of the big data application of a Rhea-GPP-like processor (ARM-based processor). More in detail, we used Apache Spark, the de facto standard for big data processing, to run two very common and widespread data/resource-intensive applications on the target architecture, and we studied the performance and the architecture response.
3. System Architecture
Building upon the architectural foundations established in
Section 2, this investigation focuses on evaluating ARM-based High-Performance Computing architectures, particularly the Rhea-GPP processor that is being developed under the European Processor Initiative (EPI), for their potential to enhance big data processing in industrial IoT and edge computing scenarios. Given the ongoing development status of the EPI project, our experimental framework employs the V1 ARM processor as a proxy, which embodies the same fundamental design principles as the forthcoming Rhea-GPP: namely, the combination of high-performance vector processing capabilities with exceptional energy efficiency—a critical requirement for sustainable Industry 4.0 and 5.0 implementations.
The V1 ARM processor’s incorporation of 256-byte Scalable Vector Extensions (SVEs) represents a significant advancement for industrial applications, enabling fine-grained parallel processing that proves particularly beneficial for real-time analytics and streaming data operations. This architectural approach distinguishes itself from conventional x86 architectures (such as those featuring Intel AVX instructions) by achieving superior energy efficiency without compromising computational performance, making it exceptionally well-suited for distributed edge-cloud industrial systems where both power consumption and processing density are paramount concerns. In practical smart factory applications, these vector extensions can dramatically accelerate critical operations including high-frequency sensor data analysis (such as FFT-based vibration monitoring), real-time quality assurance processes (like parallel image processing for defect identification), and digital twin synchronization tasks (including the concurrent simulation of multiple production line scenarios).
However, the full realization of these performance benefits depends on comprehensive software stack support across multiple layers, from the operating system through to the Java Virtual Machine (JVM) to big data frameworks like Apache Spark. This requirement becomes particularly acute in hybrid HPC-edge deployments, where industrial workflows must carefully balance the competing demands of low-latency edge processing and compute-intensive cloud or HPC-based simulations.
The current study addresses two fundamental research questions with significant implications for industrial IoT implementations. First, we examine the readiness of the existing big data software stack, particularly focusing on Apache Spark’s implementation in the JVM, to fully utilize SVE instructions for industrial applications. Our evaluation centers on OpenJDK version 16 and later, which introduced experimental SVE support through a dedicated JVM flag—a critical development for Java-based industrial applications (including Spark and Flink implementations) running on ARM-based edge nodes.
Second, we investigate the performance characteristics of ARM-based HPC systems when executing industrial big data workloads, comparing them to traditional cloud and data center deployments. This analysis is particularly relevant given the unique challenges posed by industrial IoT environments, including data locality considerations (contrasting HPC’s shared storage models with edge computing’s distributed data paradigms), the need to support mixed workload types (combining streaming edge operations with batch-oriented cloud/HPC processing), and stringent quality-of-service requirements (balancing latency-sensitive control loops against throughput-oriented analytical processes).
To our knowledge, this is the first detailed investigation into deploying big data frameworks like Apache Spark on ARM-based HPC systems tailored for industrial IoT scenarios. The results provide valuable guidance for improving performance and energy efficiency in edge-cloud computing infrastructures. For the EPI project team developing the Rhea-GPP processor, our findings provide crucial guidance for ensuring optimal compatibility with industrial IoT workloads. For system architects designing edge-cloud industrial deployments, we demonstrate how ARM’s energy efficiency can enable the sustainable scaling of distributed systems. Furthermore, our work informs the development of hybrid HPC-DISC architectures that combine Spark’s data parallelism with HPC’s computational density.
Our experimental methodology employs a testbed designed to emulate real-world industrial edge-HPC scenarios, where ARM-based nodes (equipped with V1 processors) represent either edge computing clusters or fog computing layers. Within this framework, we investigated SVE-enabled Spark processing for representative industrial workloads, including K-means clustering (for equipment anomaly detection) and windowed stream aggregations (for production line monitoring). The performance metrics we examined focus on three critical dimensions: vectorization efficiency (comparing SVE against scalar ARM instructions), energy consumption per operation (particularly relevant for edge deployments), and end-to-end latency (crucial for quality-of-service sensitive control applications).
The results of this evaluation provide practical guidance for multiple constituencies. Industrial system designers implementing ARM-based edge solutions will benefit from our performance benchmarks and optimization recommendations. The EPI development team can apply our findings to refine the Rhea-GPP processor for industrial IoT workloads. These results provide a foundation for refining Spark’s execution engine to better exploit ARM vector instructions, with direct relevance to performance-critical tasks in manufacturing analytics, including the stream aggregation and batch processing of telemetry data.
By systematically exploring the intersection of ARM-based HPC architectures and industrial big data processing, this work makes significant strides toward realizing the cloud–edge continuum vision that underpins modern smart factory initiatives. Our findings directly support the Industry 5.0 objectives of human-centric, sustainable production by demonstrating how advanced computing architectures can be effectively deployed in industrial environments without compromising energy efficiency or operational responsiveness. This research not only provides immediate practical benefits for system designers and developers but also establishes a foundation for future investigations into heterogeneous computing architectures for industrial applications.
4. Experimental Evaluation
We performed several extensive experiments to assess the impact of the potential issues regarding HPC systems (i.e., latency, contention, and file system’s configuration) on the performance of big data applications. We further described the experimental environment: the platform, deployment setup, and big data workloads.
4.1. Experimental Setup
4.1.1. Data Workloads
To test the impact of vectorial instructions, we use K-Means, a well-known clustering algorithm for knowledge discovery and data mining, as our benchmarking application. K-means is a computationally intensive application, and hence it is well-suited for measuring the impact of instruction vectorization. When applied to a dataset of n records of d dimensions, its computational complexity is O(ndk), assuming a bounded number of iterations. In the scope of this paper, we wanted to assess how efficiently the computation can be performed in our target environment. With this goal in mind, we ran the algorithm under different conditions to test the impact of using vector hardware instructions on key performance properties: speed-up, scale-up, and size-up. In all these cases, we fed K-means with three different kinds of synthetic input datasets. These datasets have the same size, but different internal structures. They consist of tables of a fixed number of rows and columns (dimensions), and random content. There is a specific reason behind this choice: although the algorithmic complexity of K-means remains the same, even different data formats can significantly modify the total execution time, as we will describe more extensively in the remainder of this section. We considered the following cases: (i) 10M rows of 1000 dimensions (10M1000d), (ii) 100M rows of 100 dimensions (100M100d), and (iii) 1000M rows of 10 dimensions (1000M10d). In the following section, we go into more details of how these datasets were used to measure specific properties of the computation.
4.1.2. Platform
We conducted our experiments on a small-scale HPC-like platform representative of industrial deployments, consisting of eight physical nodes hosted in our partner’s data center. Each node was equipped with two Marvell ThunderX2 processors, creating a total of 64 ARMv8-A cores per node. These processors are widely adopted in low-power data center applications and support Scalable Vector Extension (SVE) instructions, which were central to our evaluation. All nodes were provisioned with 256 GB of RAM and ran Red Hat Enterprise Linux 8. On each node, we installed OpenJDK 16, which can compile bytecode to optimal vector hardware instructions on our CPU architecture, thus achieving superior performance compared to equivalent scalar computations. Finally, we used the Hi-Bench benchmark suite for big data applications to generate synthetic datasets and run standardized and easily reproducible experiments. Although our setup does not qualify as a full-scale supercomputing environment, our objective was to replicate HPC workloads using industrial-grade infrastructure and widely adopted big data frameworks to evaluate the feasibility of ARM-based solutions outside of traditional HPC facilities.
4.1.3. Spark Deployment
The software stack posed several integration challenges due to the limited maturity of support for ARM-specific optimizations in big data tools. In particular, we identified OpenJDK 16 as the only version providing runtime support for SVEs via a dedicated compilation flag. However, this constrained our Spark deployment to version 3.0.2, as earlier Spark versions are incompatible with the Java reflection model introduced in newer JVM releases. These constraints are discussed in detail in
Section 5. Spark was deployed with configurations adapted from best practices in the literature [
19], with each physical processor running four Spark workers, each assigned eight cores and 32 GB RAM. For reproducibility, we report a summary of these deployment parameters in
Table 1.
4.1.4. K-Means Parameters
We set the K-means degree of parallelism to one task per core. If not otherwise specified, we configured the K-means algorithm to run for exactly 10 iterations to make results significant and enable meaningful comparisons among them, and the number of generated clusters was set to 100.
The degree of parallelism, which is roughly a number of computing nodes or threads concurrently running in HPC or cluster deployments, is normally utilized to evaluate the performance of the parallelization technique employed [
20].
4.2. Experimental Results
In this section, we provide a deep analysis of the experimental results that we have obtained, underlining the performance bottlenecks of deploying distributed big data processing systems on HPC systems. Overall, we aim to demonstrate that the EPI architecture is able to perform like the current state-of-the art processor architectures.
4.2.1. Varying the Number of Processing Nodes
We assessed the impact of varying the number of processing nodes on the overall time-based performance of the big data processing system (Spark) deployed on the HPC. Sometimes, this impact is referred to as the speed up of the algorithm. Specifically, we varied the number of nodes that execute the K-means workloads from one to eight. We ran experiments for the three different datasets.
Figure 3 plots the results using different colors to highlight the different dataset compositions. The first observation is that the processing cost significantly differs in the three cases. This effect is expected and is consistent with the existing literature. In particular, the highest number of dimensions (1000) corresponds to the best performance, but also to the lower speedup, due to an increased data shuffling overhead. In the other case, the shuffling cost is reduced, and this leads to a better speedup. In turn, however, the overall cost of the computation is increased, because larger datasets with smaller records induce a higher computational load on the system. To substantiate this claim with a quantitative performance evaluation, we included a heatmap (
Figure 4) showing CPU utilization across a subset of cores during a representative execution window. This visualization highlights the distribution of workload among Spark workers and supports the analysis of resource usage during this variant of the K-means execution.
4.2.2. Varying the Number of Processing Nodes and the Size of the Datasets
The second metric we considered in our evaluation was the scale-up, sometimes also called scaled speedup. This metric represents how large a problem can be solved in the same amount of time by a larger number of parallel processes. Hence, in this case, we considered the same three reference datasets, but as we increased the number of machines that execute the algorithm in parallel, we also increased the size of the datasets. Specifically, we considered a half-sized version of the reference datasets when using one node, the reference datasets when using two nodes, and a double-sized version of the reference datasets when using eight nodes.
Figure 5 shows the results. We observe that the best behavior, i.e., the most linear, is reported for the datasets with the least number of rows. In line with the results of the previous experiment, the reason can be attributed to the less demanding load of the system when dealing with smaller records.
4.2.3. Varying the Number of Processing Nodes with Constant Per-Node Workload
The third metric we considered, the size up, offers another perspective on the scalability of the algorithm execution. We kept constant the amount of work each node had to perform, but gradually increased the number of nodes executing the algorithm in parallel. This way, as the degree of parallelism increased, it also increased the total amount of work the system had to execute. This experiment can give us a useful insight into the efficiency of the algorithm execution settings, which in our case, also included the effectiveness of using vector hardware instructions.
Figure 6 plots the results. We used the same reference datasets used for the previous experiment, with the further differentiation in three sizes introduced in the previous paragraph. The dashed lines in the picture represent the average execution time with two nodes, and the solid lines with four nodes. We observe that the performance trend is comparable with the results in both the previous paragraphs.
However, there is a significant difference between the three datasets: in line with the results of
Figure 3, the dataset with the highest number of dimensions (red lines) is the fastest under any conditions, yet it is the hardest to scale-up linearly. Again, the reason is to be attributed to the higher communication overhead, as explained above. On the other hand, the dataset with the largest number of rows (green line) is not only the slowest, but also the hardest to scale. This is not a surprising result: as we previously commented, a larger number with smaller records puts the system under a higher load. When we increase the size of such dataset, the system load increases more than linearly and consequently the total execution time also increases.
5. Results, Discussion, and Implications
This section recapitulates the results obtained in our extensive evaluation and reports our experience with the configuration of our testbed and of the Spark platform.
As we previously commented, the execution of typical big data processing workloads on our testbed yielded consistently good performance across the evaluated scenarios. The detailed analysis presented in
Section 4 highlights how the HPC-like ARM-based testbed influences the runtime behavior of Spark. As expected, the most critical performance bottleneck lies in the data shuffling phase, during which intermediate data must be exchanged among Spark workers. Our results demonstrate that the configuration of the input dataset significantly affects this phase. Specifically, datasets with fewer rows and more columns result in better performance compared to those with many rows and few columns. This is because Spark typically partitions data by rows; reducing the number of partitions (i.e., rows) lowers the volume of data transferred across the network during shuffle-intensive stages. The experiment in
Section 4.2 further examines the impact of enabling Scalable Vector Extension (SVE) instructions on performance. We observed that vectorization is particularly effective when the degree of application-level parallelism is high, confirming the relevance of these features in compute-bound workloads. However, these optimizations must be supported by the software stack and properly exposed through the runtime environment. Our findings suggest that, in addition to selecting hardware configurations carefully, users must also pay close attention to software compatibility and workload characteristics. The choice of the JVM version, Spark release, and associated frameworks must be aligned with the hardware features to fully exploit their capabilities. Moreover, Spark parameters, such as the number of partitions, executor resources, and shuffle settings, should be tuned according to the size and shape of the input data. These aspects remain critical for ARM architectures as well, and failure to adapt the platform configuration accordingly can lead to suboptimal results, despite the underlying hardware’s capabilities.
Despite the representativeness of our testbed for industrial HPC environments and the breadth of the conducted evaluation, our study has some limitations. In particular, the use of synthetic benchmarks rather than actual industrial datasets may not capture all the complexities of real-world workloads. Incorporating domain-specific applications and data from operational environments would provide a more comprehensive assessment and strengthen the applicability of our findings to production settings.
Overall, we conclude that the results we obtained show promising performance and follow a trend that emphasizes the scalability of the Spark platform, even on the HPC platform we used, despite it being based on ARM processors. This demonstrates that the new generation of ARM chips we used is a promising template for the incumbent development of the new European processors, which is the goal of the EPI project. We want to emphasize the relevance of the adoption of vectorial instructions to achieve these results, and we recommend their adoption in the future Rhea-GPP processor.
In
Section 3, we stressed that SVE instructions can be effective only if there is adequate support in the software stack between the processor and the running application. In this paper, we were able to identify OpenJDK 16 as the main tool offering such support, as it provides a specific runtime flag to optimize the machine code for SVE on ARM processors. However, we found that the degree of maturity of such a solution still requires improvement in terms of integration with the existing platforms and tools belonging to the big data processing ecosystem. For example, in OpenJDK 16 (and newer editions) we could only run Spark 3.0 (or newer editions), whereas previous releases were not compatible with the newer versions of Java because of the new approach to reflection features in programming on which previous releases were based. This constraint forced us to use the HiBench evaluation framework (see
Section 4.1), which supports Spark 3.0, but precluded the use of other similar frameworks for comparison (e.g., Spark-Bench). These compatibility issues are not well documented and could prevent unexperienced users from successfully deploying a platform like our testbed. For instance, the flag to enable SVE code optimization is hidden among many others and is not associated with a user-friendly description of its capabilities and, even more importantly, of the limitations we experienced during the setup phase of our platform. It should be noted that due to the early-stage nature of SVE support in the JVM ecosystem at the time of experimentation, low-level verification (e.g., JIT logs, perf counters, or disassembly inspection) was not performed to confirm the emission of SVE instructions. Such verification would have provided deeper insight into the effectiveness of vectorization in our Spark workloads. This remains an important direction for future work as tooling matures and becomes more accessible within the ARM software development ecosystem.
As a result, we expect that in the next few years, the advantages brought by the adoption of ARM-based processors even in HPC environments (and above all, reduced resource consumption) will foster an effort of better support and the documentation of these new features with the well-consolidated software stack of big data platforms. Such an effort would not only benefit users and developers on currently existing platforms, but in the EPI perspective of a new European processor, will lead all the involved stakeholders to integrate such novel initiatives within a community-supported, well-integrated environment.
6. The Related Literature
Much research has been conducted to measure big data analytics frameworks performance on HPC systems.
The authors of [
20] designed a scalable computing resources system for big data storage, processing, and visualization, specifically for remote sensing (RS) applications. It emphasizes the use of Apache Spark, deployed on ARM-based High-Performance Computing (HPC) systems, to enhance the performance of data-intensive tasks. The framework utilizes Kubernetes (K8s) for container orchestration and HDFS for efficient data storage, enabling high-speed read throughput that is crucial for handling large RS datasets.
In the realm of distributed computing, serverless architectures like Lithops present a compelling approach to simplify application deployment and scaling by abstracting server management from developers. The Function-as-a-Service (FaaS) model, central to serverless computing, allows for the automatic scaling of discrete functions in response to demand, with Lithops enabling the execution of Python code across thousands of cloud cores without altering local scripts. While Lithops has primarily been utilized in cloud environments for big data processing, its potential in High-Performance Computing (HPC) systems remains largely unexplored until recently. A novel architecture has now been proposed to deploy Lithops on HPC systems, such as the MareNostrum 5 supercomputer, leveraging its computational power and the FaaS model to achieve high performance and scalability while reducing CPU wastage. The integration of serverless computing with HPC systems reflects an emerging trend that could influence how big data frameworks are deployed and optimized, particularly in ARM-based environments targeting industrial and edge computing scenarios [
21].
Ref. [
22] evaluated MapReduce applications on scale-up and scale-out clusters and proposed a hybrid scale-up/out Hadoop architecture based on the results. Other studies have focused on improving communication between compute nodes (horizontal data movement), and researchers have utilized RDMA-based mechanisms [
23,
24,
25]. It is only during the concluding part of the transfer, when data is held in memory, that these optimized RDMA techniques offer their greatest benefit value. Even though data residence is not assured, requests tend to be serviced using a client–server programming model. Performance can be optimized through multiple strategies, such as using a bounded thread pool SEDA-based approach to avoid overtaxing computing resources or having one server thread per connection, given a sufficient number of cores is available [
26]. On the other hand, for the optimization of vertical data movement, one of the main reasons for the emergence of Spark, researchers have investigated file consolidation optimization and optimizations intended to keep objects in memory when possible [
27]. Our research aims to measure the suitability of the Rhea-GPP processor for efficient big data workflows that match the performance of existing HPC systems. We aimed to evaluate the software stack necessary for running big data workloads, particularly those based on Apache Spark, and their complexity. Additionally, we aimed to examine big data processing performance on ARM processors in an HPC environment, particularly the degree of vectorial instruction supports in the software stack and the performance of the software stack given the inclusion of JVM support for SVE instructions. Lastly, we compared HPC environments to standard data center computations with regards to data storage and movement.
Several research efforts have been dedicated to measuring big data analytics frameworks performance on HPC systems, as highlighted previously. However, with the rise of Industry 4.0 and the increasing integration of cloud and edge computing in the industrial IoT (IIoT), it is becoming essential to consider the latest advancements in these research areas. In what follows, we provide an updated and expanded literature review to accommodate these emerging trends and their relevance to our work on the use of Apache Spark in ARM-based HPC systems, with a focus on how those trends influence the performance and optimization of big data processing on such architectures.
6.1. Industrial Cloud Continuum and IIoT Platforms: Implications for HPC-Based Big Data Processing
The industrial cloud continuum, which integrates cloud and edge resources, is becoming common as a foundational element of Industry 4.0. It is an integration that is considered a pillar for Industry 4.0 applications, forming a basis for a necessary change in the traditional organizational model for factories operation. This paradigm requires an emergent re-evaluation of how big data processing frameworks are deployed and optimized for applications in Industry 4.0, mainly on HPC systems in this context. Efficient data processing needs for Industry 4.0 applications are necessary, a fact that is amplified by the huge volumes of real-time data served by industrial systems in Industry 4.0 applications [
28]. This fact has a direct relationship with our work, attributed basically to the fact that the ability of Apache Spark to handle these avalanches of data on ARM-based HPC systems becomes extremely important.
The deployment of Apache Spark in ARM-based HPC systems must consider the data locality and I/O challenges that are determining factors in HPC architectures, as we have highlighted in the introduction. The integration of big data analytics, Internet of Things (IoT), Artificial Intelligence (AI), and cyber–physical systems is dramatically changing the way in which manufacturing and industrial processes operate, thus making efficient big data processing over those settings a critical challenge [
19]. This transformation highlights the requirement for HPC systems to efficiently adapt to data-intensive workloads, and our research presented in this paper aims at characterizing the performance of Apache Spark in this context.
Several relevant studies on the current state-of-the-art focus on the development and deployment of Industrial Internet of Things (IIoT) platforms to support this kind of integration. For example, Brightics-IoT aims at providing an efficient IIoT platform for the benefit of connected smart factories, thus enabling intelligent operations through the integration advanced device management and data analytics [
29]. The study introduced a platform that aims at addressing the technical challenges of gathering real-time data in manufacturing facilities and implementing features for intelligent services in smart manufacturing [
29]. This is specifically very relevant to our work, which we present in this paper, because the performance of these IIoT platforms depends heavily on the ability of the underlying infrastructure in terms of processing data efficiently. Our research on Apache Spark on ARM-based HPC systems can efficiently inform the design and optimization decisions of similar platforms.
The Helix multi-layered platform establishes an IIoT-to-cloud continuum by distributing federated brokers across the infrastructure, providing scalability and interoperability [
30]. This platform was tested in real-world deployments, demonstrating its suitability as a backend for IIoT applications [
30]. Such a platform demonstrates the necessity of scalable and interoperable big data processing solutions for IIOT application scenarios, an aim that our research aimed at addressing, basically by evaluating Apache Spark on ARM-based HPC systems in this context.
6.2. Communication of 5G and 6G for Industrial Deployment: Impact on Data Processing Requirements
The introduction of 5G and the upcoming emergence of 6G networking communication technologies is anticipated to revolutionize industrial deployments, attributed to their capabilities in providing the necessary connectivity for massive machine-type communication and ultra-reliable low-latency communication (URLLC) [
31]. These advancements can easily enable the real-time control of manufacturing processes by real-time data processing [
31]. The unprecedented increase in networking connectivity and data arrival rates adds challenging demands on underlying data processing infrastructures. This is very relevant to our work, because the performance of Apache Spark on ARM-based HPC systems has a clear and direct impact on the ability to leverage the benefits of 5G/6G networking technologies in industrial settings.
The integration of dynamic reconfigurable antennas is also being considered for enhancing reliability and seamless connectivity in Industry 4.0 application scenarios, particularly in Industrial IoT and smart manufacturing scenarios. Such antennas basically leverage electrical components and AI/ML-based agile beam-scanning techniques. The advanced and improved connectivity provided by such technologies is set to generate data on a rate that is unprecedented, a fact that further emphasizes the need for efficient big data processing solutions, like the deployment of Apache Spark big data processing systems on HPC-enabled deployments [
32].
Furthermore, a flexible hyper-distributed IoTEdgeCloud computing platform, incorporated with a private 5G network, can support real-time digital twins in logistics handling and industrial environments [
33]. This platform enhances the constrained capabilities of IoT devices with additional cloud and edge computing functionalities, thus creating an IoT–edge–cloud continuum [
33]. Performance evaluations on real data have shown the ability of the platform in supporting the high-throughput communications required for digital twins scenarios [
33]. Such a platform is an excellent example that demonstrates the convergence of multiple technologies, and our research on Apache Spark can contribute to optimizing the data processing component of such integrated systems.
Also, the introduction of 5G-enabled networks is also driving exploration and innovation in IIoT, particularly in relation to cybersecurity [
34]. The increased attack surface associated with 5G-connected IIoT devices requires robust security information and event management (SIEM) systems, which directly depend on efficient big data processing for detecting and responding to cybersecurity threats. Our work with Apache Spark is set to potentially contribute to the development of high-performance SIEM solutions for IIoT environments.
6.3. Computing Continuum for Smart Factory Services: Optimizing Data Placement and Processing
The computing continuum, which encompasses edge, cloud, and IoT devices, is becoming necessary for delivering smart factory services. The cloud–edge–IoT (CEI) continuum fuses edge computing, cloud computing, and the Internet of Things (IoT), thus fostering rapid Industrial Internet of Things (IIoT) development [
35]. In a related context, it is highly important to address challenges, such as robustness issues, communication-induced latency, and inconsistent model convergence, in order to realize the potential of the CEI continuum [
35]. Our research can potentially guide the decisions on optimizing data placement and processing across the CEI continuum by leveraging Apache Spark on ARM-based HPC systems at the edge or in the cloud.
There are existing works in the recent state-of-the-art on emerging topics such as Hierarchical Federated Learning (HFL) and Spiking Neural Networks (SNNs), aiming at building scalable and energy-efficient solutions for the industrial CEI continuum, such as the work that appears in [
35]. These advanced ML techniques consume significant computational resources, and our research can potentially help determine the suitability of ARM-based HPC systems for these workloads.
Edge computing, as a complimentary deployment of the cloud, enables the execution of typical cloud computing loads in proximity to industrial processes [
36]. This paradigm supports heterogeneous hardware and run-time platforms, thus focusing on the service layer to enable the flexible orchestration of data flows and dynamic service compositions [
36]. The ability to run Apache Spark on ARM-based HPC systems at the edge can enable real-time data processing and decision-making, thus reducing latency and improving responsiveness.
An embedded smart sensor network architecture based on edge computing can also significantly reduce data processing delays and energy consumption, in addition to providing guarantees for data security [
37]. This underpins the importance of energy-efficient computing solutions, and our research can contribute to evaluating the energy efficiency of ARM-based HPC systems for big data processing.
6.4. Digital Twins for Industrial Process or Product Monitoring: Leveraging HPC for Complex Simulations
Digital twins (DTs) are important for representing our physical world digitally, thus helping to evaluate, optimize, and predict behaviors in industrial processes [
38]. DTs enhance production automation through digitization, the integration of IoT sensors, and high-capacity cloud/edge computing infrastructure [
38]. Building and maintaining DTs typically require complex data analytics and simulations, which normally can benefit from the computational power of HPC system deployments. Therefore, our research on the use of Apache Spark in ARM-based HPC systems can potentially contribute to the creation of more enhanced and accurate DTs.
An automated systematic test architecture correlates DTs states with real-time sensor data from the forging industry, aiming at accelerating the automatic testing process and its reliability [
38]. This highlights the need for real-time data processing capabilities, which our research aims to evaluate in the context of Apache Spark on ARM-based HPC systems.
As an example in the related state-of-the-art, a project known as IoTwins aimed to investigate the opportunities and challenges of leveraging DTs in industrial manufacturing and facility management [
39]. Researchers introduced a DT reference architecture to realize platform deployment and development in a cloud setting [
39]. This project highlights the significance of adapting reference architectures and methodologies for DT implementation, and our research can inform the design of such architectures by providing performance data on the use of Apache Spark in ARM-based HPC systems.
In the same vein, a project called as digital twin bionics (DTBs) was designed by combining bionics and DTs, aiming at addressing the challenges of information islands and integrating life cycle processes [
40]. The same study focused on integrating industrial processes using a symbiotic mechanism, enriched by supporting technologies such as the industrial IoT, cloud–edge computing, big data, and AI. This unified approach requires effective simulation and data processing capabilities, and our research can contribute to evaluating the suitability of ARM-based HPC systems for such tasks.
6.5. Edge Data Center Deployment in Industrial Environments: Enabling Low-Latency Analytics
Edge data centers are crucial for providing low-latency and real-time processing capabilities in industrial environments. Edge computing addresses the drawbacks of traditional centralized systems by moving data processing resources closer to data sources [
41]. This paradigm shift makes real-time processing possible, thus facilitating the exponential growth of IoT devices that produce voluminous data at the network edge. The ability to deploy Apache Spark on ARM-based HPC systems in edge data centers can enable real-time analytics and decision-making, aiming at reducing latency and improving responsiveness in industrial applications.
Edge computing deployments dramatically reduce latency, optimize network bandwidth, and increase resource efficiency via complex horizontal and vertical scaling mechanisms [
41]. Our research can contribute to an understanding of how to effectively scale Apache Spark on ARM-based HPC systems in edge environments to meet the pressing demands of industrial workloads.
An improved edge model incorporates Artificial Intelligence along with the integration of caching to handle big data flow in IoT applications, thus minimizing delay compared to conventional cloud-only computing models [
42]. This underpins the importance of AI-enabled edge computing solutions, and our research can help evaluate the performance of Apache Spark in combination with AI workloads on ARM-based HPC systems.
6.6. ML- and AI-Based Approaches to Cloud/Edge-Based Smart Factory Applications: HPC as an Accelerator
Machine learning (ML) and Artificial Intelligence (AI) are pivotal for enabling intelligent applications in cloud–edge-based smart factories. AI-driven technologies transform conventional manufacturing processes through improved data analytics, ML algorithms, and IoT integration [
42]. These technologies improve decision-making capabilities, enhance product quality, and simplify production workflows in manufacturing environments. HPC systems speedup AI/ML workloads, and our research can help determine the effectiveness of ARM-based HPC systems for this purpose.
AI is pivotal for managing the complexities in modern manufacturing, including machine failures, variable orders, and unpredictable work arrivals [
43]. AI technologies have the potential to reduce the costs of industrial production, in addition to an increased efficiency in energy consumption in such an industrially complex world, and furthermore enhanced scheduling in practical IIoT applications. Leveraging AI solutions to optimize manufacturing processes heavily relies on efficient data processing and ML/AI model training, which can potentially benefit from the computational power of HPC systems.
A novel Explainable AI (XAI) platform builds “glass box” AI models that are explainable to a “human-in-the-loop” without decreasing AI performance [
44]. The platform consists of a catalogue of hybrid and graph AI models that are built, fine-tuned, and validated to solve concrete manufacturing problems. The training and validation of these AI models require significant computational resources, and our research can help evaluate the suitability of ARM-based HPC systems for these tasks.
6.7. Blockchain Solutions for Secure and Reliable Transactions: HPC for Blockchain Infrastructure
Blockchain technology offers a decentralized approach that helps in ensuring secure and reliable transactions between counterparts in data sharing and trading within industrial environments. A blockchain-based decentralized model for IIoT (DMIIoT) uses a secure Peer-to-Peer (P2P) network, where each node interacts with other nodes, improving production visibility and the quality of service (QoS) [
45]. The computational demands of blockchain infrastructure, especially for transaction validation and block creation, can potentially be offloaded to HPC systems.
Blockchain can also provide data integrity, exchange reliability, provenance, and trustworthiness for overall activities and service delivery prospects in Industry 5.0 [
46]. The security and reliability benefits of blockchain are particularly relevant in industrial settings, where data integrity and trust are prevalent.
A DL-Integrated Blockchain Framework secures IIoT networks using a private blockchain-based secure communication among the IIoT entities, with a session-based mutual authentication and key agreement mechanism [
47]. The authors rely on a Proof-of-Authority (PoA) consensus mechanism for verifying transactions and the creation of blocks based on miner’s voting on a cloud server. This framework shows the synergy of adapting multiple technologies, and our research can potentially contribute to optimizing the performance of the blockchain component by leveraging Apache Spark on ARM-based HPC systems.
It is now becoming common to leverage blockchain in blockchain-enabled DT collaboration, aiming at enhancing distributed IIoT manufacturing, providing up-to-date data representation of operational physical assets and therefore supporting decision-making making processes in complex IIoT scenarios [
48]. This unified method requires sophisticated data processing and secure transaction skills, and our research can contribute to evaluating the suitability of ARM-based HPC systems for these tasks.
6.8. Zero Waste/Defect Manufacturing and Green Manufacturing in Industry 5.0 Deployment: Data-Driven Optimization
Adopting zero waste/defect manufacturing and green manufacturing practices in Industry 5.0 settings is typically fueled by the common interest in sustainability practices and resource consumption efficiency. Big data analytics is very helpful in this context, as for example, it typically facilitates predictive maintenance in industrial IoT operations, in addition to its potential in optimizing industrial production processes, and its capacity in enabling systems real-time monitoring, thus allowing for more precise forecasting, reduced industrial processes downtime, and subsequentially enhanced resource management [
49]. Our research on Apache Spark on ARM-based HPC systems can contribute to enabling these data-driven optimization strategies by providing a high-performance platform for analyzing manufacturing data.
Recent studies have demonstrated the effectiveness of Apache Spark Streaming in handling real-time geospatial and mobility analytics, such as estimating vehicle speeds across metropolitan areas using dynamic sensor data [
50]. This work highlights Spark’s versatility beyond traditional batch processing and reinforces its role as a key platform for real-time decision-making in IoT-driven environments. As shown in this study, Spark’s ability to process high-throughput, low-latency data streams align well with the requirements of modern industrial IoT applications, including smart logistics, predictive maintenance, and location-based monitoring.
In the same vein, recent research has also explored the application of Apache Spark in approximate analytics of geospatial big data streams under quality-of-service constraints [
51]. The study introduces ApproxGeoMap, a framework that enables the efficient sampling and summarization of dynamic georeferenced data from urban mobility sensors. This approach demonstrates Spark’s applicability not only in exact batch processing but also in approximate stream analytics, which is particularly valuable in industrial IoT environments where timely insights often outweigh the need for absolute precision.
The increasing need for economic, safe, and sustainable smart manufacturing has paved the way for AI and big data in industries [
52]. This implies the substantial integration of AI, Industrial IIoT, Robotics, big data, blockchain, and 5G communications in support of smart manufacturing and the dynamical processes of modern industries. This integrated vision requires efficient data processing and analysis capabilities, and our research can contribute to evaluating the suitability of ARM-based HPC systems for these tasks.
6.9. Addressing the Gap: ARM-Based HPC for Big Data in Industrial IoT
The current state-of-the-art has attempted to test and characterize the performance of deploying and running parallel big data processing software stacks (such as those based on Apache Spark) over HPC hardware. However, none of these works have studied the performance of running parallel data processing software stack atop an HPC environment utilizing ARM architectures with vectorial instructions. To close this gap, this paper aims to answer two main research questions. The first research question is related to characterizing the degree of the availability of sufficient support for the use of vectorial instructions (known as Scalable Vector Extensions, SVEs for short) in the current big data processing software stack. The second research question that we addressed in this paper is related to the performance of big data processing software stacks (specifically in-memory systems such as Apache Spark) over ARM-based HPC architectures utilizing SVE instructions.
Our work directly addressed this gap by providing a first-in-class extensive performance evaluation of an ARM-based HPC deployment that leverages JVM SVE support. This evaluation will serve as a valuable testing reference for the community and will provide valuable configuration guidelines.
6.10. Relevance of Our Work: Enabling Data-Driven Innovation in Industry 4.0 and 5.0
The current trends in industrial cloud complex applications, 5G/6G communication technologies, DTs, edge big data centers, in addition to advanced AI/ML-based methods, blockchain secure solutions for advanced industrial operations, and green manufacturing, are just few examples that fueled our interest of Apache Spark on ARM-based HPC systems. This paper evaluated the performance of Apache Spark on ARM-based HPC systems equipped with Scalable Vector Extensions (SVEs), contributing to a deeper understanding of their effectiveness in handling large-scale data workloads typical of modern industrial IoT environments. Our findings can potentially guide the development of optimized configurations and deployment strategies for IIoT application scenarios that leverage ARM-based HPC systems in various Industry 4.0 and 5.0 complex applications.
The literature review we provided here highlights the current related research landscape and positions our research within the context of emerging trends on integrating IIoT and cloud/edge computing. Our work, presented in this paper, can significantly contribute to the realization of data-driven solutions in manufacturing and complex industrial sectors.
7. Conclusions and Future Directions
The integration of High-Performance Computing (HPC) with big data processing presents transformative opportunities for modern industrial IoT (IIoT) environments, where real-time analytics, scalability, and energy efficiency are paramount. This study investigated the performance of Apache Spark on ARM-based HPC systems, particularly those utilizing Scalable Vector Extensions (SVEs), to evaluate their efficacy in handling industrial-scale big data workloads within cloud–edge computing architectures. Our experiments demonstrated that ARM-based processors, such as the Rhea-GPP prototype under the European Processor Initiative (EPI), can deliver competitive performance for distributed data processing. The adoption of vectorial instructions (SVEs) significantly enhanced parallel task execution, underscoring their potential to accelerate in-memory frameworks like Spark in industrial settings. However, we identified challenges in toolchain integration and platform support, which must be addressed to fully realize these benefits.
These findings have critical implications for industrial IoT and edge computing. First, ARM-based architectures, with their energy-efficient design, are well-suited for edge deployments in smart factories, where minimizing power consumption while maintaining low-latency processing is essential. Second, the scalability of Spark on ARM-based HPC systems suggests promising applications in real-time industrial analytics, such as digital twin simulations, AI-driven predictive maintenance, and dynamic process monitoring. Third, our results align with the vision of a seamless cloud–edge continuum, where HPC-enhanced edge nodes collaborate with centralized cloud systems to optimize Industry 4.0 and 5.0 workloads.
Future research should prioritize optimizing SVE support in big data frameworks like Spark to streamline industrial adoption. Further investigations into ARM-based HPC systems could explore their performance in specific IIoT use cases, such as real-time anomaly detection or large-scale sensor data fusion. Additionally, the interplay between 5G/6G networks and edge-tier HPC deployments warrants exploration to enable ultra-low-latency data exchange in smart manufacturing. By advancing ARM-based HPC solutions, this work contributes to the broader goals of industrial digitalization, sustainable computing, and European technological sovereignty. Collaborative efforts across academia and industry will be vital to refine these technologies for next-generation smart factories and beyond. We also recognize that further investigation, particularly through low-level profiling tools such as JIT logs and perf counters, is needed to validate the extent of SVE instruction usage and optimize runtime performance in future deployments.
Author Contributions
Conceptualization, L.R., I.M.A.J., and R.V.; methodology, L.R., R.V., and I.M.A.J.; software, L.R.; validation, L.R., I.M.A.J., and R.V.; formal analysis, R.V., I.M.A.J., and L.R.; investigation, R.V., I.M.A.J., and L.R.; resources, P.B. and L.F.; data curation, R.V., I.M.A.J., and L.R.; writing—original draft preparation, R.V., I.M.A.J., L.F., L.R., and P.B.; writing—review and editing, R.V., I.M.A.J., L.F., L.R., and P.B.; visualization, R.V. and L.R.; supervision, P.B., L.F., R.V., and I.M.A.J.; project administration, R.V., L.F., and P.B.; funding acquisition, P.B. All authors have read and agreed to the published version of the manuscript.
Funding
SoBigData.it receives funding from European Union–NextGenerationEU–National Recovery and Resilience Plan (Piano Nazionale di Ripresa e Resilienza, PNRR)–Project: “SoBigData.it–Strengthening the Italian RI for Social Mining and Big Data Analytics”–Prot. IR0000013–Avviso n. 3264 del 28/12/2021.
Data Availability Statement
Dataset available on request from the authors.
Conflicts of Interest
The authors declare no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
References
- Gorton, I.; Gracio, D.K. Data-Intensive Computing: Architectures, Algorithms, and Applications; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Al Jawarneh, I.M.; Foschini, L.; Bellavista, P. Efficient Integration of Heterogeneous Mobility-Pollution Big Data for Joint Analytics at Scale with QoS Guarantees. Future Internet 2023, 15, 263. [Google Scholar] [CrossRef]
- Al Jawarneh, I.M.; Bellavista, P.; Corradi, A.; Foschini, L.; Montanari, R. QoS-Aware Approximate Query Processing for Smart Cities Spatial Data Streams. Sensors 2021, 21, 4160. [Google Scholar] [CrossRef] [PubMed]
- Shvachko, K.; Kuang, H.; Radia, S.; Chansler, R. The hadoop distributed file system. In Proceedings of the 2010 IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST), Incline Village, NV, USA, 3–7 May 2010; pp. 1–10. [Google Scholar]
- Zaharia, M.; Chowdhury, M.; Franklin, M.J.; Shenker, S.; Stoica, I. Spark: Cluster computing with working sets. HotCloud 2010, 10, 95. [Google Scholar]
- Chaimov, N.; Malony, A.; Canon, S.; Iancu, C.; Ibrahim, K.Z.; Srinivasan, J. Scaling spark on hpc systems. In Proceedings of the 25th ACM International Symposium on High-Performance Parallel and Distributed Computing, Kyoto, Japan, 31 May–4 June 2016; pp. 97–110. [Google Scholar]
- Wang, Y.; Goldstone, R.; Yu, W.; Wang, T. Characterization and optimization of memory-resident MapReduce on HPC systems. In Proceedings of the 2014 IEEE 28th International Parallel and Distributed Processing Symposium, Phoenix, AZ, USA, 19–23 May 2014; pp. 799–808. [Google Scholar]
- Yildiz, O.; Zhou, A.C.; Ibrahim, S. Eley: On the effectiveness of burst buffers for big data processing in HPC systems. In Proceedings of the 2017 IEEE International Conference on Cluster Computing (CLUSTER), Honolulu, HI, USA, 5–8 September 2017; pp. 87–91. [Google Scholar]
- Zaharia, M.; Xin, R.S.; Wendell, P.; Das, T.; Armbrust, M.; Dave, A.; Meng, X.; Rosen, J.; Venkataraman, S.; Franklin, M.J. Apache spark: A unified engine for big data processing. Commun. ACM 2016, 59, 56–65. [Google Scholar] [CrossRef]
- Bux, M.; Leser, U. Parallelization in scientific workflow management systems. arXiv 2013, arXiv:1303.7195. [Google Scholar]
- Asch, M.; Moore, T.; Badia, R.; Beck, M.; Beckman, P.; Bidot, T.; Bodin, F.; Cappello, F.; Choudhary, A.; De Supinski, B. Big data and extreme-scale computing: Pathways to convergence-toward a shaping strategy for a future software and data ecosystem for scientific inquiry. Int. J. High Perform. Comput. Appl. 2018, 32, 435–479. [Google Scholar] [CrossRef]
- Laroui, M.; Nour, B.; Moungla, H.; Cherif, M.A.; Afifi, H.; Guizani, M. Edge and fog computing for IoT: A survey on current research activities & future directions. Comput. Commun. 2021, 180, 210–231. [Google Scholar]
- Tynchenko, V.V.; Tynchenko, V.S.; Nelyub, V.A.; Bukhtoyarov, V.V.; Borodulin, A.S.; Kurashkin, S.O.; Gantimurov, A.P.; Kukartsev, V.V. Mathematical models for the design of GRID systems to solve resource-intensive problems. Mathematics 2024, 12, 276. [Google Scholar] [CrossRef]
- Dean, J.; Ghemawat, S. MapReduce: Simplified data processing on large clusters. Commun. ACM 2008, 51, 107–113. [Google Scholar] [CrossRef]
- Zaharia, M.; Das, T.; Li, H.; Hunter, T.; Shenker, S.; Stoica, I. Discretized streams: Fault-tolerant streaming computation at scale. In Proceedings of the Twenty-Fourth ACM Symposium on Operating Systems Principles, Farminton, PA, USA, 3–6 November 2013; pp. 423–438. [Google Scholar]
- Armbrust, M.; Das, T.; Torres, J.; Yavuz, B.; Zhu, S.; Xin, R.; Ghodsi, A.; Stoica, I.; Zaharia, M. Structured Streaming: A Declarative API for Real-Time Applications in Apache Spark. In Proceedings of the 2018 International Conference on Management of Data, Houston, TX, USA, 10–15 June 2018; pp. 601–613. [Google Scholar]
- Karau, H.; Warren, R. High Performance Spark: Best Practices for Scaling and Optimizing Apache Spark; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2017. [Google Scholar]
- Al Jawarneh, I.M.; Bellavista, P.; Corradi, A.; Foschini, L.; Montanari, R. SpatialSSJP: QoS-Aware Adaptive Approximate Stream-Static Spatial Join Processor. IEEE Trans. Parallel Distrib. Syst. 2023, 35, 73–88. [Google Scholar] [CrossRef]
- Janík, S.; Szabó, P.; Mĺkva, M.; Mareček-Kolibiský, M. Effective data utilization in the context of industry 4.0 technology integration. Appl. Sci. 2022, 12, 10517. [Google Scholar] [CrossRef]
- Guo, J.; Huang, C.; Hou, J. A scalable computing resources system for remote sensing big data processing using geopyspark based on spark on k8s. Remote Sens. 2022, 14, 521. [Google Scholar] [CrossRef]
- Arevalo, A.B.; Tejeda, D.C.; Call, A.; López, P.G.; Castell, R.N. Enhancing HPC with Serverless Computing: Lithops on MareNostrum5. In Proceedings of the 2024 IEEE 32nd International Conference on Network Protocols (ICNP), Charleroi, Belgium, 28–31 October 2024; pp. 1–6. [Google Scholar]
- Gu, R.; Huang, X.; Dai, H.; Geng, X.; Chen, X.; Huang, Y.; Xiao, F.; Chen, G. Efficient. scalable and robust data shuffle service for distributed MapReduce computing on cloud. In Proceedings of the 2022 IEEE 24th Int Conf on High Performance Computing & Communications; 8th Int Conf on Data Science & Systems; 20th Int Conf on Smart City; 8th Int Conf on Dependability in Sensor, Cloud & Big Data Systems & Application (HPCC/DSS/SmartCity/DependSys), Hainan, China, 18–20 December 2022; pp. 337–346. [Google Scholar]
- Yuan, Y.; Huang, J.; Sun, Y.; Wang, T.; Nelson, J.; Ports, D.R.; Wang, Y.; Wang, R.; Tai, C.; Kim, N.S. Rambda: Rdma-driven acceleration framework for memory-intensive µs-scale datacenter applications. In Proceedings of the 2023 IEEE International Symposium on High-Performance Computer Architecture (HPCA), Montreal, QC, Canada, 25 February–1 March 2023; pp. 499–515. [Google Scholar]
- Xiao, M.; Wang, H.; Geng, L.; Lee, R.; Zhang, X. An RDMA-enabled In-memory Computing Platform for R-tree on Clusters. ACM Trans. Spat. Algorithms Syst. (TSAS) 2022, 8, 15. [Google Scholar] [CrossRef]
- He, Q.; Gao, P.; Zhang, F.; Bian, G.; Zhang, W.; Li, Z. Design and optimization of a distributed file system based on RDMA. Appl. Sci. 2023, 13, 8670. [Google Scholar] [CrossRef]
- Al-Attar, K.; Shafi, A.; Subramoni, H.; Panda, D.K. MPI4Spark Meets YARN: Enhancing MPI4Spark through YARN support for HPC. In Proceedings of the 2023 IEEE International Conference on Big Data (BigData), Sorrento, Italy, 15–18 December 2023; pp. 2265–2274. [Google Scholar]
- Bhatlawande, S.; Rajandekar, R.; Shilaskar, S. Implementing middleware architecture for automated data pipeline over cloud technologies. In Proceedings of the 2024 IEEE 13th International Conference on Communication Systems and Network Technologies (CSNT), Jabalpur, India, 6–7 April 2024; pp. 506–513. [Google Scholar]
- Bin Mofidul, R.; Alam, M.M.; Rahman, M.H.; Jang, Y.M. Real-time energy data acquisition, anomaly detection, and monitoring system: Implementation of a secured, robust, and integrated global IIoT infrastructure with edge and cloud AI. Sensors 2022, 22, 8980. [Google Scholar] [CrossRef]
- Choi, H.; Song, J.; Yi, K. Brightics-IoT: Towards effective industrial IoT platforms for connected smart factories. In Proceedings of the 2018 IEEE International Conference on Industrial Internet (ICII), Seattle, WA, USA, 21–23 October 2018; pp. 146–152. [Google Scholar]
- Cabrini, F.H.; Valiante Filho, F.; Rito, P.; Barros Filho, A.; Sargento, S.; Venâncio Neto, A.; Kofuji, S.T. Enabling the industrial Internet of Things to cloud continuum in a real city environment. Sensors 2021, 21, 7707. [Google Scholar] [CrossRef]
- Yang, D.; Mahmood, A.; Hassan, S.A.; Gidlund, M. Guest editorial: Industrial IoT and sensor networks in 5G-and-beyond wireless communication. IEEE Trans. Ind. Inform. 2022, 18, 4118–4121. [Google Scholar] [CrossRef]
- Umer, M.A.; Belay, E.G.; Gouveia, L.B. Leveraging Artificial Intelligence and Provenance Blockchain Framework to Mitigate Risks in Cloud Manufacturing in Industry 4.0. Electronics 2024, 13, 660. [Google Scholar] [CrossRef]
- Crespo-Aguado, M.; Lozano, R.; Hernandez-Gobertti, F.; Molner, N.; Gomez-Barquero, D. Flexible Hyper-Distributed IoT–Edge–Cloud Platform for Real-Time Digital Twin Applications on 6G-Intended Testbeds for Logistics and Industry. Future Internet 2024, 16, 431. [Google Scholar] [CrossRef]
- Yaker, K.; Salem, B.A.; Pierard, B.; Aitsaadi, N.; Raynal, V. A Novel EDGE SIEM for Industrial IoT Flows Within 5G Private Networks. In Proceedings of the 2024 Global Information Infrastructure and Networking Symposium (GIIS), Dubai, United Arab Emirates, 19–21 February 2024; pp. 1–6. [Google Scholar]
- Aouedi, O.; Piamrat, K. Toward a Scalable and Energy-Efficient Framework for Industrial Cloud-Edge-IoT Continuum. IEEE Internet Things Mag. 2024, 7, 14–20. [Google Scholar] [CrossRef]
- Hästbacka, D.; Halme, J.; Barna, L.; Hoikka, H.; Pettinen, H.; Larrañaga, M.; Björkbom, M.; Mesiä, H.; Jaatinen, A.; Elo, M. Dynamic edge and cloud service integration for industrial IoT and production monitoring applications of industrial cyber-physical systems. IEEE Trans. Ind. Inform. 2021, 18, 498–508. [Google Scholar] [CrossRef]
- He, Q.; Feng, Z.; Fang, H.; Wang, X.; Zhao, L.; Yao, Y.; Yu, K. A blockchain-based scheme for secure data offloading in healthcare with deep reinforcement learning. IEEE/ACM Trans. Netw. 2023, 32, 65–80. [Google Scholar] [CrossRef]
- Ma, Y.; Younis, K.; Ahmed, B.S.; Kassler, A.; Krakhmalev, P.; Thore, A.; Lindbäck, H. Automated and systematic digital twins testing for industrial processes. In Proceedings of the 2023 IEEE International Conference on Software Testing, Verification and Validation Workshops (ICSTW), Dublin, Ireland, 16–20 April 2023; pp. 149–158. [Google Scholar]
- Bellavista, P.; Di Modica, G. IoTwins: Implementing distributed and hybrid digital twins in industrial manufacturing and facility management settings. Future Internet 2024, 16, 65. [Google Scholar] [CrossRef]
- Li, L.; Gu, F.; Li, H.; Guo, J.; Gu, X. Digital twin bionics: A biological evolution-based digital twin approach for rapid product development. IEEE Access 2021, 9, 121507–121521. [Google Scholar] [CrossRef]
- Bacchiani, L.; De Palma, G.; Sciullo, L.; Bravetti, M.; Di Felice, M.; Gabbrielli, M.; Zavattaro, G.; Della Penna, R. Low-latency anomaly detection on the edge-cloud continuum for industry 4.0 applications: The SEAWALL case study. IEEE Internet Things Mag. 2022, 5, 32–37. [Google Scholar] [CrossRef]
- Bourechak, A.; Zedadra, O.; Kouahla, M.N.; Guerrieri, A.; Seridi, H.; Fortino, G. At the confluence of artificial intelligence and edge computing in iot-based applications: A review and new perspectives. Sensors 2023, 23, 1639. [Google Scholar] [CrossRef]
- Del Gallo, M.; Mazzuto, G.; Ciarapica, F.E.; Bevilacqua, M. Artificial intelligence to solve production scheduling problems in real industrial settings: Systematic Literature Review. Electronics 2023, 12, 4732. [Google Scholar] [CrossRef]
- Miltiadou, D.; Perakis, K.; Sesana, M.; Calabresi, M.; Lampathaki, F.; Biliri, E. A novel explainable artificial intelligence and secure artificial intelligence asset sharing platform for the manufacturing industry. In Proceedings of the 2023 IEEE International Conference on Engineering, Technology and Innovation (ICE/ITMC), Edinburgh, UK, 19–22 June 2023; pp. 1–8. [Google Scholar]
- Kumari, A.; Tanwar, S.; Tyagi, S.; Kumar, N. Blockchain-based massive data dissemination handling in IIoT environment. IEEE Netw. 2020, 35, 318–325. [Google Scholar] [CrossRef]
- Khan, A.A.; Laghari, A.A.; Shaikh, Z.A.; Dacko-Pikiewicz, Z.; Kot, S. Internet of Things (IoT) security with blockchain technology: A state-of-the-art review. IEEE Access 2022, 10, 122679–122695. [Google Scholar] [CrossRef]
- Aljuhani, A.; Kumar, P.; Alanazi, R.; Albalawi, T.; Taouali, O.; Islam, A.N.; Kumar, N.; Alazab, M. A deep-learning-integrated blockchain framework for securing industrial IoT. IEEE Internet Things J. 2023, 11, 7817–7827. [Google Scholar] [CrossRef]
- Sahal, R.; Alsamhi, S.H.; Brown, K.N.; O’shea, D.; McCarthy, C.; Guizani, M. Blockchain-empowered digital twins collaboration: Smart transportation use case. Machines 2021, 9, 193. [Google Scholar] [CrossRef]
- Joshi, S.; Sharma, M. Intelligent algorithms and methodologies for low-carbon smart manufacturing: Review on past research, recent developments and future research directions. IET Collab. Intell. Manuf. 2024, 6, e12094. [Google Scholar] [CrossRef]
- Jawarneh, I.M.A.; Foschini, L.; Bellavista, P. Polygon Simplification for the Efficient Approximate Analytics of Georeferenced Big Data. Sensors 2023, 23, 8178. [Google Scholar] [CrossRef] [PubMed]
- Alshamsi, R.A.; Al Jawarneh, I.M.; Foschini, L.; Corradi, A. ApproxGeoMap: An Efficient System for Generating Approximate Geo-Maps from Big Geospatial Data with Quality of Service Guarantees. Computers 2025, 14, 35. [Google Scholar] [CrossRef]
- Jagatheesaperumal, S.K.; Rahouti, M.; Ahmad, K.; Al-Fuqaha, A.; Guizani, M. The duo of artificial intelligence and big data for industry 4.0: Applications, techniques, challenges, and future research directions. IEEE Internet Things J. 2021, 9, 12861–12885. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).


 ,
, 


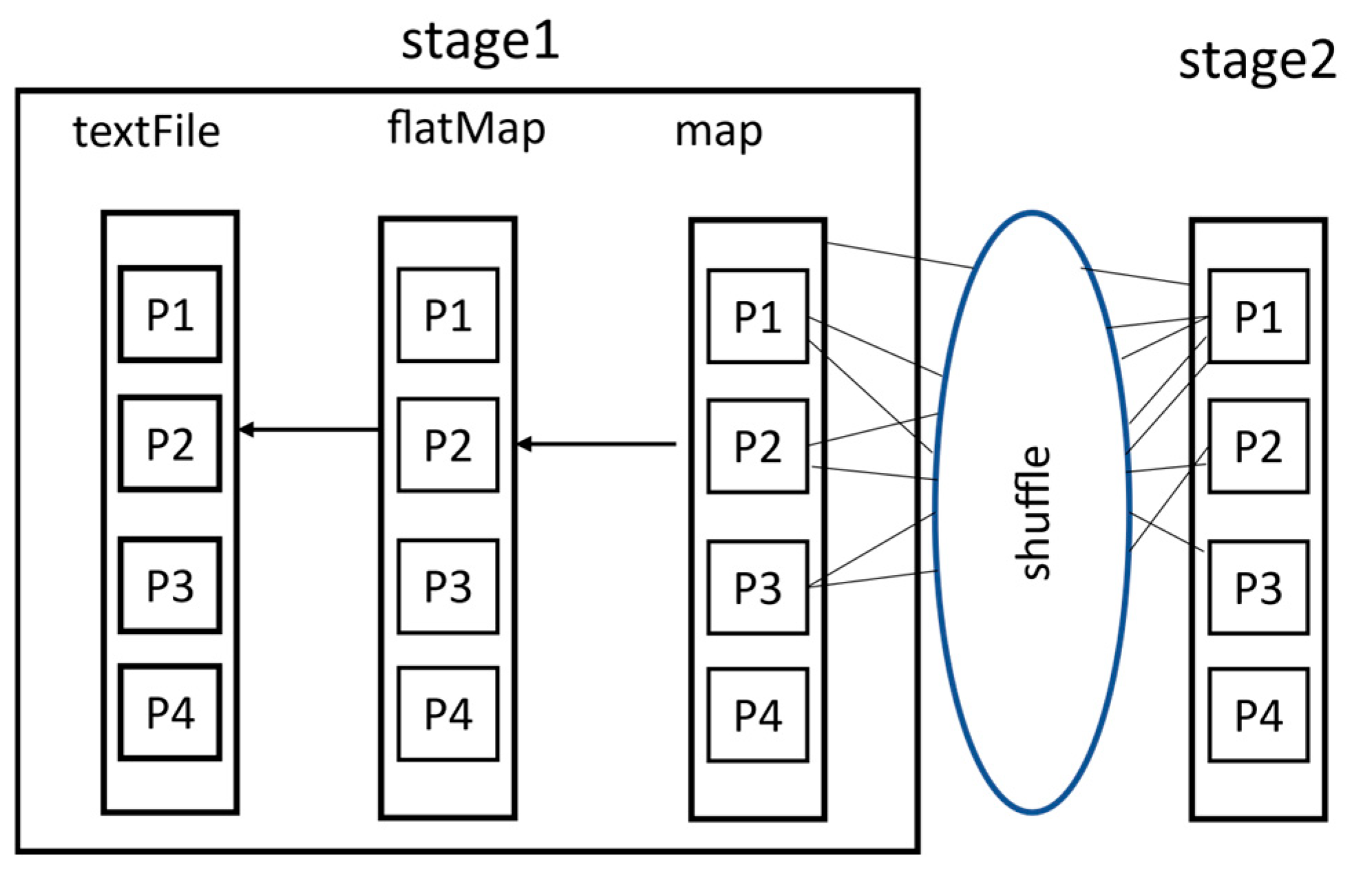

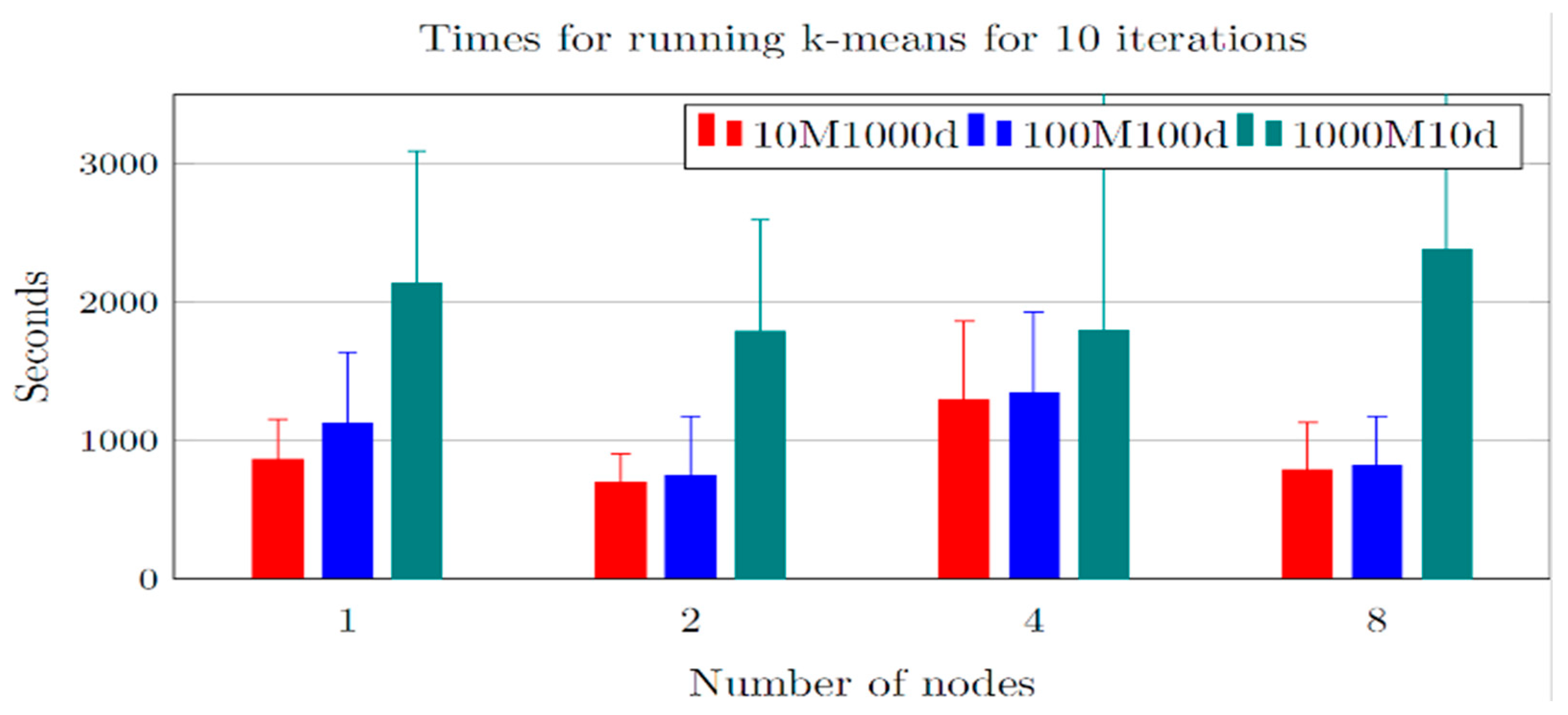




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}