Towards a Gated Graph Neural Network with an Attention Mechanism for Audio Features with a Situation Awareness Application



Abstract
1. Introduction
- We explore the performance of different audio features in SA tasks and propose audio features and their combinations suitable for graph modeling. With this approach, we uncovered the potential of graph-based features for SA applications, which can lead to more discriminative characterizations compared to traditional methods.
- We propose a method by which to convert audio features into graph representations, enabling the model to capture the relational patterns inherent in audio data. By converting specific audio features into different graph structures, e.g., connecting nodes representing audio frames in chronological order or according to the similarity of audio frames, we explore the impact of different graph structures on the model’s performance in SA. This process enables the model to utilize the rich information in the audio signal, such as temporal dependencies.
- We introduce two graph-based models for situational awareness in audio analysis. First, we propose an attention-enhanced graph neural network that employs neighborhood attention to dynamically weight node relationships during feature aggregation. Building upon this foundation, our second and primary contribution is the situation awareness gated-attention GNN (SAGA-GNN), which significantly advances the architecture through two novel mechanisms: max-relative node sampling that selectively retains only the most task-relevant connections, and a learnable gating system that adaptively filters noisy edges while amplifying critical audio event features. The SAGA-GNN demonstrates superior performance by explicitly addressing the unique challenges of SA audio graphs, where noise and irrelevant acoustic events typically compromise traditional graph representations.
2. Related Work
2.1. Audio-Based Situation Awareness
2.2. Graph-Based Methods for Audio Processing
2.3. GNNs with Attention Mechanisms
3. Methodology
3.1. Graph Construction for Audio
3.2. Graph Structure for Audio
3.3. GNN with Attention Mechnisms
3.3.1. Neighborhood Attention Mechanism
3.3.2. Audio Feature Fusion
4. Proposed Gated-Attention Graph Convolutional Network
| Algorithm 1: Situation Awareness Gated-Attention GCN. |
| Input: Graph , node features , edge features . |
| Output: Updated node features |
| Parameters: Learnable weights , , |
| for layer to do |
| for each node do |
| //1. Max-relative Neighbour Selection |
| Compute pairwise distances using Equation (17). |
| Select max-relative nodes using Equation (18). |
| //2. Edge Update & Gating Weights |
| for each do |
| Update edge feature using Equation (19) |
| Update gating weight using Equation (20) |
| Update attention-based weights using Equation (21) |
| Generate gated-attention weight using Equation (22) |
| end for |
| //3. Gated-Attention Aggregation |
| end for |
| end for |
5. Experiments
5.1. Experiment Settings
5.1.1. Experiment Datasets
5.1.2. Details of Implementation
5.1.3. Audio Features
- Spectral domain features: These include the log-Mel spectrogram (Mel) and the gammatone spectrogram (Gam), which use short-time Fourier transform (STFT) to obtain the STFT spectrum, which is subsequently passed through the corresponding filter bank to obtain the frequency selectivity that mimics the human auditory system [61,62]. These spectral domain features have also been shown to be effective in a variety of audio classification tasks [36,63]. Also, the CQT [11] and variable-Q transform (VQT) [64], which design ratios between the center frequencies of adjacent bands in filters to simulate the geometric relationship between pitch frequencies, were originally designed for music signal analysis [11]. This may make them a better representation of audio with overlapping sources or noisy backgrounds, and they were shown to be effective for sound event classification tasks in [65,66].
- Cepstral domain features: These include Mel-frequency cepstrum coefficients (MFCC) and linear frequency cepstrum coefficients (LFCC). They are calculated from the corresponding spectrograms by computing the DCT along the frequency exponent over a fixed time interval and are usually considered as a further abstract representation of the spectral domain features [67]. Although they were initially designed for speeches, several subsequent studies have demonstrated their effectiveness and applications in other audio classification scenarios, for example, on urban sound classification [13], animal sound recognition [68], and machine condition monitoring [69], etc.
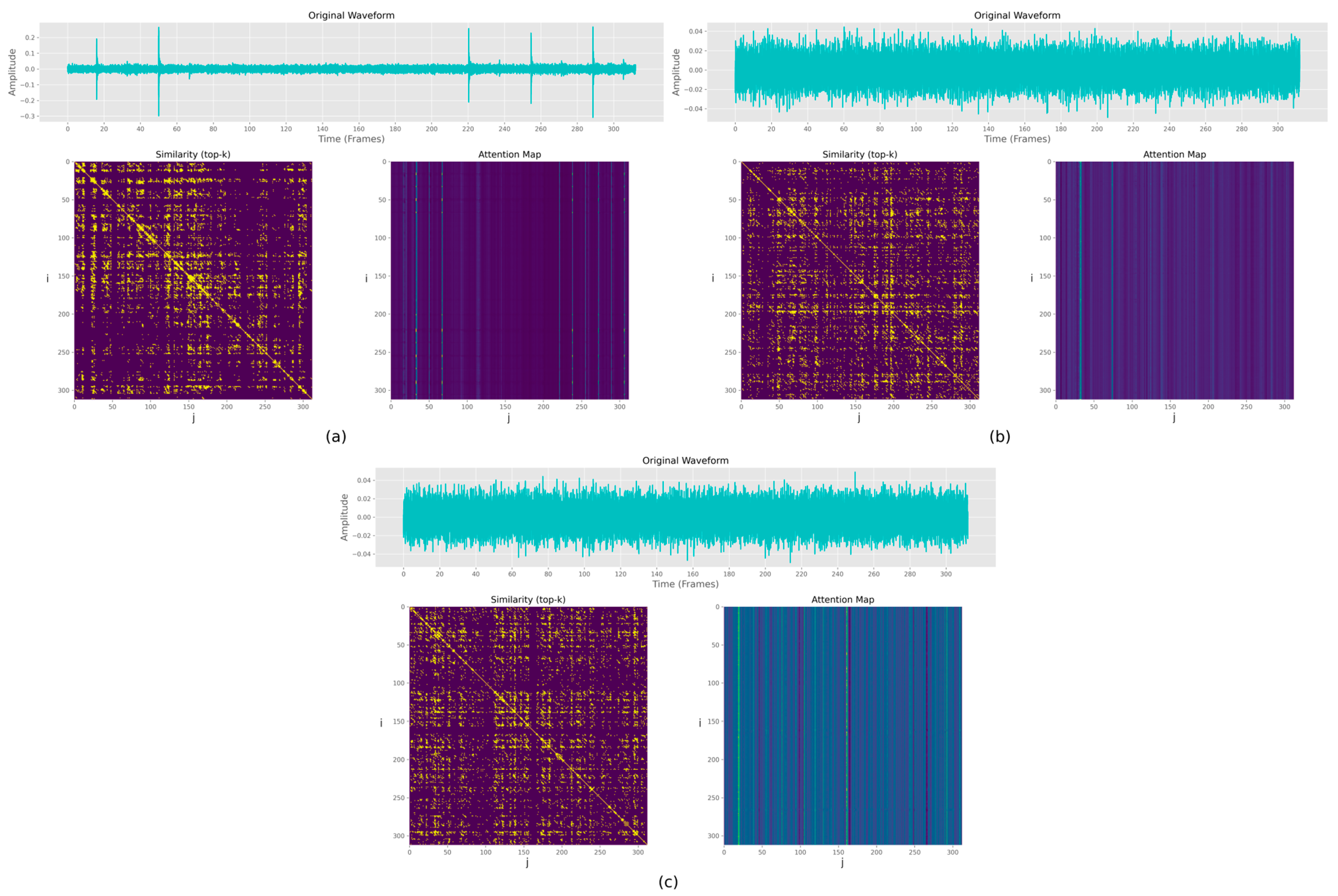
5.2. Exploration of SA-Related Audio Samples
5.3. Validity of Graph-Based Features for Situation Awareness
5.3.1. Performance of Single Feature
5.3.2. Performance of Feature Combinations on Models
5.4. Effects of Graph Structure for Situation Awareness Audio Features
5.5. Graph Neural Network with Attention Mechanism
5.6. SAGA-GNN
5.7. Limitations
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Endsley, M.R. Automation and Situation Awareness. In Automation and Human Performance: Theory and Applications; Parasuraman, R., Mouloua, M., Eds.; Lawrence Erlbaum: Mahwah, NJ, USA, 1996; pp. 163–181. [Google Scholar]
- Sui, L.; Guan, X.; Cui, C.; Jiang, H.; Pan, H.; Ohtsuki, T. Graph Learning Empowered Situation Awareness in Internet of Energy With Graph Digital Twin. IEEE Trans. Ind. Inform. 2023, 19, 7268–7277. [Google Scholar] [CrossRef]
- Chen, J.; Seng, K.P.; Ang, L.M.; Smith, J.; Xu, H. AI-Empowered Multimodal Hierarchical Graph-Based Learning for Situation Awareness on Enhancing Disaster Responses. Future Internet 2024, 16, 161. [Google Scholar] [CrossRef]
- Zhao, D.; Ji, G.; Zhang, Y.; Han, X.; Zeng, S. A Network Security Situation Prediction Method Based on SSA-GResNeSt. IEEE Trans. Netw. Serv. Manag. 2024, 21, 3498–3510. [Google Scholar] [CrossRef]
- Liu, Y.; Guan, J.; Zhu, Q.; Wang, W. Anomalous Sound Detection Using Spectral-Temporal Information Fusion. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 816–820. [Google Scholar]
- Mnasri, Z.; Rovetta, S.; Masulli, F. Anomalous Sound Event Detection: A Survey of Machine Learning Based Methods and Applications. Multimed. Tools Appl. 2022, 81, 5537–5586. [Google Scholar] [CrossRef]
- Mistry, Y.D.; Birajdar, G.K.; Khodke, A.M. Time-Frequency Visual Representation and Texture Features for Audio Applications: A Comprehensive Review, Recent Trends, and Challenges. Multimed. Tools Appl. 2023, 82, 36143–36177. [Google Scholar] [CrossRef]
- Kong, Q.; Cao, Y.; Iqbal, T.; Wang, Y.; Wang, W.; Plumbley, M.D. PANNs: Large-Scale Pretrained Audio Neural Networks for Audio Pattern Recognition. IEEEACM Trans. Audio Speech Lang. Process. 2020, 28, 2880–2894. [Google Scholar] [CrossRef]
- Chen, J.; Seng, K.P.; Smith, J.; Ang, L.-M. Situation Awareness in AI-Based Technologies and Multimodal Systems: Architectures, Challenges and Applications. IEEE Access 2024, 12, 88779–88818. [Google Scholar] [CrossRef]
- Davis, S.; Mermelstein, P. Comparison of Parametric Representations for Monosyllabic Word Recognition in Continuously Spoken Sentences. IEEE Trans. Acoust. Speech Signal Process. 1980, 28, 357–366. [Google Scholar] [CrossRef]
- Brown, J.C. Calculation of a Constant Q Spectral Transform. J. Acoust. Soc. Am. 1991, 89, 425–434. [Google Scholar] [CrossRef]
- Ruinskiy, D.; Lavner, Y. An Effective Algorithm for Automatic Detection and Exact Demarcation of Breath Sounds in Speech and Song Signals. IEEE Trans. Audio Speech Lang. Process. 2007, 15, 838–850. [Google Scholar] [CrossRef]
- Piczak, K.J. ESC: Dataset for Environmental Sound Classification. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane, Australia, 26–30 October 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 1015–1018. [Google Scholar]
- Birajdar, G.K.; Patil, M.D. Speech and Music Classification Using Spectrogram Based Statistical Descriptors and Extreme Learning Machine. Multimed. Tools Appl. 2019, 78, 15141–15168. [Google Scholar] [CrossRef]
- Breebaart, J.; McKinney, M.F. Features for Audio Classification. In Algorithms in Ambient Intelligence; Verhaegh, W.F.J., Aarts, E., Korst, J., Eds.; Springer: Dordrecht, The Netherlands, 2004; pp. 113–129. ISBN 978-94-017-0703-9. [Google Scholar]
- Koizumi, Y.; Kawaguchi, Y.; Imoto, K.; Nakamura, T.; Nikaido, Y.; Tanabe, R.; Purohit, H.; Suefusa, K.; Endo, T.; Yasuda, M.; et al. Description and Discussion on DCASE2020 Challenge Task2: Unsupervised Anomalous Sound Detection for Machine Condition Monitoring. arXiv 2020. [Google Scholar] [CrossRef]
- Shashidhar, R.; Patilkulkarni, S.; Puneeth, S.B. Combining Audio and Visual Speech Recognition Using LSTM and Deep Convolutional Neural Network. Int. J. Inf. Technol. 2022, 14, 3425–3436. [Google Scholar] [CrossRef]
- Nanni, L.; Costa, Y.M.G.; Lucio, D.R.; Silla, C.N.; Brahnam, S. Combining Visual and Acoustic Features for Audio Classification Tasks. Pattern Recognit. Lett. 2017, 88, 49–56. [Google Scholar] [CrossRef]
- Suefusa, K.; Nishida, T.; Purohit, H.; Tanabe, R.; Endo, T.; Kawaguchi, Y. Anomalous Sound Detection Based on Interpolation Deep Neural Network. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 271–275. [Google Scholar]
- Wilkinghoff, K. Self-Supervised Learning for Anomalous Sound Detection. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 276–280. [Google Scholar]
- Han, K.; Wang, Y.; Guo, J.; Tang, Y.; Wu, E. Vision GNN: An Image Is Worth Graph of Nodes. arXiv 2022, arXiv:2206.00272. [Google Scholar]
- Yao, L.; Mao, C.; Luo, Y. Graph Convolutional Networks for Text Classification. Proc. AAAI Conf. Artif. Intell. 2019, 33, 7370–7377. [Google Scholar] [CrossRef]
- Xu, H.; Seng, K.P.; Ang, L.-M. New Hybrid Graph Convolution Neural Network with Applications in Game Strategy. Electronics 2023, 12, 4020. [Google Scholar] [CrossRef]
- Singh, S.; Benetos, E.; Phan, H.; Stowell, D. LHGNN: Local-Higher Order Graph Neural Networks For Audio Classification and Tagging. arXiv 2025. [Google Scholar] [CrossRef]
- Bhattacharjee, A.; Singh, S.; Benetos, E. GraFPrint: A GNN-Based Approach for Audio Identification. arXiv 2024. [Google Scholar] [CrossRef]
- Castro-Ospina, A.E.; Solarte-Sanchez, M.A.; Vega-Escobar, L.S.; Isaza, C.; Martínez-Vargas, J.D. Graph-Based Audio Classification Using Pre-Trained Models and Graph Neural Networks. Sensors 2024, 24, 2106. [Google Scholar] [CrossRef]
- Aironi, C.; Cornell, S.; Principi, E.; Squartini, S. Graph-based Representation of Audio signals for Sound Event Classification. In Proceedings of the 2021 29th European Signal Processing Conference (EUSIPCO), Dublin, Ireland, 23–27 August 2021; pp. 566–570. [Google Scholar]
- Kim, J.-W.; Yoon, C.; Jung, H.-Y. A Military Audio Dataset for Situational Awareness and Surveillance. Sci. Data 2024, 11, 668. [Google Scholar] [CrossRef] [PubMed]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. arXiv 2018, arXiv:1710.10903. [Google Scholar]
- Rampášek, L.; Galkin, M.; Dwivedi, V.P.; Luu, A.T.; Wolf, G.; Beaini, D. Recipe for a General, Powerful, Scalable Graph Transformer. In Proceedings of the 36th International Conference on Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022; Curran Associates Inc.: Red Hook, NY, USA, 2022; Volume 35, pp. 14501–14515. [Google Scholar]
- Dwivedi, V.P.; Bresson, X. A Generalization of Transformer Networks to Graphs. arXiv 2021, arXiv:2012.09699. [Google Scholar]
- Munir, A.; Aved, A.; Blasch, E. Situational Awareness: Techniques, Challenges, and Prospects. AI 2022, 3, 55–77. [Google Scholar] [CrossRef]
- Lamsal, R.; Harwood, A.; Read, M.R. Socially Enhanced Situation Awareness from Microblogs Using Artificial Intelligence: A Survey. ACM Comput. Surv. 2022, 55, 1–38. [Google Scholar] [CrossRef]
- Dohi, K.; Endo, T.; Purohit, H.; Tanabe, R.; Kawaguchi, Y. Flow-Based Self-Supervised Density Estimation for Anomalous Sound Detection. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 336–340. [Google Scholar]
- Ekpezu, A.O.; Wiafe, I.; Katsriku, F.; Yaokumah, W. Using Deep Learning for Acoustic Event Classification: The Case of Natural Disasters. J. Acoust. Soc. Am. 2021, 149, 2926–2935. [Google Scholar] [CrossRef]
- Zavrtanik, V.; Marolt, M.; Kristan, M.; Skočaj, D. Anomalous Sound Detection by Feature-Level Anomaly Simulation. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 1466–1470. [Google Scholar]
- Shirian, A.; Guha, T. Compact Graph Architecture for Speech Emotion Recognition. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 6284–6288. [Google Scholar]
- Hou, Y.; Song, S.; Yu, C.; Wang, W.; Botteldooren, D. Audio Event-Relational Graph Representation Learning for Acoustic Scene Classification. IEEE Signal Process. Lett. 2023, 30, 1382–1386. [Google Scholar] [CrossRef]
- Gao, Y.; Zhao, H.; Zhang, Z. Adaptive Speech Emotion Representation Learning Based On Dynamic Graph. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 1116–11120. [Google Scholar]
- Singh, S.; Steinmetz, C.J.; Benetos, E.; Phan, H.; Stowell, D. ATGNN: Audio Tagging Graph Neural Network. IEEE Signal Process. Lett. 2024, 31, 825–829. [Google Scholar] [CrossRef]
- Shirian, A.; Tripathi, S.; Guha, T. Dynamic Emotion Modeling With Learnable Graphs and Graph Inception Network. IEEE Trans. Multimed. 2022, 24, 780–790. [Google Scholar] [CrossRef]
- Gong, Y.; Chung, Y.-A.; Glass, J. AST: Audio Spectrogram Transformer. In Proceedings of the Interspeech 2021, Brno, Czechia, 30 August–3 September 2021; pp. 571–575. [Google Scholar] [CrossRef]
- Xiao, F.; Guan, J.; Zhu, Q.; Wang, W. Graph Attention for Automated Audio Captioning. IEEE Signal Process. Lett. 2023, 30, 413–417. [Google Scholar] [CrossRef]
- Gao, Y.; Zhao, H.; Xiao, Y.; Zhang, Z. GCFormer: A Graph Convolutional Transformer for Speech Emotion Recognition. In Proceedings of the International Conference on Multimodal Interaction, Paris, France, 9–13 October 2023; ACM: New York, NY, USA, 2023; pp. 307–313. [Google Scholar]
- Rampášek, L.; Galkin, M.; Dwivedi, V.P.; Luu, A.T.; Wolf, G.; Beaini, D. Recipe for a General, Powerful, Scalable Graph Transformer. arXiv 2023. [Google Scholar] [CrossRef]
- Sun, C.; Jiang, M.; Gao, L.; Xin, Y.; Dong, Y. A novel Study for Depression Detecting Using Audio Signals Based on Graph Neural Network. Biomed. Signal Process. Control 2024, 88, 105675. [Google Scholar] [CrossRef]
- Ma, X.; Sun, P.; Gong, M. An Integrative Framework of Heterogeneous Genomic Data for Cancer Dynamic Modules Based on Matrix Decomposition. IEEE/ACM Trans. Comput. Biol. Bioinform. 2022, 19, 305–316. [Google Scholar] [CrossRef]
- Bresson, X.; Laurent, T. Residual Gated Graph ConvNets. arXiv 2018, arXiv:1711.07553. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Hassani, A.; Walton, S.; Li, J.; Li, S.; Shi, H. Neighborhood Attention Transformer. arXiv 2023. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2017. [Google Scholar] [CrossRef]
- Swietojanski, P.; Braun, S.; Can, D.; Da Silva, T.F.; Ghoshal, A.; Hori, T.; Hsiao, R.; Mason, H.; McDermott, E.; Silovsky, H.; et al. Variable Attention Masking for Configurable Transformer Transducer Speech Recognition. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. arXiv 2023. [Google Scholar] [CrossRef]
- Hou, Y.; Ren, Q.; Song, S.; Song, Y.; Wang, W.; Botteldooren, D. Multi-Level Graph Learning For Audio Event Classification And Human-Perceived Annoyance Rating Prediction. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 716–720. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; ISBN 978-0-262-33737-3. [Google Scholar]
- Li, G.; Muller, M.; Thabet, A.; Ghanem, B. DeepGCNs: Can GCNs Go As Deep As CNNs? In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 20–26 October 2019; pp. 9267–9276. [Google Scholar]
- Dwivedi, V.P.; Joshi, C.K.; Luu, A.T.; Laurent, T.; Bengio, Y.; Bresson, X. Benchmarking Graph Neural Networks. J. Mach. Learn. Res. 2023, 24, 1–48. [Google Scholar]
- Noman, A.; Beiji, Z.; Zhu, C.; Alhabib, M.; Al-sabri, R. FEGGNN: Feature-Enhanced Gated Graph Neural Network for Robust Few-Shot Skin Disease Classification. Comput. Biol. Med. 2025, 189, 109902. [Google Scholar] [CrossRef]
- Chen, H.; Xie, W.; Vedaldi, A.; Zisserman, A. Vggsound: A Large-Scale Audio-Visual Dataset. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 721–725. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017. [Google Scholar] [CrossRef]
- Vorländer, M. Acoustic Measurements. In Handbook of Engineering Acoustics; Müller, G., Möser, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 23–52. ISBN 978-3-540-69460-1. [Google Scholar]
- Slaney, M. An Efficient Implementation of the Patterson-Holdsworth Auditory Filter Bank. 1997. Available online: https://engineering.purdue.edu/~malcolm/apple/tr35/PattersonsEar.pdf (accessed on 19 June 2025).
- Mu, W.; Yin, B.; Huang, X.; Xu, J.; Du, Z. Environmental Sound Classification Using Temporal-Frequency Attention Based Convolutional Neural Network. Sci. Rep. 2021, 11, 21552. [Google Scholar] [CrossRef] [PubMed]
- Schörkhuber, C.; Klapuri, A.; Holighaus, N.; Dörfler, M. A Matlab Toolbox for Efficient Perfect Reconstruction Time-Frequency Transforms with Log-Frequency Resolution. In Semantic Audio; Audio Engineering Society: New York, NY, USA, 2014. [Google Scholar]
- Lidy, T.; Schindler, A. CQT-Based Convolutional Neural Networks for Audio Scene Classification. 2016. Available online: https://dcase.community/documents/challenge2016/technical_reports/DCASE2016_Lidy_4007.pdf (accessed on 19 June 2025).
- Venkatesh, S.; Koolagudi, S.G. Polyphonic Sound Event Detection Using Modified Recurrent Temporal Pyramid Neural Network. In Computer Vision and Image Processing; Kaur, H., Jakhetiya, V., Goyal, P., Khanna, P., Raman, B., Kumar, S., Eds.; Springer Nature: Cham, Switzerland, 2024; pp. 554–564. [Google Scholar]
- Anden, J.; Mallat, S. Deep Scattering Spectrum. IEEE Trans. Signal Process. 2014, 62, 4114–4128. [Google Scholar] [CrossRef]
- Nolasco, I.; Singh, S.; Morfi, V.; Lostanlen, V.; Strandburg-Peshkin, A.; Vidaña-Vila, E.; Gill, L.; Pamuła, H.; Whitehead, H.; Kiskin, I.; et al. Learning to Detect an Animal Sound from Five Examples. Ecol. Inform. 2023, 77, 102258. [Google Scholar] [CrossRef]
- Pichler, C.; Neumayer, M.; Schweighofer, B.; Feilmayr, C.; Schuster, S.; Wegleiter, H. Acoustic-Based Detection Technique for Identifying Worn-Out Components in Large-Scale Industrial Machinery. IEEE Sens. Lett. 2023, 7, 1–4. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learnin, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- van der Maaten, L.; Hinton, G. Visualizing Data Using T-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Li, Y.; Tarlow, D.; Brockschmidt, M.; Zemel, R. Gated Graph Sequence Neural Networks. arXiv 2017. [Google Scholar] [CrossRef]
- Zhang, H.; Wu, B.; Yuan, X.; Pan, S.; Tong, H.; Pei, J. Trustworthy Graph Neural Networks: Aspects, Methods, and Trends. Proc. IEEE 2024, 112, 97–139. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Mel | Gam | MFCC | LFCC | CQT | VQT | Wav |
|---|---|---|---|---|---|---|---|
| GCN | 86.6/83.0 | 80.3/75.8 | 85.6/82.7 | 86.4/81.8 | 75.4/68.7 | 73.9/68.8 | 77.1/70.2 |
| GAT | 85.7/81.5 | 80.6/74.9 | 85.7/82.3 | 85.9/81.6 | 75.8/68.8 | 72.6/68.7 | 78.6/71.9 |
| Gated-GCN | 86.7/83.1 | 84.9/78.5 | 87.6/82.7 | 87.6/81.6 | 79.3/71.4 | 76.4/70.2 | 80.6/73.0 |
| PANN | 77.0/71.5 | 77.4/73.6 | 76.6/71.4 | 79.9/73.3 | 69.5/64.8 | 69.2/63.6 | 76.1/71.9 |
| Eff.Net | 85.9/81.2 | 86.3/81.3 | 85.4/75.8 | 83.2/76.5 | 82.8/74.5 | 82.7/73.7 | 79.4/71.8 |
| AST | 85.7/78.6 | 85.5/76.0 | 83.0/76.0 | 82.7/75.3 | 76.4/67.8 | 76.1/68.3 | 71.8/66.3 |
| MLP | 77.5/70.8 | 72.8/66.9 | 77.7/71.5 | 80.2/72.0 | 63.7/61.8 | 63.7/61.9 | 62.4/59.9 |
| SVM | 72.9/66.8 | 62.4/61.1 | 74.0/68.5 | 76.3/69.1 | 63.3/61.8 | 63.4/61.7 | 61.6/59.8 |
| Models | MEL | GAM | MFCC | LFCC | CQT | VQT | Wav |
|---|---|---|---|---|---|---|---|
| GCN | 63.5 | 58.5 | 63.7 | 63.1 | 63.7 | 58.0 | 45.3 |
| GAT | 60.6 | 41.4 | 63.8 | 66.5 | 64.8 | 61.3 | 46.2 |
| Gated-GCN | 68.0 | 68.5 | 69.3 | 67.0 | 66.2 | 63.1 | 49.7 |
| PANN | 65.3 | 68.2 | 65.2 | 65.8 | 63 | 56.8 | 45.6 |
| Eff.Net | 72.2 | 72.2 | 68.0 | 67.5 | 69.7 | 69 | 50.8 |
| AST | 41.0 | 42.0 | 51.6 | 51.8 | 42.2 | 35.2 | 35.4 |
| SVM | 40.9 | 41.0 | 43.9 | 43.7 | 38.9 | 35.7 | 35.2 |
| MLP | 38.0 | 39.4 | 48.1 | 48.2 | 48.7 | 44.9 | 38.9 |
| Models | Mel + Gam | Mel + MFCC | MFCC + LFCC | Gam + LFCC |
|---|---|---|---|---|
| GCN | 87.2/83.3 | 87.8/83.4 | 86.9/82.9 | 87.0/79.5 |
| Gated-GCN | 87.5/83.4 | 88.0/84.2 | 87.8/84.2 | 87.5/82.4 |
| PANN | 77.9/71.8 | 77.5/72.6 | 79.1/70.9 | 77.8/72.9 |
| EfficientNet | 87.0/81.9 | 86.5/81.4 | 87.4/75.9 | 86.8/81.4 |
| Models | Feature | Line | Cycle | Similarity |
|---|---|---|---|---|
| Gated-GCN | Mel | 86.2/82.5 | 86.7/83.1 | 87.4/83.5 |
| MFCC | 87.1/81.4 | 87.6/82.7 | 88.2/82.9 | |
| Mel + MFCC | 87.8/82.9 | 88.0/84.2 | 89.4/84.5 |
| GNN Method | Attention Mechanism | AUC | pAUC |
|---|---|---|---|
| Gated-GCN | None | 87.4 | 83.5 |
| Self-Attention | 88.0 | 83.8 | |
| Neighborhood Attention | 89.2 | 83.8 |
| Methods | Feature | AUC | pAUC |
|---|---|---|---|
| IDNN [19] | Mel Spec. | 79.30 | 63.78 |
| MobileNet-v2 [20] | Mel Spec. | 84.00 | 77.74 |
| Glow Aff [34] | Mel Spec. | 85.20 | 73.90 |
| STgram [5] | Mel Spec. + Wav | 89.68 | 84.64 |
| AudDSR [36] | Mel Spec. | 90.12 | 84.59 |
| Proposed Gated-GCN with Attention | Mel Spec. + MFCC | 90.59 | 84.81 |
| Methods | Feature | AUC | pAUC | Param. | Time |
|---|---|---|---|---|---|
| IDNN [19] | Mel Spec. | 79.30 | 63.78 | \ | \ |
| MobileNet-v2 [20] | Mel Spec. | 84.00 | 77.74 | \ | \ |
| Glow Aff [34] | Mel Spec. | 85.20 | 73.90 | \ | \ |
| STgram [5] | Mel Spec. + Wav | 89.68 | 84.64 | 2 M | 6 h 12 min |
| AudDSR [36] | Mel Spec. | 90.12 | 84.59 | \ | \ |
| Gated-GNN | Mel Spec. + MFCC | 86.72 | 78.28 | 3 M | 7 h 11 min |
| Gated-GCN | Mel Spec. + MFCC | 89.36 | 84.49 | 5 M | 7 h 45 min |
| Proposed Gated-GCN with Attention | Mel Spec. + MFCC | 90.59 | 84.81 | 15 M | 9 h 53 min |
| Proposed SAG-GCN | Mel Spec. + MFCC | 91.09 | 85.05 | 17 M | 8 h 41 min |
| Proposed SAGA-GNN | Mel Spec. + MFCC | 91.26 | 85.18 | 18 M | 8 h 32 min |
| Methods | Feature | Acc. | Param. | Time |
|---|---|---|---|---|
| ResNet-50 | Mel Spec. | 65.1 | 26 M | 2 h 20 min |
| EfficientNet-b1 | Mel Spec. | 65.8 | 8 M | 2 h 54 min |
| PANN | Mel Spec. | 52.6 | 75 M | 4 h 53 min |
| Gated-GNN | Mel Spec. + MFCC | 66.2 | 3 M | 2 h 18 min |
| Gated-GCN | Mel Spec. + MFCC | 70.7 | 5 M | 2 h 27 min |
| Proposed Gated-GCN with Attention | Mel Spec. + MFCC | 72.4 | 15 M | 2 h 52 min |
| Proposed SAG-GCN | Mel Spec. + MFCC | 74.2 | 17 M | 2 h 45 min |
| Proposed SAGA-GNN | Mel Spec. + MFCC | 74.8 | 18 M | 2 h 42 min |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.; Seng, K.P.; Ang, L.M.; Smith, J.; Xu, H. Towards a Gated Graph Neural Network with an Attention Mechanism for Audio Features with a Situation Awareness Application. Electronics 2025, 14, 2621. https://doi.org/10.3390/electronics14132621
Chen J, Seng KP, Ang LM, Smith J, Xu H. Towards a Gated Graph Neural Network with an Attention Mechanism for Audio Features with a Situation Awareness Application. Electronics. 2025; 14(13):2621. https://doi.org/10.3390/electronics14132621
Chicago/Turabian StyleChen, Jieli, Kah Phooi Seng, Li Minn Ang, Jeremy Smith, and Hanyue Xu. 2025. "Towards a Gated Graph Neural Network with an Attention Mechanism for Audio Features with a Situation Awareness Application" Electronics 14, no. 13: 2621. https://doi.org/10.3390/electronics14132621
APA StyleChen, J., Seng, K. P., Ang, L. M., Smith, J., & Xu, H. (2025). Towards a Gated Graph Neural Network with an Attention Mechanism for Audio Features with a Situation Awareness Application. Electronics, 14(13), 2621. https://doi.org/10.3390/electronics14132621