
Efficient Smoke Segmentation Using Multiscale Convolutions and Multiview Attention Mechanisms



Abstract
1. Introduction
- Multiscale Convolutions with Rectangular Kernels: Integrates a multiscale convolution module using rectangular-shaped kernels alongside standard kernels. Rectangular kernels are designed to capture spatial patterns that are suitable for the irregular and anisotropic characteristics of smoke. Specifically, vertically oriented rectangular kernels address tall, narrow smoke plumes commonly seen in wildfires or smoke directly ejected from drilled holes during quarry blasts. In contrast, horizontally oriented kernels address wide, low plumes typically observed when smoke leaks and spreads out from collapsed rock terrain after blasting.
- Multiview Linear Attention: Employs a multiview linear attention mechanism to efficiently enhance feature integration. Traditional attention mechanisms, such as those used in Vision Transformers, calculate attention weights through pairwise interactions, resulting in quadratic computational complexity with respect to input size. In contrast, linear attention approximates these interactions using linear projections, scaling linearly with input dimensions and reducing computational demands. The multiview design further enhances feature representation by applying attention separately across spatial (height and width) and channel dimensions through element-wise multiplication.
- Layer-Specific Loss: Incorporates a layer-specific loss strategy that applies additional supervision to intermediate layers, reducing feature discrepancies between convolutional and attention modules. Directly applying a dedicated loss between these two types of features ensures alignment and consistency across layers.
2. Related Work
2.1. Deep-Learning Methods for Smoke Segmentation
2.2. Advances in Attention Mechanisms and Multiscale Feature Representation
2.3. Enhancing Model Robustness and Computational Efficiency
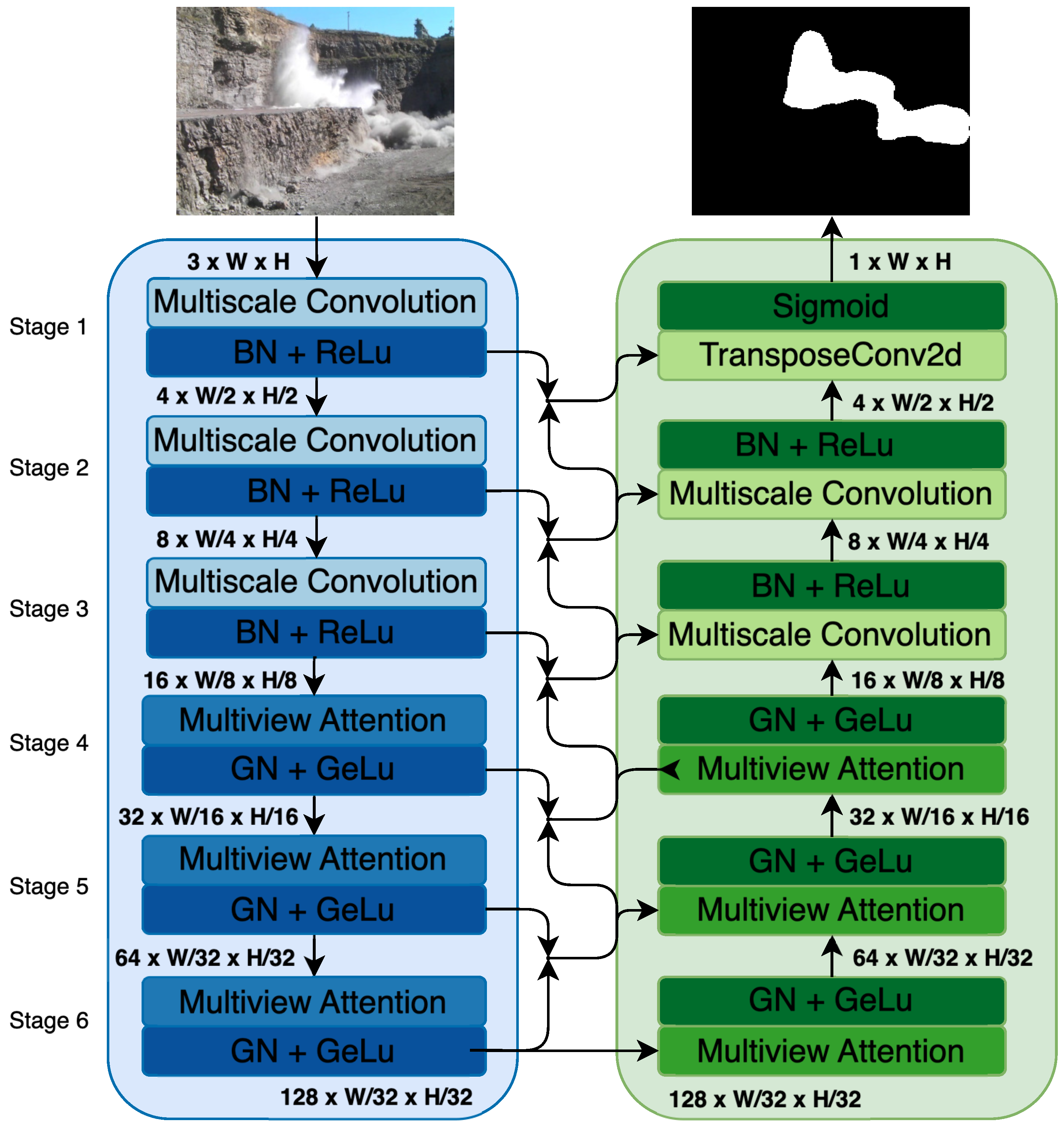
3. Methodology
3.1. Encoder
3.1.1. Multiscale Feature Extraction
3.1.2. Multiview Linear Attention Mechanism
3.2. Decoder
3.2.1. Decoder with Skip Connections
3.2.2. Decoder Stage Operations
3.3. Loss Function
4. Experiments
4.1. Experimental Setup
4.1.1. Deep Learning Architecture
4.1.2. Dataset
- Fire Smoke [44]: A real-world dataset with 3826 images, including 3060 training images and 766 test images, as illustrated in Figure 4c. It captures both outdoor wildfire smoke and indoor smoke scenarios, providing realistic environments where smoke detection is critical for early fire warning and safety monitoring.
- Quarry Smoke: An industrial dataset comprising 3703 images, including 2962 training images and 741 test images, as illustrated in Figure 4d–f. It represents dense, irregular smoke plumes mixed with dust and debris from quarry blasts, testing the model’s ability to segment smoke in dynamic and high-variability environments.
4.1.3. Quarry Smoke Dataset Collection
4.1.4. Data Augmentation
4.1.5. Performance Metrics
- Mean Intersection over Union (mIoU): Quantifies segmentation accuracy by measuring overlap between predicted and ground-truth masks, providing a balanced evaluation that equally penalizes missed segmentation and false alarms.
- Parameter Count: Indicates model scalability. Reported in millions (M).
- Floating Point Operations (FLOPs): Measures computational complexity. Reported in gigaflops (GFLOPs), as indicated in the tables.
- Frames per Second (FPS): Reflects inference speed, critical for computationally constrained applications in dynamic environments like quarry blast monitoring.
4.2. Results and Discussion
4.2.1. Results
4.2.2. Impact of Architectural Innovations
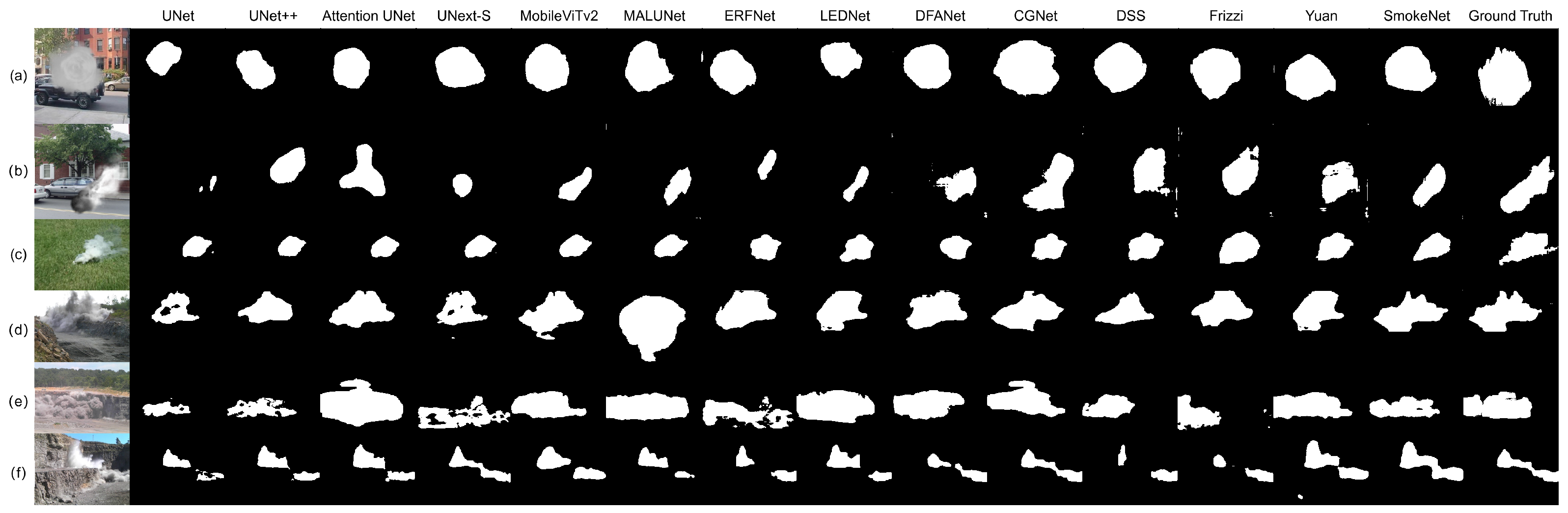
4.2.3. Segmentation Performance Comparison
4.2.4. Model Efficiency Comparison
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Oluwoye, I.; Dlugogorski, B.Z.; Gore, J.; Oskierski, H.C.; Altarawneh, M. Atmospheric emission of NOx from mining explosives: A critical review. Atmos. Environ. 2017, 167, 81–96. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015, Proceedings of the 18th International Conference, Munich, Germany, 5–9 October 2015; Springer International Publishing: New York, NY, USA, 2015; pp. 234–241. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville TN, USA, 11–15 June 2015; pp. 3431–3440. [Google Scholar]
- Howard, A.G. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the International Conference on Machine Learning (ICML), Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations (ICLR), Virtual Event, 3–7 May 2021. [Google Scholar]
- Yuan, F.; Zhang, L.; Xia, X.; Wan, B.; Huang, Q.; Li, X. Deep Smoke Segmentation. Neurocomputing 2019, 357, 248–260. [Google Scholar] [CrossRef]
- Frizzi, S.; Bouchouicha, M.; Ginoux, J.M.; Moreau, E.; Sayadi, M. Convolutional Neural Network for Smoke and Fire Semantic Segmentation. IET Image Process. 2021, 15, 634–647. [Google Scholar] [CrossRef]
- Yuan, F.; Li, K.; Wang, C.; Fang, Z. A Lightweight Network for Smoke Semantic Segmentation. Pattern Recognit. 2023, 137, 109289. [Google Scholar] [CrossRef]
- Yin, Z.; Wan, B.; Yuan, F.; Xia, X.; Shi, J. Deep normalized convolutional neural network for fire and smoke detection. Multimed. Tools Appl. 2018, 77, 28549–28565. [Google Scholar]
- Yuan, F.; Zhang, L.; Xia, X.; Wan, B.; Li, Q. Video smoke detection with deep convolutional neural networks based on spatial-temporal feature extraction. Sensors 2019, 19, 666. [Google Scholar]
- Cheng, H.Y.; Yin, J.L.; Chen, B.H.; Yu, Z.M. Smoke100k: A Database for Smoke Detection. In Proceedings of the 2019 IEEE 8th Global Conference on Consumer Electronics (GCCE), Osaka, Japan, 15–18 October 2019; pp. 596–597. [Google Scholar]
- Khan, S.; Muhammad, K.; Hussain, T.; Ser, J.D.; Cuzzolin, F.; Bhattacharyya, S.; Akhtar, Z.; de Albuquerque, V.H.C. DeepSmoke: Deep learning model for smoke detection and segmentation in outdoor environments. Expert Syst. Appl. 2021, 182, 115125. [Google Scholar] [CrossRef]
- Yao, L.; Zhao, H.; Peng, J.; Wang, Z.; Zhao, K. FoSp: Focus and Separation Network for Early Smoke Segmentation. arXiv 2023, arXiv:2306.04474. [Google Scholar] [CrossRef]
- Marto, T.; Bernardino, A.; Cruz, G. Fire and Smoke Segmentation Using Active Learning Methods. Remote Sens. 2023, 15, 4136. [Google Scholar] [CrossRef]
- Dewangan, A.; Pande, Y.; Braun, H.; Vernon, F.; Perez, I.; Altintas, I.; Cottrell, G.W.; Nguyen, M.H. FIgLib & SmokeyNet: Dataset and Deep Learning Model for Real-Time Wildland Fire Smoke Detection. arXiv 2021, arXiv:2112.08598. [Google Scholar]
- Pesonen, J.; Hakala, T.; Karjalainen, V.; Koivumäki, N.; Markelin, L.; Raita-Hakola, A.M.; Honkavaara, E. Detecting Wildfires on UAVs with Real-time Segmentation by Larger Teacher Models. arXiv 2024, arXiv:2408.10843. [Google Scholar]
- Lee, e.a. Real-Time Smoke Detection in Surveillance Videos Using an RT-DETR Architecture. Fire 2024, 7, 387. [Google Scholar]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. UNet++: A Nested U-Net Architecture for Medical Image Segmentation. In Proceedings of the 4th International Workshop on Deep Learning in Medical Image Analysis (DLMIA 2018), Granada, Spain, 20 September 2018; pp. 3–11. [Google Scholar]
- Oktay, O. Attention U-Net: Learning Where to Look for the Pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Cai, Y.; Wang, Y. MA-Unet: An improved version of U-Net based on multi-scale and attention mechanism for medical image segmentation. arXiv 2020, arXiv:2012.10952. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-Unet: Unet-Like Pure Transformer for Medical Image Segmentation. In Proceedings of the ECCV 2022 Workshops, Tel Aviv, Israel, 23–27 October 2022; Volume 13803, pp. 205–218. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training Data-Efficient Image Transformers & Distillation Through Attention. In Proceedings of the 38th International Conference on Machine Learning (ICML), Virtual, 18–24 July 2021; pp. 10347–10357. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 568–578. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Rajamani, K.T.; Rani, P.; Siebert, H.; ElagiriRamalingam, R.; Heinrich, M.P. Attention-Augmented U-Net (AA-U-Net) for Semantic Segmentation. Signal Image Video Process. 2023, 17, 981–989. [Google Scholar] [CrossRef]
- Yan, H.; Zhang, C.; Wu, M. Lawin Transformer: Improving Semantic Segmentation Transformer with Multi-Scale Representations via Large Window Attention. arXiv 2022, arXiv:2201.01615. [Google Scholar]
- Yang, J.; Li, C.; Dai, X.; Gao, J. Focal Self-attention for Local-Global Interactions in Vision Transformers. arXiv 2021, arXiv:2107.00641. [Google Scholar]
- Rahman, M.M.; Marculescu, R. MERIT: Multi-scale Hierarchical Vision Transformer with Cascaded Attention Decoding for Medical Image Segmentation. In Proceedings of the Medical Imaging with Deep Learning (MIDL), Paris, France, 3–5 July 2024. [Google Scholar]
- Chu, X.; Tian, Z.; Wang, Y.; Zhang, B.; Ren, H.; Wei, X.; Xia, H.; Shen, C. Twins: Revisiting the Design of Spatial Attention in Vision Transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 9355–9366. [Google Scholar]
- Poudel, R.P.; Liwicki, S.; Cipolla, R. Fast-SCNN: Fast semantic segmentation network. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 1308–1314. [Google Scholar]
- Wang, Y.; Zhou, Q.; Liu, J.; Xiong, J.; Gao, G.; Wu, X.; Latecki, L.J. LEDNet: A Lightweight Encoder-Decoder Network for Real-Time Semantic Segmentation. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1860–1864. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. BiSeNet: Bilateral segmentation network for real-time semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 325–341. [Google Scholar]
- Yu, C.; Gao, C.; Wang, J.; Yu, G.; Shen, C.; Sang, N. BiSeNet V2: Bilateral Network with Guided Aggregation for Real-time Semantic Segmentation. arXiv 2020, arXiv:2004.02147. [Google Scholar] [CrossRef]
- Cheng, H.; Zhang, Y.; Xu, H.; Li, D.; Zhong, Z.; Zhao, Y.; Yan, Z. MSGU-Net: A lightweight multi-scale Ghost U-Net for image segmentation. Front. Neurorobotics 2025, 18, 1480055. [Google Scholar] [CrossRef]
- Sawant, S.S.; Medgyesy, A.; Raghunandan, S.; Götz, T. LMSC-UNet: A Lightweight U-Net with Modified Skip Connections for Semantic Segmentation. In Proceedings of the 17th International Conference on Agents and Artificial Intelligence, Porto, Portugal, 23–25 February 2025; pp. 726–734. [Google Scholar] [CrossRef]
- Rosas-Arias, L.; Benitez-Garcia, G.; Portillo-Portillo, J.; Sánchez-Pérez, G.; Yanai, K. Fast and Accurate Real-Time Semantic Segmentation with Dilated Asymmetric Convolutions. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021. [Google Scholar]
- Wu, B.; Xiong, X.; Wang, Y. Real-Time Semantic Segmentation Algorithm for Street Scenes Based on Attention Mechanism and Feature Fusion. Electronics 2024, 13, 3699. [Google Scholar] [CrossRef]
- Guo, Z.; Ma, D.; Luo, X. Lightweight Semantic Segmentation Algorithm Integrating Coordinate and ECA-Net Modules. Optoelectron. Lett. 2024, 20, 568. [Google Scholar] [CrossRef]
- Kwon, Y.; Kim, W.; Kim, H. HARD: Hardware-Aware Lightweight Real-Time Semantic Segmentation Model Deployable from Edge to GPU. In Proceedings of the 17th Asian Conference on Computer Vision (ACCV), Hanoi, Vietnam, 8–12 December 2024; pp. 252–269. [Google Scholar] [CrossRef]
- Kaabi, R.; Bouchouicha, M.; Mouelhi, A.; Sayadi, M.; Moreau, E. An Efficient Smoke Detection Algorithm Based on Deep Belief Network Classifier using Energy and Intensity Features. Electronics 2020, 9, 1390. [Google Scholar] [CrossRef]
- Buslaev, A.; Iglovikov, V.I.; Khvedchenya, E.; Parinov, A.; Druzhinin, M.; Kalinin, A.A. Albumentations: Fast and flexible image augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Configuration | mIoU (%) | #Params (M) ↓ | GFLOPs ↓ | FPS ↑ | |||
|---|---|---|---|---|---|---|---|
| Smoke100k | DS01 | Fire Smoke | Quarry Smoke | ||||
| Baseline | 72.40 ± 0.08 | 70.83 ± 0.06 | 70.45 ± 0.11 | 69.12 ± 0.05 | 0.42 | 0.24 | 54.25 |
| + Multiscale | 72.19 ± 0.10 | 69.78 ± 0.05 | 67.22 ± 0.07 | 63.71 ± 0.06 | 0.23 | 0.08 | 128.65 |
| + MultiviewAttn | 73.81 ± 0.07 | 71.53 ± 0.12 | 69.62 ± 0.04 | 67.74 ± 0.10 | 0.71 | 0.12 | 56.03 |
| + LayerLoss | 70.75 ± 0.09 | 67.45 ± 0.06 | 66.16 ± 0.08 | 63.52 ± 0.07 | 0.42 | 0.24 | 54.25 |
| + Multiscale + LayerLoss | 72.24 ± 0.04 | 71.41 ± 0.05 | 68.95 ± 0.08 | 66.67 ± 0.07 | 0.23 | 0.08 | 128.65 |
| + MultiviewAttn + LayerLoss | 74.10 ± 0.07 | 73.14 ± 0.06 | 72.24 ± 0.05 | 71.67 ± 0.08 | 0.71 | 0.12 | 56.03 |
| + Multiscale + MultiviewAttn | 75.63 ± 0.05 | 73.83 ± 0.09 | 71.22 ± 0.06 | 70.34 ± 0.07 | 0.34 | 0.07 | 77.05 |
| Full Model (SmokeNet) | 76.45 ± 0.10 | 74.43 ± 0.04 | 73.43 ± 0.03 | 72.74 ± 0.06 | 0.34 | 0.07 | 77.05 |
| Methods | mIoU (%) | #Params (M) ↓ | GFLOPs ↓ | FPS ↑ | |||
|---|---|---|---|---|---|---|---|
| Smoke100k | DS01 | Fire Smoke | Quarry Smoke | ||||
| UNet (2015) | 66.13 ± 0.10 | 61.32 ± 0.08 | 60.14 ± 0.06 | 57.18 ± 0.05 | 28.24 | 35.24 | 75.58 |
| UNet++ (2018) | 69.12 ± 0.09 | 64.65 ± 0.04 | 61.77 ± 0.10 | 58.44 ± 0.06 | 9.16 | 10.72 | 91.25 |
| AttentionUNet (2018) | 69.68 ± 0.05 | 66.59 ± 0.12 | 64.15 ± 0.07 | 59.64 ± 0.09 | 31.55 | 37.83 | 46.48 |
| UNeXt-S (2022) | 72.25 ± 0.11 | 71.62 ± 0.07 | 69.59 ± 0.12 | 64.54 ± 0.04 | 0.77 | 0.08 | 202.06 |
| MobileViTv2 (2022) | 71.73 ± 0.10 | 71.54 ± 0.07 | 70.23 ± 0.04 | 69.12 ± 0.11 | 2.30 | 0.09 | 98.84 |
| MALUNet (2022) | 71.81 ± 0.05 | 70.16 ± 0.10 | 69.42 ± 0.04 | 67.64 ± 0.07 | 0.17 | 0.09 | 87.72 |
| ERFNet (2017) | 71.84 ± 0.09 | 71.38 ± 0.10 | 66.59 ± 0.06 | 66.24 ± 0.07 | 2.06 | 3.32 | 61.22 |
| LEDNet (2019) | 70.76 ± 0.10 | 71.63 ± 0.07 | 70.13 ± 0.08 | 67.74 ± 0.11 | 0.91 | 1.41 | 60.19 |
| DFANet (2019) | 66.91 ± 0.05 | 63.87 ± 0.10 | 62.76 ± 0.07 | 70.21 ± 0.09 | 2.18 | 0.44 | 31.05 |
| CGNet (2020) | 75.64 ± 0.07 | 73.76 ± 0.11 | 72.04 ± 0.10 | 71.91 ± 0.08 | 0.49 | 0.86 | 53.53 |
| DSS (2019) | 73.25 ± 0.05 | 72.17 ± 0.04 | 69.78 ± 0.12 | 69.81 ± 0.07 | 30.20 | 184.90 | 32.56 |
| Frizzi (2021) [9] | 73.44 ± 0.06 | 71.67 ± 0.09 | 70.51 ± 0.07 | 70.40 ± 0.11 | 20.17 | 27.90 | 60.32 |
| Yuan (2023) [10] | 75.57 ± 0.07 | 74.84 ± 0.06 | 71.94 ± 0.10 | 70.92 ± 0.08 | 0.88 | 1.15 | 68.81 |
| SmokeNet | 76.45 ± 0.10 | 74.43 ± 0.04 | 73.43 ± 0.03 | 72.74 ± 0.06 | 0.34 | 0.07 | 77.05 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Ientilucci, E.J. Efficient Smoke Segmentation Using Multiscale Convolutions and Multiview Attention Mechanisms. Electronics 2025, 14, 2593. https://doi.org/10.3390/electronics14132593
Liu X, Ientilucci EJ. Efficient Smoke Segmentation Using Multiscale Convolutions and Multiview Attention Mechanisms. Electronics. 2025; 14(13):2593. https://doi.org/10.3390/electronics14132593
Chicago/Turabian StyleLiu, Xuesong, and Emmett J. Ientilucci. 2025. "Efficient Smoke Segmentation Using Multiscale Convolutions and Multiview Attention Mechanisms" Electronics 14, no. 13: 2593. https://doi.org/10.3390/electronics14132593
APA StyleLiu, X., & Ientilucci, E. J. (2025). Efficient Smoke Segmentation Using Multiscale Convolutions and Multiview Attention Mechanisms. Electronics, 14(13), 2593. https://doi.org/10.3390/electronics14132593