
YOLO-LSDI: An Enhanced Algorithm for Steel Surface Defect Detection Using a YOLOv11 Network


Abstract
1. Introduction
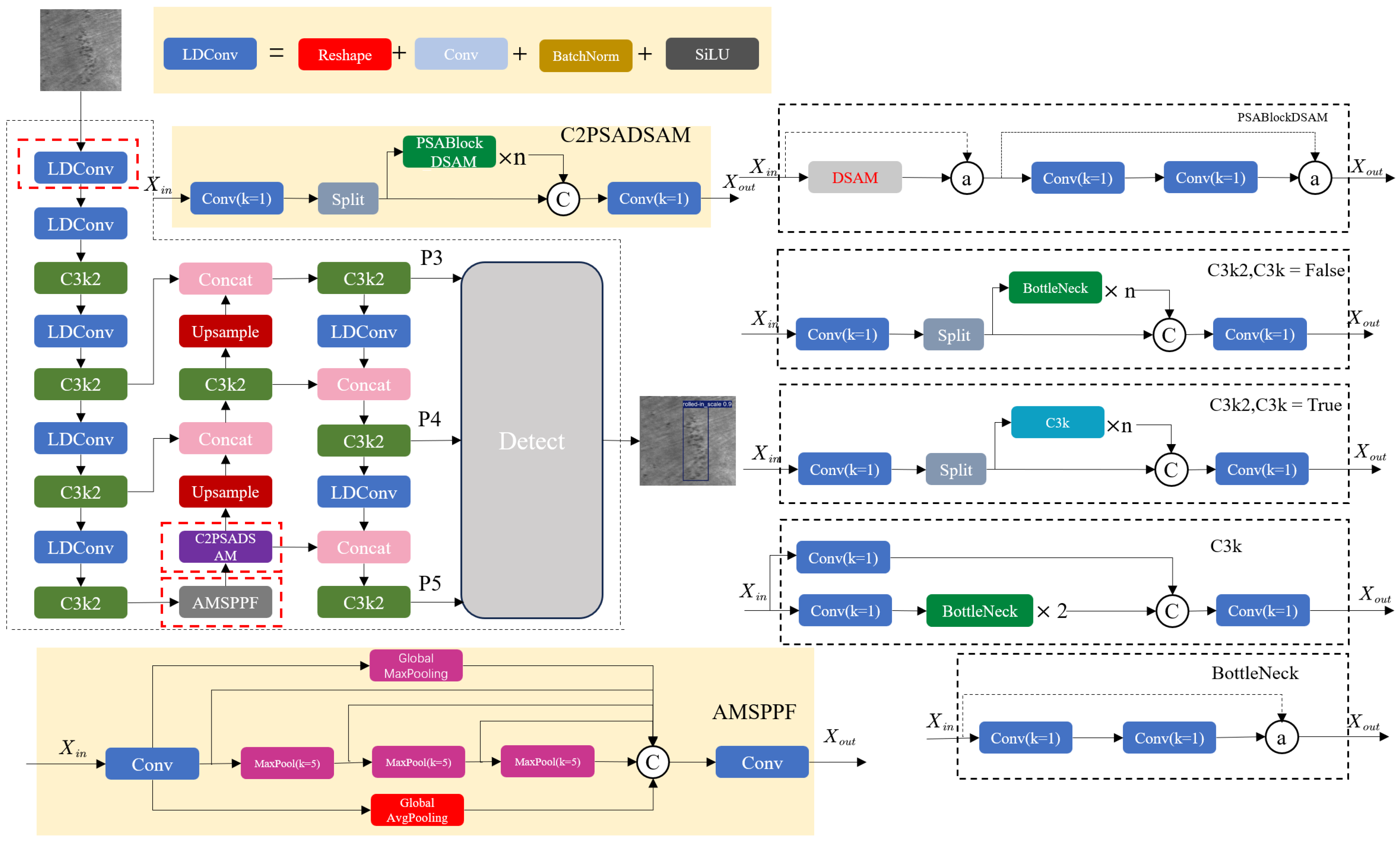
- An Adaptive Multi-Scale Pooling–Fast module (AMSPPF) is introduced to better capture both global semantic context and local edge features by fusing global average pooling (GAP) and global max pooling (GMP). Unlike the original SPPF in YOLOv11, which primarily focuses on fixed-scale local features, AMSPPF provides a broader receptive field and enhanced sensitivity to contour information. This is particularly effective for detecting defects with varying scales and low visual contrast. Experimental results show that AMSPPF contributes to a 2.2% improvement in mAP@0.5 and a 0.8% improvement in mAP@0.5:0.95 on the NEU-DET dataset, along with a 3.8% improvement in the F1-score.
- A Deformable Spatial Attention Module (DSAM) is proposed, combining deformable bi-level attention with a spatial attention mechanism. This hybrid design allows the network to dynamically focus on defect-relevant regions while preserving spatial detail. This proves especially beneficial for fine-grained discrimination of visually similar defect types and in mitigating interference from complex backgrounds—challenges often encountered in steel surface inspection. Integrated into the backbone alongside the C2PSA module, DSAM leads to a further 0.4% improvement in mAP@0.5, a further 0.1% improvement in mAP@0.5:0.95, and a further 0.2% improvement in the F1-score, validating its effectiveness in enhancing feature expressiveness.
- We introduce Linear Deformable Convolution (LDConv) to replace the standard convolutional layers in YOLOv11. Unlike fixed receptive fields, LDConv learns spatial offsets to adapt to the irregular shapes of steel defects, enhancing localization and classification. Moreover, LDConv maintains efficiency through a lightweight design, reducing computational cost. GFLOPs dropped from 6.4 to 6.1, while mAP@0.5 increased by an additional 2.0%, mAP@0.5:0.95 improved by 0.7%, and the F1-score rose 1.0%, achieving higher accuracy without compromising real-time performance.
- We replace the traditional Complete-IoU (CIoU) loss function with the Inner-CIoU, a refined variant that incorporates a scaling factor to regulate the auxiliary box in IoU computation. This design addresses issues such as slow convergence and suboptimal localization accuracy, especially critical when detecting overlapping or small-scale defects under cluttered industrial backgrounds. The proposed loss function accelerates training and stabilizes regression performance, contributing an additional 1.2% improvement in mAP@0.5, a further 0.8% improvement in mAP@0.5:0.95, and a 1.2% improvement in the F1-score while also boosting inference speed to 162.1 FPS. Cumulatively, these enhancements yield a total mAP@0.5 improvement of 5.8% and an mAP@0.5:0.95 improvement of 2.4%, demonstrating the robustness of the proposed framework.
- We validate the generalization ability of our model across multiple industrial defect datasets, including NEU-DET (steel), GC-DET (steel), APSPC (aluminum), and a PCB surface defect dataset. Experimental results indicate consistent and superior performance across domains, with mAP@0.5 improvements of 4.2, 2.1, and 3.1%, respectively, mAP@0.5:0.95 improvements of 1.1, 1.5, and 1.3%, and F1-score improvements of 4.2, 3.3, and 1.5% compared to existing state-of-the-art methods. These findings underline the practical value and deployment potential of the proposed system in diverse real-world inspection scenarios.
2. Materials and Methods
2.1. Experimental Dataset
2.1.1. Dataset Source
2.1.2. Dataset Analysis
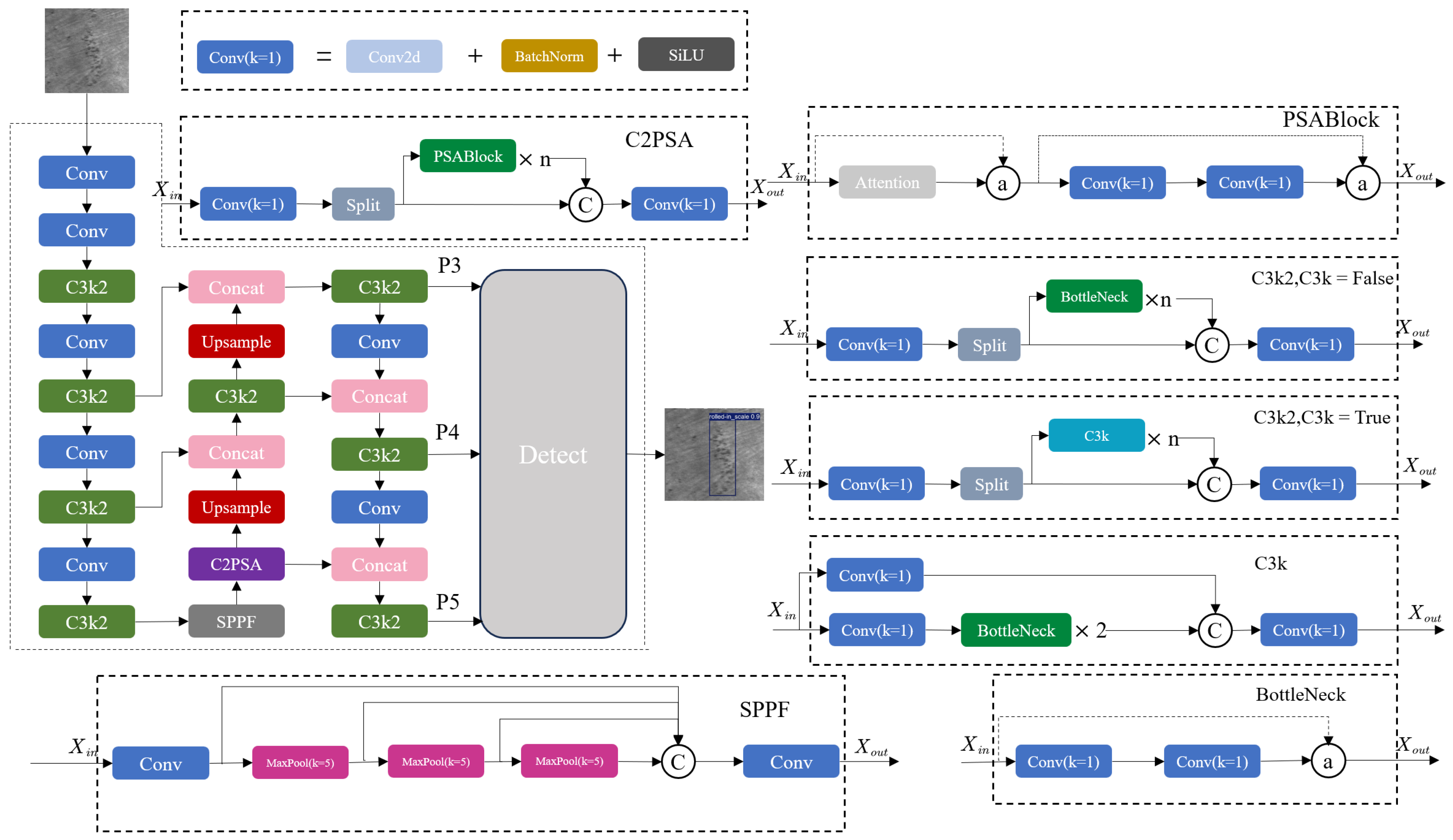
2.2. YOLOv11 Algorithm
2.3. YOLO-LSDI Algorithm
2.3.1. A New Spatial Pyramid Module: AMSPPF
2.3.2. New Module Based on C2PSA: C2PSA-DSAM
2.3.3. Introducing LDConv
2.3.4. Inner-CIoU Loss
3. Results
3.1. Experimental Setup and Training Parameters
3.2. Evaluation Metrics
3.3. Ablation Experiments
- Single-strategy optimization scheme: This scheme primarily evaluated the impact of using a single strategy to improve the detection performance of the original model.
- Combined-strategy optimization scheme: This scheme primarily evaluated the impact of combining different strategies to optimize the detection performance of the original model.
3.4. Attention Heatmap Visualization of Module Improvements
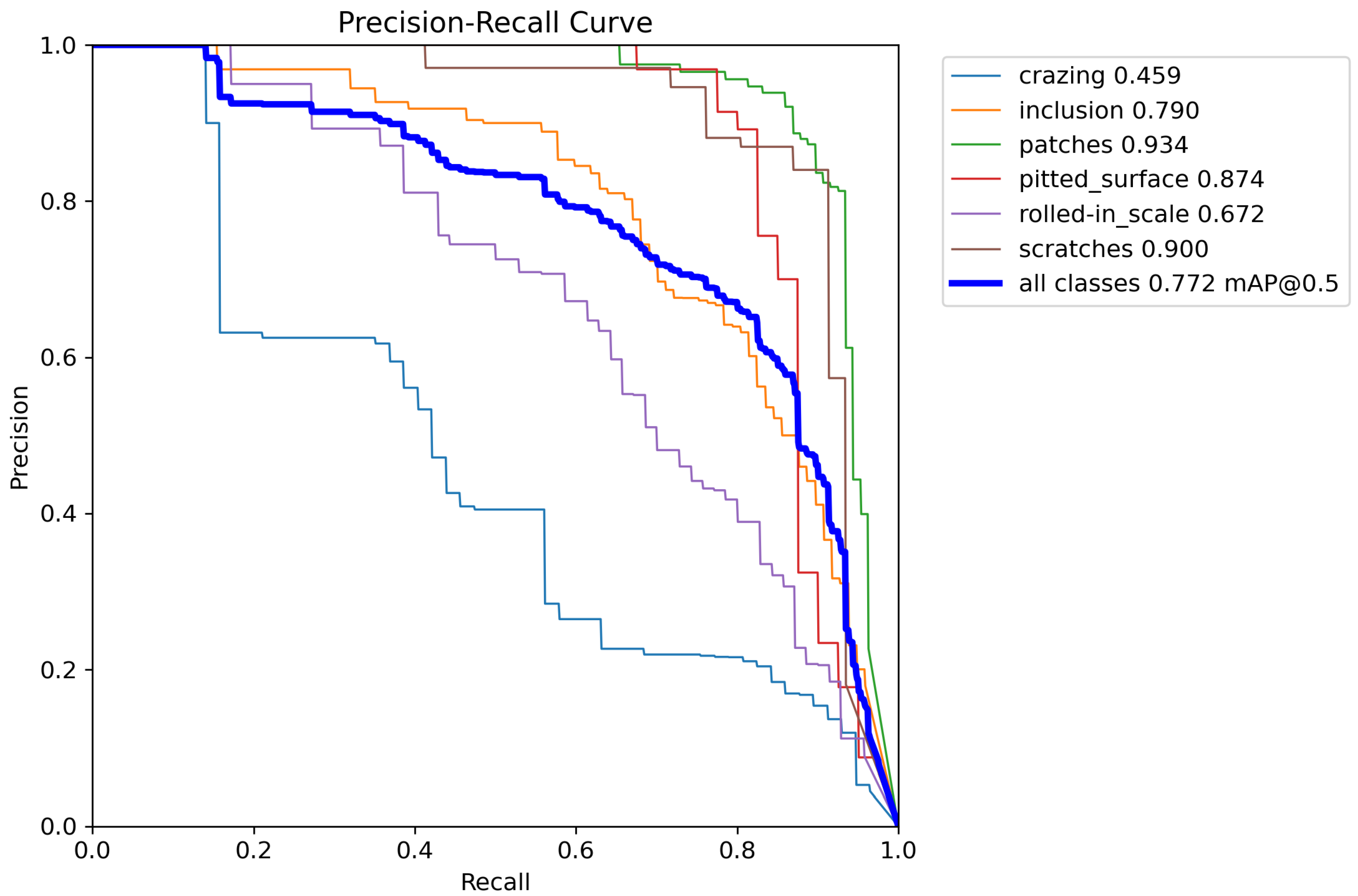
3.5. Precision–Recall Curves and Visual Predictions
3.6. Confusion Matrix and Class-Wise Performance
3.7. Performance of the YOLO-LSDI Algorithm on Multiple Datasets
3.8. Comparison with Mainstream Object-Detection Algorithms
4. Discussion
4.1. Findings and Implications
4.2. Limitations and Future Research Directions
- Impact of Image Quantity and Quality on Detection Performance: Surface defect detection in deep learning frameworks hinges heavily on the number and clarity of images for enhanced performance. Regarding the issue of small-sample datasets, widely used traditional data augmentation methods, such as single-image and multi-image augmentation, are often limited to simple transformations of the original data, which may not effectively enhance the diversity in the feature space of the dataset. Future work could leverage the exceptional image-generation capabilities of models like Generative Adversarial Networks (GANs) to generate highly realistic and diverse steel surface defect images. Moreover, improving image quality should start at the source, with a focus on obtaining high-quality images. Methods like image denoising could be considered to reduce information loss and improve image quality.
- Improvement of the YOLO-LSDI Algorithm: Although the proposed YOLO-LSDI algorithm resulted in some performance improvements, and strategies have been suggested to enhance its lightweight nature and generalization ability, most steel defect-detection tasks are performed in industrial environments with limited resources. These environments impose high demands on model performance, and the current work may not meet the specific requirements of certain scenarios. Therefore, future research may enhance the model using methods like pruning and knowledge distillation to better address industrial defect-detection requirements.
- Considerations for Industrial Deployment and Domain Adaptation: In real-world applications, steel surface defect-detection models are often required to operate on edge devices (e.g., NVIDIA Jetson Nano) with limited computational and memory resources. To meet these constraints, future work will consider conducting edge-deployment experiments and adopting model acceleration techniques such as quantization and TensorRT optimization. Additionally, due to the variability in steel production processes and imaging conditions across different plant sites, the generalization ability of the model becomes critical. Domain adaptation strategies—such as feature distribution alignment, adversarial training, or self-supervised domain-invariant learning—will be explored to enable the model to adapt effectively to unseen domains without extensive retraining. These efforts aim to close the gap between lab-level performance and industrial-level robustness.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| NEU-DET | Northeastern University surface defect database for defect-detection tasks |
| PCB | Printed circuit board |
| PSA | Pyramid Spatial Attention |
| C2PSA | Convolutional block with Parallel Spatial Attention |
| DSAM | Deformable Spatial Attention Module |
| LDConv | Linear Deformable Convolution |
References
- Wang, X.; Wang, Z.; Guo, C.; Han, Y.; Zhao, J.; Lu, N.; Tang, H. Application and Prospect of New Steel Corrugated Plate Technology in Infrastructure Fields. IOP Conf. Ser. Mater. Sci. Eng. 2020, 741, 012099. [Google Scholar] [CrossRef]
- Yao, X.; Zhou, J.; Zhang, J.; Boer, C.R. From Intelligent Manufacturing to Smart Manufacturing for Industry 4.0 Driven by Next Generation Artificial Intelligence and Further On. In Proceedings of the 2017 5th International Conference on Enterprise Systems (ES), Beijing, China, 22–24 September 2017. [Google Scholar]
- Neogi, N.; Mohanta, D.K.; Dutta, P.K. Review of vision-based steel surface inspection systems. EURASIP J. Image Video Process. 2014, 2014, 50. [Google Scholar] [CrossRef]
- Vasan, V.; Sridharan, N.V.; Vaithiyanathan, S.; Aghaei, M. Detection and classification of surface defects on hot-rolled steel using vision transformers. Heliyon 2024, 10, e38498. [Google Scholar] [CrossRef] [PubMed]
- Zhao, B.; Chen, Y.; Jia, X.; Ma, T. Steel surface defect detection algorithm in complex background scenarios. Measurement 2024, 237, 115189. [Google Scholar] [CrossRef]
- Gao, X. Research on automated defect detection system based on computer vision. Appl. Comput. Eng. 2024, 101, 192–197. [Google Scholar] [CrossRef]
- Beyerer, J.; León, F.P.; Frese, C. Machine Vision: Automated Visual Inspection: Theory, Practice and Applications; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Kumar, G.; Bhatia, P.K. A detailed review of feature extraction in image processing systems. In Proceedings of the 2014 Fourth International Conference on Advanced Computing & Communication Technologies, Rohtak, India, 8–9 February 2014; pp. 5–12. [Google Scholar]
- Song, W.; Chen, T.; Gu, Z.; Gai, W.; Huang, W.; Wang, B. Wood materials defects detection using image block percentile color histogram and eigenvector texture feature. In Proceedings of the First International Conference on Information Sciences, Machinery, Materials and Energy, Chongqing, China, 11–13 April 2015; Atlantis Press: Dordrecht, The Netherlands, 2015; pp. 779–783. [Google Scholar]
- Ma, N.; Gao, X.; Wang, C.; Zhang, Y.; You, D.; Zhang, N. Influence of hysteresis effect on contrast of welding defects profile in magneto-optical image. IEEE Sens. J. 2020, 20, 15034–15042. [Google Scholar] [CrossRef]
- Wang, F.l.; Zuo, B. Detection of surface cutting defect on magnet using Fourier image reconstruction. J. Cent. South Univ. 2016, 23, 1123–1131. [Google Scholar] [CrossRef]
- Li, J.H.; Quan, X.X.; Wang, Y.L. Research on defect detection algorithm of ceramic tile surface with multi-feature fusion. Comput. Eng. Appl 2020, 56, 191–198. [Google Scholar]
- Chang, C.F.; Wu, J.L.; Chen, K.J.; Hsu, M.C. A hybrid defect detection method for compact camera lens. Adv. Mech. Eng. 2017, 9, 1687814017722949. [Google Scholar] [CrossRef]
- Liu, Y.; Xu, K.; Xu, J. An improved MB-LBP defect recognition approach for the surface of steel plates. Appl. Sci. 2019, 9, 4222. [Google Scholar] [CrossRef]
- Putri, A.P.; Rachmat, H.; Atmaja, D.S.E. Design of automation system for ceramic surface quality control using fuzzy logic method at Balai Besar Keramik (BBK). In Proceedings of the MATEC Web of Conferences, Malacca, Malaysia, 25–27 February 2017; EDP Sciences: Les Ulis, France, 2017; Volume 135, p. 00053. [Google Scholar]
- Gao, X.; Xie, Y.; Chen, Z.; You, D. Fractal feature detection of high-strength steel weld defects by magneto optical imaging. Trans. China Weld. Inst. 2017, 38, 1–4. [Google Scholar]
- Jimenez-del Toro, O.; Otálora, S.; Andersson, M.; Eurén, K.; Hedlund, M.; Rousson, M.; Müller, H.; Atzori, M. Analysis of histopathology images: From traditional machine learning to deep learning. In Biomedical Texture Analysis; Elsevier: Amsterdam, The Netherlands, 2017; pp. 281–314. [Google Scholar]
- Zhao, X.; Wang, L.; Zhang, Y.; Han, X.; Deveci, M.; Parmar, M. A review of convolutional neural networks in computer vision. Artif. Intell. Rev. 2024, 57, 99. [Google Scholar] [CrossRef]
- He, Y.; Song, K.; Meng, Q.; Yan, Y. An end-to-end steel surface defect detection approach via fusing multiple hierarchical features. IEEE Trans. Instrum. Meas. 2019, 69, 1493–1504. [Google Scholar] [CrossRef]
- Damacharla, P.; Rao, A.; Ringenberg, J.; Javaid, A.Y. TLU-net: A deep learning approach for automatic steel surface defect detection. In Proceedings of the 2021 International Conference on Applied Artificial Intelligence (ICAPAI), Halden, Norway, 19–21 May 2021; pp. 1–6. [Google Scholar]
- Bhatt, P.M.; Malhan, R.K.; Rajendran, P.; Shah, B.C.; Thakar, S.; Yoon, Y.J.; Gupta, S.K. Image-based surface defect detection using deep learning: A review. J. Comput. Inf. Sci. Eng. 2021, 21, 040801. [Google Scholar] [CrossRef]
- Zhao, W.; Chen, F.; Huang, H.; Li, D.; Cheng, W. A new steel defect detection algorithm based on deep learning. Comput. Intell. Neurosci. 2021, 2021, 5592878. [Google Scholar] [CrossRef]
- Liu, Q.; Wang, C.; Li, Y.; Gao, M.; Li, J. A fabric defect detection method based on deep learning. IEEE Access 2022, 10, 4284–4296. [Google Scholar] [CrossRef]
- Zhao, C.; Shu, X.; Yan, X.; Zuo, X.; Zhu, F. RDD-YOLO: A modified YOLO for detection of steel surface defects. Measurement 2023, 214, 112776. [Google Scholar] [CrossRef]
- Yi, F.; Zhang, H.; Yang, J.; He, L.; Mohamed, A.S.A.; Gao, S. YOLOv7-SiamFF: Industrial defect detection algorithm based on improved YOLOv7. Comput. Electr. Eng. 2024, 114, 109090. [Google Scholar] [CrossRef]
- Xie, W.; Sun, X.; Ma, W. A light weight multi-scale feature fusion steel surface defect detection model based on YOLOv8. Meas. Sci. Technol. 2024, 35, 055017. [Google Scholar] [CrossRef]
- Zou, J.; Wang, H. Steel Surface Defect Detection Method Based on Improved YOLOv9 Network. IEEE Access 2024, 12, 124160–124170. [Google Scholar] [CrossRef]
- Ruengrote, S.; Kasetravetin, K.; Srisom, P.; Sukchok, T.; Kaewdook, D. Design of Deep Learning Techniques for PCBs Defect Detecting System based on YOLOv10. Eng. Technol. Appl. Sci. Res. 2024, 14, 18741–18749. [Google Scholar] [CrossRef]
- Tang, H.; Li, Z.; Zhang, D.; He, S.; Tang, J. Divide-and-Conquer: Confluent Triple-Flow Network for RGB-T Salient Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2025, 47, 1958–1974. [Google Scholar] [CrossRef] [PubMed]
- Bao, Y.; Song, K.; Liu, J.; Wang, Y.; Yan, Y.; Yu, H.; Li, X. Triplet-Graph Reasoning Network for Few-Shot Metal Generic Surface Defect Segmentation. IEEE Trans. Instrum. Meas. 2021, 70, 5011111. [Google Scholar] [CrossRef]
- Khanam, R.; Hussain, M. Yolov11: An overview of the key architectural enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Qiu, J. Ultralytics YOLO, Version 8.0.0. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 14 June 2025).
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-time end-to-end object detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; Kwon, Y.; Michael, K.; Fang, J.; Yifu, Z.; Wong, C.H.; Montes, D.; et al. YOLOv5 by Ultralytics, Version 7.0. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 14 June 2025).
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zhu, L.; Wang, X.; Ke, Z.; Zhang, W.; Lau, R.W. Biformer: Vision transformer with bi-level routing attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 10323–10333. [Google Scholar]
- Zhang, X.; Song, Y.; Song, T.; Yang, D.; Ye, Y.; Zhou, J.; Zhang, L. LDConv: Linear deformable convolution for improving convolutional neural networks. Image Vis. Comput. 2024, 149, 105190. [Google Scholar] [CrossRef]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. Unitbox: An advanced object detection network. In Proceedings of the 24th ACM international conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 516–520. [Google Scholar]
- Zheng, Z.; Wang, P.; Ren, D.; Liu, W.; Ye, R.; Hu, Q.; Zuo, W. Enhancing geometric factors in model learning and inference for object detection and instance segmentation. IEEE Trans. Cybern. 2021, 52, 8574–8586. [Google Scholar] [CrossRef]
- Zhang, H.; Xu, C.; Zhang, S. Inner-IoU: More effective intersection over union loss with auxiliary bounding box. arXiv 2023, arXiv:2311.02877. [Google Scholar]
- Lv, X.; Duan, F.; Jiang, J.j.; Fu, X.; Gan, L. Deep Metallic Surface Defect Detection: The New Benchmark and Detection Network. Sensors 2020, 20, 1562. [Google Scholar] [CrossRef] [PubMed]
- Huang, W.; Wei, P. A PCB Dataset for Defects Detection and Classification. arXiv 2019, arXiv:1901.08204. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequence | AMSPPF | C2PSA-DSAM | LDConv | Inner-CIoU | Params | GFLOPs | mAP@0.5 | mAP@0.5:0.95 | F1 | FPS |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | - | - | - | - | 2.5 | 6.4 | 77.2 | 45.6 | 72.1 | 158.3 |
| 2 | ✓ | 2.6 | 6.4 | 79.4 | 46.4 | 75.9 | 163.9 | |||
| 3 | ✓ | 2.8 | 6.4 | 78.8 | 45.8 | 74.1 | 171.2 | |||
| 4 | ✓ | 2.4 | 6.0 | 80.5 | 46.9 | 75.9 | 150.8 | |||
| 5 | ✓ | 2.5 | 6.4 | 78.9 | 46.1 | 73.8 | 195.1 | |||
| 6 | ✓ | ✓ | ✓ | 2.7 | 6.1 | 81.8 | 47.2 | 77.1 | 135.6 | |
| 7 | ✓ | ✓ | ✓ | 2.9 | 6.4 | 79.8 | 46.5 | 76.1 | 207.3 | |
| 8 | ✓ | ✓ | ✓ | 2.4 | 6.1 | 81.1 | 47.0 | 76.8 | 142.8 | |
| 9 | ✓ | ✓ | ✓ | 2.7 | 6.1 | 80.8 | 46.6 | 76.2 | 157.2 | |
| 10 | ✓ | ✓ | ✓ | ✓ | 2.7 | 6.1 | 83.0 | 48.0 | 78.3 | 162.1 |
| Dataset | Model | Params (M) | GFLOPs | mAP@0.5 (%) | mAP@0.5:0.95 (%) | F1 (%) | FPS |
|---|---|---|---|---|---|---|---|
| GC10-DET | YOLOv11n | 2.5 | 6.4 | 62.3 | 35.7 | 58.0 | 141.4 |
| YOLO-LSDI | 2.6 | 6.1 | 66.5 | 36.8 | 62.2 | 156.3 | |
| APSPC | YOLOv11n | 2.5 | 6.4 | 52.1 | 27.2 | 50.1 | 182.4 |
| YOLO-LSDI | 2.6 | 6.1 | 54.2 | 28.7 | 53.4 | 190.7 | |
| PCB | YOLOv11n | 2.5 | 6.4 | 88.3 | 47.5 | 88.7 | 155.5 |
| YOLO-LSDI | 2.6 | 6.1 | 91.4 | 48.8 | 90.2 | 175.1 |
| Model | Params (M) | GFLOPs | mAP@0.5 (%) | mAP@0.5:0.95 (%) | F1 (%) | FPS |
|---|---|---|---|---|---|---|
| Faster R-CNN | 136.8 | 251.4 | 76.8 | 43.7 | 68.0 | 45.2 |
| SSD300 | 24.2 | 71.5 | 72.9 | 40.2 | 59.7 | 142.1 |
| Deformable DETR | 34.2 | 78.0 | 71.6 | 40.1 | 69.7 | 118.7 |
| RT-DETR-R18 | 19.5 | 99.8 | 72.8 | 38.6 | 71.2 | 145.7 |
| YOLOv5s | 7.0 | 16.0 | 74.3 | 42.3 | 70.7 | 136.3 |
| YOLOv7tiny | 6.0 | 13.2 | 68.1 | 35.9 | 67.3 | 135.2 |
| YOLOv8n | 3.0 | 8.9 | 76.3 | 46.1 | 73.6 | 158.3 |
| YOLOv9s | 7.2 | 26.5 | 78.6 | 47.5 | 73.7 | 106.5 |
| YOLO-MS-XS | 4.5 | 8.8 | 77.9 | 48.2 | 74.0 | 141.6 |
| YOLOv10s | 8.0 | 24.5 | 70.7 | 40.5 | 68.3 | 180.1 |
| YOLOv10n | 2.7 | 8.2 | 73.7 | 41.8 | 69.1 | 220.7 |
| YOLOv11n | 2.5 | 6.4 | 77.2 | 45.6 | 72.1 | 158.3 |
| YOLO-LSDI | 2.7 | 6.1 | 83.0 | 48.0 | 78.3 | 162.1 |
| Model | AP (%) | |||||
|---|---|---|---|---|---|---|
| Cr | In | Pa | Ps | Rs | Sc | |
| Faster R-CNN | 44.1 | 87.4 | 93.0 | 87.7 | 62.3 | 93.3 |
| SSD300 | 37.6 | 82.3 | 91.0 | 82.3 | 62.6 | 83.5 |
| Deformable DETR | 27.6 | 80.2 | 88.9 | 75.1 | 60.9 | 78.4 |
| RT-DETR-R18 | 24.8 | 79.3 | 90.7 | 77.6 | 51.8 | 84.0 |
| YOLOv5s | 46.8 | 78.8 | 91.6 | 73.4 | 65.9 | 89.2 |
| YOLOv7tiny | 39.4 | 75.6 | 88.5 | 81.5 | 43.6 | 79.8 |
| YOLOv8n | 52.7 | 83.3 | 94.6 | 78.9 | 69.0 | 79.6 |
| YOLOv9s | 44.7 | 88.3 | 91.2 | 90.5 | 62.6 | 88.9 |
| YOLO-MS-XS | 50.7 | 87.5 | 90.2 | 87.1 | 66.9 | 90.5 |
| YOLOv10s | 26.7 | 78.6 | 88.7 | 80.1 | 63.6 | 86.2 |
| YOLOv10n | 43.9 | 71.3 | 87.7 | 83.9 | 69.0 | 86.4 |
| YOLOv11n | 45.9 | 79.0 | 93.4 | 87.4 | 67.2 | 90.0 |
| YOLO-LSDI | 54.8 | 90.2 | 95.8 | 87.5 | 77.6 | 92.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, F.; Jiang, X.; Han, Y.; Wu, L. YOLO-LSDI: An Enhanced Algorithm for Steel Surface Defect Detection Using a YOLOv11 Network. Electronics 2025, 14, 2576. https://doi.org/10.3390/electronics14132576
Wang F, Jiang X, Han Y, Wu L. YOLO-LSDI: An Enhanced Algorithm for Steel Surface Defect Detection Using a YOLOv11 Network. Electronics. 2025; 14(13):2576. https://doi.org/10.3390/electronics14132576
Chicago/Turabian StyleWang, Fuqiang, Xinbin Jiang, Yizhou Han, and Lei Wu. 2025. "YOLO-LSDI: An Enhanced Algorithm for Steel Surface Defect Detection Using a YOLOv11 Network" Electronics 14, no. 13: 2576. https://doi.org/10.3390/electronics14132576
APA StyleWang, F., Jiang, X., Han, Y., & Wu, L. (2025). YOLO-LSDI: An Enhanced Algorithm for Steel Surface Defect Detection Using a YOLOv11 Network. Electronics, 14(13), 2576. https://doi.org/10.3390/electronics14132576