
Advances in NLP Techniques for Detection of Message-Based Threats in Digital Platforms: A Systematic Review


Abstract
1. Introduction
- Has the account of the person I am interacting with been compromised?
- Is this unknown sender a real person acting with malicious intent?
- Could this be part of a manipulation scam or a targeted social engineering attempt?
- Is the sender impersonating someone else?
- Could that profile be fake and controlled by a bot for deceptive purposes?
- RQ1.
- What NLP techniques are employed in threat detection for messaging platforms, and how are LLMs integrated into these approaches, according to recent research?
- RQ2.
- What evaluation strategies are used to measure the effectiveness of these techniques?
- RQ3.
- What types of input are used for online threat detection in recent studies?
- RQ4.
- How can detection efficacy be balanced with privacy, informed consent, and compliance with legal and ethical regulations?
- A characterization of message-based threat detection strategies as reported in the recent scientific literature and the extent to which LLMs are involved;
- Understand whether there is standardization or not of the evaluation strategies of contemporary approaches;
- Determine the monitoring scope selected in research for threat detection;
- How current research addresses new challenges regarding ethics and privacy in the use of data in a real-world scenario.
2. Problem Context
2.1. Message-Based Threats
- Fake profile is a fake online persona designed to mislead or deceive other users. It may involve photos, names, or details copied from other people, or artificially fabricated by AI. It can be operated by a bot, controlled by AI, or directly by a human.
- Impersonation is the malicious use of another person’s identity, by creating a fake profile, or by hacking into an existing legitimate account. By impersonating a celebrity, for example, the attacker may gain advantages and convince victims to provide information while thinking they are actually talking to that person.
- Shaming and cancel culture is the act of explicit criticism towards victims, through comments, group chats, or posts online, either for offensive reasons or in an attempt to shape public opinion against them.
- Pretexing is a form of social engineering in which the victim is confronted with an unreal and unexpected scenario (the pretext), and the attacker tries to manipulate them with persuasive storytelling.
- Social engineering is a manipulation technique that seeks to take advantage of human behavior and psychology and is used to deceive individuals into revealing valuable information, performing actions, or instinctively react in a compromising way.
- Phishing is a form of cyberattack where criminals use forged messages or web content to scam victims into disclosing sensitive information. Usually it comprises two parts: the bait, or deceptive content alluding to some trusted entity, and the hook, or a way of capturing information or inserting malware.
- Spear phishing is a form of phishing targeted at a specific individual or organization, often involving prior research to include credible and personalized elements.
- Smishing is a phishing variant where the attack is conducted via text messages (SMS). The name first S stands for SMS, just like in Vishing, where the V stands for voice call-based phishing.
- Doxing (also referred to as ’doxxing’) is the malicious act of exposing someone’s private or sensitive information in public or within a group, in an unauthorized manner, and with the purpose of harassing or humiliating.
- Spam is the process of sending unsolicited (or simply irrelevant) messages, usually to a large number of recipients. It can be used to send advertising or to spread rumors or misinformation, but it can also be a channel for phishing.
- A scam is a broad class of deliberate fraudulent schemes designed to manipulate victims into losing money, or to obtain control, resources, or valuable information.
- Harmful content, as a threat, is the transmission of material that inflicts emotional, physical, or societal harm or was created through any form of abuse or exploitation.
- Hate speech is a form of harmful content that promotes hostility against individuals or groups.
2.2. Landscape of NLP and AI
2.2.1. NLP
2.2.2. ML and DL
2.2.3. LLMs
3. Methodology
3.1. Search Strategy
3.1.1. Data Sources
3.1.2. Selection Criteria
- Inclusion criteria:
- Relevance to the research questions;
- Conference or journal articles;
- Indexed in at least one of the selected databases (Section 3.1.1);
- Published within the time frame defined for this review;
- Written in English.
- Exclusion criteria:
- The publication date falls outside the time frame defined for this review;
- The report is a pre-print, review, or meta-analysis paper;
- After abstract or full-text screening, a study is excluded when outside the scope of the review and not aligned with the research questions;
- The document does not allow retrieval of at least half of the analysis items specified in Section 3.2;
- The full text of the document is not accessible through academic channels and is restricted behind a paywall;
- The document is inaccessible due to legal or technical constraints.
3.2. Data Extraction
- Targeted threats: the specific types of malicious intent or threats that the research aims to detect.
- Approach: general type of process, such as classification on text or image, sentiment analysis, regression, or other.
- Model architecture: the type and architecture of the AI model used for threat detection (ML, DL, Transformer-based, LLM, rule-based or other).
- Preprocessing: the transformation steps applied to raw data.
- Text representation: how the text is converted into a model appropriate input, such as Bag of Words (BoW), Term Frequency–Inverse Document Frequency (TF-IDF), n-grams, word embeddings, or contextualized embeddings.
- Detection features: type of features considered in threat detection, text-based, or not (as behavioral features or network connections-based data).
- Supported language: the language(s) for which the paper’s detection techniques were explicitly designed or evaluated.
- Input scope: the type of data sources analyzed for threat detection.
- Evaluation: the assessment form and obtained results.
- Limitations: the researched approach caveats as identified by the authors of the paper.
- Future directions: the suggestions for improvements or research next steps proposed by the authors.
- Deployment platform: the specific messaging platforms or environments where the threat detection techniques are applied.
- Datasets: description of the datasets used for training and evaluating.
- Real time: whether the research proposal is feasible for real-time detection.
- Implementation tools: tools, libraries, or frameworks used for implementation or evaluation.
- Ethical aspects of real-world deployment: considerations regarding ethical implications of deploying the proposed detection methods, including privacy handling, informed consent, or legal compliance to GDPR, CCPA, or other.
4. Results
4.1. Search and Screening

4.2. Analysis of the NLP Techniques Employed
4.3. Analysis of the Use of LLMs
4.4. Analysis of Threat Detection Evaluation Methods
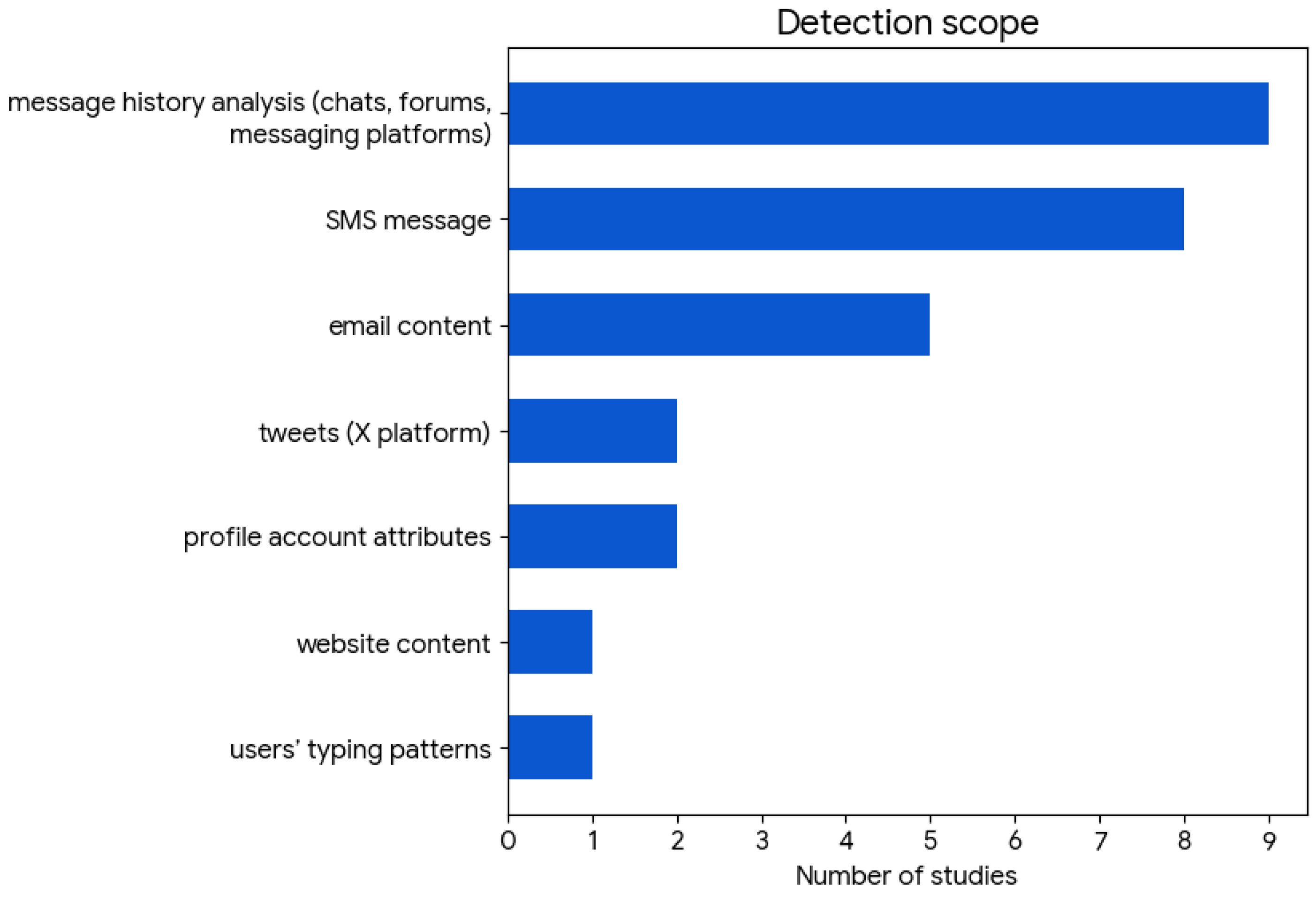
4.5. Analysis of Detection Input Scope
4.6. Analysis of Real-World Applicability and Ethical Compliance
5. Discussion
6. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| AUC | Area Under the ROC Curve |
| BERT | Bidirectional Encoder Representations from Transformers |
| BiLSTM | Bidirectional Long Short-Term Memory |
| CNN | Convolutional Neural Network |
| CTI | Cyberthreat Intelligence |
| DL | Deep Learning |
| DT | Decision Tree |
| F1 | F1-Score (harmonic mean of precision and recall) |
| GPT | Generative Pre-trained Transformer |
| IRB | Institutional Review Board |
| KNN | K-Nearest Neighbors |
| LLM | Large Language Model |
| LR | Logistic Regression |
| LSTM | Long Short-Term Memory |
| ML | Machine Learning |
| MLP | Multilayer Perceptron |
| MSE | Mean Squared Error |
| NB | Naïve Bayes |
| NER | Named Entity Recognition |
| NLP | Natural Language Processing |
| PII | Personally Identifiable Information |
| RAG | Retrieval-Augmented Generation |
| RF | Random Forest |
| RNN | Recurrent Neural Network |
| SMS | Short Message Service (text message) |
| SVM | Support Vector Machine |
Appendix A

{kind=link}
{kind=link}
{kind=link}
| Ref | Targeted Threats | Approach | Model Architecture | Preprocessing | Text Representation | Detection Features |
|---|---|---|---|---|---|---|
| [16] | Phishing | Text classification using LLMs | LLM | Prompt development | LLM’s contextual embeddings | Text-based features: message content, subject, sender, recipient |
| [26] | Scam | LLM applies a scam detection rubric | LLM | Prompt development including instructions, E-mail, and rubric | LLM’s contextual embeddings | Text-based features and rubric rules |
| [21] | Smishing | Text classification | ML (Random Forest) | Tokenization, stopword removal, stemming | TF-IDF | Text-based features |
| [39] | Toxic communication | Text classification | ML (RF, SVM, LR, MNB, KNN), and BERT | Normalization, tag and link removal, stopword removal, stemming, lemmatization | TF-IDF | Text-based features |
| [34] | Fake profile | Classification | DL (RNN: GRU+LSTM) | Tokenization, normalization | Word embedding: GloVe | Text-based features (from tweets, user profile, network) |
| [40] | Inappropriate messages | Rule-based, sentiment analysis | DL (LSTM) | Tokenization, stopword removal, stemming | Unspecified | Text-based features, behavior temporal features |
| [48] | Authenticity classification | Topic modeling (LDA), text classification | XLNet and BERT | Tokenization, special characters and stopword removal | TF-IDF with LDA; contextual embeddings for classification | Text-based features |
| [17] | Phishing | Benchmarking 12 LLMs instructed for detection | LLM | Benchmarking setup; prompt development | LLM’s contextual embeddings | Text-based features |
| [35] | Fake profile | text classification | Transformer-based (BERT) | tag, punctuation and stopword removal; lemmatization | BERT’s contextual embeddings | Text-based features from tweet content and properties |
| [24] | Social engineering | Simulated annealing optimized fusion of five specialized DL models | DL (bi-LSTM, CNN, MLP) and Transformer-based | Not mentioned. Specific to inner models. | Static embeddings and BERT’s contextual embeddings | personality traits, linguistic aspects, behavioral characteristics, and IT attributes |
| [28] | Spam | text classification | ML (NB, RF, SVM…) | Tokenization, stemming | BoW and TF-IDF | Text-based features |
| [25] | Social engineering | LLM-based text classification pipeline | LLM | Not mentioned | Contextual embeddings (LLM+RAG) | Text-based features (message-level and conversation-level) |
| [29] | Spam | Text classification | ML, DL | Tokenization, stopword removal, stemming | GloVe embeddings | Text-based features |
| [18] | Phishing | DL+deep stacked autoencoder | DL | Not mentioned | BoW, n-gram, hashtags, sentence length, uppercase, TF-IDF | Web and URL features and text-based features |
| [30] | Spam | Federated learning for classification | FedAvg, FedAvgM, FedAdam | NA | PhoBERT’s embeddings | Text-based features |
| [44] | Harmful content | LLMs as content classifiers in a custom policy moderation pipeline | LLM | NA | GPT 3.5 and LLaMa 2’s embeddings | Text-based features |
| [36] | Fake profile | Classification | ML (Random Forest, SVM, KNN) | Converting profile attributes into numerical form | NA (the proposal uses no text) | Profile account metadata, behavioral features, network follower, and following numbers |
| [31] | Spam | text classification | DL (LSTM) | Punctuation, stopwords, and URL removal; lemmatization | BoW, TF- IDF, word embeddings | Text-based features |
| [37] | Fake profile, payment fraud | Classification | ML (XGBoost, CatBoost, GBM) | Numerical feature scaling, categorical encoding, derived features’ generation. | Not mentioned | Average likes per post, sentiment analysis of profile bio text, post hashtags |
| [41] | Impersonation, clone channels | Classification | ML (RF, SVM) and DL (MLP) | Removal of mentions, numbers, links, emoji, and messages shorter than 15 characters; tokenization | Message format and structure features (not the usual text representation) | Behavioral features (#forwarded messages, average length of posted messages, #messages posted in the last 3 months, interaction features); profile attributes |
| [43] | Aggressive content | Text classification | ML, DL (LSTM) | Punctuation and stopword removal; stemming; Labeling | Semantic features (actor, target, polarity), and TF-IDF | Text-based features |
| [38] | Fake profile | Statistical methods for data match score | Separate and combined similarity verifiers | Not mentioned | NA | Key hold time, key interval time, word hold time |
| [22] | Smishing | Text classification | DL (CNN + LSTM) | Lowercase conversion, tokenization, punctuation and stopword removal | Trained embeddings | Text-based features |
| [27] | Malicious (spam, phishing, or fraud) messages | Text classification | ML | Stopword removal, stemming, lemmatization | Lexical (word frequencies, n-grams), Semantic features (fraud related), context features (sender, time related) | Text-based features and behavioral features |
| [42] | Hacker discussions as early threat indicator | LLM-based named entity recognition and classification | NLP, ML, and LLM | lowercase conversion; tokenization; punctuation, stopword, slang and non-ASCII removal; lemmatization | BoW and TF-IDF for SVM; BERT’s contextual embeddings | Text-based features |
| [32] | Spam | Text classification | ML (LR, SVM, RF), DL (RNN) | Tokenization, stopword and punctuation removal, stemming | BoW, message length | Text-based features |
| [33] | Spam | Classification and regression approach | ML (RF, RF Regressor) | Not mentioned | Features representing the outcome of criteria checks (binary/numerical) | 56 features extracted using NLP and grouped into categories: headers, text, attachments, URLs, and protocols |
| [20] | Phishing | Text classification | ML (RF) | Stemming via AraBERT | TF-IDF | Text-based features |
| [19] | Phishing | Text classification | ML (RF, DT, LR, SVM) | Convert to lowercase, punctuation and stopword removal, tokenization, lemmatization | TF-IDF | Text-based features |
| [23] | Smishing | Text classification | ML (LR, SVM, RF...) | Prior feature extraction, tokenization, emojis and punctuation removal, lowercase | TF-IDF and BERT embeddings | Metadata and text-based features |
| Ref | Supported Language | Input Scope | Evaluation | Limitations | Future Directions |
|---|---|---|---|---|---|
| [16] | Unspecified (multilingual ability by LLM) | Accuracy, confidence score distribution; OpenAI models excel | Sporadic experience involving copying text into a prompt for the analyzed models | Further model fine-tuning and refinement | |
| [26] | Unspecified (multilingual ability by LLM) | Accuracy: 69% to 98% | Limited experience; vulnerable to OpenAI interface downtime, and API rate limits | Refining the scam detection rubric; creating an entirely self-contained ML algorithm | |
| [21] | English and Bemba | SMS text messages | F1: 90.2%, AUC: 95% | Restricted data access | The need for further model optimization |
| [39] | English | Chat message content | Accuracy: 84% to 92% | Not specified; scale challenges | Optimizing ML parameters, bot enhancing, and multilingual support |
| [34] | Mostly English (dataset-dependent) | Tweets | Accuracy: 99.73%, Precision: 98.23%, Recall: 99.56%, F1: 99.63% | Not specified | Wider range of features, multilingual, language-agnostic features |
| [40] | Unspecified | Chat message content | Planned, not performed | Not specified; the proposed methodology lacks implementation details | Refine the core components; broader chat platform scope |
| [48] | Chinese | Chat messages’ content | Accuracy: 77% to 82.5% | Not specified. | Optimizing the model and enhancing generalization, alongside supporting diverse languages and cultural backgrounds |
| [17] | English | Accuracy: 62.5% to 97.5%, F1: 44% to 97.6% | The benchmark used base models and small datasets; optimized temperature value was different for each model | Phishing detection using fine-tuned LLMs; expanding datasets to include more complex scenarios | |
| [35] | English (multilingual depends on BERT version) | Tweets | Precision: 31%, recall: 50% | Not specified; poor performance; small dataset | Not specified |
| [24] | English | Chat history | Accuracy: 79.9%, AUC: 74.3%, F1: 70.1% | Gap between the AUC value of the multimodal fusion model and one inner component; further research is needed to investigate the model interpretability | Expand capabilities, identifying deepfake content |
| [28] | English | SMS text messages | Accuracy: 98% | Scalability challenges; dataset size | Exploring temporal patterns features |
| [25] | English; multilingual not specified | Chat message; chat conversation (history) | F1: 80% | Dataset is focused on simulated scenarios in a particular topic; LLM-generated messages may be unrealistic or overly agreeable and could affect the dataset reliability | Expand to other domains such as financial services or customer support; consider the broader ethical and practical LLM usage implications |
| [29] | English | Message text | Accuracy: 80.6%, F1: 75.5% | Not specified | Incorporate BERT or GPTs; use HuggingFace |
| [18] | Unspecified | Website data | Accuracy: 92%, TPR: 92.5%, TNR: 92.1% | Not specified | Utilize transfer learning |
| [30] | Vietnamese | SMS text messages | Accuracy: 98% | NA | NA |
| [44] | English | Posts, comments, messages (text) | F1: 44% to 77.6% | Cannot differentiate between a violation detected with high confidence and one just suspected | Expand across diverse languages, cultures, and contexts, even involving real users; using multimodal models, generalize the approach to different types of data |
| [36] | Unspecified | Profile account attributes | Accuracy: 92.5% | Not specified | Not specified |
| [31] | Unspecified (dataset dependent) | Message | Accuracy: 85.6% | Not specified | Contextual analysis; user-centric approaches. |
| [37] | Unspecified | Profile account attributes | Accuracy: 93%, F1: 92% | Not specified | Detection across various domain sectors |
| [41] | English | Channel text messages; message-related counters; channel (profile) attributes | F1: 85.45% | Focused only on English channels | Incorporate LLMs and include semantic features. |
| [43] | English | Text sentences | F1: 77.13% for LR/ML, F1: 91.61% for BiLSTM/DL | Linguistic features seem to make the models over-generalize; for the textual features, models tend to be biased; model interpretability; limited to English. | Dataset’s human annotation; increase dataset positive instances |
| [38] | Unspecified | Users’ typing patterns | Accuracy: 91.6% to 100% | Not specified | Augment the dataset with additional users; investigate additional linguistic features; include multimodal, multi-device, usage-context, and DL |
| [22] | Swahili | SMS text messages | Accuracy: 99.98% | Not specified | Tune hyperparameters to reduce false negatives; develop a mobile application |
| [27] | English | SMS, chat, app, or E-mail messages | Accuracy: 94.6%, F1: 93.2% | Not specified | Not specified |
| [42] | Dataset-dependent (English) | Forum or group chat contents | Accuracy: 91.7%, F1: 87.8% | Communities are probably moving to other platforms; sampling bias; report and forum information reliability; the scope of the analysis was English-speaking forums only | Develop benchmark datasets for NER models within the CTI domain; focus on topic matching that incorporates contextual semantics; extend data sources to include modern platforms |
| [32] | English | SMS text messages | Accuracy: 99.28% | Not specified | Train the model with other datasets and fine tuning; curate new SMS datasets |
| [33] | English and Spanish | E-mail message with headers | F1: 91.4% for classification, and MSE: 0.781 for regression | Considerable feature extraction time | Development of an ensemble model based on stacked generalization; explore more distinctive features |
| [20] | Arabic | SMS text messages | Accuracy: 98.66%, F1: 98.67% | Some inaccuracies in translating an English dataset to Arabic | Use a real Arabic dataset |
| [19] | Dataset-dependent (English) | Accuracy: 98.72% and 99.15%, depending on the dataset | Not specified | Dataset augmentation; try a wider range of phishing strategies and linguistic nuances | |
| [23] | Unspecified | SMS text messages | Accuracy: 94%, F1: 93.78% | Not specified | Extend to analyze various social platform messages; collect other language-based datasets. |
| Ref | Deployment Platform | Datasets | Real-Time | Implementation Tools | Ethical Aspects of Real-World Deployment |
|---|---|---|---|---|---|
| [16] | Fraudulent E-mail corpus | N | poe.com AI chat platform, LLMs | Not mentioned | |
| [26] | Nazario database, Untroubled Scam 2023 Archive, and custom | N | OpenAI ChatGPT API, ChatGPT 3.5 | Not mentioned | |
| [21] | SMS | English + Bemba Smishing datasets | Y | Unspecified | Not mentioned |
| [39] | Telegram platform | Chat dataset from social platforms and Kaggle | Y | HuggingFace, Python packages | Not mentioned |
| [34] | X platform (Twitter) | TwiBot-20 dataset | Unspecified | Python packages | Not mentioned |
| [40] | Messaging apps | Unspecified | NA | Unspecified | Data anonymization and user consent are proposed |
| [48] | WeChat group chats | Custom chat dataset | Unspecified | HuggingFace’s Transformers library | Not mentioned |
| [17] | Enterprise E-mails (contemporary message quality) | NA | Chatbot Arena, Ollama | Self-hosting a model is suggested for privacy | |
| [35] | X platform (Twitter) | Collected tweet dataset | Unspecified | Unspecified | Not mentioned |
| [24] | Chat platforms | Chat social engineering corpus | Unspecified | SpaCy, PyTorch, HuggingFace | Not mentioned |
| [28] | SMS | SMS Spam Collection | N | Python sklearn | Not mentioned |
| [25] | Chat platforms | SEConvo, a developed dataset | Unspecified | LangChain, OpenAI API, Faiss, Python | Ethical dilemma: the potential dataset misuse; privacy and consent are not mentioned. |
| [29] | SMS, chat, messaging platforms | Compilation of SMS and Twitter datasets | N | Unspecified | Not mentioned |
| [18] | Content referring Webpages | Webpage phishing detection dataset | N | Python | Not mentioned |
| [30] | SMS | Spam dataset | Unspecified | NA | FL is used to reduce the exposure of sensitive information |
| [44] | Social media | OpenAI’s content moderation dataset; Reddit’s Multilingual Content Moderation dataset | Unspecified | Unspecified | Ethical and legal concerns are reported on how data and personal information might be used for training without the user’s awareness |
| [36] | Instagram platform | Instagram fake/spammer/genuine accounts | Unspecified | Python, Pandas, NumPy, Scikit-learn | Not mentioned |
| [31] | Social media | Custom dataset | Unspecified | NLTK, Pandas, TensorFlow, PyTorch, Scikit-learn | Not mentioned |
| [37] | Social Media | Fake profile and payment fraud datasets | Unspecified | Unspecified | Not mentioned |
| [41] | Telegram platform | Collected data from 120,979 Telegram public channels | Unspecified | NLTK, LangDetect, Scikit-learn, PyTorch, Telegram API | The protection of user privacy is mentioned; PII was removed; authors reported the detected fake and clone channels to Telegram |
| [43] | Text message platform | LLM generated dataset | Unspecified | Textblob, ChatGPT, Google Colab | Not mentioned |
| [38] | Social networks | Collected keystroke timings on Facebook, X, and Instagram | Unspecified | Python | Study participants signed a consent; deployment phase not mentioned |
| [22] | SMS | 32,259 Swahili SMS messages | Unspecified | Python, Keras, Google Colab | Not mentioned |
| [27] | Mobile messaging applications | 50,000 (benign, spam, phishing, and fraud) messages | Y | Unspecified | Not mentioned |
| [42] | Online forums | Hacker forums articles covering 20 years; threat report data (intelligence community, press, sites) | N | NLTK, DarkBERT | Ethical and privacy concerns are mentioned by the authors regarding the use of conversations; some measures are suggested to mitigate privacy risks |
| [32] | SMS | SMS Spam Dataset (UCI) | Unspecified | Python, Google Colab | Not mentioned |
| [33] | Custom dataset built from two sources | N | Python, Scikit-learn | Not mentioned | |
| [20] | SMS | Custom, translated dataset: 638 phishing and 4,844 legitimate messages | Unspecified | AraBERT (Arabic LM), Python, Scikit-learn, Google Colab | Not mentioned |
| [19] | Fraud E-mail dataset and phishing E-mail dataset | Unspecified | Unspecified | Not mentioned | |
| [23] | SMS | Custom dataset combining messages from three sources | Unspecified | NLTK, Scikit-learn, TensorFlow | Not mentioned |
References
- Thumboo, S.; Mukherjee, S. Digital romance fraud targeting unmarried women. Discov. Glob. Soc. 2024, 2, 105. [Google Scholar] [CrossRef]
- Buil-Gil, D.; Zeng, Y. Meeting you was a fake: Investigating the increase in romance fraud during COVID-19. J. Financ. Crime 2022, 29, 460–475. [Google Scholar] [CrossRef]
- Alharbi, A.; Dong, H.; Yi, X.; Tari, Z.; Khalil, I. Social Media Identity Deception Detection: A Survey. Acm Comput. Surv. 2021, 54, 69. [Google Scholar] [CrossRef]
- Perik, L.W. Leveraging Generative Pre-trained Transformers for the Detection and Generation of Social Engineering Attacks: A Case Study on YouTube Collusion Scams. Master’s Thesis, University of Twente, Enschede, The Netherlands, 12 January 2025. [Google Scholar]
- Kyaw, P.H.; Gutierrez, J.; Ghobakhlou, A. A Systematic Review of Deep Learning Techniques for Phishing Email Detection. Electronics 2024, 13, 3823. [Google Scholar] [CrossRef]
- Europol. Internet Organised Crime Threat Assessment (IOCTA) 2021; Publications Office of the European Union: Luxembourg, 2021. [Google Scholar] [CrossRef]
- Europol. Internet Organised Crime Threat Assessment (IOCTA) 2024; Publications Office of the European Union: Luxembourg, 2024. [Google Scholar] [CrossRef]
- Jurafsky, D.; Martin, J.H. Speech and Language Processing, 3rd ed.; Stanford University: Stanford, CA, USA, 2025. [Google Scholar]
- IBM. What is Machine Learning? Available online: https://www.ibm.com/think/topics/machine-learning (accessed on 4 April 2025).
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All You Need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Barberá, I. AI Privacy Risks & Mitigations—Large Language Models (LLMs). European Data Protection Board. Available online: https://www.edpb.europa.eu/system/files/2025-04/ai-privacy-risks-and-mitigations-in-llms.pdf (accessed on 12 June 2025).
- Booth, A.; Sutton, A.; Clowes, M.; James, M. Systematic Approaches to a Successful Literature Review, 3rd ed.; SAGE Publications Ltd.: Thousand Oaks, CA, USA, 2022. [Google Scholar]
- Fakhouri, H.; Alhadidi, B.; Omar, K.; Makhadmeh, S.; Hamad, F.; Halalsheh, N. AI-Driven Solutions for Social Engineering Attacks: Detection, Prevention, and Response. In Proceedings of the 2nd International Conference on Cyber Resilience (ICCR), Dubai, United Arab Emirates, 26–28 February 2024; pp. 1–8. [Google Scholar] [CrossRef]
- Haddaway, N.R.; Page, M.J.; Pritchard, C.C.; McGuinness, L.A. PRISMA2020: An R package and Shiny app for producing PRISMA 2020-compliant flow diagrams, with interactivity for optimised digital transparency and Open Synthesis. Campbell Syst. Rev. 2022, 18, e1230. [Google Scholar] [CrossRef] [PubMed]
- Patel, H.; Rehman, U.; Iqbal, F. Evaluating the Efficacy of Large Language Models in Identifying Phishing Attempts. In Proceedings of the 16th International Conference on Human System Interaction (HSI), Paris, France, 8–11 July 2024; pp. 1–7. [Google Scholar] [CrossRef]
- Zhang, J.; Wu, P.; London, J.; Tenney, D. Benchmarking and Evaluating Large Language Models in Phishing Detection for Small and Midsize Enterprises: A Comprehensive Analysis. IEEE Access 2025, 13, 28335–28352. [Google Scholar] [CrossRef]
- Vidyasri, P.; Suresh, S. FDN-SA: Fuzzy deep neural-stacked autoencoder-based phishing attack detection in social engineering. Comput. Secur. 2025, 148, 104188. [Google Scholar] [CrossRef]
- Aljamal, M.; Alquran, R.; Aljaidi, M.; Aljamal, O.S.; Alsarhan, A.; Al-Aiash, I.; Samara, G.; Banisalman, M.; Khouj, M. Harnessing ML and NLP for Enhanced Cybersecurity: A Comprehensive Approach for Phishing Email Detection. In Proceedings of the 25th International Arab Conference on Information Technology, Zarqa, Jordan, 10–12 December 2024. [Google Scholar] [CrossRef]
- Ibrahim, A.; Alyousef, S.; Alajmi, H.; Aldossari, R.; Masmoudi, F. Phishing Detection in Arabic SMS Messages using Natural Language Processing. In Proceedings of the Seventh International Women in Data Science Conference at Prince Sultan University, Riyadh, Saudi Arabia, 3–4 March 2024. [Google Scholar] [CrossRef]
- Zimba, A.; Phiri, K.; Kashale, C.; Phiri, M. A machine learning and natural language processing-based smishing detection model for mobile money transactions. Int. J. Inf. Technol. Secur. 2024, 16, 69–80. [Google Scholar] [CrossRef]
- Mambina, I.S.; Ndibwile, J.D.; Uwimpuhwe, D.; Michael, K.F. Uncovering SMS Spam in Swahili Text Using Deep Learning Approaches. IEEE Access 2024, 12, 25164–25175. [Google Scholar] [CrossRef]
- Jain, A.K.; Kaur, K.; Gupta, N.K.; Khare, A. Detecting Smishing Messages Using BERT and Advanced NLP Techniques. SN Comput. Sci. 2025, 6, 109. [Google Scholar] [CrossRef]
- Tsinganos, N.; Fouliras, P.; Mavridis, I.; Gritzalis, D. CSE-ARS: Deep Learning-Based Late Fusion of Multimodal Information for Chat-Based Social Engineering Attack Recognition. IEEE Access 2024, 12, 16072–16088. [Google Scholar] [CrossRef]
- Ai, L.; Kumarage, T.; Bhattacharjee, A.; Liu, Z.; Hui, Z.; Davinroy, M.; Cook, J.; Cassani, L.; Trapeznikov, K.; Kirchner, M.; et al. Defending Against Social Engineering Attacks in the Age of LLMs. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Miami, FL, USA, 12–26 November 2024; pp. 12880–12902. [Google Scholar] [CrossRef]
- DiMario, C.L.; Bacha, R.C.; Butka, B.K. Combatting Senior Scams Using a Large Language Model-Created Rubric. In Proceedings of the 5th Asia Service Sciences and Software Engineering Conference (ASSE 2024), Tokyo, Japan, 11–13 September 2024. [Google Scholar] [CrossRef]
- Reddy, M.; Pallerla, R. Using AI to Detect and Classify Suspicious Mobile Messages in Real Time. In Proceedings of the 3rd International Conference on Intelligent Data Communication Technologies and Internet of Things (IDCIoT), Bengaluru, India, 5–7 February 2025; pp. 1772–1777. [Google Scholar] [CrossRef]
- Dharrao, D.; Gaikwad, P.; Gawai, S.V.; Bongale, A.M.; Patel, K.; Singh, A. Classifying SMS as spam or ham: Leveraging NLP and machine learning techniques. Int. J. Saf. Secur. Eng. 2024, 14, 289–296. [Google Scholar] [CrossRef]
- Asmitha, M.; Kavitha, C.R. Exploration of Automatic Spam/Ham Message Classifier Using NLP. In Proceedings of the 9th International Conference for Convergence in Technology (I2CT), Pune, India, 5–7 April 2024; pp. 1–7. [Google Scholar] [CrossRef]
- Anh, H.Q.; Anh, P.T.; Nguyen, P.S.; Hung, P.D. Federated Learning for Vietnamese SMS Spam Detection Using Pre-trained PhoBERT. In Proceedings of the 25th International Conference on Intelligent Data Engineering and Automated Learning—IDEAL 2024, Valencia, Spain, 20–22 November 2024; Volume 15346. [Google Scholar] [CrossRef]
- Sivakumar, M.; Abishek, S.A.; Karthik, N.; Vanitha, J. Offensive Message Spam Detection in Social Media Using Long Short-Term Memory. In Proceedings of the 3rd Edition of IEEE Delhi Section Flagship Conference (DELCON), New Delhi, India, 21–23 November 2024. [Google Scholar] [CrossRef]
- Bennet, D.T.; Bennet, P.S.; Thiagarajan, P.; Sundarakantham, K. Content Based Classification of Short Messages using Recurrent Neural Networks in NLP. In Proceedings of the International Conference on Artificial Intelligence, Computer, Data Sciences and Applications (ACDSA), Victoria, Seychelles, 1–2 February 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Jáñez-Martino, F.; Alaiz-Rodríguez, R.; González-Castro, V.; Fidalgo, E.; Alegre, E. Spam email classification based on cybersecurity potential risk using natural language processing. Knowl.-Based Syst. 2025, 310, 112939. [Google Scholar] [CrossRef]
- Geetha, B.; Sushmitha, B.; Ilanchezhian, P.; Alabdeli, H.; Ahila, R. A Bi-directional Gated Recurrent Unit and Long Short-Term Memory based Fake Profile Identification System. In Proceedings of the First International Conference on Software, Systems and Information Technology (SSITCON), Tumkur, India, 18–19 October 2024; pp. 1–5. [Google Scholar] [CrossRef]
- Singha, A.K.; Paul, A.; Sonti, S.; Guntur, K.; Chiranjeevi, M.; Dhuli, S. BERT-Based Detection of Fake Twitter Profiles: A Case Study on the Israel-Palestine War. In Proceedings of the 15th International Conference on Computing Communication and Networking Technologies (ICCCNT), Kamand, India, 24–28 June 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Arunprakaash, R.R.; Nathiya, R. Leveraging Machine Learning algorithms for Fake Profile Detection on Instagram. In Proceedings of the 7th International Conference on Circuit Power and Computing Technologies (ICCPCT), Kollam, India, 8–9 August 2024; pp. 869–876. [Google Scholar] [CrossRef]
- Asha, V.; Nithya, B.; Prasad, A.; Kumari, M.; Hujaifa, M.; Sharma, A. Optimizing Fraud Detection with XGBoost and CatBoost for Social Media Profiles and Payment Systems. In Proceedings of the International Conference on Electronics and Renewable Systems (ICEARS), Tuticorin, India, 11–13 February 2025; pp. 1987–1992. [Google Scholar] [CrossRef]
- Kuruvilla, A.; Daley, R.; Kumar, R. Spotting Fake Profiles in Social Networks via Keystroke Dynamics. In Proceedings of the IEEE 21st Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 6–9 January 2024; pp. 525–533. [Google Scholar] [CrossRef]
- Abhijith, A.B.; Prithvi, P. Automated Toxic Chat Synthesis, Reporting and Removing the Chat in Telegram Social Media Using Natural Language Processing Techniques. In Proceedings of the Fourth International Conference on Advances in Electrical, Computing, Communication and Sustainable Technologies (ICAECT), Bhilai, India, 11–12 January 2024; pp. 1–7. [Google Scholar] [CrossRef]
- Shiny, J.; Penyameen, S.; Hannah, N.; Harilakshmi, J.S.; Hewin, A.; Thanusha, S. Analysis of Behavior in Chat Applications using Natural Language Processing. In Proceedings of the 2nd International Conference on Sustainable Computing and Smart Systems (ICSCSS), Coimbatore, India, 10–12 July 2024; pp. 718–725. [Google Scholar] [CrossRef]
- La Morgia, M.; Mei, A.; Mongardini, A.; Wu, J. Pretending to be a VIP! Characterization and Detection of Fake and Clone Channels on Telegram. Acm Trans. 2024, 19, 1–24. [Google Scholar] [CrossRef]
- Paladini, T.; Ferro, L.; Polino, M.; Zanero, S.; Carminati, M. You Might Have Known It Earlier: Analyzing the Role of Underground Forums in Threat Intelligence. In Proceedings of the 27th International Symposium on Research in Attacks, Intrusions and Defenses (RAID ’24), Padua, Italy, 30 September–2 October 2024; pp. 368–383. [Google Scholar] [CrossRef]
- Raza, M.O.; Meghji, A.F.; Mahoto, N.A.; Reshan, M.S.A.; Abosaq, H.A.; Sulaiman, A.; Shaikh, A. Reading Between the Lines: Machine Learning Ensemble and Deep Learning for Implied Threat Detection in Textual Data. Int. J. Comput. Intell. Syst. 2024, 17, 183. [Google Scholar] [CrossRef]
- Franco, M.; Gaggi, O.; Palazzi, C.E. Integrating Content Moderation Systems with Large Language Models. Acm Trans. 2024, 19, 1–21. [Google Scholar] [CrossRef]
- Feretzakis, G.; Vagena, E.; Kalodanis, K.; Peristera, P.; Kalles, D.; Anastasiou, A. GDPR and Large Language Models: Technical and Legal Obstacles. Future Internet 2025, 17, 151. [Google Scholar] [CrossRef]
- Narayan, S.M.; Kohli, N.; Martin, M.M. Addressing contemporary threats in anonymised healthcare data using privacy engineering. NPJ Digit. Med. 2025, 8, 145. [Google Scholar] [CrossRef] [PubMed]
- Karliuk, M. Proportionality principle for the ethics of artificial intelligence. AI Ethics 2023, 3, 985–990. [Google Scholar] [CrossRef]
- Nie, N.; Guo, H.; Song, W. Authenticity Classification of WeChat Group Chat Messages Based on LDA and NLP. In Proceedings of the 9th International Conference on Cloud Computing and Big Data Analytics (ICCCBDA), Chengdu, China, 25–27 April 2024; pp. 313–319. [Google Scholar] [CrossRef]

| Database Name | URL |
|---|---|
| ACM Digital Library | https://dl.acm.org/ (accessed on 4 April 2025) |
| IEEE Xplore | https://ieeexplore.ieee.org/ (accessed on 4 April 2025) |
| PubMed | https://pubmed.ncbi.nlm.nih.gov/ (accessed on 4 April 2025) |
| Scopus | https://www.scopus.com/ (accessed on 4 April 2025) |
| Web of Science | https://www.webofscience.com/ (accessed on 4 April 2025) |
| Technique | Best Evaluation | Best-Case Threat Type | Top Citation |
|---|---|---|---|
| ML | Accuracy: 99.15% | Phishing (E-mail) | [19] |
| DL | Accuracy: 99.98% | Smishing (Swahili) | [22] |
| LLMs | Acc.: 97.5%, F1: 97.6% | Phishing | [17] |
| Ensemble DL | F1: 91.61% | Aggressive content | [43] |
| Statistical/other | Acc.: 91.6% to 100% | Fake profile | [38] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saias, J. Advances in NLP Techniques for Detection of Message-Based Threats in Digital Platforms: A Systematic Review. Electronics 2025, 14, 2551. https://doi.org/10.3390/electronics14132551
Saias J. Advances in NLP Techniques for Detection of Message-Based Threats in Digital Platforms: A Systematic Review. Electronics. 2025; 14(13):2551. https://doi.org/10.3390/electronics14132551
Chicago/Turabian StyleSaias, José. 2025. "Advances in NLP Techniques for Detection of Message-Based Threats in Digital Platforms: A Systematic Review" Electronics 14, no. 13: 2551. https://doi.org/10.3390/electronics14132551
APA StyleSaias, J. (2025). Advances in NLP Techniques for Detection of Message-Based Threats in Digital Platforms: A Systematic Review. Electronics, 14(13), 2551. https://doi.org/10.3390/electronics14132551