
Detection of Trees and Objects in Apple Orchard from LiDAR Point Cloud Data Using a YOLOv5 Framework

 ,
,  ,
, 
Abstract
1. Introduction
2. Related Works
- The proposed detection pipeline, including pre-processing and training, would optimize for deployment on resource-constrained platforms such as UAVs or mobile agricultural robots, making it suitable for real-time orchard monitoring.
- The model was trained and validated using real-world data collected from a commercial apple orchard, accounting for occlusion, class imbalance, and visual ambiguity, which improves robustness under field conditions.
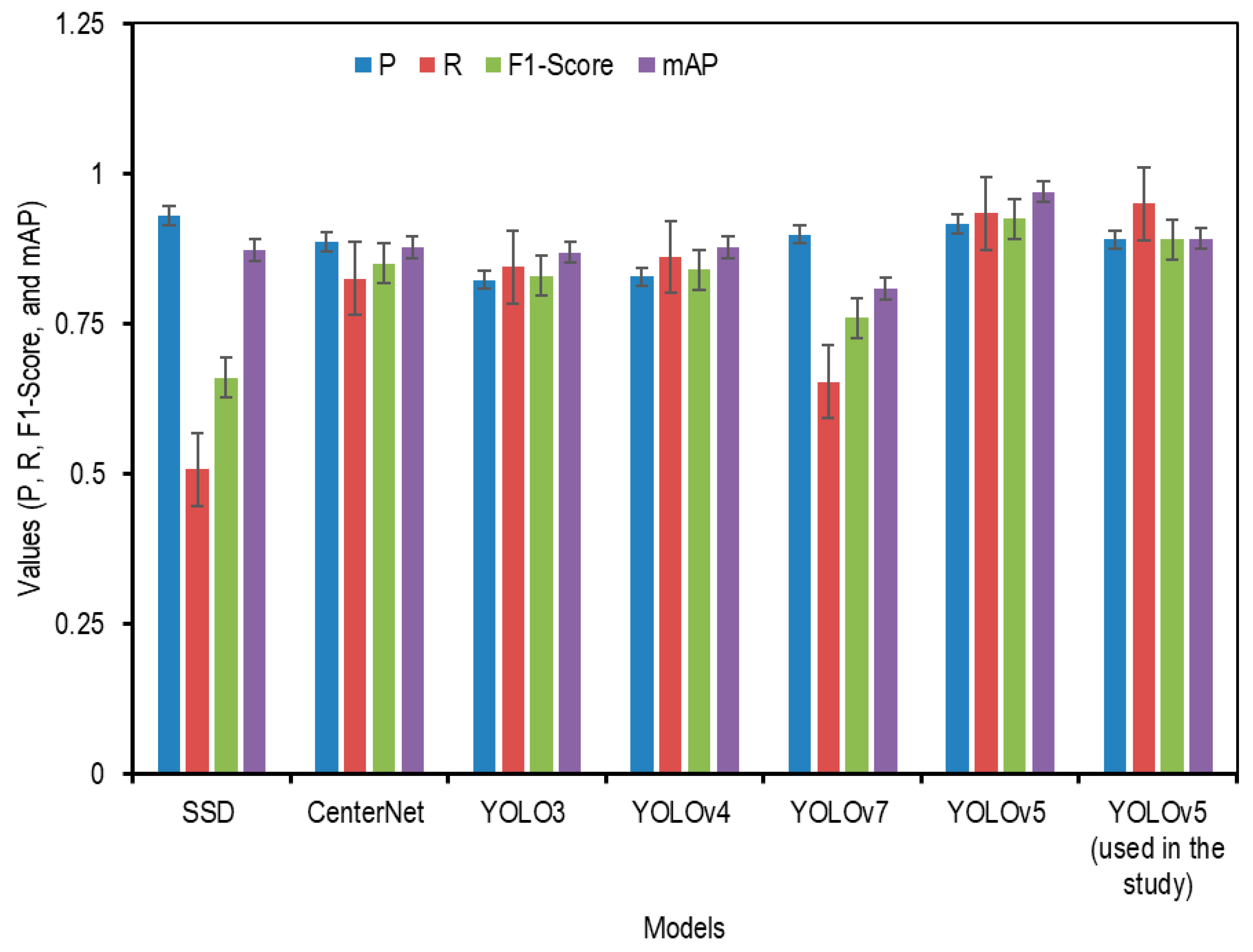
- The study provides a performance comparison of the proposed method with other object detection models, including SSD, YOLOv3–v7, and transformer-based approaches, supporting the justification for adopting YOLOv5 in precision agriculture.
- The findings suggest economic feasibility by reducing the manual labor and processing time. Moreover, the detection framework was shown to be scalable and transferable to other fruit orchards (e.g., pear, orange, peach, and persimmon) through minimal retraining.
3. Materials and Methods
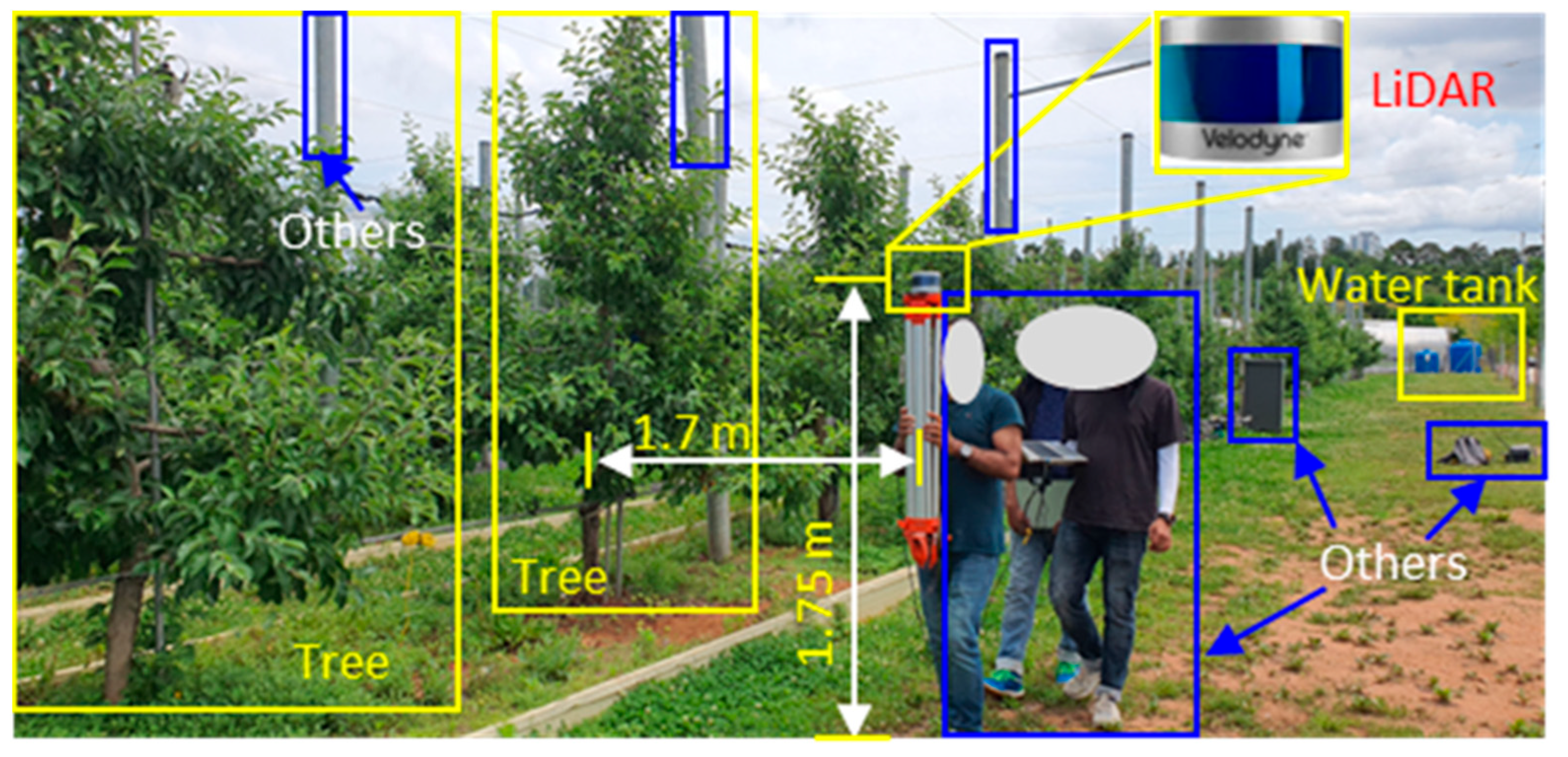
3.1. Data Collection Site
3.2. Sensor Selection and Data Collection
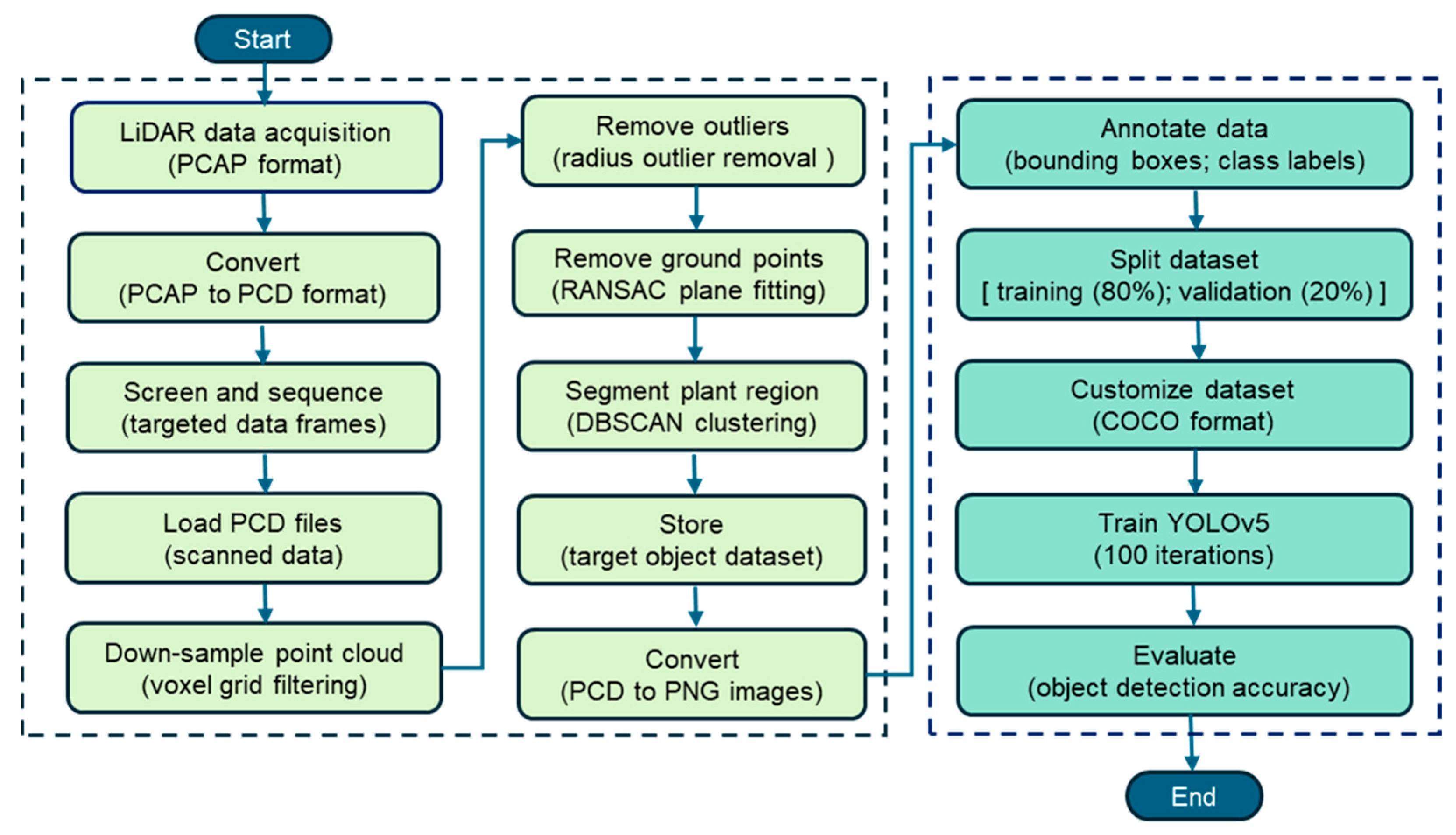
3.3. Data Pre-Processing Procedure
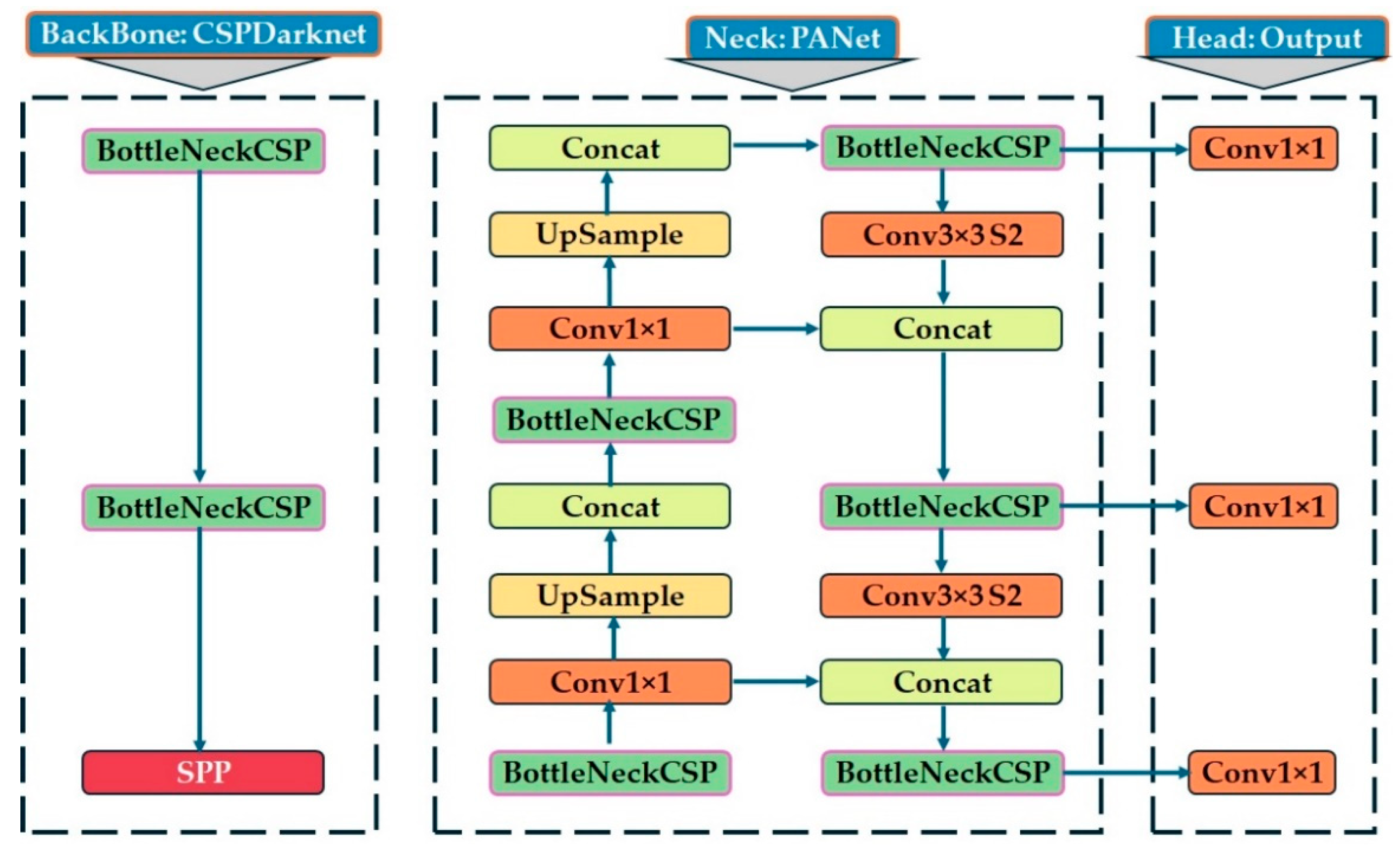
3.4. YOLOv5 Model
3.5. Model Performance Matrices
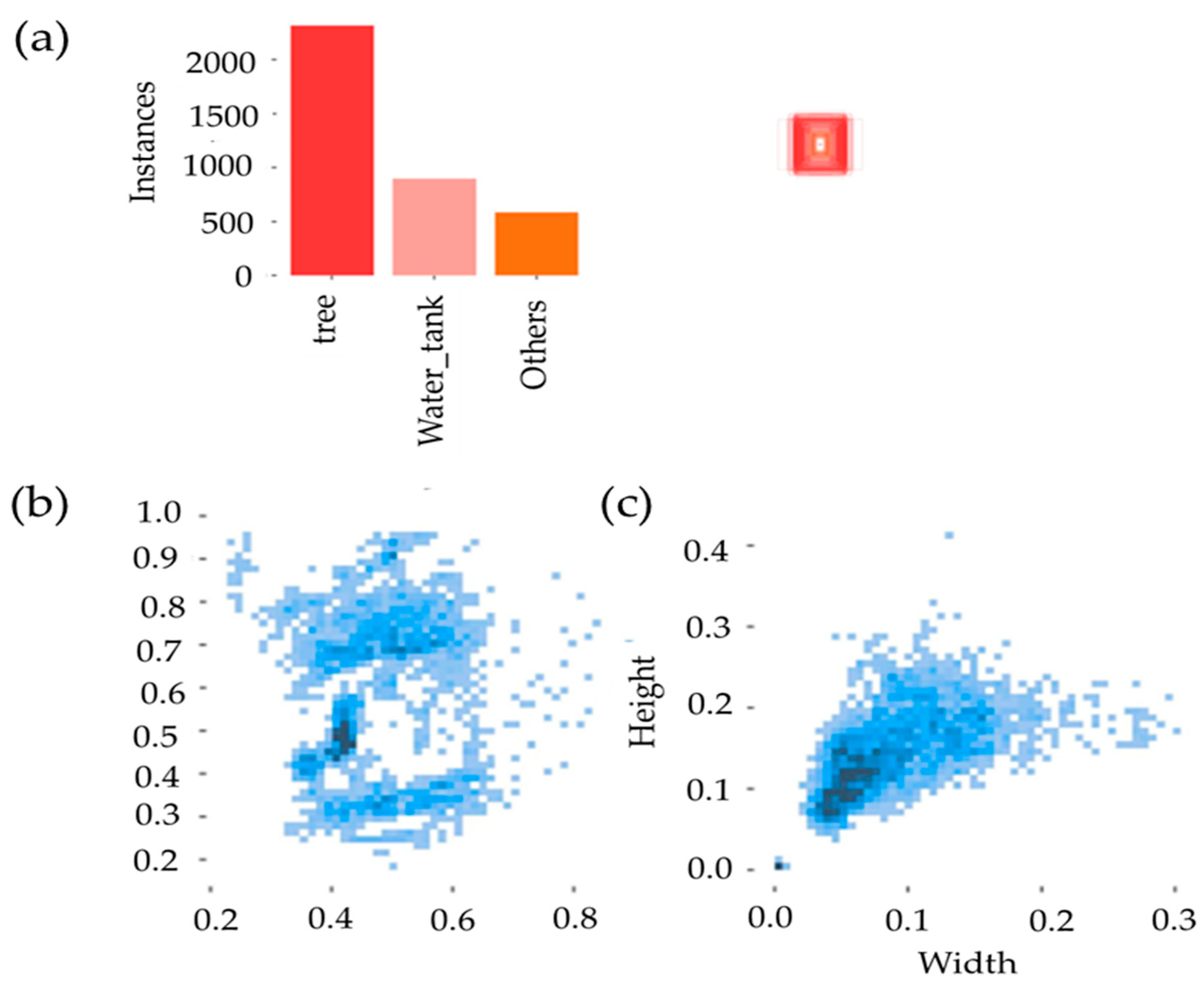
3.6. Dataset Preparation and Training Process
4. Results
4.1. Training Outputs on Key Performance Indicators
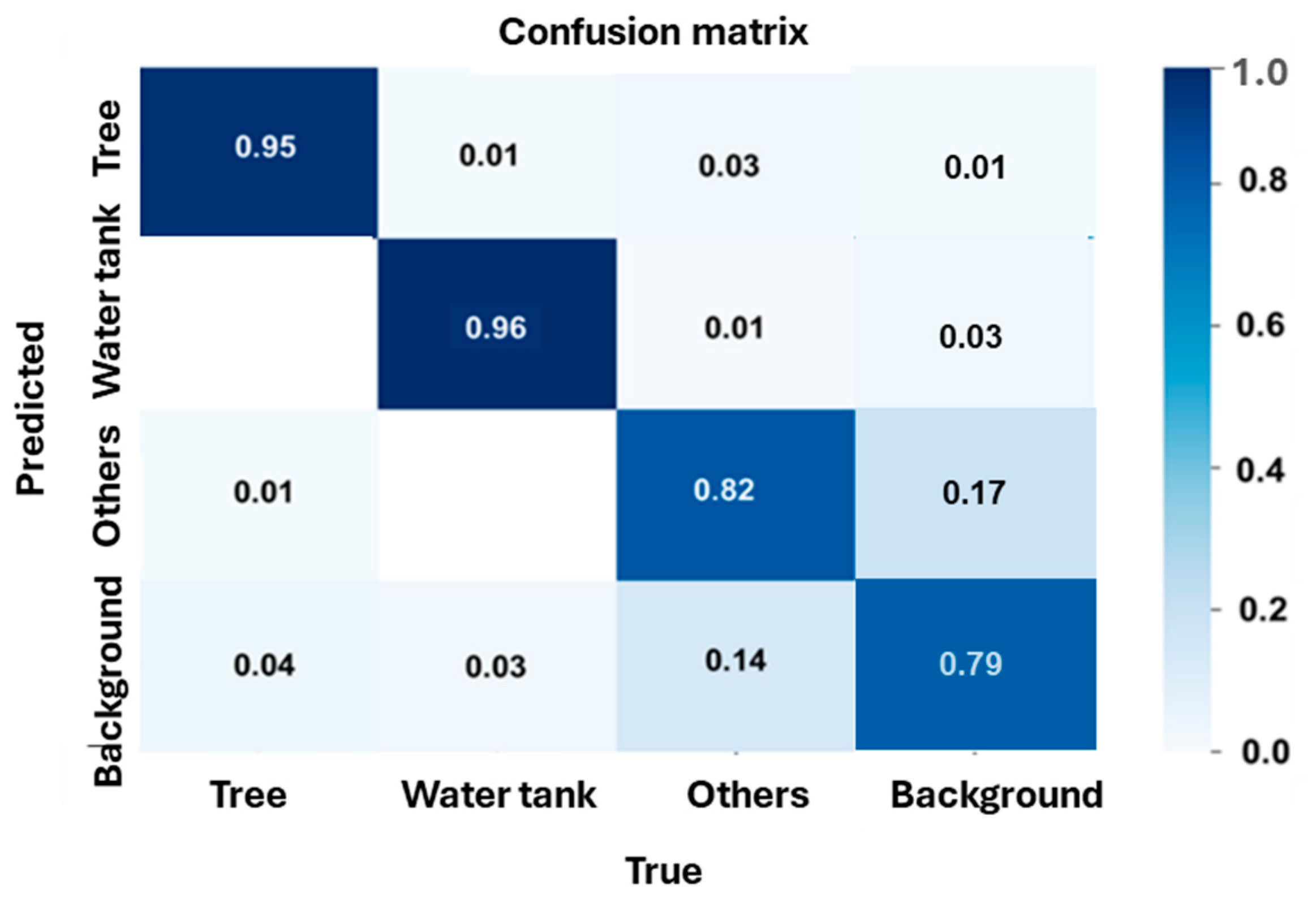
4.2. Object Detection Performance
5. Discussion
5.1. Implications for Theory
5.2. Implications for Practice
5.3. Implications for Economic Benefit
5.4. Scalability and Cross-Crop Applicability
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tlais, A.Z.A.; Fiorino, G.M.; Polo, A.; Filannino, P.; Di Cagno, R. High-value compounds in fruit, vegetable and cereal byproducts: An overview of potential sustainable reuse and exploitation. Molecules 2020, 25, 2987. [Google Scholar] [CrossRef] [PubMed]
- Behailu, A.; Kebede, J. A study on the causes of apple (malus domestica) fruit loss at Chencha woreda of Gamo gofa zone, southern Ethiopia. J. Stored Prod. Postharvest Res. 2018, 9, 72–77. [Google Scholar]
- Fetena, S.; Shara, S.; Anjulo, A.; Gulie, G.; Woldesenbet, F.; Yilma, B. Survey on apple production and variety identification in Chencha District of Gamo Gofa Zone, Southern Ethiopia. J. Agric. Food Technol. 2014, 4, 7–15. [Google Scholar]
- Ntakyo, P.R.; Mugisha, J.; Elepu, G. Socio-economic factors affecting apple production in South-Western Uganda. Afr. Crop Sci. J. 2013, 21, 311–321. [Google Scholar]
- Desmarescaux, M.; Kaddah, W.; Alfalou, A.; Badoc, I. SiamYOLOv8: A rapid conditional detection framework for one-shot object detection. Appl. Intell. 2025, 55, 609. [Google Scholar] [CrossRef]
- Huang, Y.; Qian, Y.; Wei, H.; Lu, Y.; Ling, B.; Qin, Y. A survey of deep learning-based object detection methods in crop counting. Comput. Electron. Agric. 2023, 215, 108425. [Google Scholar]
- Kang, S.; Hu, Z.; Liu, L.; Zhang, K.; Cao, Z. Object detection YOLO algorithms and their industrial applications: Overview and comparative analysis. Electronics 2025, 14, 1104. [Google Scholar] [CrossRef]
- Liu, R.; Yang, B.; Zio, E.; Chen, X. Artificial intelligence for fault diagnosis of rotating machinery: A review. Mech. Syst. Signal Process. 2018, 108, 33–47. [Google Scholar] [CrossRef]
- Gautam, D.; Mawardi, Z.; Elliott, L.; Loewensteiner, D.; Whiteside, T.; Brooks, S. Detection of invasive species (Siam Weed) using drone-based imaging and YOLO deep learning model. Remote Sens. 2025, 17, 120. [Google Scholar] [CrossRef]
- Liu, G. Surface defect detection methods based on deep learning: A brief review. In Proceedings of the 2020 2nd International Conference on Information Technology and Computer Application (ITCA), Guangzhou, China, 18–20 December 2020; pp. 200–203. [Google Scholar]
- Hassan, M.U.; Ullah, M.; Iqbal, J. Towards autonomy in agriculture: Design and prototyping of a robotic vehicle with seed selector. In Proceedings of the 2016 2nd International Conference on Robotics and Artificial Intelligence (ICRAI), Rawalpindi, Pakistan, 1–2 November 2016; pp. 37–44. [Google Scholar]
- Karim, M.R.; Ahmed, S.; Reza, M.N.; Lee, K.H.; Jin, H.; Ali, M.; Sung, J.; Chung, S.O. A review on stereo vision for feature characterization of upland crops and orchard fruit trees. Precis. Agric. Sci. Technol. 2024, 6, 104–122. [Google Scholar]
- Bicamumakuba, E.; Habineza, E.; Lee, K.H.; Chung, S.O. Sensor technologies for remote monitoring of automated orchard irrigation: A review. Precis. Agric. Sci. Technol. 2024, 6, 81–95. [Google Scholar]
- Ariza-Sentís, M.; Vélez, S.; Martínez-Peña, R.; Baja, H.; Valente, J. Object detection and tracking in precision farming: A systematic review. Comput. Electron. Agric. 2024, 219, 108757. [Google Scholar] [CrossRef]
- Badgujar, C.M.; Poulose, A.; Gan, H. Agricultural object detection with You Only Look Once (YOLO) algorithm: A bibliometric and systematic literature review. Comput. Electron. Agric. 2024, 223, 109090. [Google Scholar] [CrossRef]
- Aslan, M.F.; Sabanci, K.; Aslan, B. Artificial intelligence techniques in crop yield estimation based on Sentinel-2 data: A comprehensive survey. Sustainability 2024, 16, 8277. [Google Scholar] [CrossRef]
- Padilla, R.; Passos, W.L.; Dias, T.L.; Netto, S.L.; Da Silva, E.A. A comparative analysis of object detection metrics with a companion open-source toolkit. Electronics 2021, 10, 279. [Google Scholar] [CrossRef]
- Hu, T.; Wang, W.; Gu, J.; Xia, Z.; Zhang, J.; Wang, B. Research on apple object detection and localization method based on improved YOLOX and RGB-D images. Agronomy 2023, 13, 1816. [Google Scholar] [CrossRef]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep learning for generic object detection: A survey. Int. J. Comput. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Yan, X.; Shen, B.; Li, H. Small objects detection method for UAVs aerial image based on YOLOv5s. In Proceedings of the 2023 IEEE 6th International Conference on Electronic Information and Communication Technology (ICEICT), Qingdao, China, 21–24 July 2023; pp. 61–66. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer International Publishing: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. DSSD: Deconvolutional single shot detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Single-shot refinement neural network for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Jeong, K.S.; Go, S.H.; Jo, W.K.; Park, J.H. Simplified image analysis for early detection of missing and low-vigor cabbage plants using UAV RGB imagery and deep learning. Korean J. Agric. Sci. 2025, 52, 51–65. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Martins, N.A.B.; Cruz, L.A.d.S.; Lopes, F. Impact of LiDAR point cloud compression on 3D object detection evaluated on the KITTI dataset. Eurasip J. Image Video Process. 2024, 2024, 15. [Google Scholar] [CrossRef]
- Murthy, C.B.; Hashmi, M.F.; Bokde, N.D.; Geem, Z.W. Investigations of object detection in images/videos using various deep learning techniques and embedded platforms—A comprehensive review. Appl. Sci. 2020, 10, 3280. [Google Scholar] [CrossRef]
- Ansari, M.A.; Crampton, A.; Parkinson, S. A layer-wise surface deformation defect detection by convolutional neural networks in laser powder-bed fusion images. Materials 2022, 15, 7166. [Google Scholar] [CrossRef] [PubMed]
- Hussain, M. Yolov1 to v8: Unveiling each variant—A comprehensive review of yolo. IEEE 2024, 12, 42816–42833. [Google Scholar] [CrossRef]
- Zahid, A.; Hussain, M.; Hill, R.; Al-Aqrabi, H. Lightweight convolutional network for automated photovoltaic defect detection. In Proceedings of the 2023 9th International Conference on Information Technology Trends (ITT), Dubai, United Arab Emirates, 24–25 May 2023; pp. 133–138. [Google Scholar]
- Hussain, M. When, where, and which?: Navigating the intersection of computer vision and generative ai for strategic business integration. IEEE 2023, 11, 127202–127215. [Google Scholar] [CrossRef]
- Hussain, M.; Khanam, R. In-depth review of yolov1 to yolov10 variants for enhanced photovoltaic defect detection. Solar 2024, 4, 351–386. [Google Scholar] [CrossRef]
- Hussain, M. Yolo-v5 variant selection algorithm coupled with representative augmentations for modelling production-based variance in automated lightweight pallet racking inspection. Big Data Cogn. Comput. 2023, 7, 120. [Google Scholar] [CrossRef]
- Jocher, G.; Kwon, Y.; guigarfr; perry0418; Veitch-Michaelis, J.; Ttayu; Suess, D.; Baltacı, F.; Bianconi, G.; IlyaOvodov; et al. ultralytics/yolov3: v9.5.0-YOLOv5 v5.0 Release Compatibility Update for YOLOv3, Published 12 April 2021. Available online: https://zenodo.org/records/4681234 (accessed on 24 May 2025).
- Malavazi, F.B.P.; Guyonneau, R.; Fasquel, J.B.; Lagrange, S.; Mercier, F. LiDAR-only based navigation algorithm for an autonomous agricultural robot. Comput. Electron. Agric. 2018, 154, 71–79. [Google Scholar] [CrossRef]
- Gu, C.; Zhai, C.; Wang, X.; Wang, S. CMPC: An innovative LiDAR-based method to estimate tree canopy meshing-profile volumes for orchard target-oriented spray. Sensors 2021, 21, 4252. [Google Scholar] [CrossRef] [PubMed]
- Kolb, A.; Meaclem, C.; Chen, X.Q.; Parker, R.; Milne, B. Tree trunk detection system using LiDAR for a semi-autonomous tree felling robot. In Proceedings of the 2015 IEEE 10th Conference on Industrial Electronics and Applications (ICIEA), Auckland, New Zealand, 15–17 June 2015; pp. 84–89. [Google Scholar]
- Chen, X.; Wang, S.; Zhang, B.; Liang, L. Multi-feature fusion tree trunk detection and orchard mobile robot localization using camera/ultrasonic sensors. Comput. Electron. Agric. 2018, 147, 91–108. [Google Scholar] [CrossRef]
- Vodacek, A.; Hoffman, M.J.; Chen, B.; Uzkent, B. Feature matching with an adaptive optical sensor in a ground target tracking system. IEEE Sens. J. 2015, 15, 510–519. [Google Scholar]
- Zhang, X.; Karkee, M.; Zhang, Q.; Whiting, M.D. Computer vision-based tree trunk and branch identification and shaking points detection in dense-foliage canopy for automated harvesting of apples. J. Field Robot. 2021, 58, 476–493. [Google Scholar] [CrossRef]
- Wang, L.; Lan, Y.; Zhang, Y.; Zhang, H.; Tahir, M.N.; Ou, S.; Liu, X.; Chen, P. Applications and prospects of agricultural unmanned aerial vehicle obstacle avoidance technology in China. Sensors 2019, 19, 642. [Google Scholar] [CrossRef] [PubMed]
- Shalal, N.; Low, T.; Mccarthy, C.; Hancock, N. A preliminary evaluation of vision and laser sensing for tree trunk detection and orchard mapping. In Proceedings of the Australasian Conference on Robotics and Automation (ACRA 2013), Sydney, NSW, Australia, 2–4 December 2013; pp. 80–89. [Google Scholar]
- Freitas, G.; Hamner, B.; Bergerman, M.; Singh, S. A practical obstacle detection system for autonomous orchard vehicles. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Algarve, Portugal, 7–12 October 2012; pp. 3391–3398. [Google Scholar]
- Bietresato, M.; Carabin, G.; Vidoni, R.; Gasparetto, A.; Mazzetto, F. Evaluation of a LiDAR-based 3D-stereoscopic vision system for crop-monitoring applications. Comput. Electron. Agric. 2016, 124, 1–13. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldu, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef]
- Li, Y.; Li, M.; Qi, J.; Zhou, D.; Liu, K. Detection of typical obstacles in orchards based on deep convolutional neural network. Comput. Electron. Agric. 2021, 181, 105932. [Google Scholar] [CrossRef]
- Wang, Z.; Li, P.; Cui, Y.; Lei, S.; Kang, Z. Automatic detection of individual trees in forests based on airborne LiDAR data with a tree region-based convolutional neural network (RCNN). Remote Sens. 2023, 15, 1024. [Google Scholar] [CrossRef]
- Zulkifli, Z.M.; Hashim, F.H.; Raj, T.; Huddin, A.B. A rapid and non-destructive technique in determining the ripeness of oil palm fresh fruit bunch (FFB). J. Kejuruter. 2018, 30, 93–101. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; Kwon, Y.; Michael, K.; Fang, J.; Yifu, Z.; Wong, C.; Montes, D.; et al. ultralytics/yolov5: v7. 0-YOLOv5 SOTA Realtime Instance Segmentation; Zenodo: Geneva, Switzerland, 2022. [Google Scholar] [CrossRef]
- Terven, J.; Córdova-Esparza, D.M.; Romero-González, J.A. A comprehensive review of YOLO architectures in computer vision: From yolov1 to yolov8 and yolo-nas. Mach. Learn. Knowl. Extr. 2023, 5, 1680–1716. [Google Scholar] [CrossRef]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2018, arXiv:1710.09412. Available online: http://arxiv.org/abs/1710.09412 (accessed on 24 May 2025).
- Xu, R.; Lin, H.; Lu, K.; Cao, L.; Liu, Y. A forest fire detection system based on ensemble learning. Forests 2021, 12, 217. [Google Scholar] [CrossRef]
- Everingham, M.; Eslami, S.A.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the 13th European Conference on Computer Vision (ECCV 2014), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Wang, C.Y.; Mark Liao, H.Y.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2020), Washington, DC, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Koirala, A.; Walsh, K.B.; Wang, Z.; McCarthy, C. Deep learning-method overview and review of use for fruit detection and yield estimation. Comput. Electron. Agric. 2019, 162, 219–234. [Google Scholar] [CrossRef]
- Khanam, R.; Hussain, M. What is YOLOv5: A deep look into the internal features of the popular object detector. arXiv 2024, arXiv:2407.20892. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12993–13000. [Google Scholar]
- Yang, G.; Wang, J.; Nie, Z.; Yang, H.; Yu, S. A lightweight YOLOv8 tomato detection algorithm combining feature enhancement and attention. Agronomy 2023, 13, 1824. [Google Scholar] [CrossRef]
- Shao, H.; Li, X.; Wang, F.; Sun, L.; Wang, C.; Hu, Y. Feasibility study on fruit parameter estimation based on hyperspectral LiDAR point cloud. J. Food Meas. Charact. 2024, 18, 7185–7197. [Google Scholar] [CrossRef]
- Wang, K.; Liew, J.H.; Zou, Y.; Zhou, D.; Feng, J. Panet: Few-shot image semantic segmentation with prototype alignment. In Proceedings of the IEEE International Conference on Computer Vision (ICCV 2019), Seoul, Korea, 20–26 October 2019; pp. 9197–9206. [Google Scholar]
- Make Sense AI. Available online: https://www.makesense.ai/ (accessed on 24 May 2025).
- Kawulok, M.; Ma’ckowski, M. YOLO-type neural networks in the process of adapting mathematical Graphs to the Needs of the Blind. Appl. Sci. 2024, 14, 11829. [Google Scholar] [CrossRef]
- Johnson, J.M.; Khoshgoftaar, T.M. Survey on deep learning with class imbalance. J. Big Data 2019, 6, 27. [Google Scholar] [CrossRef]
- Du, X.; Meng, Z.; Ma, Z.; Lu, W.; Cheng, H. Tomato 3D pose detection algorithm based on keypoint detection and point cloud processing. Comput. Electron. Agric. 2023, 212, 108056. [Google Scholar] [CrossRef]
- Zhang, J.; Tian, M.; Yang, Z.; Li, J.; Zhao, L. An improved target detection method based on YOLOv5 in natural orchard environments. Comput. Electron. Agric. 2024, 219, 108780. [Google Scholar] [CrossRef]
- Sun, L.; Yao, J.; Cao, H.; Chen, H.; Teng, G. Improved YOLOv5 network for detection of peach blossom quantity. Agriculture 2024, 14, 126. [Google Scholar] [CrossRef]
- Peng, H.; Li, Z.; Zou, X.; Wang, H.; Xiong, J. Research on Litchi image detection in orchard using UAV based on improved YOLOv5. Expert Syst. Appl. 2025, 263, 125828. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Lu, X.; Li, B.; Yue, Y.; Li, Q.; Yan, J. Grid R-CNN. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7363–7372. [Google Scholar]
- Crasto, N. Class imbalance in object detection: An experimental diagnosis and study of mitigation strategies. arXiv 2024, arXiv:2403.07113. [Google Scholar]
- Gezawa, A.S.; Liu, C.; Junejo, N.U.R.; Chiroma, H. The applications of 3D input data and scalability element by transformer based methods: A review. Arch. Comput. Methods Eng. 2024, 31, 4129–4147. [Google Scholar] [CrossRef]
- Jia, J.; Liang, W.; Liang, Y. A review of hybrid and ensemble in deep learning for natural language processing. arXiv 2023, arXiv:2312.05589. [Google Scholar]
- Kulik, S.; Shtanko, A. Experiments with neural net object detection system YOLO on small training datasets for intelligent robotics. In Advanced Technologies in Robotics and Intelligent Systems: Proceedings of ITR 2019; Springer: Berlin/Heidelberg, Germany, 2020; pp. 157–162. [Google Scholar]
- DosReis, D.H.; Welfer, D.; De Souza Leite Cuadros, M.A.; Gamarra, D.F.T. Mobile robot navigation using an object recognition software with RGBD images and the YOLO algorithm. Appl. Artif. Intell. 2019, 33, 1290–1305. [Google Scholar] [CrossRef]
- Sahin, O.; Ozer, S. Yolodrone: Improved Yolo architecture for object detection in drone images. In Proceedings of the 2021 44th International Conference on Telecommunications and Signal Processing (TSP), Brno, Czech Republic, 26–28 July 2021; pp. 361–365. [Google Scholar]
- Chen, C.; Zheng, Z.; Xu, T.; Guo, S.; Feng, S.; Yao, W.; Lan, Y. YOLO-Based UAV Technology: A Review of the Research and Its Applications. Drones 2023, 7, 190. [Google Scholar] [CrossRef]
- Dilmi, W.; ElFerik, S.; Ouerdane, F.; Khaldi, M.K.; Saif, A.-W.A. Technical aspects of deploying UAV and ground robots for intelligent logistics using YOLO on embedded systems. Sensors 2025, 25, 2572. [Google Scholar] [CrossRef]




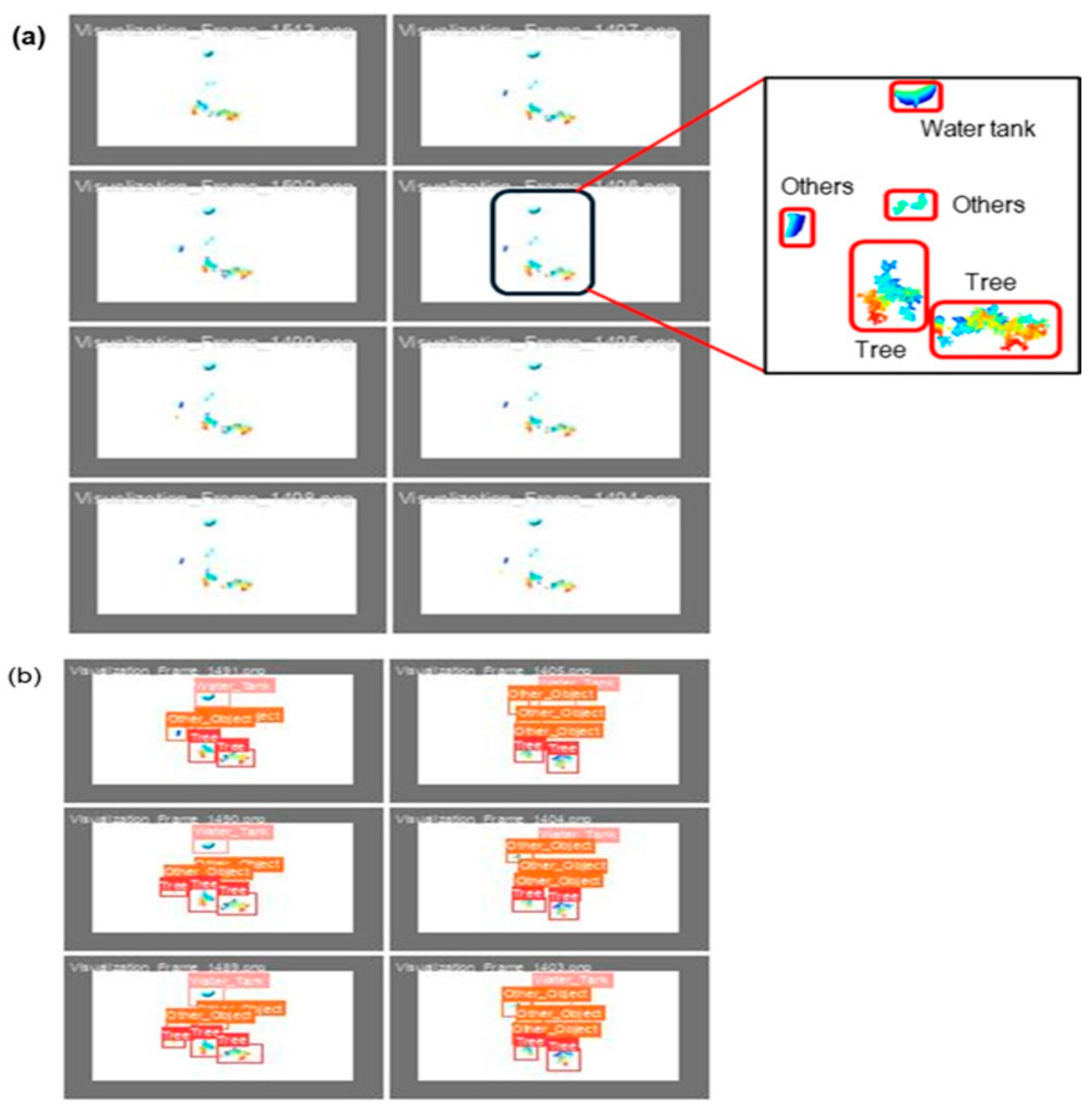
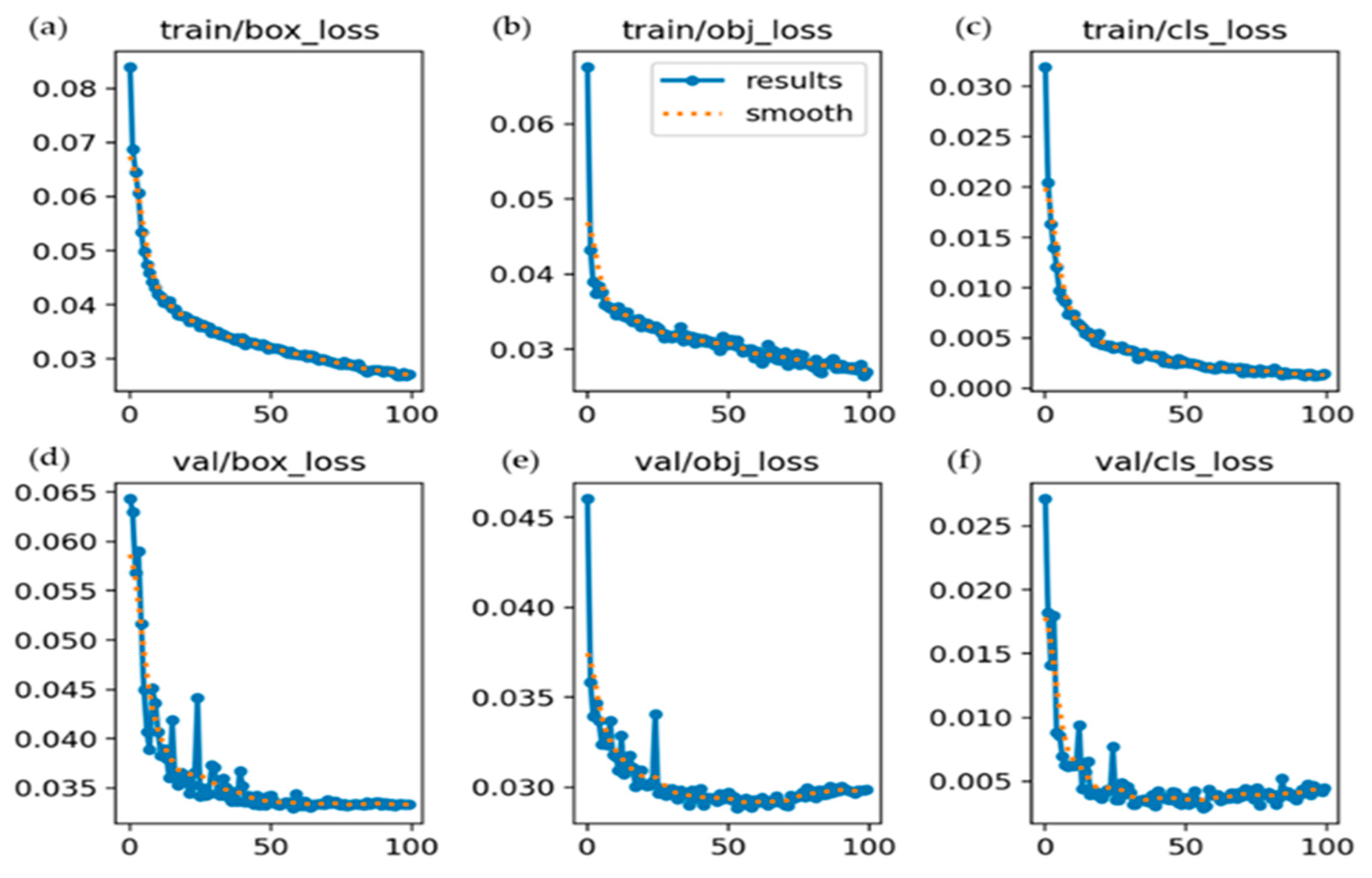
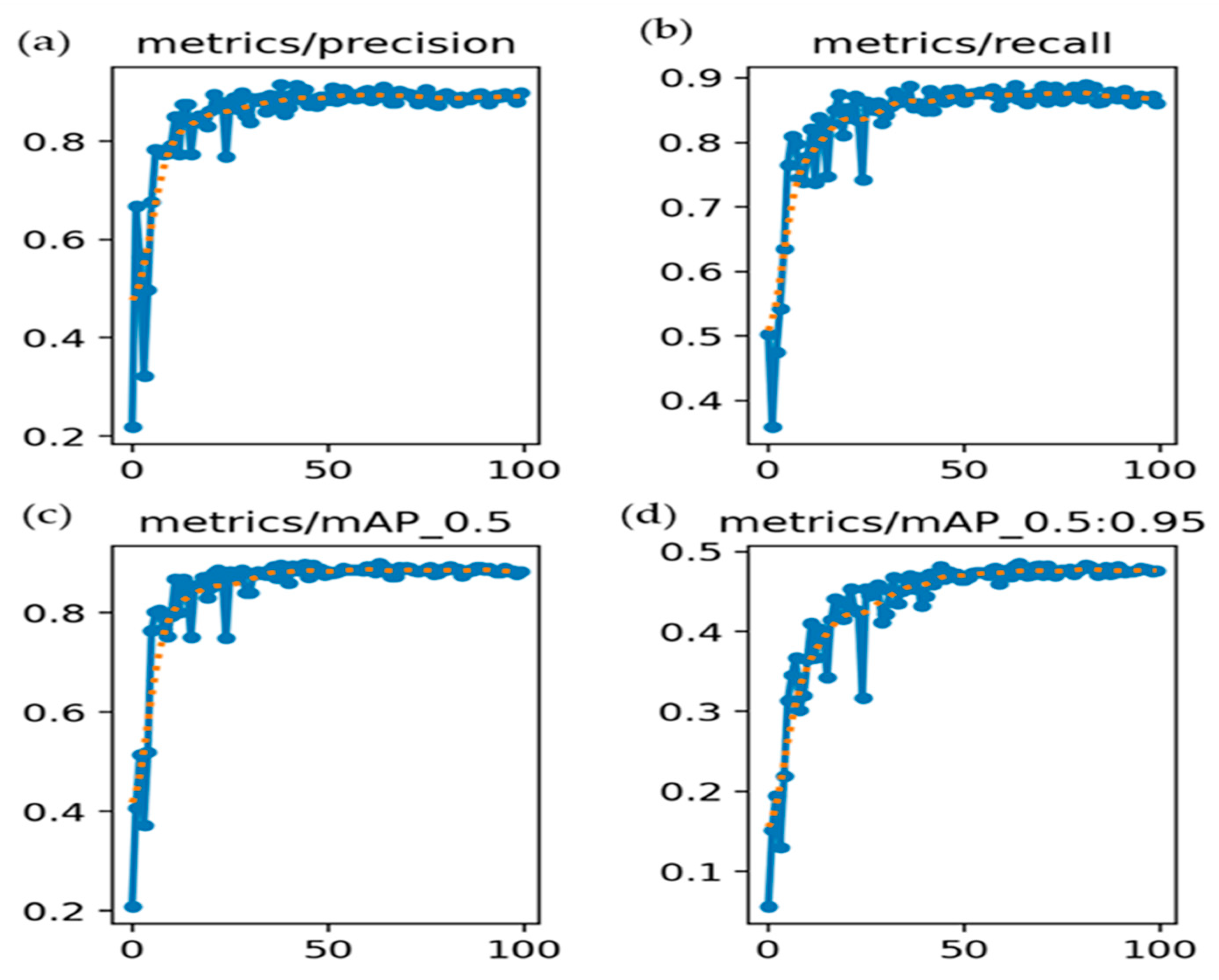
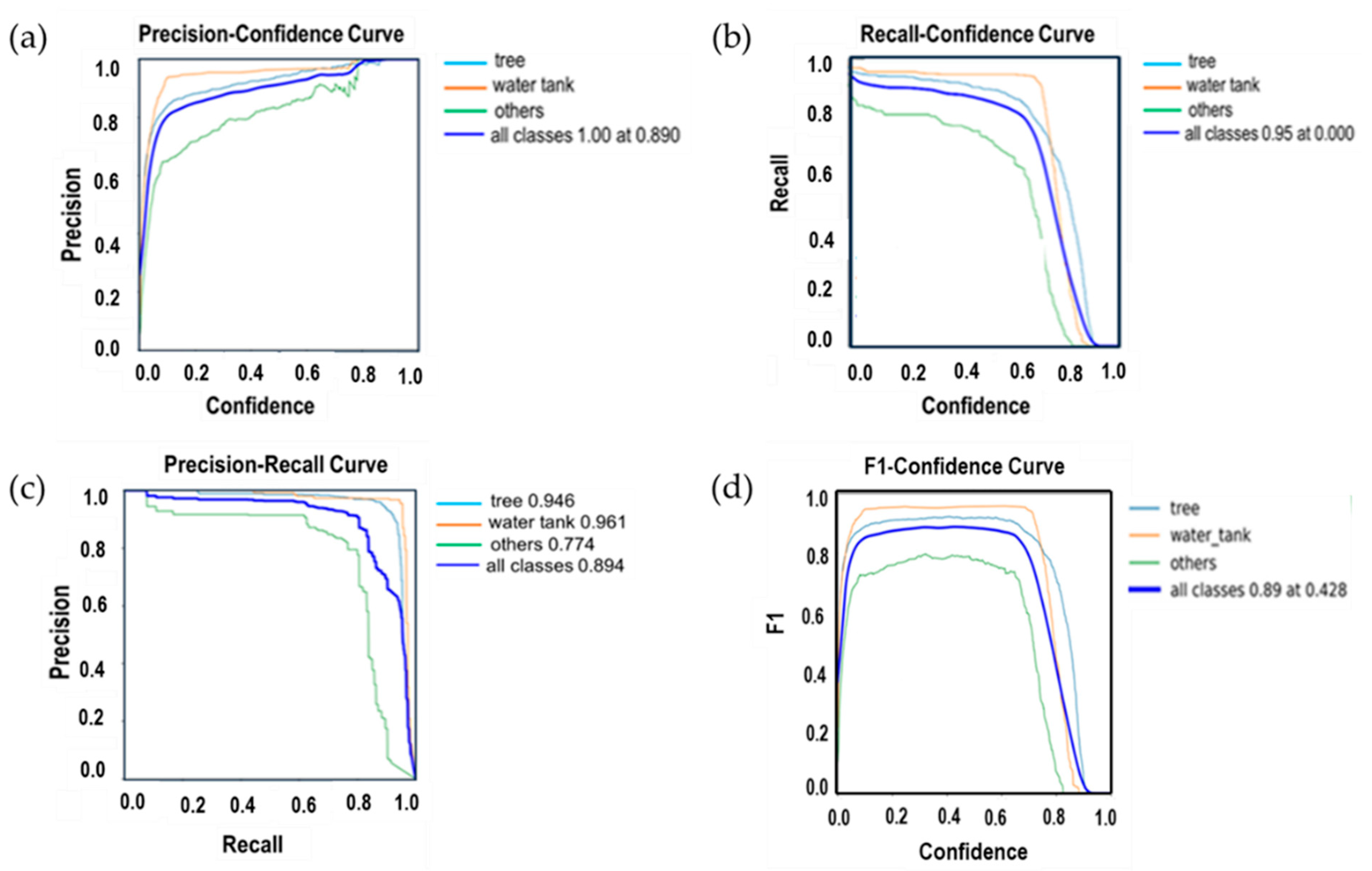



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Specifications |
|---|---|
| Channels | 16 |
| Range of measurement | Up to 100 m |
| Range accuracy | ±3 cm (typical) |
| HFOV | 360° |
| VFOV | 30° (+15.0° to −15.0°) |
| Angular Resolution (vertical) | 2.0° |
| Angular Resolution (horizontal) | 0.1–0.4° |
| Rotation rate | 5–20 Hz |
| Wavelength (laser) | 903 nm |
| Power (consumption) | 8 W (typical) |
| Voltage (operating) | 9–18 V |
| Weight | ~830 g |
| Temperature (operating) | −10 °C to +60 °C |
| Temperature (storage) | −40 °C to +105 °C |
| Data interface | 100 Mbps ethernet |
| Data format | UDP packets with ToF, distance, rotation angles, and synchronized timestamps (µs resolution) |
| Measurement rate | 300,000 points/s (single return), 600,000 points/s (dual return) |
| Epochs | GPU Memory | Box Loss | Objectness_Loss | Class Loss | Instances | Size |
|---|---|---|---|---|---|---|
| 100/100 | 12.6 GB | 0.025 | 0.028 | 0.001 | 96 | 1216 × 1216 |
| Class | Images | Instances | P | R | mAP@0.5 | mAP@0.5:0.95 |
| All | 300 | 949 | 0.903 | 0.871 | 0.892 | 0.478 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Karim, M.R.; Reza, M.N.; Ahmed, S.; Lee, K.-H.; Sung, J.; Chung, S.-O. Detection of Trees and Objects in Apple Orchard from LiDAR Point Cloud Data Using a YOLOv5 Framework. Electronics 2025, 14, 2545. https://doi.org/10.3390/electronics14132545
Karim MR, Reza MN, Ahmed S, Lee K-H, Sung J, Chung S-O. Detection of Trees and Objects in Apple Orchard from LiDAR Point Cloud Data Using a YOLOv5 Framework. Electronics. 2025; 14(13):2545. https://doi.org/10.3390/electronics14132545
Chicago/Turabian StyleKarim, Md Rejaul, Md Nasim Reza, Shahriar Ahmed, Kyu-Ho Lee, Joonjea Sung, and Sun-Ok Chung. 2025. "Detection of Trees and Objects in Apple Orchard from LiDAR Point Cloud Data Using a YOLOv5 Framework" Electronics 14, no. 13: 2545. https://doi.org/10.3390/electronics14132545
APA StyleKarim, M. R., Reza, M. N., Ahmed, S., Lee, K.-H., Sung, J., & Chung, S.-O. (2025). Detection of Trees and Objects in Apple Orchard from LiDAR Point Cloud Data Using a YOLOv5 Framework. Electronics, 14(13), 2545. https://doi.org/10.3390/electronics14132545