3.1. Feature-Enhanced Neck Network
In real-world applications, traffic cameras often suffer from varying resolutions, making multi-resolution feature fusion crucial. However, low-resolution images often lack detailed information due to blurring, which can negatively impact the model’s detection capability. Popular neck networks, such as Feature Pyramid Networks (FPNs), Path Aggregation Networks (PANets), and Globally Distributed (GD) mechanisms, attempt to address this challenge. FPN transmits semantic information through a top-down path, but the semantic confusion between hierarchical levels of low-resolution feature maps can weaken the ability to detect small objects. PANet introduces lateral paths to better integrate features from different levels, but it is structurally complex and computationally expensive. The GD mechanism effectively utilizes global information through global pooling and information distribution, but at the cost of local details. The FPN variant used in the classic YOLO series achieves feature fusion between adjacent levels, but the efficiency of cross-level information transmission is insufficient, and features obtained indirectly suffer from information degradation.
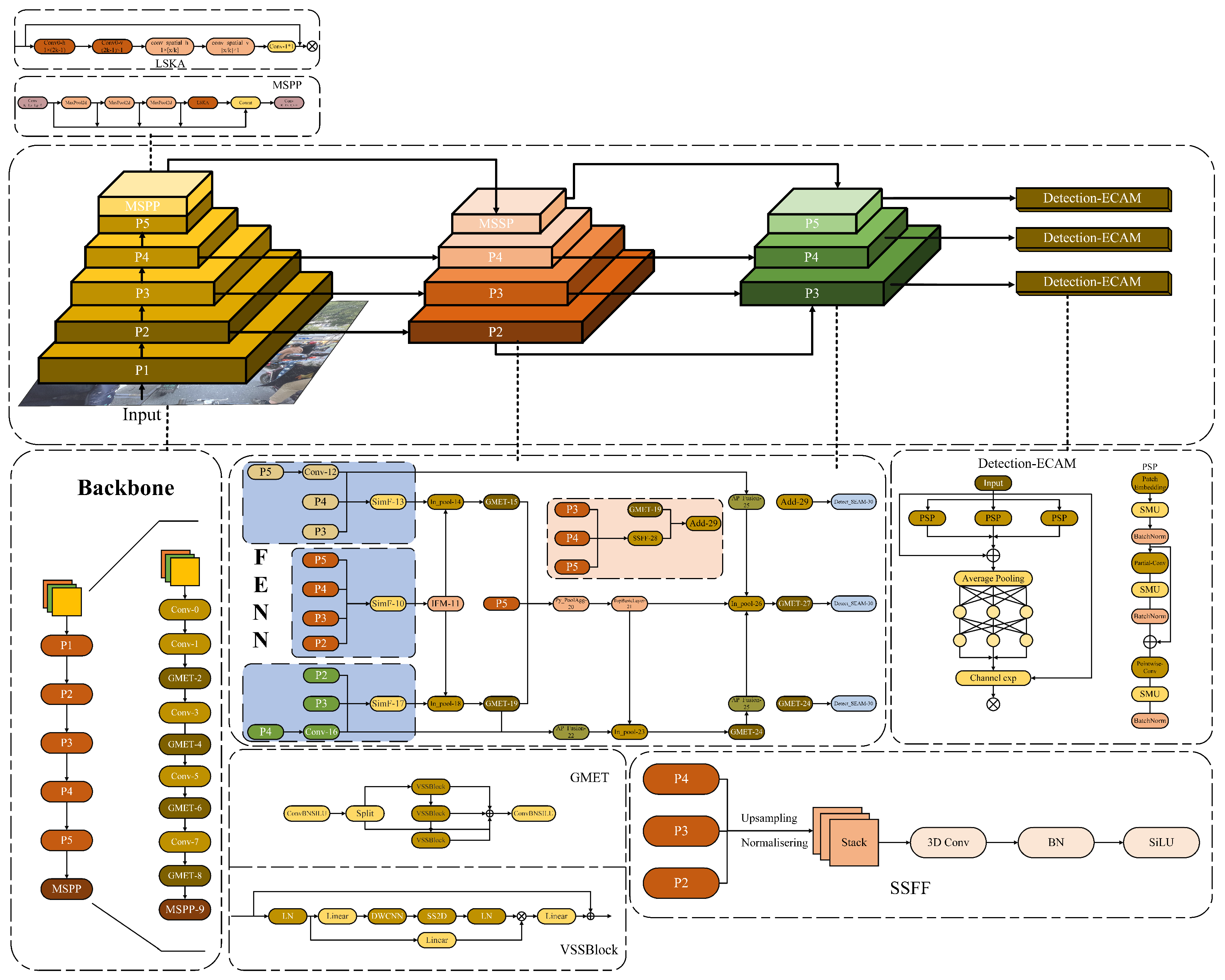
To address these bottlenecks, this study proposes a Feature-Enhanced Neck Network (FENN), which innovatively integrates the core ideas of the GD mechanism with the SSFF module [
42]. FENN constructs a dual-path cross-level fusion architecture, utilizing convolutional operators and self-attention mechanisms to efficiently fuse multi-resolution features. As shown in
Figure 4, FENN enhances multi-scale features through the cross-level feature interaction module.
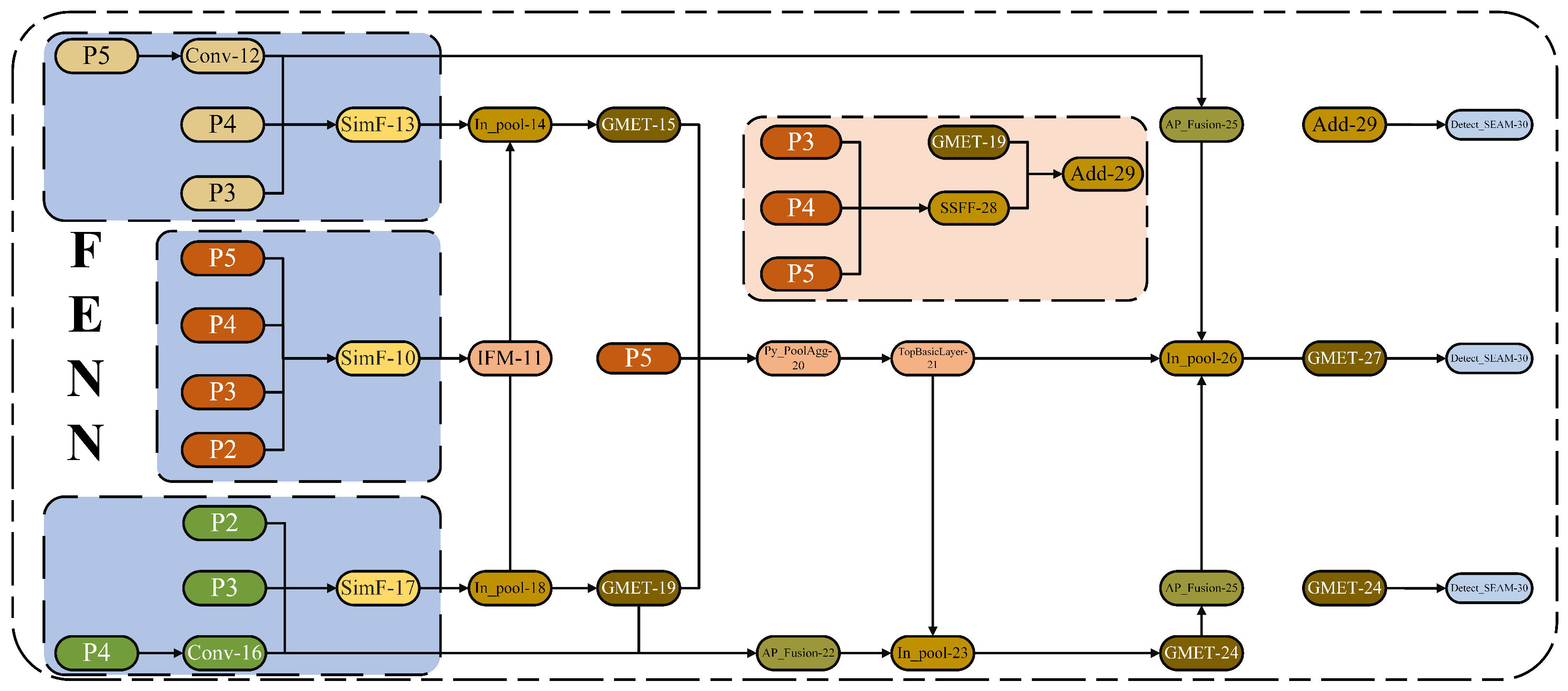
To prevent information loss during transmission, a novel network structure, the FENN mechanism, designed for non-motorized vehicle and helmet recognition, is used in the neck part of this study. It abandons the original recursive method and employs a unified module (SimF) to collect and fuse information from all layers, which is then distributed to different layers. This approach not only avoids the inherent information loss problem of traditional FPN structures but also enhances the information fusion capability of intermediate layers without significantly increasing latency. The FENN neck network first uses the CSPDarknet53 backbone network P2, P3, P4, and P5 to extract multidimensional feature information from the image for fusion, thereby obtaining high-resolution features that retain small target information. To address the challenges of multi-resolution target images and dense scenes, SimF collects and aligns features from different layers, fusing three input feature maps into one more informative output feature map. Then, IFM further extracts and fuses the aligned features via a series of convolutions and feature fusion to obtain global information, providing richer feature information for subsequent network layers. Specifically, Inpool is used to convert the convolution embeddings of local (SimF) and global (IFM) feature maps, reducing the dimension of input features to a unified size using specific global feature channel weighting during the feature fusion process. The fused features are activated and distributed across different layers, achieving more efficient information transmission and richer feature representation.
The two global Mamba-enhanced architectures GMET (detailed later) utilize state space modeling and four-direction scanning strategies to extract key information from multi-scale features and enhance global context capture, resulting in deep global feature information. To enhance the model’s ability to process features at different scales, the PyPoolAgg module adjusts the spatial dimensions of P5 and deep feature maps to the same target size using adaptive mean pooling for channel dimension concatenation, forming a high-dimensional feature map that retains multi-scale information. Convolution operations then adjust the channel number to the target number of channels, outputting the fused feature map, effectively enhancing feature expression while reducing the computational demand of subsequent steps.
APFusion adjusts the size of the two input tensors, Conv-16 and GMET, to match GMET through an adaptive mean pooling operation, and then performs concatenation along the channel dimension. This operation is used to fuse information from different sources when processing feature maps for further processing or feature extraction. To construct a large-scale neural network model with Transformer characteristics, this study builds the TopBasicLayer on the Transformer block. By gradually passing the input features through multiple Transformer blocks, followed by a convolutional layer for feature transformation, feature extraction, and conversion, the model is refined. Finally, at the end of the network, Inpool adjusts the channel number of the local features (APFusion) to the output channel number through convolution layers, extracts specific parts of the global features (TopBasicLayer) to generate global features and activation weights, and dynamically selects pooling or upsampling operations based on the spatial dimensions of the local features. This ensures that the spatial dimensions of both are consistent. The local and global features are then fused using a weighted sum (with weights generated by the activated global features), enhancing the expression capability of the local features. This design enables the effective fusion of local details and global context information, which is further captured by GMET for key feature information.
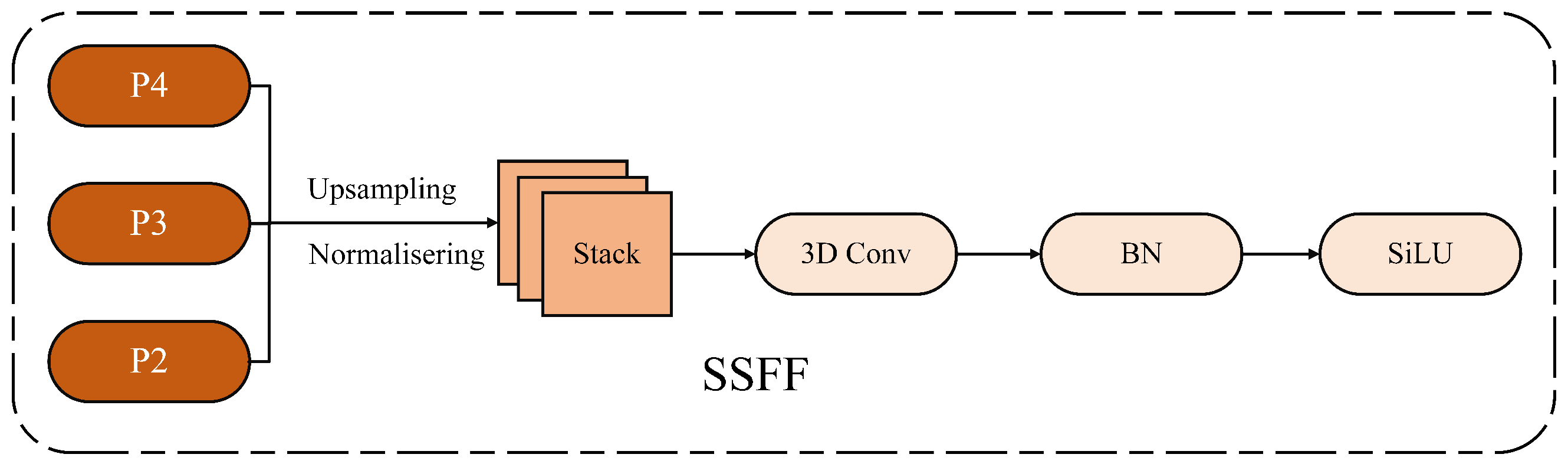
The neck network finally integrates the SSFF scale sequence feature fusion module, as shown in
Figure 5. It aims to effectively fuse the feature maps of P3, P4, and P5 to capture non-motorized vehicles and riders wearing helmets at different spatial scales, sizes, and shapes. The P3, P4, and P5 feature maps are normalized to the same size, upsampled, and stacked together as 3D convolution inputs to Add. These are then combined with two GMET feature inputs from different layers and passed to the detection head, which integrates information from multi-resolution images. This allows for a better combination of high-dimensional information from deep feature maps with detailed information from shallow feature maps, further improving helmet target detection accuracy. According to the evaluation of this study’s helmet dataset, the neck network outperforms other state-of-the-art methods in terms of detection accuracy and speed.
3.2. Global Mamba Architecture Enhancement Algorithm
In traffic scenarios with dense and complex weather conditions (e.g., low light), the model must be capable of efficiently understanding and processing the distribution of non-motorized vehicles and helmets under challenging meteorological conditions, while capturing key features from a global perspective. Recent advancements in image analysis have established important benchmarks with Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) [
43]. CNNs excel in capturing local features through convolution operations, while ViT significantly enhances global context understanding using self-attention mechanisms. However, both architectures have limitations in perceiving global information in images, which makes it difficult to maintain global perception while significantly reducing computational complexity—an essential aspect for the accuracy and speed of object detection.
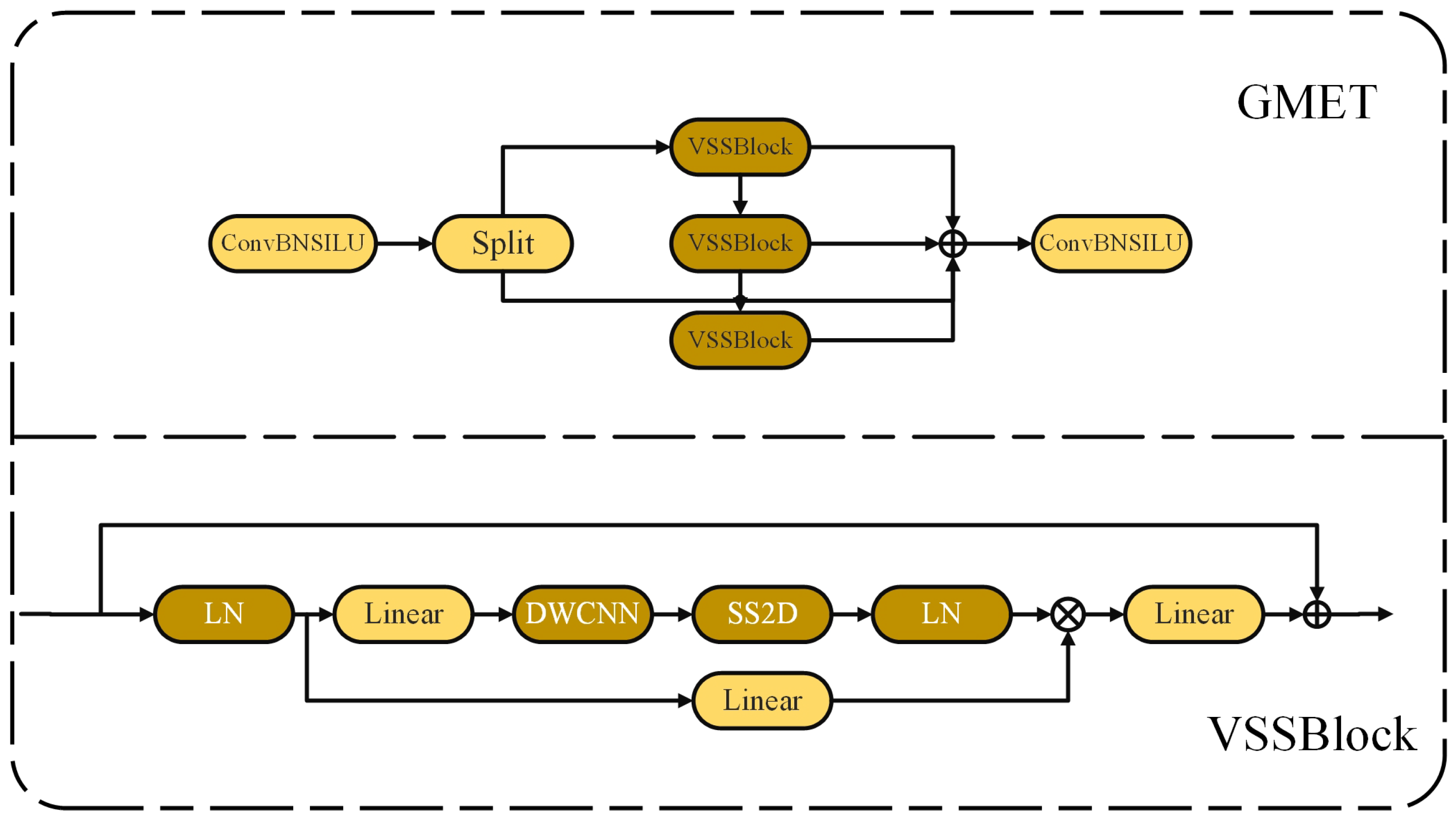
To address the aforementioned issues, this study draws inspiration from the Visual State Space (VSS) module in the VMamba architecture and constructs the Global Mamba Architecture Enhancement Algorithm (GMET). The GMET mechanism is illustrated in
Figure 6. The GMET module is a custom neural network component inherited from the C2f class, where the Bottleneck in C2f is replaced by the VSS module. By utilizing a four-directional scanning strategy and the selective scanning spatial state sequence model S6, GMET enables a more comprehensive scan of information and captures diverse features. At the same time, it significantly reduces computational complexity while maintaining global perception capability. This approach enhances detection precision in complex environments. Based on the C2f module, the input data is processed through the first convolutional layer, followed by a Split operation, which divides the output into two parts. One part is directly passed to the output, while the other part is processed through multiple VSS modules. The VSS module normalizes the data through a linear layer and splits it into two branches. The first branch is processed by a linear layer and activation function, while the second branch undergoes linear layers, depthwise separable convolutions, and activation functions before entering the 2D Selective Scan (SS2D) [
44]. The SS2D module unfolds the input image into sequences in four directions through a scanning operation, followed by the self-selective scanning spatial state sequence model S6 [
45] to extract features. S6 is an extension of the state space model (SSM), allowing the model to dynamically adjust weights by introducing an input-dependent selection mechanism to ensure comprehensive scanning and capture of diverse features. A subsequent scan merging operation sums the sequences from the four directions and restores the output image to the input size, helping retain relevant information and filter out irrelevant details. The processed features are then normalized again and element-wise multiplied with the output from the first branch. After a linear layer that mixes the features, they are added with a residual connection to form the output of the VSS block. Finally, the results of the two parts are concatenated along the channel dimension and passed through a second convolutional layer to obtain the final output. GMET achieves a more enriched gradient flow while ensuring lightweight processing. Unlike the typical ViT, it adopts a simplified structure without the MLP stage, enabling denser block stacking within the same depth budget. GMET thus offers lower computational complexity while enhancing the ability to capture key features across a global range.
State space models (SSMs) originated from the Kalman filter and are mathematical models used to describe the dynamic behavior of systems. They map input signals to output responses through hidden states. is the hidden state. is the input signal, is the output response:
Continuous-Time State Space Model:
where
,
,
, and
are the weighting parameters.
Discrete-Time State Space Model:
To integrate continuous-time state space models into deep learning models, they need to be discretized. Specifically, for the time interval
, the analytical solution of the hidden state
at
can be expressed as:
By sampling with the time-scale parameter
(i.e.,
, the hidden state
can be discretized as:
where
and
are the hidden states at time steps
b and
a.
and
are the input matrix and input signal at time step
i.
is the time step length at time step
i. This discretization method is based on the Zero-Order Hold (ZOH) method, which is widely used for discretizing state space models. The discretized version achieves linear complexity through a parallel scanning algorithm, but it is only applicable to one-dimensional sequences. For two-dimensional image data, directly applying the one-dimensional scanning would result in the loss of spatial structure information.
S6 is an extension of the state-space model that enables the model to dynamically adjust the weights to better capture contextual information by introducing an input-dependent selection mechanism, which is formulated as follows:
where
is the weight matrix, representing the weight at time step
i.
is calculated as:
This means that the weights are computed from the exponential function of the state matrix A of the accumulated time steps j. The selective scanning mechanism (S6) improves the flexibility and efficiency of the model by dynamically adjusting the weights so that the model can selectively focus on different time steps according to the input signals .
GMET (Generalized Matrix Expansion Technique) unfolds a 2D image into multiple 1D sequences through the SS2D four-way scanning path, which is represented mathematically as:
Scan: The input image is unfolded into four independent 1D sequences along four directions (such as from top-left to bottom-right, bottom-right to top-left, etc.). Each sequence is processed by an independent S6 module, generating intermediate state sequences
. Merge: The four processed sequences are then merged back into a 2D feature map. SS2D, through the four-way scanning path, covers all spatial positions, and each pixel’s hidden state
integrates contextual information from different directions. In contrast to the traditional SSM’s 1D scanning, its response computation can be expanded as:
Here,
represents the direction-dependent dynamic parameters, which are adjusted through an input-dependent selection mechanism, enhancing the dynamic perception of both local and global information. The complexity of GMET is
, still maintaining linear growth (in contrast to the traditional ViT self-attention, which has a complexity of
, further reducing the actual computational overhead. The corresponding computation formula is:
Here, w represents the accumulated weights along the scanning path, and M is the mask matrix. GMET, through the superposition of multi-directional scanning paths, implicitly constructs global interactions similar to self-attention but avoids quadratic complexity.
In order to more effectively extract global features and reduce the number of parameters, the GMET module is not only deployed in the backbone network but is also incorporated after the In_pool in the neck network of FENN. The choice of this position is carefully designed, based on a comprehensive consideration of the spatial dimensions and semantic information of the feature maps. In the backbone network, the GMET module primarily extracts basic features layer by layer. In the neck network, feature maps from different layers contain various scales and semantic information. By integrating the GMET module after In_pool, the feature maps at this location can be fully utilized, allowing for effective fusion of multi-scale features. This design enables the GMET module to extract key information from features at different scales and pass it on to subsequent classification or regression tasks, providing the model with more discriminative feature inputs. Although the GMET module is applied in both the backbone and neck networks, its focus in the backbone network is mainly on the initial extraction and enhancement of basic features, while in the neck network, it emphasizes the further fusion and optimization of features from different stages to achieve better feature transfer and utilization. Therefore, this design allows the GMET module to exert its unique advantages at different stages of the model.
The parameter setting of the GMET module typically configures the output channel number (c2) to be the same as the input channel number (c1) to maintain consistency in feature dimensions. For instance, when the input channel number is 256, c2 is also set to 256. When channel fusion or dimensionality reduction is required, c2 can be set to other values (e.g., 128), which helps reduce the number of parameters while preserving the feature representation capability. The repetition count of the VSSBlock (n) is typically set to 3 to 5. For complex tasks or deep networks, the value of n can be increased to enhance the feature representation capability. For example, when the FENN network processes high-resolution images or performs fine-grained classification tasks, n can be set to 5.
Through the detailed integration and tuning strategies outlined above, the GMET module can effectively extract and enhance global features while maintaining a low parameter count, providing high-quality feature inputs for subsequent tasks.
3.3. Multi-Scale Spatial Pyramid Pooling
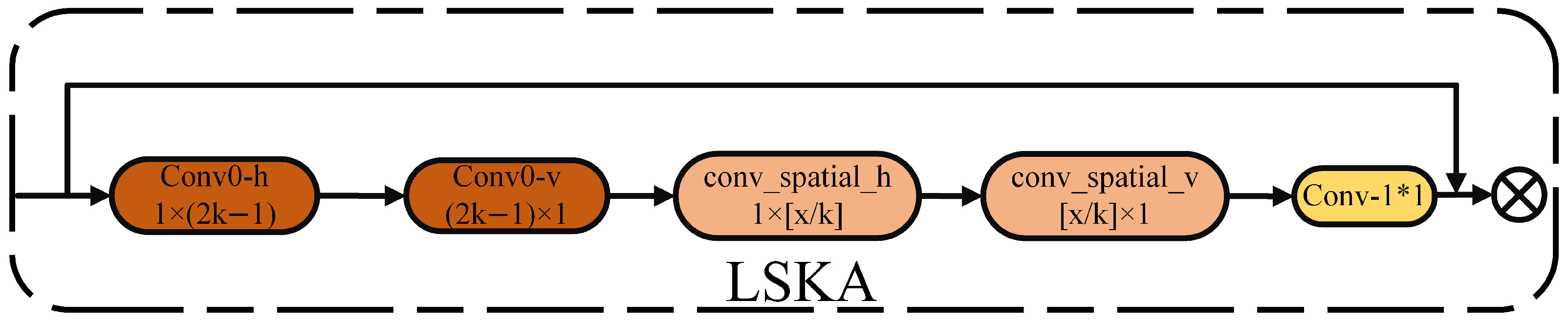
In real-world traffic scenarios, the scale of helmets constantly changes, and in low-light and dim environments, the model’s detection precision decreases. This requires the model to enhance its ability to fuse cross-scale features. In the feature extraction process, although SPPF can divide the receptive fields of different sizes into multiple levels and generate fixed-length feature representations for input images of any size through pooling operations, it tends to lose detailed information and incur high computational costs, especially when dealing with higher-level pooling during the pyramid pooling and feature fusion stages. To address this issue, this paper designs a Multi-Scale Spatial Pyramid Pooling (MSPP) module, which integrates SPPF with the LSKA attention mechanism and introduces multi-dilation convolution and adaptive kernel selection strategies, enabling more effective capture of multi-scale features. The LSKA mechanism achieves this by decomposing the two-dimensional convolution kernels of deep convolution layers into cascaded horizontal and vertical one-dimensional convolution kernels, allowing the direct use of large convolution kernels in the attention module without the need for additional modules. This design not only enhances the ability to extract cross-scale features but also effectively alleviates the secondary increase in computational and memory overhead caused by the larger convolution kernel sizes in the SPPF module.
The structure of LSKA mainly consists of an initialization convolution layer, spatial dilated convolution layers, and fusion with attention application. The shape of the input feature map
X is (B, D, H, W), where B represents the batch size, D is the number of channels, and H and W are the spatial dimensions. conv0h and conv0v perform one-dimensional convolutions in the horizontal and vertical directions, respectively, to initially extract horizontal and vertical information. This step generates an initial attention map to help the model focus on the important parts of the image. Subsequently, spatial dilated convolutions conv-spatial-h and conv-spatial-v, with different dilation rates, perform large kernel convolutions in the horizontal and vertical directions to capture long-range spatial dependencies. These convolution operations use dilated convolutions to expand the receptive field, enabling the model to process image features with greater precision and enhance its understanding of spatial relationships within the image. They effectively increase the receptive field without significantly increasing computational cost, allowing for the capture of broader contextual information. Afterward, LSKA adjusts the number of channels() in the feature map to D through a convolution, merging horizontal and vertical feature information. The fused features are then used to generate the final attention map. The input feature map
X is element-wise multiplied by the generated attention map to enhance the representational power of the input feature map. In this way, each element of the original feature map is weighted according to the values of the attention map, highlighting important features while suppressing irrelevant ones. The structure of LSKA is shown in
Figure 7.
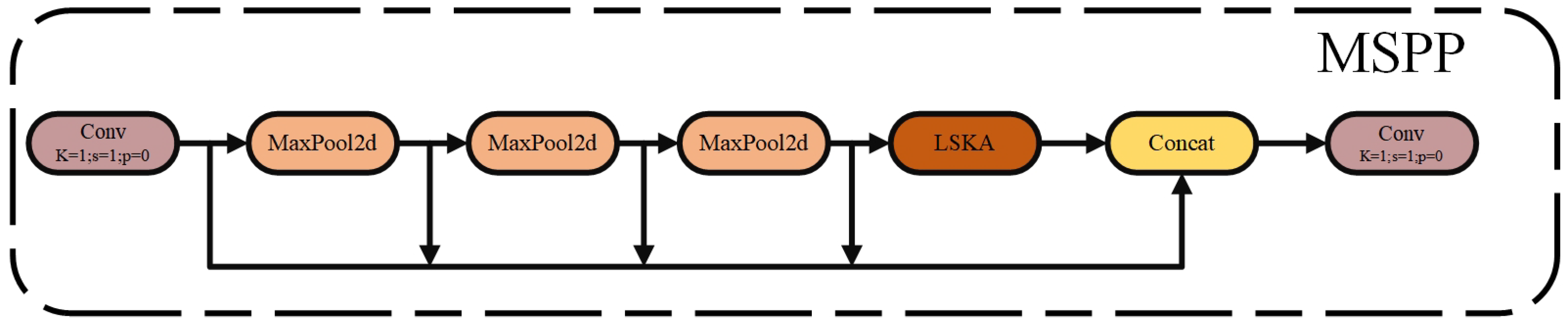
This study proposes a Multi-Scale Spatial Pyramid Pooling (MSPP) mechanism, which significantly enhances the multi-scale feature aggregation ability in complex traffic scenarios by reconstructing the traditional SPPF architecture and deeply integrating the large-kernel separable attention mechanism (LSKA). The MSPP structure first receives the input feature map and undergoes preliminary processing through a convolutional layer. Then, the feature map sequentially undergoes three consecutive maximum pooling operations with residual structures. In each pooling operation, the kernel size is 5 × 5, and padding is added to maintain the feature map dimensions. The pooled feature maps are concatenated with the original feature map to form a feature map that contains multi-scale information. The pooling formula is as follows:
Here, refers to the input size, padding denotes the convolution padding pixels, and kernel size represents the size of the convolution kernel.
This study integrates the SPPF attention mechanism with the LSKA module, referred to as the Multi-Scale Spatial Pyramid Pooling (MSPP) attention mechanism. The goal is to enhance feature representation by leveraging multi-scale feature fusion and attention mechanisms. In the structure of MSPP, the LSKA module is added after all max-pooling operations and before the second convolutional layer. The input feature map
X has the shape of (
), where
B is the batch size,
C is the number of channels, and
H and
W are the spatial dimensions. The channel number of the input feature map is halved, and the output feature map has the shape of (
). The MaxPool layer is applied multiple times to perform max-pooling operations on the feature map, generating feature maps at different scales. Each pooling operation maintains the spatial dimensions while gradually reducing the detail of information, thus extracting features at different scales. This process can be expressed as:
Next, the original feature map X, along with the pooled feature maps , , and , are concatenated along the channel dimension to form a high-dimensional feature map with the shape of (). This concatenated high-dimensional feature map is then input into the LSKA module, where the attention mechanism is applied to enhance the feature representation. Finally, a convolutional layer is used to adjust the number of channels to , producing the final output feature map.
However, as part of the feature map layer in the backbone network, MSPP plays a role in the feature fusion process and is integrated into the FENN neck network, providing richer multi-scale feature inputs for the neck network. Specifically, MSPP adjusts the feature map to the appropriate target size through operations such as adaptive average pooling, and concatenates it along the channel dimension with other feature maps, forming a high-dimensional feature map that retains multi-scale information. This feature map is then passed to the PyPoolAgg module in the FENN neck network, where it is fused with features from different levels of SimF as input, significantly enhancing the neck network’s ability to process multi-scale features. This design allows MSPP and FENN to complement each other’s strengths, forming an organic whole.
By embedding the LSKA module into the MSPP structure, the model is able to focus more precisely on the key information in the image, significantly enhancing the fusion ability of multi-scale features in complex traffic scenarios. This also effectively improves the understanding of spatial relationships, ultimately achieving more accurate feature extraction and classification. The MSPP structure is shown in
Figure 8.
3.4. Detection-ECAM (Enhanced Channel Attention Mechanism with Self-Attention)
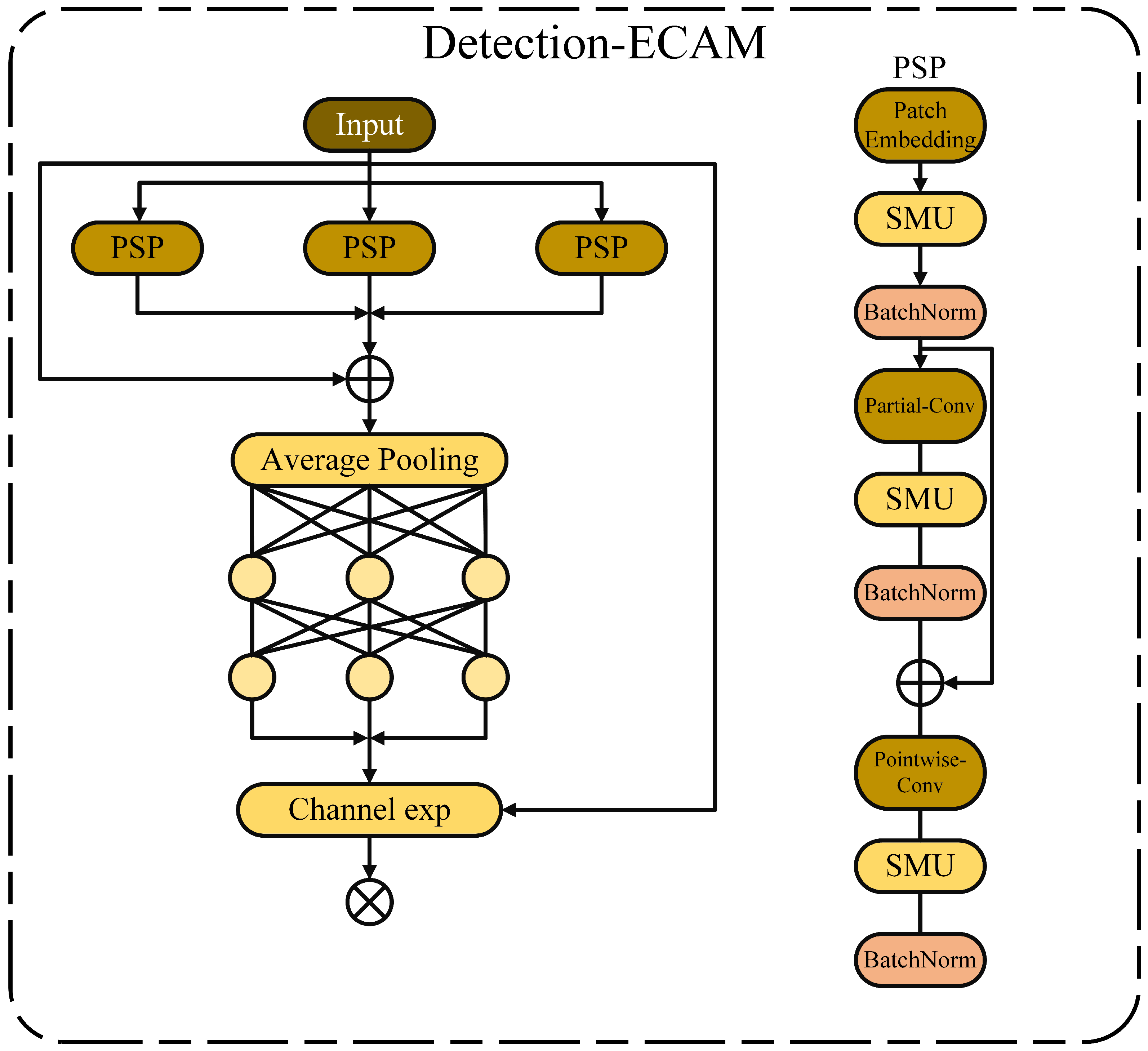
Helmet occlusion frequently occurs in traffic-dense environments, often leading to the detector’s inability to accurately detect helmets, thereby reducing the system’s precision and recall rate. Occlusion results in the loss of some data, making it difficult for the model to extract sufficient features for precise localization and detection. Helmet occlusion can be categorized into two types: occlusion between different helmets and occlusion caused by other objects. The former makes detection accuracy highly sensitive to the NMS threshold, leading to missed detections, while the latter causes feature disappearance and inaccurate localization. To address this challenge, this paper proposes the enhanced channel attention mechanism with self-attention (ECAM). ECAM enhances the detection capability of occluded targets, emphasizes the helmet regions in the image, and weakens the background areas accordingly, as shown in
Figure 9.
This study observes that the feature maps of different channels are highly similar, leading to feature map redundancy in both standard convolution and depthwise separable convolution. However, when utilizing depthwise convolution (DWConv) or group convolution (GConv) to extract spatial features, while DWConv can effectively reduce FLOPs, it cannot simply replace regular convolution, as it causes a significant drop in precision. Chen J et al. [
46] pointed out that partial convolution (PConv) can automatically mask invalid regions in the input feature map during the convolution process, demonstrating excellent performance when handling incomplete or unevenly distributed data. This characteristic allows PConv to focus better on valid information areas when processing images with complex backgrounds or occlusions, thereby improving the precision of feature extraction. We have experimentally verified that PConv achieves higher feature extraction precision than traditional convolutions when handling occluded images, as confirmed in the ablation experiment
Section 4.4.5. The masking mechanism of PConv effectively reduces the interference from invalid regions during feature extraction, enhancing the model’s ability to capture valid information. In the first part of ECAM, the convolution with residual connections is PConv, which has lower FLOPs compared to regular convolution and higher computational speed (FLOPs) than DWConv/GConv. The working principle of PConv is shown in
Figure 10. It applies regular convolution to a subset of the input channels for spatial feature extraction, without modifying the remaining channels. For continuous or regular memory access, this study considers the first or last contiguous channel as the representative of the entire feature map for computation. Without loss of generality, we assume that the input and output feature maps have the same number of channels. The computational cost (FLOPs) of PConv is defined as follows:
The memory access pattern of PConv is as follows:
Here, h and w represent the width and height of the feature map, k is the size of the convolution kernel, and is the number of channels in a standard convolution. With a typical partial ratio , the FLOPs of a PConv is only of a regular Conv. The memory access of PConv is only one-quarter of that of the standard convolution.
To fully and effectively utilize the information from all channels, this study further adds pointwise convolution (PWConv) after PConv, which can leverage the redundancy in intermediate convolutions and further reduce FLOPs, that is:
The second part of ECAM utilizes a two-layer fully connected network to integrate information from each channel, enabling the network to strengthen the connections between all channels. By learning the relationship between occluded and non-occluded helmets in previous steps, the model aims to address the missing cases in occlusion scenarios. However, excessive use of these layers throughout the network could limit feature diversity, thereby degrading network performance and potentially reducing overall computation speed. The SMU (Sigmoid-Multiplied Unit) activation function is a self-gating activation function. Biswas K et al. [
47] pointed out that it adapts features by multiplying the input features with the output of the sigmoid function. Compared to the GELU (Gaussian Error Linear Unit) activation function, the SMU activation function is more effective in preserving the detailed information of features while reducing the over-smoothing phenomenon. We conducted a detailed comparison experiment between the SMU and GELU activation functions, as confirmed in the ablation experiment
Section 4.4.5. The experimental results show that the SMU activation function better preserves the detailed information of features when processing images with rich details, thereby demonstrating higher performance in image classification and object detection tasks. To avoid this, this study places BatchNorm and the activation function SMU after each intermediate layer of PWConv to maintain feature diversity and achieve lower latency. The ECAM structure is shown in
Figure 9. This exponential normalization provides a monotonic mapping relationship, making the results more tolerant of positional errors. Finally, the output of the ECAM module is used to scale the attention of the original features, allowing the model to more effectively handle the occlusion of non-motorized vehicles, riders, and helmets, while also reducing computational load. This is confirmed in the visual experiments in
Section 4.4.6.
3.5. Enhanced Precision-IoU
There are currently many regression-based loss functions, such as GIoU [
48], which introduces the minimum enclosing box of the predicted and ground truth boxes to obtain the relative weight of the predicted and ground truth boxes in the closure area. However, the minimum enclosing rectangle must be computed for each predicted and ground truth box, limiting the computation and convergence speed. DIoU builds upon IoU by directly regressing the Euclidean distance between the centers of the two boxes, improving convergence speed. CIoU extends DIoU by incorporating the consistency of aspect ratios between the predicted and ground truth boxes. EIoU [
49] adds a penalty term that splits the aspect ratio influence factor into separate calculations for the target box and anchor box’s width and height, based on the penalty term of CIoU. This loss function consists of three components: overlap loss, center distance loss, and width–height loss. The first two components follow the approach in CIoU, while the width–height loss directly minimizes the width and height differences between the target and anchor boxes, leading to faster convergence. SIoU [
50] redefines the distance loss, effectively reducing the degrees of freedom in regression, thus accelerating network convergence and further enhancing regression accuracy. However, existing IoU loss functions suffer from unreasonable penalty factors, causing anchor boxes to enlarge and slowing convergence in object detection. Although CIoU and EIoU acknowledge this issue, they do not address its root cause. Additionally, the current IoU loss functions have limitations, such as failing to accurately reflect the differences between the anchor box and the target box, neglecting object size, or degrading performance under certain conditions. The formula is as follows.
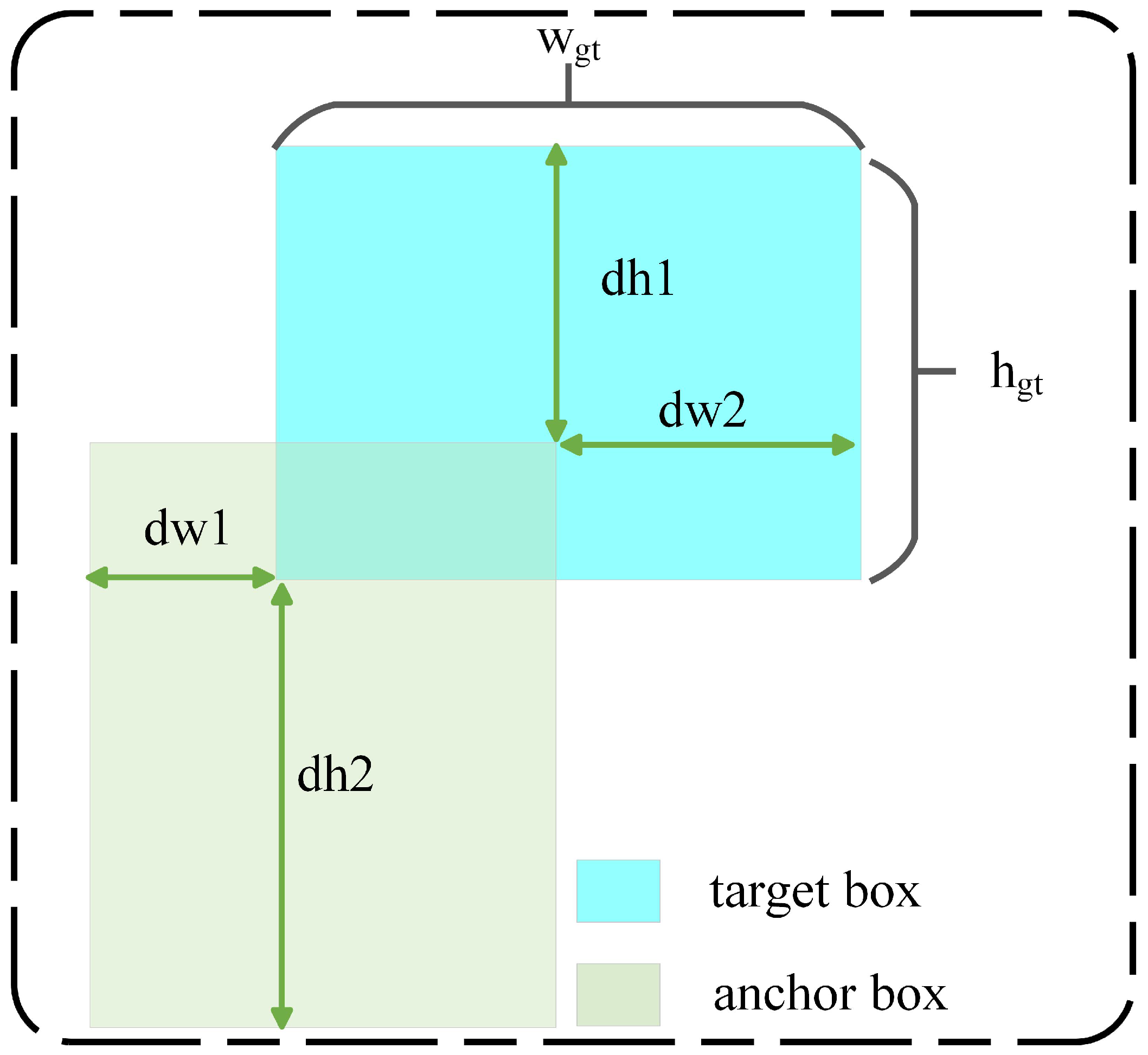
However, this study thoroughly analyzes the underlying causes of anchor box enlargement in existing loss functions. It was observed that using a factor related to the size of the smallest enclosing box between the anchor box and the target box as the denominator in the penalty term is inappropriate, as it leads to the expansion of the anchor boxes during the regression process and significantly slows down the convergence speed. Therefore, IoU-based regression loss functions require more appropriate penalty terms. To address the issue of anchor box enlargement and the limitations of existing IoU-based loss functions, EPIoU introduces a penalty factor
P, that adapts to the target size. Since the denominator of
P solely depends on the size of the target box and is independent of the size of the smallest enclosing box between the anchor and target boxes, using
P as the penalty factor in the loss function does not cause anchor box expansion. Unlike penalty factors used in other loss functions, the expansion of the anchor box does not alter
P. The penalty factor
P is defined as follows:
where
,
,
and
represent the absolute distances between the edges of the predicted and target boxes, while
and
denote the width and height of the target box, respectively.
Using (P) as a penalty factor in the loss function does not cause the anchor boxes to expand because the denominator of (P) depends solely on the size of the target box and is independent of the size of the minimal enclosing box of the anchor box as well as the target box. Unlike the penalty factors used in other loss functions, the expansion of the anchor box does not affect (P). Furthermore, unless the anchor box fully overlaps with the target box, (P) will always degrade to zero. Additionally, (P) adapts to the size of the target. Through the effective design of the loss function, the regression process of the anchor box can be better aligned with the practical needs of object detection, thereby improving the overall model performance.
Therefore, this study designs a gradient adjustment function
based on the quality of the anchor boxes to meet these requirements. The improved EPIoU combines a target size adaptive penalty factor and a gradient adjustment function based on the quality of the anchor boxes. This includes a penalty term with the size of the target box as the denominator. The EPIoU loss thus guides the anchor boxes to regress along an effective path, leading to faster convergence compared to the existing IoU-based losses, preventing anchor box expansion, and better adapting to the target size. This results in faster convergence and higher detection precision. In the
, the EPIoU loss only uses the edges of the target box as the denominator in the loss factor.
is illustrated in
Figure 11. The computation formula is as follows:
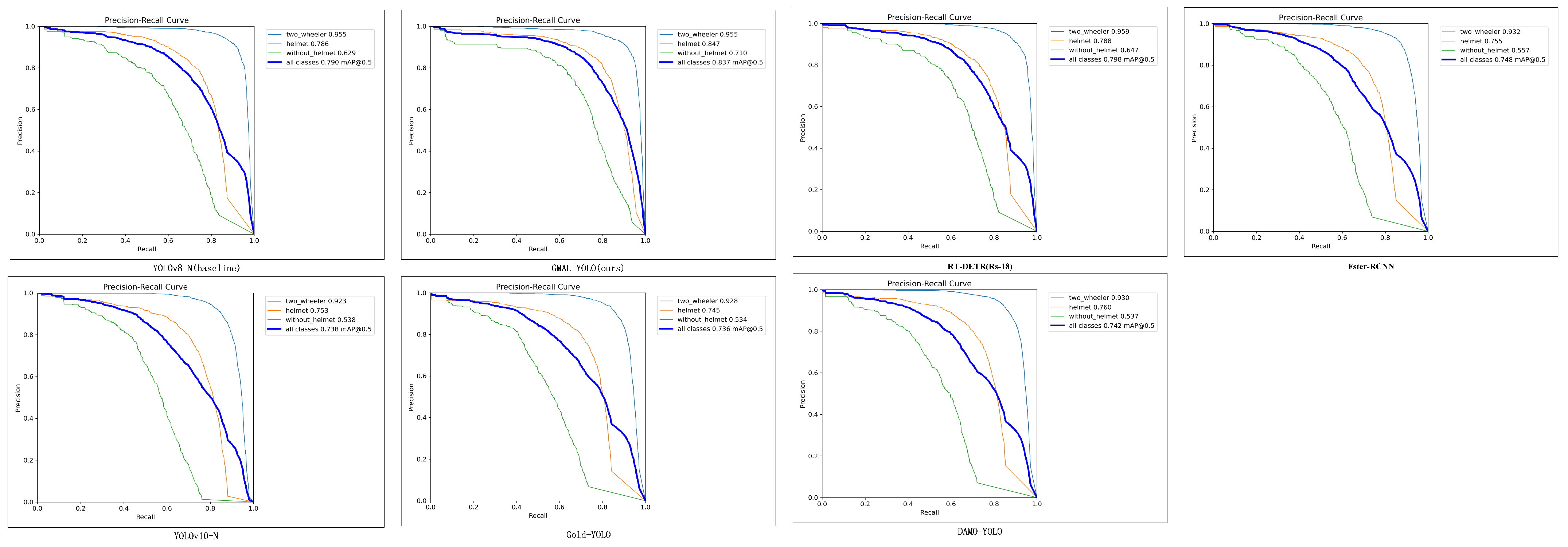
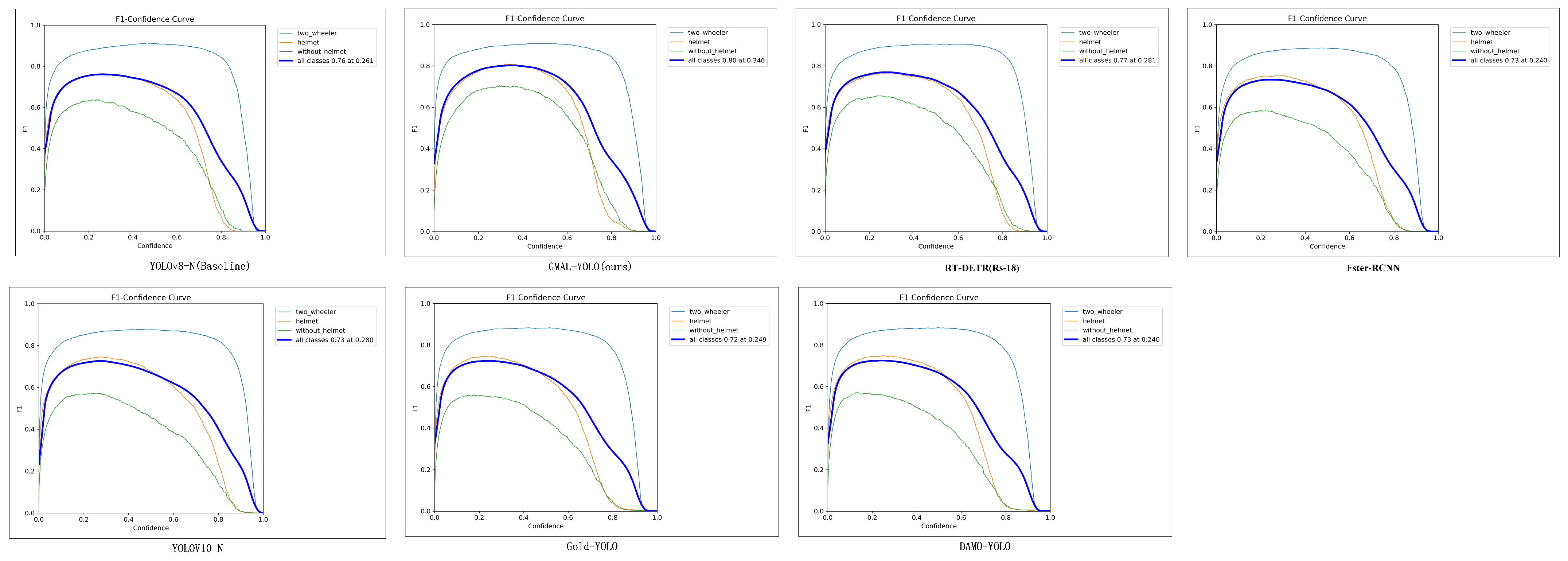
The study designs an EPIoU loss with a stronger penalty factor, addressing the issue of box expansion and a series of limitations in the existing IoU, thereby achieving faster convergence and higher precision. It can more accurately assess the quality of object detection results, as confirmed in
Section 4.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}