RMSENet: Multi-Scale Reverse Master–Slave Encoder Network for Remote Sensing Image Scene Classification

Abstract
1. Introduction
- 1.
- A reverse cross-scale fusion strategy for the master encoder and a reverse cross-scale supplementation strategy for the slave encoder were designed, which not only fused the features extracted from each stage of the master encoder cross-scale but also supplemented the high-level semantic information output from the slave encoder to the shallow stage of the master encoder network, effectively guided the feature extraction of the image in each stage of the master encoder network, and enhanced the multi-level understanding ability of the network to the input image.
- 2.
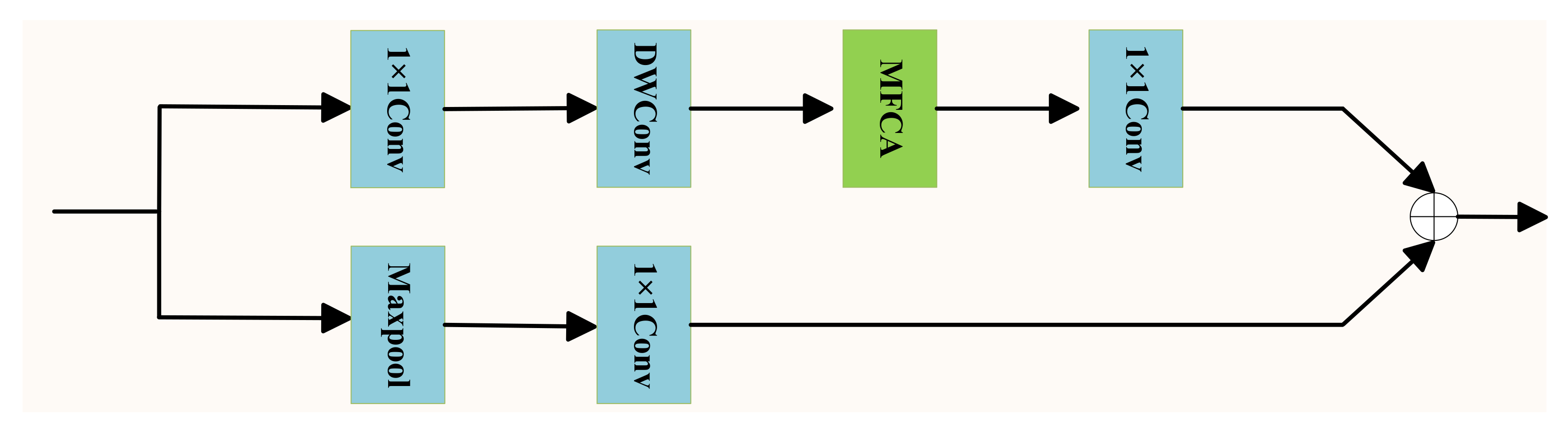
- The local information extraction module is designed. In this module, multi-frequency coordinate channel attention is proposed. According to the importance of each channel in the feature map, weight distribution is given and spatial position information and rich frequency information are embedded at the same time, which effectively improves the feature extraction ability of remote sensing images.
- 3.
- The local global information parallel extraction module is designed. In this module, the local global information parallel extraction and cross-fusion are realized. The multi-scale wavelet self-attention is proposed. Before the self-attention calculation, the wavelet transform is used to complete the downsampling of the input feature map, and the information loss caused by the downsampling is compensated by the inverse wavelet transform, so as to realize the lossless downsampling.
- 4.
- Based on the above design module, RMSENet is proposed. The experimental results show that the classification performance of RMSENet on RSSCN7, AID and SIRI-WHU datasets has certain advantages over other classification models.
2. Related Work
2.1. CNN-Based RSSC Models
2.2. Transformer-Based RSSC Models
2.3. Hybrid CNN-Transformer Architecture Models for RSSC
2.4. The Encoder Structure for RSSC
3. Methods
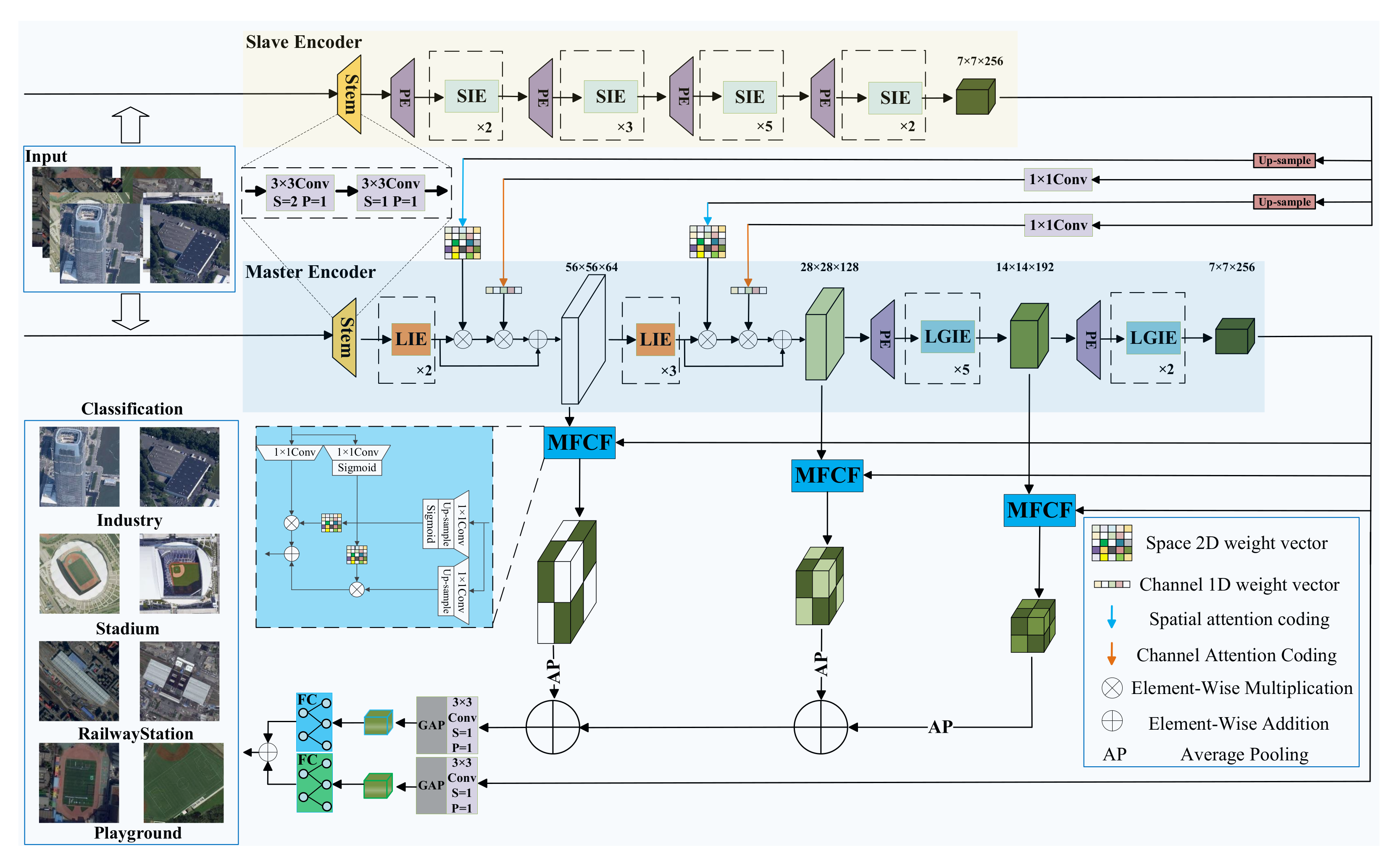
3.1. Overall Architecture
3.2. Slave Encoder
3.2.1. SIE Module
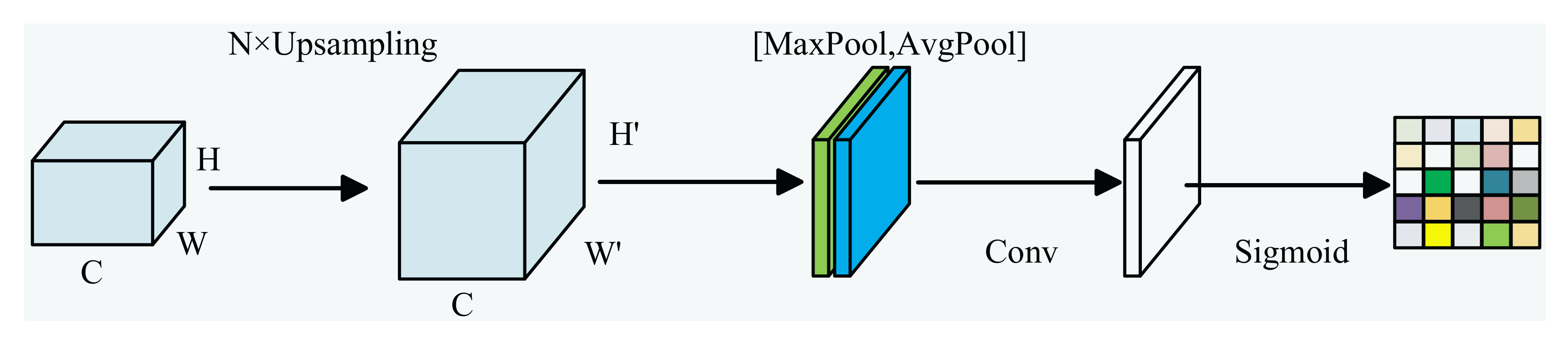
3.2.2. Reverse Cross-Scale Supplementation Strategy for the Slave Encoder
3.3. Master Encoder
3.3.1. Local Information Extraction (LIE) Module
3.3.2. Local and Global Information Extraction (LGIE) Module
3.3.3. Reverse Cross-Scale Fusion Strategy for the Master Encoder
3.4. Classifier
4. Experiment and Analysis
4.1. Dataset Introduction
4.2. The Evaluation Metric
4.3. Experiment Setup
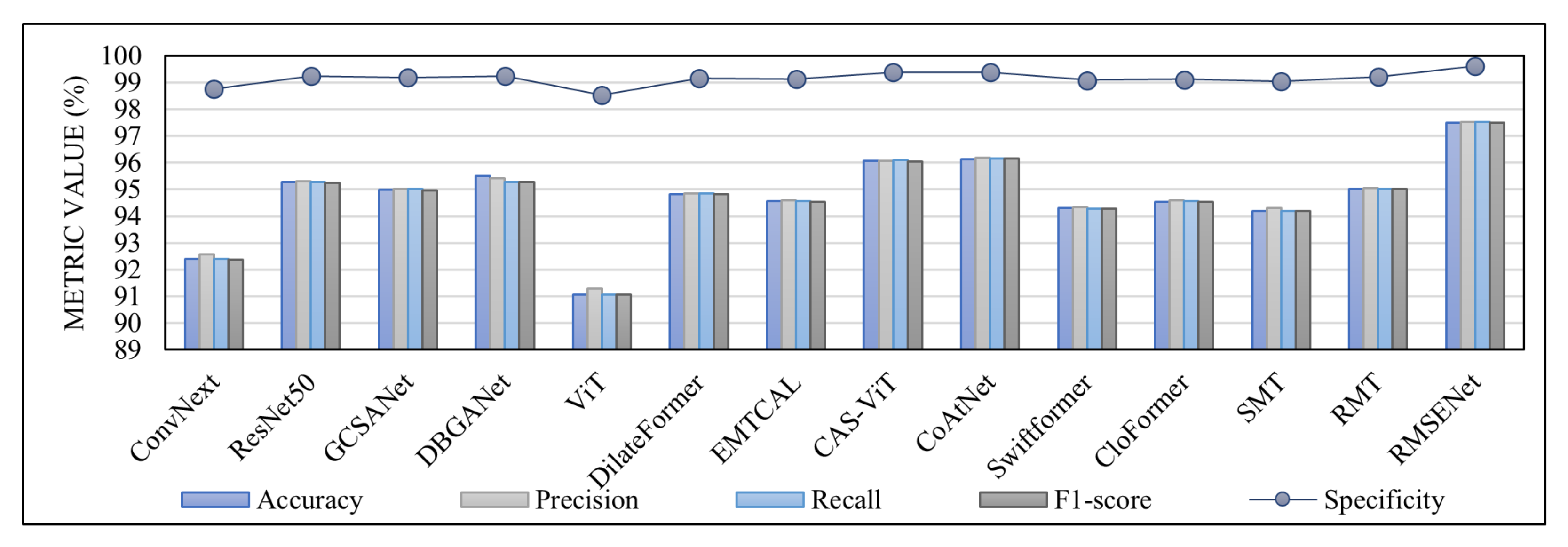
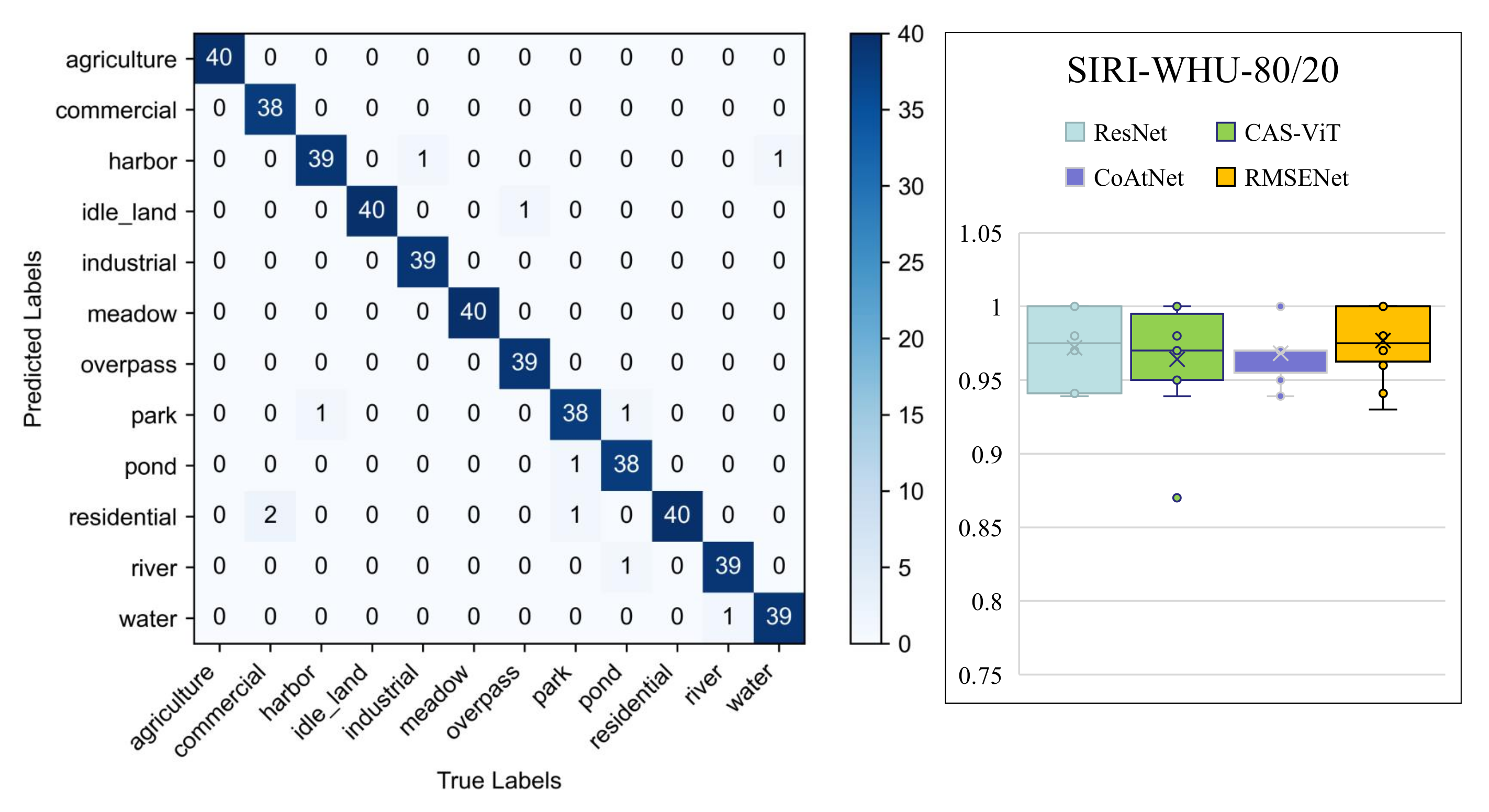
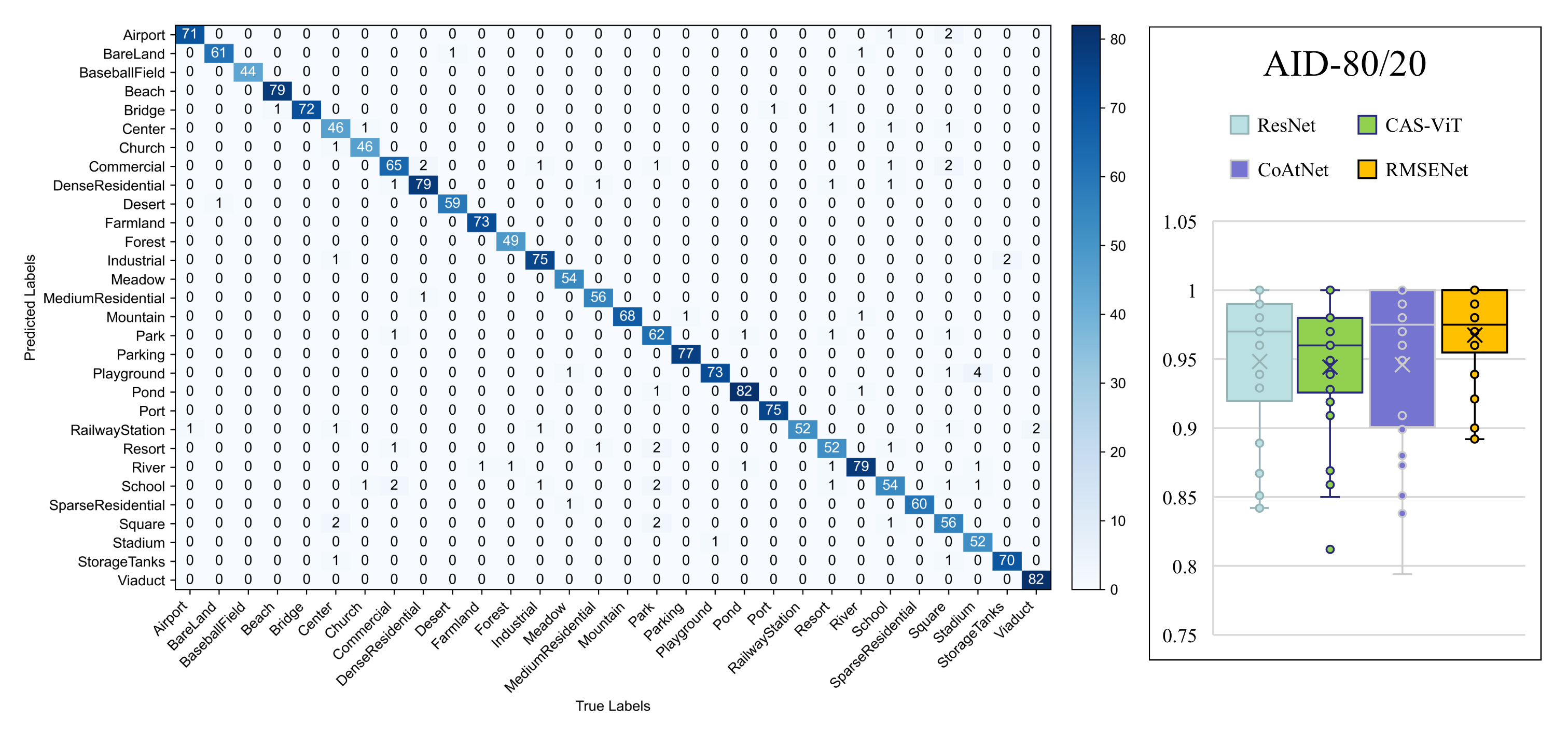
4.4. Comparative Experiments
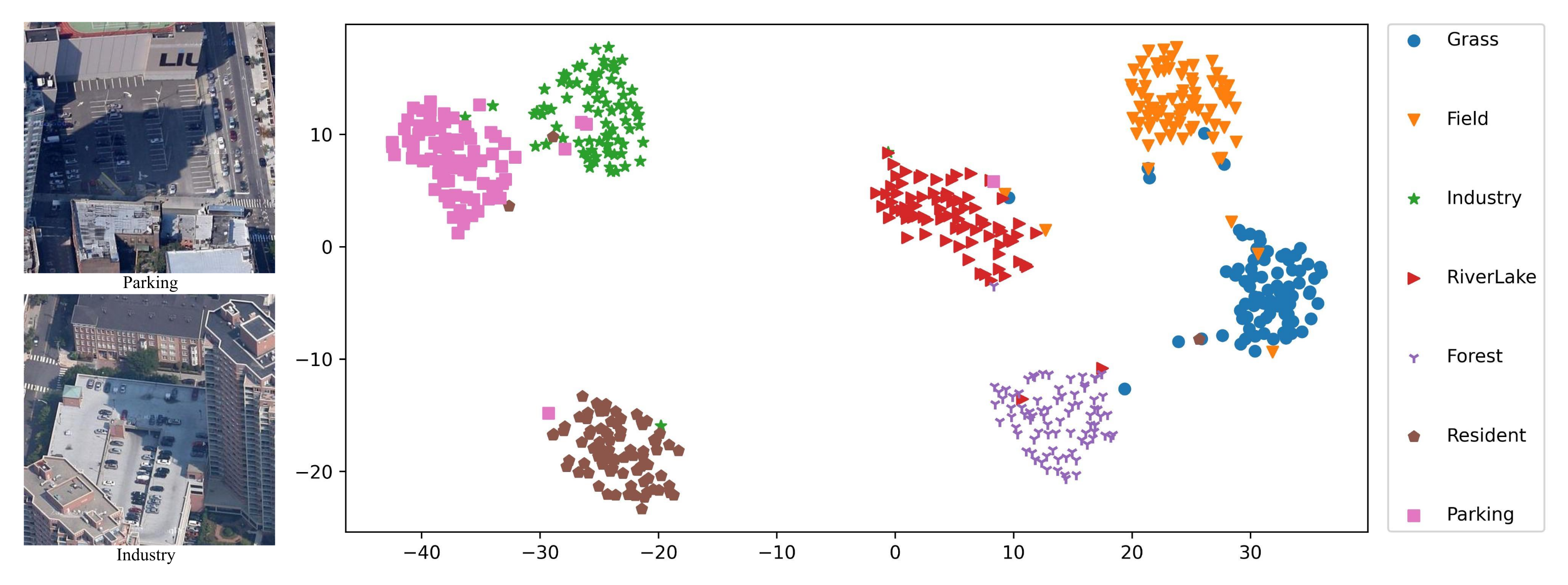
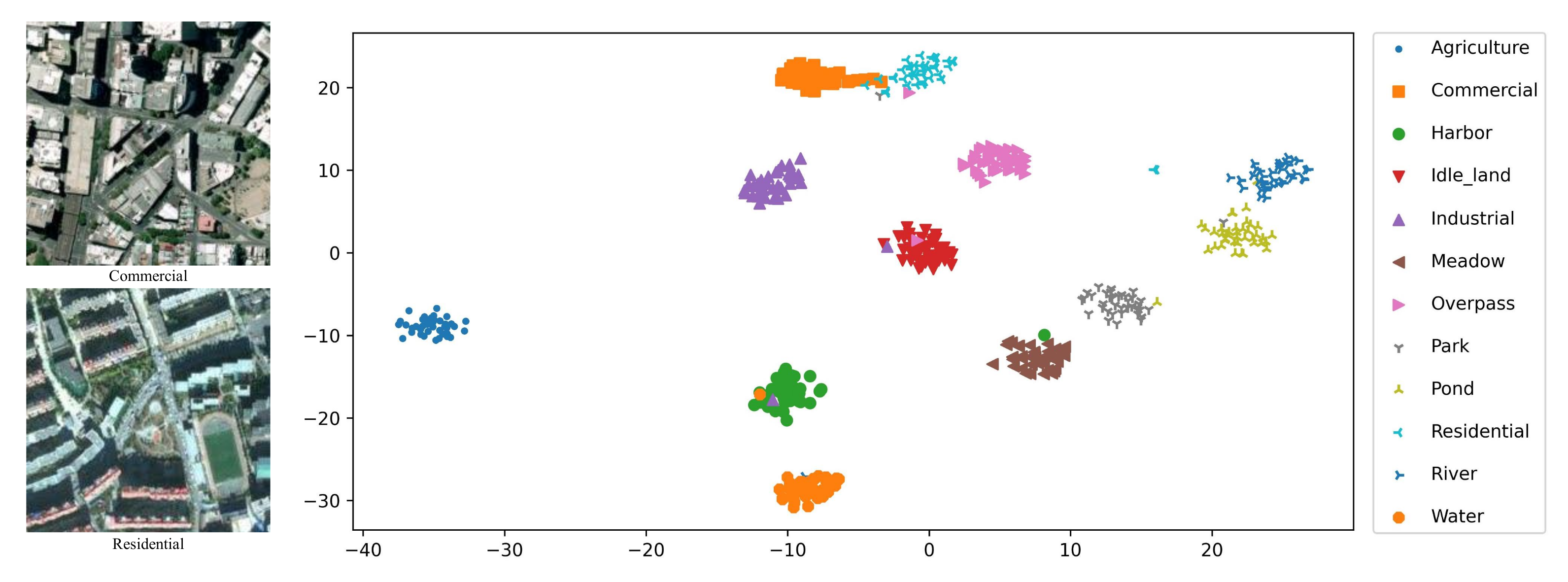
4.5. Visual Analysis
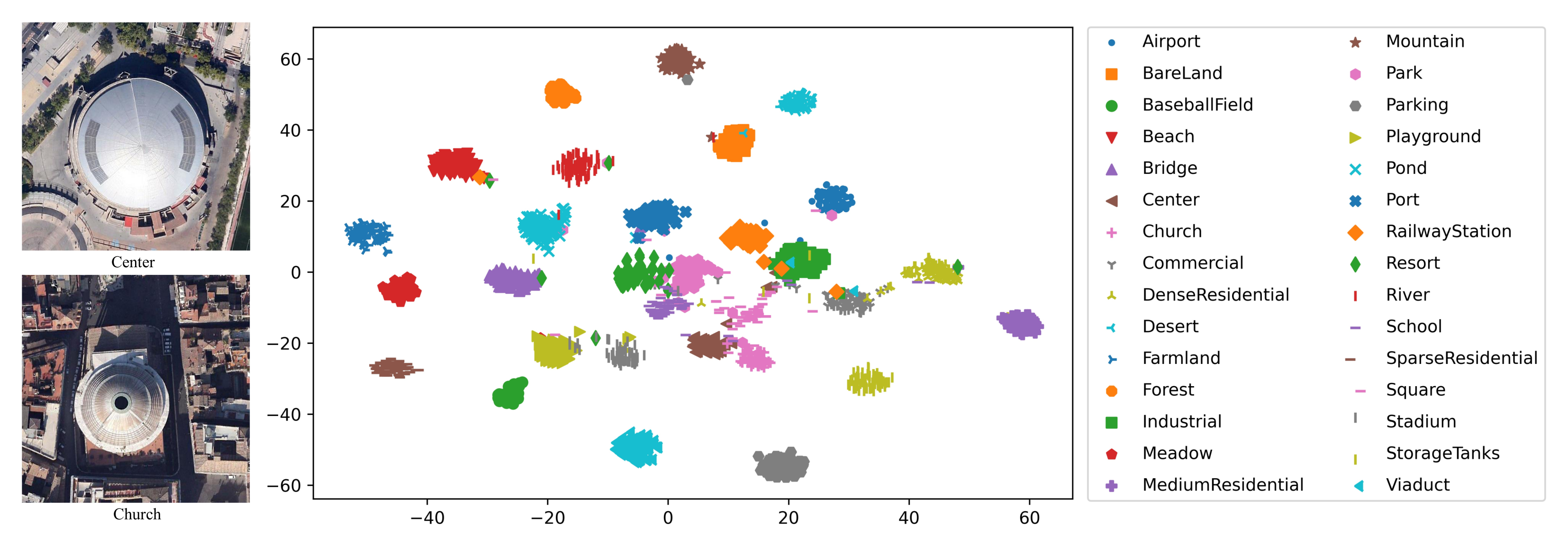
4.5.1. Visualization Analysis with t-SNE
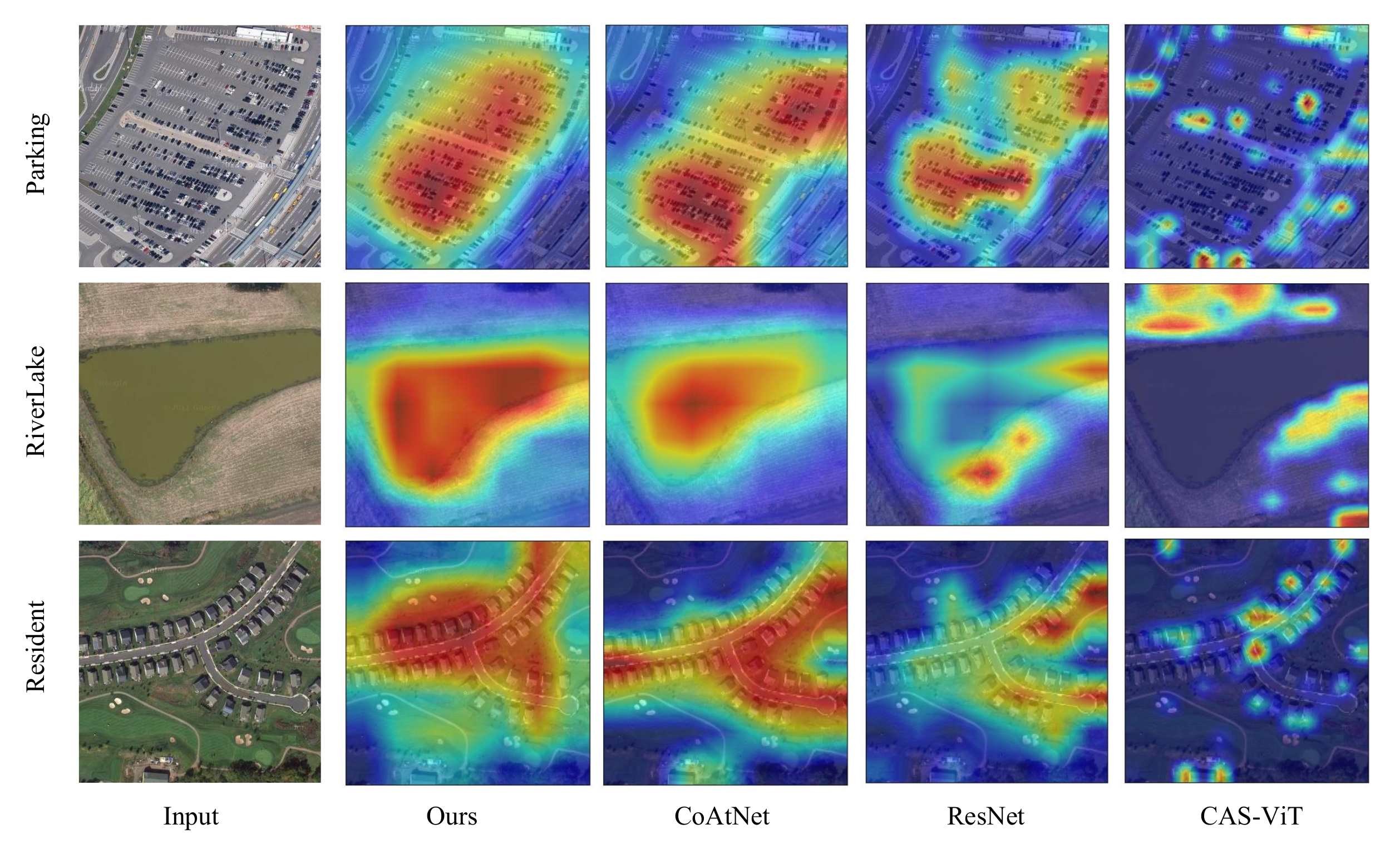
4.5.2. Visualization Analysis with Grad-CAM
4.6. Ablation Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gong, J.; Zhang, M.; Hu, X.; Zhang, Z.; Li, Y.; Jiang, L. The design of deep learning framework and model for intelligent remote sensing. Acta Geod. Cartogr. Sin. 2022, 51, 475. [Google Scholar]
- Quan, S.; Zhang, T.; Wang, W.; Kuang, G.; Wang, X.; Zeng, B. Exploring fine polarimetric decomposition technique for built-up area monitoring. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5204719. [Google Scholar] [CrossRef]
- Chen, L.; Li, S.; Bai, Q.; Yang, J.; Jiang, S.; Miao, Y. Review of image classification algorithms based on convolutional neural networks. Remote Sens. 2021, 13, 4712. [Google Scholar] [CrossRef]
- Cha, Y.J.; Choi, W.; Büyüköztürk, O. Deep learning-based crack damage detection using convolutional neural networks. Comput. Aided Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Cha, Y.J.; Ali, R.; Lewis, J.; Büyük, O. Deep learning-based structural health monitoring. Autom. Constr. 2024, 161, 105328. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Kang, D.H.; Cha, Y.J. Efficient attention-based deep encoder and decoder for automatic crack segmentation. Struct. Health Monit. 2022, 21, 2190–2205. [Google Scholar] [CrossRef]
- Ali, R.; Cha, Y.J. Attention-based generative adversarial network with internal damage segmentation using thermography. Autom. Constr. 2022, 141, 104412. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 84–90. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Tong, W.; Chen, W.; Han, W.; Li, X.; Wang, L. Channel-attention-based DenseNet network for remote sensing image scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4121–4132. [Google Scholar] [CrossRef]
- Finder, S.E.; Amoyal, R.; Treister, E.; Freifeld, O. Wavelet convolutions for large receptive fields. In European Conference on Computer Vision; Springer Nature: Cham, Switzerland, 2024; pp. 363–380. [Google Scholar]
- Cheng, X.; Li, B.; Deng, Y.; Tang, J.; Shi, Y.; Zhao, J. MMDL-Net: Multi-Band Multi-Label Remote Sensing Image Classification Model. Appl. Sci. 2024, 14, 2226. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Lv, P.; Wu, W.; Zhong, Y.; Du, F.; Zhang, L. SCViT: A spatial-channel feature preserving vision transformer for remote sensing image scene classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4409512. [Google Scholar] [CrossRef]
- Wu, N.; Lv, J.; Jin, W. S4Former: A Spectral–Spatial Sparse Selection Transformer for Multispectral Remote Sensing Scene Classification. IEEE Geosci. Remote Sens. Lett. 2024, 21, 5001605. [Google Scholar] [CrossRef]
- Zhang, T.; Li, L.; Zhou, Y.; Liu, W.; Qian, C.; Hwang, J.-N.; Ji, X. Cas-vit: Convolutional additive self-attention vision transformers for efficient mobile applications. arXiv 2024, arXiv:2408.03703. [Google Scholar]
- Dai, Z.; Liu, H.; Le, Q.V.; Tan, M. Coatnet: Marrying convolution and attention for all data sizes. Adv. Neural Inf. Process. Syst. 2021, 34, 3965–3977. [Google Scholar]
- Xu, R.; Dong, X.-M.; Li, W.; Peng, J.; Sun, W.; Xu, Y. DBCTNet: Double branch convolution-transformer network for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5509915. [Google Scholar] [CrossRef]
- Zheng, Y.; Liu, S.; Chen, H.; Bruzzone, L. Hybrid FusionNet: A hybrid feature fusion framework for multisource high-resolution remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5401714. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Deng, P.; Xu, K.; Huang, H. When CNNs meet vision transformer: A joint framework for remote sensing scene classification. IEEE Geosci. Remote Sens. Lett. 2021, 19, 8020305. [Google Scholar] [CrossRef]
- Yang, Y.; Jiao, L.; Li, L.; Liu, X.; Liu, F.; Chen, P.; Yang, S. LGLFormer: Local–global lifting transformer for remote sensing scene parsing. IEEE Trans. Geosci. Remote Sens. 2023, 62, 5602513. [Google Scholar] [CrossRef]
- Yue, H.; Qing, L.; Zhang, Z.; Wang, Z.; Guo, L.; Peng, Y. MSE-Net: A novel master–slave encoding network for remote sensing scene classification. Eng. Appl. Artif. Intell. 2024, 132, 107909. [Google Scholar] [CrossRef]
- Yu, W.; Luo, M.; Zhou, P.; Si, C.; Zhou, Y.; Wang, X.; Feng, J.; Yan, S. Metaformer is actually what you need for vision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10819–10829. [Google Scholar]
- Liu, L.; Liu, J.; Yuan, S.; Slabaugh, G.; Leonardis, A.; Zhou, W.; Tian, Q. Wavelet-based dual-branch network for image demoiréing. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference; Glasgow, UK, 23–28 August 2020, Proceedings, Part XIII 16; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 86–102. [Google Scholar]
- Zou, Q.; Ni, L.; Zhang, T.; Wang, Q. Deep learning based feature selection for remote sensing scene classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2321–2325. [Google Scholar] [CrossRef]
- Xia, G.-S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef]
- Zhu, Q.; Zhong, Y.; Zhao, B.; Xia, G.-S.; Zhang, L. Bag-of-visual-words scene classifier with local and global features for high spatial resolution remote sensing imagery. IEEE Geosci. Remote Sens. Lett. 2016, 13, 747–751. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.-Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- Chen, W.; Ouyang, S.; Tong, W.; Li, X.; Zheng, X.; Wang, L. GCSANet: A global context spatial attention deep learning network for remote sensing scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 1150–1162. [Google Scholar] [CrossRef]
- Xia, J.; Zhou, Y.; Tan, L. DBGA-Net: Dual-branch global–local attention network for remote sensing scene classification. IEEE Geosci. Remote Sens. Lett. 2023, 20, 7502305. [Google Scholar] [CrossRef]
- Jiao, J.; Tang, Y.-M.; Lin, K.-Y.; Gao, Y.; Ma, J.; Wang, Y.; Zheng, W.-S. Dilateformer: Multi-scale dilated transformer for visual recognition. IEEE Trans. Multimed. 2023, 25, 8906–8919. [Google Scholar] [CrossRef]
- Tang, X.; Li, M.; Ma, J.; Zhang, X.; Liu, F.; Jiao, L. EMTCAL: Efficient multiscale transformer and cross-level attention learning for remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5626915. [Google Scholar] [CrossRef]
- Shaker, A.; Maaz, M.; Rasheed, H.; Khan, S.; Yang, M.-H.; Khan, F.S. Swiftformer: Efficient additive attention for transformer-based real-time mobile vision applications. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 17425–17436. [Google Scholar]
- Fan, Q.; Huang, H.; Guan, J.; He, R. Rethinking local perception in lightweight vision transformer. arXiv 2023, arXiv:2303.17803. [Google Scholar]
- Lin, W.; Wu, Z.; Chen, J.; Huang, J.; Jin, L. Scale-aware modulation meet transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 6015–6026. [Google Scholar]
- Fan, Q.; Huang, H.; Chen, M.; Liu, H.; He, R. Rmt: Retentive networks meet vision transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 5641–5651. [Google Scholar]
- McGill, R.; Tukey, J.W.; Larsen, W.A. Variations of box plots. Am. Stat. 1978, 32, 12–16. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Wang, W.; Yang, T.; Wang, X. From Spatial to Frequency Domain: A Pure Frequency Domain FDNet Model for the Classification of Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5636413. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Year | Params () | Flops () |
|---|---|---|---|
| ConvNext [32] | 2022 | 28.75 | 4.46 |
| ResNet50 [8] | 2016 | 23.52 | 4.13 |
| GCSANet [33] | 2022 | 12.84 | 3.43 |
| DBGANet [34] | 2023 | 108.38 | 13.212 |
| ViT [12] | 2020 | 85.66 | 16.86 |
| DilateFormer [35] | 2022 | 23.48 | 4.41 |
| EMTCAL [36] | 2022 | 27.30 | 4.23 |
| CAS-ViT [18] | 2024 | 20.74 | 3.59 |
| CoAtNet [19] | 2021 | 16.99 | 3.35 |
| Swiftformer [37] | 2023 | 11.29 | 1.60 |
| CloFormer [38] | 2023 | 11.88 | 2.13 |
| SMT [39] | 2023 | 10.99 | 2.4 |
| RMT [40] | 2024 | 13.19 | 2.32 |
| RMSENet | Ours | 13.26 | 3.47 |
| Model | RSSCN7-Accuracy (%) | Train | Test | Input Size |
|---|---|---|---|---|
| ConvNext | 92.40 ± 0.80 | 2240 | 560 | 400 × 400 |
| ResNet50 | 95.26 ± 0.09 | 2240 | 560 | 400 × 400 |
| GCSANet | 94.99 ± 0.72 | 2240 | 560 | 400 × 400 |
| DBGANet | 95.50 ± 0.50 | 2240 | 560 | 400 × 400 |
| ViT | 91.07 ± 0.54 | 2240 | 560 | 400 × 400 |
| DilateFormer | 94.81 ± 0.71 | 2240 | 560 | 400 × 400 |
| EMTCAL | 94.55 ± 0.09 | 2240 | 560 | 400 × 400 |
| CAS-ViT | 95.80 ± 0.27 | 2240 | 560 | 400 × 400 |
| CoAtNet | 96.13 ± 0.12 | 2240 | 560 | 400 × 400 |
| Swiftformer | 94.29 ± 0.54 | 2240 | 560 | 400 × 400 |
| CloFormer | 94.54 ± 0.62 | 2240 | 560 | 400 × 400 |
| SMT | 95.12 ± 0.06 | 2240 | 560 | 400 × 400 |
| RMT | 95.00 ± 0.89 | 2240 | 560 | 400 × 400 |
| RMSENet | 97.41 ± 0.09 | 2240 | 560 | 400 × 400 |
| Model | AID-Accuracy (%) | Train | Test | Input Size |
|---|---|---|---|---|
| ConvNext | 91.78 ± 0.28 | 8000 | 2000 | 600 × 600 |
| ResNet50 | 95.0 ± 0.25 | 8000 | 2000 | 600 × 600 |
| GCSANet | 94.63 ± 0.07 | 8000 | 2000 | 600 × 600 |
| DBGANet | 94.40 ± 0.50 | 8000 | 2000 | 600 × 600 |
| ViT | 79.95 ± 0.15 | 8000 | 2000 | 600 × 600 |
| DilateFormer | 93.98 ± 0.68 | 8000 | 2000 | 600 × 600 |
| EMTCAL | 94.10 ± 0.45 | 8000 | 2000 | 600 × 600 |
| CAS-ViT | 94.0 ± 0.20 | 8000 | 2000 | 600 × 600 |
| CoAtNet | 94.82 ± 0.18 | 8000 | 2000 | 600 × 600 |
| Swiftformer | 93.10 ± 0.10 | 8000 | 2000 | 600 × 600 |
| CloFormer | 94.08 ± 0.18 | 8000 | 2000 | 600 × 600 |
| SMT | 93.43 ± 0.42 | 8000 | 2000 | 600 × 600 |
| RMT | 94.67 ± 0.23 | 8000 | 2000 | 600 × 600 |
| RMSENet | 95.9 ± 0.18 | 8000 | 2000 | 600 × 600 |
| Model | SIRI-WHU-Accuracy (%) | Train | Test | Input Size |
|---|---|---|---|---|
| ConvNext | 93.75 ± 0.41 | 1920 | 480 | 200 × 200 |
| ResNet50 | 96.04 ± 0.21 | 1920 | 480 | 200 × 200 |
| GCSANet | 96.35 ± 0.32 | 1920 | 480 | 200 × 200 |
| DBGANet | 95.94 ± 0.52 | 1920 | 480 | 200 × 200 |
| ViT | 91.88 ± 0.21 | 1920 | 480 | 200 × 200 |
| DilateFormer | 95.96 ± 0.17 | 1920 | 480 | 200 × 200 |
| EMTCAL | 95.31 ± 0.52 | 1920 | 480 | 200 × 200 |
| CAS-ViT | 96.56 ± 0.52 | 1920 | 480 | 200 × 200 |
| CoAtNet | 96.41 ± 0.21 | 1920 | 480 | 200 × 200 |
| Swiftformer | 94.90 ± 0.52 | 1920 | 480 | 200 × 200 |
| CloFormer | 95.27 ± 0.36 | 1920 | 480 | 200 × 200 |
| SMT | 93.61 ± 0.14 | 1920 | 480 | 200 × 200 |
| RMT | 95.69 ± 0.14 | 1920 | 480 | 200 × 200 |
| RMSENet | 97.61 ± 0.21 | 1920 | 480 | 200 × 200 |
| Model | MFCA | SE | MWSA | MHSA | Slave-E | MFCF | Accuracy (%) |
|---|---|---|---|---|---|---|---|
| RMSENet | ✓ | × | ✓ | × | ✓ | ✓ | |
| RMSENet-1 | ✓ | × | ✓ | × | × | ✓ | |
| RMSENet-2 | ✓ | × | ✓ | × | ✓ | × | |
| RMSENet-3 | × | × | ✓ | × | ✓ | ✓ | |
| RMSENet-4 | × | ✓ | ✓ | × | ✓ | ✓ | |
| RMSENet-5 | ✓ | × | × | ✓ | ✓ | ✓ |
| Model | Wavelet Transform Basis Function | Accuracy (%) |
|---|---|---|
| RMSENet | Haar Wavelet | |
| RMSENet-6 | Daubechies Wavelet | |
| RMSENet-7 | Symlet Wavelet | |
| RMSENet-8 | Coiflet Wavelet | |
| RMSENet-9 | Biorthogonal Wavelet | |
| RMSENet-10 | Reverse Biorthogonal Wavelet |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wen, Y.; Zhou, J.; Zhang, Z.; Tang, L. RMSENet: Multi-Scale Reverse Master–Slave Encoder Network for Remote Sensing Image Scene Classification. Electronics 2025, 14, 2479. https://doi.org/10.3390/electronics14122479
Wen Y, Zhou J, Zhang Z, Tang L. RMSENet: Multi-Scale Reverse Master–Slave Encoder Network for Remote Sensing Image Scene Classification. Electronics. 2025; 14(12):2479. https://doi.org/10.3390/electronics14122479
Chicago/Turabian StyleWen, Yongjun, Jiake Zhou, Zhao Zhang, and Lijun Tang. 2025. "RMSENet: Multi-Scale Reverse Master–Slave Encoder Network for Remote Sensing Image Scene Classification" Electronics 14, no. 12: 2479. https://doi.org/10.3390/electronics14122479
APA StyleWen, Y., Zhou, J., Zhang, Z., & Tang, L. (2025). RMSENet: Multi-Scale Reverse Master–Slave Encoder Network for Remote Sensing Image Scene Classification. Electronics, 14(12), 2479. https://doi.org/10.3390/electronics14122479