
Efficient License Plate Alignment and Recognition Using FPGA-Based Edge Computing


Abstract
1. Introduction
- An efficient pose estimation method based on a refined and pruned CPM model is proposed for license plate alignment. This method enables robust corner-point prediction for perspective transformation, ensuring accurate geometric correction across a wide range of viewing angles.
- A lightweight character recognition module was constructed by modifying the LPRNet model and utilizing an attention-based mechanism to capture more spatial information and detailed features, thereby improving recognition accuracy.
- A fully integrated and FPGA-compatible LPAR pipeline was established, incorporating model restructuring, pruning, and quantization. The FPGA-based LPAR system achieved millisecond-level inference speed and watt-level power consumption, outperforming GPU-based implementations in terms of efficiency and suitability for edge deployment.
- An end-to-end license plate detection, alignment, and recognition (LPAR) system was developed. On skewed license plate datasets, the proposed LPAR system achieved a recognition accuracy of 95.00%, significantly outperforming the original LPRNet [8] (88.33%), demonstrating its effectiveness in practical scenarios.
2. Related Work
2.1. License Plate Recognition Techniques
2.2. License Plate Pose Estimation and Alignment
2.3. Edge Computing and FPGA Deployment
3. Methodology
- License Plate Detection: A lightweight YOLOv4-tiny model is employed to efficiently and accurately localize license plates in input images.
- Pose Estimation and Alignment: A deep learning-based model is utilized to detect the four corner points of the license plate, followed by perspective transformation to rectify the image.
- Character Recognition: The aligned license plate image is fed into a modified LPRNet for end-to-end character recognition.
3.1. License Plate Detection
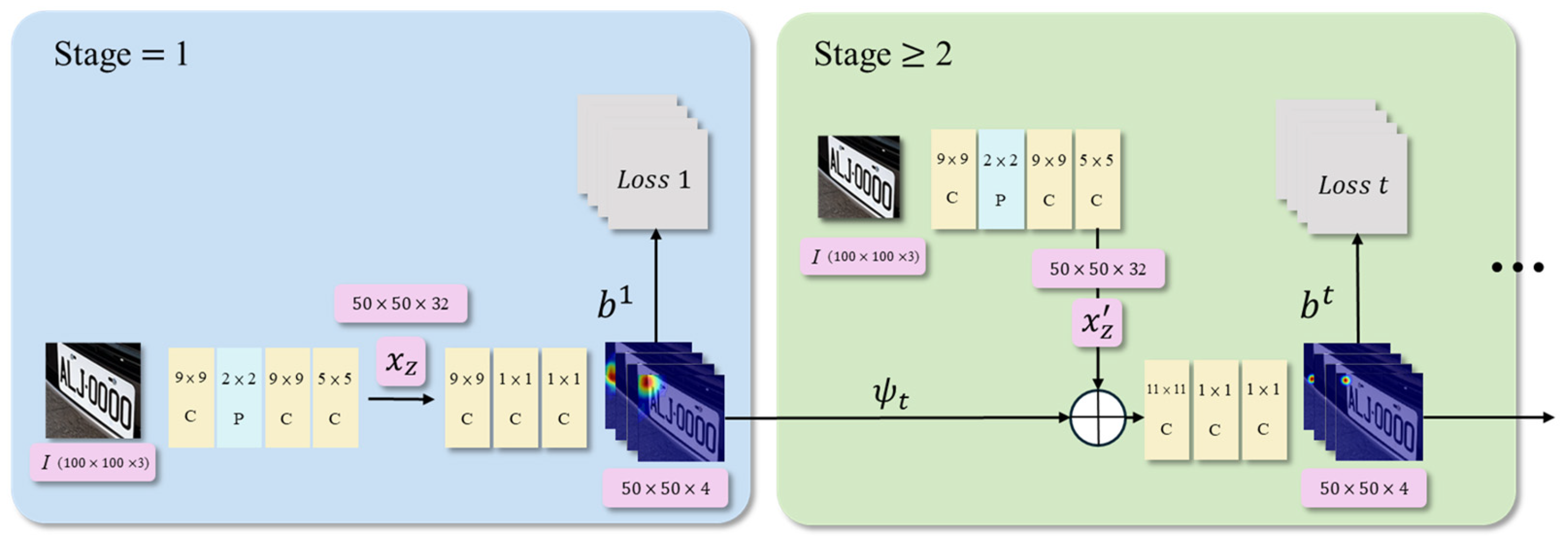
3.2. Pose Estimation and Alignment
3.3. LPRNet: License Plate Recognition Model
3.3.1. LPRNet Architecture and Model Optimization
3.3.2. CTC Loss and Greedy Decoding
4. Experiment Setup
4.1. Experimental Environment
4.2. Dataset Preparation
4.3. Model Training and Parameter Settings
5. Experiment Results
5.1. YOLOv4-Tiny Detection Results
5.2. Pose Estimation and Alignment Results and Ablation Study
5.2.1. Keypoint Detection Accuracy
5.2.2. Ablation Studies
- Stage Pruning: Reducing the number of stages from 7 to 2 maintained a PCK of 96.67%, indicating redundancy in the later stages (Table 2).
- Kernel Size Modification: Reducing the number of 9 × 9 kernels from two to one increased PCK accuracy to 97.55%. In contrast, replacing them with smaller 7 × 7 or 5 × 5 kernels led to performance degradation (Figure 9).
- Channel Pruning with APoZ: Using the average percentage of zeros (APoZ) method, channels with over 45% zero activation were pruned. As shown in Figure 10, pruning 2 channels from layer 2 and 8 from layer 3 led to a slight PCK accuracy drop to 96.7%, which is acceptable given the computational savings. This pruning significantly reduces multiply–accumulate (MAC) operations and memory access, aligning with the logic and memory constraints of our target FPGA platform.
- Additionally, internal operations were adjusted to meet deployment requirements. Due to hardware limitations on FPGA, operations such as basic arithmetic operations, mean pooling, and 3D convolutions are not supported. Therefore, we redesigned the network to rely solely on convolutional layers, replacing unsupported components and aligning with the operator set supported by Xilinx Vitis-AI [29], as listed in Table 1. This approach preserves recognition performance while ensuring compatibility with accelerated deployment on the Xilinx KV260 FPGA platform.
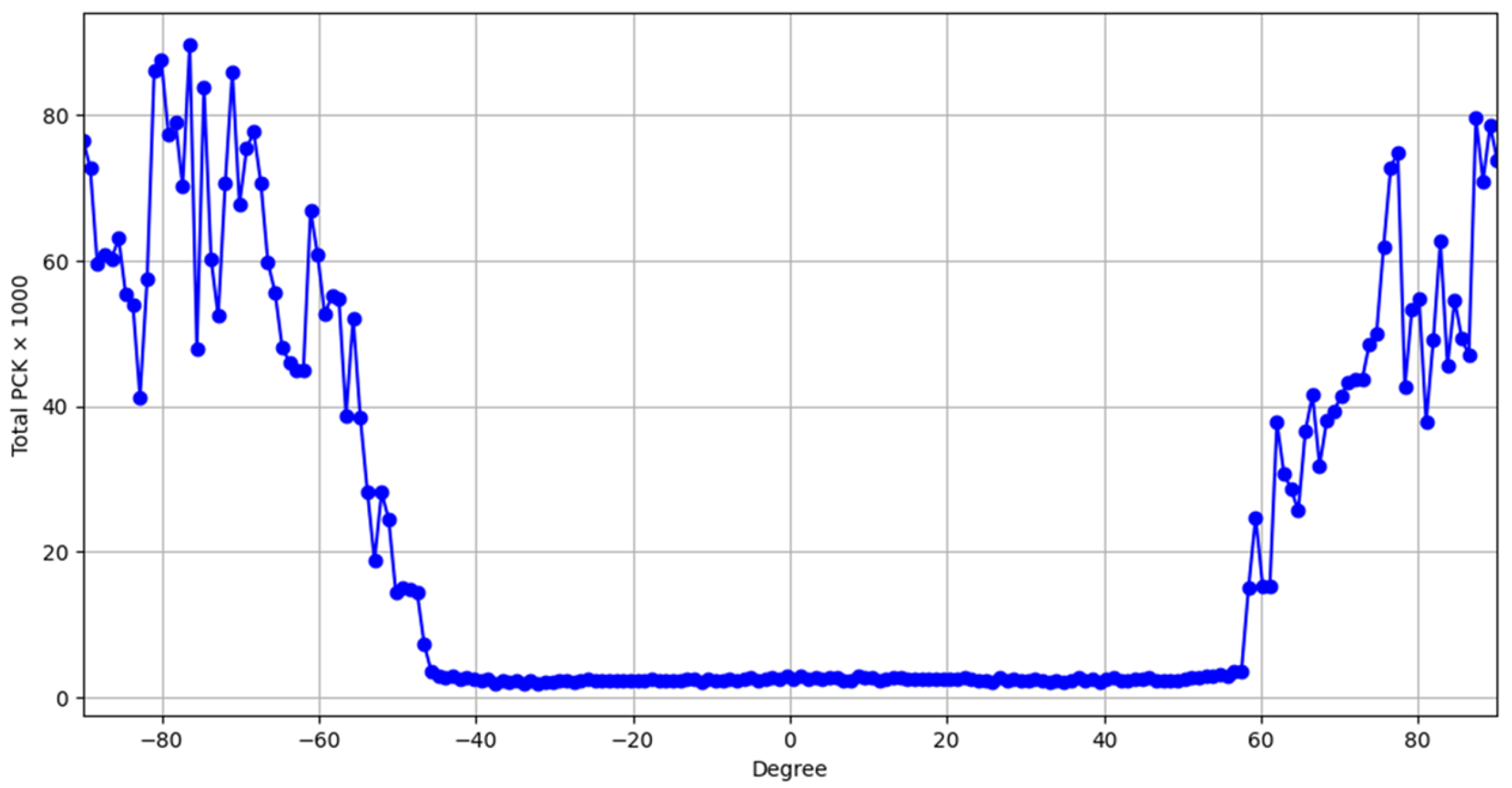
5.2.3. Angle Robustness Test
5.2.4. Optimizer Comparison
5.3. Performance on PC-Based Platform
- Baseline model: The unaligned license plate test data from the TLPD dataset with basic data transformation (cropping) were directly utilized to test the modified LPRNet, resulting in 88.33% accuracy. The test data, consisting of images from the YOLOv4-tiny bounding box (YOLO-Box), were cropped to obtain the rectangular character region (Character-Box). In this instance, CPM was used to identify the rectangle’s four corners, as shown in Figure 12. Note that the plate images in the Character-Box were further transformed using perspective to obtain the corrected plate images (CPM-Corrected).
- Manual-aligned dataset: Manually rectified images were utilized to test the modified LPRNet, improving accuracy to 98%, though this is impractical for real-time systems.
- License Plate Alignment and Recognition (LPAR): The modified LPRNet was integrated with the refined CPM module and tested on the unaligned license plate dataset, achieving 95% accuracy.
5.4. Quantization and Speed Evaluation
5.5. Zero-Shot Testing on Untrained Plate Formats
5.6. Analysis of LPAR Failure Cases
5.7. LPAR Under Challenging Conditions
5.8. Experimental Results of Keypoint Detection
5.8.1. Comparison of Models for Keypoint Detection
5.8.2. Comparison of Models for Keypoint Detection on Fisheye Images
5.9. Comparative Experiments on License Plate Recognition
6. Conclusions
- When the license plate is tilted beyond 45 degrees, keypoint prediction errors increase significantly, leading to failed geometric correction and lower recognition accuracy. To address this, we plan to include more heavily rotated images during data augmentation to improve robustness under extreme angles.
- The current FPGA platform requires specific model conversion tools (e.g., Xilinx Vitas-AI [29]), and not all PyTorch functions are supported. This limits architectural flexibility and requires hardware-aware design. Future work will explore models more compatible with FPGA toolchains to enhance system scalability and integration.
- To support deployment in GPU-free edge environments, we reduced the model from 7 stages to 2 and applied post-training quantization. In future work, we plan to train larger models and compress them using knowledge distillation to balance performance and generalization.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Anagnostopoulos, C.-N.E.; Anagnostopoulos, I.E.; Psoroulas, I.D.; Loumos, V.; Kayafas, E. License plate recognition from still images and video sequences: A survey. IEEE Trans. Intell. Transp. Syst. 2008, 9, 377–391. [Google Scholar] [CrossRef]
- Du, S.; Ibrahim, M.; Shehata, M.; Badawy, W. Automatic license plate recognition (ALPR): A state-of-the-art review. IEEE Trans. Circuits Syst. Video Technol. 2012, 23, 311–325. [Google Scholar] [CrossRef]
- Khan, M.M.; Ilyas, M.U.; Khan, I.R.; Alshomrani, S.M.; Rahardja, S. A review of license plate recognition methods employing neural networks. IEEE Access 2023, 11, 73613–73646. [Google Scholar] [CrossRef]
- Jiang, Z.; Zhao, L.; Li, S.; Jia, Y. Real-time object detection method based on improved YOLOv4-tiny. arXiv 2020, arXiv:2011.04244. [Google Scholar]
- Zendehdel, N.; Chen, H.; Leu, M.C. Real-time tool detection in smart manufacturing using You-Only-Look-Once (YOLO) v5. Manuf. Lett. 2023, 35, 1052–1059. [Google Scholar] [CrossRef]
- NanoDet. Available online: https://github.com/RangiLyu/nanodet (accessed on 7 May 2025).
- Wei, S.-E.; Ramakrishna, V.; Kanade, T.; Sheikh, Y. Convolutional pose machines. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4724–4732. [Google Scholar] [CrossRef]
- Zherzdev, S.; Gruzdev, A. Lprnet: License plate recognition via deep neural networks. arXiv 2018, arXiv:1806.10447. [Google Scholar]
- Li, H.; Shen, C. Reading car license plates using deep convolutional neural networks and LSTMs. arXiv 2016, arXiv:1601.05610. [Google Scholar]
- Cheang, T.K.; Chong, Y.S.; Tay, Y.H. Segmentation-free vehicle license plate recognition using ConvNet-RNN. arXiv 2017, arXiv:1701.06439. [Google Scholar]
- Recurrent Neural Network. Available online: https://en.wikipedia.org/wiki/Recurrent_neural_network. (accessed on 15 December 2024).
- Rao, Z.; Yang, D.; Chen, N.; Liu, J. License plate recognition system in unconstrained scenes via a new image correction scheme and improved CRNN. Expert Syst. Appl. 2024, 243, 122878. [Google Scholar] [CrossRef]
- Liu, Q.; Liu, Y.; Chen, S.-L.; Zhang, T.-H.; Chen, F.; Yin, X.-C. Improving multi-type license plate recognition via learning globally and contrastively. IEEE Trans. Intell. Transp. Syst. 2024, 25, 11092–11102. [Google Scholar] [CrossRef]
- Ismail, A.; Mehri, M.; Sahbani, A.; Amara, N.E.B. A dual-stage system for real-time license plate detection and recognition on mobile security robots. Robotica 2025, 1–22. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Wang, D.; Tian, Y.; Geng, W.; Zhao, L.; Gong, C. LPR-Net: Recognizing Chinese license plate in complex environments. Pattern Recognit. Lett. 2020, 130, 148–156. [Google Scholar] [CrossRef]
- Kim, T.-G.; Yun, B.-J.; Kim, T.-H.; Lee, J.-Y.; Park, K.-H.; Jeong, Y.; Kim, H.D. Recognition of vehicle license plates based on image processing. Appl. Sci. 2021, 11, 6292. [Google Scholar] [CrossRef]
- Špaňhel, J.; Sochor, J.; Juránek, R.; Herout, A. Geometric alignment by deep learning for recognition of challenging license plates. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 3524–3529. [Google Scholar] [CrossRef]
- Yoo, H.; Jun, K. Deep corner prediction to rectify tilted license plate images. Multimed. Syst. 2021, 27, 779–786. [Google Scholar] [CrossRef]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part VIII 14. pp. 483–499. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.-E.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7291–7299. [Google Scholar] [CrossRef]
- Wang, K.; Lin, L.; Jiang, C.; Qian, C.; Wei, P. 3D human pose machines with self-supervised learning. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 1069–1082. [Google Scholar] [CrossRef]
- Zhang, T.; Lin, H.; Ju, Z.; Yang, C. Hand Gesture recognition in complex background based on convolutional pose machine and fuzzy Gaussian mixture models. Int. J. Fuzzy Syst. 2020, 22, 1330–1341. [Google Scholar] [CrossRef]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X. Deep high-resolution representation learning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3349–3364. [Google Scholar] [CrossRef]
- Wang, Y.; Li, M.; Cai, H.; Chen, W.-M.; Han, S. Lite pose: Efficient architecture design for 2d human pose estimation. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13126–13136. [Google Scholar] [CrossRef]
- Field Programmable Gate Array (FPGA). Available online: https://en.wikipedia.org/wiki/Field-programmable_gate_array (accessed on 1 June 2024).
- Xilinx KV260. Available online: https://xilinx.github.io/kria-apps-docs/kv260/2022.1/build/html/index.html (accessed on 17 June 2025).
- The Xilinx Deep Learning Processing Unit (DPU). Available online: https://docs.xilinx.com/r/3.2-English/pg338-dpu/Introduction?tocId=iBBrgQ7pinvaWB_KbQH6hQ (accessed on 1 June 2024).
- Xilinx Vitis-AI. Available online: https://www.xilinx.com/products/design-tools/vitis/Vitis-AI.html (accessed on 1 August 2024).
- Gong, F.; Ma, Y.; Zheng, P.; Song, T. A deep model method for recognizing activities of workers on offshore drilling platform by multistage convolutional pose machine. J. Loss Prev. Process Ind. 2020, 64, 104043. [Google Scholar] [CrossRef]
- Xu, H.; Zhou, X.-D.; Li, Z.; Liu, L.; Li, C.; Shi, Y. EILPR: Toward end-to-end irregular license plate recognition based on automatic perspective alignment. IEEE Trans. Intell. Transp. Syst. 2022, 23, 2586–2595. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef]
- Liu, W.; Rabinovich, A.; Berg, A.C. Parsenet: Looking wider to see better. arXiv 2015, arXiv:1506.04579. [Google Scholar]
- Lee, H.; Hsiao, C.-H. Taiwan License Plate Dataset. Available online: https://huggingface.co/datasets/evan6007/TLPD (accessed on 4 June 2025).
- Osokin, D. Global context for convolutional pose machines. arXiv 2019, arXiv:1906.04104. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Input Size | Functions | |||
|---|---|---|---|---|---|
| Original LPRNet [8] | 94 × 24 | nn.MaxPool3D | Average Pooling | Standardization | Mean |
| Modified LPRNet | 94 × 48 | nn.MaxPool2D | Conv2D | BatchNorm2D | Conv2D |
| ) | 1 | 2 | 3 | 4 | 5 | 6 | 7 (Baseline) |
|---|---|---|---|---|---|---|---|
| 0.9583 | 0.9667 | 0.9667 | 0.9500 | 0.9750 | 0.9750 | 0.9667 | |
| 0.7833 | 0.8417 | 0.7833 | 0.7750 | 0.8333 | 0.7917 | 0.7917 |
| Data Split | Original LPRNet [8] (%) | Modified LPRNet (%) | Δ Accuracy (%) | |
|---|---|---|---|---|
| Fold | 1 | 89.47 | 90.79 | 1.32 |
| 2 | 86.51 | 86.18 | −0.33 | |
| 3 | 92.08 | 97.75 | 5.67 | |
| 4 | 88.12 | 87.13 | −0.99 | |
| 5 | 83.83 | 90.43 | 6.60 | |
| 6 | 84.16 | 86.47 | 2.31 | |
| 7 | 85.81 | 90.10 | 4.29 | |
| 8 | 86.47 | 91.09 | 4.62 | |
| 9 | 86.47 | 88.45 | 1.98 | |
| 10 | 88.45 | 86.80 | −1.65 | |
| (Mean) (Std) | 87.14 | 88.92 | 1.78 | |
| ±2.35 | ±3.28 | |||
| Experiment No. | Methods | Accuracy (%) |
|---|---|---|
| 1 | Baseline model (modified LPRNet) tested on unaligned dataset | 88.33 |
| 2 | Modified LPRNet tested on manual-aligned dataset | 98.00 |
| 3 | LPAR tested on unaligned dataset | 95.00 |
| Module | Metrics | Pre-Quantization (%) | Quantized (%) |
|---|---|---|---|
| Pose estimation (refined CPM) | PCK (m = 45) | 97.55 | 97.50 |
| LPAR | Recognition accuracy | 95.00 | 95.00 |
| Stages | YOLOv4-Tiny (s) | Refined CPM (s) | Modified LPRNet (s) | Total (s) | Accuracy (%) |
|---|---|---|---|---|---|
| 7 | 0.437 | 0.110 | 0.05 | 0.597 | 95.00 |
| 2 | 0.437 | 0.013 | 0.05 | 0.500 | 96.67 |
| Δ Total | −0.097 | +1.67 |
| Model | Regular Image Accuracy | Fisheye Image Accuracy | FLOPs (M) | Parameters (M) | FPGA Deployability |
|---|---|---|---|---|---|
| HRNet [24] | 90.00% | 81.67% | 2503.92 | 1.250216 | Yes |
| LitePose [25] | 96.60% | 89.17% | 2644.75 | 1.103608 | No |
| Refined CPM | 97.55% | 94.17% | 3203.23 | 1.123928 | Yes |
| Model | YOLO-Box Data Accuracy | Character-Box Data Accuracy | CPM-Corrected Data Accuracy |
|---|---|---|---|
| CRNN [12] | 0.83% | 79.16% | 85.83% |
| Modified LPR (Ours) | 2.50% | 88.33% | 95.00% |
| Model | Model Training-Time (Hours) | FLOPs (M) | Parameters (M) | FPGA Deployability |
|---|---|---|---|---|
| CRNN [12] | 30 | 104.05 | 16.62 | No |
| Modified LPR (Ours) | 6 | 5983.63 | 6.92 | Yes |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hsiao, C.-H.; Lee, H.; Wang, Y.-T.; Hsu, M.-J. Efficient License Plate Alignment and Recognition Using FPGA-Based Edge Computing. Electronics 2025, 14, 2475. https://doi.org/10.3390/electronics14122475
Hsiao C-H, Lee H, Wang Y-T, Hsu M-J. Efficient License Plate Alignment and Recognition Using FPGA-Based Edge Computing. Electronics. 2025; 14(12):2475. https://doi.org/10.3390/electronics14122475
Chicago/Turabian StyleHsiao, Chao-Hsiang, Hoi Lee, Yin-Tien Wang, and Min-Jie Hsu. 2025. "Efficient License Plate Alignment and Recognition Using FPGA-Based Edge Computing" Electronics 14, no. 12: 2475. https://doi.org/10.3390/electronics14122475
APA StyleHsiao, C.-H., Lee, H., Wang, Y.-T., & Hsu, M.-J. (2025). Efficient License Plate Alignment and Recognition Using FPGA-Based Edge Computing. Electronics, 14(12), 2475. https://doi.org/10.3390/electronics14122475