
Automatic Assembly Inspection of Satellite Payload Module Based on Text Detection and Recognition


Abstract
1. Introduction
- We proposed an automatic assembly inspection framework for the high-throughput satellite payload module based on text information.
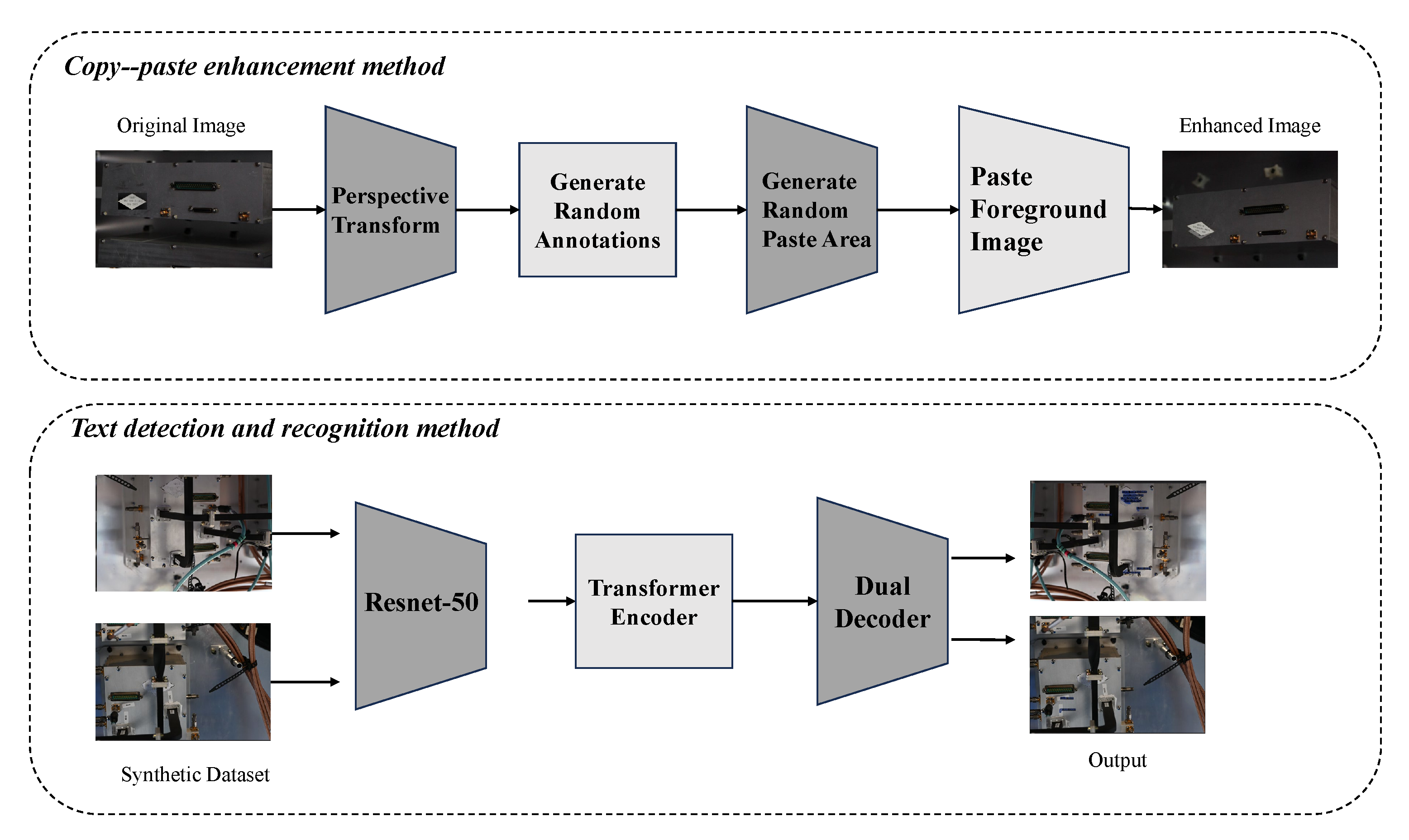
- We developed a copy–paste data augmentation method that generates synthetic images by overlaying foreground images onto background images. Combined with an end-to-end text detection and recognition model, the proposed method enables highly accurate detection performance.
- We conducted experiments on images captured within the specified payload module, achieving an accuracy rate of 87.42% and surpassing the existing methods.
2. Related Work
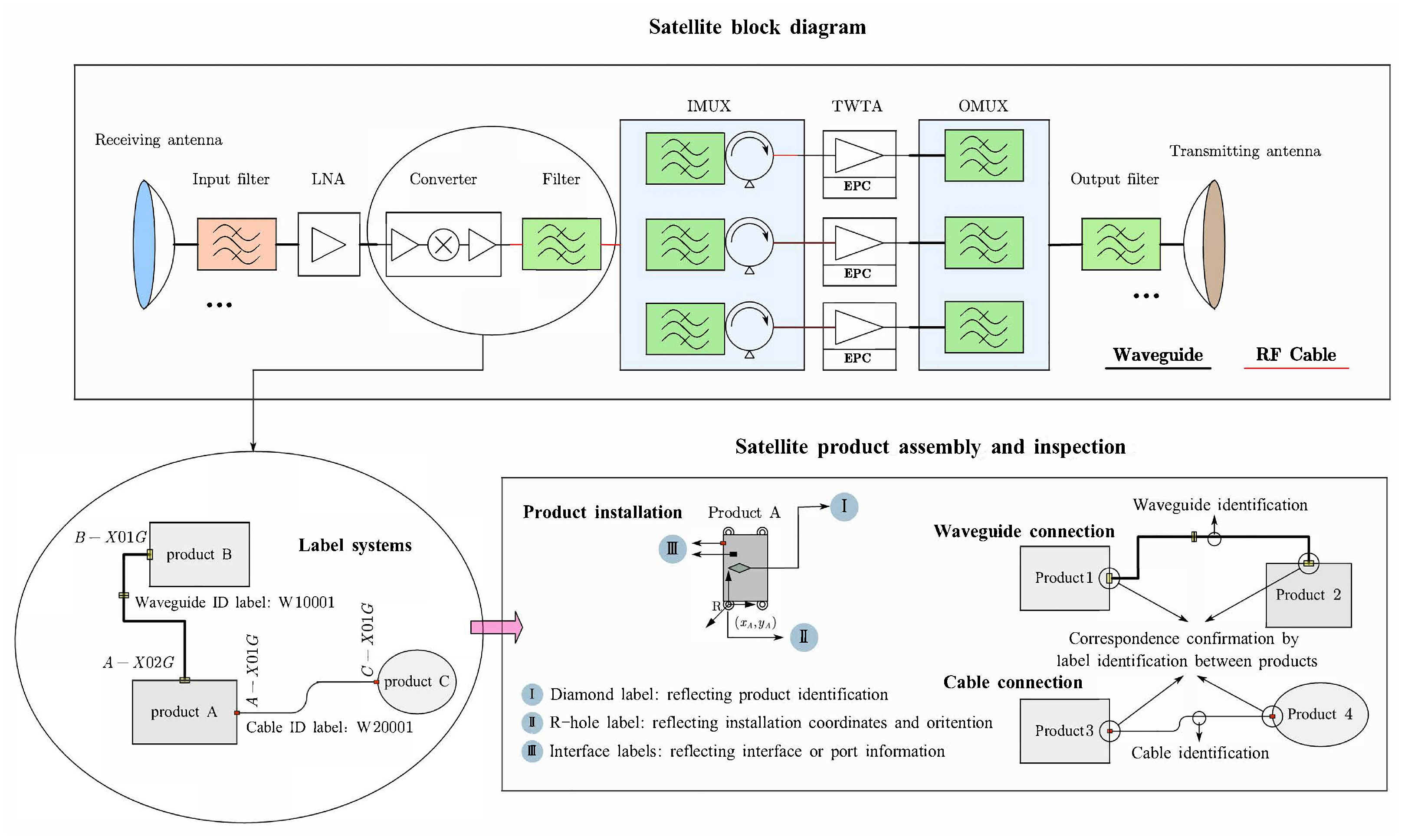
2.1. Inspection of the Assembly of the High-Throughput Satellite Payload Module
2.2. Text Detection and Recognition
3. Materials and Methods
3.1. Copy–Paste Enhancement Method
3.2. Text Detection and Recognition Method
- ResNet-50: ResNet-50 is a convolutional neural network that serves as the backbone for feature extraction and is designed to capture high-level image features. Its residual structure enables the network to handle deeper architectures effectively, making it well-suited for complex image recognition tasks. In our implementation, ResNet-50 is applied to the input image to extract key features that are essential for subsequent text detection and recognition tasks.
- Transformer Encoder: Following the feature extraction by ResNet-50, a Transformer Encoder is utilized. Transformers excel at capturing long-range dependencies in sequential data, which enables the modeling of relationships between different parts of the text within the image. The Transformer Encoder processes the features extracted by ResNet-50, preparing them for the subsequent decoders. This integration enhances the understanding of both location and character information, thereby improving the overall performance of text detection and recognition.
- Location Decoder: The Location Decoder is tasked with accurately localizing text within the image. It employs queries tailored to each text instance and predicts control points, such as the corners of bounding boxes or vertices of polygons. This method enables precise identification of text regions, even when faced with deformations or distortions, thereby ensuring robust text localization. Specifically, the initial control point queries are input into the Location Decoder. After undergoing multi-layer decoding, the refined control point queries are processed by two heads: a classification head that predicts the confidence score, and a 2-channel regression head that outputs the normalized coordinates for each control point. The predicted control points can represent either the N vertices of a polygon or the control points for Bezier curves [24]. For polygon vertices, we adopt a sequence that begins at the top-left corner and proceeds in a clockwise direction. For Bezier control points, Bernstein Polynomials [25] are employed to construct the parametric curves. In this context, we utilize two cubic Bezier curves [24] for each text instance, corresponding to the two potentially curved sides of the text.
- Character Decoder: While the Location Decoder focuses on the spatial localization of text, the Character Decoder is dedicated to the actual recognition of the text content. It predicts the characters within each localized text region by leveraging character queries that are learned and aligned with the location queries. This alignment allows the model to handle both text detection and recognition in parallel, ensuring seamless integration of spatial and semantic information. It largely follows the structure of the Location Decoder, with the key difference being that control point queries are replaced by character queries. The initial character queries consist of a learnable query embedding combined with 1D sine positional encoding, and these queries are shared across different text instances. Importantly, the character query and control point query with the same index correspond to the same text instance.
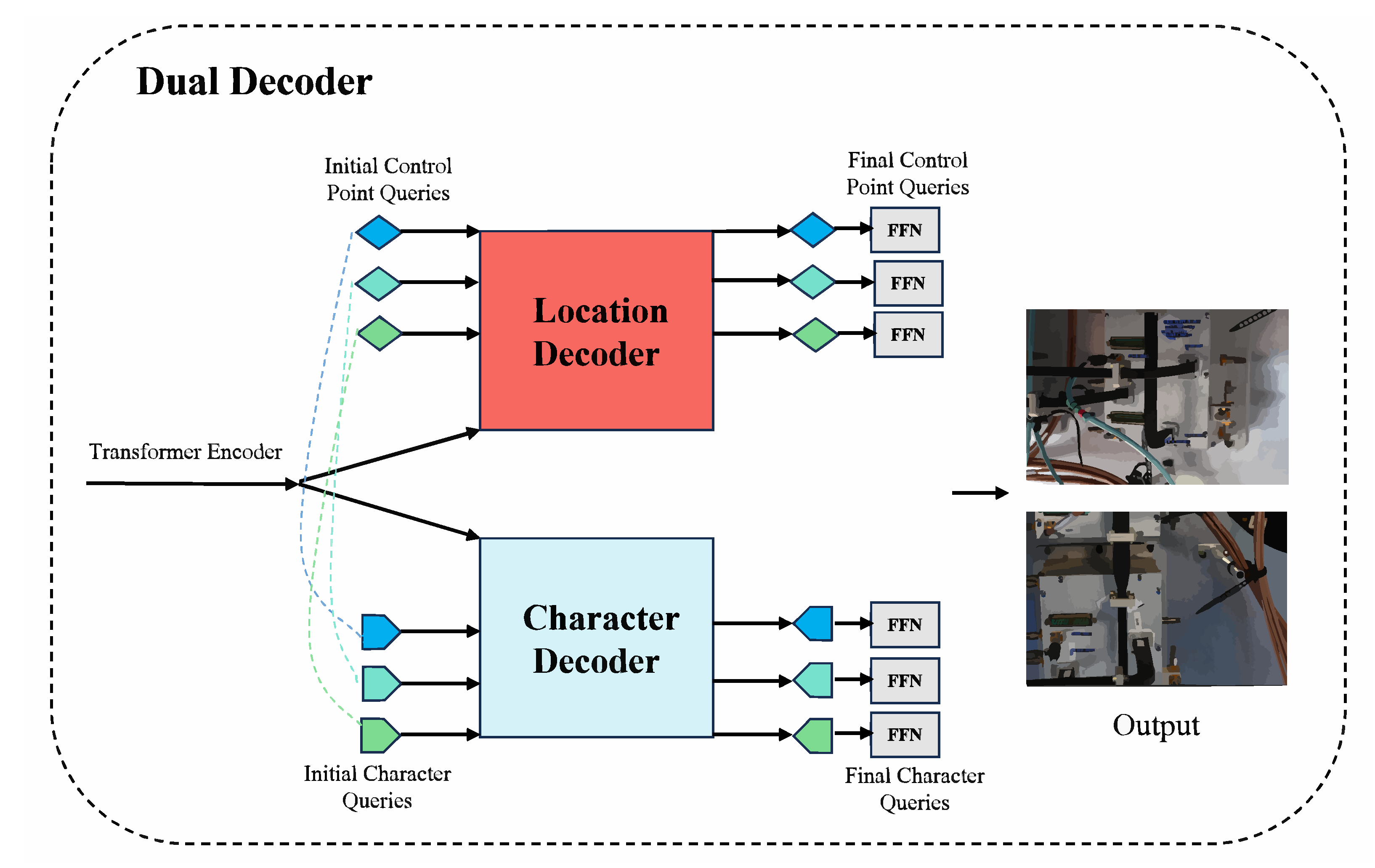
3.3. Training Losses
- Instance classification loss: We use Focal Loss [26] as the loss function for instance classification. It is used to predict whether a text instance exists. Each query corresponds to a text instance, and the loss is used to classify whether each query correctly identifies a text instance. For the t-th query, the loss is defined as follows:where is a balancing factor, used to adjust the importance of positive and negative examples. is the predicted probability of the correct class for the t-th query. is the focusing parameter, which down-weights easy examples and focuses the model on hard examples.
- Control Point Loss: We use Smooth L1 Loss [27] as the control point loss. It is used to regress the control point coordinates of each text instance. The control points define the shape of the text area, usually the four corner points of the text bounding box. The loss is defined as follows:where is the predicted coordinate of the i-th control point. is the ground truth coordinate of the i-th control point. is the Smooth L1 loss function, which combines L1 and L2 loss, being less sensitive to large errors than L2 loss.
- Character classification loss: We use Cross-Entropy Loss [28] as the loss function for character classification. It is used to classify each character in the detected text instance to identify the text content. The loss is defined as follows:where is the true label for the c-th character in the text instance. is the predicted probability of the c-th character. The summation runs over all possible characters in the detected text instance.
4. Results and Discussion
4.1. Dataset and Evaluation Metric
4.2. Comparing Methods
4.3. Implementation Details
4.4. Results and Analysis
4.4.1. Evaluation of the Proposed Method
4.4.2. Ablation Studies on Key Components
4.4.3. Improved Assembly Inspection Efficiency
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tan, X.; Li, X.; Li, Y.; Sun, G.; Niyato, D. Exploration and research on satellite payload technology in boosting the low-altitude economy. Space Electron. Technol. 2025, 22, 1–10. [Google Scholar]
- Baghal, L.A. Assembly, Integration, and Test Methods for Operationally Responsive Space Satellites. Master’s Thesis, Air Force Institute of Technology, Wright-Patterson Air Force Base, Dayton, OH, USA, 2010. [Google Scholar]
- Reyneri, L.M.; Sansoè, C.; Passerone, C.; Speretta, S.; Tranchero, M.; Borri, M.; Corso, D.D. Design solutions for modular satellite architectures. In Aerospace Technologies Advancements; IntechOpen: London, UK, 2010. [Google Scholar]
- Zu, J.; Xiao, P.; Shi, H.; Zhang, X.; Hao, G. Design of Spacecraft Configuration and Assembly. In Spacecraft System Design; CRC Press: Boca Raton, FL, USA, 2023; pp. 221–264. [Google Scholar]
- Rong, Y.; Bingyi, T.; Wei, H.; Yu, L.; Xiting, Q.; Cheng, L. Research on Lean and Accurate Method for High Throughput Satellite Payload Modules’ Assembly Process. In Proceedings of the 2024 IEEE 2nd International Conference on Sensors, Electronics and Computer Engineering (ICSECE), Jinzhou, China, 29–31 August 2024; pp. 48–52. [Google Scholar]
- Stanczak, M. Optimisation of the Waveguide Routing for a Telecommunication Satellite. Ph.D. Thesis, ISAE-Institut Supérieur de l’Aéronautique et de l’Espace, Toulouse, France, 2022. [Google Scholar]
- Liang, S.; Jin, R.; Li, Y.; Dou, H. A convolutional neural network based method for repairing offshore bright temperature error of radiometer array. Space Electron. Technol. 2024, 21, 39–49. [Google Scholar]
- Starodubov, D.; Danishvar, S.; Abu Ebayyeh, A.A.R.M.; Mousavi, A. Advancements in PCB Components Recognition Using WaferCaps: A Data Fusion and Deep Learning Approach. Electronics 2024, 13, 1863. [Google Scholar] [CrossRef]
- Cao, W.; Chen, Z.; Wu, C.; Li, T. A Layered Framework for Universal Extraction and Recognition of Electrical Diagrams. Electronics 2025, 14, 833. [Google Scholar] [CrossRef]
- Liao, M.; Shi, B.; Bai, X.; Wang, X.; Liu, W. Textboxes: A fast text detector with a single deep neural network. In Proceedings of the AAAI Conference on Artificial Intelligence, Atlanta, GA, USA, 11–15 July 2017; Volume 31, pp. 4161–4167. [Google Scholar]
- Liu, Y.; Jin, L. Deep Matching Prior Network: Toward Tighter Multi-Oriented Text Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1962–1969. [Google Scholar]
- Liao, M.; Zhu, Z.; Shi, B.; Xia, G.; Bai, X. Rotation-sensitive regression for oriented scene text detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 5909–5918. [Google Scholar]
- Peng, H.; Yu, J.; Nie, Y. Efficient Neural Network for Text Recognition in Natural Scenes Based on End-to-End Multi-Scale Attention Mechanism. Electronics 2023, 12, 1395. [Google Scholar] [CrossRef]
- Fang, S.; Xie, H.; Wang, Y.; Mao, Z.; Zhang, Y. Read like humans: Autonomous, bidirectional and iterative language modeling for scene text recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 7098–7107. [Google Scholar]
- Qiao, L.; Tang, S.; Cheng, Z.; Xu, Y.; Niu, Y.; Pu, S.; Wu, F. Text Perceptron: Towards End-to-End Arbitrary-Shaped Text Spotting. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11899–11907. [Google Scholar]
- Huang, M.; Liu, Y.; Peng, Z.; Liu, C.; Lin, D.; Zhu, S.; Yuan, N.; Ding, K.; Jin, L. SwinTextSpotter: Scene text spotting via better synergy between text detection and text recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 4593–4603. [Google Scholar]
- Zhou, B.; Wang, X.; Zhou, W.; Li, L. Trademark Text Recognition Combining SwinTransformer and Feature-Query Mechanisms. Electronics 2024, 13, 2814. [Google Scholar] [CrossRef]
- Kortmann, M.; Zeis, C.; Meinert, T.; Schröder, K.; Dueck, A. Design and qualification of a multifunctional interface for modular satellite systems. In Proceedings of the 69th International Astronautical Congress, Bremen, Germany, 1–5 October 2018; pp. 1–5. [Google Scholar]
- Liu, Y.; Li, Y.; Sun, B.; Zheng, Y.; Ye, Z. Multi-scale heterogeneous and cross-modal attention for remote sensing image classification. Space Electron. Technol. 2024, 21, 57–65. [Google Scholar]
- Ghiasi, G.; Cui, Y.; Srinivas, A.; Qian, R.; Lin, T.; Cubuk, E.D.; Le, Q.V.; Zoph, B. Simple Copy-Paste is a Strong Data Augmentation Method for Instance Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 2918–2928. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 5998–6008. [Google Scholar]
- Zhang, X.; Su, Y.; Tripathi, S.; Tu, Z. Text Spotting Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 9519–9528. [Google Scholar]
- Liu, Y.; Chen, H.; Shen, C.; He, T.; Jin, L.; Wang, L. ABCNet: Real-Time Scene Text Spotting with Adaptive Bezier-Curve Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9809–9818. [Google Scholar]
- Lorentz, G.G. Bernstein Polynomials; AMS Chelsea Publishing, American Mathematical Society: New York, NY, USA, 2012; Volume 323. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Janocha, K.; Czarnecki, W.M. On Loss Functions for Deep Neural Networks in Classification. arXiv 2017, arXiv:1702.05659. [Google Scholar] [CrossRef]
- Zhang, Z.; Sabuncu, M.R. Generalized Cross Entropy Loss for Training Deep Neural Networks with Noisy Labels. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; Volume 31, pp. 8778–8788. [Google Scholar]
- Bogdanović, M.; Frtunić Gligorijević, M.; Kocić, J.; Stoimenov, L. Improving Text Recognition Accuracy for Serbian Legal Documents Using BERT. Appl. Sci. 2025, 15, 615. [Google Scholar] [CrossRef]
- Du, Y.; Li, C.; Guo, R.; Yin, X.; Liu, W.; Zhou, J.; Bai, Y.; Yu, Z.; Yang, Y.; Dang, Q.; et al. Pp-ocr: A practical ultra lightweight ocr system. arXiv 2020, arXiv:2009.09941. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Success Images | All Images | Success Rate [%] |
|---|---|---|---|
| ABINet-PP [14] | 87 | 159 | 54.71 |
| SwinTextSpotter [16] | 67 | 159 | 42.14 |
| Text Perceptron E2E(OCR) [15] | 91 | 159 | 57.23 |
| Paddle OCR [30] | 48 | 159 | 30.19 |
| Proposed | 139 | 159 | 87.42 |
| Method | Success Images | All Images | Success Rate [%] |
|---|---|---|---|
| Without Data Augmentation | 93 | 159 | 58.49 |
| Proposed | 139 | 159 | 87.42 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Dai, J.; Kang, J.; Wei, W. Automatic Assembly Inspection of Satellite Payload Module Based on Text Detection and Recognition. Electronics 2025, 14, 2423. https://doi.org/10.3390/electronics14122423
Li J, Dai J, Kang J, Wei W. Automatic Assembly Inspection of Satellite Payload Module Based on Text Detection and Recognition. Electronics. 2025; 14(12):2423. https://doi.org/10.3390/electronics14122423
Chicago/Turabian StyleLi, Jun, Junwei Dai, Jia Kang, and Wei Wei. 2025. "Automatic Assembly Inspection of Satellite Payload Module Based on Text Detection and Recognition" Electronics 14, no. 12: 2423. https://doi.org/10.3390/electronics14122423
APA StyleLi, J., Dai, J., Kang, J., & Wei, W. (2025). Automatic Assembly Inspection of Satellite Payload Module Based on Text Detection and Recognition. Electronics, 14(12), 2423. https://doi.org/10.3390/electronics14122423