
Large Language Model Text Adversarial Defense Method Based on Disturbance Detection and Error Correction

Abstract
1. Introduction
2. Related Work
3. Approach
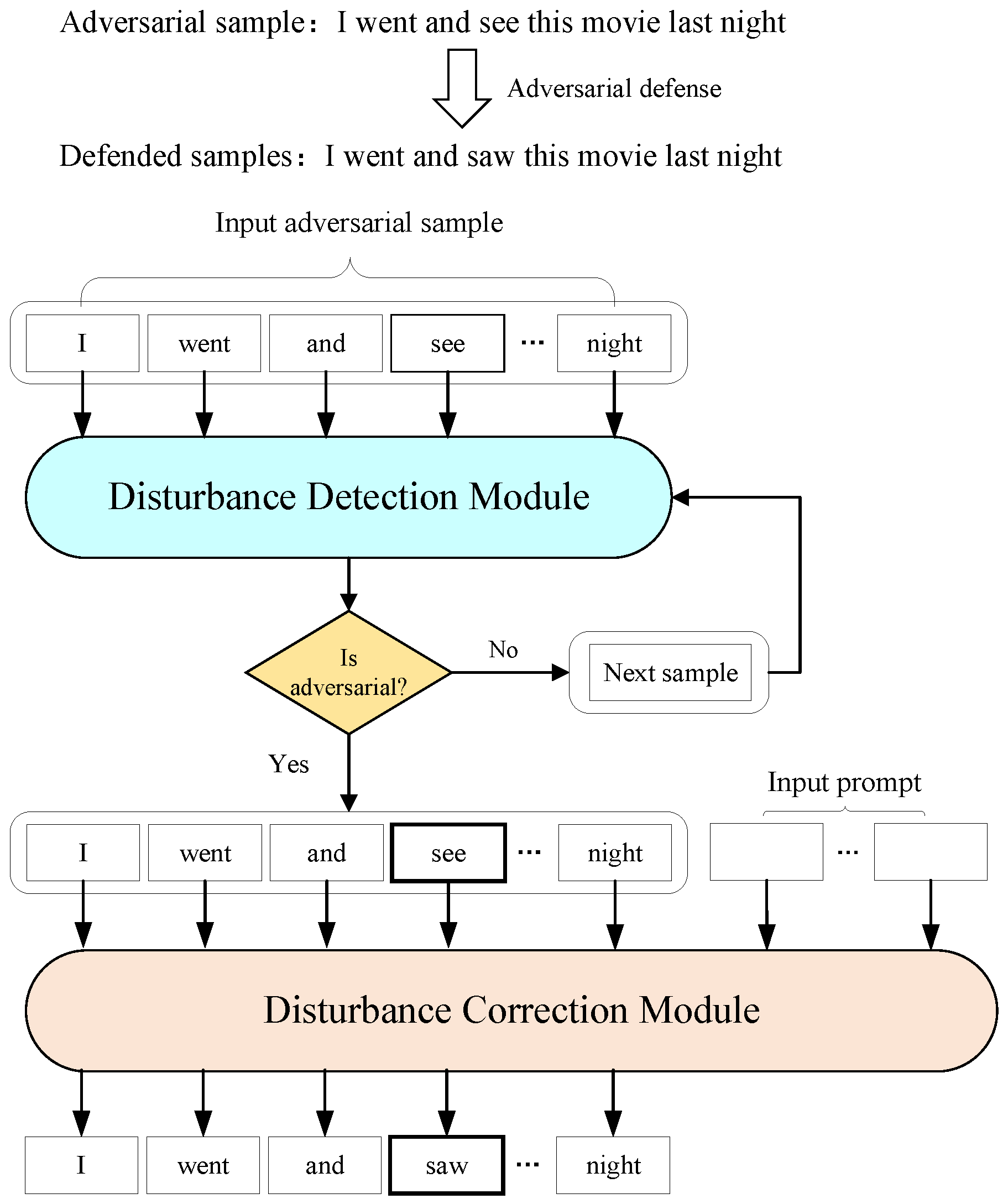
3.1. Problem Formulation
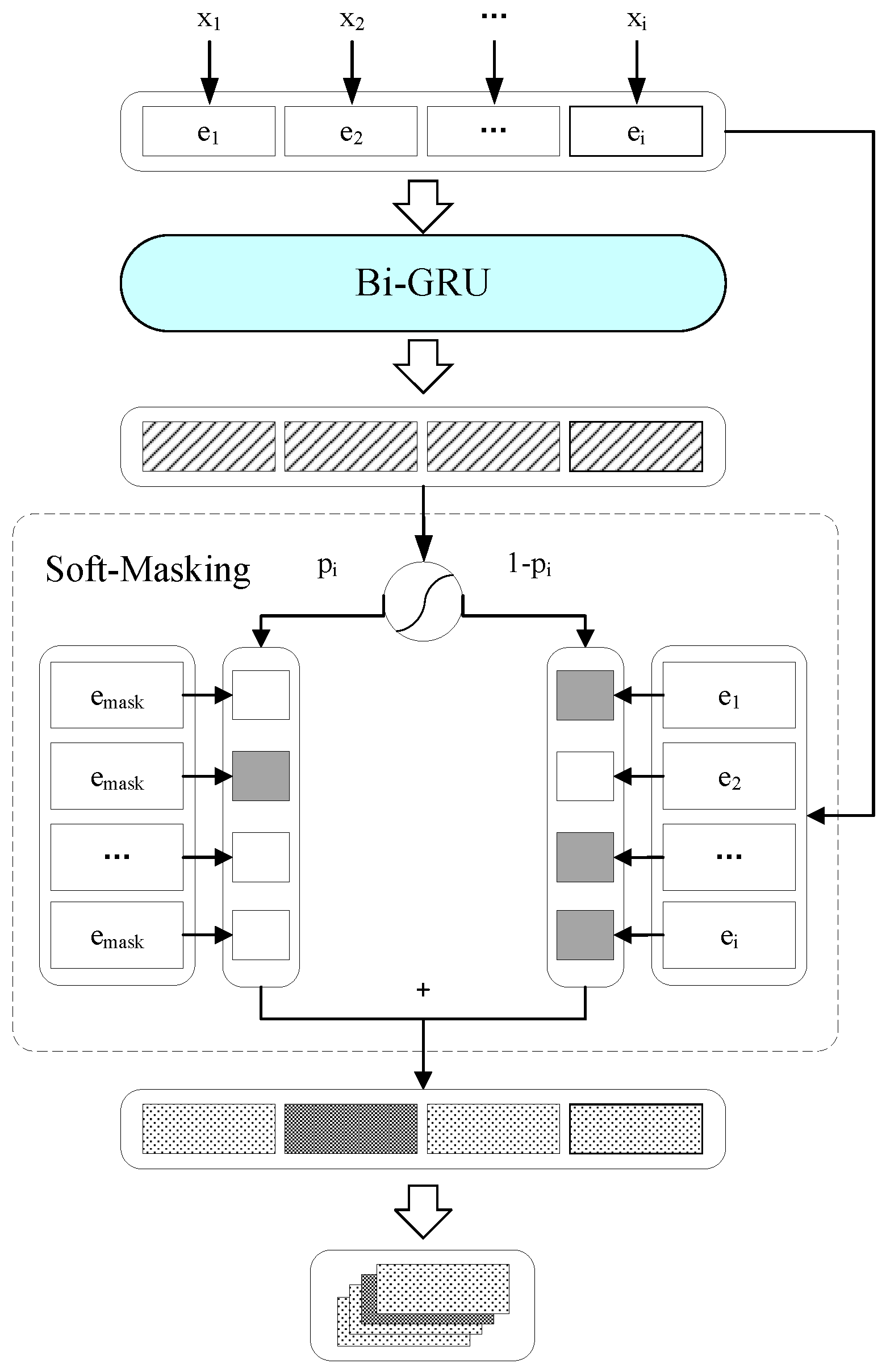
3.2. Model
3.3. Disturbance Detection Module
3.4. Perturbation Correction Module
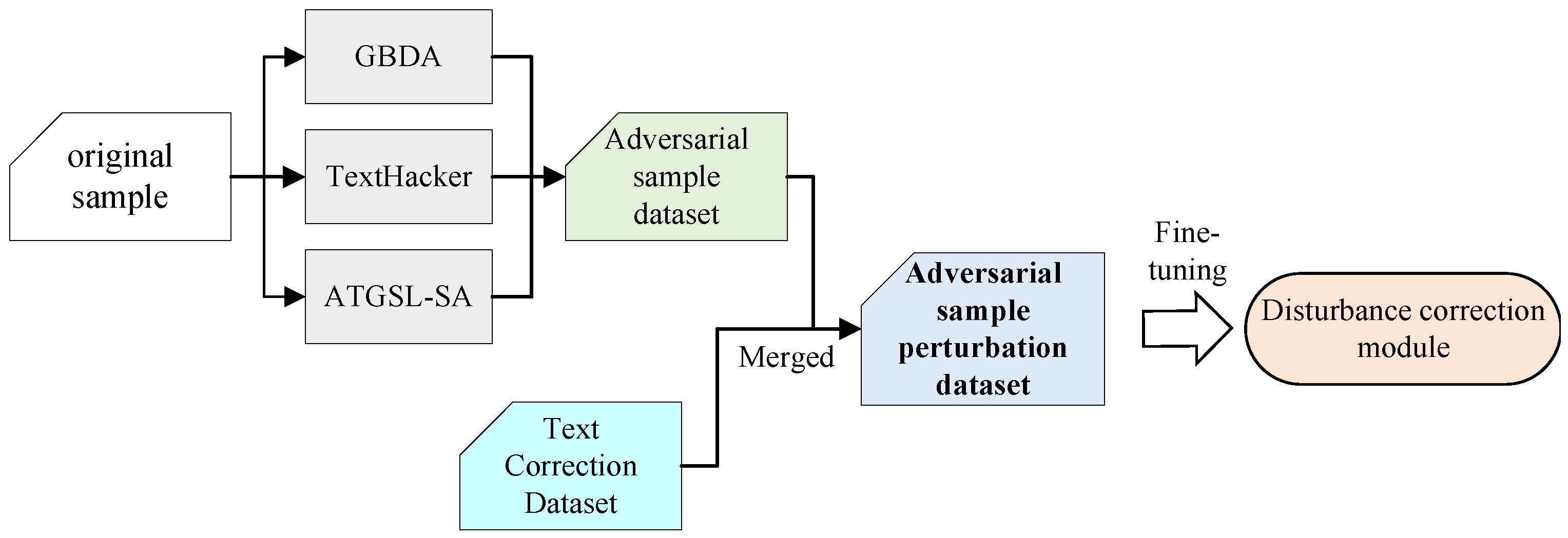
3.4.1. Construction of Adversarial Perturbation Dataset
- ATGSL-SA employs a heuristic search-based attack algorithm combined with a linguistic lexicon to generate adversarial examples with high semantic similarity;
- TextHacker utilizes a learning-based hybrid local search algorithm that estimates word importance through prediction label changes induced via word substitutions and optimizes adversarial perturbations to minimize deviations from original samples;
- GBDA searches for an adversarial distribution, leveraging BERTScore and language model perplexity to enhance perceptual quality and fluency. The integration of these components enables powerful, efficient, and gradient-based textual adversarial attacks.
- The FEC dataset consists of 1244 scripts written by international learners of English as a second language. Each script typically contains two errors, with each error annotated and corrected by human annotators based on a framework of 88 error types;
- The NUCLE dataset comprises 1397 argumentative essays covering diverse topics such as technology, healthcare, and finance. Each essay is corrected by an annotator following a taxonomy of 28 error types.
3.4.2. Fine-Tuning of the Perturbation Correction Module
4. Experiments
4.1. Dataset and Metrics
4.2. Baselines
- CNN: CNN uses multi-scale convolutional kernels, embedding layers, varied convolutions, max-pooling, fully-connected layers, and softmax for text feature extraction and classification.
- LSTM: LSTM network introduces a gated mechanism, employing forget gates, input gates, and output gates to dynamically control the retention, updating, and transmission of sequential state information.
- BERT: BERT, a bidirectional transformer model, uses self-attention and masked language tasks to learn global context. Fine-tuning adapts it to downstream tasks with improved transfer.
- PWWS [29]: PWWS creates text adversarial examples by replacing words with synonyms weighted by word saliency and classification probability change.
- TextFooler [30]: TextFooler generates adversarial text by replacing important words with semantically similar synonyms to alter model predictions while preserving semantic meaning.
- DeepWordBug [31]: DeepWordBug generates adversarial text sequences by identifying critical tokens and applying small character-level transformations to evade deep learning classifiers.
- FGWS [14]: FGWS detects adversarial examples by replacing infrequent words with semantically similar, more frequent ones based on a frequency analysis of adversarial substitutions.
- WDR [32]: WDR detects adversarial text examples by analyzing logits variation to identify suspicious word-level changes in classifier reactions.
- SEM [33]: SEM defends against synonym substitution attacks by encoding synonyms to unique tokens before the input layer.
4.3. Experiment Setting
4.4. Main Results
4.5. Perturbation Detection Performance
4.6. Semantic Similarity Performance
4.7. Ablation Study
5. Discussion
5.1. Future Research Directions
5.2. Practical Application
5.3. Statistical Significance Test
5.4. Case Study
- Adversarial perturbation detection: The heatmap highlights significantly elevated perturbation probabilities (darker hues) in tampered words (e.g., “trOied”), confirming the detection module’s precision in localizing adversarial modifications.
- Linguistic error correction: the defense module not only corrects adversarial perturbations (e.g., “mvoie”→“movie”) but also adaptively fixes grammatical errors in original samples (e.g., capitalizing “The”).
- Classification outcome rectification: the post-defense sample’s classification shifts from “positive” to “negative”, empirically proving that perturbation correction restores the model’s understanding of true semantic meaning.

6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| LLMAD | Large Language Model Adversarial Defense |
| LLMs | Large Language Models |
| MDLM | Multi-level Disturbance Localization Method |
| DISP | DIScriminate Perturbations |
| FGWSs | Frequency-Guided Word Substitutions |
| SCRN | Siamese Calibrated Reconstruction Network |
| MQA | Multi-Query Attention |
| GLU | Gated Linear Unit |
| FFN | Feed-forward Network |
| ODDMAD | Adversarial Defense with Only Disturbance Detection Module |
| ODCMAD | Adversarial Defense with Only Disturbance Correction Module |
References
- Joshi, A.; Dabre, R.; Kanojia, D.; Li, Z.; Zhan, H.; Haffari, G.; Dippold, D. Natural Language Processing for Dialects of a Language: A Survey. ACM Comput. Surv. 2025, 57, 1–37. [Google Scholar] [CrossRef]
- Noor, M.H.M.; Ige, A.O. A Survey on State-of-the-art Deep Learning Applications and Challenges. arXiv 2024, arXiv:2403.17561. [Google Scholar]
- Xiao, Q.; Li, K.; Zhang, D.; Xu, W. Security Risks in Deep Learning Implementations. In Proceedings of the 2018 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 24 May 2018; pp. 123–128. [Google Scholar]
- Behjati, M.; Moosavi-Dezfooli, S.M.; Baghshah, M.S.; Frossard, P. Universal Adversarial Attacks on Text Classifiers. In Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 7345–7349. [Google Scholar]
- Zhou, L.; Cui, P.; Zhang, X.; Jiang, Y.; Yang, S. Adversarial Eigen Attack on Black-Box Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 15254–15262. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Liu, H.; Zhao, B.; Guo, J.B.; Peng, Y.F. A Survey of Adversarial Attacks Against Deep Learning. J. Cryptol. 2021, 8, 202–214. [Google Scholar]
- Zhao, H.; Chang, Y.K.; Wang, W.J. Adversarial Attacks and Defense Methods for Deep Neural Networks: A Survey. Comput. Sci. 2022, 49, 662–672. [Google Scholar]
- Wu, H.; Liu, Y.; Shi, H.; Zhao, H.; Zhang, M. Toward Adversarial Training on Contextualized Language Representation. arXiv 2023, arXiv:2305.04557. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing Properties of Neural Networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Papernot, N.; McDaniel, P.; Swami, A.; Harang, R. Crafting Adversarial Input Sequences for Recurrent Neural Networks. In Proceedings of the 2016 IEEE Military Communications Conference, Baltimore, MD, USA, 1–3 November 2016; pp. 49–54. [Google Scholar]
- Hou, Y.; Che, L.; Li, H. A Multi-level Perturbation Localization Method for Generating Chinese Textual Adversarial Examples. Comput. Eng. 2024, 1–11. [Google Scholar] [CrossRef]
- Zhou, Y.; Jiang, J.Y.; Chang, K.W.; Wang, W. Learning to Discriminate Perturbations for Blocking Adversarial Attacks in Text Classification. arXiv 2019, arXiv:1909.03084. [Google Scholar]
- Mozes, M.; Stenetorp, P.; Kleinberg, B.; Griffin, L.D. Frequency-Guided Word Substitutions for Detecting Textual Adversarial Examples. arXiv 2020, arXiv:2004.05887. [Google Scholar]
- Huang, G.; Zhang, Y.; Li, Z.; You, Y.; Wang, M.; Yang, Z. Are AI-Generated Text Detectors Robust to Adversarial Perturbations? arXiv 2024, arXiv:2406.01179. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models Are Few-Shot Learners. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–12 December 2020; pp. 1877–1901. [Google Scholar]
- Wei, J.; Tay, Y.; Bommasani, R.; Raffel, C.; Zoph, B.; Borgeaud, S.; Yogatama, D.; Bosma, M.; Zhou, D.; Metzler, D.; et al. Emergent Abilities of Large Language Models. arXiv 2022, arXiv:2206.07682. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems 30, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Xu, X.; Kong, K.; Liu, N.; Cui, L.; Wang, D.; Zhang, J.; Kankanhalli, M. An LLM Can Fool Itself: A Prompt-Based Adversarial Attack. arXiv 2023, arXiv:2310.13345. [Google Scholar]
- Li, G.; Shi, B.; Liu, Z.; Kong, D.; Wu, Y.; Zhang, X.; Huang, L.; Lyu, H. Adversarial Text Generation by Search and Learning. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, 6–10 December 2023; pp. 15722–15738. [Google Scholar]
- Yu, Z.; Wang, X.; Che, W.; He, K. TextHacker: Learning-Based Hybrid Local Search Algorithm for Text Hard-Label Adversarial Attack. arXiv 2022, arXiv:2201.08193. [Google Scholar]
- Guo, C.; Sablayrolles, A.; Jégou, H.; Kiela, D. Gradient-Based Adversarial Attacks Against Text Transformers. arXiv 2021, arXiv:2104.13733. [Google Scholar]
- Bryant, C.; Yuan, Z.; Qorib, M.R.; Cao, H.; Ng, H.T.; Briscoe, T. Grammatical Error Correction: A Survey of the State of the Art. Comput. Linguist. 2023, 49, 643–701. [Google Scholar] [CrossRef]
- Maas, A.; Daly, R.E.; Pham, P.T.; Huang, D.; Ng, A.Y.; Potts, C. Learning word vectors for sentiment analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; pp. 142–150. [Google Scholar]
- Zhang, X.; Zhao, J.; LeCun, Y. Character-level convolutional networks for text classification. In Proceedings of the 28th Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 649–657. [Google Scholar]
- Zhang, Y.; Wallace, B. A sensitivity analysis of (and practitioners’ guide to) convolutional neural networks for sentence classification. arXiv 2015, arXiv:1510.0382. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Ren, S.; Deng, Y.; He, K.; Che, W. Generating natural language adversarial examples through probability weighted word saliency. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 1085–1097. [Google Scholar]
- Jin, D.; Jin, Z.; Zhou, J.T.; Szolovits, P. Is BERT Really Robust? A Strong Baseline for Natural Language Attack on Text Classification and Entailment. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 8018–8025. [Google Scholar]
- Gao, J.; Lanchantin, J.; Soffa, M.L.; Qi, Y. Black-box Generation of Adversarial Text Sequences to Evade Deep Learning Classifiers. In Proceedings of the 2018 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 24 May 2018; pp. 50–56. [Google Scholar]
- Mosca, E.; Agarwal, S.; Rando, J.; Groh, G. “That Is a Suspicious Reaction!”: Interpreting logits variation to detect NLP adversarial attacks. arXiv 2022, arXiv:2204.04636. [Google Scholar]
- Wang, X.; Hao, J.; Yang, Y.; He, K. Natural language adversarial defense through synonym encoding. In Proceedings of the 37th Conference on Uncertainty in Artificial Intelligence, Online, 27–30 July 2021; pp. 823–833. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Prompt Template | Output |
|---|---|---|
| ChatGLM3-6b | input: {adversarial sample} Please correct the spelling and grammar errors in the previous sentence, with minimal modificatio- ns and try not to change the sentence length, and output the corrected sentence | {correct sample} |
| Dataset | Classes | Number of Training Samples | Number of Test Samples | Average Length |
|---|---|---|---|---|
| IMDB | 2 | 25,000 | 25,000 | 215 |
| AG’s News | 4 | 120,000 | 7600 | 43 |
| Yahoo!Answers | 10 | 140,000 | 5000 | 108 |
| Model | Defense Approach | None | PWWS | TextFooler | DeepWord-Bug |
|---|---|---|---|---|---|
| CNN | None | 89.5 | 0.8 | 2.8 | 1.6 |
| FGWS | 81.5 | 76.2 | 76.5 | 44.1 | |
| WDR | 85.2 | 63.8 | 67.1 | 64.7 | |
| SEM | 87.4 | 63.7 | 63.9 | 61.7 | |
| LLMAD | 88.1 | 82.4 | 82.7 | 83.7 | |
| LSTM | None | 89 | 0.4 | 1.8 | 0.5 |
| FGWS | 77.4 | 67.8 | 68 | 46.8 | |
| WDR | 85 | 72 | 75.2 | 74.1 | |
| SEM | 86.3 | 63.4 | 63.8 | 62.2 | |
| LLMAD | 87.4 | 80.4 | 80.5 | 76.9 | |
| BERT | None | 92.2 | 16.4 | 8.1 | 1.7 |
| FGWS | 72.1 | 60.1 | 61.2 | 38.1 | |
| WDR | 81.3 | 65.2 | 65.4 | 63.9 | |
| SEM | 89.5 | 70.2 | 70.8 | 69.6 | |
| LLMAD | 91.6 | 82.6 | 82.8 | 81.4 |
| Model | Defense Approach | None | PWWS | TextFooler | DeepWord-Bug |
|---|---|---|---|---|---|
| CNN | None | 62.9 | 1.2 | 1.5 | 0.9 |
| FGWS | 52.4 | 47.8 | 48.2 | 32.0 | |
| WDR | 61.7 | 50.3 | 52.0 | 50.5 | |
| SEM | 60.5 | 34.8 | 34.5 | 32.7 | |
| LLMAD | 59.8 | 57.1 | 57.3 | 56.8 | |
| LSTM | None | 65.8 | 0.6 | 1.0 | 0.6 |
| FGWS | 42.8 | 42.3 | 41.7 | 28.1 | |
| WDR | 62.7 | 48.3 | 49.8 | 47.2 | |
| SEM | 61.9 | 35.2 | 35.3 | 33.8 | |
| LLMAD | 62.9 | 58.0 | 57.8 | 57.5 | |
| BERT | None | 65.9 | 2.5 | 1.5 | 0.9 |
| FGWS | 58.3 | 44.7 | 42.5 | 29.5 | |
| WDR | 63.4 | 50.3 | 51.0 | 49,5 | |
| SEM | 64.0 | 39.9 | 37.5 | 39.6 | |
| LLMAD | 63.2 | 55.8 | 55.3 | 55.7 |
| Model | Defense Approach | None | PWWS | TextFooler | DeepWord-Bug |
|---|---|---|---|---|---|
| CNN | None | 72.8 | 6.9 | 7.3 | 5.1 |
| FGWS | 63.5 | 55.1 | 55.3 | 38.7 | |
| WDR | 72.3 | 62.7 | 63.1 | 62.8 | |
| SEM | 69.5 | 53.6 | 52.7 | 52.3 | |
| LLMAD | 69.5 | 66.5 | 66.3 | 67.2 | |
| LSTM | None | 74.9 | 11.4 | 10.1 | 6.8 |
| FGWS | 54.7 | 47.8 | 47.9 | 33.7 | |
| WDR | 73.8 | 61.0 | 60.5 | 60.3 | |
| SEM | 72.3 | 57.2 | 56.5 | 56.0 | |
| LLMAD | 71.9 | 69.2 | 68.4 | 68.1 | |
| BERT | None | 77.3 | 21.0 | 10.5 | 7.5 |
| FGWS | 70.9 | 59.9 | 62.4 | 37.2 | |
| WDR | 75.6 | 66.8 | 67.5 | 65.3 | |
| SEM | 75.2 | 64.6 | 62.8 | 62.3 | |
| LLMAD | 75.5 | 71.4 | 71.8 | 71.3 |
| Dataset | Model | Attack Method | FGWS | WDR | LLMAD | |||
|---|---|---|---|---|---|---|---|---|
| Rec | F1 | Rec | F1 | Rec | F1 | |||
| IMDB | CNN | PWWS | 80.2 | 86 | 87.9 | 87.2 | 97.7 | 95.8 |
| TextFooler | 75.8 | 85.1 | 89.9 | 91.5 | 97 | 94.5 | ||
| DeepWordBug | 56.7 | 57.8 | 91 | 86.3 | 95.3 | 93.1 | ||
| LSTM | PWWS | 70.7 | 80.1 | 92.5 | 92.4 | 95 | 94.6 | |
| TextFooler | 77.6 | 83.7 | 94.8 | 95 | 95.7 | 95.5 | ||
| DeepWordBug | 59.8 | 60.1 | 92 | 93.6 | 96.2 | 96.1 | ||
| BERT | PWWS | 82.6 | 85.9 | 91.7 | 93.2 | 92 | 93.7 | |
| TextFooler | 79.9 | 86.6 | 93.7 | 93.9 | 97.1 | 95.2 | ||
| DeepWordBug | 58.8 | 64.7 | 92 | 91.5 | 92.2 | 93.6 | ||
| AG’s News | CNN | PWWS | 86 | 90.2 | 91 | 86.1 | 94.2 | 90.5 |
| TextFooler | 82.5 | 85.9 | 92.5 | 87.7 | 95.3 | 91.2 | ||
| DeepWordBug | 49.7 | 57.2 | 90.1 | 85.3 | 92.3 | 87.9 | ||
| LSTM | PWWS | 87.3 | 86.7 | 84.6 | 86.8 | 94.5 | 88.5 | |
| TextFooler | 89.7 | 89 | 91.2 | 89.8 | 96.2 | 91.2 | ||
| DeepWordBug | 56.7 | 62.1 | 83.4 | 83.3 | 88.6 | 84.1 | ||
| BERT | PWWS | 85 | 89.5 | 87.9 | 90.6 | 91.9 | 92.2 | |
| TextFooler | 81.5 | 87.5 | 84.5 | 86.3 | 91.7 | 90.5 | ||
| DeepWordBug | 62.2 | 67.9 | 75.4 | 78.3 | 85.3 | 85.8 | ||
| Yahoo! | CNN | PWWS | 79.8 | 85.7 | 89.5 | 89.2 | 94.8 | 94.1 |
| TextFooler | 74.3 | 84 | 88.7 | 89.8 | 94.5 | 93.2 | ||
| DeepWordBug | 55.2 | 56.4 | 89.6 | 84.5 | 93.8 | 91.5 | ||
| LSTM | PWWS | 82.3 | 86.1 | 90.8 | 90.1 | 93.4 | 92.3 | |
| TextFooler | 89.2 | 89.5 | 92.6 | 92.7 | 94.2 | 94.0 | ||
| DeepWordBug | 58.4 | 63.5 | 90.3 | 91.8 | 91.5 | 92.4 | ||
| BERT | PWWS | 81.1 | 84.6 | 91.5 | 92.4 | 91.8 | 92.1 | |
| TextFooler | 78.4 | 85.3 | 91.8 | 91.7 | 95.4 | 94.6 | ||
| DeepWordBug | 59.5 | 63.9 | 89.9 | 90.5 | 90.2 | 90.3 | ||
| Model | Attack Method | FGWS | WDR | LLMAD |
|---|---|---|---|---|
| CNN | PWWS | 83.5 | 84.9 | 85.8 |
| TextFooler | 85.2 | 86.4 | 88.0 | |
| DeepWordBug | 85.0 | 86.6 | 87.8 | |
| LSTM | PWWS | 80.3 | 81.5 | 83.1 |
| TextFooler | 83.5 | 84.8 | 86.2 | |
| DeepWordBug | 88.9 | 90.2 | 91.6 | |
| BERT | PWWS | 92.7 | 94.0 | 95.4 |
| TextFooler | 94.2 | 95.5 | 96.9 | |
| DeepWordBug | 92.1 | 93.5 | 95.8 |
| Model | Defense Approach | None | PWWS | TextFooler | DeepWord-Bug |
|---|---|---|---|---|---|
| CNN | None | 89.5 | 0.8 | 2.8 | 1.6 |
| ODDMAD | 89.1 | 76.9 | 76.3 | 78.7 | |
| ODCMAD | 86.7 | 79.6 | 79.5 | 81.3 | |
| MMLAD | 88.1 | 82.4 | 82.7 | 83.7 | |
| LSTM | None | 89 | 0.4 | 1.8 | 0.5 |
| ODDMAD | 89.3 | 74 | 75.1 | 72.6 | |
| ODCMAD | 87.4 | 77.2 | 77.9 | 75.1 | |
| MMLAD | 87.4 | 80.4 | 80.5 | 76.9 | |
| BERT | None | 92.2 | 16.4 | 8.1 | 1.7 |
| ODDMAD | 91.2 | 74.3 | 76.8 | 74.1 | |
| ODCMAD | 90.6 | 78.2 | 80.5 | 79.5 | |
| MMLAD | 91.6 | 82.6 | 82.8 | 81.4 |
| Model | Comparison Pair | Attack Methods | t(38) | p-Value | Significant |
|---|---|---|---|---|---|
| CNN | LLMAD vs. FGWS | DeepWordBug | 10.21 | 0.001 | Yes |
| CNN | LLMAD vs. WDR | DeepWordBug | 8.76 | 0.001 | Yes |
| CNN | LLMAD vs. FGWS | PWWS | 4.21 | 0.001 | Yes |
| CNN | LLMAD vs. WDR | PWWS | 3.76 | 0.002 | Yes |
| LSTM | LLMAD vs. FGWS | TextFooler | 6.34 | 0.001 | Yes |
| LSTM | LLMAD vs. WDR | TextFooler | 5.12 | 0.001 | Yes |
| BERT | LLMAD vs. FGWS | None | 9.78 | 0.001 | Yes |
| BERT | LLMAD vs. WDR | None | 7.45 | 0.001 | Yes |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Che, L.; Wu, C.; Hou, Y. Large Language Model Text Adversarial Defense Method Based on Disturbance Detection and Error Correction. Electronics 2025, 14, 2267. https://doi.org/10.3390/electronics14112267
Che L, Wu C, Hou Y. Large Language Model Text Adversarial Defense Method Based on Disturbance Detection and Error Correction. Electronics. 2025; 14(11):2267. https://doi.org/10.3390/electronics14112267
Chicago/Turabian StyleChe, Lei, Chengcong Wu, and Yan Hou. 2025. "Large Language Model Text Adversarial Defense Method Based on Disturbance Detection and Error Correction" Electronics 14, no. 11: 2267. https://doi.org/10.3390/electronics14112267
APA StyleChe, L., Wu, C., & Hou, Y. (2025). Large Language Model Text Adversarial Defense Method Based on Disturbance Detection and Error Correction. Electronics, 14(11), 2267. https://doi.org/10.3390/electronics14112267