
Multimodal Medical Image Fusion Using a Progressive Parallel Strategy Based on Deep Learning

Abstract
1. Introduction
- (a)
- Progressive parallel fusion strategy: by employing hierarchical progressive feature extraction and parallel fusion, this strategy enhances global–local collaborative optimization, promotes structural consistency and detail preservation, mitigates single-modality dominance, and enhances image layering and diagnostic sensitivity.
- (b)
- Hierarchical heterogeneous fusion architecture, comprising three core modules: ① a Nonlinear Interactive Feature Extraction (NIFE) module, which uses element-wise multiplication and residual connections to progressively fuse MRI texture and PET metabolic features; ② a Transformer-Enhanced Global Modeling (TEGM) module, which combines the global modeling capability of Transformers with the local perception of CNNs to capture both channel-wise and spatial dependencies; and ③ a Dynamic Edge-Enhanced Module (DEEM) built upon inverted residual and SE blocks, which emphasizes high-frequency features in diagnostically sensitive regions.
- (c)
- Optimized multimodal fusion loss function: A triple-objective unsupervised loss is designed, consisting of Lfunctional (for improving metabolic region fidelity), Lstructure (to constrain structural consistency), and Ldetail (to enhance edges and textures), thereby significantly improving lesion distinguishability. PPMF-Net integrates the advantages of Transformers and CNNs, strengthening the robustness of unregistered image fusion and demonstrating strong potential for clinical application.
2. Application of Deep Learning in Multimodal Medical Image Fusion
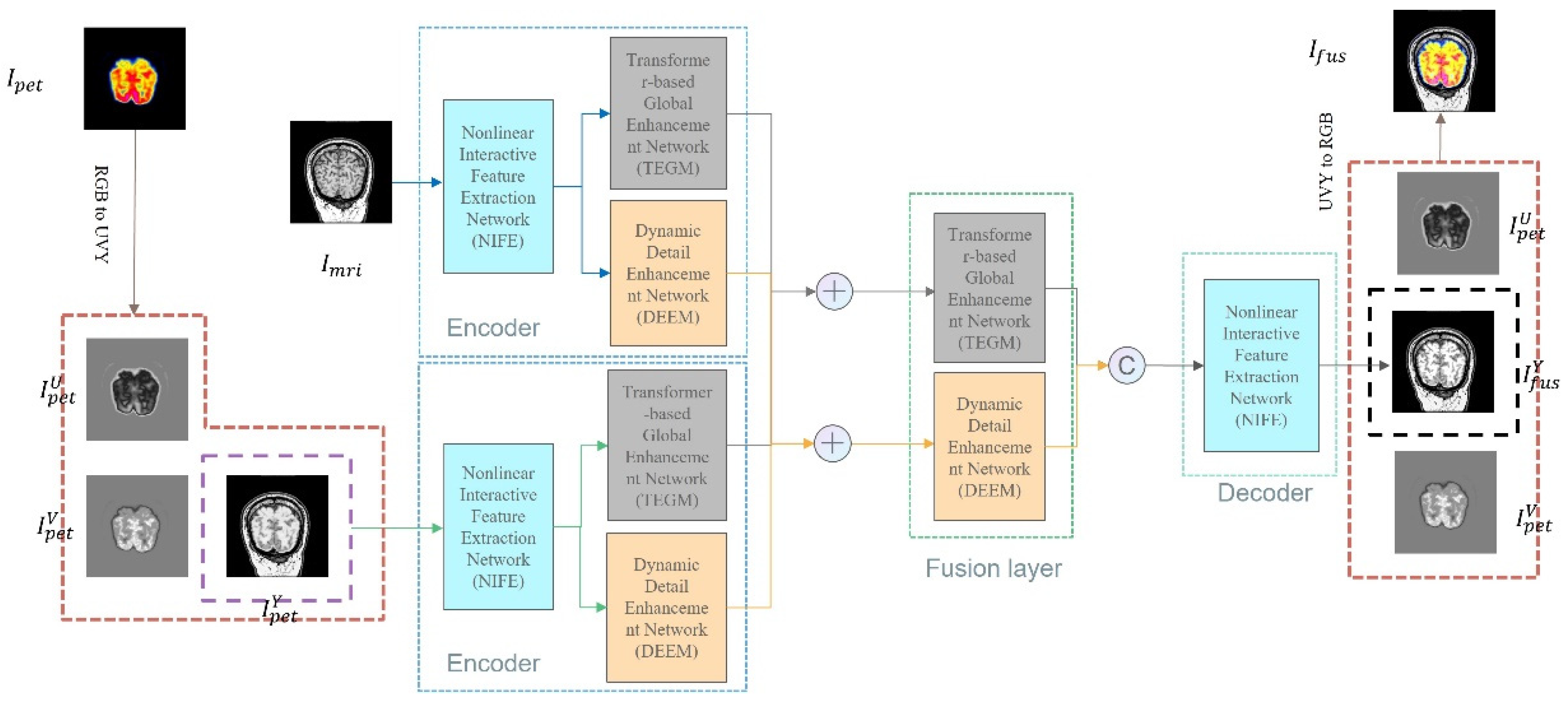
3. PPMF-Net Fusion Network Architecture Design
3.1. Progressive Parallel Fusion Strategy
3.2. Hierarchical Heterogeneous Feature Fusion Architecture
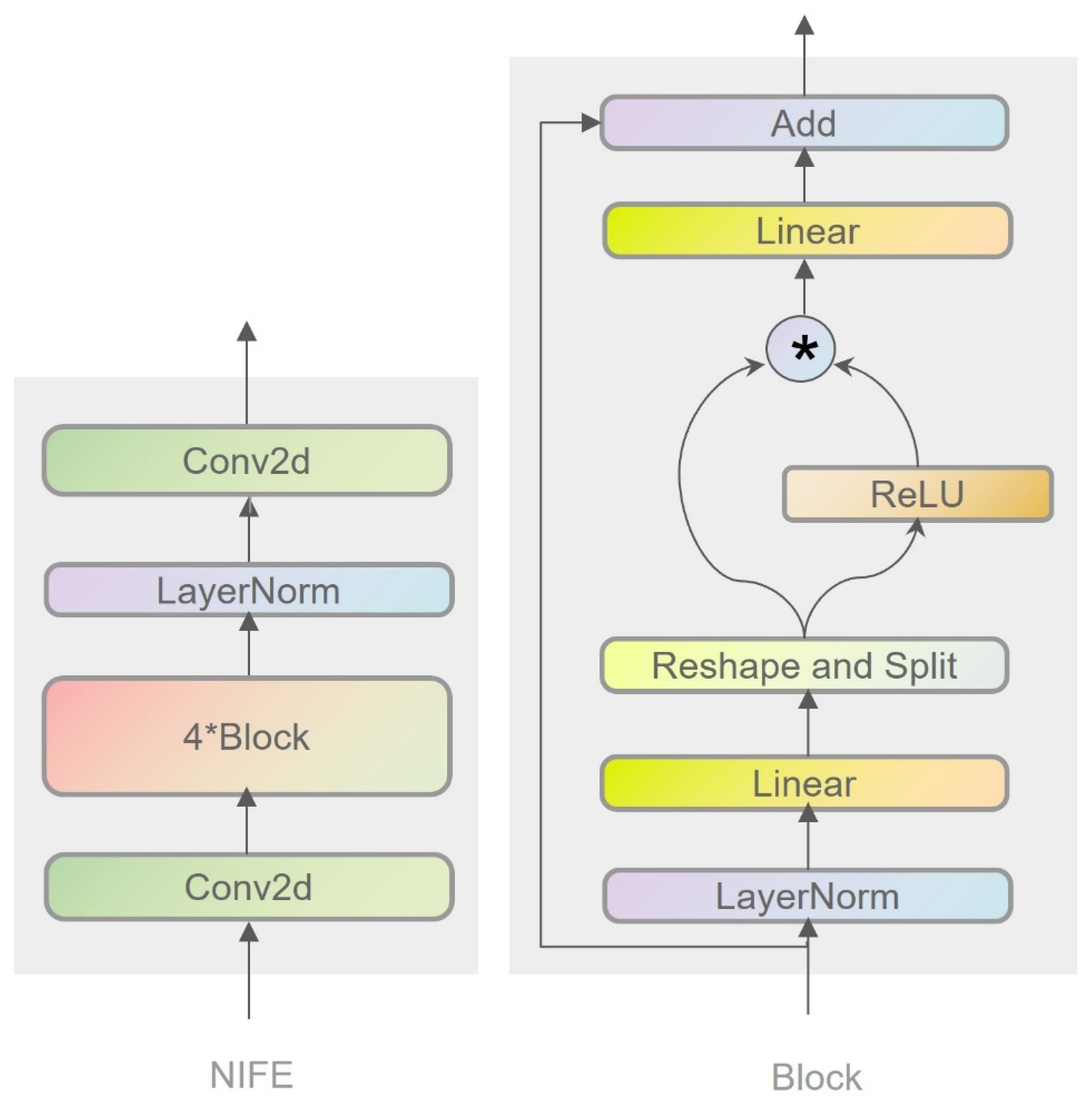
3.2.1. Nonlinear Interactive Feature Extraction Module
- Feature transformation and activation: in the Block module, the input features are first normalized and linearly transformed, followed by nonlinear processing through an activation function (e.g., ReLU).
- 2.
- Feature fusion: next, element-wise multiplication is employed to fuse the transformed features with the original input features.
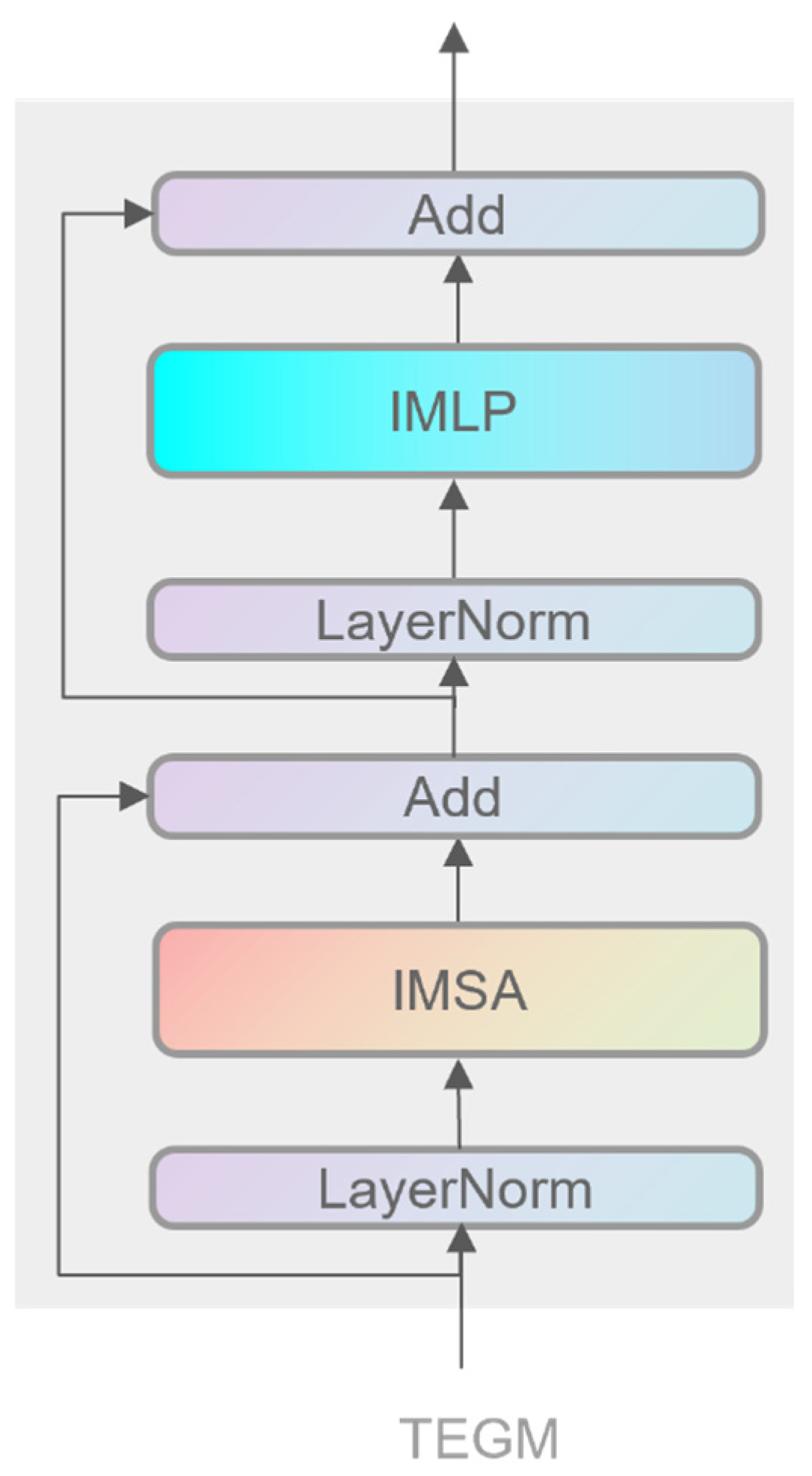
3.2.2. Transformer-Enhanced Global Modeling Module
- Residual and attention output computation: First, the input features are processed via an improved multilayer perceptron (MLP) and an improved multi-head self-attention (IMSA) mechanism. Assuming the input features are denoted as INIFE (i.e., output from the NIFE module), the process can be expressed as:
- 2.
- Generation of final output features: subsequently, the computed attention output is fused with the original input to produce the final feature output:
3.2.3. Dynamic Edge-Enhanced Module
- Convolution and shuffling: represents the output features of the DEEM. It is the enhanced result obtained by dividing the input features from NIFE () into groups and feeding them into three sequentially connected Block modules for processing.
- 2.
- Core inverted residual block and expansion: is input into a new inverted residual block and expansion operations—such as channel expansion, feature amplification, or attention weighting— are applied to obtain the enhanced intermediate feature , which is used to further improve detail preservation.
- 3.
- Multiplicative and additive operations with SE block: First, the Squeeze-and-Excitation (SE) attention module is applied to Y1 to obtain the channel weights. Then, element-wise multiplication between the weighted result and the expanded feature is performed, and this is fused with the residual path of to obtain the output feature .
3.3. Multimodal Image Fusion Optimization Loss
3.3.1. Functional Loss
3.3.2. Structural Loss
3.3.3. Detail Loss
3.4. Model Training
4. Experiment and Analysis
4.1. Datasets and Preprocessing
4.2. Comparison Method and Evaluation Index
4.2.1. Comparison Method
4.2.2. Evaluation Index
- Spatial Frequency (SF)
- 2.
- Standard Deviation (SD)
- 3.
- Correlation Coefficient (CC)
- 4.
- Spatial Correlation Degree (SCD)
- 5.
- Structural Similarity Index (SSIM)
- 6.
- Multi-scale Structural Similarity Index (MS-SSIM)
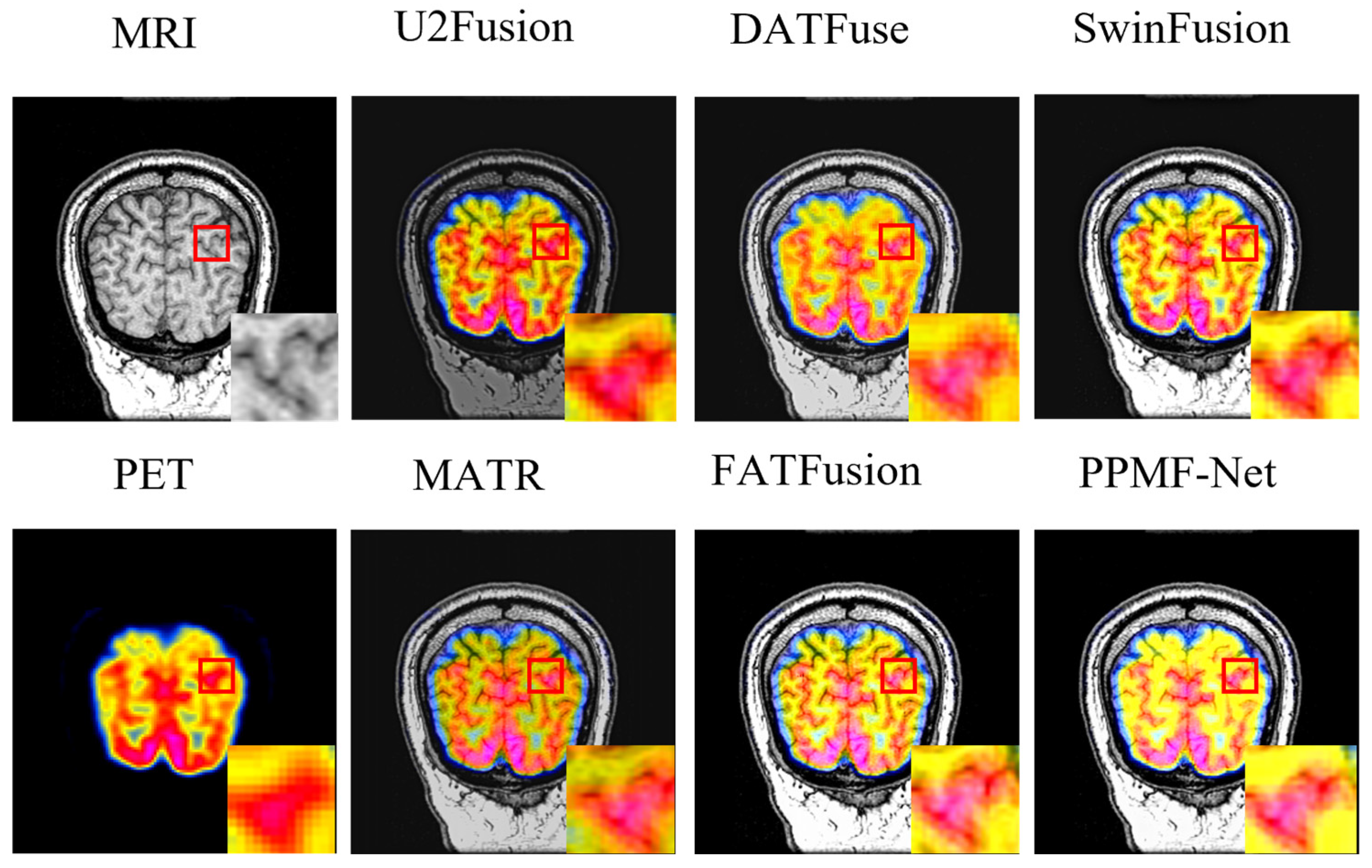
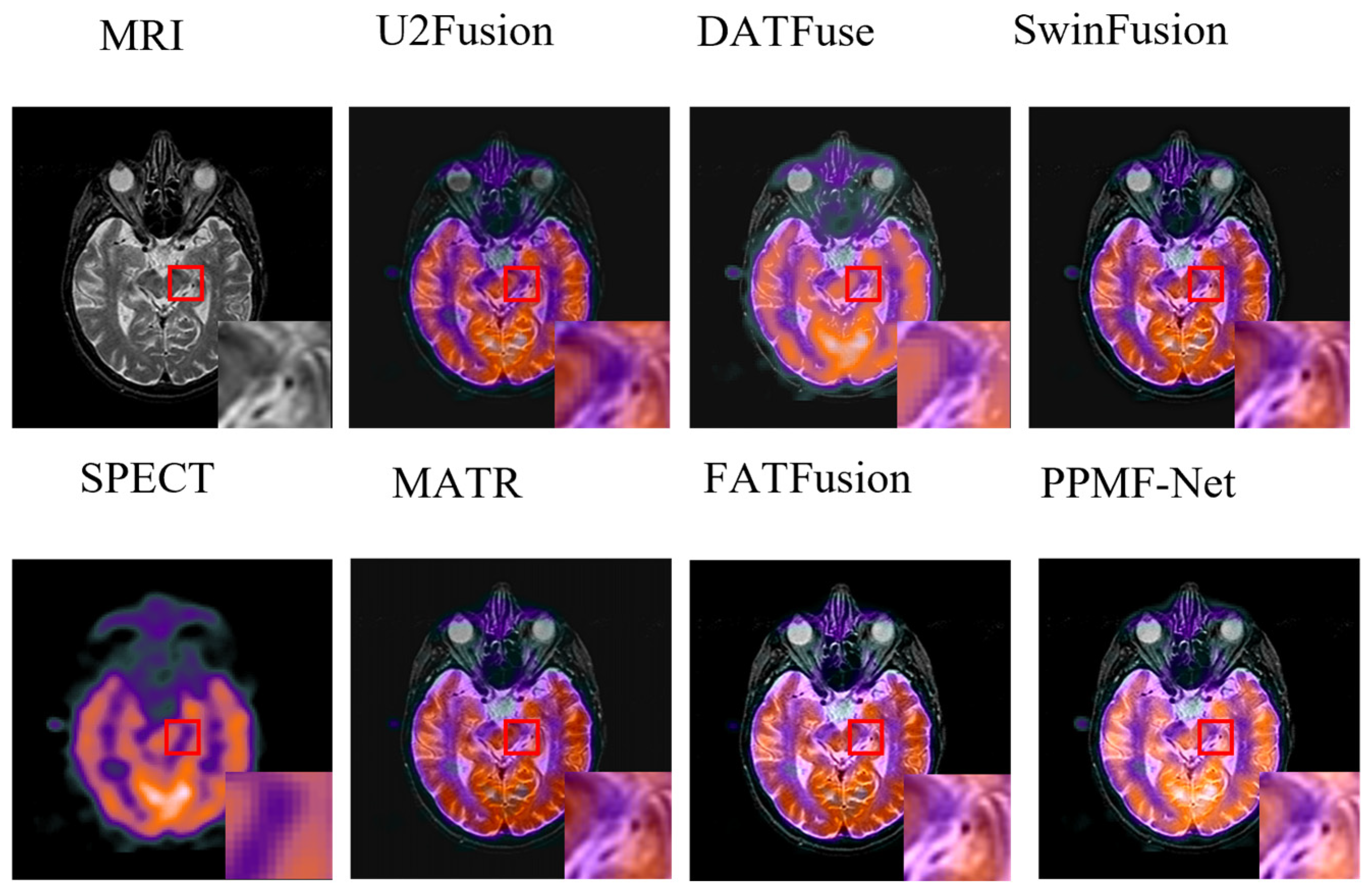
4.3. Fusion Comparison Experiment and Result Analysis
- Quantitative analysis
- 2.
- Fusion image analysis
4.4. Model Generalization Verification
- Quantitative analysis
- 2.
- Fusion image analysis
4.5. Ablation Experiment
4.5.1. Module Performance Analysis
- Setup of the module validity verification experiment
- 2.
- Quantitative analysis of the module component ablation experiment
4.5.2. Loss Function Analysis
- Validity verification experiment of the loss function
- 2.
- Quantitative analysis of the loss function ablation experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; van der Laak, J.A.W.M.; van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Manjunath, B.S.; Mitra, S.K. Multisensor image fusion using the wavelet transform. Graph. Models Image Process. 1995, 57, 235–245. [Google Scholar] [CrossRef]
- James, A.P.; Dasarathy, B.V. Medical image fusion: A survey of the state of the art. Inf. Fusion 2014, 19, 4–19. [Google Scholar] [CrossRef]
- Hsieh, J. Computed Tomography: Principles, Design, Artifacts, and Recent Advances; The international Society for Optical Engineering: Bellingham, WA, USA, 2003. [Google Scholar]
- Westbrook; Talbot, J. MRI in Practice; John Wiley & Sons: Hoboken, NJ, USA, 2018. [Google Scholar]
- Cabello, J.; Ziegler, S.I. Advances in PET/MR instrumentation and image reconstruction. Br. J. Radiol. 2018, 91, 20160363. [Google Scholar] [CrossRef]
- Nagamatsu, M.; Maste, P.; Tanaka, M.; Fujiwara, Y.; Arataki, S.; Yamauchi, T.; Takeshita, Y.; Takamoto, R.; Torigoe, T.; Tanaka, M.; et al. Usefulness of 3D CT/MRI Fusion Imaging for the Evaluation of Lumbar Disc Herniation and Kambin’s Triangle. Diagnostics 2022, 12, 956. [Google Scholar] [CrossRef]
- Catana, C.; Drzezga, A.; Heiss, W.D.; Rosen, B.R. PET/MRI for neurologic applications. J. Nucl. Med. 2012, 53, 1916–1925. [Google Scholar] [CrossRef]
- Ljungberg, M.; Pretorius, P.H. SPECT/CT: An update on technological developments and clinical applications. Br. J. Radiol. 2018, 91, 20160402. [Google Scholar] [CrossRef]
- Li, C.; Zhu, A. Application of image fusion in diagnosis and treatment of liver cancer. Appl. Sci. 2020, 10, 1171. [Google Scholar] [CrossRef]
- Pajares, G.; De La Cruz, J.M. A wavelet-based image fusion tutorial. Pattern Recognit. 2004, 37, 1855–1872. [Google Scholar] [CrossRef]
- Zitova, B.; Flusser, J. Image registration methods: A survey. Image Vis. Comput. 2003, 21, 977–1000. [Google Scholar] [CrossRef]
- Ma, J.; Yu, W.; Liang, P.; Li, C.; Jiang, J. FusionGAN: A generative adversarial network for infrared and visible image fusion. Inf. Fusion 2019, 48, 11–26. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–Miccai 2015: 18th International Conference, Munich, Germany, 5–9 October; Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Bhatnagar, G.; Wu, Q.J.; Liu, Z. Directive contrast based multimodal medical image fusion in NSCT domain. IEEE Trans. Multimed. 2013, 15, 1014–1024. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the Ieee Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Li, H.; Wu, X.J. DenseFuse: A fusion approach to infrared and visible images. IEEE Trans. Image Process. 2018, 28, 2614–2623. [Google Scholar] [CrossRef]
- Ma, J.; Xu, H.; Jiang, J.; Mei, X.; Zhang, X.P. DDcGAN: A dual-discriminator conditional generative adversarial network for multi-resolution image fusion. IEEE Trans. Image Process. 2020, 29, 4980–4995. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021. [Google Scholar]
- Dai, Y.; Gao, Y.; Liu, F. TransMed: Transformers advance multi-modal medical image classification. Diagnostics 2021, 11, 1384. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, Y.; Sun, P. TransFuse: Fusing transformers and CNNs for medical image segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—Miccai 2021: 24th International Conference, Strasbourg, France, 27 September–1 October 2021; Springer International Publishing: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Liu, Y.; Zhang, Y.; Wang, J. Multi-branch CNN and grouping cascade attention for medical image classification. IEEE Trans. Med. Imaging 2021, 40, 2585–2595. [Google Scholar] [CrossRef]
- Sonka, M.; Hlavac, V.; Boyle, R. Image Processing, Analysis and Machine Vision; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Tang, W.; He, F.; Liu, Y.; Duan, Y.; Si, T. DATFuse: Infrared and visible image fusion via dual attention transformer. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 3159–3172. [Google Scholar] [CrossRef]
- Tang, W.; He, F.; Liu, Y.; Duan, Y. MATR: Multimodal medical image fusion via multiscale adaptive transformer. IEEE Trans. Image Process. 2022, 31, 5134–5149. [Google Scholar] [CrossRef]
- Ma, J.; Tang, L.; Fan, F.; Huang, J.; Mei, X.; Ma, Y. SwinFusion: Cross-domain long-range learning for general image fusion via swin transformer. IEEE/CAA J. Autom. Sin. 2022, 9, 1200–1217. [Google Scholar] [CrossRef]
- Tang, W.; He, F. FATFusion: A functional–anatomical transformer for medical image fusion. Inf. Process. Manag. 2024, 61, 103687. [Google Scholar] [CrossRef]
- Ma, X.; Dai, X.; Bai, Y.; Wang, Y.; Fu, Y. Rewrite the stars. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, the Seattle Convention Center, Nashville, TN, USA, 17–21 June 2024; pp. 5694–5703. [Google Scholar]
- Zhao, Z.; Bai, H.; Zhang, J.; Zhang, Y.; Xu, S.; Lin, Z.; Timofte, R.; Van Gool, L. Cddfuse: Correlation-driven dual-branch feature decomposition for multi-modality image fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada; 2023; pp. 5906–5916. [Google Scholar]
- Liu, J.; Li, X.; Wang, Z.; Jiang, Z.; Zhong, W.; Fan, W.; Xu, B. PromptFusion: Harmonized semantic prompt learning for infrared and visible image fusion. IEEE/CAA J. Autom. Sin. 2025, 12, 502–515. [Google Scholar] [CrossRef]
- Liu, J.; Lin, R.; Wu, G.; Liu, R.; Luo, Z.; Fan, X. Coconet: Coupled contrastive learning network with multi-level feature ensemble for multi-modality image fusion. Int. J. Comput. Vis. 2024, 132, 1748–1775. [Google Scholar] [CrossRef]
- Liu, J.Y.; Wu, G.; Liu, Z.; Wang, D.; Jiang, Z.; Ma, L.; Zhong, W.; Fan, X. Infrared and visible image fusion: From data compatibility to task adaption. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 47, 2349–2369. [Google Scholar] [CrossRef]
- Ashish, V. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, I60. [Google Scholar]
- Eskicioglu, A.M.; Fisher, P.S. Image quality measures and their performance. IEEE Trans. Commun. 1995, 43, 2959–2965. [Google Scholar] [CrossRef]
- Howard, A.G. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, the Calvin L. Rampton Salt Palace Convention Center, Salt Lake City, UT, USA; 2018; pp. 4510–4520. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA; 2018; pp. 7132–7141. [Google Scholar]
- Bovik, A.C. Handbook of Image and Video Processing; Academic Press: Amsterdam, The Netherlands, 2010. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Zaremba, W.; Sutskever, I. Learning to execute. arXiv 2014, arXiv:1410.4615. [Google Scholar]
- Loshchilov, I. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Xu, H.; Ma, J.; Jiang, J.; Guo, X.; Ling, H. U2Fusion: A unified unsupervised image fusion network. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 502–518. [Google Scholar] [CrossRef]
- JÄHNE, B. Digital Image Processing; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- JAIN, A.K. Fundamentals of Digital Image Processing; Prentice-Hall, Inc.: Hoboken, NJ, USA, 1989. [Google Scholar]
- Wang, Z.; Simoncelli, E.P.; Bovik, A.C. Multiscale structural similarity for image quality assessment. In Proceedings of the Thrity-Seventh Asilomar Conference on Signals, Pacific Grove, CA, USA, 9–12 November 2003; Volume 2, pp. 1398–1402. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metrics | SF | SD | CC | SCD | SSIM | MS-SSIM |
|---|---|---|---|---|---|---|
| U2Fusion | 20.039 | 58.149 | 0.859 | 0.535 | 0.574 | 1.16 |
| DATFuse | 31.284 | 76.463 | 0.812 | 0.958 | 0.659 | 1.166 |
| MATR | 27.211 | 67.55 | 0.778 | 0.181 | 0.652 | 1.133 |
| SwinFusion | 34.877 | 85.013 | 0.81 | 1.395 | 0.706 | 1.226 |
| FATFusion | 37.321 | 90.466 | 0.778 | 1.336 | 1.175 | 1.19 |
| PPMF-Net | 38.2661 | 96.554 | 0.81725 | 1.61505 | 1.14395 | 1.229 |
| Metrics | SF | SD | CC | SCD | SSIM | MS-SSIM |
|---|---|---|---|---|---|---|
| U2Fusion | 14.206 | 39.536 | 0.888 | 0.068 | 0.527 | 1.194 |
| DATFuse | 18.85 | 56.197 | 0.878 | 0.998 | 0.543 | 1.182 |
| MATR | 18.396 | 50.609 | 0.842 | −0.006 | 0.551 | 0.981 |
| SwinFusion | 22.085 | 56.129 | 0.85 | 1.395 | 0.022 | 0.612 |
| FATFusion | 24.581 | 68.375 | 0.847 | 1.509 | 1.158 | 1.108 |
| PPMF-Net | 22.98 | 72.483 | 0.885 | 1.802 | 1.201 | 1.275 |
| Metrics | SF | SD | CC | SCD | SSIM | MS-SSIM |
|---|---|---|---|---|---|---|
| U2Fusion | 20.277 | 48.199 | 0.817 | 0.579 | 0.508 | 0.972 |
| DATFuse | 32.13 | 69.766 | 0.792 | 1.176 | 0.464 | 0.875 |
| MATR | 18.389 | 50.548 | 0.695 | −0.17 | 0.491 | 0.895 |
| SwinFusion | 27.031 | 67.071 | 0.805 | 1.197 | 0.539 | 0.924 |
| FATFusion | 26.071 | 69.634 | 0.709 | 0.937 | 1.266 | 0.97 |
| PPMF-Net | 30.641 | 89.542 | 0.816 | 1.735 | 1.284 | 1.03 |
| Metrics | SF | SD | CC | SCD | SSIM | MS-SSIM |
|---|---|---|---|---|---|---|
| ɑ1 | 38.43 | 91.345 | 0.782 | 1.235 | 1.134 | 1.211 |
| ɑ2 | 36.723 | 88.898 | 0.788 | 1.237 | 1.145 | 1.217 |
| ɑ3 | 38.295 | 90.998 | 0.789 | 1.328 | 1.21 | 1.236 |
| PPMF-Net | 38.2661 | 96.6941 | 0.81725 | 1.61505 | 1.14395 | 1.2299 |
| Metrics | SF | SD | CC | SCD | SSIM | MS-SSIM |
|---|---|---|---|---|---|---|
| β1 | 11.275 | 83.916 | 0.777 | 1.02 | 0.351 | 1.045 |
| β2 | 20.001 | 85.688 | 0.799 | 1.164 | 0.559 | 1.109 |
| β3 | 13.615 | 71.276 | 0.78 | 0.697 | 1.002 | 1.132 |
| PPMF-Net | 38.2661 | 96.6941 | 0.81725 | 1.61505 | 1.14395 | 1.2299 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, P.; Luo, Y. Multimodal Medical Image Fusion Using a Progressive Parallel Strategy Based on Deep Learning. Electronics 2025, 14, 2266. https://doi.org/10.3390/electronics14112266
Peng P, Luo Y. Multimodal Medical Image Fusion Using a Progressive Parallel Strategy Based on Deep Learning. Electronics. 2025; 14(11):2266. https://doi.org/10.3390/electronics14112266
Chicago/Turabian StylePeng, Peng, and Yaohua Luo. 2025. "Multimodal Medical Image Fusion Using a Progressive Parallel Strategy Based on Deep Learning" Electronics 14, no. 11: 2266. https://doi.org/10.3390/electronics14112266
APA StylePeng, P., & Luo, Y. (2025). Multimodal Medical Image Fusion Using a Progressive Parallel Strategy Based on Deep Learning. Electronics, 14(11), 2266. https://doi.org/10.3390/electronics14112266