The refinement network adopts a generator structure similar to Vanilla GAN, with the proposed MPD layers replacing the standard convolutional layers. As shown in
Figure 1, a random variable
z of size 256 serves as the input to the refinement network. After passing through a fully connected layer, six MPD modules and an activation function, it outputs the refined result
Iout. Additionally, an attention layer is applied after the fourth MPD module.
3.2.1. MPD Module
Current image inpainting tasks under large masks require the inpainting results to be both structurally reasonable and diverse. The SPADE module can modulate random vectors using semantic information to generate diverse outputs. However, it lacks a large receptive field to capture global texture and structural features. Complementarily, the DMFB module can expand the receptive field. Therefore, we design the MPD module by integrating the DMFB module with an improved SPADE module. After receiving the feature maps from the upper network, the MPD module first passes them to the improved SPADE module. The improved SPADE module utilizes the prior information
P to guide the diverse generation of the image. Then, it passes to the DMFB module to control the overall features. The MPD module is shown in
Figure 2.
We make improvements to SPADE, utilizing the similar idea of PDGAN, as the patterns closer to the edges of the masked area have a greater correlation with the surrounding pattern information. Therefore, when generating the image within the mask, we hope that closer to the edge of the mask, the generated content will be more fixed. Conversely, we hope for more freedom for the generated content which is closer to the center. To this end, a probabilistic diversity mapping is incorporated into the SPADE module to control the modulation strength of the prior information
P on the input
Fin. And it is jointly controlled with the two variables,
γ and
β, and output by the convolutional layer. The improved SPADE module consists of hard SPDNE and soft SPDNE, controlled by probabilistic diversity mappings
Dh and
Ds, respectively. The structure is shown in
Figure 2.
The hard SPADE module was designed with its probability map
Dh calculated based on the distance to the edge of the mask
M. The iterative calculation formula can be expressed as
where
N(x, y) represents the 3 × 3 neighborhood centered at position
(x, y).
Mi represents the probability map obtained after the
i-th iteration. The known pixels are assigned as 1. With each iteration, the probability map shrinks inward (
Mi −
Mi−1). And this region is assigned as
1/ki. Thus, the probability closer to 0 is achieved when it is closer to the center of the mask.
Dh is only related to the mask but ignores the overall structural features. To address this issue, soft SPDNE is used as a complement. Soft SPDNE can dynamically learn global structural features of prior information and stabilize training. The probabilistic diversity mapping
Ds of soft SPDNE is obtained by extracting features from Fin and the prior information
P using a trainable network, which can be represented as
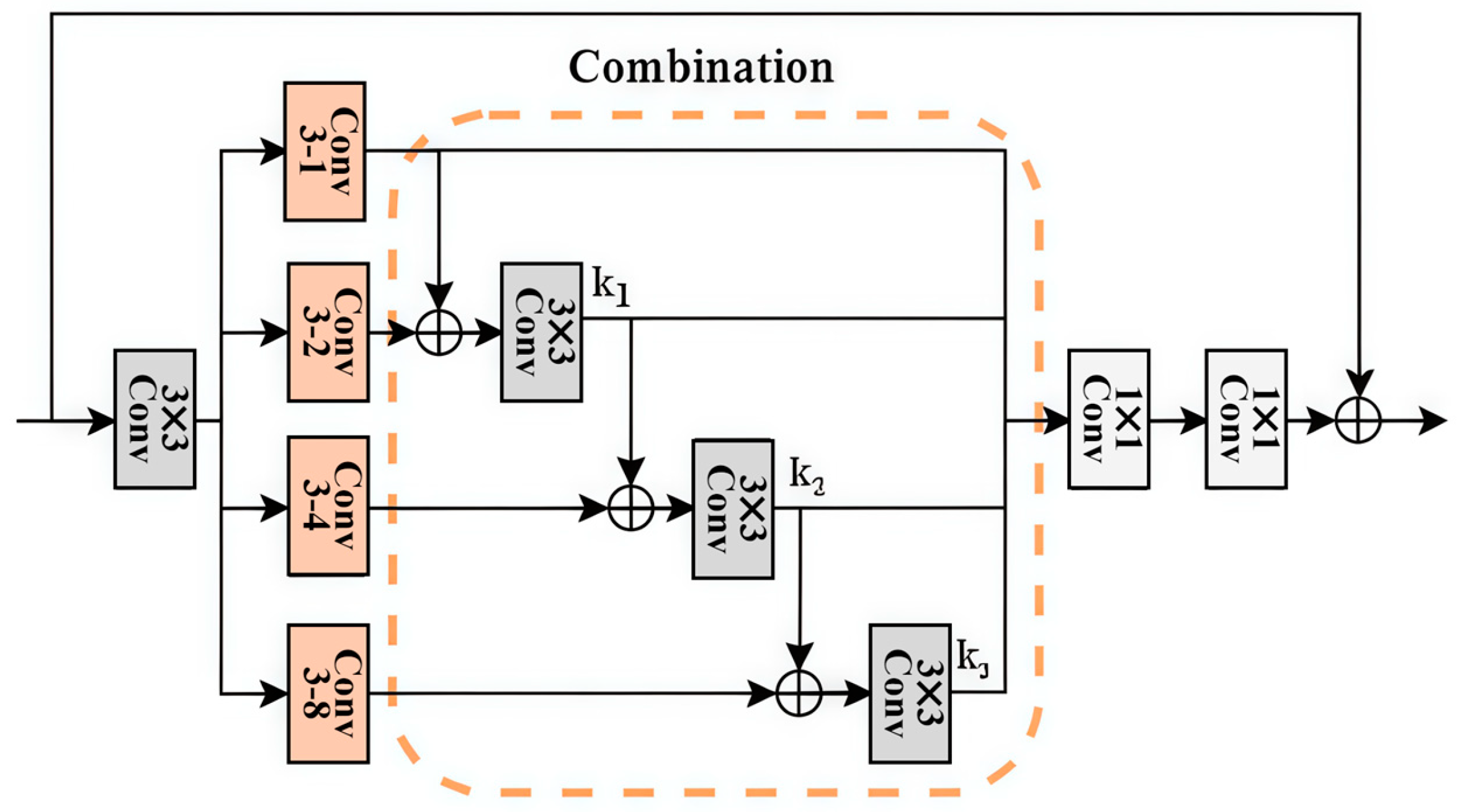
After passing through the improved SPADE module, the generated results are more diverse. However, there is still insufficient control over global information, leading to the generation of unreasonable structural features and textural details. To address this issue, a sufficiently large effective receptive field is needed to capture enough overall image information. Dilated convolutions can expand the receptive field, but their sparse kernels skip many effective pixels during computation. Using large kernel convolutions with dense kernels [
22] will introduce a large number of parameters, slowing down the network training. To expand the effective receptive field while minimizing the introduction of numerous parameters, the DMFB module is integrated into the improved SPDNE module to form the MPD module. The structure of the DMFB module is shown in
Figure 3.
Dilated convolution increases the effective size of the convolution kernel by inserting a fixed number of spaces, known as the expansion factor, into the kernel. The convolution kernel is thus able to cover a larger input area and capture a wider range of contextual information. Dilated convolution adds a key parameter compared to ordinary convolution: the dilation rate. The dilation rate affects the number of spaces inserted into the convolution kernel. When the dilation rate is 1, it is the same as ordinary convolution. When the dilation rate is 2, every two pieces of data in the convolutional kernel are separated by a column of zeros. When dilated convolutions with different expansion coefficients are used consecutively, more pixels can be utilized with the same calculation parameters. Therefore, the network uses four dilated convolutions with different expansion coefficients and superimposes them to form a dense multi-scale fusion block DMFB of dilated convolution.
The input features are extracted by dilated convolutions with different dilation rates to obtain multi-scale features. Then, they are fused. We incorporate the DMFB module into the soft SPADE module, replacing the standard convolutional layers. This further enhances the soft SPADE module’s ability to capture global features. Additionally, we integrate the DBFM module after the improved SPADE modules and design a residual structure. The input feature map is added to the output feature map from the MPD module, which stabilizes the training process. This process can be expressed as
3.2.2. Attention Module
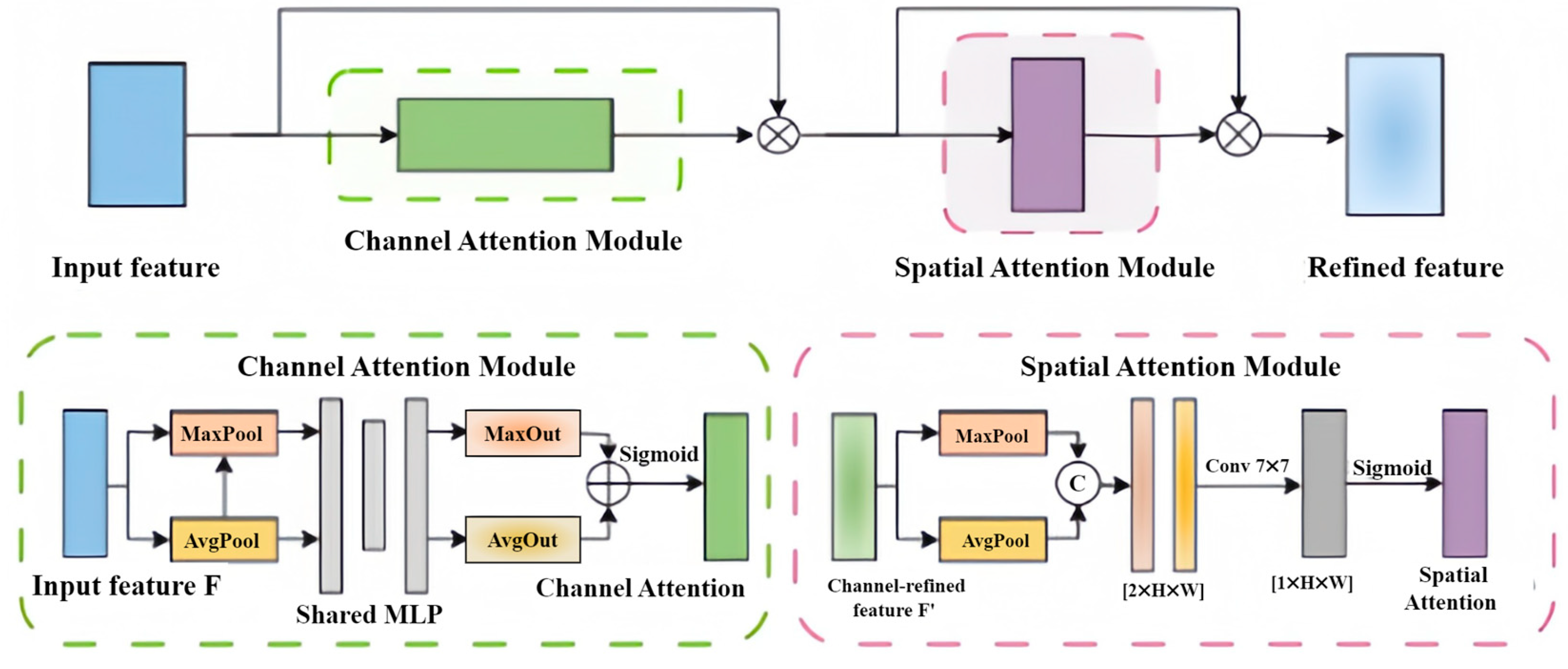
To enhance the network’s ability to represent the overall structure and texture of an image, a CBAM attention module is introduced. The CBAM attention module was introduced into the refinement network to emphasize key information. It cascades a channel attention module (CAM) and a spatial attention module (SAM) [
11]. The channel attention focuses on the relationships between feature map channels. The spatial attention operates on pixel regions to complement the channel attention. The structure is shown in
Figure 4.
The feature maps passed through the generator network, and then were fed into the attention module. In the attention module, the feature attention maps are derived sequentially along two independent dimensions: channel dimensions and spatial dimensions. Channel attention suppresses irrelevant semantic channels and enhances target channels, ensuring the semantic plausibility of generated content. Spatial attention focuses on key regions such as mask edges, guiding the network to prioritize repairing structural boundaries and improving the continuity of local details. Their synergistic effect enables MD-GAN to maintain global structural consistency while refining local textures in large-mask inpainting. These feature attention maps are then multiplied with the input feature maps to refine the features. Ablation experiments demonstrate that the addition of the CBAM attention module significantly improves the visual performance of the results. Our experiments show that when it is added after the fourth MPD module in the refinement network, the results are the best.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}