1. Introduction
With the widespread adoption of traffic surveillance systems, vehicle detection has become a critical technology for intelligent traffic management and road safety, playing a pivotal role in fields such as autonomous vehicle tracking and intelligent traffic signal control [
1]. Accurate vehicle detection serves as the foundation for autonomous navigation and obstacle avoidance systems, directly impacting driving safety and the level of vehicular intelligence [
2]. However, despite significant advancements in computer vision and deep learning technologies, vehicle detection still faces numerous challenges [
3]. In complex environments, variations in vehicle shape and scale make detection particularly difficult. Additionally, factors such as occlusion often lead to small-target vehicles being overlooked or misidentified, resulting in delayed responses or erroneous judgments. These issues not only threaten road safety but also increase the complexity of traffic management, adversely affecting urban traffic efficiency and the overall level of intelligent transportation systems. These persistent challenges—particularly the struggles with scale variation and occluded small targets—have urgently driven the development of new detection technologies.
To overcome the abovementioned technical bottlenecks, automated detection methods based on deep learning have rapidly emerged in recent years. Models represented by Convolutional Neural Networks (CNNs) [
4] and the You Only Look Once (YOLO) [
5,
6,
7,
8,
9] series have opened up new paths for vehicle detection. In 2024, Shuqin Huang et al. [
10] proposed a detection algorithm based on the improved Faster Region-based Convolutional Neural Network (Faster R-CNN), which optimizes semantic feature balance through the Balanced Feature Pyramid (BFP) module, dynamically adjusts label thresholds via the Dynamic Label Assignment (DLA) strategy, and improves target suppression by integrating Soft Non-Maximum Suppression (Soft-NMS), significantly enhancing detection accuracy. However, constrained by the inherent limitations of the two-stage detection architecture, its lengthy candidate box generation and feature processing pipeline lead to a real-time performance that struggles to meet the demands of high-speed scenarios. In the Transformer-related research, Lv Xiaohan et al. [
11] designed a photovoltaic cell defect-detection model based on an improved Vision Transformer (ViT), which extracts multi-scale features through a 12-layer convolutional residual network and feature pyramid before feeding them into the Transformer. The Transformer structure’s high computational complexity limits detection speed. Zhao et al. [
12] improved YOLOv5s by replacing its CSPDarknet backbone network with Swin-Transformer, but the self-attention mechanism in the model increases computational costs, affecting the real-time performance. Although these models have achieved phased results, they also reveal a critical contradiction between algorithm efficiency and performance, prompting researchers to focus on the new direction of the collaborative optimization of detection capabilities and real-time performance.
Following this line of thought, attempts have been made to break through performance ceilings via feature enhancement techniques based on the YOLO algorithm. In 2023, Ding Q et al. employed the YOLOv5 model [
13], enhancing feature fusion through the introduction of the Focus structure and Cross Stage Partial (CSP) architecture. By incorporating the Generalized Intersection over Union (GIoU) loss function, the model achieved improved detection accuracy and convergence stability. Nevertheless, it exhibits limitations in small-object detection within complex scenarios. The RES-YOLO detection algorithm proposed by Wang et al. [
14] in 2022 effectively reduces missed detection rates in multi-vehicle scenarios and enhances model stability in dynamic environments through novel feature extraction and target localization methods. However, this algorithm is prone to localization deviations when handling scenarios with drastic target scale changes. The RO-YOLOv9 algorithm proposed by Liao et al. [
15] in 2025 optimizes multi-scale feature fusion by introducing a dedicated small-target detection layer and a Bidirectional and Adaptive Scale Fusion Feature Pyramid Network (BiASF-FPN). However, with a large number of parameters, its computational efficiency decreases, posing deployment challenges on devices with limited hardware resources. These efforts demonstrate that while feature enhancement strategies significantly boost the baseline algorithm performance, complex and variable application scenarios impose higher requirements on algorithm adaptability—especially when dealing with targets of different scales and distributions, models lacking dynamic receptive field-adjustment mechanisms often struggle to fully unleash their detection potential.
This challenge is particularly prominent in small-target detection. The ShuffYOLOX detection model proposed by He et al. [
16] in 2023 replaces CSPDark53 with the ShuffDet feature extraction model, reducing the computational complexity while maintaining high accuracy, but it has low sensitivity to small targets and is prone to missed detections in occluded or dense scenarios. In the same year, Xin Shiao et al. [
17] improved the YOLOv7 model by introducing the ACmix hybrid attention module to enhance the semantic modeling of small-target features, but the model as a whole lacks an adaptive adjustment mechanism for multi-scale receptive fields. Wu Jiancheng et al.’s [
18] improved RES-YOLO algorithm performs well on the VisDrone dataset but suffers from significant decreases in small-target detection accuracy and increased missed detection rates in the face of dense target distributions or blurred conditions. The enhanced detection algorithm based on the YOLOv11 architecture proposed by Liu et al. [
19] in 2025 lacks adaptive receptive field-adjustment capabilities, making it difficult to accurately capture details in complex small-target scenarios and limiting detection accuracy. These dilemmas profoundly reveal that breaking through the challenges of occlusion and dense interference in small-target detection and constructing detection models with adaptive receptive field -adjustment capabilities have become critical breakthroughs for the practical application of vehicle detection technologies. These persistent issues in real-world applications—particularly the trade-offs between receptive field adaptability and detection accuracy—highlight the urgent need for innovative solutions.
Against this backdrop, in complex road scenarios, existing road vehicle detection algorithms often suffer from low recognition accuracy when handling small objects, and issues such as missed detections frequently occur due to occlusion and localization inaccuracies. To address these challenges, this paper proposes an improved YOLOX-based algorithm named V-YOLO. The main contributions are as follows:
First, we propose a novel Wavelet-Enhanced Convolution (WEC) module, which significantly enlarges the receptive field to enhance the network’s global perception capability. This enables the model to better capture and process extensive contextual information from input images, thereby improving its understanding and adaptability in complex scenes.
Second, we introduce the Simple Attention Mechanism (SimAM) module, which adaptively fuses semantic features across different channels and spatial locations. This enhances feature saturation and strengthens the network’s generalization ability for multi-scale objects, allowing more accurate recognition and localization of targets at varying scales.
Finally, we propose a new Varifocal Intersection over Union (VIoU) bounding-box regression loss function. This loss function optimizes the convergence of feature learning across different scales during regression, enabling the model to effectively extract global features. Consequently, it further improves the network’s performance in complex object detection tasks.
3. Improved YOLOX Algorithm
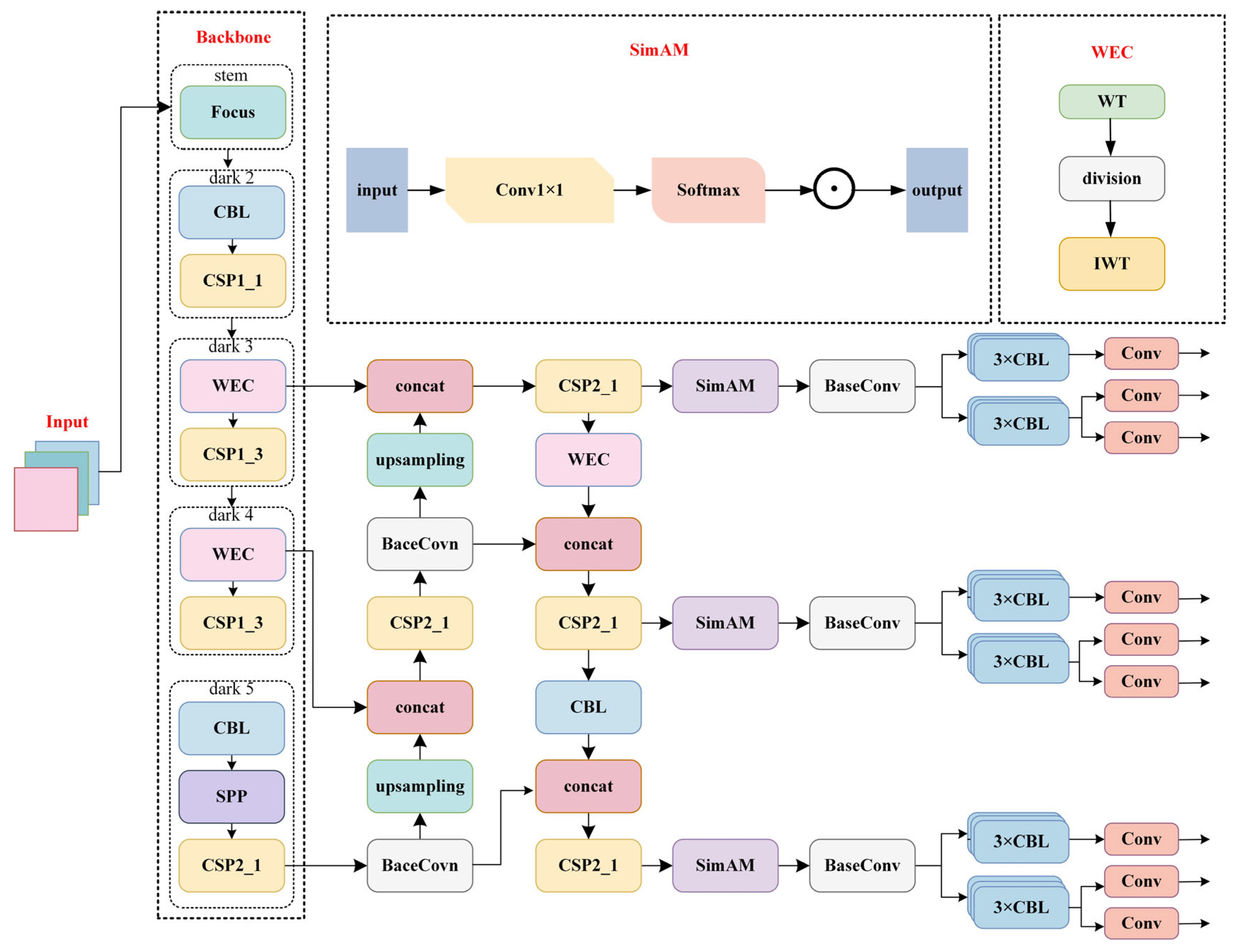
The architecture of the improved YOLOX network is shown in
Figure 2. Through multi-level optimization and innovative design, it demonstrates significant performance improvements in the field of object detection.
Specifically, the model incorporates the following key enhancements based on the original YOLOX architecture: First, prior to deep feature extraction, we introduce the WEC module, which expands the receptive field to enhance the model’s global perception capability. Second, we integrate the SimAM attention mechanism at the end of the feature pyramid network. This module adaptively fuses semantic features across different channels and spatial locations, improving feature saturation and thereby strengthening the network’s generalization ability for multi-scale objects. This enhancement enables a more accurate identification and localization of targets at varying scales. Finally, we propose a novel VIoU bounding-box regression loss function. This loss function optimizes the convergence of multi-scale feature learning during regression, enabling more stable training and the effective extraction of global features. Consequently, it further improves the network’s performance in complex object detection tasks.
3.1. Convolution Module
In deep neural networks with multiple downsampling layers, employing fixed-size convolutional kernels for single-scale convolution operations often fails to establish long-range pixel dependencies. This approach typically leads to the loss of both high-frequency textures and low-frequency structural information after successive downsampling operations, thereby constraining overall feature extraction and perceptual capabilities. In deep neural networks with multiple downsampling layers, employing fixed-size convolutional kernels for single-scale convolution operations often fails to establish long-range pixel dependencies. This approach typically leads to the loss of both high-frequency textures and low-frequency structural information after successive downsampling operations, thereby constraining overall feature extraction and perceptual capabilities.
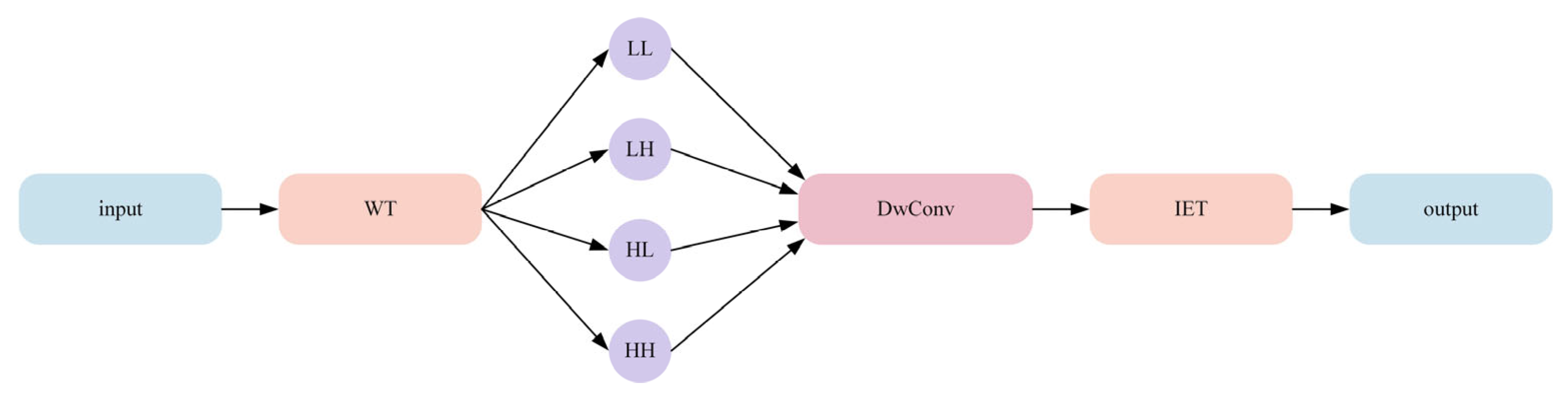
To enhance multi-scale and multi-frequency feature representation, this paper proposes a novel wavelet convolution module termed WEC, the structure is shown in
Figure 3. Specifically, we first perform a 2D Haar wavelet transform (WT) [
21] on the input feature map
, decomposing each channel into four sub-bands
. This operation can be mathematically expressed as Equation (1):
The sub-bands are denoted as follows: LL represents low-frequency components, LH captures vertical low-frequency features, HL contains horizontal high-frequency details, and HH encodes diagonal high-frequency information. WT(X) denotes the wavelet transform module, which performs wavelet transformation on the input feature map X. The module decomposes the features into four channels, each corresponding to characteristic information at different scales and orientations, thereby achieving multi-resolution feature analysis and enhancement.
Through this decomposition, each sub-band’s resolution is reduced to half of the original size, thereby explicitly separating global morphology from directional high-frequency details.
Following this decomposition, more targeted feature extraction is performed on each channel within the sub-band domain. To achieve this, depthwise convolution (
DwConv) combined with an attention mechanism (
Att) is applied to each sub-band to generate weighted outputs, as expressed in Equation (2):
Depthwise convolution (
DwConv) enables localized perception for each sub-band while maintaining the original resolution, while the attention mechanism further emphasizes important channels or spatial regions to better preserve both high-frequency textures and low-frequency structures. After obtaining these weighted sub-bands, they need to be restored to match the original input dimensions. This reconstruction is achieved through inverse wavelet transform (
IWT), which can be mathematically represented by Equation (3):
This yields the feature map after one complete decomposition–reconstruction cycle. Since each sub-band has undergone independent convolution and attention processing, the output effectively preserves both local textural details and global structural patterns.
After obtaining
, we perform a second wavelet transform to capture higher-level global dependencies at deeper network lavers or lower resolutions.
is then decomposed into four new sub-bands, which can be mathematically represented by Equation (4):
This enables the network to capture contextual information within an expanded receptive field, thereby enhancing holistic representation of target objects. Similarly, for the sub-bands obtained from the second decomposition, we apply identical depthwise convolution and attention operations, followed by inverse wavelet transform to reconstruct the original resolution, yielding the final output,
. This process can be mathematically formulated as Equation (5):
The multi-level wavelet processing enhances both the textural and structural information of targets across different scales and frequency bands.
In the final stage, the current output
is either summed or concatenated with the results generated from the first sub-band convolution attention process. This produces multi-level output feature maps, which can be mathematically represented by Equation (6):
Through iterative sub-band decomposition and hierarchical feature aggregation, the network effectively facilitates the interaction between high- and low-frequency information components. This architecture significantly improves the preservation of both local details and global semantic representations during downsampling operations, thereby providing more comprehensive feature representations for subsequent detection or recognition tasks.
3.2. SimAM Attention Mechanism
Traditional attention mechanisms demonstrate limited adaptive focus capability for critical features in complex scenes. To address this issue, we introduce the Simple Attention Module (SimAM) attention mechanism [
22]. As illustrated in
Figure 4, SimAM is a lightweight 3D attention module. Similar to attention mechanisms like ECA and SA, it can derive attention weights, but distinguishes itself by requiring no additional parameters. Unlike other attention mechanisms that focus solely on channel-wise or spatial importance, SimAM simultaneously considers correlations across both spatial positions and channel dimensions, implementing defined 3D attention weights [
23].
The SimAM mechanism achieves the co-existence of spatial and channel attention, enabling each neuron to be assigned a unique weight that enhances feature saturation in visual representations. Given that the spatial inhibition effects of neurons are crucial for localization tasks, these neurons should be prioritized. To accomplish this objective, we employ a straightforward approach that measures the linear separability between individual target neurons. Based on neuroscientific findings, each neuron is assigned an energy function incorporating binary labels and regularization terms. The final energy function can be expressed by the following equation:
In the equation,
denotes the input feature, and
represents the hyperparameter, where
corresponds to the number of neurons per channel calculated as the product of the feature map’s height and width. The terms
and
compute the mean and variance losses for all neurons within individual channels, with values determined by Equation (8) and Equation (9), respectively. Notably, a smaller
value indicates a greater distinction between neuron t and its neighboring neurons, with values determined by Equation (7), implying higher significance in visual processing. To suppress outliers in attention weights while enhancing feature representation, we employ a Sigmoid activation function to constrain the energy function’s range, as formally expressed in Equation (10):
In the equation, denotes the activation-enhanced output, represents the input feature, and indicates the dot product operation. This approach generates weight values for each neuron without introducing additional network parameters. This paper proposes replacing the original network with an attention-fused depthwise separable network. The proposed architecture employs depthwise convolution (DwConv) to reduce both model parameters and computational overhead, while integrating the SimAM attention module at the terminal of the feature pyramid to enhance both the representational capacity and receptive field of feature maps. Consequently, this design achieves improvements in both detection speed and accuracy while demonstrating strong robustness across various scales and scenarios.
3.3. VIoU Loss
The Complete IoU (CIoU) metric reduces sensitivity to bounding-box relative positions demonstrating better robustness for targets at different locations, shapes, and sizes. However, when the height and width of predicted boxes maintain a proportional but unequal relationship with ground-truth boxes, the normalized weight parameters become ineffective. The Efficient IoU (EIOU) addresses sample imbalance in bounding-box regression by focusing regression emphasis on high-quality anchors, thereby improving model convergence efficiency. Nevertheless, IoU-based metrics exhibit high sensitivity to target scales—under identical offset conditions, the IoU value of small objects decays significantly faster than large targets. Inspired by the Jaccard similarity coefficient, this study innovatively introduces Wasserstein distance as a similarity metric for small objects. This distance metric can stably reflect distribution differences even when targets have no spatial overlap. The experimental results demonstrate that the proposed Wasserstein-based metric outperforms traditional IoU in evaluating small objects’ similarity.
The Normalized Wasserstein Distance (NWD) method [
24] represents bounding boxes as 2D Gaussian distributions and calculates the similarity between predicted and ground-truth boxes through their corresponding Gaussian distributions. For any two target boxes, VIoU measures their relationship via the similarity of their Gaussian distributions. VIoU Loss is formally expressed in Equation (11):
where:
denotes the Wasserstein distance between predicted and ground-truth boxes;
and represent the 2D Gaussian distributions of predicted and ground-truth boxes, respectively;
indicates a constant term;
represents the Euclidean distance between the centroids of predicted bounding boxes and ground-truth boxes;
and specify the horizontal and vertical dimensions of the predicted box;
and define the horizontal and vertical dimensions of the minimum enclosing rectangle.
4. Experimental Design and Result Analysis
4.1. Experimental Design
The experiments were conducted on a Linux system equipped with an NVIDIA Tesla V100S PCle32GB GPU. We employed PyTorch 1.8.1 as the deep learning framework and CUDA 11.0 for training acceleration. The experimental parameters are as follows: training epochs: 200, image size: 640 × 640, learning rate momentum: 0.937, and batch size: 16.
The experiments utilized the VisDrone dataset [
25], a large-scale, autonomous driving dataset comprising real-world scene images from various environments, including urban areas, rural regions, and highways. This dataset is particularly valuable for training and evaluating object detection models. During training, the images were divided into training, validation, and test sets in a 7:1:2 ratio to ensure model effectiveness across different phases. Model performance was evaluated using the following metrics [
26]:
mAP50: Mean Average Precision with IoU threshold set at 50%.
mAP75: Mean Average Precision with IoU threshold set at 75%.
4.2. Ablation Experiment
This paper proposes three key improvements to YOLOX: (1) a novel Wavelet-Enhanced Convolution (WEC) module, (2) integration of the Simple Attention Module (SimAM) mechanism, and (3) a new Varifocal Intersection over Union (VIoU) bounding-box regression function. To systematically evaluate the contribution of each improvement, we conducted comprehensive ablation studies comparing the baseline YOLOX with progressively enhanced variants:
YOLOX_1: Baseline + WEC. YOLOX_2: Baseline + SimAM attention + WEC. YOLOX_3: Baseline + self-attention mechanism. YOLOX_4: Baseline + adaptive multi-scale attention. V-YOLO: Baseline + WEC + SimAM attention + VIoU loss function.
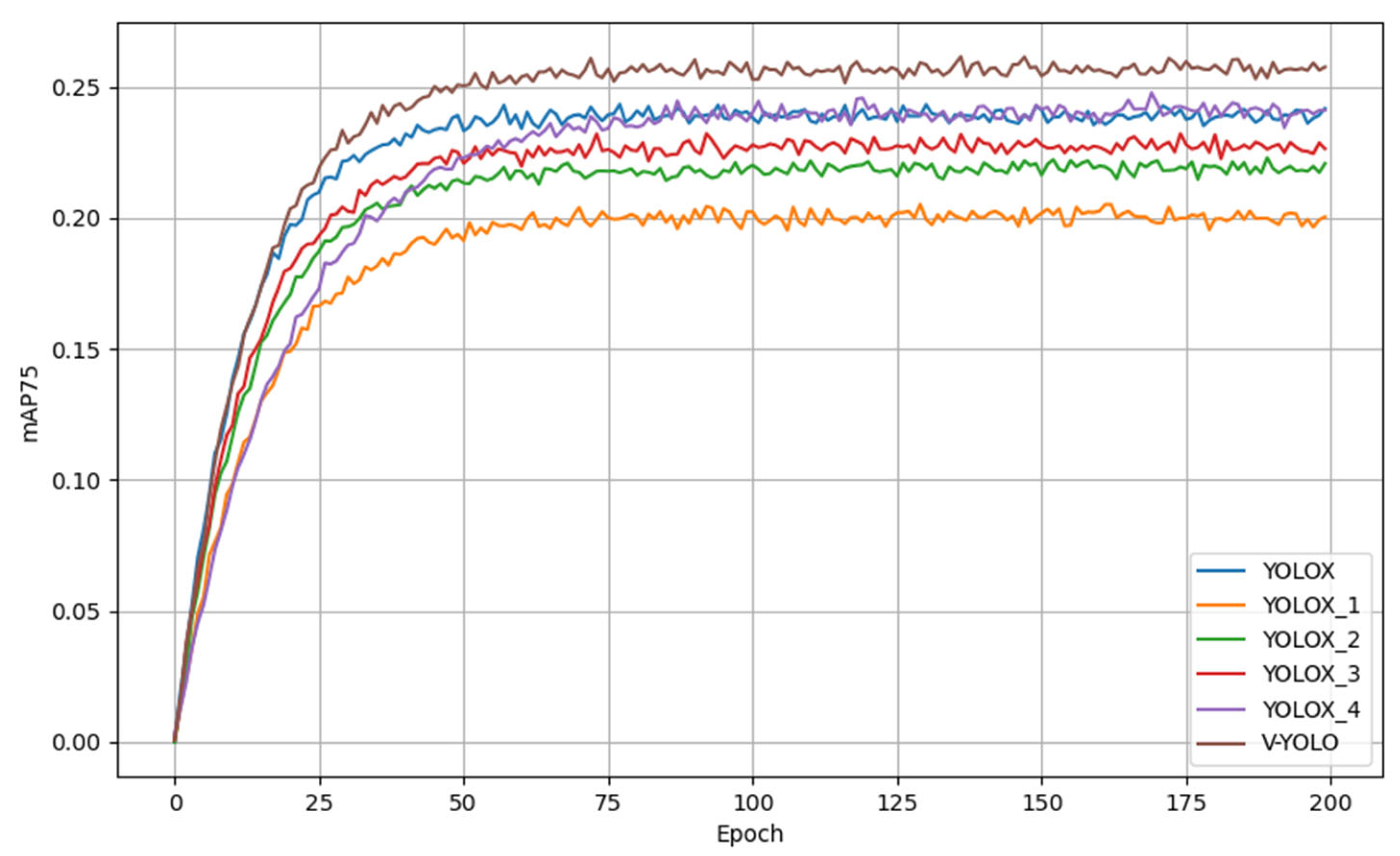
The experimental results, including quantitative metrics and comparative analyses, are presented in
Figure 5 and
Figure 6 and
Table 1.
Specifically, in this experiment, we trained six different models (YOLOX, YOLOX_1, YOLOX_2, YOLOX_3, YOLOX_4, and V-YOLO) and evaluated their performance on object detection tasks. By plotting the mAP50 and mAP75 curves across training epochs, we analyzed the convergence speed, final accuracy, and overall stability of different models. The mAP50 and mAP75 curves revealed distinct convergence rates among the models. Generally, most models achieved their primary performance improvements within the first 50 epochs and gradually stabilized thereafter. Notably, V-YOLO reached an mAP50 of approximately 0.4 during the early training stage (Epoch < 50), eventually stabilizing at 40.3% (mAP50) and 25.7% (mAP75). The YOLOX 1, YOLOX 2, and YOLOX 3 models exhibited slightly slower initial convergence rates, indicating that changes in feature extraction methods impacted the training process, though the overall trends remained relatively stable. The proposed V-YOLO model, incorporating VIoU Loss, WEC, and SimAM, demonstrated significant improvements in both mAP50 and mAP75, achieving 40.3% and 25.7% respectively. Particularly noteworthy is V-YOLO’s rapid mAP improvement during early training phases, with continued performance gains in later stages, demonstrating superior generalization capability.
Based on the comparative analysis of the models, V-YOLO achieved the highest scores in bothmAP50 and mAP75 metrics, showing improvements of 0.9% and 1.8%, respectively, compared to the baseline model (YOLOX). The learning curves indicate that all models stabilized after 100 epochs, demonstrating the robustness of the training parameters and optimization methods. Regarding the impact of individual components: In YOLOX_1 ~ YOLOX_4 variants, while the WEC module may have slightly reduced the initial convergence rate, the final accuracy remained consistently between 37.9% and 38.7%. This suggests that WEC primarily affects training dynamics rather than ultimate performance. The significant improvement in mAP75 observed in both YOLOX 4 and V-YOLO indicates that the SimAM attention mechanism is particularly effective for high-precision object detection tasks. V-YOLO’s superior performance across both mAP50 and mAP75 metrics demonstrates that the VIoU Loss function plays a crucial role in optimizing detection box accuracy.
As shown in
Figure 7, we plotted the loss convergence curves of different models during training to demonstrate their optimization performance. From the overall trend, the loss values of all models decrease rapidly in the initial stage and gradually stabilize, eventually converging to relatively low values. The experimental loss curves indicate that all models exhibit good convergence behavior during training, with the decreasing trend of loss values meeting expectations. This further validates the effectiveness of our proposed method.
4.3. Comparative Experiment
To evaluate the performance of our proposed method, we conducted comparative experiments using the same dataset with representative detection models, including YOLOv5, YOLOv6, and YOLOX. Model performance was assessed by computing mean Average Precision (mAP) at specified IoU thresholds and parameter counts (Params) across different object categories. For a comprehensive evaluation, we adopted metrics from the COCO benchmark, with detailed results presented in
Table 2.
Comparative experiments demonstrate that employing CIoU and EIoU as regression loss functions can marginally improve YOLOX’s performance on the VisDrone dataset, with detailed results presented in
Table 3. Our proposed VIoU demonstrates superior performance, achieving 40.3% mAP and 25.7% mAP75 improvements of 0.9% and 1.8%, respectively, over the baseline. This indicates VIoU’s distinct advantages, particularly for small-object detection.
Figure 8 demonstrates that under long-distance and occluded conditions, YOLOX fails to detect certain small objects in the image, while V-YOLO successfully identifies vehicles in the top-left corner with the lowest miss rate compared to the original YOLOX.
Detailed analysis of
Figure 8 reveals: YOLOv5 detects 8 objects, demonstrating its fundamental detection capability;
Figure 8b: YOLOv6 identifies 10 objects, showing improved detection accuracy over YOLOv5;
Figure 8c: YOLOX detects 9 objects, exhibiting enhanced adaptability to complex scenes;
Figure 8d: YOLOv7 detects 9 objects, exhibiting enhanced adaptability to complex scenes; and
Figure 8e: Our proposed improved model successfully detects 11 objects, conclusively proving its superiority in object detection through both higher precision and significantly reduced miss rates.
4.4. Generalization Performance Experiments Under Adverse Weather Conditions
The algorithm proposed in this study primarily addresses detection challenges in complex traffic scenarios characterized by high vehicle density, severe occlusion, and small-scale targets.
The experimental results demonstrate that under adverse weather conditions (e.g., nighttime and foggy environments), as shown in the comparative
Figure 9, while our algorithm outperforms the baseline methods in detection performance, certain targets remain undetected. This indicates that the system’s robustness requires further enhancement.
5. Conclusions
In this study, the challenges of high vehicle density, occlusion, and small-object detection in complex traffic scenarios are investigated. To address these issues, V-YOLO, an advanced vehicle detection algorithm based on the modified YOLOX architecture, is proposed. The research introduces three key innovations: (1) the WEC (Wide-scope Enhancement Component) module, which significantly improves the network’s global perception ability; (2) the integration of the SimAM attention mechanism, enhancing feature saturation and multi-scale object generalization; and (3) the optimization of the VIoU bounding-box regression loss function, accelerating learning convergence and enhancing global feature extraction across various scales. Using the VisDrone dataset for model training and validation, the experimental results provide strong evidence that V-YOLO outperforms baseline algorithms in vehicle detection accuracy.
However, the detection precision for extremely dense or heavily occluded objects under adverse weather conditions remains suboptimal.
To further improve the model, it would be desirable to optimize the network architecture to reduce computational complexity while enhancing its adaptability to complex scenarios. This paper directly applies the modified YOLOX based V-YOLO for vehicle detection, conducting experimental analysis and comparison to identify the effectiveness of the proposed method. Indeed, the V-YOLO algorithm identified by this study may contribute to improving the prediction accuracy of vehicle detection in future research. Notably, the detection of vehicles in extremely dense traffic or under adverse weather conditions remains a limitation, which should be addressed in future studies.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}