
Learning to Utilize Multi-Scale Feature Information for Crisp Power Line Detection


Abstract
1. Introduction
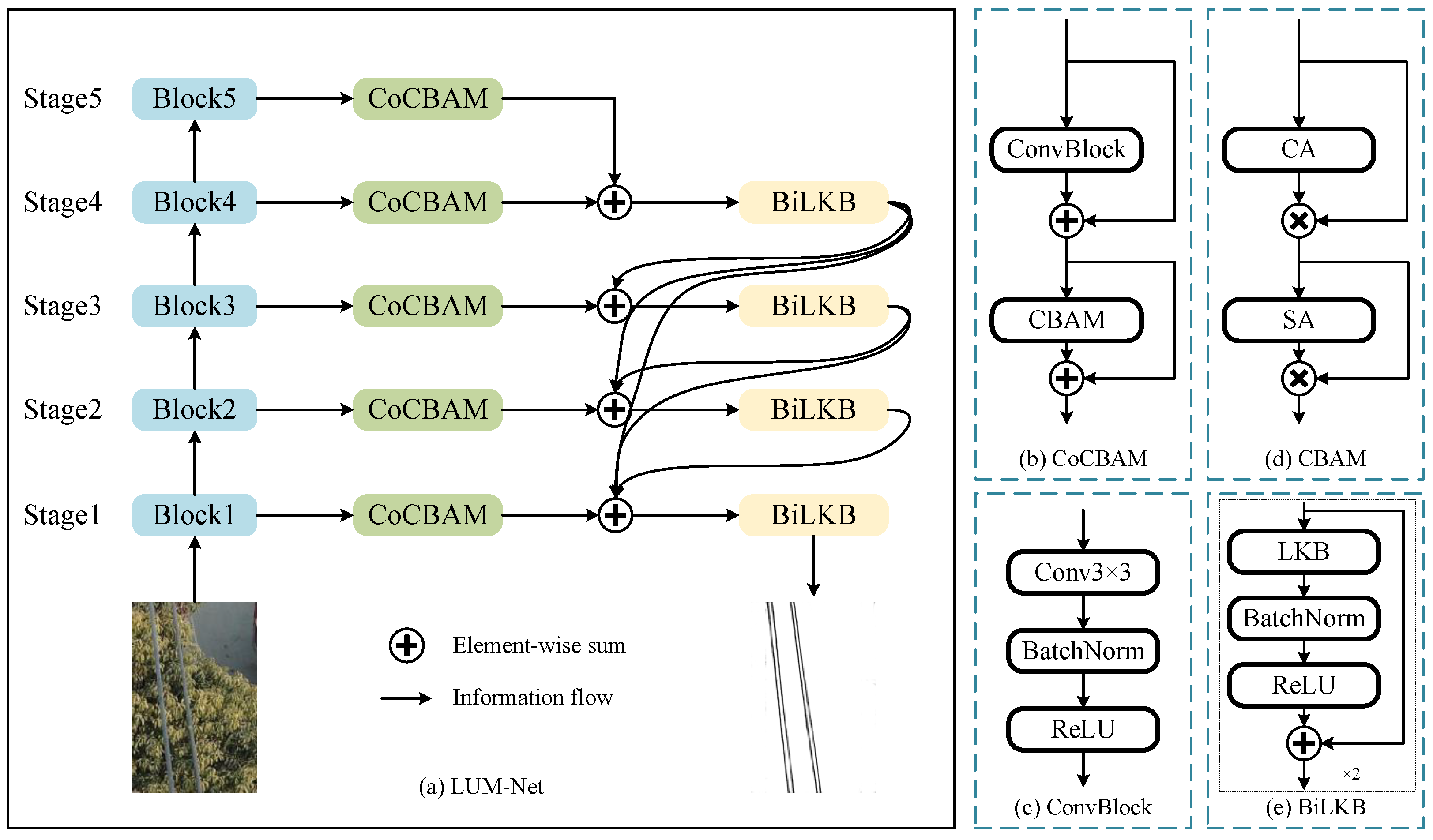
- We propose the Coordinated Convolutional Block Attention Module (CoCBAM). This module selectively focuses on critical features by emphasizing both channel and spatial information, thereby refining the power lines and reducing noise.
- We designed the Bi-Large Kernel Convolutional Block (BiLKB) module as the decoder, utilizing larger convolutional kernels to achieve feature decoding with a broader receptive field, supplemented by auxiliary small kernels to refine the extracted feature information.
- We constructed a U-shape encoder–decoder network named LUM-Net, which consists of the above key components and can predict clean power line maps. The high-precision mapping capability of LUM-Net demonstrates substantial engineering value by enabling automated UAV inspection systems.
2. Related Work
2.1. UAVs for PLD
2.2. Deep Learning Application for PLD
2.3. Deep Learning Application for Other Fields
3. Methodology
3.1. Network Architecture
3.2. CoCBAM Module
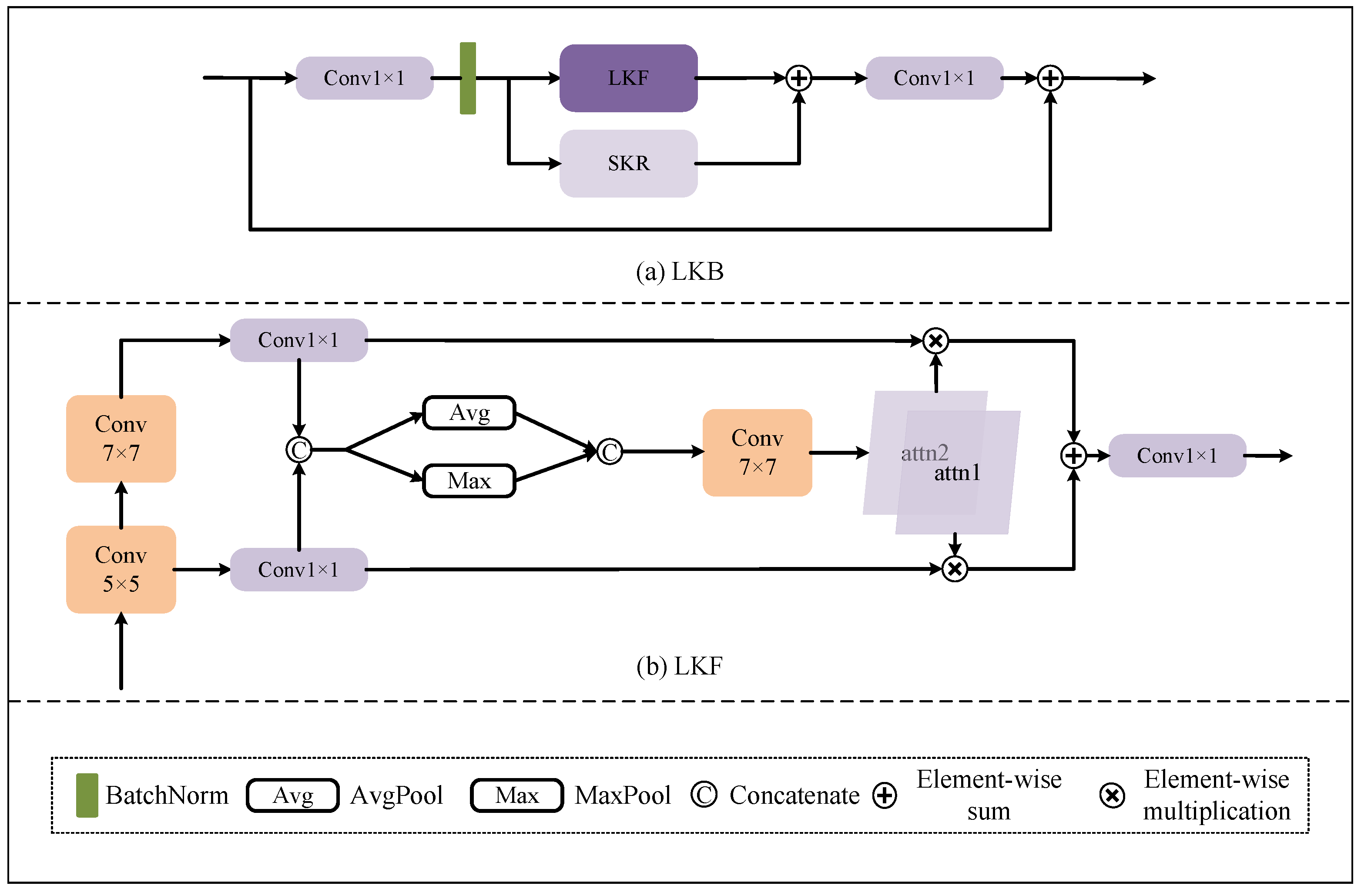
3.3. BiLKB Module
3.4. Dense Connection
3.5. Loss Function
4. Experiment
4.1. Implentation Details
4.2. Evaluation Metrics
4.3. Ablation Study
4.4. Comparative Experiments
5. Conclusions and Discussion
5.1. Conclusions
5.2. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
| ReLU | Rectified Linear Unit |
| CoCBAM | Coordinated Convolutional Block Attention Module |
| BiLKB | Bi-Large Kernel Convolutional Block |
| CAM | Channel Attention Module |
| SAM | Spatial Attention Module |
| HED | Holistically-nested Edge Detection |
| RCF | Richer Convolutional Features for Edge Detection |
| CBAM | Convolutional Block Attention Module |
| LKF | Large Kernel Fusion |
| SKR | Small Kernel Rectification |
| UAV | Unmanned Aerial Vehicle |
| PLD | Power Line Detection |
References
- Yang, L.; Fan, J.; Liu, Y.; Li, E.; Peng, J.; Liang, Z. A review on state-of-the-art power line inspection techniques. IEEE Trans. Instrum. Meas. 2020, 69, 9350–9365. [Google Scholar] [CrossRef]
- Deng, C.; Wang, S.; Huang, Z.; Tan, Z.; Liu, J. Unmanned Aerial Vehicles for Power Line Inspection: A Cooperative Way in Platforms and Communications. J. Commun. 2014, 9, 687–692. [Google Scholar] [CrossRef]
- Nguyen, V.; Jenssen, R.; Roverso, D. Electrical power and energy systems automatic autonomous vision-based power line inspection: A review of current status and the potential role of deep learning. Electr. Power Energy Syst. 2018, 99, 107–120. [Google Scholar] [CrossRef]
- Canny, J. A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 679–698. [Google Scholar] [CrossRef]
- Sobel, I.E. Camera Models and Machine Perception. Ph.D. Thesis, Stanford University, Stanford, CA, USA, 1970. [Google Scholar]
- Zhang, H.; Yang, W.; Yu, H.; Zhang, H.; Xia, G.S. Detecting power lines in UAV images with convolutional features and structured constraints. Remote Sens. 2019, 11, 1342. [Google Scholar] [CrossRef]
- Tran, D.K.; Roverso, D.; Jenssen, R.; Kampffmeyer, M. LSNetv2: Improving weakly supervised power line detection with bipartite matching. Expert Syst. Appl. 2024, 250, 123773. [Google Scholar] [CrossRef]
- Guo, J.; Wang, Z.; Li, H.; Yang, Y.; Huang, C.G.; Yazdi, M.; Kang, H.S. A hybrid prognosis scheme for rolling bearings based on a novel health indicator and nonlinear Wiener process. Reliab. Eng. Syst. Saf. 2024, 245, 110014. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, S.; Kim, M.; Hae, H.; Cao, M.; Kim, J. The development of a rebar-counting model for reinforced concrete columns: Using an unmanned aerial vehicle and deep-learning approach. J. Constr. Eng. Manag. 2023, 149, 04023111. [Google Scholar] [CrossRef]
- Kittler, J. On the accuracy of the Sobel edge detector. Image Vis. Comput. 1983, 1, 37–42. [Google Scholar] [CrossRef]
- Kasturi, R.; Camps, O.I. Wire Detection Algorithms for Navigation. 2002. Available online: https://ntrs.nasa.gov/citations/20020060508 (accessed on 25 May 2025).
- Yan, G.; Li, C.; Zhou, G.; Zhang, W.; Li, X. Automatic extraction of power lines from aerial images. IEEE Geosci. Remote Sens. Lett. 2007, 4, 387–391. [Google Scholar] [CrossRef]
- Li, Z.; Liu, Y.; Walker, R.; Hayward, R.; Zhang, J. Towards automatic power line detection for a UAV surveillance system using pulse coupled neural filter and an improved Hough transform. Mach. Vis. Appl. 2010, 21, 677–686. [Google Scholar] [CrossRef]
- Song, B.; Li, X. Power line detection from optical images. Neurocomputing 2014, 129, 350–361. [Google Scholar] [CrossRef]
- Pan, C.; Cao, X.; Wu, D. Power line detection via background noise removal. In Proceedings of the 2016 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Washington, DC, USA, 7–9 December 2016; pp. 871–875. [Google Scholar]
- Gubbi, J.; Varghese, A.; Balamuralidhar, P. A new deep learning architecture for detection of long linear infrastructure. In Proceedings of the 2017 Fifteenth IAPR International Conference on Machine Vision Applications (MVA), Nagoya, Japan, 8–12 May 2017; pp. 207–210. [Google Scholar]
- Madaan, R.; Maturana, D.; Scherer, S. Wire detection using synthetic data and dilated convolutional networks for unmanned aerial vehicles. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 3487–3494. [Google Scholar] [CrossRef]
- Yetgin, Ö.E.; Benligiray, B.; Gerek, Ö.N. Power line recognition from aerial images with deep learning. IEEE Trans. Aerosp. Electron. Syst. 2018, 55, 2241–2252. [Google Scholar] [CrossRef]
- Jaffari, R.; Hashmani, M.A.; Reyes-Aldasoro, C.C. A novel focal phi loss for power line segmentation with auxiliary classifier U-Net. Sensors 2021, 21, 2803. [Google Scholar] [CrossRef]
- Abdelfattah, R.; Wang, X.; Wang, S. Plgan: Generative adversarial networks for power-line segmentation in aerial images. IEEE Trans. Image Process. 2023, 32, 6248–6259. [Google Scholar] [CrossRef] [PubMed]
- Khan, M.A.M.; Kee, S.H.; Pathan, A.S.K.; Nahid, A.A. Image processing techniques for concrete crack detection: A scientometrics literature review. Remote Sens. 2023, 15, 2400. [Google Scholar] [CrossRef]
- Akinsemoyin, A.; Awolusi, I.; Chakraborty, D.; Al-Bayati, A.J.; Akanmu, A. Unmanned aerial systems and deep learning for safety and health activity monitoring on construction sites. Sensors 2023, 23, 6690. [Google Scholar] [CrossRef]
- Perez, H.; Tah, J.H.; Mosavi, A. Deep learning for detecting building defects using convolutional neural networks. Sensors 2019, 19, 3556. [Google Scholar] [CrossRef]
- Gargari, M.S.; Seyedi, M.H.; Alilou, M. Segmentation of Retinal Blood Vessels Using U-Net++ Architecture and Disease Prediction. Electronics 2022, 11, 3516. [Google Scholar] [CrossRef]
- Loh, H.W.; Hong, W.; Ooi, C.P.; Chakraborty, S.; Barua, P.D.; Deo, R.C.; Soar, J.; Palmer, E.E.; Acharya, U.R. Application of deep learning models for automated identification of Parkinson’s disease: A review (2011–2021). Sensors 2021, 21, 7034. [Google Scholar] [CrossRef]
- Li, F.; Yigitcanlar, T.; Nepal, M.; Nguyen, K.; Dur, F. Machine learning and remote sensing integration for leveraging urban sustainability: A review and framework. Sustain. Cities Soc. 2023, 96, 104653. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Li, Y.; Li, X.; Dai, Y.; Hou, Q.; Liu, L.; Liu, Y.; Cheng, M.M.; Yang, J. Lsknet: A foundation lightweight backbone for remote sensing. Int. J. Comput. Vis. 2024, 133, 1410–1431. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014, Proceedings, Part I 13; Springer: Berlin/Heidelberg, Germany, 2014; pp. 818–833. [Google Scholar]
- Mao, A.; Mohri, M.; Zhong, Y. Cross-entropy loss functions: Theoretical analysis and applications. In Proceedings of the International Conference on Machine Learning, PMLR, Honolulu, HI, USA, 23–29 July 2023; pp. 23803–23828. [Google Scholar]
- Xie, S.; Tu, Z. Holistically-nested edge detection. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1395–1403. [Google Scholar]
- Liu, Y.; Cheng, M.M.; Hu, X.; Wang, K.; Bai, X. Richer convolutional features for edge detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3000–3009. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CoCBAM | LKF | SKR | CBAM | ODS | OIS | AP |
|---|---|---|---|---|---|---|
| ✓ | ✓ | 0.966 | 0.975 | 0.963 | ||
| ✓ | ✓ | 0.962 | 0.970 | 0.961 | ||
| ✓ | ✓ | 0.968 | 0.975 | 0.965 | ||
| ✓ | ✓ | ✓ | 0.965 | 0.971 | 0.962 | |
| ✓ | ✓ | ✓ | 0.969 | 0.976 | 0.965 |
| Method | ODS | OIS | AP |
|---|---|---|---|
| Canny | 0.235 | 0.270 | 0.109 |
| Sobel | 0.453 | 0.500 | 0.365 |
| HED | 0.917 | 0.937 | 0.927 |
| RCF | 0.864 | 0.879 | 0.893 |
| LUM-Net | 0.969 | 0.976 | 0.965 |
| Method | ODS | OIS | AP |
|---|---|---|---|
| Canny | 0.152 | 0.164 | 0.054 |
| Sobel | 0.537 | 0.674 | 0.546 |
| HED | 0.835 | 0.845 | 0.716 |
| RCF | 0.785 | 0.794 | 0.620 |
| LUM-Net | 0.943 | 0.960 | 0.925 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, K.; Liu, M.; Wang, F.; Guo, X.; Han, G.; Bai, X.; Liu, C. Learning to Utilize Multi-Scale Feature Information for Crisp Power Line Detection. Electronics 2025, 14, 2175. https://doi.org/10.3390/electronics14112175
Li K, Liu M, Wang F, Guo X, Han G, Bai X, Liu C. Learning to Utilize Multi-Scale Feature Information for Crisp Power Line Detection. Electronics. 2025; 14(11):2175. https://doi.org/10.3390/electronics14112175
Chicago/Turabian StyleLi, Kai, Min Liu, Feiran Wang, Xinyang Guo, Geng Han, Xiangnan Bai, and Changsong Liu. 2025. "Learning to Utilize Multi-Scale Feature Information for Crisp Power Line Detection" Electronics 14, no. 11: 2175. https://doi.org/10.3390/electronics14112175
APA StyleLi, K., Liu, M., Wang, F., Guo, X., Han, G., Bai, X., & Liu, C. (2025). Learning to Utilize Multi-Scale Feature Information for Crisp Power Line Detection. Electronics, 14(11), 2175. https://doi.org/10.3390/electronics14112175