1. Introduction
As human–robot interaction (HRI) becomes increasingly important due to advancements in artificial intelligence (AI) and robotics, emotion recognition technology plays a critical role in enabling natural and seamless communication between humans and machines across various fields such as entertainment, healthcare, and education [
1]. For instance, if virtual assistants or social robots can accurately identify users’ emotional states, they can provide more personalized and context-aware responses. This has led to a growing body of research aimed at developing accurate emotion recognition systems [
2].
Traditionally, emotion recognition has relied on single modalities such as voice, facial expressions, or physiological signals. While these approaches have been widely studied, they often fail to fully capture the complexity of human emotions. Human emotions are inherently complex due to their ambiguous, overlapping, temporally dynamic, and culturally influenced nature. For instance, emotions like fear and surprise can share similar facial expressions, while anger and disgust may be indistinguishable from vocal tones alone. Furthermore, emotional expressions are often context-dependent, requiring integration of both verbal and nonverbal cues for accurate interpretation. As a result, single-modal systems—whether based on facial expressions, speech, or text—struggle to resolve these ambiguities and often produce inconsistent or incomplete emotional assessments. This has sparked increasing interest in multimodal methods that integrate text, video, and audio to enhance recognition accuracy [
3,
4,
5]. However, while multimodal fusion offers high accuracy, it is challenging to apply in real-time systems or on lightweight devices due to its high computational and memory demands. This difficulty stems from the heterogeneity of multimodal data, which makes it hard to integrate different types of information effectively. Since data fusion plays a key role in multimodal emotion recognition, the overall model performance largely depends on how well these modalities are combined [
6]. Feature-level fusion, also known as early fusion, combines data from different modalities at the input stage and trains a single model, allowing it to capture inter-modal correlations from the beginning [
7]. However, it often suffers from issues such as high dimensionality and difficulties in time synchronization.
In contrast, decision-level fusion—also referred to as late fusion—processes each modality separately and integrates the results at the final stage. This approach provides flexibility and allows independent learning for each modality, but it can be challenging to design effective fusion rules and may suffer from limited performance due to overly simplistic combination strategies.
Recent studies have explored and compared various fusion techniques to identify the most effective strategies for multimodal emotion recognition. With the rapid advancement of deep learning, its application to multimodal data fusion has become increasingly widespread [
8,
9]. For instance, Cimtay et al. [
10] demonstrated that hybrid fusion methods, which integrate the strengths of both feature-level and decision-level fusion, can significantly improve classification accuracy. Sahu and Vechtomova [
11] proposed an adaptive fusion technique that enables neural networks to dynamically determine the optimal way to combine multimodal inputs, outperforming traditional fusion approaches. In a related domain, Li et al. [
12] introduced a sensor-adaptive multimodal fusion method for 3D object detection, effectively combining LiDAR and camera data through a deformable attention mechanism to produce a unified representation across modalities.
Despite recent advances, securing large-scale emotional datasets remains a fundamental challenge in affective computing. Most studies rely on relatively small corpora, which limits both the learning capacity and generalization ability of emotion recognition models. This problem is particularly acute in Korean-language research, where high-quality multimodal emotion datasets—especially video-based—are significantly fewer than in English. To address this underrepresentation, we focus on a Korean-language multimodal video dataset in this study. Importantly, our aim is not to develop a language-specific system but to propose a modular fusion architecture that generalizes across languages. The proposed framework utilizes transferable features such as text embeddings and visual emotion dynamics, enabling potential deployment in multilingual contexts.
In low-resource scenarios, feature-level multimodal fusion is especially challenging due to the high dimensionality and synchronization demands of heterogeneous inputs. To overcome this, we propose a decision-level fusion framework that integrates modality-specific emotion scores from text and video. While recent advancements in pre-trained language models—particularly GPT-based generative models—have improved contextual and emotional understanding in text, their performance still suffers from domain shifts, ambiguous expressions, and the absence of nonverbal cues. Emotional meaning in short utterances often remains unclear, and text cannot capture critical signals such as tone, facial expressions, or gestures.
Therefore, for more robust and context-aware emotion recognition, a multimodal approach that integrates both verbal and nonverbal information is essential. By combining the strengths of pretrained language models with lightweight visual emotion classification and efficient decision-level fusion, our framework aims to balance accuracy, adaptability, and computational efficiency. Therefore, this study aims to enhance emotion recognition by addressing the following key aspects:
Utilization of pre-trained language models: To overcome the limited availability of Korean emotion datasets, we explore the use of large-scale pre-trained models for text-based emotion analysis.
Multimodal fusion: By integrating text and video data, we aim to mitigate the limitations of single-modality approaches and improve recognition accuracy.
Emotion score-based decision fusion: We propose various fusion strategies that leverage the emotion scores from each modality, accounting for differences in classification performance.
The structure of this paper is as follows:
Section 2 reviews related work.
Section 3 details the proposed methodology.
Section 4 presents the experimental setup, results, and comparative analysis.
Section 5 concludes the paper with a summary and future research directions.
2. Related Work
This section reviews previous studies that have employed feature-level, decision-level, and hybrid fusion techniques for multimodal emotion recognition, particularly in video-based contexts.
Viegas et al. [
13] proposed a two-stage emotion recognition model that combines frame-level and video-level features. It applied feature-level fusion by combining Facial Action Units (FAUs), voice features (MFCC), and skeleton motion data, and utilized a method of classifying emotions into stage 1 (positive/neutral/negative) and stage 2 (detailed emotions). The experimental results showed that video-level features outperform frame-level features, suggesting that a fusion method that reflects temporal emotional changes can improve emotion recognition performance.
Kumar et al. [
14] proposed an audio-video multimodal emotion recognition model using deep learning and applied a feature-level fusion method that combined voice feature extraction using ResNet20 and image feature analysis using 3D CNN. In particular, OpenSMILE was used to extract voice features (MFCC, pitch, energy, etc.), facial emotions were analyzed from the image, and the Weighted Concatenation Fusion technique was applied to generate the optimal emotion expression vector. However, the feature-level fusion method may be difficult to apply in real applications due to high-dimensional feature problems and time synchronization issues, and, in particular, generalization performance may be degraded when the dataset is insufficient. In Lee Dae-jong’s study [
15], a fusion method was applied that combined facial features extracted from still images with temporal emotional changes analyzed from videos. In particular, we effectively analyzed emotional changes that are difficult to detect in still images by utilizing a dynamic modeling technique based on the HMM (Hidden Markov Model), thereby enabling more precise emotion recognition. However, if the emotional features of still images and videos are not consistent, the problem of inter-modality imbalance may occur, and especially if the dataset size is insufficient, the model performance may deteriorate.
Jo and Jung’s study [
16] proposed a multimodal emotion recognition system that combines facial images and multidimensional emotion-based text information. This method applies a fusion method that combines a CNN-based facial emotion recognition model and a BERT-based text emotion recognition model to quantitatively analyze emotions in a multidimensional space (VAD: Valence–Arousal–Dominance). In particular, by combining feature-level fusion and decision-level fusion, they optimized the integration of the emotional information of facial images and texts, effectively improving the accuracy of emotional recognition compared to single-modality approaches. However, text emotion analysis has limitations. It is difficult for learned models to consistently perform in real-world situations due to differences in speaking styles across domains, and it is difficult to recognize emotions when contextual information is lacking. S. Moon’s study [
17] proposed a multimodal method for the emotion classification of Korean video data. They designed deep learning models specialized for video and voice. The video model extracts features using a 3D convolutional neural network, and the voice model uses MFCC technology to create spectrogram images that can visualize and express voice data. The feature vectors from the two feature extraction methods were merged, and the emotion with the highest probability was predicted using the Softmax function. However, since the Korean emotional dataset is limited, the generalization performance of the trained model is likely to be low, and additional fusion strategies are needed to address the problem of emotional information mismatch between voice and video. Ortega et al.’s study [
18] proposed a multimodal emotion recognition model using deep neural networks. Unlike previous studies that applied the Early Fusion (feature combination) or Late Fusion (result combination) method, we introduced a new approach that learns audio, video, and text data individually and then learns the optimal emotional expression using the Intermediate Fusion method. The proposed model applies a method in which each modality is learned in independent layers and then combined in shared layers to perform emotion classification. However, although the Intermediate Fusion method recorded high performance, it has limitations in that its performance may deteriorate when there is not much training data, and it is difficult to apply it to real-time emotion analysis.
In the study by Yi et al. [
19], the HyFusER (Hybrid Multimodal Transformer for Emotion Recognition Using Dual Cross-Modal Attention) model was proposed to improve emotion recognition performance. This model extracts text features using the KoELECTRA pre-trained model, extracts speech features using HuBERT, then learns features of both modalities using the Transformer encoder, and then effectively combines information between the two modalities using the Dual Cross Modal Attention technique. In particular, information exchange was maximized by applying Intermediate Layer Fusion and Last Fusion, and the final emotion prediction was performed using the average ensemble method. However, because it uses various pre-learning models and complex fusion techniques, it has the limitation that the model structure is complex and the amount of computational processing is large, and the performance is not high compared to that.
Recent efforts in lightweight emotion recognition have also adopted entropy-based feature fusion to minimize computational overhead. For example, Li et al. [
20] proposed a resource-efficient EEG emotion recognition method that converts single-channel signals into a Brain Rhythm Entropy Matrix (BREM) using multi-entropy features. This matrix is then classified using simple similarity measures, achieving over 80% accuracy on the DEAP dataset while maintaining interpretability and reducing model complexity. Such entropy-driven approaches provide a promising direction for real-time applications in constrained environments, aligning with our goal of lightweight multimodal systems.
As shown in
Table 1, existing approaches often rely on complex fusion mechanisms or resource-intensive models, which limits their applicability in real-time or low-resource scenarios. Our method addresses these limitations by adopting a simple yet effective decision-level fusion strategy.
3. Materials and Methods
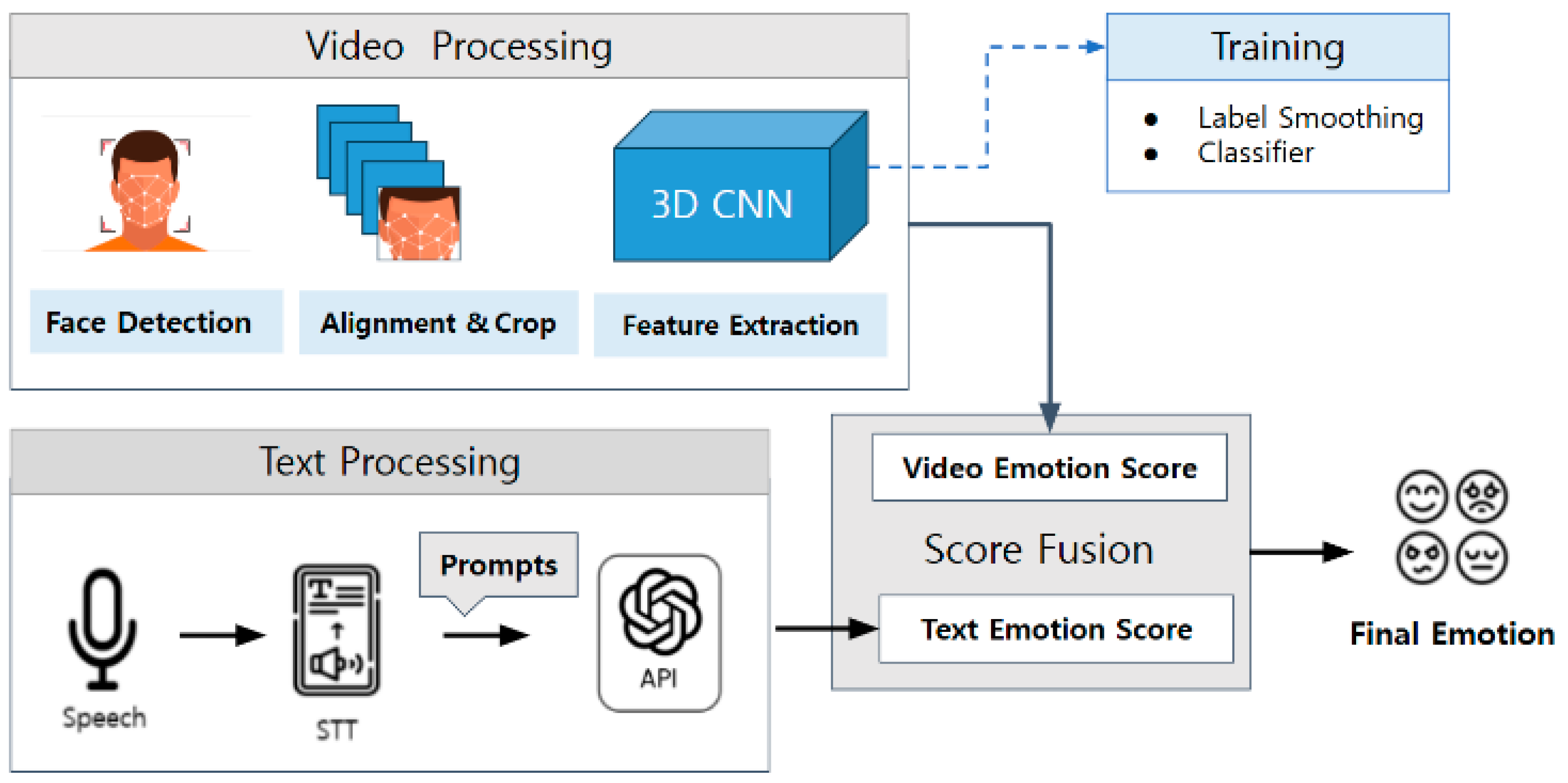
In this study, we propose an emotion recognition fusion method that applies a decision fusion method using text and video modalities based on a Korean video dataset, as shown in
Figure 1.
The research flow is largely divided into the Text Information Processing section, which processes text data extracted from audio, and the Video Information Processing section, which processes facial image data. The detailed processing steps are divided into the step of extracting emotion scores from text, the step of implementing a model that learns videos to determine facial emotions, the step of extracting emotion scores using a video determination model, and finally the step of deriving the final emotion by fusing the text emotion scores and video emotion scores. At this time, emotions are based on seven basic emotions (happy, surprise, neutral, fear, disgust, angry, and sad).
3.1. Dataset
The video dataset is a dataset for emotion classification provided by AI-HUB [
21], consisting of a total of 10,351 videos, and in each video, 100 actors perform lines in situations classified into seven basic emotions (happiness, surprise, blank expression, fear, disgust, anger, and sadness). Examining the data structure, it consists of 350 situational texts and utterances, videos of actors performing the utterances, and facial expression images for each emotion. The actors consisted of 43 males and 57 females, and their ages ranged from 20 to 40 s. Each video was produced in such a way that each person acted out the given utterance, given a situational text that could infer emotions. The video length varies from 2 to 4 s, depending on the speech duration, and consists of 90 to 150 frames.
Figure 2 shows some frames from a video of a person acting out the line “Why are you saying this now?” in a situation where a person had planned to meet a friend but received a phone call 30 min before the appointment saying, “I don’t think I can make it today”.
3.2. Text Emotion Score Extraction with GPT-4
One of the major challenges in emotion recognition research is the lack of high-quality, large-scale emotional datasets. To address this issue, recent studies have explored methods such as fine-tuning pre-trained models and using generative models to supplement emotional data.
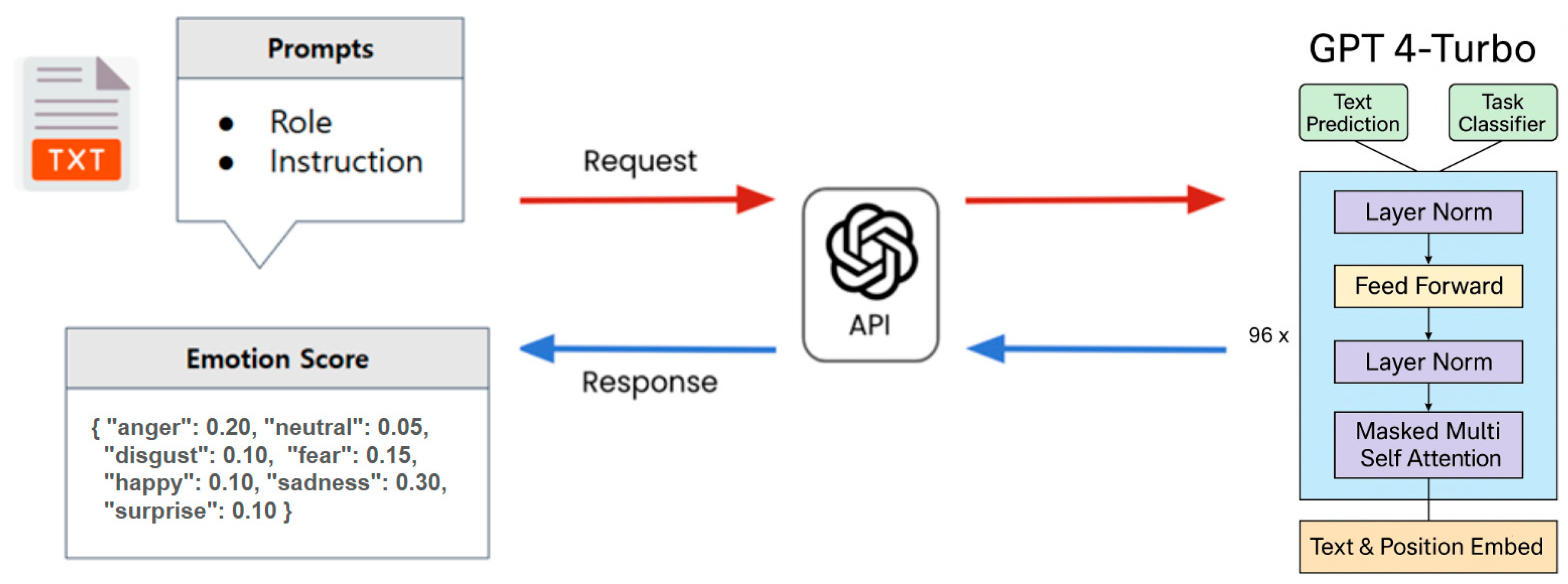
In this study, we utilize a small-scale Korean emotion dataset consisting of approximately 350 text utterances. To compensate for data scarcity and obtain consistent emotion annotations, we send each utterance as a prompt to GPT-4 Turbo—an advanced large language model (LLM)—via the OpenAI API. The structure of the prompt and the inference process are detailed in
Table 2. The model returns seven emotion scores per text. The overall process of emotion scoring using the LLM is illustrated in
Figure 3. For consistency and reproducibility, we use a low temperature setting (0.2), which minimizes randomness in generation.
GPT-4 Turbo is based on the Transformer architecture and leverages a self-attention mechanism to understand contextual relationships. The input text is tokenized using Byte Pair Encoding (BPE), transformed into high-dimensional vectors via an embedding layer, and passed through multiple Transformer encoder layers to infer emotion scores in context.
While the use of GPT-4 Turbo involves external API calls, which may raise concerns about latency and computational cost, this approach serves as a proof-of-concept. It allows immediate deployment without requiring additional model training or dataset-specific fine-tuning. Furthermore, it enables access to the latest model updates and large-scale pre-learned emotional knowledge without incurring maintenance or retraining costs.
In practical applications, the framework can be adapted to run with lighter, locally fine-tuned models such as KoELECTRA or DistilBERT. These alternatives preserve the structure of our system while supporting faster inference and lower resource consumption. Therefore, our current implementation demonstrates conceptual validity while remaining flexible for future lightweight deployment.
3.3. Video Score Extraction with 3DCNN
Analyzing facial expressions in a video modality requires detecting and tracking faces in video frames. Three-dimensional convolutional neural networks (3DCNNs) are important in video-based emotion recognition. This algorithm improves emotion recognition performance by leveraging the inherent information in video data. Since video data have various lengths and resolutions, a preprocessing process is required to convert it into a certain format and normalize it to be used as input for the model.
First, the video frames are loaded, and the face is detected using 49 facial landmark information for each frame, and the face portion is accurately cropped. At this time, if the face is not detected, the frame is excluded. To maintain data consistency, we align the faces based on the positions of the two eyes and then reduce the size of the images to 240 × 240. Afterwards, cropping is additionally performed based on the image center point to remove noise. Next, the frame size is adjusted to 128 × 128 to fit the designed 3D CNN model, and 16 consecutive frames are composed into one clip through clip unit division operation. At this time, if the video length is short enough to not fill the required number of clips, add blank clips filled with 0 and delete excess clips to keep the maximum number of clips to 6.
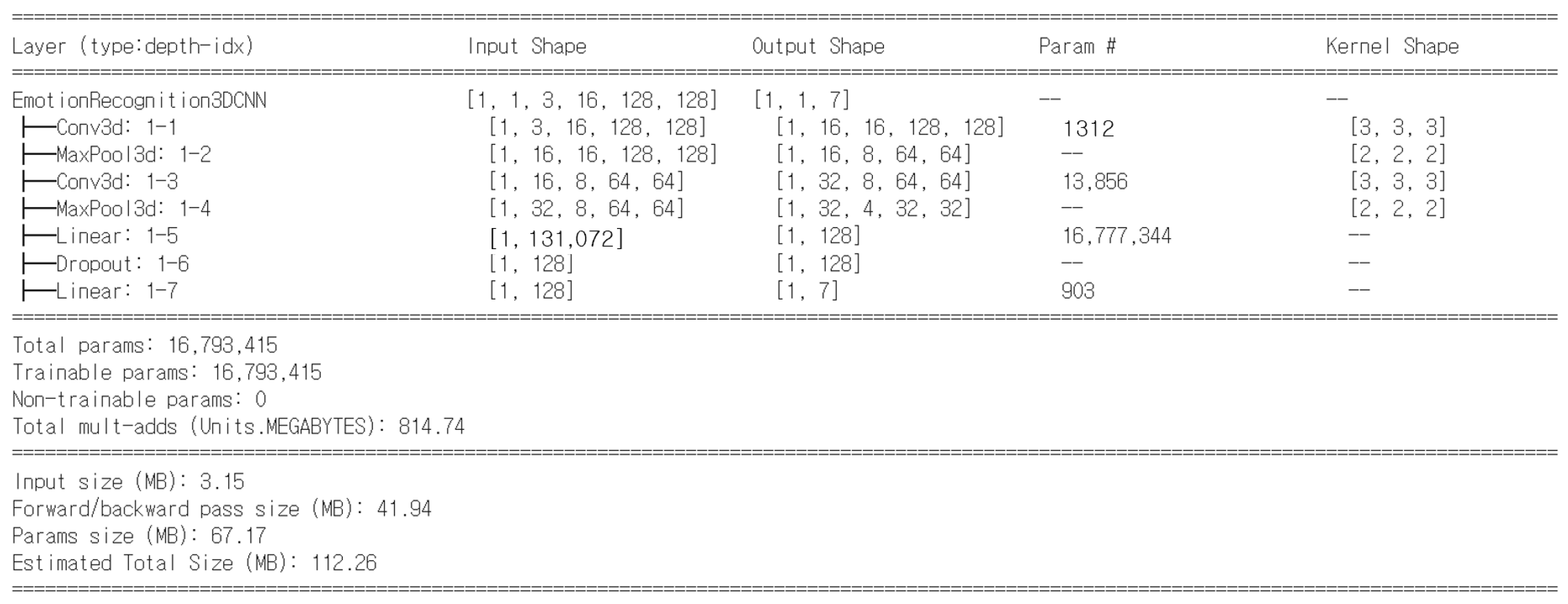
Figure 4 illustrates the architecture of the video emotion classification model, which is based on a compact 3D Convolutional Neural Network (3D CNN). The model takes input in the form of 16-frame RGB video clips (each of size 128 × 128 × 3) and applies a 3 × 3 × 3 convolution filter to extract spatio-temporal features that capture both local image patterns and temporal emotional dynamics. To ensure lightweight computation and real-time applicability, the model is designed with only two 3D convolutional layers, two 3D max-pooling layers, and a two-layer fully connected classifier. This efficient structure allows the model to maintain high performance while minimizing computational load. As confirmed by the model summary, it contains approximately 16.8 million trainable parameters, requires 814.74 million multiply–add operations (MACs) per inference, and has an estimated total memory footprint of 112.26 MB, including input, activation, and parameter sizes. Compared to more complex architectures such as Transformer-based multimodal models, the proposed video classifier offers a practical trade-off between performance and efficiency, making it suitable for deployment on edge devices and in real-time systems.
To avoid overfitting due to a small amount of data, we use the loss function of Equation (1) with a label-smoothing technique instead of dropout and a general cross-entropy loss function. This equation represents the cross-entropy loss with label smoothing applied.
C is the number of classes and is the smoothing coefficient.
The optimizer uses Adam to apply an adaptive learning rate to improve learning speed. Additionally, the stability of emotion classification is improved by averaging multiple clips.
3.4. Score-Based Decision-Level Fusion
In emotion analysis, effectively combining multimodal data from text and video is essential for improving recognition accuracy. However, a simple average-based fusion method has limitations, as text and video convey emotional information in inherently different ways and exhibit varying levels of model reliability. To address this, we propose three fusion strategies (Method 1, Method 2, and Method 3) that integrate emotion scores from both modalities based on different theoretical perspectives on model confidence and inter-modality relationships.
Method 1 applies a fixed confidence-based weighting scheme to each modality. Specifically, the final emotion score is computed by weighting the text and video emotion scores using predefined confidence values (
Ct for text,
Cv for video), which are derived from each modality’s standalone classification performance. This method assumes that model confidence remains stable across all samples, providing a consistent and interpretable baseline.
Method 2, in contrast, introduces a dynamic weighting mechanism based on the correlation between the emotion scores of the two modalities. If the two scores are strongly correlated, the method simply sums them; if they are weakly correlated, it falls back to the confidence-based weighting from Method 1. This method assumes that real-time agreement between modalities is an indicator of reliability and thus adapts fusion weights accordingly.
These two methods are theoretically distinct: Method 1 is static and performance-driven, whereas Method 2 is adaptive and context-sensitive, leveraging inter-modal consistency. The comparison between them allows us to evaluate the effectiveness of static vs. dynamic fusion strategies in multimodal emotion recognition.
Method 3 combines emotion scores from text and video modalities using Dempster–Shafer Theory (DST), a framework for reasoning under uncertainty. While DST has been used in prior multimodal fusion studies, our method introduces two key adaptations tailored for emotion recognition tasks with soft probabilistic scores. First, we convert soft emotion scores into basic belief assignments (BBAs), enabling the model to handle ambiguous emotional states. Second, we incorporate modality-specific confidence into the DST combination rule, allowing more reliable sources to influence the final decision. These adaptations enhance DST’s applicability to emotion recognition in uncertain and low-resource environments. Unlike conventional DST applications that rely on discrete class labels, our approach enables graded reasoning over soft emotional probabilities.
4. Results
4.1. Text Emotion Recognition Performance
Emotion classification for text was performed on 350 data, each labeled with 50 emotions per emotion, using the ChatGPT API (accessed via
https://platform.openai.com, GPT-4 Turbo, version as of April 2025), a large language model (LLM), to classify the seven basic emotions. The results are shown in
Table 3.
Table 4 compares the results of emotion classification on text when only simple utterances are given and when contextual information is given along with the utterances.
Figure 5 shows the results as a confusion matrix. In simple utterances, it is particularly difficult to distinguish between fear, disgust, anger, and sadness. When context information is provided, it can be confirmed that the performance improves.
4.2. Video Emotion Recognition Performance
For training, only 4900 video samples, which are a subset of the entire dataset, were used. These samples were divided into three groups—training, validation, and testing—as shown in
Table 5, and experiments were conducted accordingly.
Table 6 presents the training parameters: each clip consists of 16 frames, each video is divided into 6 standard clips, the input frame size is adjusted to 128 × 128, and a single filter with a size of 3 × 3 × 3 is applied.
As a result,
Figure 6 is a graph showing the changes in loss and accuracy during the model’s training process, and the classification accuracy was found to be approximately 74%. (a) In the graph, the loss decreases quickly and then stabilizes, but the validation loss decreases and then fluctuates at a certain level. (b) In the graph, the learning accuracy increases continuously and approaches 100%, while the verification accuracy initially increases and then remains at a relatively low level, showing a tendency to oscillate. This situation indicates overfitting due to insufficient data, and data augmentation is needed to address the issue. In this study, however, we assumed a low-resource scenario and employed early stopping to save and use the best-performing model during training.
As shown in
Figure 7 and
Table 7, the video-based emotion classification model outperformed the text-only emotion classification model overall. Nevertheless, distinguishing between
fear,
disgust, and
anger remains challenging.
4.3. Score-Based Fusion Performance
The results in
Table 8 are the result of applying Method 1, which calculates a weighted average of the video and text emotion scores reflecting the reliability of each model and then determines the final emotion. In other words, it is a fusion method that dynamically adjusts the weights reflecting the reliability of each data modality.
Table 9 shows the results of an algorithm that calculates the correlation between the text and video emotion scores and then dynamically adjusts the weights according to the similarity to determine the final emotion. Unlike Method 1, this method uses the Normalized Correlation Coefficient (NCC) to determine whether the emotion distributions of the text and video are similar.
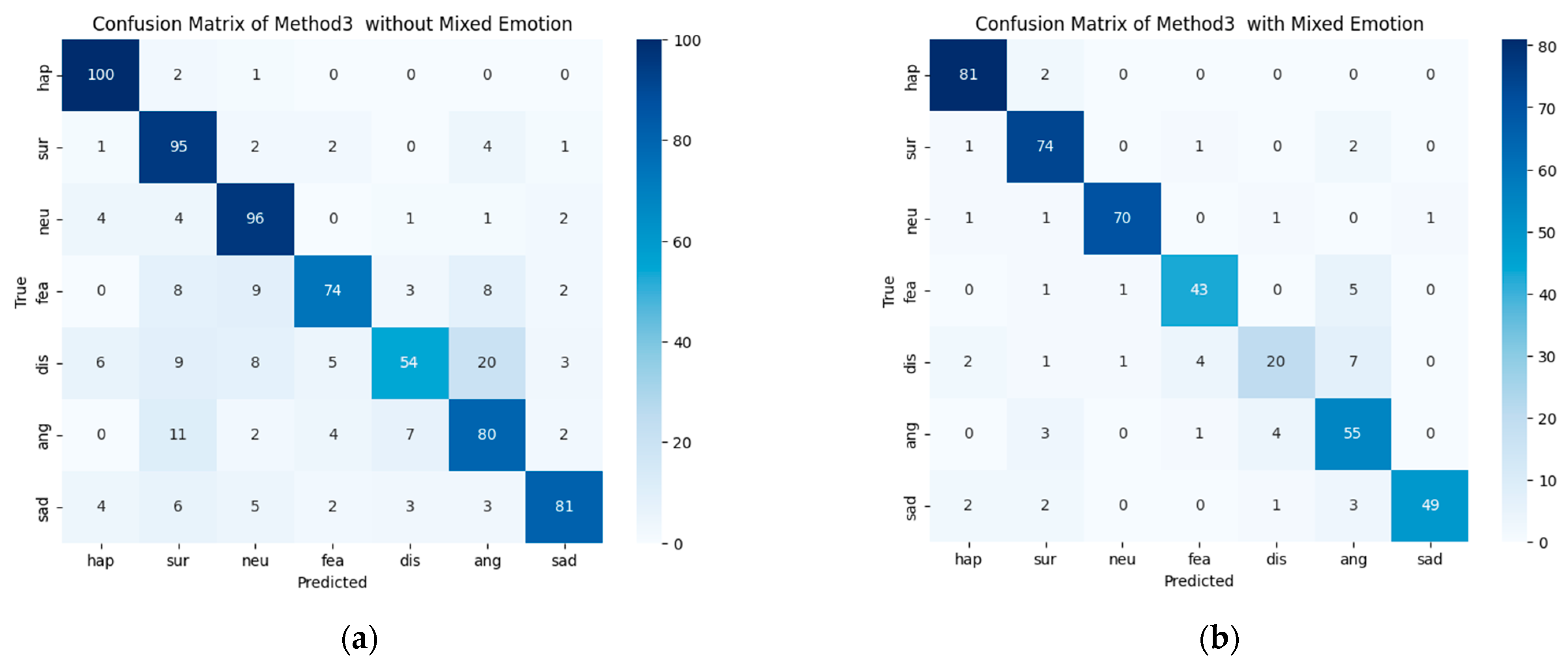
Figure 8 shows the results of applying Method 3, which combines text and video emotion scores by modifying the Dempster–Shafer Theory (DST) and then determines the final emotion: (a) is the case where compound emotion is not considered, and (b) is the case where compound emotion is considered.
When using compound emotions, prediction became more challenging compared to the conventional single-emotion model. However, strong emotions such as anger, disgust, and fear were expressed in a more complex manner. Nonetheless, as seen in the sample data from
Table 10, compound emotions better captured the contextual nuances of the situation.
Figure 9 shows a comparison of performance between single-modality models and the proposed multi-modal fusion approaches in terms of recall and F1-score. The analysis revealed that the proposed methods consistently achieved superior performance across most emotion categories. As summarized in
Table 11, the proposed fusion method achieved higher accuracy (0.80) and F1-score (0.79) compared to the text-only and video-only baselines. Since accurately identifying negative emotions is particularly important, recall was emphasized as a key evaluation metric in this study.
Furthermore, repeated experiments demonstrated that the performance of the three fusion strategies was stable, with minimal variation across runs. Although minor differences were observed in emotion-specific metrics—especially in harder-to-classify emotions like disgust—the macro-average F1-score difference between methods was within 1%, suggesting that all proposed methods are comparably effective overall.
Table 12 compares the performance with existing studies based on the Korean video dataset. As shown in
Table 9, the proposed method achieved the highest performance with an accuracy of 0.80 and an F1-score of 0.79, outperforming existing approaches such as those by Chanyoung J [
16] and Seokho [
17]. This demonstrates the effectiveness of the proposed fusion strategy over traditional multimodal methods.
5. Discussion
A key challenge in emotion recognition research is the scarcity of large-scale annotated datasets, particularly for the Korean language. This limitation reduces model generalization and makes feature-level fusion difficult due to high-dimensional and asynchronous data. To address this issue, we leveraged pre-trained large-scale language models and proposed an emotion score-based decision fusion method that combines text and video information, aiming to complement the limitations of single-modality approaches while reducing learning complexity.
For the text modality, emotion scores were obtained by submitting text prompts to GPT-4 Turbo, a large language model (LLM), via the OpenAI API. The model returned a vector of seven emotion scores per utterance. In simple expressions, the model achieved 58% accuracy, which improved to 72% when contextual information was considered, demonstrating its effectiveness in capturing nuanced emotional cues. However, it still showed difficulty in accurately classifying negative emotions such as fear, disgust, and sadness.
For the video modality, we trained a model based on a 3D convolutional neural network, which achieved strong performance (74% accuracy) despite the limited dataset. The proposed 3D CNN model was designed to be lightweight, containing only two convolutional layers, two pooling layers, and two fully connected layers, with approximately 16.8 million parameters and a total memory footprint of around 112 MB. This compact design enables efficient inference suitable for edge computing.
To further enhance overall classification, we implemented and compared three fusion algorithms based on the reliability of each modality: (1) confidence-based weighting, (2) correlation-aware adjustment, and (3) Dempster–Shafer Theory (DST)-based combination. These methods yielded comparable performance overall, with minor variations in the classification of disgust. Compared to previous studies using Korean datasets, our approach achieved a favorable trade-off between model complexity and recognition performance.
Our approach maintains lightweight design principles at every level: (i) text-based emotion recognition is conducted using LLM APIs during inference only, without local fine-tuning or additional training; (ii) the video modality uses a simple 3D CNN model with no complex temporal attention or Transformer blocks; and (iii) fusion is performed using score-level decision methods rather than neural-level integration, minimizing additional computational overhead. These design choices result in a multimodal emotion recognition framework that is both accurate and highly suitable for real-time applications.
Although our proposed fusion methods improved the overall classification performance, the emotion class disgust consistently exhibited low recognition accuracy. This may be attributed to its semantic and expressive proximity to Anger, leading to frequent confusion between the two. To address this, we considered merging closely related negative emotions, such as anger and disgust, into a single broader category—a strategy supported in prior affective computing literature. While this could improve classification robustness and mitigate class imbalance, it would also reduce emotional granularity and limit interpretive resolution. Thus, we chose to maintain separate classes in this study, but we recognize the value of category merging as a promising direction for future work, especially in real-time or low-resource scenarios. In addition, we aim to incorporate audio as a supplementary modality and explore the use of combined emotion categories to gain a deeper understanding of affective states. Ultimately, our goal is to develop a lightweight, real-time multimodal emotion recognition system that balances accuracy with practical deployability.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}