
Sentiment Analysis of Digital Banking Reviews Using Machine Learning and Large Language Models


Abstract
1. Introduction
- Building an annotated dataset for Arabic user reviews of digital banking applications in Saudi Arabia.
- Assessing various ML classifiers for sentiment classification of user reviews into positive, negative, and conflict classes.
- In-depth analysis of customer feedback regarding banking services to uncover the key concerns associated with each category.
- Evaluate the effectiveness of LLMs for Arabic SA tasks with a multi-label and domain focus dataset.
2. Related Work
2.1. Arabic Sentiment Analysis
2.2. Sentiment Analysis in Mobile Application Domain
2.3. Sentiment Analysis Using Large Language Models
3. Methodology
3.1. Data Collection
3.2. Data Annotation
3.3. PII Anonymization and Censoring
3.4. Data Preprocessing
- Data cleaning: this process involves eliminating unnecessary elements that do not contribute to polarity classification, such as English letters, numbers, punctuation marks, spaces, and URLs.
- Normalization: The primary goal of normalization is to standardize the forms of several Arabic characters that have different forms. This involves converting various forms of Arabic letters into a single standardized representation. Additionally, normalization involves removing elongated characters in a string and also replacing consecutive occurrences of the same character.
- Tokenization: Dividing a sentence of strings into a list of words, called tokens, separated by delimiters.
- Stop word removal: Stop words are a group of frequently used, less-meaningful terms that appear regularly in natural language. A substantial list of Arabic stop words can be found in the library of NLTK [46].
3.5. Feature Extraction
3.6. Handling Class Imbalance
3.7. Classification Models
- SVM: This is a common type of supervised machine algorithm used for classification tasks. It seeks to find the optimal hyperplane that separates the inputs into distinct categories in feature space. Depending on the kernel model type, SVM can adapt to solve a nonlinear classification type.
- LR: This is a statistical method that originates from the linear regression model. It involves mapping the categorical output into one or more independent variables based on probability, providing an analytical overview of the dataset.
- DT: A classification algorithm based on a simple decision rule. It involves decomposing the dataset into smaller subsets, creating a tree-like structure. Through recursive division, the algorithm continues to separate the data until the leaf node is reached, achieving a homogeneous grouping of data.
- RF: Random Forest is an Ensemble Learning technique that involves building a large number of decision trees during training. Each tree generates an output for a given input, and the final prediction is based on the majority voting of the results from each tree. It is known for its flexibility and its ability to handle large, multidimensional datasets.
- XGBoost Classifier: A gradient boosted decision tree model called XGBoost was introduced by Chen and Guestrin [49]. It builds multiple decision trees sequentially, where at each iteration, a new tree is added to correct the errors of its predecessors.
- Voting Classifier: A type of Ensemble technique that learns by combining baseline models and predicting the output based on the class with the highest probability, thereby enhancing overall performance. There are two types of Voting Classifiers: hard voting and soft voting. Hard voting determines the final prediction by selecting the class with the majority vote, while soft voting relies on average probabilities to identify the final class. For this study, we implemented hard voting to aggregate predictions from SVM, RF, and LR.
3.8. LLM Selection
3.9. Prompt Design
3.10. Model Evaluation
- Accuracy: This is assessed by comparing the percentage of accurately labeled data points to the total accuracy. This statistic offers a comprehensive assessment of the model’s performance in classification tasks.
- Precision: The proportion of true positive predictions over all positive predictions.
- Recall: The proportion of true positives to the sum of true positives and false negatives.
- F1-score: The harmonic mean of precision and recall.
4. Results
4.1. Evaluating ML Approaches for Digital Banking SA
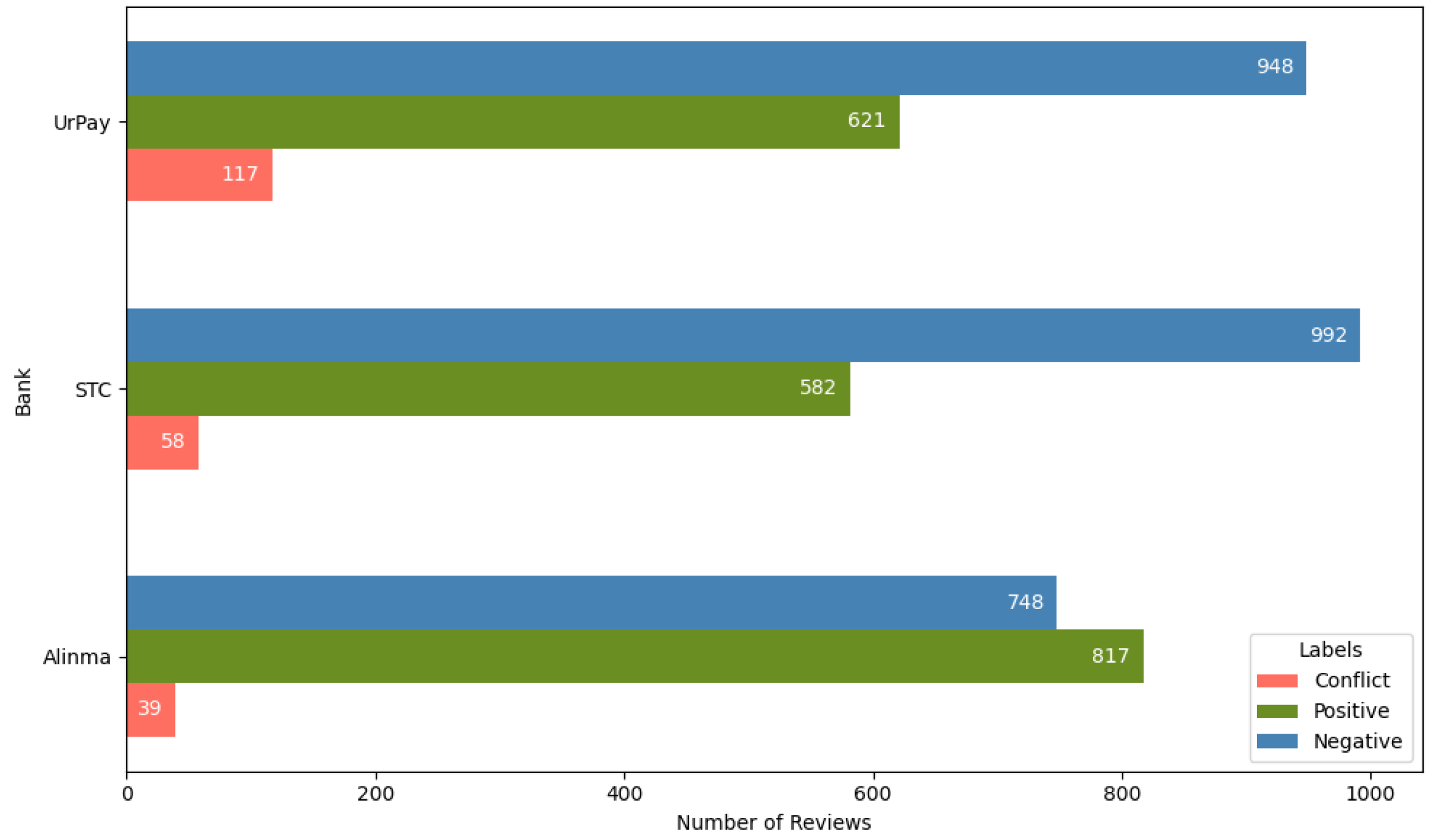
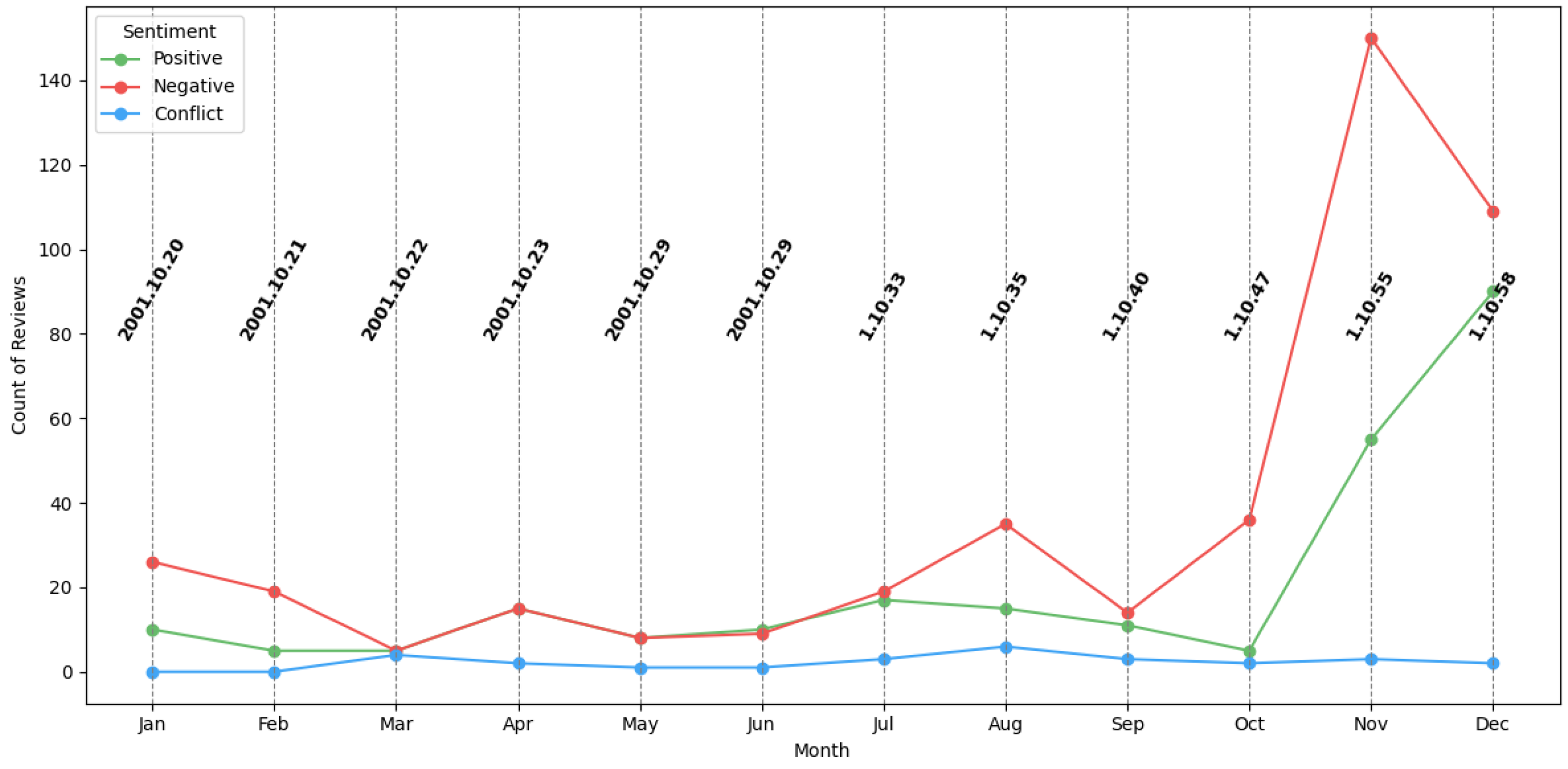
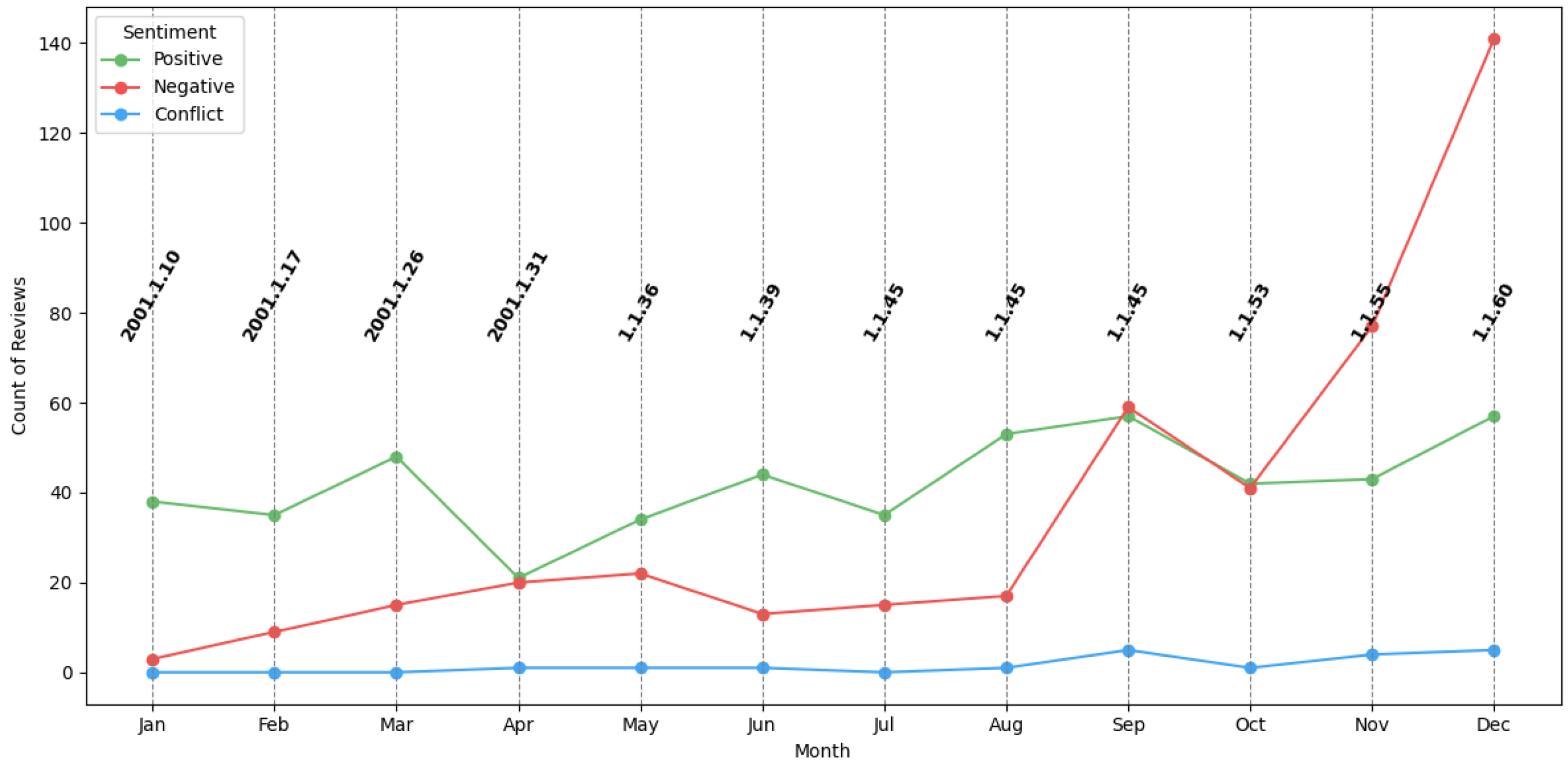
Quantitative Analysis of Bank Reviews
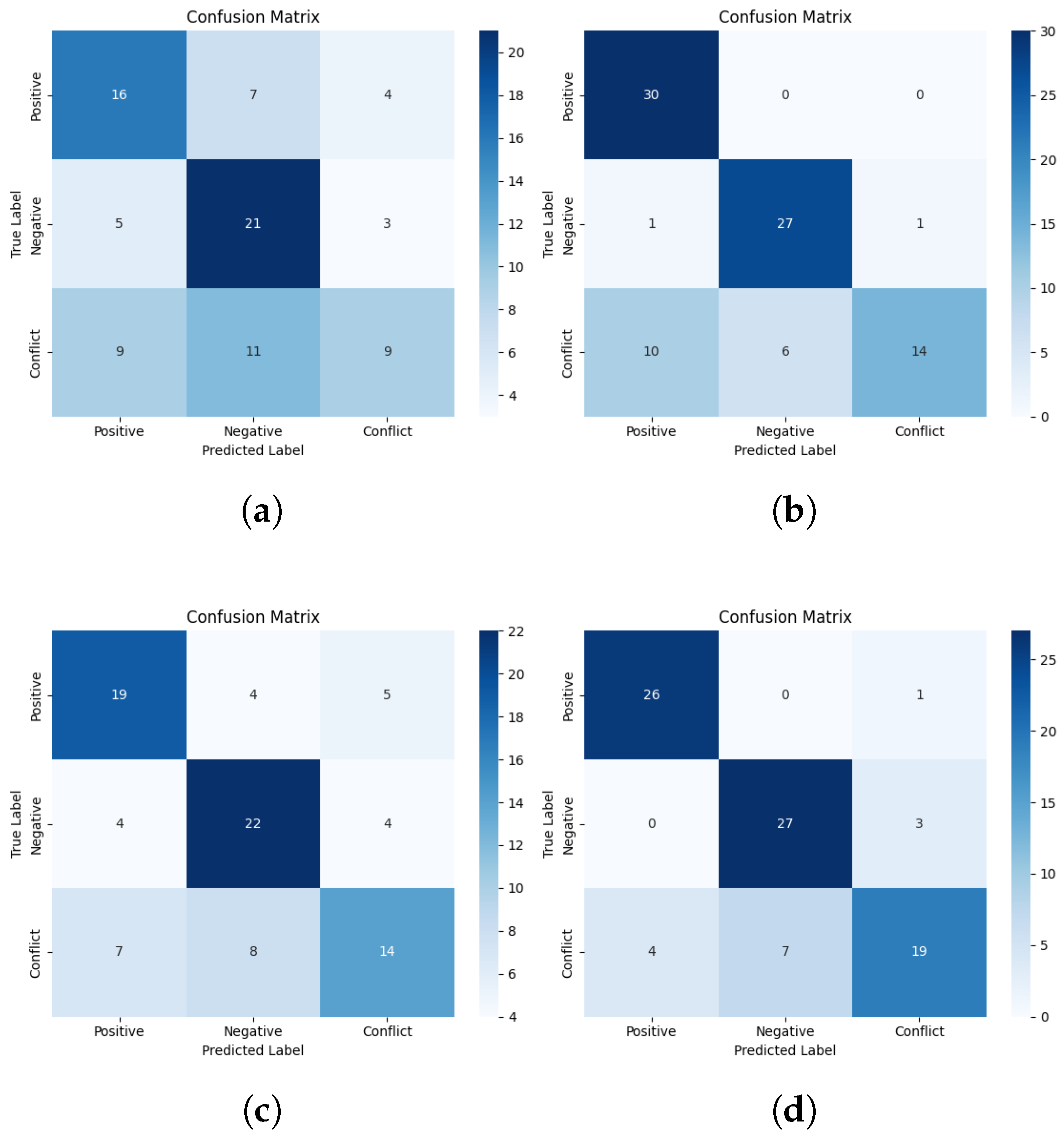
4.2. Evaluating LLM Approaches for Digital Banking SA
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| BERT | Bidirectional Encoder Representations from Transformers |
| DL | Deep Learning |
| DT | Decision Tree |
| KNN | K-Nearest Neighbor |
| LLMs | Large Language Models |
| LR | Logistic Regression |
| LIWC | Linguistic Inquiry Word Count |
| ML | Machine Learning |
| NB | Naive Bayes |
| NLP | Natural Language Processing |
| PII | Personal identifiable information |
| RF | Random Forest |
| SA | Sentiment Analysis |
| SVM | Support Vector Machine |
| TF-IDF | Term frequency-inverse document frequency |
Appendix A. Sample of Prompts

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Prompt Setting | Template Prompt |
|---|---|
| Zero-Shot | Analyse the sentiment of the reviews written in Arabic language. In your output, only return the sentiment for each review as either [‘positive’, ‘conflict’, ‘negative’]. Respond with only one word. |
| Few-Shot | Analyse the sentiment of the reviews written in Arabic language. In your output, only return the sentiment for each review as either [‘positive’, ‘conflict’, ‘negative’]. Respond with only one word. Here are some examples to guide you: Review: positive train review ; Sentiment: positive Review: negative train review ; Sentiment: negative Review: conflict train review ; Sentiment: conflict |
| Prompt Setting | Template Prompt |
|---|---|
| Zero-Shot |  |
| Few-Shot |  |
Appendix B. Confusion Matrices for ML Models
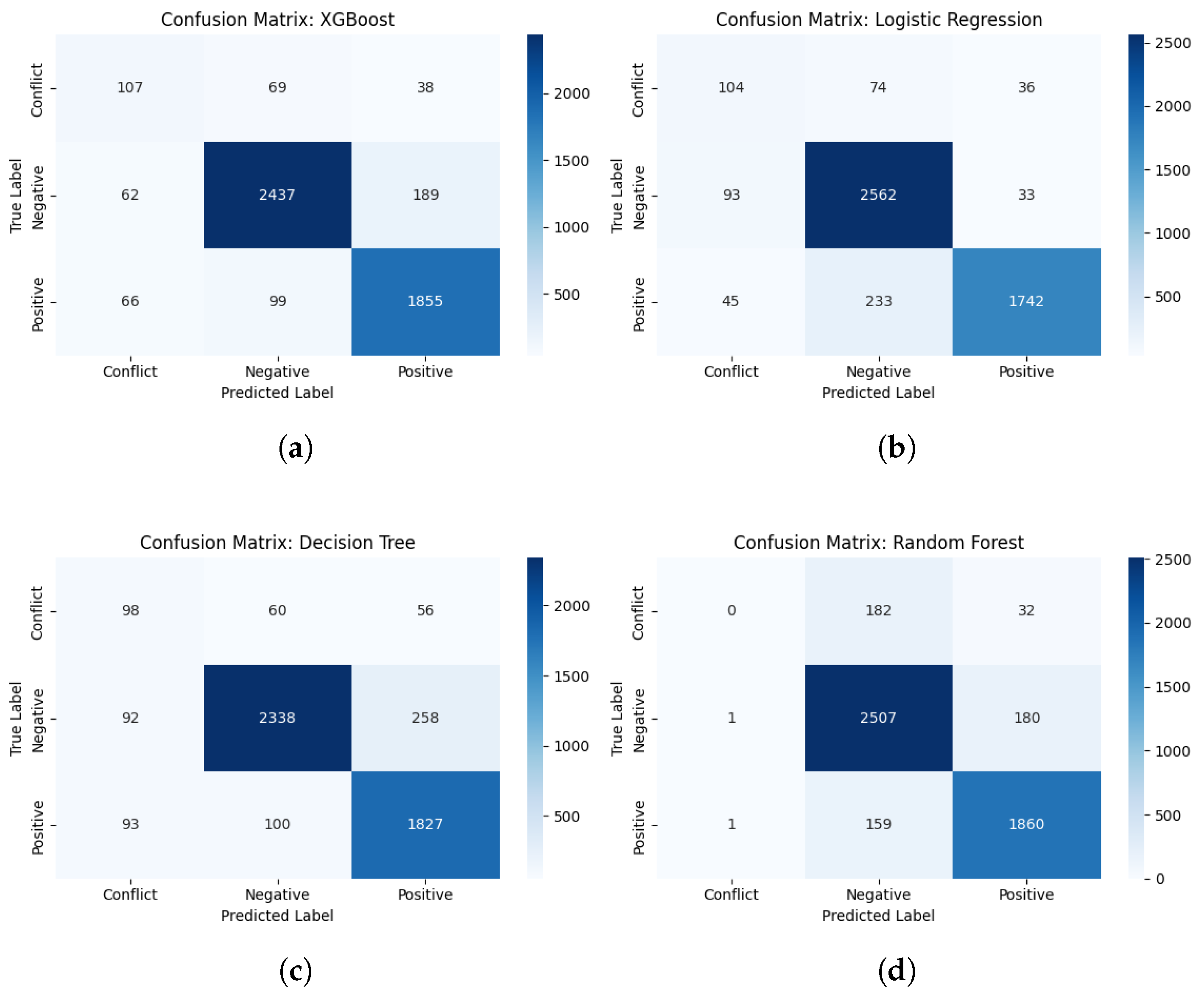
Appendix C. Translation of the N-Grams Terms
| Bigram (Arabic) | Frequency | Bigram (English Translation) |
|---|---|---|
 | 162 | Very good |
 | 155 | Not working |
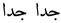 | 139 | Very very |
 | 133 | More than |
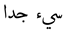 | 133 | Very bad |
 | 113 | After the update |
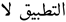 | 93 | The application does not |
 | 80 | Solve the problem |
 | 76 | Latest update |
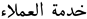 | 72 | Customer Service |
| Trigram (Arabic) | Frequency | Trigram (English Translation) |
|---|---|---|
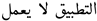 | 60 | The app is not working |
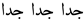 | 45 | Very very very |
 | 32 | After the last update |
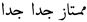 | 26 | Very very excellent |
 | 24 | More than once |
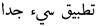 | 20 | Very bad application |
 | 17 | Very very bad |
 | 17 | Please solve the problem |
 | 16 | STC |
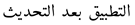 | 16 | The application after the update |
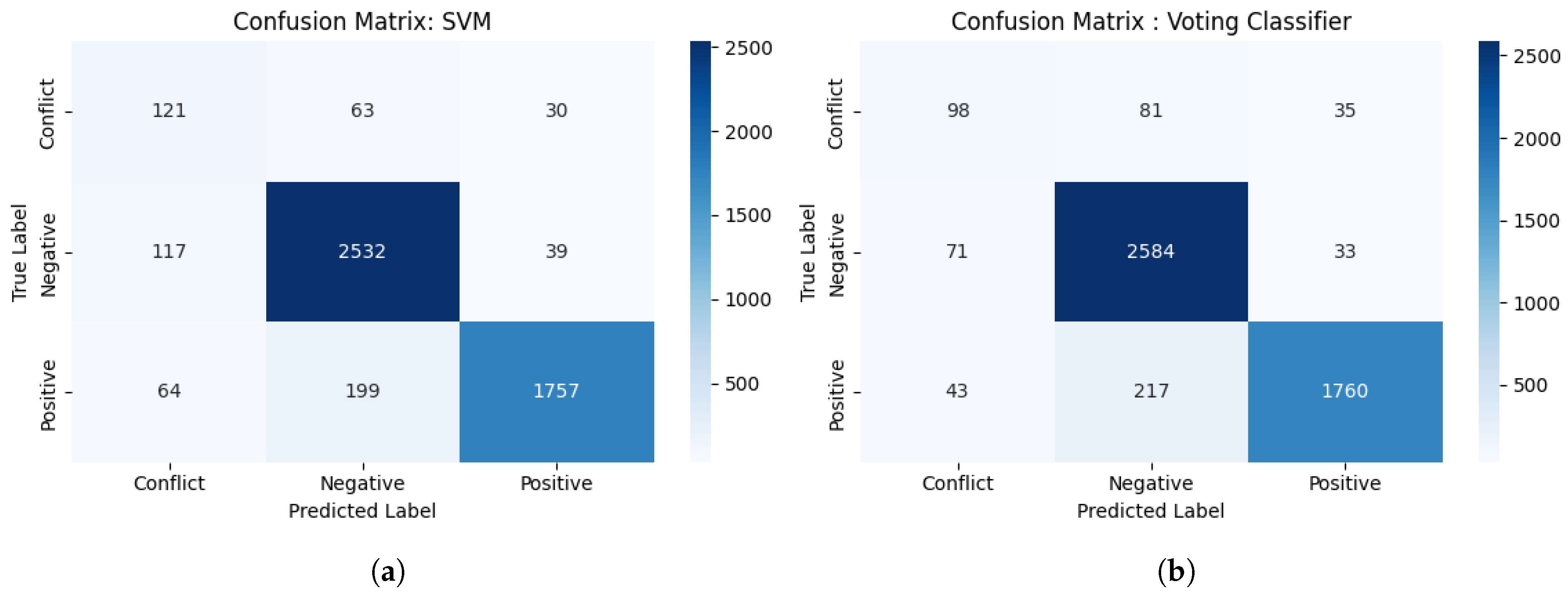
Appendix D. Confusion Matrices for LLMs Models
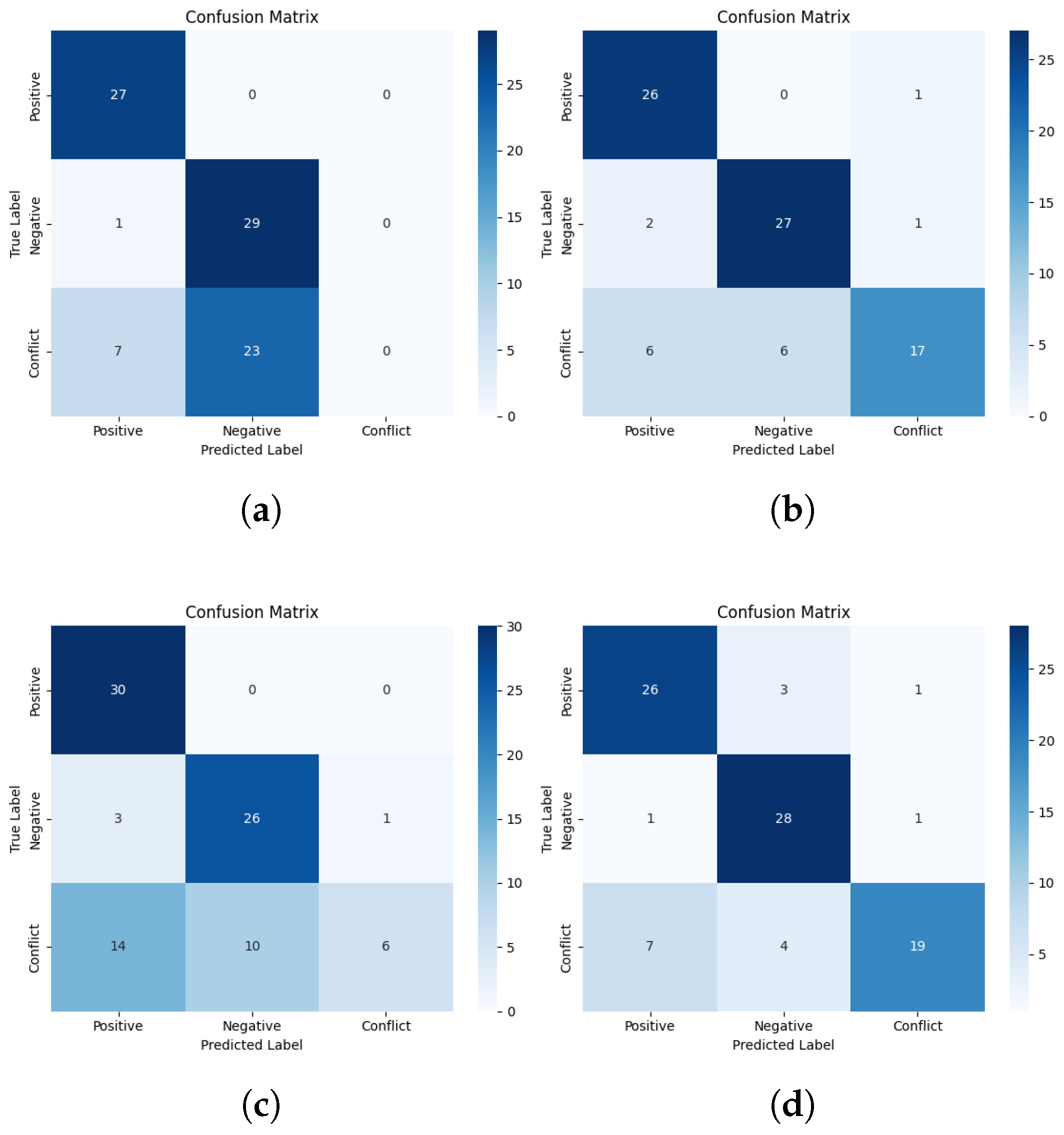
References
- Al-Qudah, A.A.; Al-Okaily, M.; Alqudah, G.; Ghazlat, A. Mobile payment adoption in the time of the COVID-19 pandemic. Electron. Commer. Res. 2024, 24, 427–451. [Google Scholar] [CrossRef]
- Alkhwaldi, A.F.; Alharasis, E.E.; Shehadeh, M.; Abu-AlSondos, I.A.; Oudat, M.S.; Bani Atta, A.A. Towards an understanding of FinTech users’ adoption: Intention and e-loyalty post-COVID-19 from a developing country perspective. Sustainability 2022, 14, 12616. [Google Scholar] [CrossRef]
- Statista. Digital Population Worldwide as of January 2024. February 2024. Available online: https://www.statista.com/statistics/617136/digital-populationworldwide/ (accessed on 14 May 2025).
- Persia, F.; D’Auria, D. A survey of online social networks: Challenges and opportunities. In Proceedings of the 2017 IEEE International Conference on Information Reuse and Integration (IRI), San Diego, CA, USA, 4–6 August 2017; pp. 614–620. [Google Scholar]
- Indrasari, A.; Nadjmie, N.; Endri, E. Determinants of satisfaction and loyalty of e-banking users during the COVID-19 pandemic. Int. J. Data Netw. Sci. 2022, 6, 497–508. [Google Scholar] [CrossRef]
- Michailidis, P.D. A Comparative Study of Sentiment Classification Models for Greek Reviews. Big Data Cogn. Comput. 2024, 8, 107. [Google Scholar] [CrossRef]
- Sharma, H.D.; Goyal, P. An analysis of sentiment: Methods, applications, and challenges. Eng. Proc. 2023, 59, 68. [Google Scholar]
- Devlin, J. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Kalyan, K.S. A survey of GPT-3 family large language models including ChatGPT and GPT-4. Nat. Lang. Process. J. 2023, 6, 100048. [Google Scholar] [CrossRef]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.-A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. Llama: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Qin, L.; Chen, Q.; Feng, X.; Wu, Y.; Zhang, Y.; Li, Y.; Li, M.; Che, W.; Yu, P.S. Large language models meet nlp: A survey. arXiv 2024, arXiv:2405.12819. [Google Scholar]
- Nandwani, P.; Verma, R. A review on sentiment analysis and emotion detection from text. Soc. Netw. Anal. Min. 2021, 11, 81. [Google Scholar] [CrossRef]
- Yang, L.; Li, Y.; Wang, J.; Sherratt, R.S. Sentiment analysis for E-commerce product reviews in Chinese based on sentiment lexicon and deep learning. IEEE Access 2020, 8, 23522–23530. [Google Scholar] [CrossRef]
- Jain, V.; Kashyap, K.L. Ensemble hybrid model for Hindi COVID-19 text classification with metaheuristic op-timization algorithm. Multimed. Tools Appl. 2023, 82, 16839–16859. [Google Scholar] [CrossRef]
- Musleh, D.A.; Alkhwaja, I.; Alkhwaja, A.; Alghamdi, M.; Abahussain, H.; Alfawaz, F.; Min-Allah, N.; Abdulqader, M.M. Arabic Sentiment Analysis of YouTube Comments: NLP-Based Machine Learning Approaches for Content Evaluation. Big Data Cogn. Comput. 2023, 7, 127. [Google Scholar] [CrossRef]
- Soumelidou, A.; Tsohou, A. Validation and extension of two domain-specific information privacy competency models. Int. J. Inf. Secur. 2024, 23, 2437–2455. [Google Scholar] [CrossRef]
- Genc-Nayebi, N.; Abran, A. A systematic literature review: Opinion mining studies from mobile app store user reviews. J. Syst. Softw. 2017, 125, 207–219. [Google Scholar] [CrossRef]
- Zhao, J.; Gui, X. Comparison research on text preprocessing methods on twitter sentiment analysis. IEEE Access 2017, 5, 2870–2879. [Google Scholar]
- Mathayomchan, B.; Sripanidkulchai, K. Utilizing Google translated Reviews from Google maps in senti-ment analysis for Phuket tourist attractions. In Proceedings of the 2019 16th International Joint Conference on Computer Science and Software Engineering (JCSSE), Chonburi, Thailand, 10–12 July 2019; pp. 260–265. [Google Scholar]
- Sghaier, M.A.; Zrigui, M. Sentiment analysis for Arabic e-commerce websites. In Proceedings of the 2016 International Conference on Engineering & MIS (ICEMIS), Agadir, Morocco, 22–24 September 2016; pp. 1–7. [Google Scholar]
- Nasrullah, H.A.; Nasrullah, M.A.; Flayyih, W.N. Sentiment analysis in Arabic language using machine learning: Iraqi dialect case study. AIP Conf. Proc. 2023, 2651, 060015. [Google Scholar]
- Ziani, A.; Azizi, N.; Zenakhra, D.; Cheriguene, S.; Aldwairi, M. Combining RSS-SVM with genetic algorithm for Arabic opinions analysis. Int. J. Intell. Syst. Technol. Appl. 2019, 18, 152–178. [Google Scholar] [CrossRef]
- Hicham, N.; Karim, S.; Habbat, N. Customer sentiment analysis for Arabic social media using a novel ensemble machine learning approach. Int. J. Electr. Comput. Eng. 2023, 13, 4504–4515. [Google Scholar] [CrossRef]
- Oussous, A.; Lahcen, A.A.; Belfkih, S. Improving sentiment analysis of moroccan tweets using Ensemble Learning. In Big Data, Cloud and Applications, Proceedings of the Third International Conference, BDCA 2018, Kenitra, Morocco, 4–5 April 2018; Revised Selected Papers 3; Springer International Publishing: Cham, Switzerland, 2018; pp. 91–104. [Google Scholar]
- Benrouba, F.; Boudour, R. Emotional sentiment analysis of social media content for mental health safety. Soc. Netw. Anal. Min. 2023, 13, 17. [Google Scholar] [CrossRef]
- Masrury, R.A.; Alamsyah, A. Analyzing tourism mobile applications perceived quality using sentiment analysis and topic modeling. In Proceedings of the 2019 7th International Conference on Information and Communication Technology (ICoICT), Kuala Lumpur, Malaysia, 24–26 July 2019; pp. 1–6. [Google Scholar]
- Rhanoui, M.; Mikram, M.; Yousfi, S.; Barzali, S. A CNN-BiLSTM model for document-level sentiment analysis. Mach. Learn. Knowl. Extr. 2019, 1, 832–847. [Google Scholar] [CrossRef]
- Olagunju, T.; Oyebode, O.; Orji, R. Exploring key issues affecting african mobile ecommerce applications using sentiment and thematic analysis. IEEE Access 2020, 8, 114475–114486. [Google Scholar] [CrossRef]
- Permana, M.E.; Ramadhan, H.; Budi, I.; Santoso, A.B.; Putra, P.K. Sentiment analysis and topic detection of mobile banking application review. In Proceedings of the 2020 Fifth International Conference on Informatics and Computing (ICIC), Gorontalo, Indonesia, 3–4 November 2020; pp. 1–6. [Google Scholar]
- Hadwan, M.; Al-Hagery, M.; Al-Sarem, M.; Saeed, F. Arabic sentiment analysis of users’ opinions of govern-mental mobile applications. Comput. Mater. Contin. 2022, 72, 4675–4689. [Google Scholar]
- Andrian, B.; Simanungkalit, T.; Budi, I.; Wicaksono, A.F. Sentiment analysis on customer satisfaction of digital banking in Indonesia. Int. J. Adv. Comput. Sci. Appl. 2022, 13, 466–473. [Google Scholar] [CrossRef]
- Samudera, B.; Nurdin, N.; Aidilof, H. Sentiment analysis of user reviews on BSI Mobile and Action Mobile applications on the Google Play Store using multinomial Naive Bayes algorithm. Int. J. Eng. Sci. Inf. Technol. 2024, 4, 101–112. [Google Scholar] [CrossRef]
- Al-Hagree, S.; Al-Gaphari, G. Arabic Sentiment Analysis Based Machine Learning for Measuring User Satisfaction with Banking Services’ Mobile Applications: Comparative Study. In Proceedings of the 2022 2nd International Conference on Emerging Smart Technologies and Applications (eSmarTA), Ibb, Yemen, 25–26 October 2022; pp. 1–4. [Google Scholar]
- Chader, A.; Hamdad, L.; Belkhiri, A. Sentiment analysis in google play store: Algerian reviews case. In Modelling and Implementation of Complex Systems, Proceedings of the 6th International Symposium, MISC 2020, Batna, Algeria, 24–26 October 2020; Springer International Publishing: Cham, Switzerland, 2021; pp. 107–121. [Google Scholar]
- Mustafa, D.; Khabour, S.M.; Shatnawi, A.S.; Taqieddin, E. Arabic Sentiment Analysis of Food Delivery Services Reviews. In Proceedings of the 2023 International Symposium on Networks, Computers and Communications (ISNCC), Doha, Qatar, 23–26 October 2023; pp. 1–6. [Google Scholar]
- Zhong, Q.; Ding, L.; Liu, J.; Du, B.; Tao, D. Can chatgpt understand too? A comparative study on chatgpt and fine-tuned bert. arXiv 2023, arXiv:2302.10198. [Google Scholar]
- Koto, F.; Beck, T.; Talat, Z.; Gurevych, I.; Baldwin, T. Zero-shot sentiment analysis in low-resource languages using a multilingual sentiment lexicon. arXiv 2024, arXiv:2402.02113. [Google Scholar]
- Ye, J.; Chen, X.; Xu, N.; Zu, C.; Shao, Z.; Liu, S.; Cui, Y.; Zhou, Z.; Gong, C.; Shen, Y.; et al. A comprehensive capability analysis of gpt-3 and gpt-3.5 series models. arXiv 2023, arXiv:2303.10420. [Google Scholar]
- Mo, K.; Liu, W.; Xu, X.; Yu, C.; Zou, Y.; Xia, F. Fine-Tuning Gemma-7B for Enhanced Sentiment Analysis of Financial News Headlines. arXiv 2024, arXiv:2406.13626. [Google Scholar]
- Xiao, H.; Luo, L. An Automatic Sentiment Analysis Method For Short Texts Based on Transformer-BERT Hybrid Model. IEEE Access 2024, 12, 93305–93317. [Google Scholar] [CrossRef]
- Zhao, W.X.; Zhou, K.; Li, J.; Tang, T.; Wang, X.; Hou, Y.; Min, Y.; Zhang, B.; Zhang, J.; Dong, Z.; et al. A survey of large language models. arXiv 2023, arXiv:2303.18223. [Google Scholar]
- Tawkat Islam Khondaker, M.; Waheed, A.; Moatez Billah Nagoudi, E.; Abdul-Mageed, M. GPTAraEval: A Comprehensive Evaluation of ChatGPT on Arabic NLP. arXiv 2023, arXiv:2305.14976. [Google Scholar]
- Alderazi, F.; Algosaibi, A.; Alabdullatif, M.; Ahmad, H.F.; Qamar, A.M.; Albarrak, A. Generative artificial intelligence in topic-sentiment classification for Arabic text: A comparative study with possible future directions. PeerJ Comput. Sci. 2024, 10, e2081. [Google Scholar] [CrossRef]
- Oreščanin, D.; Hlupić, T.; Vrdoljak, B. Managing Personal Identifiable Information in Data Lakes. IEEE Access 2024, 12, 32164–32180. [Google Scholar] [CrossRef]
- Olabanji, S.O.; Oladoyinbo, O.B.; Asonze, C.U.; Oladoyinbo, T.O.; Ajayi, S.A.; Olaniyi, O.O. Effect of adopting AI to explore big data on personally identifiable information (PII) for financial and economic data transformation. Asian J. Econ. Bus. Account. 2024, 24, 106–125. [Google Scholar] [CrossRef]
- Bird, S. NLTK: The natural language toolkit. In Proceedings of the COLING/ACL 2006 Interactive Presentation Sessions, Sydney, Australia, 17–18 July 2006; pp. 69–72. [Google Scholar]
- Yamamoto, M.; Church, K.W. Using suffix arrays to compute term frequency and document frequency for all substrings in a corpus. Comput. Linguist. 2001, 27, 1–30. [Google Scholar] [CrossRef]
- Razali, M.N.; Arbaiy, N.; Lin, P.C.; Ismail, S. Optimizing Multiclass Classification Using Convolutional Neural Networks with Class Weights and Early Stopping for Imbalanced Datasets. Electronics 2025, 14, 705. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Grattafiori, A.; Dubey, A.; Jauhri, A.; Pandey, A.; Kadian, A.; Al-Dahle, A.; Letman, A.; Mathur, A.; Schelten, A.; Vaughan, A.; et al. The llama 3 herd of models. arXiv 2024, arXiv:2407.21783. [Google Scholar]
- Kaliappan, J.; Bagepalli, A.R.; Almal, S.; Mishra, R.; Hu, Y.C.; Srinivasan, K. Impact of Cross-validation on Machine Learning models for early detection of intrauterine fetal demise. Diagnostics 2023, 13, 1692. [Google Scholar] [CrossRef]
- Rasool, A.; Shahzad, M.I.; Aslam, H.; Chan, V.; Arshad, M.A. Emotion-Aware Embedding Fusion in Large Language Models (Flan-T5, Llama 2, DeepSeek-R1, and ChatGPT 4) for Intelligent Response Generation. AI 2025, 6, 56. [Google Scholar] [CrossRef]



| Label | Review (Arabic) | Translation (English) |
|---|---|---|
| Positive |  | A very distinguished bank in its transactions and speed of accomplishments. I recommend dealing with it because of the ease of the matter. |
| Negative |  | Bad app. If I enter my information and complete everything correctly, in the end it logs me out of the app more than 20 times. |
| Conflict |  | Excellent but a bit heavy |
| Prompt Setting | Template Prompt |
|---|---|
| Zero-Shot | Analyse the sentiment of the reviews written in Arabic language above and return a JSON array as the result. In your output, only return the sentiment for each review as ‘positive’, ‘negative’, and ‘conflict’. Do not include any other sentiment. |
| Few-Shot | Analyse the sentiment of the reviews written in Arabic language above and return a JSON array as the result. In your output, only return the sentiment for each review as ‘positive’, ‘negative’, and ‘conflict’. Do not include any other sentiment. Examples of good sentiment-analysis classification are provided between separator “###”. ### Review: positive train review ; Sentiment: positive Review: negative train review ; Sentiment: negative Review: conflict train review ; Sentiment: conflict ### |
| Model Name | Class-Weighted | Accuracy | F1 | R | P |
|---|---|---|---|---|---|
| XGBoost | Without | 89.15 | 88.68 | 89.15 | 88.75 |
| With | 89.37 | 89.47 | 89.37 | 89.65 | |
| RF | Without | 89.23 | 87.26 | 89.23 | 85.40 |
| With | 88.89 | 86.93 | 88.89 | 85.10 | |
| DT | Without | 87.06 | 86.82 | 87.06 | 86.86 |
| With | 86.47 | 86.91 | 86.47 | 87.68 | |
| LR | Without | 89.86 | 87.92 | 89.86 | 87.82 |
| With | 89.56 | 89.66 | 89.56 | 90.15 | |
| SVM | Without | 90.45 | 89.12 | 90.45 | 89.98 |
| With | 89.60 | 89.98 | 89.60 | 90.73 | |
| Voting Classifier | Without | 90.00 | 88.20 | 90.00 | 89.39 |
| With | 90.24 | 90.20 | 90.24 | 90.50 |
| Model Name | Prompt Type | Accuracy | F1 | P | R |
|---|---|---|---|---|---|
| GPT 3.5 | Zero-shot | 54.12 | 52.67 | 54.33 | 54.00 |
| Few-shot | 63.22 | 63.00 | 63.00 | 63.00 | |
| GPT 4 | Zero-shot | 79.78 | 78.00 | 82.67 | 80.00 |
| Few-shot | 82.76 | 82.33 | 83.00 | 83.00 | |
| Llama-3-8B-Instruct | Zero-shot | 62.22 | 51.34 | 44.30 | 62.22 |
| Few-shot | 77.78 | 78.73 | 82.59 | 77.78 | |
| SILMA-9B-Instruct—English | Zero-shot | 64.44 | 51.89 | 43.44 | 64.44 |
| Few-shot | 33.33 | 16.67 | 11.11 | 33.33 | |
| SILMA-9B-Instruct—Arabic | Zero-shot | 68.89 | 62.99 | 73.92 | 68.89 |
| Few-shot | 81.11 | 80.64 | 82.31 | 81.11 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alawaji, R.; Aloraini, A. Sentiment Analysis of Digital Banking Reviews Using Machine Learning and Large Language Models. Electronics 2025, 14, 2125. https://doi.org/10.3390/electronics14112125
Alawaji R, Aloraini A. Sentiment Analysis of Digital Banking Reviews Using Machine Learning and Large Language Models. Electronics. 2025; 14(11):2125. https://doi.org/10.3390/electronics14112125
Chicago/Turabian StyleAlawaji, Raghad, and Abdulrahman Aloraini. 2025. "Sentiment Analysis of Digital Banking Reviews Using Machine Learning and Large Language Models" Electronics 14, no. 11: 2125. https://doi.org/10.3390/electronics14112125
APA StyleAlawaji, R., & Aloraini, A. (2025). Sentiment Analysis of Digital Banking Reviews Using Machine Learning and Large Language Models. Electronics, 14(11), 2125. https://doi.org/10.3390/electronics14112125