Accelerating CRYSTALS-Kyber: High-Speed NTT Design with Optimized Pipelining and Modular Reduction



Abstract
1. Introduction
1.1. Motivation for CRYSTALS-Kyber and the Importance of Hardware-Optimized Number Theoretic Transform
1.2. Advances in NTT Hardware Accelerators: Enhancing Efficiency and Flexibility for CRYSTALS-Kyber and Beyond
1.3. Limitations in Existing NTT Accelerator Designs: Challenges and Opportunities for Improvement
1.4. Proposed High-Speed NTT Accelerator for CRYSTALS-Kyber: Innovations in Modular Reduction and Pipelining
- Optimized Barrett Reduction Architecture with Shift-Add Operations: The modular reduction operation is redesigned to eliminate integer multipliers, replacing them with lightweight shift-add circuits. This novel approach significantly reduces the critical path delay and minimizes hardware resource utilization while enhancing circuit operating frequencies. By eliminating DSP dependency, the architecture achieves greater area efficiency on FPGA devices. Details are in Section 3.3.
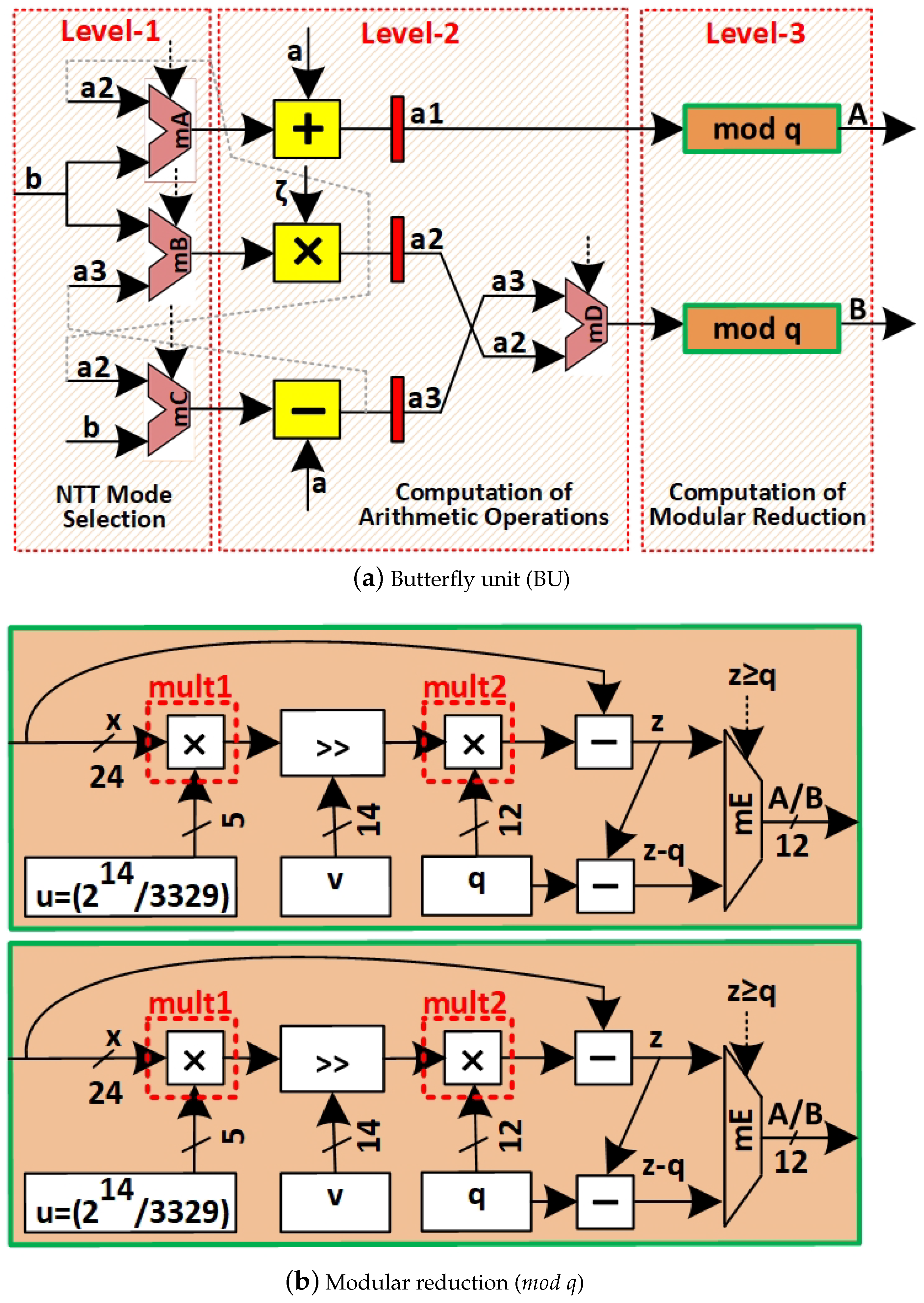
- Pipelined Unified Butterfly Unit Architecture: A dual-stage pipelined butterfly unit is designed to perform both forward NTT (FNTT) and inverse NTT (INTT) computations within a single framework, employing Cooley–Tukey and Gentleman–Sande configurations. This design improves computational throughput, reduces processing latency, and optimizes memory access for efficient data flow. The corresponding details are given in Section 3.2.
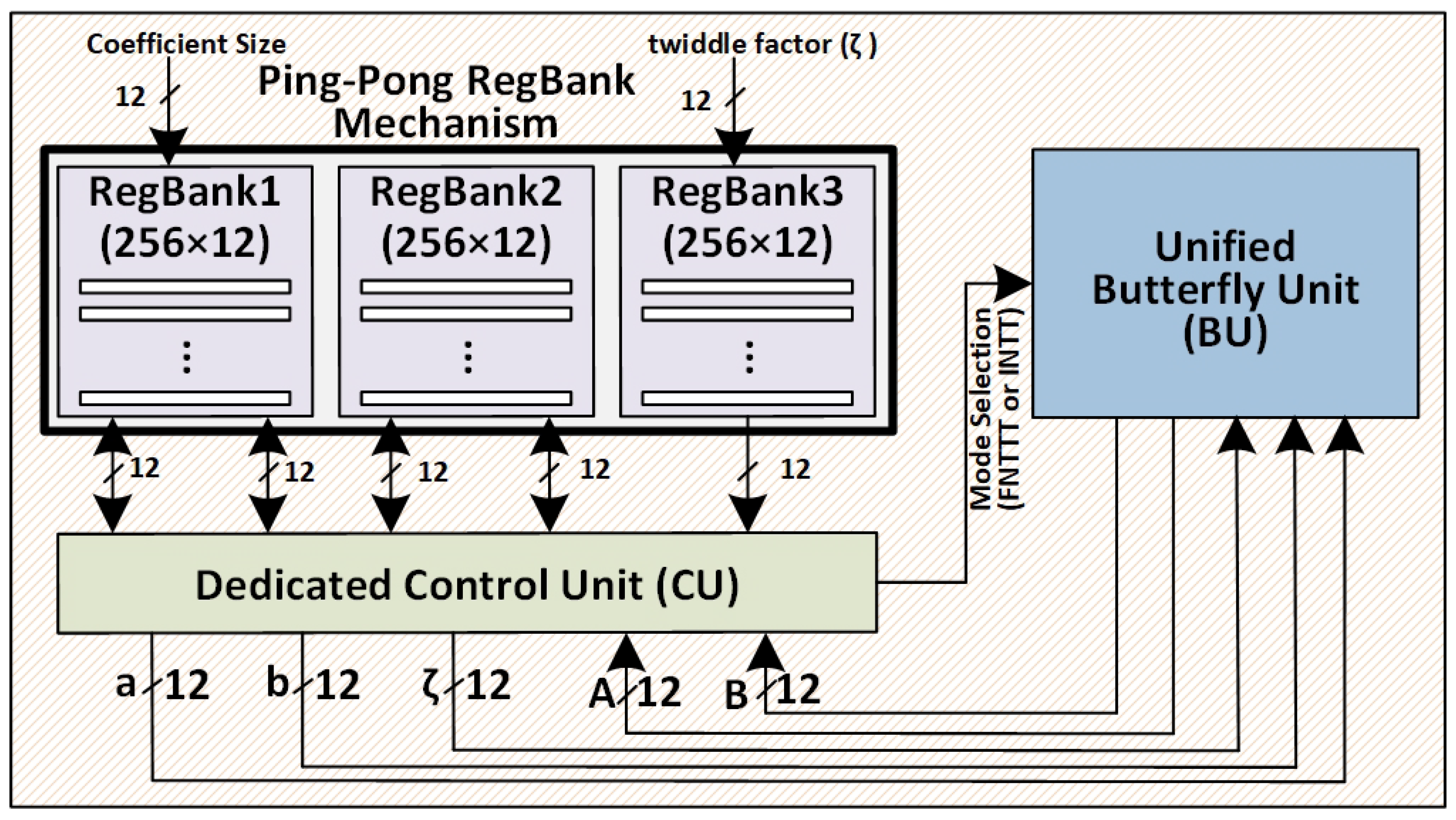
- Integration of RegBanks for Continuous Data Processing: Three register banks (RegBanks) are utilized to manage input, intermediate, and precomputed data, enabling seamless ping-pong memory access and eliminating idle cycles. This mechanism ensures parallel processing and supports scalable computations (see Section 3).
- Performance Evaluation and Benchmarking: The proposed NTT accelerator architecture has been implemented in Verilog HDL and synthesized using Vivado v.2023. Performance evaluations were conducted on three FPGA platforms: Virtex-5, Virtex-6, and Virtex-7, with detailed resource utilization reported as follows: 2604 slices, 7141 LUTs, and 7332 FFs for Virtex-5; 2865 slices, 7856 LUTs, and 8066 FFs for Virtex-6; and 3152 slices, 8642 LUTs, and 8873 FFs for Virtex-7. The accelerator executes FNTT and INTT computations within 898 clock cycles, excluding coefficient loading into or from memories. In terms of operating frequency, the Virtex-7 implementation achieves significant speed improvements, operating at 261 MHz, compared to 179 MHz and 209 MHz on Virtex-5 and Virtex-6, respectively. This results in a computation time that is 1.45× faster than Virtex-5 and 1.24× faster than Virtex-6. Similarly, throughput evaluations reveal that the Virtex-7 achieves a remarkable value of 290.69 Kbps, which is 1.45× higher than Virtex-5 and 1.24× higher than Virtex-6. Notably, the Virtex-7 design delivers the highest throughput-per-slice metric of 111.63, emphasizing its efficiency in resource utilization for FNTT and INTT computations. These results underscore the superior performance of the proposed accelerator architecture, making it highly effective for high-speed cryptographic applications (details are in Section 4).
2. Mathematical Background
| Algorithm 1 Iterative NTT Algorithm [31] |
|
3. Proposed NTT Architecture
3.1. Ping-Pong RegBank Mechanism for Parallel FNTT and INTT Processing
3.2. Unified Butterfly Unit (BU)
3.3. Optimized Barrett Reduction: Shift-Add Circuits and Architectural Design
| Algorithm 2 General Barrett reduction Algorithm (taken from [19]) |
| Algorithm 3 Optimized Barrett reduction algorithm for CRYSTALS-Kyber |
|
3.4. Efficient Addressing and Signal Management Through an FSM-Based Control Unit
- Initial data loading: To load 256 input coefficients for the FNTT or INTT computations, a total of 256 clock cycles is required—one cycle per coefficient.
- Processing stages: For CRYSTALS-Kyber, which entails stages (where ), the computations require 896 clock cycles. An additional 2 clock cycles account for the pipeline registers—one for filling and one for clearing the pipeline—bringing the total to 898 clock cycles for these stages.
- Initial data loading: 256 cycles
- Processing (FNTT or INTT): 898 cycles
- Data transfer to output pins: 256 cycles
4. Implementation Results and Comparisons
4.1. Implementation Results
4.2. Comparisons to Existing NTT Accelerators
4.2.1. Comparison of NTT Accelerators (Single Butterfly Unit)
4.2.2. Comparison of NTT Accelerators (Multiple Butterfly Units)
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Rashid, M.; Imran, M.; Jafri, A.R.; Al-Somani, T.F. Flexible architectures for cryptographic algorithms—A systematic literature review. J. Circuits Syst. Comput. 2019, 28, 1930003. [Google Scholar] [CrossRef]
- Shor, P.W. Polynomial-Time Algorithms for Prime Factorization and Discrete Logarithms on a Quantum Computer. SIAM J. Comput. 1997, 26, 1484–1509. [Google Scholar] [CrossRef]
- Arya, K.; Babbush, R.; Bacon, D.; Bardin, J.C.; Barends, R.; Biswas, R.; Boixo, S.; Brandao, F.G.; Buell, D.A.; Burkett, B. Quantum supremacy using a programmable superconducting processor. Nature 2019, 574, 505–510. [Google Scholar] [CrossRef]
- Gong, M.; Wang, S.; Zha, C.; Chen, M.C.; Huang, H.L.; Wu, Y.; Zhu, Q.; Zhao, Y.; Li, S.; Guo, S.; et al. Quantum walks on a programmable two-dimensional 62-qubit superconducting processor. Science 2021, 372, 948–952. [Google Scholar] [CrossRef] [PubMed]
- National Institute of Standards and Technology. NIST to Standardize Encryption Algorithms That Can Resist Attack by Quantum Computers. Available online: https://csrc.nist.gov/projects/post-quantum-cryptography (accessed on 26 March 2025).
- National Institute of Standards and Technology. FIPS 203: Module-Lattice-Based Key-Encapsulation Mechanism Standard. Federal Information Processing Standards Publication. Available online: https://nvlpubs.nist.gov/nistpubs/FIPS/NIST.FIPS.203.ipd.pdf (accessed on 26 March 2025).
- National Institute of Standards and Technology. FIPS 204: Module-Lattice-Based Digital Signature Standard. Federal Information Processing Standards Publication. Available online: https://nvlpubs.nist.gov/nistpubs/FIPS/NIST.FIPS.204.ipd.pdf (accessed on 26 March 2025).
- Fouque, P.A.; Hoffstein, J.; Kirchner, P.; Lyubashevsky, V.; Pornin, T.; Prest, T.; Ricosset, T.; Seiler, G.; Whyte, W.; Zhang, Z. Falcon: Fast-Fourier Lattice-Based Compact Signatures over NTRU Specifications v1.1. Available online: https://falcon-sign.info (accessed on 26 March 2025).
- National Institute of Standards and Technology. FIPS 205: Stateless Hash-Based Digital Signature Standard. Federal Information Processing Standards Publication. Available online: https://nvlpubs.nist.gov/nistpubs/FIPS/NIST.FIPS.205.ipd.pdf (accessed on 26 March 2025).
- Imran, M.; Abideen, Z.U.; Pagliarini, S. An Experimental Study of Building Blocks of Lattice-Based NIST Post-Quantum Cryptographic Algorithms. Electronics 2020, 9, 1953. [Google Scholar] [CrossRef]
- Rashid, M.; Sonbul, O.S.; Jamal, S.S.; Jaffar, A.Y.; Kakhorov, A. A Pipelined Hardware Design of FNTT and INTT of CRYSTALS-Kyber PQC Algorithm. Information 2024, 16, 17. [Google Scholar] [CrossRef]
- Satriawan, A.; Syafalni, I.; Mareta, R.; Anshori, I.; Shalannanda, W.; Barra, A. Conceptual Review on Number Theoretic Transform and Comprehensive Review on Its Implementations. IEEE Access 2023, 11, 70288–70316. [Google Scholar] [CrossRef]
- Boussakta, S.; Holt, A.G.J. Number Theoretic Transforms and their Applications in Image Processing. Adv. Imaging Electron. Phys. 1999, 111, 1–90. [Google Scholar]
- Zhou, R.; Wen, J.; Zou, Y.; Wang, A.; Hua, J.; Sheng, B. Enhanced image compression method exploiting NTT for internet of thing. Int. J. Circuit Theory Appl. 2023, 51, 1879–1892. [Google Scholar] [CrossRef]
- Abdelmonem, M.; Holzbaur, L.; Raddum, H.; Zeh, A. Efficient Error Detection Methods for the Number Theoretic Transforms in Lattice-Based Algorithms. Cryptology ePrint Archive, Paper 2025/170. 2025. Available online: https://eprint.iacr.org/2025/170 (accessed on 21 May 2025).
- Brier, E.; Coron, J.S.; Géraud, R.; Maimut, D.; Naccache, D. A Number-Theoretic Error-Correcting Code. arXiv 2015, arXiv:1509.00378. [Google Scholar]
- Zhang, C.; Liu, D.; Liu, X.; Zou, X.; Niu, G.; Liu, B.; Jiang, Q. Towards Efficient Hardware Implementation of NTT for Kyber on FPGAs. In Proceedings of the 2021 IEEE International Symposium on Circuits and Systems (ISCAS), Daegu, Republic of Korea, 22–28 May 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Chen, Z.; Ma, Y.; Chen, T.; Lin, J.; Jing, J. Towards Efficient Kyber on FPGAs: A Processor for Vector of Polynomials. In Proceedings of the 2020 25th Asia and South Pacific Design Automation Conference (ASP-DAC), Beijing, China, 13–16 January 2020; pp. 247–252. [Google Scholar] [CrossRef]
- Khan, S.; Khalid, A.; Rafferty, C.; Shah, Y.A.; O’Neill, M.; Lee, W.K.; Hwang, S.O. Efficient, Error-Resistant NTT Architectures for CRYSTALS-Kyber FPGA Accelerators. In Proceedings of the 2023 IFIP/IEEE 31st International Conference on Very Large Scale Integration (VLSI-SoC), Dubai, United Arab Emirates, 16–18 October 2023; IEEE: New York, NY, USA, 2023; pp. 1–6. [Google Scholar]
- Imran, M.; Khan, S.; Khalid, A.; Rafferty, C.; Shah, Y.A.; Pagliarini, S.; Rashid, M.; O’Neill, M. Evaluating NTT/INTT Implementation Styles for Post-Quantum Cryptography. IEEE Embed. Syst. Lett. 2024, 16, 485–488. [Google Scholar] [CrossRef]
- Botros, L.; Kannwischer, M.J.; Schwabe, P. Memory-efficient high-speed implementation of Kyber on Cortex-M4. In Proceedings of the Progress in Cryptology—AFRICACRYPT 2019: 11th International Conference on Cryptology in Africa, Rabat, Morocco, 9–11 July 2019; Proceedings 11. Springer: Cham, Switzerland, 2019; pp. 209–228. [Google Scholar]
- Bisheh-Niasar, M.; Azarderakhsh, R.; Mozaffari-Kermani, M. High-Speed NTT-based Polynomial Multiplication Accelerator for Post-Quantum Cryptography. In Proceedings of the 2021 IEEE 28th Symposium on Computer Arithmetic (ARITH), Lyngby, Denmark, 14–16 June 2021; pp. 94–101. [Google Scholar] [CrossRef]
- Yaman, F.; Mert, A.C.; Öztürk, E.; Savaş, E. A Hardware Accelerator for Polynomial Multiplication Operation of CRYSTALS-KYBER PQC Scheme. In Proceedings of the 2021 Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 1–5 February 2021; pp. 1020–1025. [Google Scholar] [CrossRef]
- Saoudi, M.; Kermiche, A.; Benhaddad, O.H.; Guetmi, N.; Allailou, B. Low latency FPGA implementation of NTT for Kyber. Microprocess. Microsyst. 2024, 107, 105059. [Google Scholar] [CrossRef]
- Xu, C.; Yu, H.; Xi, W.; Zhu, J.; Chen, C.; Jiang, X. A Polynomial Multiplication Accelerator for Faster Lattice Cipher Algorithm in Security Chip. Electronics 2023, 12, 951. [Google Scholar] [CrossRef]
- Derya, K.; Mert, A.C.; Öztürk, E.; Savaş, E. CoHA-NTT: A Configurable Hardware Accelerator for NTT-based Polynomial Multiplication. Microprocess. Microsyst. 2022, 89, 104451. [Google Scholar] [CrossRef]
- Mert, A.C.; Öztürk, E.; Savaş, E. FPGA implementation of a run-time configurable NTT-based polynomial multiplication hardware. Microprocess. Microsyst. 2020, 78, 103219. [Google Scholar] [CrossRef]
- Rashid, M.; Khan, S.; Sonbul, O.S.; Hwang, S.O. A Flexible and Parallel Hardware Accelerator for Forward and Inverse Number Theoretic Transform. IEEE Access 2024, 12, 181351–181361. [Google Scholar] [CrossRef]
- Aguilar-Melchor, C.; Barrier, J.; Guelton, S.; Guinet, A.; Killijian, M.O.; Lepoint, T. NFLlib: NTT-based fast lattice library. In Proceedings of the Cryptographers’ Track at the RSA Conference, San Francisco, CA, USA, 29 February–4 March 2016; Springer: Cham, Switzerland, 2016; pp. 341–356. [Google Scholar]
- Imran, M.; Abideen, Z.U.; Pagliarini, S. An open-source library of large integer polynomial multipliers. In Proceedings of the 2021 24th International Symposium on Design and Diagnostics of Electronic Circuits & Systems (DDECS), Vienna, Austria, 7–9 April 2021; IEEE: New York, NY, USA, 2021; pp. 145–150. [Google Scholar]
- Aikata, A.; Mert, A.C.; Imran, M.; Pagliarini, S.; Roy, S.S. KaLi: A Crystal for Post-Quantum Security Using Kyber and Dilithium. IEEE Trans. Circuits Syst. I Regul. Pap. 2023, 70, 747–758. [Google Scholar] [CrossRef]
- Fritzmann, T.; Sigl, G.; Sepúlveda, J. RISQ-V: Tightly Coupled RISC-V Accelerators for Post-Quantum Cryptography. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2020, 2020, 239–280. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
| Device | Operation | Hardware Utilizations | Timing-Related Results | TP | TP/Slices | ||||
|---|---|---|---|---|---|---|---|---|---|
| Slices | LUTs | FFs | CCs | Freq. (MHz) | Latency (μs) | (Kbps) | |||
| Virtex-5 | FNTT + INTT | 3152 | 8642 | 8873 | 898 | 179 | 5.01 | 199.60 | 63.32 |
| Virtex-6 | FNTT + INTT | 2865 | 7856 | 8066 | 898 | 209 | 4.29 | 233.10 | 81.36 |
| Virtex-7 | FNTT + INTT | 2604 | 7141 | 7332 | 898 | 261 | 3.44 | 290.69 | 111.63 |
| Designs/Year | Device | NTT | Hardware Area | Timing-Related Results | Butterfly | |||
|---|---|---|---|---|---|---|---|---|
| Type | LUTs | FFs | CCs | Freq. (MHz) | Latency (μs) | Units (BUs) | ||
| [19]/2023 | Virtex-7 | FNTT | 7800 | – | – | 72 | – | 1 |
| [20]/2024 | Virtex-7 | FNTT + INTT | 9298 | 9402 | 898 | 20 | 44.90 | 1 |
| [23]/2021 | Artix-7 | FNTT + INTT | 948 | 352 | 904 | 190 | 4.75 | 1 |
| [26]/2022 | Virtex-7 | FNTT | 2128 | 1144 | 922 | 174 | 5.29 | 1 |
| INTT | 1184 | 6.80 | ||||||
| [28]/2024 | Virtex-7 | FNTT | 2018 | 1829 | 1154 | 250 | 4.61 | 1 |
| INTT | 1282 | 5.12 | ||||||
| [32]/2020 | ZynQ-7000 | FNTT | 2908 | 170 | 1935 | 45 | 43 | 1 |
| INTT | 1930 | 42.88 | ||||||
| [17]/2021 | Artix-7 | FNTT + INTT | 609 | 640 | 490 | 257 | 1.9 | 2 |
| [23]/2021 | Artix-7 | FNTT + INTT | 2543 | 792 | 232 | 182 | 1.27 | 4 |
| [23]/2021 | Artix-7 | FNTT + INTT | 9508 | 2684 | 69 | 172 | 0.40 | 16 |
| [24]/2024 | Artix-7 | FNTT | 18,296 | 12,134 | 85 | 210 | 0.40 | 64 |
| INTT | 104 | 0.5 | ||||||
| This Work (TW) | Virtex-7 | FNTT + INTT | 7141 | 7332 | 898 | 261 | 3.44 | 1 |
| Artix-7 | FNTT + INTT | 6841 | 6982 | 898 | 249 | 3.72 | 1 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sonbul, O.S.; Rashid, M.; Jaffar, A.Y. Accelerating CRYSTALS-Kyber: High-Speed NTT Design with Optimized Pipelining and Modular Reduction. Electronics 2025, 14, 2122. https://doi.org/10.3390/electronics14112122
Sonbul OS, Rashid M, Jaffar AY. Accelerating CRYSTALS-Kyber: High-Speed NTT Design with Optimized Pipelining and Modular Reduction. Electronics. 2025; 14(11):2122. https://doi.org/10.3390/electronics14112122
Chicago/Turabian StyleSonbul, Omar S., Muhammad Rashid, and Amar Y. Jaffar. 2025. "Accelerating CRYSTALS-Kyber: High-Speed NTT Design with Optimized Pipelining and Modular Reduction" Electronics 14, no. 11: 2122. https://doi.org/10.3390/electronics14112122
APA StyleSonbul, O. S., Rashid, M., & Jaffar, A. Y. (2025). Accelerating CRYSTALS-Kyber: High-Speed NTT Design with Optimized Pipelining and Modular Reduction. Electronics, 14(11), 2122. https://doi.org/10.3390/electronics14112122