5.4.1. Performance of Different Generative Models at Different Scales
This study reproduces SMOTE, CTGAN, and CTABGAN under consistent experimental conditions, including the same dataset, preprocessing steps, and detection model, and compares them with the proposed M2M-VAEGAN on a CNN-based multi-classification task. Four generation strategies were explored, generating 10,000, 5000, 2000/5000, and 1000/3000 samples for the U2R and R2L classes, respectively, to systematically evaluate the impact of sample size on model performance.
Table 8,
Table 9,
Table 10 and
Table 11 present the performance of each model at different sample sizes, and
Table 12 summarizes the best results, offering a clear comparison of overall performance. Key metrics such as recall, F1-score, and G-means highlight the effectiveness of the generation models in enhancing the detection of minority classes within the CNN framework.
In
Table 8, SMOTE achieves its best performance across all metrics—Precision, Recall, F1-score, G-means, and Accuracy—when generating 5000 samples for both U2R and R2L. However, increasing the sample size to 10,000 results in a notable decline, with F1-score dropping by 2.3%, indicating that the linear interpolation mechanism is sensitive to noise. Conversely, generating fewer samples (e.g., U2R: 2000) leads to reduced performance due to insufficient data coverage.
In
Table 9, CTGAN achieves a Precision of 86.02% at Both-10,000, but Recall is limited to 80.68%. This suggests that while the generated samples improve detection precision, the model struggles to effectively generate minority class samples. When the generation ratio is balanced at U2R:2000 and R2L:5000, G-means increases to 84.96%, highlighting the importance of maintaining a balanced generation strategy.
In
Table 10, CTABGAN enhances CTGAN by incorporating a semantic classifier. The model achieves the best overall performance under the Both-5000 setting, with the highest G-means of 85.36% and F1-score of 81.14%. Although the semantic classifier helps to mitigate generation drift, generating excessive samples at the Both-10,000 setting results in a decline in the F1-score to 80.00%.
Table 11 shows that M2M-VAEGAN achieves its highest Precision of 83.31% and F1-score of 82.40% under the U2R 1000 and R2L 3000 settings. The model also demonstrates strong performance in G-means at 85.96% and Accuracy at 82.93%. Variations in the number of generated samples have minimal impact on performance, with F1-score fluctuations remaining below 0.4%. The model effectively combines its cross-category generation strategy with the VGM module to integrate majority-class knowledge while preserving the multimodal distribution of minority classes.
Table 12 provides a clear comparison of the overall performance of different generation models at their optimal sampling levels. M2M-VAEGAN-IDS demonstrates the best overall performance, achieving the highest Recall at 82.93%, F1-score at 82.40%, and G-means at 85.96%, making it well-suited for scenarios requiring balanced detection of majority and minority classes. CTGAN stands out in precision, with a Precision of 86.02%, making it a suitable choice for tasks sensitive to false positives, though its capability for minority class detection is limited. SMOTE and CTABGAN deliver moderate performance but significantly outperform the baseline CNN. This comparative analysis highlights the applicability of generation models in different contexts: CTGAN is preferable for high-precision needs, while M2M-VAEGAN is the optimal choice for balanced performance. Additionally, the study explores the complex relationship between the number of generated samples and model performance across different generation models.
To maintain brevity,
Table 13 presents the results of different generation models at their optimal sampling levels on the CIC-IDS2017 dataset.
SMOTE showed a slight improvement in precision at 98.94% when generating 20,000 samples, while maintaining a high F1-score at 98.89% and recall at 98.87%. This indicates that SMOTE is effective in balancing class distribution. However, increasing the sample size further yielded limited performance gains, showing no significant improvement overall.
CTGAN performed less effectively on CIC-IDS2017 compared to NSL-KDD. With 10,000 generated samples, it achieved a precision of 98.41%, but recall slightly declined, and G-means dropped significantly to 97.10%.
CTABGA achieved its best results with 15,000 generated samples, where precision and recall were comparable to the CNN baseline at 98.88% and 98.85%, respectively, with a minor increase in G-means to 98.68%. However, the overall improvement remained modest.
M2M-VAEGAN demonstrated outstanding performance with 10,000 generated samples, achieving Precision, Recall, and F1-score of 99.46% and a G-means of 99.54%. These results highlight M2M-VAEGAN’s ability to generate high-quality balanced samples, effectively aligning the minority class distribution with the real data and significantly improving overall model performance.
The performance differences of generative models between the smaller-scale NSL-KDD dataset with 41 features and the larger-scale CIC-IDS2017 dataset with 78 features highlight their varying adaptability to high-dimensional data. SMOTE, which relies on linear interpolation, struggles to capture the complex class distributions in CIC-IDS2017, resulting in limited performance improvements. CTGAN and CTABGAN, faced with the eight attack classes in CIC-IDS2017, require more robust conditional constraints, leading to less pronounced effectiveness compared to their performance on NSL-KDD. While the semantic classifier in CTABGAN enhances generative performance, its impact on CIC-IDS2017 remains limited.
In contrast, M2M-VAEGAN’s cross-class generation mechanism effectively incorporates majority-class features, significantly improving the diversity and realism of minority class samples. This enhances the classifier’s ability to recognize minority classes. Furthermore, the combination of VAE and GAN not only preserves sample diversity but also optimizes sample quality through ACGAN, thereby delivering superior performance.
5.4.2. Ablation Experiment
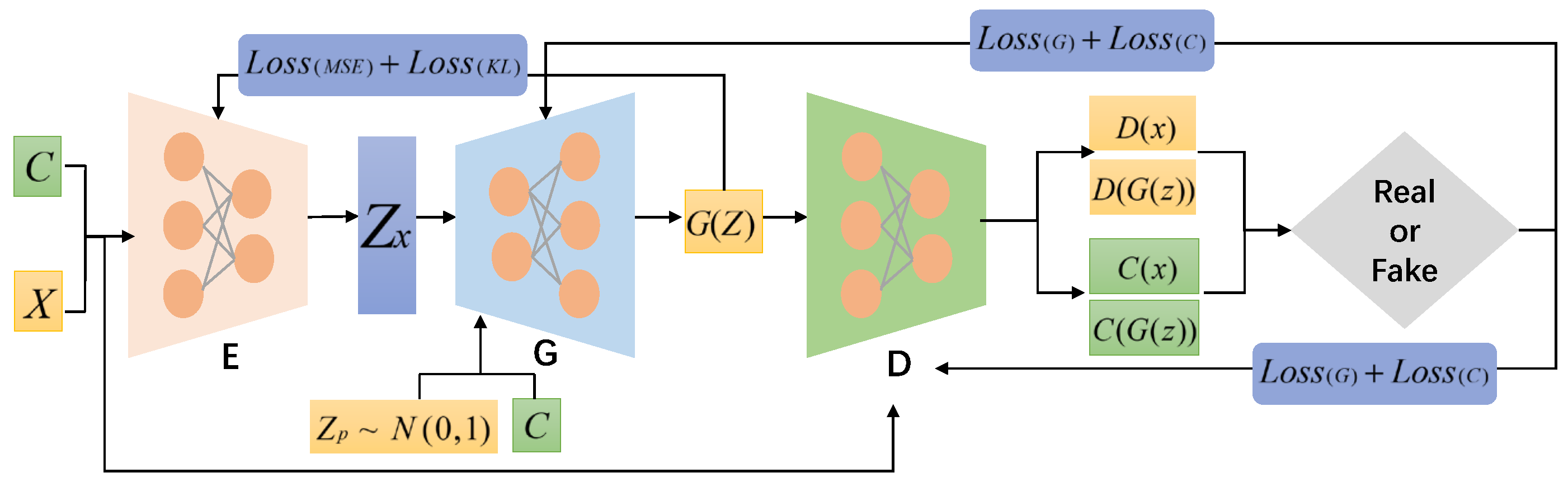
This study includes ablation experiments to evaluate the contribution of key components in the M2M-VAEGAN model, including the pre-training–fine-tuning strategy (P&F), auxiliary classifier (AC), and VGM.
Table 14 and
Table 15 present the performance comparisons on the NSL-KDD and CIC-IDS2017 datasets, respectively.
In the NSL-KDD dataset, incorporating the P&F-VAEGAN model improved the F1-score by 1.22%, with Recall reaching 78.92%, indicating that pre-training and finetuning contribute to generating more accurate minority class samples. Adding the auxiliary classifier (P&F-VAEGAN-AC) further increased Recall to 79.66% and significantly boosted the G-means to 83.37%, highlighting the classifier’s importance in minority class recognition. The VGM-P&F-VAEGAN model showed limited gains in low-dimensional feature scenarios, with an F1-score of 78.77%, suggesting a lower need for complex distribution modeling. Ultimately, the combined model integrating VGM, P&F-VAEGAN, and the auxiliary classifier (VGM-P&F-VAEGAN-AC) achieved the best performance, significantly enhancing G-means and overall effectiveness.
In the CIC-IDS2017 dataset, P&F-VAEGAN improved both precision and recall, demonstrating its effectiveness in generating balanced samples. Adding the auxiliary classifier (P&F-VAEGAN-AC) boosted G-means to 99.44%, emphasizing the classifier’s crucial role in maintaining semantic consistency for high-dimensional features. Although VGM preprocessing improved precision and recall, it led to a decrease in G-means, indicating that the complexity of high-dimensional data requires additional balancing methods. Ultimately, the VGM-P&F-VAEGAN-AC model achieved the best performance, further enhancing the model’s ability to address class imbalance.
The improvement from CNN to P&F-VAEGAN demonstrates that the generative model effectively mitigates class imbalance issues. With the addition of the auxiliary classifier, recall and F1-score were significantly enhanced, improving the model’s ability to identify minority class samples. VGM preprocessing improved model performance in some cases, but it also had some impact on balancing precision and recall. Ultimately, the combination of all modules greatly boosted the model’s performance across both datasets, particularly in addressing class imbalance, and significantly enhanced the model’s generalization ability and overall performance.
5.4.3. Model Complexity
In the comparison of generative models, model complexity directly impacts computational resource consumption and runtime efficiency. Since SMOTE is not a neural network model, it is not included in this comparison. We focus on comparing three generative models: CTGAN, CTABGAN, and M2M-VAEGAN, and concentrate solely on the complexity of the generative models, excluding the computational cost of subsequent classification tasks. The complexity is typically measured by two indicators: (1) FLOPs, which represent the computational complexity of a single forward pass, reflecting the demand on hardware resources; (2) the number of parameters, which indicates the total number of trainable parameters in the model, reflecting the storage complexity and the risk of overfitting. The experimental results are shown in the
Table 16.
The discriminator and generator of CTGAN consist of fully connected layers, with the layer dimensions of both the generator and discriminator fixed, regardless of the input feature dimensions. As a result, the number of parameters and FLOPs remain consistent across both high-dimensional and low-dimensional datasets. The CTABGAN model converts tabular data into images, causing FLOPs to increase quadratically with input dimensions. For NSL-KDD, with one-hot encoding resulting in 123 dimensions, FLOPs reach approximately 6.0 G, while for CIC-IDS2017, with 78 input dimensions, FLOPs drop to around 3.1G. In M2M-VAEGAN, the model structure consists of 1D convolution and fully connected layers, and its complexity is linearly related to the input dimensions. For NSL-KDD, the model has 5.2 M parameters and 18M FLOPs. For CIC-IDS2017, the parameters decrease to 3.3 M (a 37% reduction) and FLOPs to 10 M (a 44% reduction).
Thus, CTGAN is suitable for high-dimensional data and resource-limited scenarios. CTABGAN is more appropriate for low-dimensional data, particularly in tasks where high generation quality is required. M2M-VAEGAN strikes a good balance between complexity and performance and performs excellently in comparison experiments. Furthermore, if training a generative model is not required, the traditional SMOTE method remains the preferred choice.
5.4.4. Comprehensive Evaluation Compared with Other IDS
In the comparison with other IDS models (see
Section 2.1), we used the NSL-KDD and CIC-IDS2017 datasets and referenced performance metrics reported in the related literature to produce the experimental results shown in
Table 17 and
Table 18. All compared methods employed data augmentation techniques to improve intrusion detection performance, ensuring consistency in the technical background and research objectives of the experiments. Additionally, we consistently adopted Precision, Recall, F1-score, and Accuracy as evaluation metrics and carefully selected studies with detailed experimental setups and well-documented data sources to ensure the credibility and comparability of the results.
In
Table 16, the performance of M2M-VAEGAN-IDS on the NSL-KDD dataset is well-balanced, with Recall of 82.93% and F1-score of 82.40%, significantly outperforming other models. This indicates that it demonstrates a balanced classification ability for both majority and minority classes. In comparison to KGMS-IDS, although KGMS-IDS has a higher Accuracy of 86.39%, its Recall of 70.22% and F1-score of 71.49% are lower, suggesting that the model may be overly biased toward the majority class. The F1-score of KGMS-IDS is higher than that of our model, but its Recall is noticeably lower, indicating that its overall performance is not sufficient to handle complex class imbalance tasks. This suggests that M2M-VAEGAN-IDS still has room for improvement.
In the CIC-IDS2017 dataset, M2M-VAEGAN-IDS stands out with an Accuracy of 99.46%, Recall of 99.45%, and F1-score of 99.45%, outperforming all the other models and demonstrating exceptional overall performance. Transformer-CNN shows slightly lower Accuracy of 99.22% and Recall of 99.13%, indicating that its generated data quality is somewhat insufficient. However, it still performs better than other models.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}