1. Introduction
Smart meters can collect real-time electricity consumption data from users, providing decision support for electric companies in areas such as load forecasting, energy optimization, and demand response [
1]. How to efficiently and accurately analyze these electricity consumption data to extract valuable information has become a key challenge [
2,
3]. Clustering analysis, as a key method in data analysis, can group electricity consumption data based on specific similarity metrics, helping electric companies classify user groups and provide personalized services and energy-saving recommendations [
4,
5]. Therefore, clustering analysis has become an essential tool for smart meter data analysis.
Among various clustering methods,
K-means has been widely applied in smart meter data analysis due to its simple computational principle and easy realization [
6,
7]. For example, Choksi et al. [
8] proposed a feature-based clustering method that integrates
K-means with feature selection techniques to analyze smart meter data, aiding electric companies in making decisions more effectively. Rafiq et al. [
9] employed
K-means to measure the similarity between electricity consumption data and classify users, enabling electric companies to offer differentiated services. However, these methods incur high computational overhead when calculating data similarity. They show that
K-means is widely used in smart meter data analysis, but it often incurs significant computational overhead.
Some researchers have reduced the computational overhead of
K-means by decreasing computational workloads [
10]. For example, Alguliyev et al. [
11] introduced a novel parallel batch clustering method based on
K-means, which partitions the dataset into blocks for computation, thereby improving computational efficiency. This method still requires calculating the data similarity between all data points and cluster centers in each iteration, leading to significant repeated computations. Nie et al. [
12] proposed an optimized
K-means algorithm (
IK-means), which eliminates the need to compute cluster centers in each iteration and requires only a small number of additional intermediate variables during optimization. This algorithm still does not resolve the issue of repeated computation in
K-means. Therefore, reducing both the computational workload and repeated computation is crucial for improving the efficiency of
K-means in data analysis.
In addition, the process of analyzing electricity consumption data using
K-means can lead to the leakage of users’ privacy, such as lifestyle patterns, electricity consumption habits, and economic status [
13,
14,
15,
16]. The exposure of such sensitive information can threaten users’ safety [
17,
18,
19]. To protect user privacy during
K-means-based electricity consumption data analysis, many researchers have applied differential privacy by adding noise to the data [
20,
21]. For example, Gough et al. [
22] proposed an optimized differential privacy method that protects electricity consumption data through a random noise sampling technique. Similarly, Zheng et al. [
23] introduced a distributed privacy-preserving mechanism for smart grids, which injects Laplace noise in a distributed manner to prevent attacks on electricity consumption data. However, these methods apply a uniform privacy budget allocation for data, resulting in low data availability. Therefore, applying a uniform differential privacy mechanism for electricity consumption data can reduce data availability.
In summary, current research mainly faces two challenges: (1) When analyzing electricity consumption data, K-means requires computing the similarity between all data points and cluster centers in each iteration, leading to a lot of repeated computations and significantly increasing the computational overhead of data analysis. (2) Although differential privacy is used to protect data during K-means-based electricity consumption data analysis, applying a uniform privacy budget allocation reduces data availability.
To address the above issues, this paper proposes an adaptive differential privacy-based CK-means clustering scheme, named DPCK. It adopts the CK-means method to reduce the computational overhead of data analysis and employs an adaptive differential privacy mechanism to enhance data availability while preserving the privacy of smart meter data. The main contributions are as follows:
We propose a CK-means clustering method by improving the K-means algorithm. This method only computes data similarity between data points and the adjacent cluster center set, effectively reducing the computational workload. In addition, during iterations, data that do not require repeated computation are placed into a stability area, avoiding repeated computation. This method significantly decreases the computational overhead of data analysis.
We design an adaptive differential privacy mechanism to protect smart meter data. During the CK-means analysis of electricity consumption data, this mechanism calculates an appropriate privacy budget for each cluster based on its distribution and adds Laplace noise. It protects data privacy while enhancing data availability in the clustering process.
Theoretical analysis demonstrates that DPCK provides differential privacy protection and effectively protects user privacy. Experimental results show that, compared to baseline methods, DPCK effectively reduces the computational overhead of data analysis and improves data availability by 11.3% while preserving data privacy.
The rest of this paper is structured as follows. We review related work on
K-means and differential privacy methods in
Section 2. After introducing the system model and relevant definitions in
Section 3, we provide a detailed introduction and theoretical analysis of the proposed DPCK scheme in
Section 4 and
Section 5, respectively. We verify its performance in
Section 6. Finally, we conclude this paper in
Section 7.
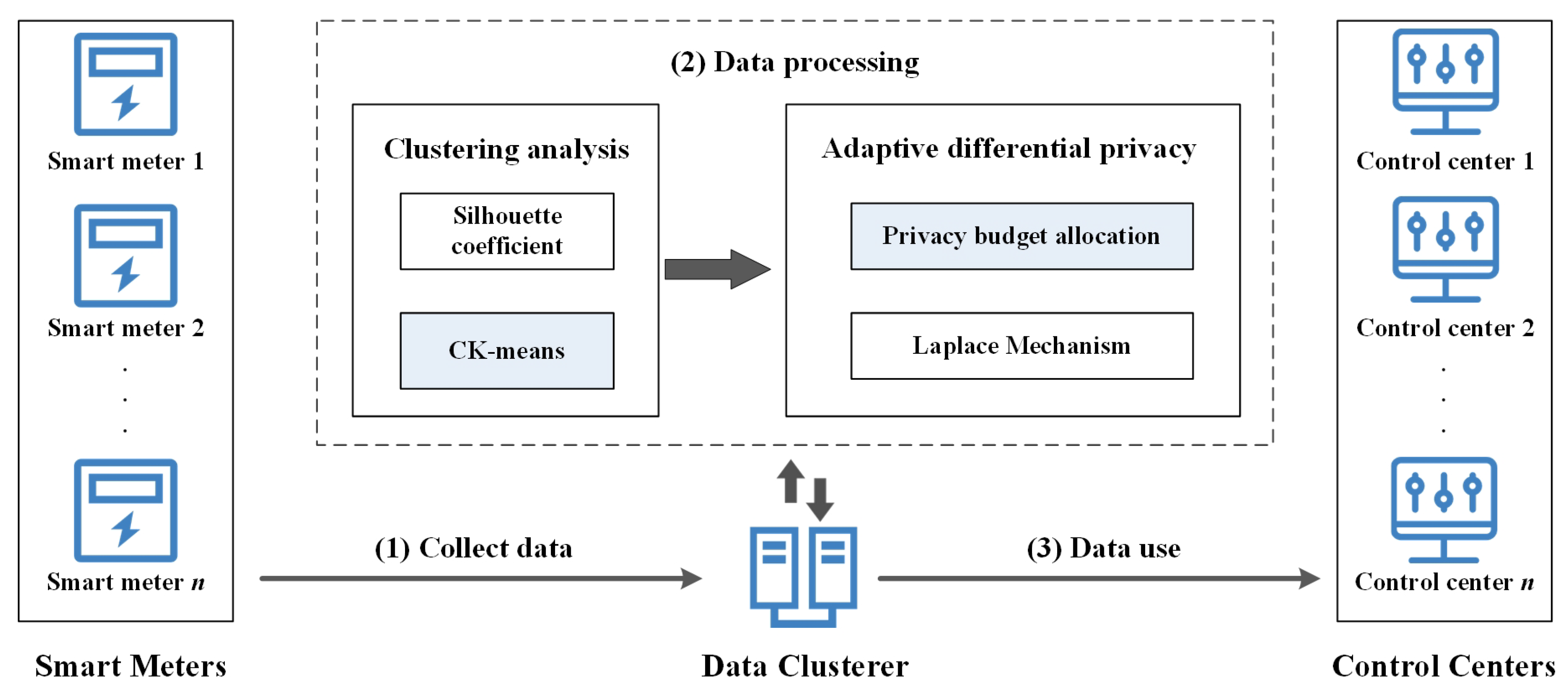
4. Our Proposed DPCK Scheme
We will detail the proposed DPCK scheme in this section, which consists of the following three steps: initialization,
CK-means, and adaptive differential privacy. The architecture of DPCK is shown in
Figure 2, and the descriptions of the notations used in this paper are shown in
Table 2.
4.1. Initialization
We use Max-Min normalization [
39] to standardize the electricity consumption data. It is a linear normalization that linearly maps the original data to the range
; the dataset
x is normalized to obtain
as follows:
The core idea of the silhouette coefficient method [
40] is to calculate the silhouette coefficient for all clusters and identify the peak as the optimal number of clusters
k. The silhouette coefficient
is as follows:
where
is the average distance between the data point
x and all other points within the same cluster. And
is the minimum average distance from the data point
x to all points in any other cluster.
We determine the optimal number of clusters k by comparing the average silhouette coefficients under different k values and selecting the k corresponding to the highest coefficient. For the query cluster, when the data points within the cluster do not move and no new data points are added, we mark the flag of the query cluster as TRUE. Conversely, it is marked as FALSE.
4.2. CK-Means Clustering
After completing the initialization, and if the is FALSE, DPCK reduces the computational workload during cluster analysis by the CK-means algorithm. A circle is the set of all points consisting of a fixed point as the center of mass and a fixed distance as the radius. The CK-means algorithm uses this structure to improve the traditional K-means algorithm, where circles are used to describe clusters. The specific definition of a circular cluster is as follows.
Definition 3 (Circular Cluster). A cluster C with the center c and the radius r is defined as a circular cluster, where x represents a data point in the cluster. The center c and radius r are defined aswhere is the amount of data in the cluster C. Furthermore, we propose the concept of adjacent clusters to reduce the computation between clusters that are far away from each other. The definition of adjacent clusters is as follows. Definition 4 (Adjacent Cluster). Let represent the center of the query cluster and stand for the center of . If satisfies Equation (8), then is the adjacent cluster of the queried cluster . We will introduce the CK-means algorithm in detail, which consists of two steps: calculating the adjacent cluster center set and data assignment.
4.2.1. Calculating the Adjacent Cluster Centers Set
DPCK calculates the movement
of the center point
of the cluster
between the
t-th and
-th iterations and the distance
between
and its adjacent cluster center
in the
t-th iteration.
and
are defined as
Subsequently, the adjacent cluster
of the query cluster
is identified using Equation (
8), and its center
is added to the adjacent center set
of
. As illustrated in
Figure 3, if half the distance between
and
is less than the radius
, then
is considered an adjacent cluster of
. In contrast, if half the distance between
and another cluster,
C, exceeds
, then
C is not regarded as adjacent.
When computing distances between data points in the query cluster and other cluster centers, only the centers in the adjacent set are considered. This adjacency-based filtering helps eliminate unnecessary comparisons with distant clusters, significantly reducing the overall computational burden during clustering. The adjacent center set is initialized as , and all cluster centers satisfying the distance condition are added to it.
When performing distance calculations, it is only necessary to compute the distance between each cluster’s data points and adjacent cluster centers. Therefore, this step reduces the computational workload of clustering analysis, and it is detailed in Algorithm 1.
| Algorithm 1 Calculating the adjacent cluster center set. |
Input: Dataset X, k, initial centers c. Output: , . 1: for to k do 2: if then 3: Calculate the movement of the center of cluster ; 4: Calculate the radius ; 5: end if 6: end for 7: if
then 8: Calculate the distance ; 9: else 10: for to k do 11: for to k do 12: if then 13: ; 14: end if 15: end for 16: end for 17: end if 18: for
do 19: if then 20: Append to ; 21: end if 22: end for 23: return , . |
4.2.2. Data Assignment
After calculating the adjacent cluster center set, we assign data by dividing each cluster into stability areas and circular areas. Specifically, DPCK calculates the distance between data points of circular areas and the adjacent centers and assigns the data points to the closer clusters.
Let be the query cluster and be the set of centers of adjacent clusters of . If is the center of and , then the stability area of is defined as a area with the clustering center and radius . The rest of the area is the moving area. The points within the stability area do not participate in data assignment, meaning that they are excluded from distance calculations and do not move. Let ; if , then has no adjacent cluster, and the data points in the cluster of do not need to be involved in the calculation.
Then, DPCK divides the moving area of
C into
i circular areas. Let
C be a query cluster with
c and
r, and let
be the set of centers of clusters adjacent to
C, where
and
. Let
and
be the center of the
i-th and
-th nearest adjacent clusters of
C. The
i-th circular area
of cluster
C is
Figure 4 shows the stability area and the circular areas of the cluster
C. From Equation (
11) and
Figure 4, it can be seen that data points in the
i-th circular area of
C are closer to the center
c than to the center of the
-th nearest cluster. Therefore, they can only be assigned within the query cluster
C and its
i nearest adjacent clusters.
For data points in the circular area, the distances to the centers in the adjacent center set are calculated, and these data points are assigned to the nearest cluster, completing the data assignment. This process is detailed in Algorithm 2.
| Algorithm 2 Data assignment. |
Input: Dataset X, k, , . Output: The set of centers c, the set of clusters C. 1: for to k do 2: if and and then 3: continue 4: else 5: Sort by distance in ascending order; 6: for each x in do 7: if then 8: continue 9: else 10: if x in the i-th circular area then 11: Compute the distance from x to its first i closest centers; 12: Assign x to the nearest cluster; 13: end if 14: end if 15: end for 16: end if 17: end for 18: for to k do 19: if is stable then 20: = TRUE 21: else 22: = FALSE 23: end if 24: end for 25: ; 26: return c, C. |
4.3. Adaptive Differential Privacy
After the current iteration of CK-means, DPCK assigns an appropriate privacy budget to each cluster and adds Laplace noise to achieve adaptive differential privacy protection. In the context of smart meter data, potential privacy threats include membership inference, where an adversary attempts to determine whether a specific user’s data were used in the dataset, and linkage attacks, where external information is used to associate anonymous records with individuals. Our adaptive differential privacy mechanism is designed to mitigate such risks by ensuring that the inclusion or exclusion of any individual user data does not significantly affect the output, thereby preserving plausible deniability and robustness against these inference-based threats. The within-cluster variance
for the cluster
, represented as the sum of the Euclidean distances between data points in
and the center
, is defined as
The between-cluster variance
for the cluster
, represented as the Euclidean distance between the center
and the mean of the
k centers, is defined as
where
is the mean center of all clusters. The clustering effectiveness of the cluster
, denoted as
, is defined as
A higher value in the current iteration indicates the tighter clustering of data points within the cluster and greater separation from other clusters, implying better clustering performance. However, it should be noted that the definition of implicitly assumes that the cluster structure remains relatively stable over time. In practice, household energy consumption behaviors may vary significantly due to seasonal, behavioral, or external factors. This temporal variability may lead to a lag between the metric and the actual clustering effectiveness. To address this limitation, a practical solution is to re-evaluate cluster stability and recompute at regular intervals or upon detecting significant changes in consumption patterns.
DPCK evaluates clustering performance using the
value and calculates appropriate privacy budgets
for each cluster:
A lower
implies poorer clustering quality or greater instability in cluster structure, suggesting a higher risk of distortion under noise. To compensate, DPCK allocates a larger privacy budget,
, to such clusters to improve utility.
Based on clustering performance, we calculate the privacy budget and inject Laplace noise,
, into each cluster to achieve adaptive differential privacy protection. This noise perturbs the data points’ values and affects their distribution, requiring the recalculation of the cluster centers. To ensure numerical stability, especially when the denominator becomes very small due to noise, we introduce a safeguard by setting a lower bound,
. The updated cluster center
is computed as
where
is the sensitivity of the query function, and
is a small positive constant to prevent instability without compromising privacy guarantees.
After computing the noisy cluster centers, we compare them with those from the previous iteration. If the centers remain consistent, DPCK terminates and outputs the final clustering results. Otherwise, the procedure in
Section 4.2 and
Section 4.3 is repeated until convergence.
5. Theoretical Analysis
In this section, we analyze the time complexity of DPCK and prove that it provides differential privacy protection for electricity consumption data through privacy analysis.
5.1. Complexity Analysis
Let N and k represent the number of data points in the dataset and the number of clusters, respectively. The time complexity of DPCK mainly consists of three parts: initialization, calculation of the adjacent cluster centers set, and data assignment.
(1) In the initialization phase, the silhouette method is used to calculate the optimal number of clusters k, and it costs .
(2) To search for the adjacent clusters of the query cluster, the distances between the query cluster center and the centers of the other clusters need to be calculated in the worst case, which costs . In Algorithm 2, the quicksort algorithm is used to sort the adjacent cluster center set in ascending order based on the distance to the query cluster center (line 5). The time complexity of this process is . In the worst case, multiplying this by all k centers gives a time complexity of . Since the adjacent clusters of the query cluster have a specific stability between successive iterations, and for many sorting algorithms, the existence of some pre-existing order in the set to be sorted can reduce the cost. Therefore, the time complexity of sorting the m distances from the center of the cluster C to the center of its m adjacent clusters is generally less than .
(3) Let and represent the number of data points in the moving area and the average number of adjacent clusters of the query cluster, respectively. The data points in the stability area remain unchanged in the current iteration and do not participate in the calculations. Therefore, during the clustering process, it is only necessary to calculate the distances from all data points in the moving area to the adjacent cluster centers, which costs . In addition, the distances from all data points in all clusters to their respective cluster centers must be calculated, which costs .
Overall, considering the worst-case scenario and all other evident loops in the algorithm, the total time complexity per iteration of DPCK is . However, an increasing number of spherical clusters become stable in the practical application, and the data points within these stable spherical clusters are not be included in any distance calculations. Consequently, in subsequent iterations, the time complexity per iteration decreases to a sublinear level.
5.2. Privacy Analysis
The DPCK scheme ensures
-differential privacy for the clustering results by adding appropriate noise, satisfying the Laplace distribution of the centers during the clustering process. Let
and
be adjacent datasets, and let
and
represent the outputs of executing DPCK on these datasets, respectively. Let
S denote any possible output set. If DPCK satisfies
-differential privacy, then the following holds:
Assume that the query function
f returns
and
as the true query results for the adjacent datasets
and
. Let
denote a specific output result. According to the probability formula of the Laplace distribution, we have
Similarly, we can obtain
According to the above equations, we have
We can also have
According to the above formula, we can obtain
Therefore, DPCK can provide -differential privacy protection for data. In real-world scenarios, it is impossible to access users’ sensitive information.
6. Experiments
In this section, we will detail how we verified the performance of DPCK by conducting experiments with other comparative methods.
6.1. Exprimental Settings
All experiments were conducted using Microsoft Windows 11 using the Python 3.9 programming language. The hardware environment used was AMD Ryzen 7 5800HS Creator Edition 3.20 GHz CPU, 16GB RAM.
The datasets used in experiments include data with different dimensions, sample sizes, and categories. They were sourced from the UCI Machine Learning Repository [
41]. The specific descriptions are as follows:
Iris: This dataset includes three classes, with 50 instances per class, totaling 150 instances, and four attributes. Each class represents a type of iris plant. Notably, the 35th sample needs to be manually modified to 4.9, 3.1, 1.5, 0.2, ‘Iris-setosa’; the 38th sample needs to be manually modified to 4.9, 3.6, 1.4, 0.1, ‘Iris-setosa’.
Wine: This dataset includes 178 instances, divided into three classes, each containing 13 attribute, with no missing values.
Electrical Grid data: This dataset includes 10,000 instances, 12 attributes, and no missing values. It is a simulated dataset designed for studying the stability of electrical grid systems.
Gamma: This dataset includes 19,020 instances, 10 attributes, and no missing values.
Eco dataset: The Eco dataset provides total electricity consumption data at 1 Hz, collected as part of the smart meter service project at ETH Zurich [
42]. Each file contains 86,400 rows (i.e., one row per second), with rows with missing measurements represented by “−1”.
6.2. Evaluation Criteria Metrics
In this section, we introduce the indicators for evaluating the experiments: the F-measure, objective function value, and silhouette coefficient.
We used the F-measure to evaluate data availability, which is the harmonic mean of
Precision (
Pre) and
Recall (
Re).
Pre refers to the proportion of correctly classified instances among all instances classified as a certain category.
Re refers to the proportion of correctly classified instances among all instances that actually belong to that category. The F-measure is the weighted harmonic mean of
Pre and
Re, and the formula is as follows:
where
is the balance coefficient for
Pre and
Re, which we set to 1 by default. A higher F-measure value indicates that the noise has less impact on the results, the availability of the data is higher, and the experimental outcome is better.
We analyzed the convergence of the DPCK scheme by comparing the objective function values of DPCK and other algorithms with different numbers of iterations. The objective of the
K-means clustering algorithm is to minimize the Sum of Squared Errors (SSE) between each data point and the center of its assigned cluster. The SSE is used as the objective function value and is
where
is the set of
k cluster centers, and
represents the center of the
i-th cluster
. The smaller the objective function value is, the smaller the convergence value of the scheme is. If the initial convergence value of the scheme is closer to the final convergence value, it means that the convergence of the scheme is better, which means that the clustering performance of the scheme is better.
We used the silhouette coefficient to evaluate the clustering performance of the DPCK scheme under different privacy budgets. The silhouette coefficient was adopted to evaluate the performance of clustering results without relying on ground truth labels. It reflected both the cohesion within clusters and the separation between different clusters. For a given data point, its silhouette coefficient was calculated as follows: Let
denote the average distance between the point and all other points in the same cluster (intra-cluster distance) and
denote the minimum average distance from the point to all points in the nearest neighboring cluster (inter-cluster distance). The silhouette coefficient of the point is then
The overall silhouette coefficient was obtained by averaging the values of all data points. A higher silhouette coefficient indicates that data points are more tightly grouped within their clusters and well separated from other clusters, implying better clustering performance.
6.3. Discussion of Experiments
We conducted experiments on computational overhead, convergence, and data availability and discuss the results. To ensure statistical reliability, each experiment was independently repeated 20 times under the same conditions. The results represent the mean values across these 20 runs.
6.3.1. Computational Overhead
In this subsection, we will analyze the computational overhead of the DPCK scheme during clustering analysis by comparing the running times for different methods. The comparison methods include the
K-means++ algorithm [
43], the
IK-means algorithm proposed by Nie et al. [
12], and the PADC mechanism proposed by Xiong et al. [
34]. Specifically, the
K-means++ algorithm improves upon standard
K-means by introducing a probabilistic initialization method that selects distant points as initial centers with higher probability, thereby reducing sensitivity to initialization and improving convergence speed.
IK-means does not require computing the cluster centers in each iteration and needs only a few additional intermediate variables during the optimization process, demonstrating both effectiveness and efficiency. The PADC mechanism improves the selection of initial centers and the distance calculation from other points to the centers. In the experimental analysis of this section, we removed the adaptive differential privacy module and only retained the
CK-means method in DPCK for comparison with other methods.
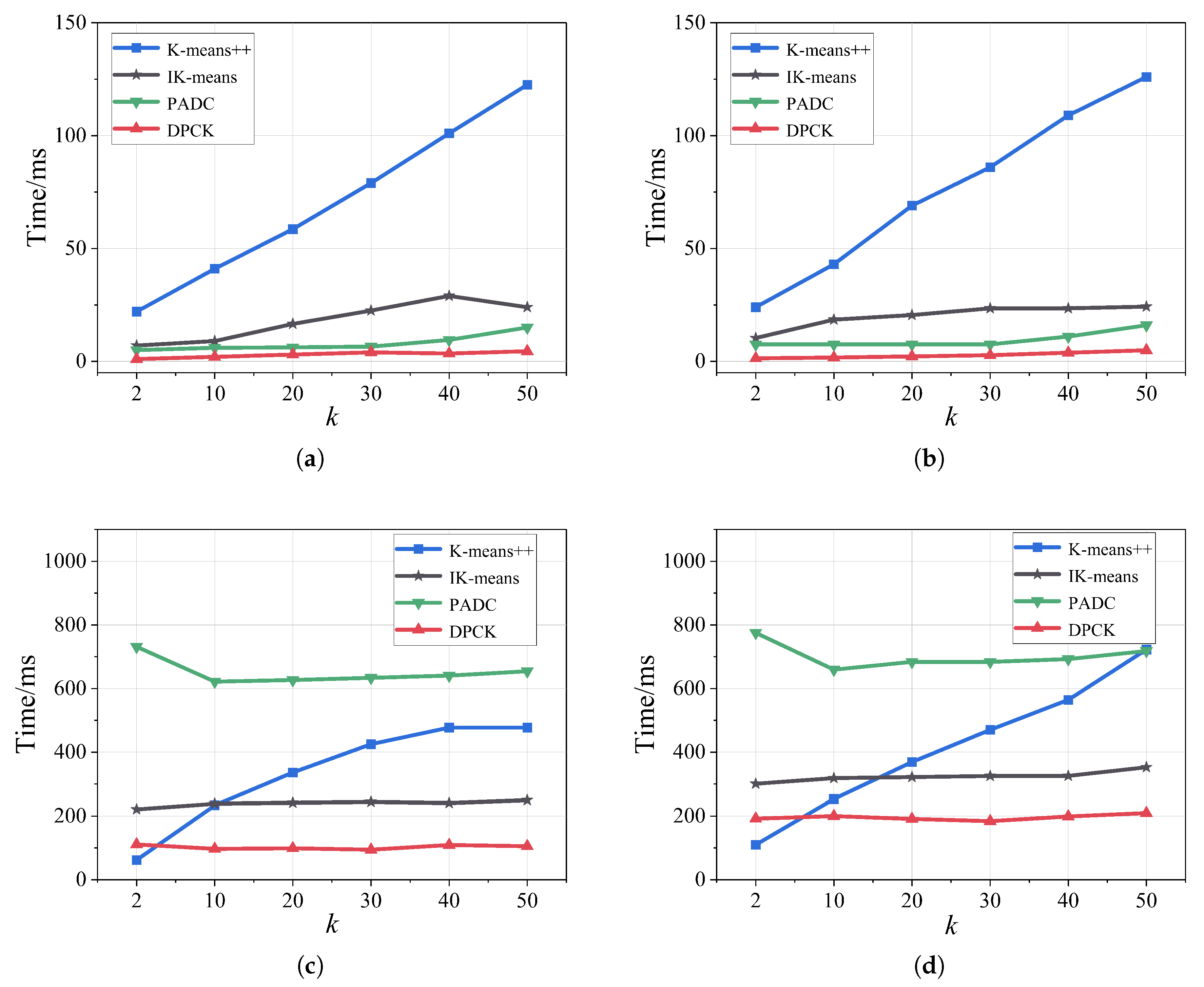
Figure 5 shows the running time of methods under different values of
k. The running time of the DPCK scheme was significantly lower than that of other methods, and its increase in running time was minimal as
k grew, where the advantages of DPCK became more evident on relatively larger datasets. To further clarify the computational overhead of the DPCK scheme, we roughly divided its overall running time into two parts: the
CK-means and the adaptive differential privacy. Empirically, we observed that
CK-means accounted for approximately 75–85% of the overall running time, while the adaptive differential privacy constituted the remaining 15–25%. The main reason is that the DPCK scheme reduced the computation workload by calculating the adjacent clusters. It also avoided repeated computation by assigning the data points that did not need to be involved in the calculation into the stability region. These factors enabled DPCK to incur lower computational overhead compared to other methods.
Therefore, compared to other methods, DPCK effectively reduced the computational overhead during clustering analysis, with its advantages becoming more pronounced as the number of clusters increased.
6.3.2. Convergence
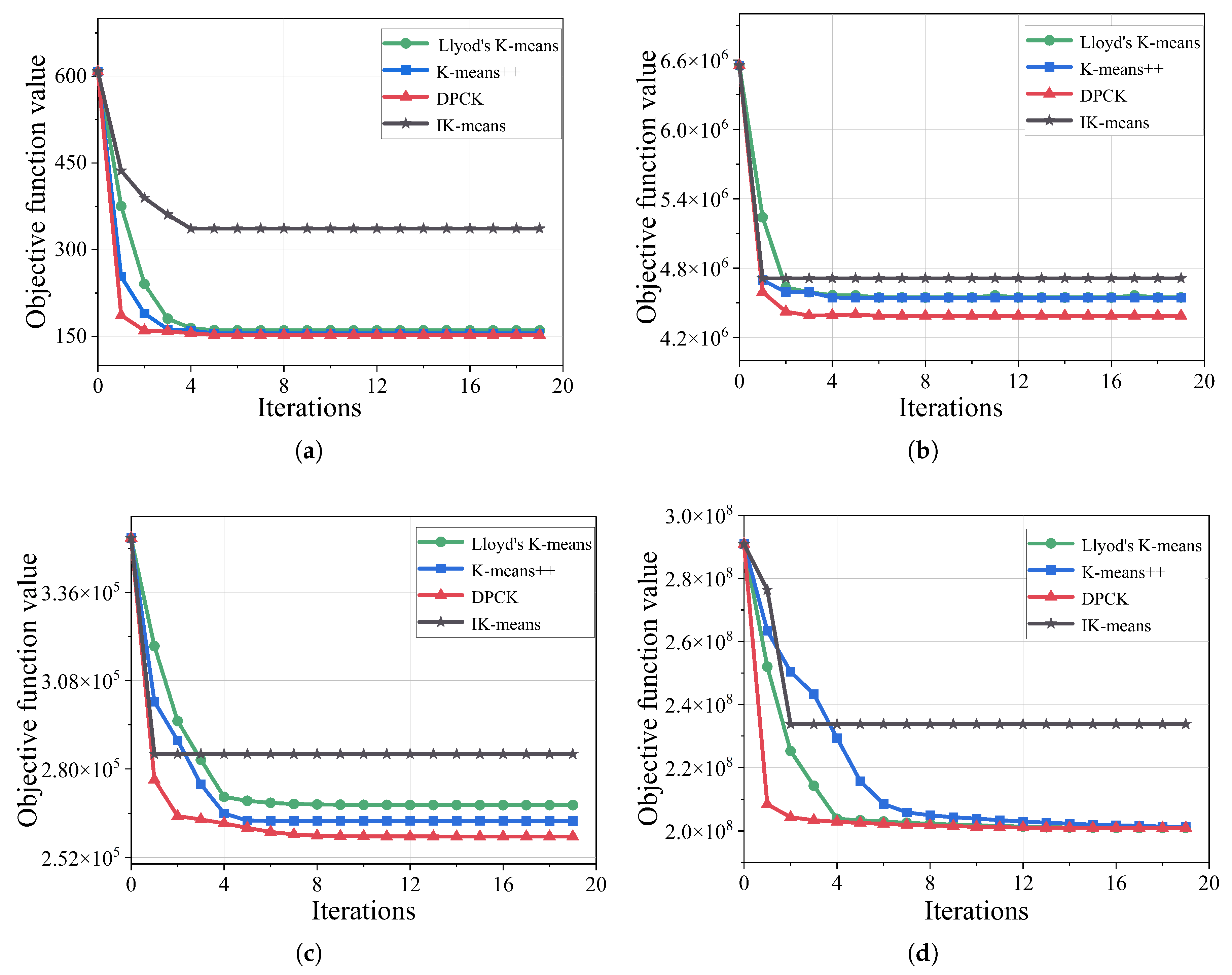
In this subsection, we will analyze the convergence of the DPCK scheme by the calculated objective function values in different iterations for the IK-means algorithm, Lloyd’s K-means algorithm, and the K-means++ algorithm.
Figure 6 demonstrates the objective function values of methods in different iterations. The results of
Figure 6a,b show that the convergence values of methods had small differences. The main reason is that the small-scale dataset involved fewer distance calculations, so the differences between the methods were subtle. However, the results of
Figure 6c,d show that the initial convergence value of DPCK was significantly smaller than that of the other methods, and its convergence curve was more stable in relatively larger datasets. This is because our method no longer needed to compute the distance between all data points and the center points in subsequent iterations, which significantly improved the convergence speed and ensured more stable convergence.
Therefore, CK-means proposed in DPCK achieved a faster convergence rate and a lower initial objective function value, indicating that DPCK has better clustering performance.
6.3.3. Data Availability
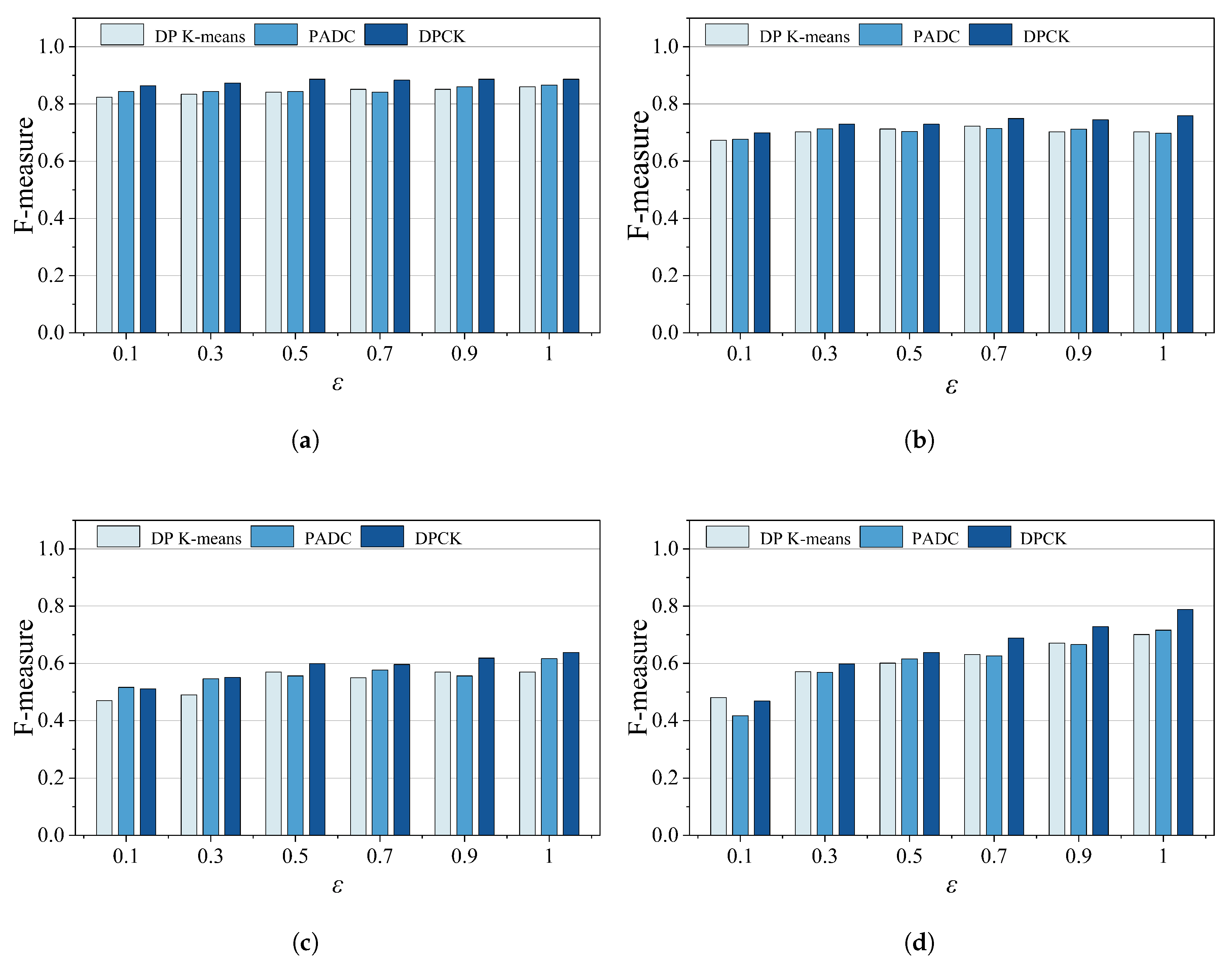
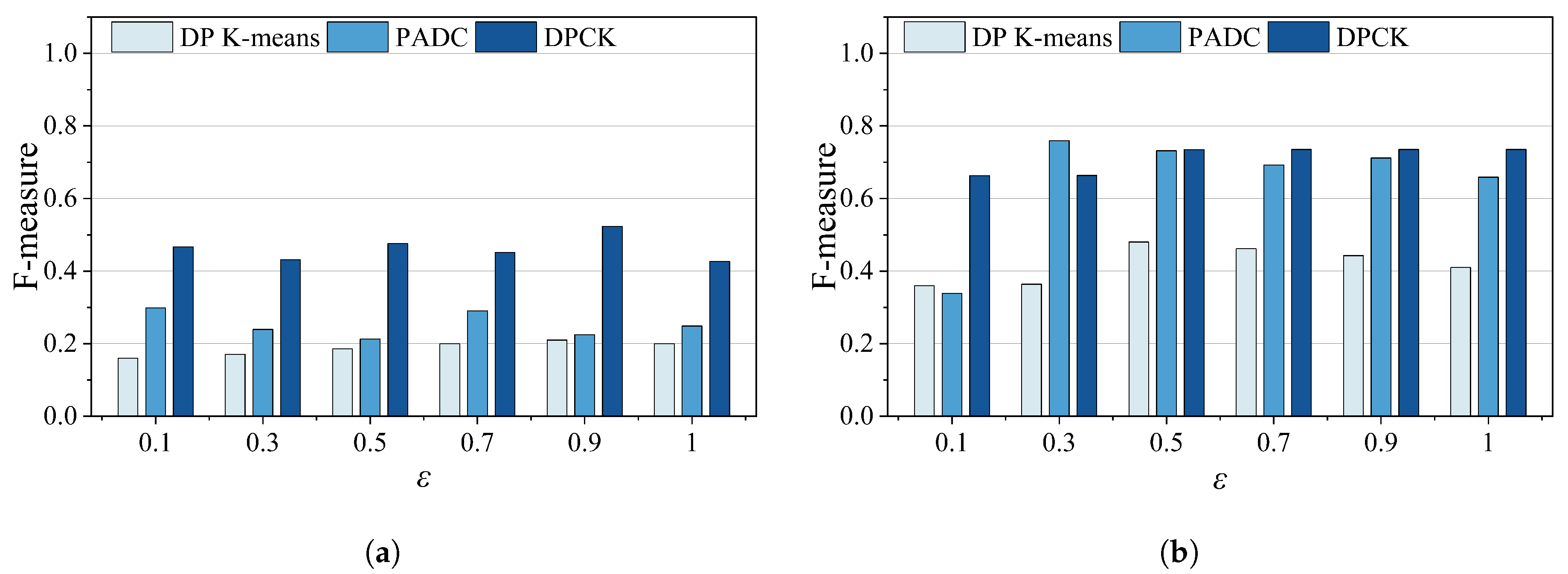
In this section, we will analyze the data availability by the calculated F-measure for the PADC mechanism, Differentially Private K-means (DP K-means), and the DPCK scheme on different datasets. Where the DP K-means is an algorithm that combines the K-means clustering algorithm with differential privacy techniques, it is used as a baseline method for DPCK to compare data availability. The privacy budget value gradually increased from 0.1 to 1.0. The larger the value was, the less the noise added was, resulting in lower data privacy and clustering results closer to the true results.
Figure 7 shows the F-measure of methods under different privacy budgets. As shown in
Figure 7a,b, the DPCK scheme averaged 8.0% higher than the other schemes. The results in
Figure 7c,d show that the DPCK scheme outperformed other methods by an average of 12%, and the advantage was more pronounced as
increased in relatively larger datasets. Overall, under the same privacy protection conditions, DPCK achieved an average F-measure improvement of 11.3% over the baseline methods. The main reason for this is that in the DPCK scheme, the necessary privacy budget was calculated based on the distribution of data points in each cluster after each clustering iteration, allowing Laplace noise to be adaptively added. It prevented either insufficient or excessive privacy protection, maximally protecting user privacy while enhancing data availability.
Furthermore, we evaluated the precision of DPCK by calculating the values of
Pre and
Re. With
= 0.1 and
= 0.9, the results for different methods are presented in
Table 3 and
Table 4. We can conclude from the tables that as the privacy budget increased, the amount of noise added to the data decreased, resulting in clustering outcomes that more closely approximated the actual data. For instance, in
Table 4, it is shown that when
= 0.9, the higher privacy budget yielded clustering results nearly identical to the real data, thereby leading to relatively small differences in the experimental results between different methods. Therefore, in the case of the same privacy budget, the
Pre and
Re values of DPCK were better than those of the other methods.
Therefore, DPCK enhances data availability compared to other methods while effectively protecting user privacy.
6.3.4. Clustering Performance
In this section, we evaluate the clustering performance of the PADC mechanism, DP K-means, and the DPCK scheme by the silhouette coefficient calculated with different datasets. The higher the silhouette coefficient was, the better the clustering performance of the method was. The privacy budget ranged from 0.1 to 1.0.
Figure 8 shows the silhouette coefficient values obtained by each method under different privacy budgets. We can see from the figure that the silhouette coefficient of DPCK was significantly higher than that of the other two comparison methods, and its fluctuation was relatively stable as the privacy budget increased. These results indicate that the DPCK scheme provided better clustering cohesion and separation across all tested datasets and privacy levels. The primary reason for this is that DPCK adaptively allocated the privacy budget based on the clustering distribution after each iteration, ensuring that an appropriate level of Laplace noise was injected. This mechanism preserved meaningful cluster boundaries and internal consistency, thus yielding a better clustering performance under differential privacy constraints.
7. Conclusions
In this paper, we propose a CK-means clustering scheme based on adaptive differential privacy, named DPCK. It introduces a CK-means clustering algorithm, effectively avoiding repeated computation and thereby reducing the computational overhead of clustering analysis. Furthermore, DPCK incorporates an adaptive differential privacy mechanism that mitigates the impact of excessive or insufficient noise caused by uniform privacy budget allocation, thereby significantly enhancing data availability. The experimental results show that the DPCK scheme effectively reduced the computational overhead during clustering analysis, with more pronounced advantages in relatively larger datasets. And compared to baseline methods, it improved the data availability by 11.3%.
In future work, we aim to improve CK-means to mitigate the impact of outliers and enhance clustering robustness. Outliers (such as meters exhibiting sudden spikes or flatlines) may significantly skew cluster centroids. We plan to investigate simple pre-filtering or localized-noise strategies to reduce their influence. We will also explore strategies to optimize the computational efficiency of the DPCK algorithm to enable faster processing on relatively large-scale energy datasets. Based on the current complexity of the DPCK scheme, we estimate that it could handle a dataset with around one million records within a few minutes on standard computing infrastructure, due to the efficiency gains from the reduction in repeated calculations and the filtering of stable regions. In addition, we plan to conduct a fine-grained runtime analysis by decomposing the overall execution time into key components—such as the CK-means loop and differential privacy adjustment—to better understand performance bottlenecks, especially in high-dimensional spaces. In terms of privacy, we plan to investigate localized differential privacy mechanisms to protect user data on the client side, including strategies to reduce the influence of extreme behaviors such as consumption spikes or flatlines. These efforts will collectively help strengthen the trade-off between computational overhead and data availability in practical deployments and will help advance the development of data analysis and privacy protection.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}