1. Introduction
With the growing maturity of autonomous driving technology, ensuring the robustness of ADS has become a key research focus [
1,
2]. As a core multimodal interface, the TSC module performs hierarchical visual–semantic parsing via DNNs to interpret regulatory instructions and guide real-time driving policies [
1,
2,
3,
4]. Enhanced by adaptive feature disentanglement mechanisms [
5], TSC balances robustness and decision granularity. However, numerous studies have demonstrated that subtle adversarial examples (AEs) [
6] can mislead TSC models, posing potentially fatal risks [
7,
8,
9]. This challenge has motivated researchers to prioritize the development of robust and effective defense mechanisms for TSC systems.
Pavlitska et al. [
10] offered a comprehensive overview of attacks on TSC systems, while highlighting a significant research gap in adversarial defense strategies. Our analysis of recent defense approaches reveals that most of them focus on input transformation [
11,
12,
13,
14,
15,
16,
17] and detection-based methods [
18,
19,
20]. For digital defenses, Wu et al. [
13] utilized 5G capabilities and mobile edge computing with singular value decomposition to mitigate perturbations from traditional attacks such as CW [
21], DeepFool [
22], and I-FGSM [
23]. Inspired by attention mechanisms, Li et al. [
14] employed a CNN to extract affine coordinates and filter pixels to counter various attacks. Salek et al. [
15] explored the use of GANs for AE denoising, though it suffers from poor transferability. Suri et al. [
16] proposed a bit-plane isolation system, utilizing a voting mechanism across models for defense, though it demands significant resources. Huang et al. [
20] used a deep image prior combined with U-Net for image reconstruction, employing a multi-stage decision-making mechanism to defend against physical AEs targeting traffic signs. Collectively, these studies indicate that current defense strategies are predominantly inclined to image reconstruction, neglecting the model’s inherent robustness. In contrast, AT [
24] has emerged as a widely used strategy for directly enhancing model robustness. Well-designed AT schemes have demonstrated considerable success in balancing robustness and accuracy [
25,
26,
27,
28]. Therefore, a comprehensive TSC system should achieve intrinsic robustness and strong generalization through AT, while maintaining minimal resource consumption.
Inspired by the cost-effective success of parameter-efficient fine-tuning [
29] in large-scale models such as GPT-3 [
30,
31]. The robust pre-training–fine-tuning paradigm [
32] has garnered increasing attention, which consists of two stages, namely, robust pre-training (RPT) and RFT. Within this context, recent innovations in AT-based RPT techniques, such as ACL methods [
33,
34,
35,
36], have made notable contributions to robust representation learning [
37,
38]. Correspondingly, the following three representative RFT strategies have emerged: standard linear fine-tuning (SLF), adversarial linear fine-tuning (ALF), and adversarial full fine-tuning (AFF). These techniques have been successfully leveraged in TSC systems, yielding outstanding performance in both standard and adversarial settings [
39].
Nevertheless, challenges remain, particularly with the rise of
upstream attacks [
40,
41], where AEs generated during pre-training compromise the robustness of downstream models. To provide a more holistic evaluation of defense capabilities in TSC systems, we categorize traditional attacks such as the fast gradient sign method (FGSM) [
6] and projected gradient descent (PGD) [
24] as
downstream attacks. Additionally, our previous work, MAD [
42], introduced a benchmark dataset specifically designed to assess robustness against
unknown attacks, further broadening the adversarial threat landscape considered in this study.
Motivation. Through a review of the existing defense methods against these diverse and complex attacks, we identify the following drawbacks in current research: (1) SSL-based defense benchmarks tailored to upstream attacks, such as genetic evolution-nurtured adversarial fine-tuning (Gen-AF) [
39], suffer drastic performance drops when deployed on downstream tasks or unseen attack scenarios. (2) ACL methods remain vulnerable to unknown attacks, revealing limitations in robustness-oriented encoder pre-training, as shown in
Figure 1. (3) Current robust pre-training–fine-tuning paradigm fails to address comprehensive security-performance trade-offs in TSC systems.
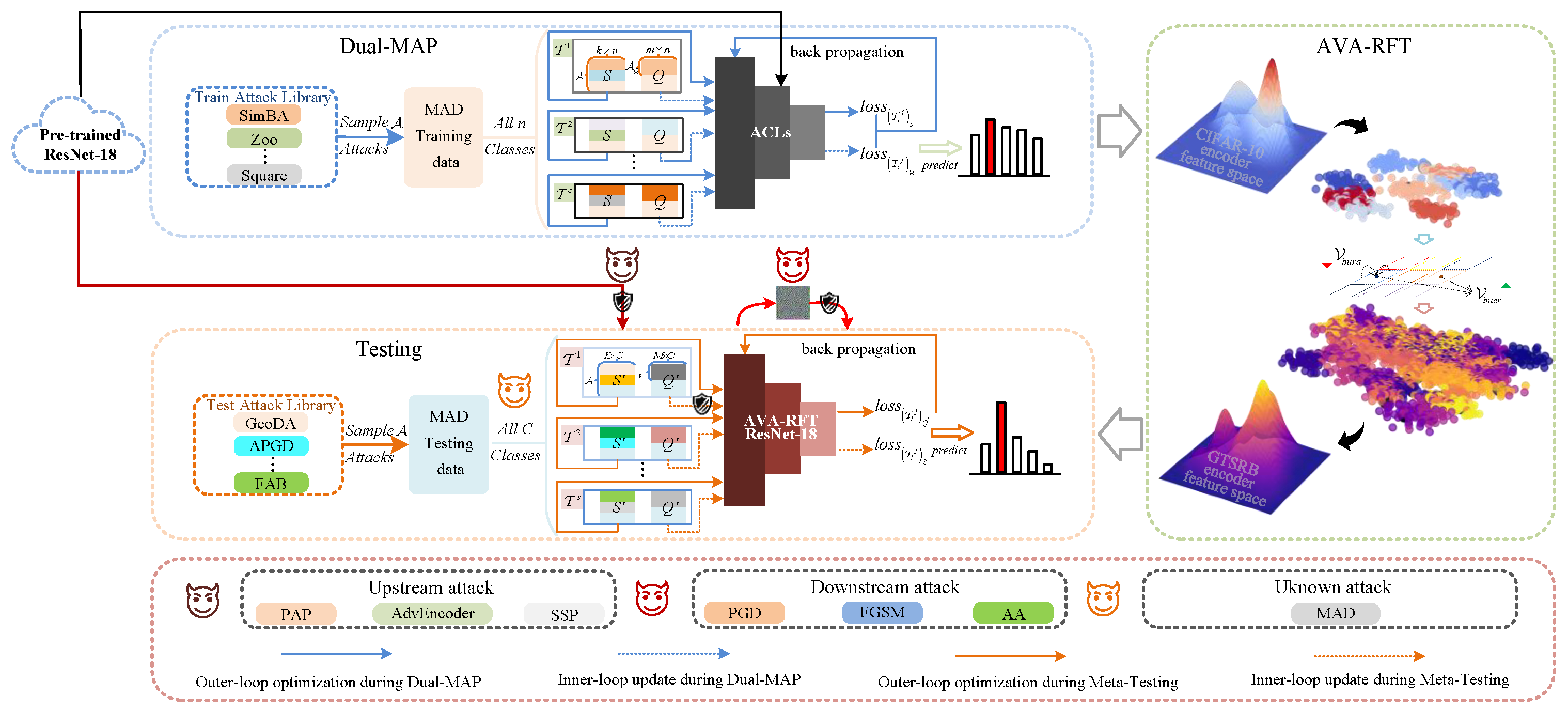
To address these limitations, we propose RPF-MAD, a robust pre-training–fine-tuning method aimed at providing comprehensive defense for TSC systems, with a focus on mitigating fundamental digital attacks. Following the widely adopted and efficient two-stage paradigm in Robust-SSL [
43], we introduce targeted innovations in both the upstream and downstream stages. In the RPT phase, we proposed a Dual-MAP algorithm, which optimizes ACL strategies to reinforce SSL-based defenses. In the RFT stage, we proposed AVA-RFT, designed as an implicit manifold alignment mechanism to preserve feature space integrity and enhance the inheritance of meta-generalized defense knowledge from the upstream model. Furthermore, by integrating meta-adversarial learning during pre-training and enforcing structure-preserving fine-tuning, RPF-MAD is inherently designed to improve adaptability and resilience against future novel adversarial attacks, thereby ensuring the sustainable robustness of TSC systems even in the presence of emerging threats. The detailed framework for RPF-MAD is depicted in
Figure 2. Experimental results demonstrate that the RPF-MAD optimized TSC model achieves comprehensive outstanding performance across upstream, downstream, and unknown attacks, with an average improvement of 1.53% in
, 2.64% in
, and 13.77% in equilibrium defense success rate (
), significantly outperforming existing methods. In summary, the specific contributions of this study are as follows:
We propose RPF-MAD as a comprehensive SSL-based defense algorithm for TSC systems, which is capable of defending against upstream, downstream, and unknown attacks.
We introduce the Dual-MAP algorithm, which empowers upstream models to maintain inherent robustness while ensuring generalized defense capabilities.
We propose the AVA-RFT algorithm, which preserves the structural integrity of the feature space, ensuring effective transfer of meta-learned robustness to downstream models. Extensive experiments validate the sustainability of the proposed defense mechanism and its adaptability across different attacks.
Figure 2.
Overview of RPF-MAD and classification of adversarial attacks in the pre-training–fine-tuning paradigm.
Figure 2.
Overview of RPF-MAD and classification of adversarial attacks in the pre-training–fine-tuning paradigm.
The remainder of this article is structured as follows:
Section 2 reviews related work on adversarial attacks and defense strategies in TSC systems.
Section 3 introduces the theoretical foundation.
Section 4 details the design of RPF-MAD and key components, while
Section 5 presents experimental evaluations and ablation studies.
Section 6 discusses broader implications, and
Section 7 concludes the study with future research directions.
4. Robust Pre-training–Fine-tuning Algorithm for Meta-Adversarial Defense
MAD augments AT by introducing broadly adaptable defensive capabilities while maintaining classification accuracy. However, its potential applicability and effectiveness within the domain of Robust-SSL are underexplored. To address this, we propose the RPF-MAD, as depicted in
Figure 2. The approach consists of two stages, as follows: (1) Dual-MAP, which enhances the robustness and defense generalization of the upstream model, and (2) Meta-RFT, which facilitates the effective transfer of upstream robustness to the downstream model, thereby ensuring comprehensive defense against various adversarial attacks.
4.1. Dual-Track Meta-Adversarial Pre-Training Algorithm (Dual-MAP)
Given an upstream MAD dataset and an ACL pre-trained encoder , we construct meta-task from a batch of AE pairs . During training, each comprises the following:
The validation/testing phase adopts an
“-way, K-shot” protocol with non-overlapping sets
and
following equivalent sizing rules. Distinct from the vanilla Meta-AT, Dual-MAP introduces a dual-track optimization strategy. We apply differentiated learning rates to the
and
, explicitly formulated as follows:
where
governs the learning rate decay for the encoder to prevent catastrophic forgetting of generic features. Consequently, the upstream model
is optimized to satisfy the following:
where
denotes the distribution of tasks, and during the training process, term
s denotes the number of episodes, multiple norms (
) of perturbations are learned. Furthermore, the upstream meta-adversarial pre-training loss is the objective function that incorporates task-specific cross-entropy loss with a smoothness-inducing adversarial regularizer (SAR) as below.
is a tuning parameter, and SAR is applied during the meta-update phase to effectively control the complexity of the model. These implementations are based on the TRADES framework [
64]. We define the
and
as follows:
Specifically, where
is chosen as the symmetrized KL-divergence. We seek to determine the optimal parameter set
of the parameterized function
at the point of minimal loss, such that the fine-tuned model
under the
ath attack generalizes effectively to a new task
under the
bth attack. The meta-update process is then expressed as follows:
The detailed pre-training phase of Dual-MAP is outlined in Algorithm 1.
| Algorithm 1 Dual-MAP (pre-training phase). |
- Input:
Pre-trained encoder , meta-learning classifier , training dataset , number of attacks in S and in Q, learning rates , , total pre-train epochs , number of classes n. - Output:
Robustly pre-trained model with meta-knowledge. - 1:
Initialize parameters and randomly; - 2:
for to do - 3:
Sample a batch of tasks , where ; - 4:
for each do - 5:
Sample datapoints from ; - 6:
Compute loss on using Equation ( 8); - 7:
Update classifier: ; - 8:
Update encoder: ; - 9:
Sample datapoints from ; - 10:
Compute meta-update loss on using Equation ( 8); - 11:
end for - 12:
Update global parameters: . - 13:
end for
|
4.2. Adaptive Variance Anchoring Robust Fine-Tuning Algorithm (AVA-RFT)
Traditional fine-tuning distorts the latent space geometry of pre-trained models, compromising adversarial robustness and weakening the rapid adaptation capability of Dual-MAP against unknown attacks. To mitigate this, we propose the AVA-RFT algorithm, which serves as an implicit manifold alignment mechanism. It preserves intra-class compactness and enhances inter-class separability, ensuring consistency between downstream optimization and latent space evolution. AVA-RFT introduces an adaptive variance anchoring (AVA) term
into the traditional fine-tuning loss function. The overall fine-tuning loss
is defined as follows (using AFF as an example):
AFF follows the TRADES paradigm. The pre-trained encoder
maps input data to a high-dimensional implicit differentiable manifold
. The geometric properties of this manifold encode meta-knowledge. The geometric structure of
encodes meta-knowledge, which AVA leverages to enforce structure-preserving fine-tuning. This process comprises three key components, mathematically formulated as follows:
Intra-class compactness and local manifold linearization. Minimizing intra-class variance
forces features of the same class to contract toward their class centroid on manifold
. This ensures feature compactness in the local tangent space:
Using the Euclidean distance approximation (L2-norm), this assumption implies that the manifold is locally flat, aligning with the low-curvature property of pre-trained models. Here, represents the size of the current mini-batch, denotes the subset of belonging to class c, denote the feature representations, and denotes the class centroid.
Inter-class separability and global topology preservation. Maximizing inter-class variance
increases the geodesic distance between different class centroids, preventing feature collapse and maintaining global manifold distinguishability:
Here, C is the number of classes, and , represent different class centroids. This is equivalent to maximizing the deviation of all centroids from the global mean under Euclidean assumptions.
AVA achieves adaptability by computing variance within each mini-batch, ensuring independence from batch size while dynamically adjusting feature distributions to align with local manifold structures. This mechanism prevents bias accumulation in global statistics and enhances feature separation. To validate the effectiveness of AVA, we analyze the dynamic behavior of
and
. From a qualitative perspective, the reduction of
encourages intra-class samples to cluster within the tangent space, while the increase of
enhances inter-class separability, thereby optimizing feature distribution on the manifold. This attraction-repulsion mechanism, jointly optimized with the task loss, ensures both compactness and discriminability of feature representations. Furthermore, we quantitatively track the variance changes throughout training, as illustrated in
Figure 3. It is evident that
exhibits a relatively decreasing trend, while
gradually increases. Despite some fluctuations, their overall trends align with theoretical expectations. These results demonstrate that AVA effectively regulates feature distribution as a structural constraint, thereby enhancing model robustness and generalization. Overall, the AVA-RFT procedure is outlined in Algorithm 2, taking AFF as an example. To further address unknown attacks, we provide the pseudo-code for the complete model evaluation process at the testing stage in Algorithm 3.
| Algorithm 2 AVA-RFT (Fine-tuning phase). |
- Input:
Pre-trained model , downstream dataset , learning rate , regularization parameters , batch size , total fine-tune epochs . - Output:
Fine-tuned model . - 1:
Initialize optimizer; - 2:
for to do - 3:
Shuffle dataset and partition into mini-batches ; - 4:
for each mini-batch do - 5:
Generate AE according to Equation ( 5); - 6:
Compute feature representations: , ; - 7:
Compute classification outputs: , ; - 8:
Compute and through Equations ( 14) and ( 15); - 9:
Compute using Equation ( 13); - 10:
Compute as in Equation ( 12); - 11:
end for - 12:
Perform gradient update . - 13:
end for
|
| Algorithm 3 RPF-MAD (testing phase). |
- Input:
Fine-tuned model , validation dataset , number of attacks in () and () set, learning rates of saved best checkpoint. - Output:
Robustly evaluated model performance. - 1:
Split into the and set; - 2:
Sample a batch of tasks , where ; - 3:
for each task do - 4:
Sample datapoints from ; - 5:
Compute loss on using Equation ( 8); - 6:
Compute adapted parameters: . - 7:
Sample datapoints from for the meta-update; - 8:
end for - 9:
Update global parameters: .
|
5. Experiments
In this section, we conduct a structured set of experiments to verify the effectiveness of RPF-MAD across the upstream task and the downstream TSC system. We evaluate its two main modules, Dual-MAP and AVA-RFT, through comparisons with SOTA ACL methods, aiming to assess robustness, transferability, and generalization under diverse adversarial conditions. Ablation studies are further conducted to examine their individual contributions to the overall defense performance.
5.1. Experimental Setup
We first present the experimental environment and basic configurations used to evaluate the proposed RPF-MAD. To ensure fair comparisons, all models were trained under identical random seeds, learning rate schedules, and evaluation protocols. Additionally, all reported results are averaged over three independent runs to mitigate performance variance due to randomness.
5.1.1. Basic Settings
All experiments were conducted on a high-performance computing (HPC) server equipped with an Intel Xeon Gold 6132 CPU and four NVIDIA Tesla P100 GPUs (12 GB VRAM each). The software environment was implemented using PyTorch (v1.13.1) with torchvision for data preprocessing and augmentation. GPU acceleration was enabled through CUDA 11.6, with mixed-precision training (FP16) applied to optimize computational efficiency.
5.1.2. Datasets and Models
To rigorously evaluate the proposed method, we conducted experiments on (1) CIFAR-10 [
65], a canonical image classification dataset comprising 50,000 training images and 10,000 test images spanning 10 classes, and (2) MAD-C [
42], a benchmark dataset comprising offline AEs generated using 29 attacks on the CIFAR-10 validation set, specifically designed for meta-adversarial defense in upstream evaluations. For downstream application analysis, we utilized (3) the GTSRB dataset [
66], which is a large-scale traffic sign classification dataset containing 39,209 training images and 12,630 test images across 43 traffic sign classes.
To ensure a fair comparison, we selected eight ACL methods from the Robust-SSL framework, all developed under the SimCLR paradigm to align with modern contrastive learning protocols. The baseline models are described as follows:
ACL [
33]. A pioneering framework that integrates AEs into contrastive learning by perturbing positive pairs to improve robustness.
AdvCL [
34]. Introduces adversarial augmentation to both anchors and positives in contrastive learning, enhancing robustness against perturbations.
A-InfoNCE [
67]. Adapts the InfoNCE loss by incorporating adversarial perturbations, improving feature discrimination under adversarial conditions.
DynACL [
54]. Applies dynamic loss scaling to balance clean and adversarial views during training.
DynACL++ [
54]. Builds upon DynACL by adding distribution-level adversarial perturbations for stronger generalization across attack types.
DynACL-AIR [
68]. Enhances DynACL by introducing adversarial instance reweighting to emphasize harder examples.
DynACL-AIR++ [
68]. Refines DynACL-AIR with adaptive instance-level perturbation scheduling to further improve sample-wise robustness.
DynACL-RCS [
55]. Introduces regularized contrastive sampling to improve robustness to unknown and distributional shifts.
For architectural uniformity, all models adopt a ResNet-18 backbone pretrained as the feature encoder, followed by a single fully connected layer for classification.
5.1.3. Adversarial Attack Protocols
Upstream attacks. To systematically evaluate the transferability of AEs generated during the pre-training phase and their impact on downstream models, we select four cutting-edge adversarial attacks: AdvEncoder [
40], PAP [
41], SSP [
57], and UAPGD [
58];
Downstream attacks. For robustness assessment on fine-tuned models, we implement two standard adversarial attacks: PGD-20 [
24] (20 iterations,
,
in
norm) and AA (evaluated on 1000 test samples with the “standard” protocol) [
56];
Unknown attacks. To assess generalization against novel threats, we curate six test attacks used in MAD-C [
42]: 2, 10, 11, 27, 28, and 29. The remaining attacks are listed in
Table A1.
5.1.4. Evaluation Metrics
To systematically evaluate the effectiveness of the proposed RPF-MAD, we employ the following key metrics:
. Measures the classification accuracy on clean examples, serving as a baseline indicator of general classification performance;
. Evaluates the classification accuracy under different attacks, quantifying the model’s resilience against adversarial perturbations;
. Provides a standardized benchmark by AutoAttack for assessing robustness across different attack scenarios, facilitating direct comparisons among defense strategies. To ensure better comparability with results reported in prior works, we also provide evaluations on the full test set, denoted as (full).
. Quantify the proportion of AEs that successfully manipulate the model’s predictions, serving as a key evaluation metric for upstream attack effectiveness. To ensure fair comparison, we standardize its definition as follows:
. Captures the trade-off between adversarial robustness and clean sample classification following rapid adaptation. A higher
reflects strong few-shot learning capabilities with minimal degradation in clean accuracy.
Furthermore, to enhance clarity in our evaluations, we introduce distinct notations to differentiate between various scenarios. Specifically, metrics for upstream models are denoted with the subscript “u”, while those for downstream models are labeled as “d”. Additionally, pre- and post-few-shot learning evaluations are distinguished using the superscript “*”. Notably, we set , and in the absence of few-shot learning, the penalty term vanishes (), reducing to a conventional defense success rate, thereby ensuring its broad applicability across diverse defense frameworks.
5.1.5. Implementation Details
To rigorously assess the effectiveness of RPF-MAD, we provide a detailed breakdown of the experimental hyperparameter configurations across different stages. The specific settings for Dual-MAP training and testing of RPF-MAD are summarized in
Table 2. Additionally, the core innovation of AVA-RFT lies in its loss function design. To ensure a controlled experimental setup, the primary hyperparameter configurations remain consistent with those used in various ACL methods across different RFT strategies. A comprehensive summary of these settings is presented in
Table 3.
5.2. Comprehensive Evaluation of Dual-MAP on Upstream Models
The robustness of upstream models plays a crucial role in determining the performance of downstream models. To investigate this relationship, we first evaluate the robustness of both vanilla RPT and Dual-MAP models, as presented in
Table 4. The results indicate that while Dual-MAP generally enhances standard classification ability, it also leads to a slight degradation in robustness. The highest metric values are in bold. Among these,
is a key indicator of the meta-learning capability of upstream models. Notably, negative
values, marked in red, indicate that unknown attacks fail against DynACL++ and Meta_AdvCL. In these cases, the
exceeds the
for vanilla RPT and Dual-MAP models, leading to negative
scores. Additionally, an extreme outlier is observed, with a value of 1327.80. This anomaly arises due to model overfitting to AEs during meta-learning, resulting in a significantly higher
than
, while
remains largely unchanged.
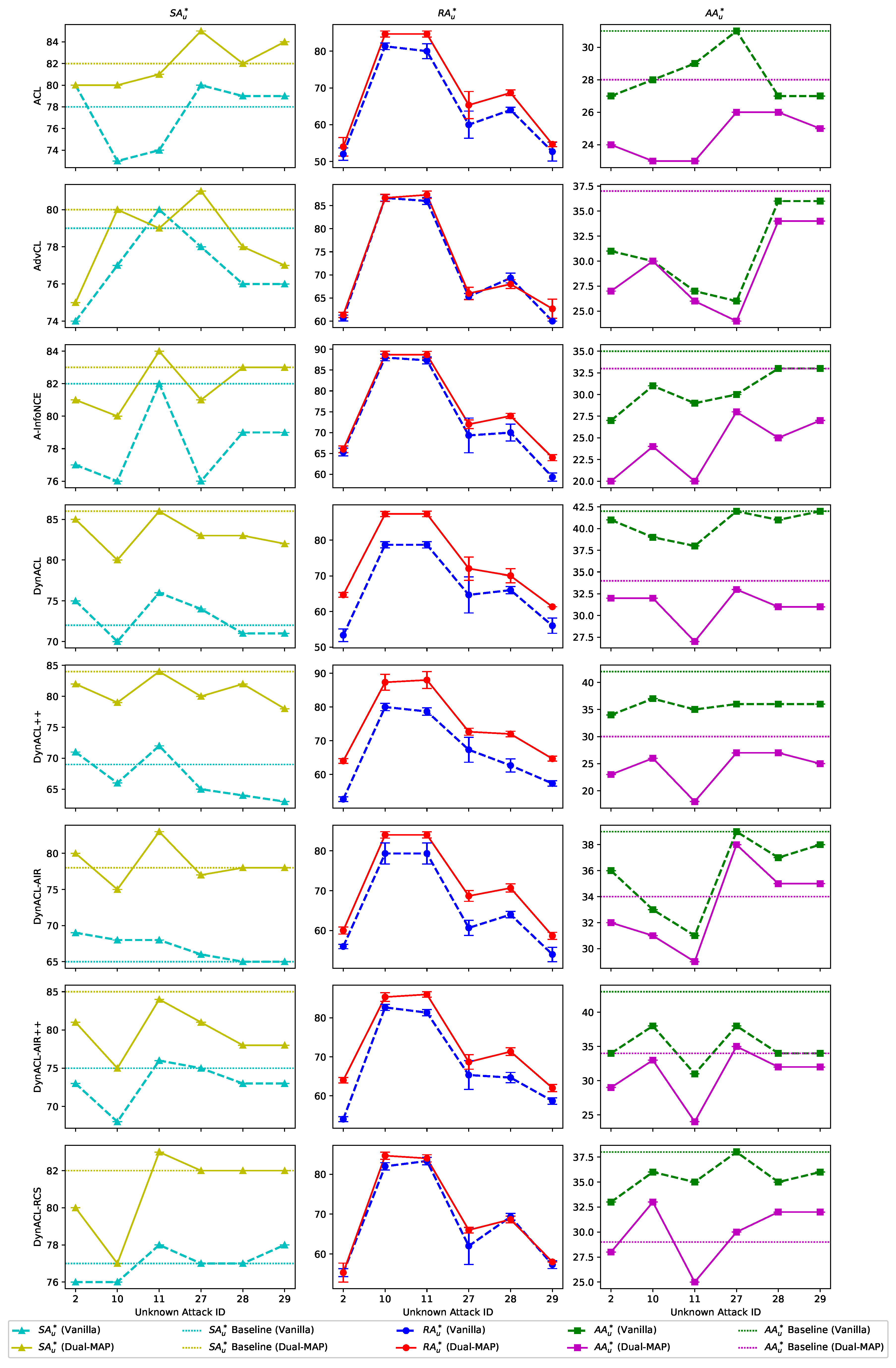
To further analyze the meta-learning defense capability of the models against unknown attacks, we conduct cross-attack generalization analysis through
Figure A1. The figure reveals that during meta-testing under unknown attacks, the increase in
and
approaches 100%, but this improvement comes at the expense of robustness, reflected in a decrease in
. Additionally, since each type of attack in meta-testing is repeated five times, we present box plots for
values in
Figure A1. These box plots demonstrate that Dual-MAP models exhibit greater stability during meta-testing, suggesting that meta-learning enables models to generalize better under previously unseen adversarial conditions.
In addition to the quantitative analysis, we also conduct a qualitative evaluation, as illustrated in
Figure A3. The figure demonstrates that models trained with Dual-MAP exhibit notable differences in feature representations compared to their vanilla counterparts. Specifically, clusters in the meta-trained models appear more compact and well-separated, indicating enhanced feature discriminability. This suggests that Dual-MAP effectively refines the feature space, potentially improving the model’s ability to generalize under adversarial conditions.
Overall, these results demonstrate that Dual-MAP enhances meta-learning defense capabilities, offering improved generalization under unknown attacks while maintaining stability during meta-testing. These findings align with our previous work, Meta-AT, which confirmed that meta-training enhances robustness against unknown attacks. Therefore, we establish that this method is also applicable within the SSL framework, further broadening its potential applications.
5.3. Comprehensive Evaluation of RPF-MAD on TSC System
In the previous evaluation of upstream models, both quantitative and qualitative analyses revealed that Dual-MAP enhances intra-class compactness and inter-class separation. This insight motivated the development of AVA-RFT to transfer the meta-defense knowledge from upstream to downstream models. To validate the effectiveness of RPF-MAD, we conduct a comprehensive evaluation of the best-performing model, A-InfoNCE, assessing its robustness against various adversarial threats in TSC systems.
We begin by evaluating model robustness, which is a central concern in the design of TSC systems.
Table 5 presents the performance of different models under varying levels of defense, where A-InfoNCE is fine-tuned under the AFF strategy. The results show that SimCLR, when fine-tuned to downstream tasks, exhibits the weakest robustness and meta-defense capacity, displaying negligible resistance to adversarial attacks. Gen-AF, as the defense baseline for comparison, improves
by 12.08% compared to the original model. However, its improvements in overall robustness and meta-defense capabilities remain limited. Notably, even the vanilla A-InfoNCE surpasses Gen-AF in robustness metrics. When equipped with RPF-MAD, the model exhibits substantial performance gains across all evaluation indicators. These results confirm that RPF-MAD effectively strengthens adversarial robustness while maintaining task-specific performance in TSC systems.
Table 6 evaluates the impact of RPF-MAD on A-InfoNCE under four SOTA upstream attacks. For clarity, we highlight the highest
and lowest
values in bold. Notably, we observe a negative
outlier case where
exceeds
, according to Equation (
16), indicating a failed attack. A comprehensive analysis of the table reveals several key insights. First, SimCLR, lacking any dedicated defense, is highly susceptible to upstream perturbations, with attacks such as PAP achieving a 100%
, and all four attacks yielding less than 16%
. This demonstrates its complete vulnerability to upstream attacks. Second, while Gen-AF demonstrates strong resistance across upstream attacks and achieves an average
of 89.20% and
of 1.57%, outperforming vanilla A-InfoNCE in all cases. However, its limited robustness under downstream attacks constrains its practical deployment in real-world TSC systems. In contrast, when enhanced with RPF-MAD, A-InfoNCE achieves comparable or even superior robustness, with an average
of 88.98% and
reduced to 1.31%. Specifically, RPF-MAD achieves the lowest
in three out of four attack settings, including a substantial reduction under UAPGD from 1.40% to 0.23%. Moreover, in the PAP attack, RPF-MAD even results in a negative
, which signifies complete defense success. These results confirm that RPF-MAD not only offers robust protection against upstream adversarial threats but also enhances the transferability and consistency of robustness across stages. This highlights its potential as a comprehensive defense solution for TSC systems, ensuring greater resilience from pre-training through downstream deployment.
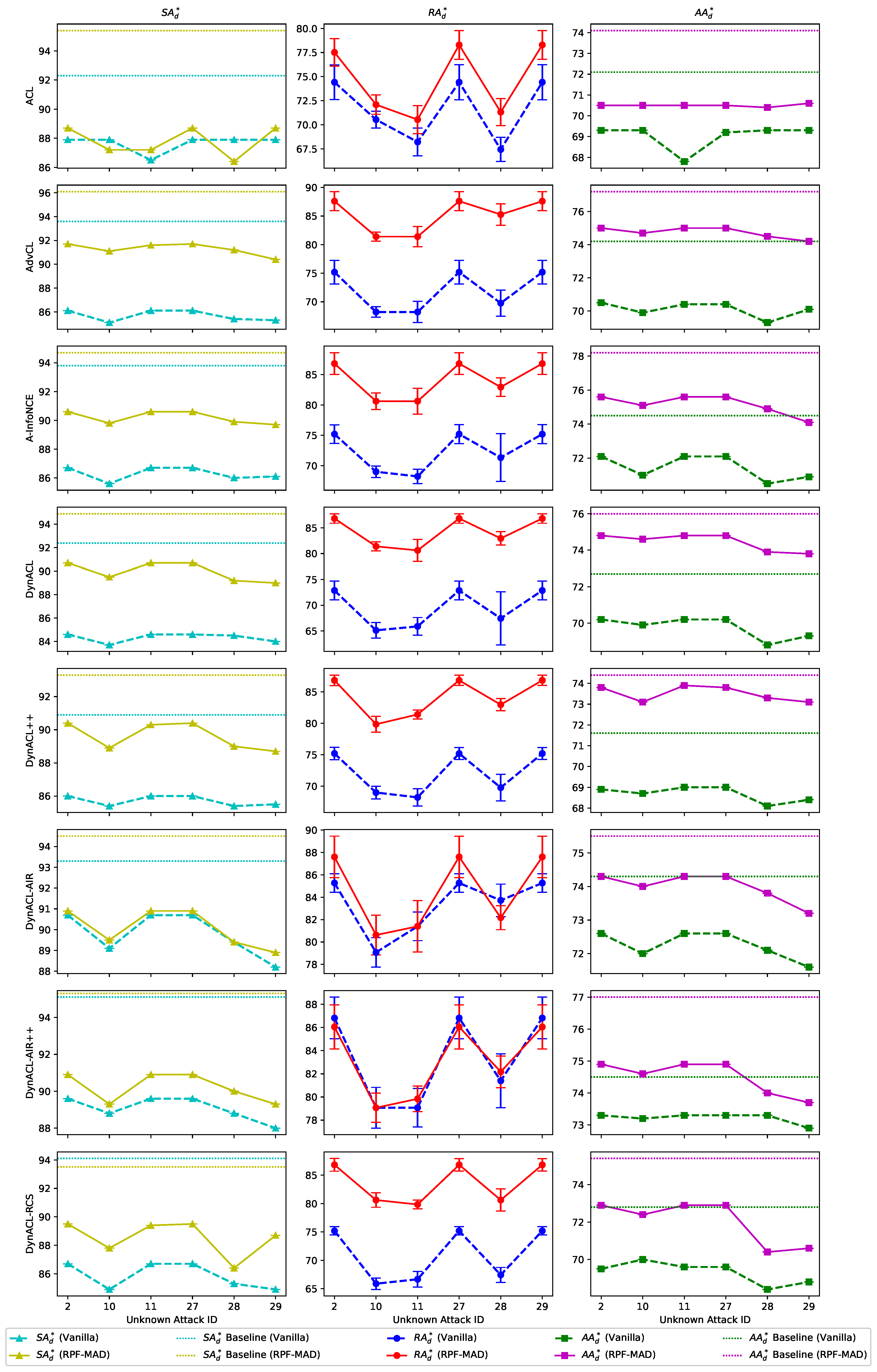
To evaluate the meta-defense capabilities inherited from upstream models, we analyze
in
Table 5. The results demonstrate that RPF-MAD significantly enhances the transferability of adversarial robustness, where
improves from 8.79% to 30.78%, indicating a more effective retention of meta-adversarial knowledge throughout the fine-tuning process.
Figure A2 provides a visual comparison of meta-defense effectiveness under unknown attacks. Across all attacks,
exhibits a slight decline during meta-testing, but RPF-MAD consistently outperforms vanilla RFT across all evaluation metrics. Surprisingly, the fact that
exceeds its baseline value further suggests that RPF-MAD not only enhances meta-defense transfer but also substantially improves downstream model robustness. This suggests that the integration of adversarial meta-learning within RPF-MAD effectively balances robustness and generalization, ensuring consistent adversarial protection across both pre-training and downstream deployment stages.
Figure 4 provides a qualitative summary of model predictions across both upstream and downstream datasets under various adversarial attack settings. Overall, qualitative and quantitative analyses of both upstream and downstream models confirm that RPF-MAD offers comprehensive defense against upstream, downstream, and unknown attacks, outperforming traditional approaches. In particular, the results under unknown attack scenarios demonstrate that RPF-MAD not only improves robustness but also increases the difficulty for adversaries to discover effective attack strategies. Specifically, compared to baseline methods, RPF-MAD significantly reduces the ASR and achieves substantial improvements in the EDSR. Since EDSR represents a comprehensive measure of the defense success rate against adversarial perturbations, its consistent increase directly indicates that the attack surface has been effectively constrained and that adversaries face greater difficulty in crafting successful attacks. Furthermore, the successful validation on the GTSRB dataset demonstrates the potential of RPF-MAD as a novel and effective robust pre-training–fine-tuning paradigm for meta-adversarial defense in TSC systems within autonomous driving. This highlights its potential for real-world deployment, ensuring enhanced model resilience against adversarial threats in safety-critical applications.
5.4. Ablation Study
In this section, we conduct ablation experiments to systematically validate the selection of A-InfoNCE as the primary robust model for TSC systems. Additionally, we evaluate the two major innovations proposed in this study: Dual-track LR optimization and the AVA term. These components are designed to enhance the robustness and generalization capabilities of our proposed RPF-MAD framework by improving both upstream meta-learning effectiveness and downstream fine-tuning stability.
5.4.1. Selection of Primary Models for TSC System
To identify the most suitable model for robust TSC systems, we conduct a comprehensive evaluation of various upstream SSL models under different RFT strategies. As shown in
Table 7, we place particular emphasis on their ability to withstand adversarial perturbations while maintaining high classification accuracy. Among these strategies, AFF consistently delivers the strongest defense performance across all models, significantly outperforming both SLF and ALF. While models such as ACL and DynACL-AIR demonstrate competitive robustness, A-InfoNCE emerges as the most balanced candidate in terms of both robustness and generalization. It is worth noting that this ablation study is conducted on the GTSRB dataset, which aligns with our primary focus on TSC systems. The optimal backbone configuration may vary for other downstream tasks, depending on the dataset characteristics and task-specific requirements.
Building on this observation, we further assess all models under the AFF configuration using the standardized AA protocol. As shown in
Table 8, RPF-MAD consistently improves downstream robustness across all evaluated models, with notable gains across all metrics. Although
remains relatively similar among models, A-InfoNCE achieves the highest
(78.20%), underscoring its superior adversarial resilience.
We further assess the meta-defense capability of A-InfoNCE through its
score, which increases substantially from 8.79% to 30.78%, ranking among the top three improvements across all models (
Table 8). Complementary results in
Figure A2 show that most models benefit from enhanced meta-defense when integrated with RPF-MAD. Taking both adversarial robustness (
) and standard classification accuracy (
) into account, A-InfoNCE demonstrates the most consistent and stable performance, maintaining lower variance and greater resilience across diverse unknown attack scenarios. These results suggest that A-InfoNCE effectively retains transferable meta-defense knowledge while preserving structural feature integrity under perturbations.
Upstream adversarial attack defense is also a central focus of our study.
Table 9 presents a comprehensive evaluation of vanilla and RPF-MAD models under four representative upstream attack types. Overall, the integration of RPF-MAD yields consistent improvements across all models, as evidenced by increased downstream robustness (
) and reduced
. Among them, A-InfoNCE exhibits the most balanced and robust performance. It achieves the highest average
across attacks and the lowest average
, including the best result under UAPGD, where
drops to 0.23%. Moreover, under the more challenging PAP attack, A-InfoNCE achieves a negative
of −0.86%, indicating complete defense success in certain instances. These findings further underscore its superior resistance to upstream adversarial transfer and its capacity to retain transferable meta-defense knowledge.
Qualitative analyses further support these findings. As shown in the t-SNE visualization in
Figure A4, A-InfoNCE, alongside other RPF-MAD models, exhibits clearer inter-class boundaries and reduced feature overlap compared to vanilla variants, indicating enhanced feature separability and adversarial robustness.
In summary, both quantitative and qualitative evidence establish A-InfoNCE as the most reliable and well-rounded choice for robust TSC systems. Its exceptional generalization, adversarial resilience, and structural representation capabilities justify its adoption as the primary robust model within the RPF-MAD framework.
5.4.2. Dual-Track Learning Rate Optimization
In this experiment, we conducted a Pareto front-based visualization (
Figure 5) to analyze the impact of different LR configurations on model performance, specifically focusing on the LR of the encoder and the fully connected layer (FC) in ACL. The dataset comprises multiple
results, with the objective of identifying an optimal LR combination that maximizes
while maximizing
.
To systematically assess the effect of different LRs, each experimental configuration is represented using a dual-layer color encoding. The inner solid color (blue) represents Encoder LR, with darker shades signifying higher values and lighter shades indicating lower values. Similarly, the outer circular border (green) reflects FC LR, where deeper shades correspond to smaller values and lighter shades denote larger ones. This dual-layer representation effectively distinguishes the respective influences of the encoder and FC LRs on model performance. A Pareto front (depicted as a gray dashed line) is constructed to identify optimal LR trade-offs. Among all tested configurations, is selected as the optimal setting, with Encoder LR = 0.01 and FC LR = 0.005. This point is explicitly highlighted with a bold red circular marker, while a surrounding elliptical blue dashed boundary encloses other near-optimal configurations. These results validate the dual-track optimization strategy, demonstrating its efficacy in refining model performance through targeted learning rate selection.
5.4.3. Adaptive Variance Anchoring Term
Table 10 and
Table 11 present an ablation study evaluating the impact of the AVA term on the robustness of various downstream models under both vanilla and meta-pre-trained settings. The results indicate that incorporating AVA consistently enhances model robustness across different architectures. Specifically, in the vanilla setting (
Table 10), the inclusion of AVA improves robust accuracy
and adversarial accuracy
in all models. For instance, in the ACL model,
increases from 59.83% to 64.52%, and
rises from 45.26% to 49.33%. Similarly, DynACL-RCS exhibits an improvement in
from 58.61% to 64.14% and in
from 43.67% to 48.55%.
In the meta-pre-trained setting (
Table 11), the benefits of AVA are also evident, particularly in models such as AdvCL and A-InfoNCE. The AdvCL model achieves an increase in
from 58.27% to 65.46% and in
from 44.20% to 49.26%. Likewise, A-InfoNCE with AVA attains the highest
improvement in the meta-setting, rising from 45.28% to 50.17%. While some models exhibit minor reductions in
with AVA, these decreases are marginal and offset by significant gains in robust and adversarial accuracy.
For the horizontal comparison in vanilla and RPF-MAD, we observe that without AVA, meta-pre-trained models do not consistently outperform traditional fine-tuning methods. This may be attributed to the increased feature dispersion introduced during meta-pre-training, which can lead to suboptimal adaptation. However, with the anchoring constraint of AVA, the robustness of meta-pre-trained models improves significantly during fine-tuning, surpassing traditional methods while preserving the benefits of meta-knowledge. This highlights AVA’s role in mitigating the instability of pre-trained features, ensuring more structured adaptation to downstream tasks.
The consistent improvements across various architectures confirm that AVA serves as a crucial mechanism in stabilizing the meta-adaptation process, reinforcing the model’s resilience while maintaining strong generalization capabilities. These findings validate RPF-MAD as a promising solution for adversarial robustness in the pre-training–fine-tuning paradigm.
7. Conclusions
In this paper, we propose RPF-MAD, a novel meta-adversarial defense algorithm designed to enhance the sustainability and safety of TSC systems. RPF-MAD integrates Dual-MAP for upstream robustness enhancement and AVA-RFT for structured fine-tuning. By leveraging meta-learning principles, our approach constructs a scalable and generalizable adversarial defense strategy that effectively addresses the limitations of traditional AT and conventional pre-training–fine-tuning paradigms. Specifically, Dual-MAP optimizes ACL-based self-supervised learning methods to enhance the upstream model’s capacity to generalize across diverse adversarial attacks. Meanwhile, AVA-RFT preserves latent feature structure during fine-tuning, ensuring that the downstream model inherits upstream robustness while maintaining strong generalization.
To systematically evaluate RPF-MAD, we conducted extensive experiments on eight SOTA ACL methods and three RFT techniques using the CIFAR-10 and GTSRB datasets, demonstrating its superiority across multiple attack scenarios. Our results show that RPF-MAD significantly improves , , , and , outperforming existing SOTA defense methods. In particular, our method enables rapid adaptation to novel attacks while ensuring long-term robustness, a critical requirement for autonomous perception systems.
While RPF-MAD offers significant advantages, it also presents certain challenges. Future work will focus on further enhancing the framework, including integrating backdoor defenses to mitigate potential vulnerabilities. Additionally, beyond image classification, we plan to extend RPF-MAD to object detection, multimodal learning, and large-scale adversarial adaptation in safety-critical environments.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}